Share
第6回MLOps勉強会で発表した内容になります。
------ 広告配信領域において、TFXとKubeflowによる学習パイプラインを構築した事例についてお話します。 具体的には学習処理を定期実行し、鮮度の高い学習済みモデルを本番にデプロイする構成についてお話します。 出来る限りMLOps周りに焦点をあて、事業ドメインや採用しているモデルに深入りせずお話出来ればと思います。
https://mlops.connpass.com/event/206228/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
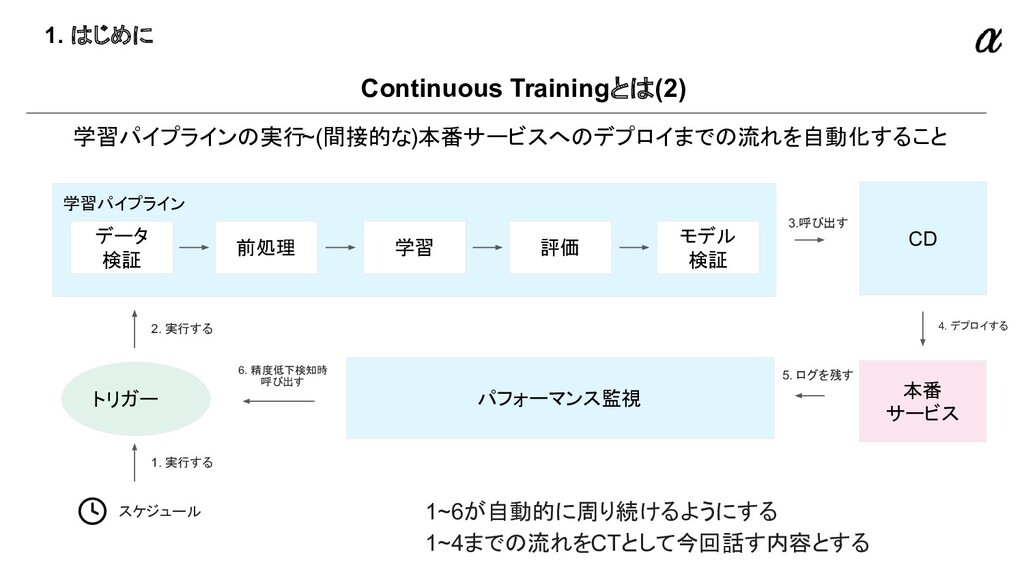{kind=link}
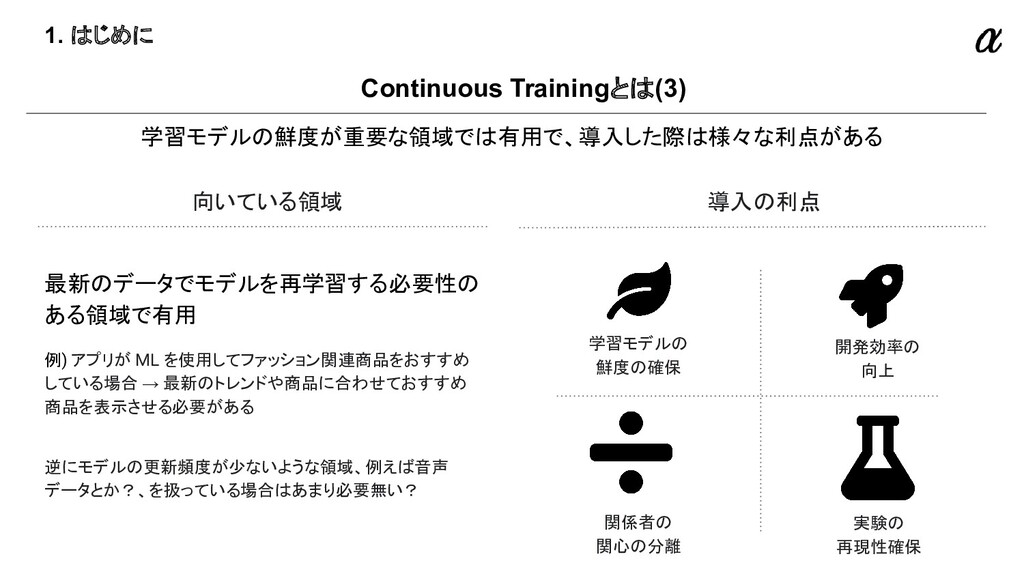{kind=link}
{kind=link}
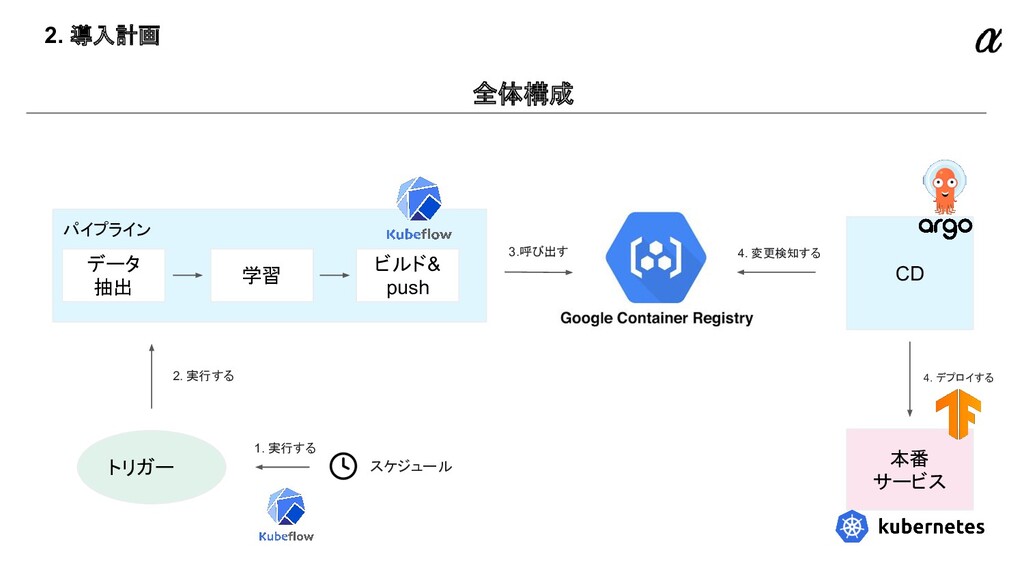{kind=link}
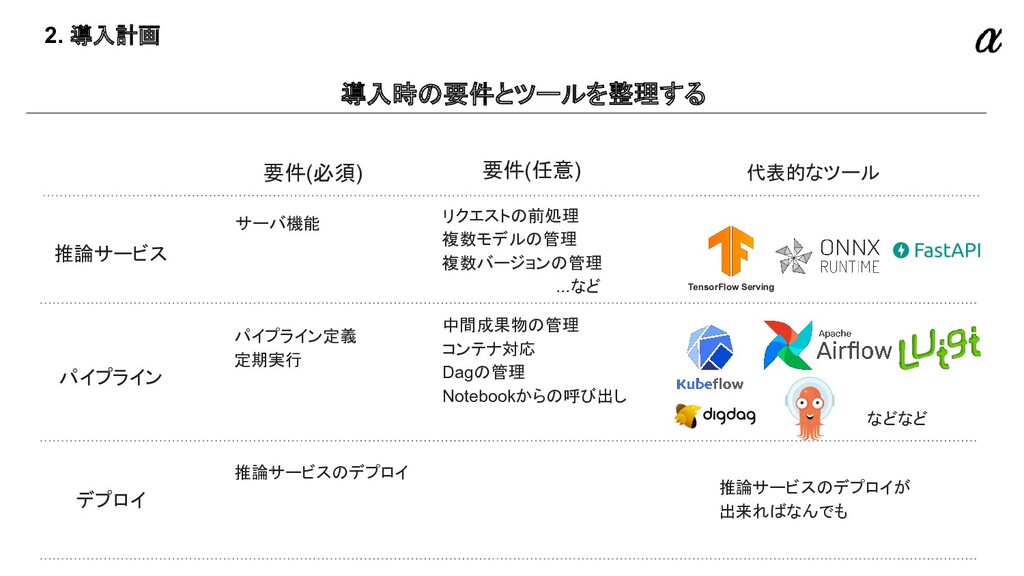{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
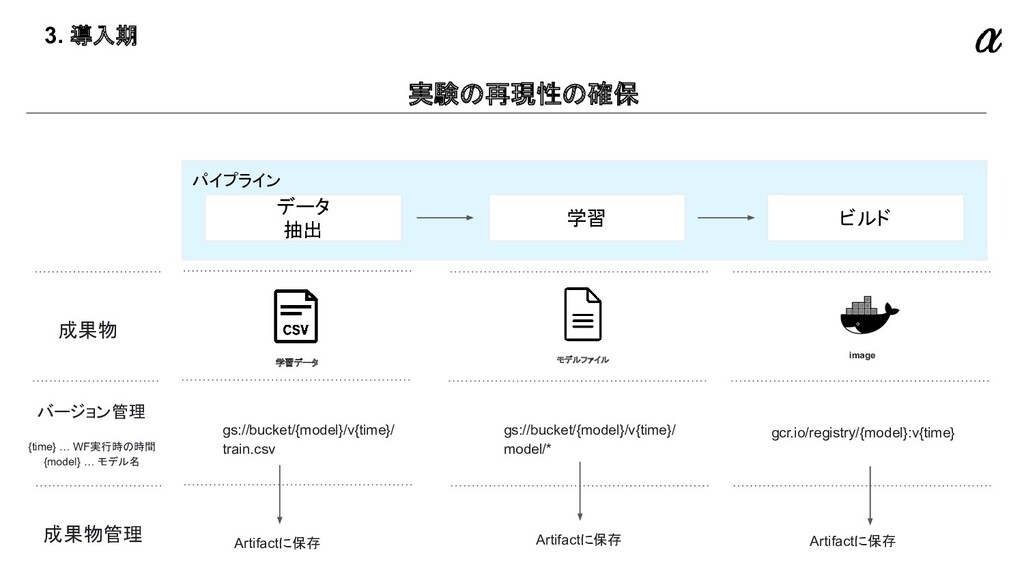{kind=link}
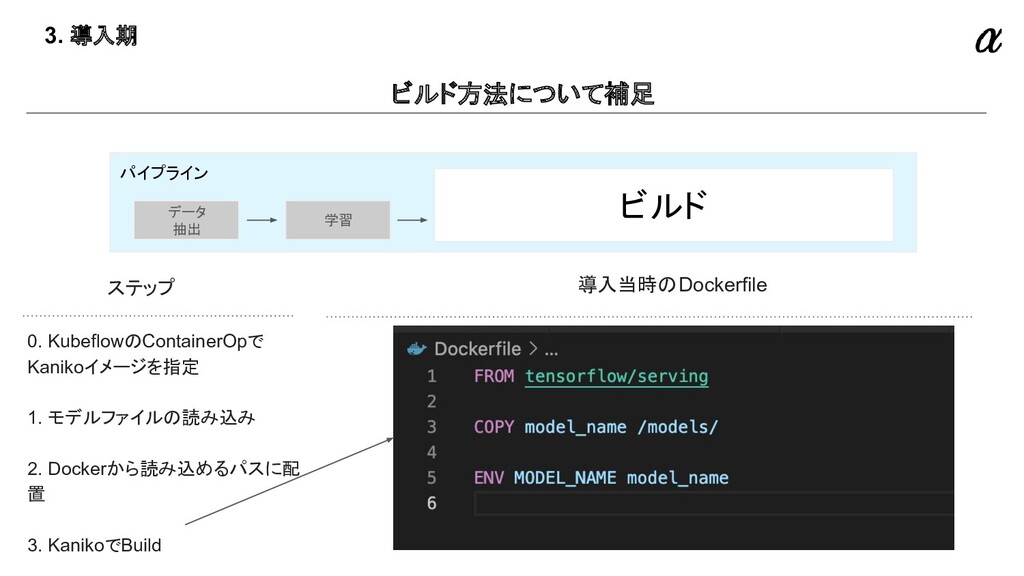{kind=link}
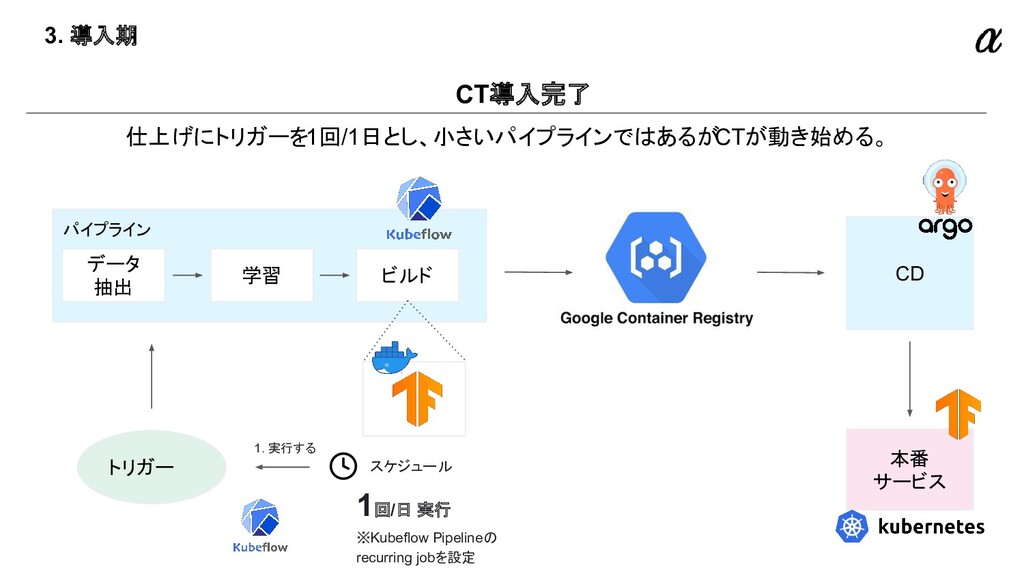{kind=link}
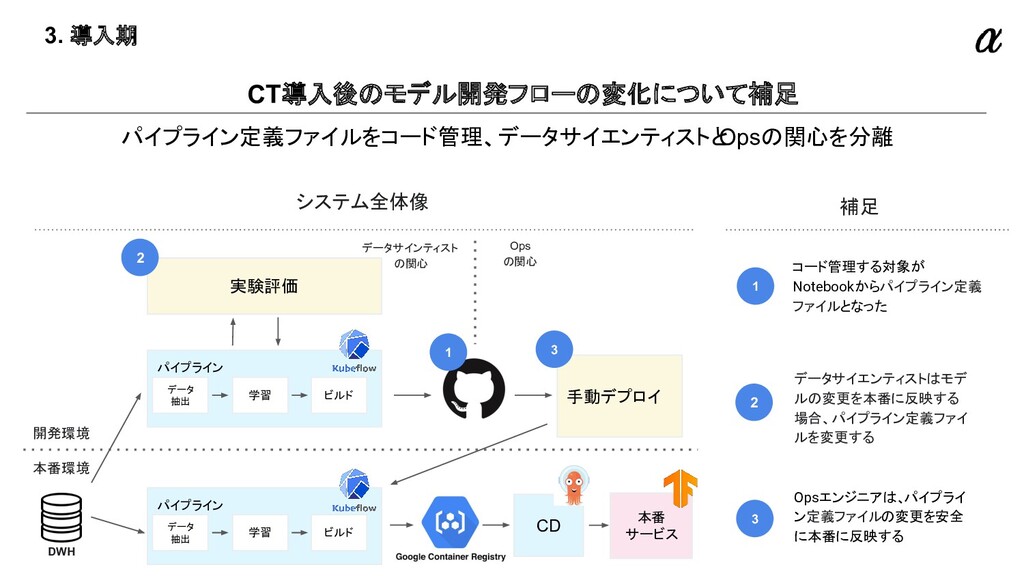{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}