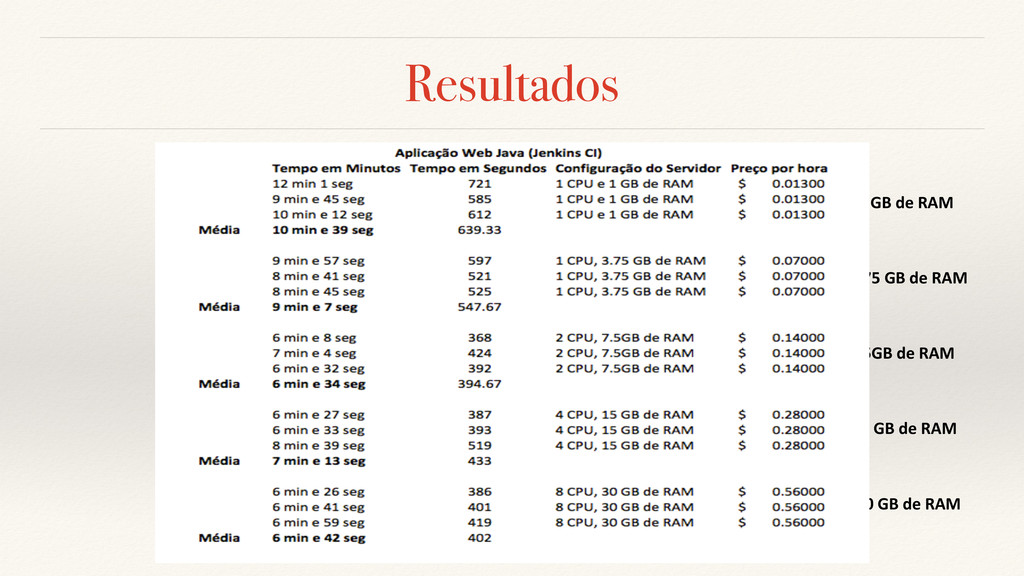
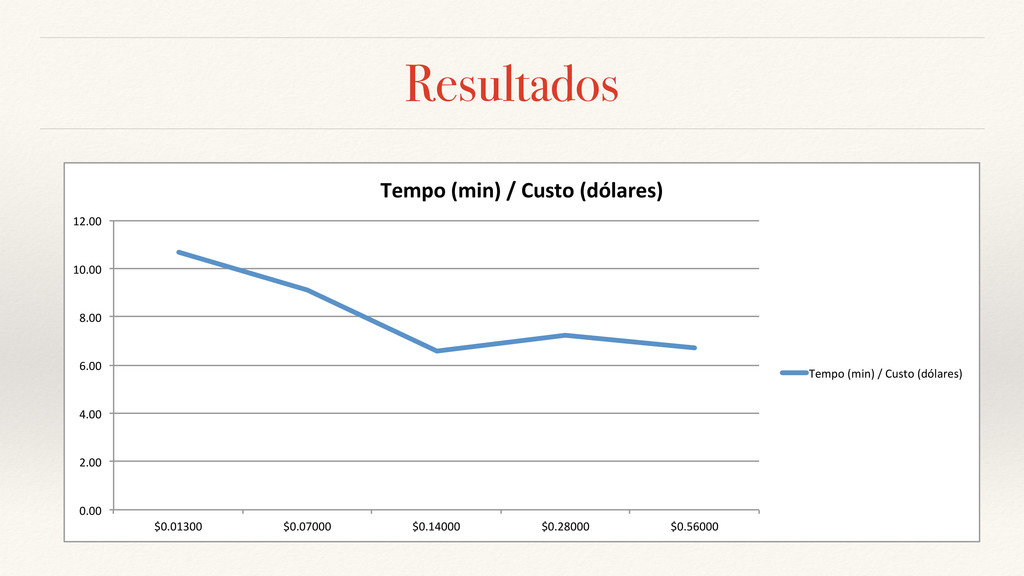
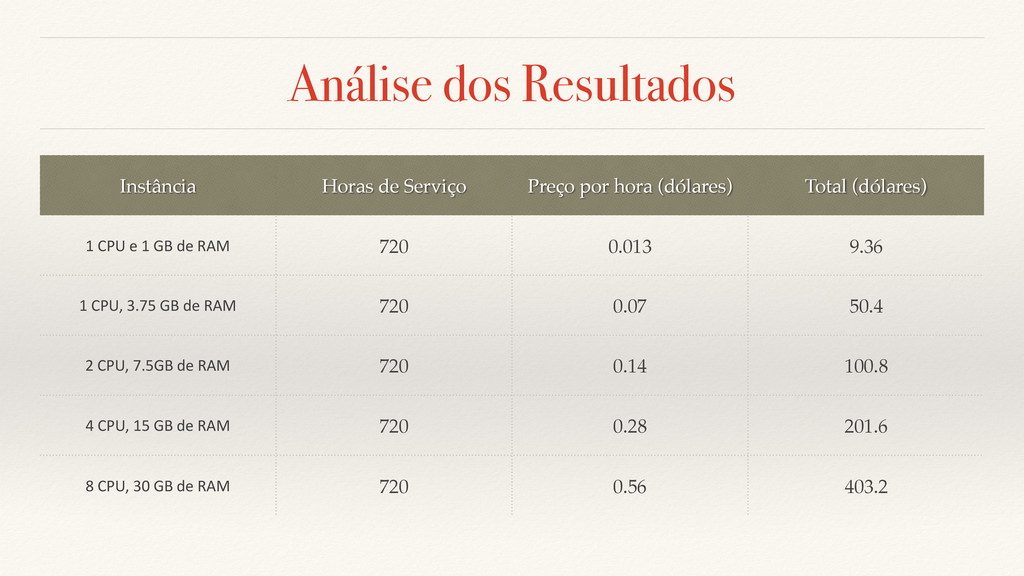
aplicação pode se tornar indisponível por 3 dias e meio, ou aproximadamente 85 horas. ❖ Considerando o DR sendo feito em máquinas de custo inferior a $0.14 por hora e o tempo médio de deploy nestas sendo 9 minutos e 53 segundos, seria possível o uso desta proposta 441 vezes durante o ano para que fosse cumprido este uptime. ❖ Para o teste realizado com aplicações em máquinas virtuais de custo superior a $0.14 por hora, e o tempo médio de deploy nestas sendo 6 minutos e 49 segundos, seria possível o uso desta proposta 746 vezes durante o ano para que fosse cumprido este uptime.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Referência: [1]](https://files.speakerdeck.com/presentations/f67f5f9bd29842fea906d9e0bcf29f79/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Amazon AWS Referência: [3]](https://files.speakerdeck.com/presentations/f67f5f9bd29842fea906d9e0bcf29f79/slide_11.jpg){kind=link}
![Amazon AWS Referência: [2]](https://files.speakerdeck.com/presentations/f67f5f9bd29842fea906d9e0bcf29f79/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Custos Referência: [4]](https://files.speakerdeck.com/presentations/f67f5f9bd29842fea906d9e0bcf29f79/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Referências ❖ [1] http://www.techtudo.com.br/noticias/noticia/2014/11/black-friday- comeca-com-erros-durante-a-compra-sites-offline-e-reclamacoes.html ❖ [2] AWS Summit NYC](https://files.speakerdeck.com/presentations/f67f5f9bd29842fea906d9e0bcf29f79/slide_27.jpg){kind=link}
![[email protected] [email protected] Obrigado](https://files.speakerdeck.com/presentations/f67f5f9bd29842fea906d9e0bcf29f79/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}