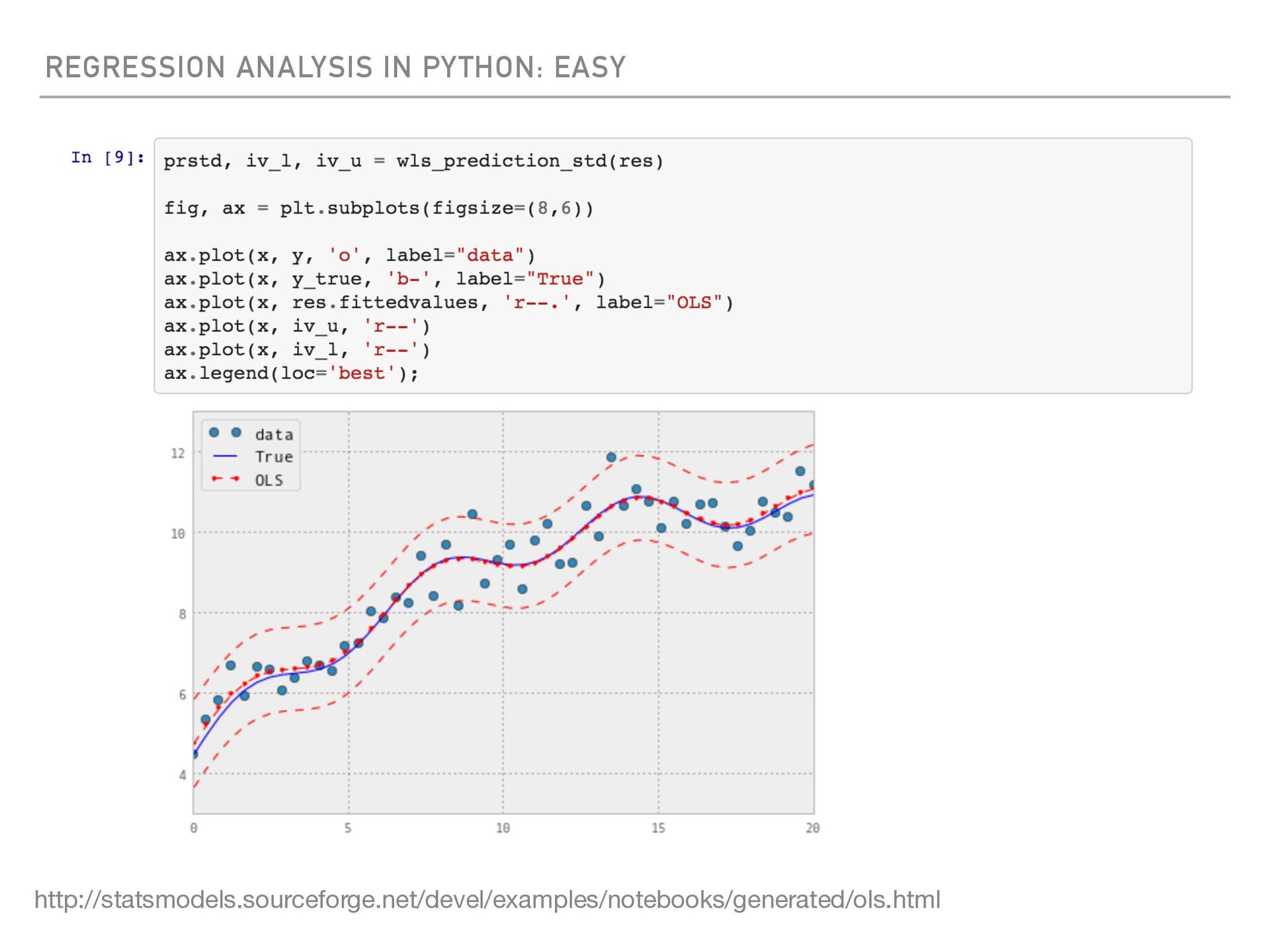
TEST, PERFORM A REGRESSION ANALYSIS OVER DATA SAMPLES WITH R, DESIGN AND IMPLEMENT AN ALGORITHM FOR SOME DATA-INTENSIVE PRODUCT OR SERVICE IN HADOOP, OR COMMUNICATE THE RESULTS OF OUR ANALYSES Jeff Hammerbacher ONE DAY AT FACEBOOK’S DATA SCIENCE TEAM, A MEMBER COULD… http://berkeleysciencereview.com/scienti fi c-collaborations-uc-berkeley-data-driven-cover/
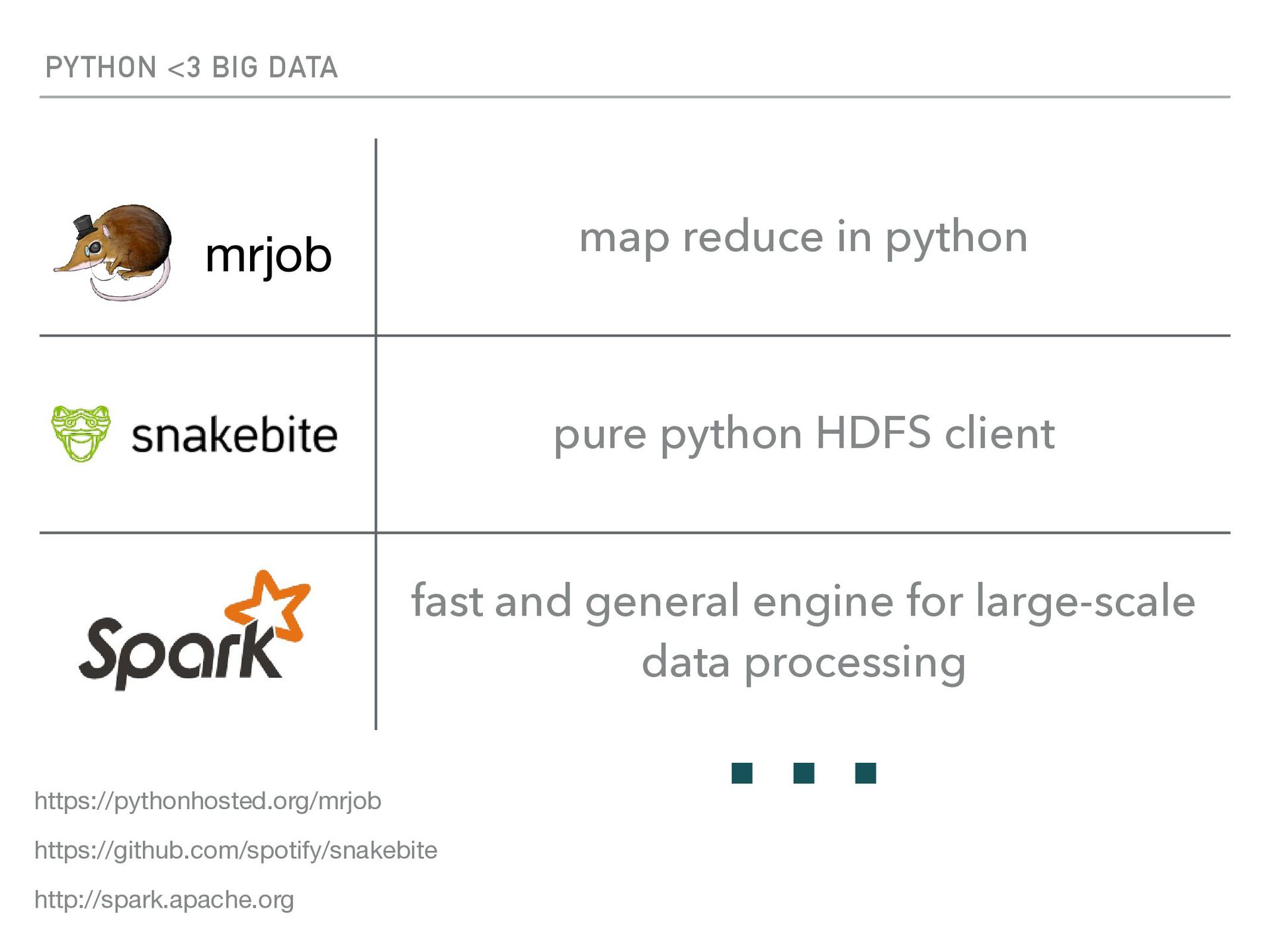
HDFS client fast and general engine for large-scale data processing mrjob http://spark.apache.org https://github.com/spotify/snakebite https://pythonhosted.org/mrjob …
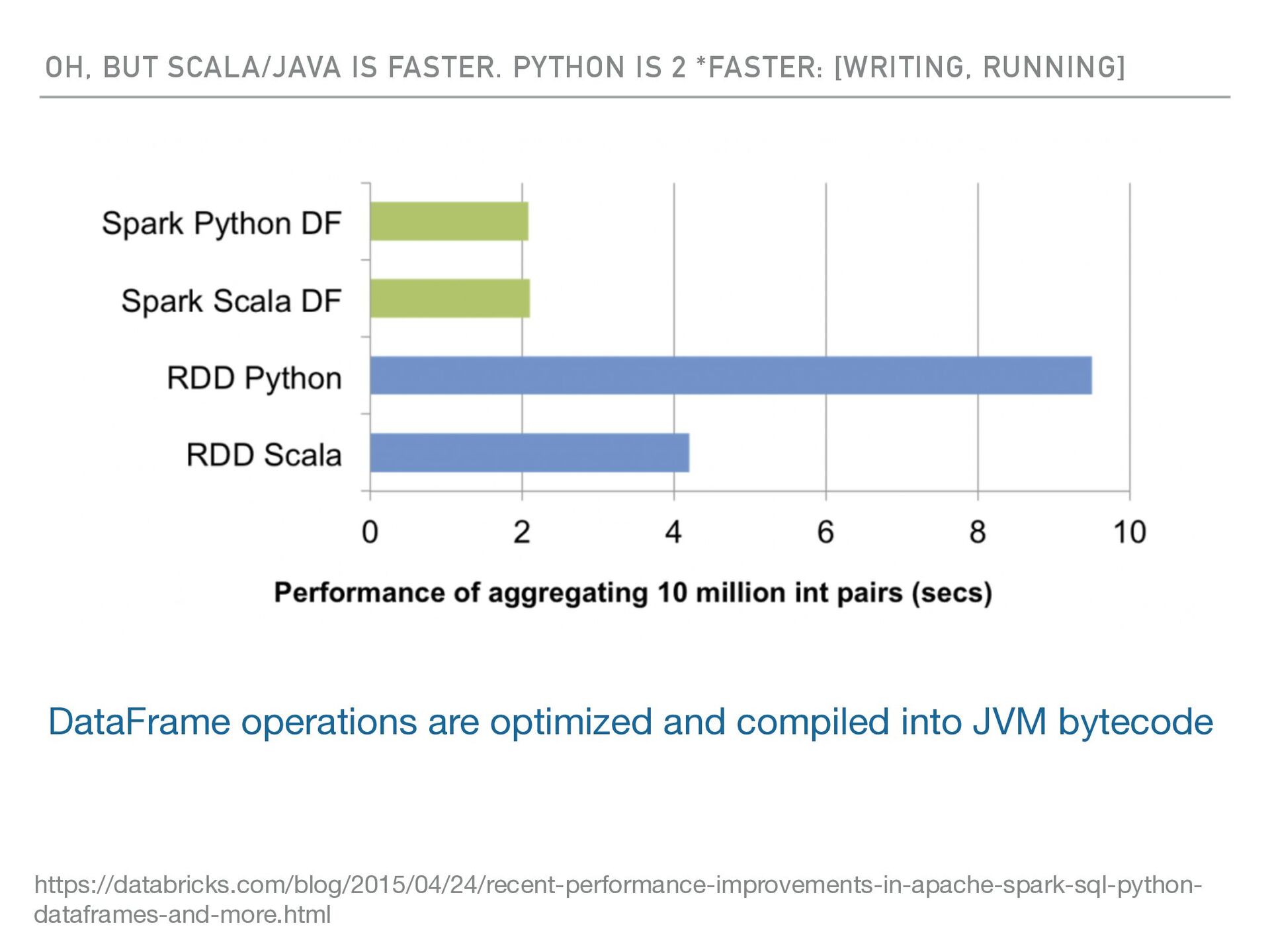
RUNNING] DataFrame operations are optimized and compiled into JVM bytecode https://databricks.com/blog/2015/04/24/recent-performance-improvements-in-apache-spark-sql-python- dataframes-and-more.html
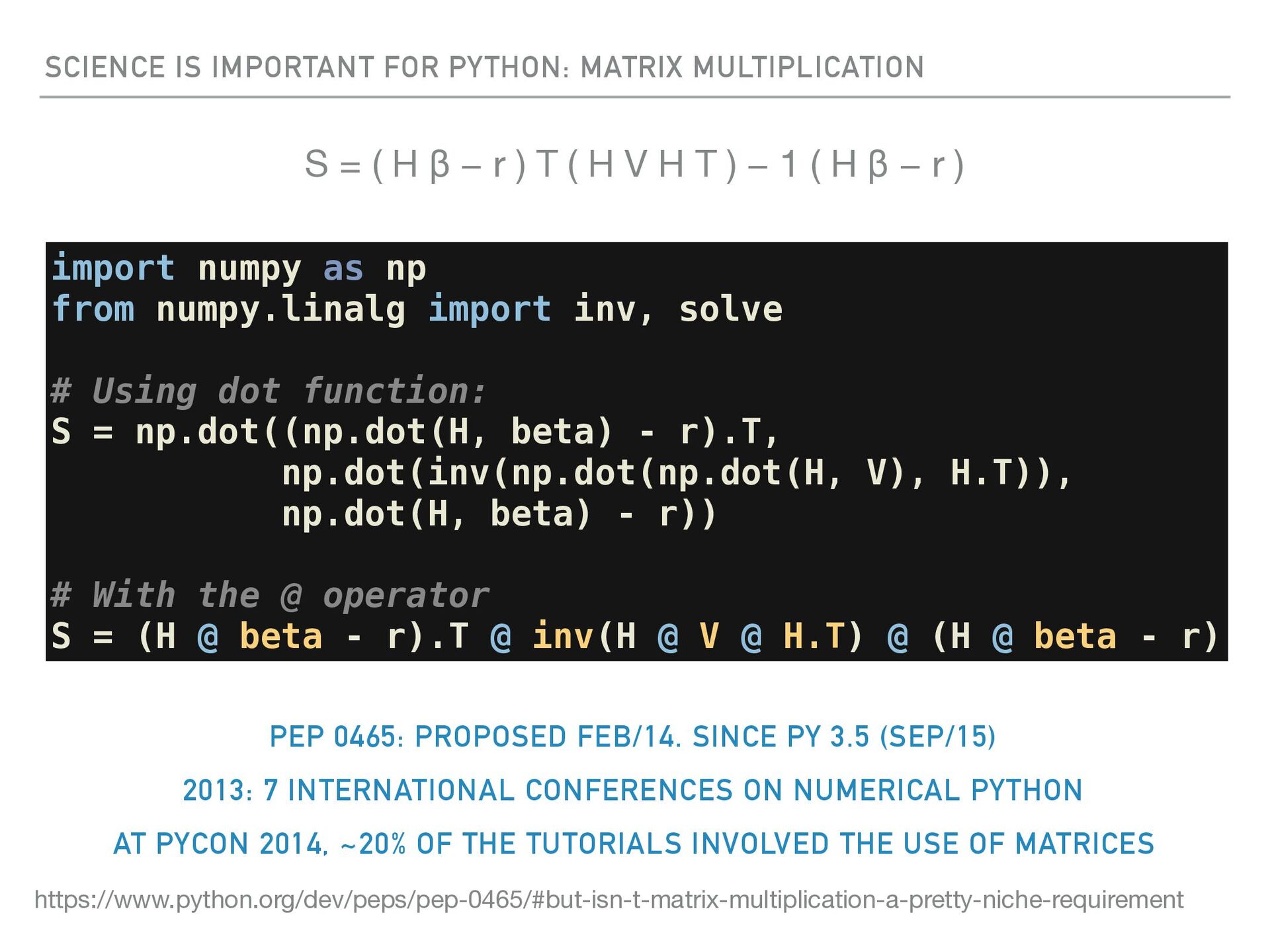
as np from numpy.linalg import inv, solve # Using dot function: S = np.dot((np.dot(H, beta) - r).T, np.dot(inv(np.dot(np.dot(H, V), H.T)), np.dot(H, beta) - r)) # With the @ operator S = (H @ beta - r).T @ inv(H @ V @ H.T) @ (H @ beta - r) S = ( H β − r ) T ( H V H T ) − 1 ( H β − r ) PEP 0465: PROPOSED FEB/14. SINCE PY 3.5 (SEP/15) 2013: 7 INTERNATIONAL CONFERENCES ON NUMERICAL PYTHON AT PYCON 2014, ~20% OF THE TUTORIALS INVOLVED THE USE OF MATRICES
{kind=link}
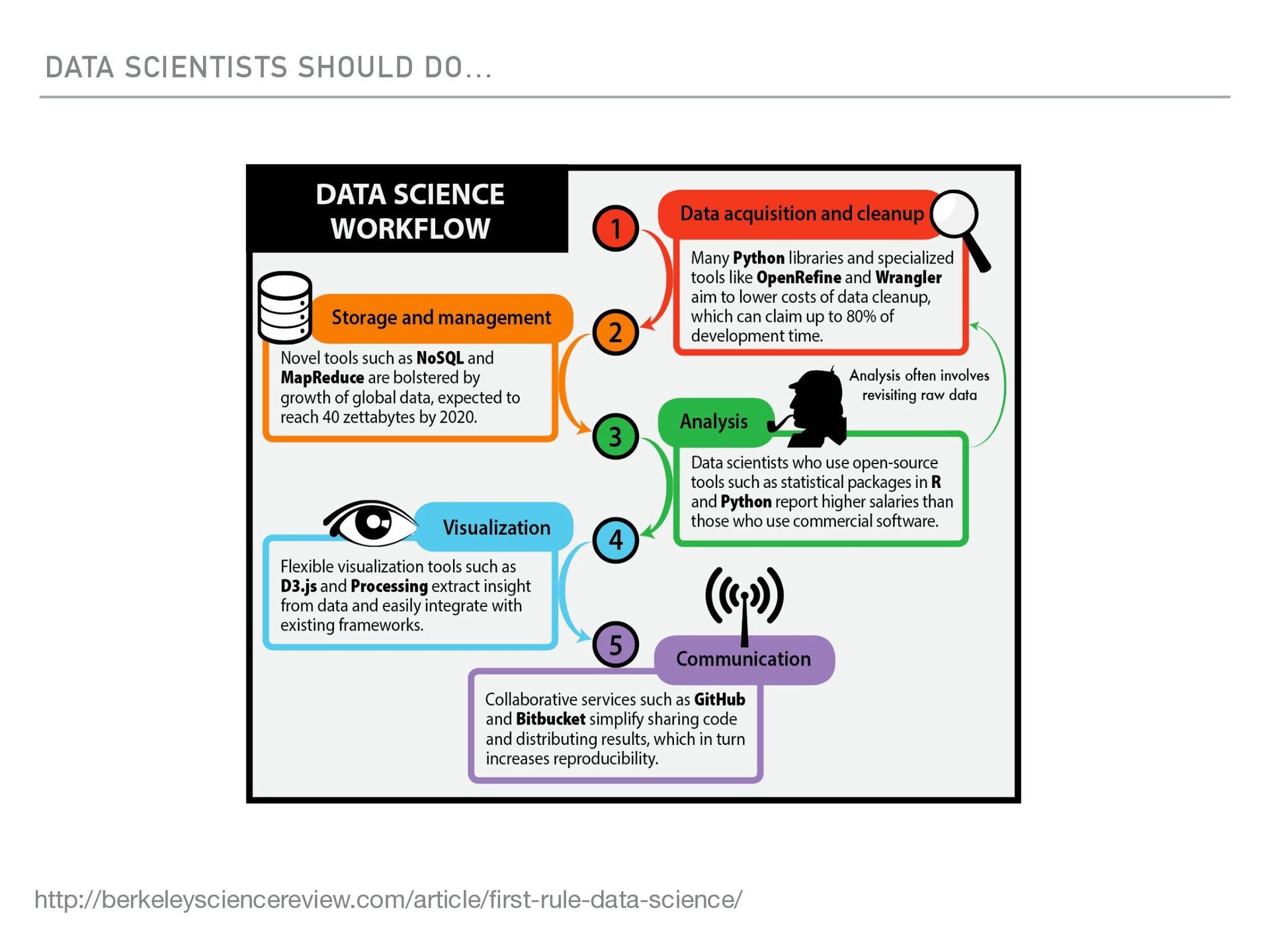{kind=link}
{kind=link}
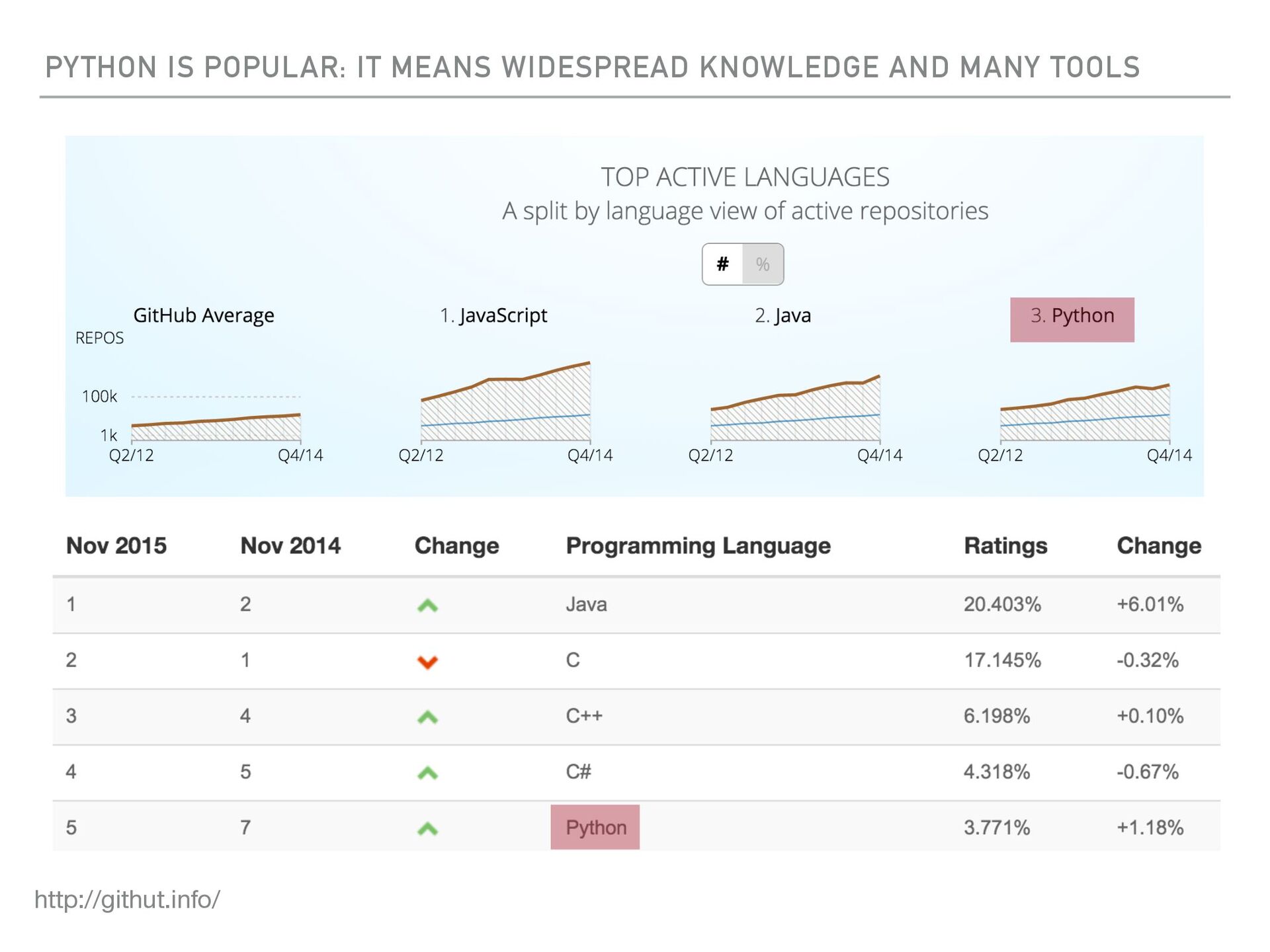{kind=link}
{kind=link}
{kind=link}
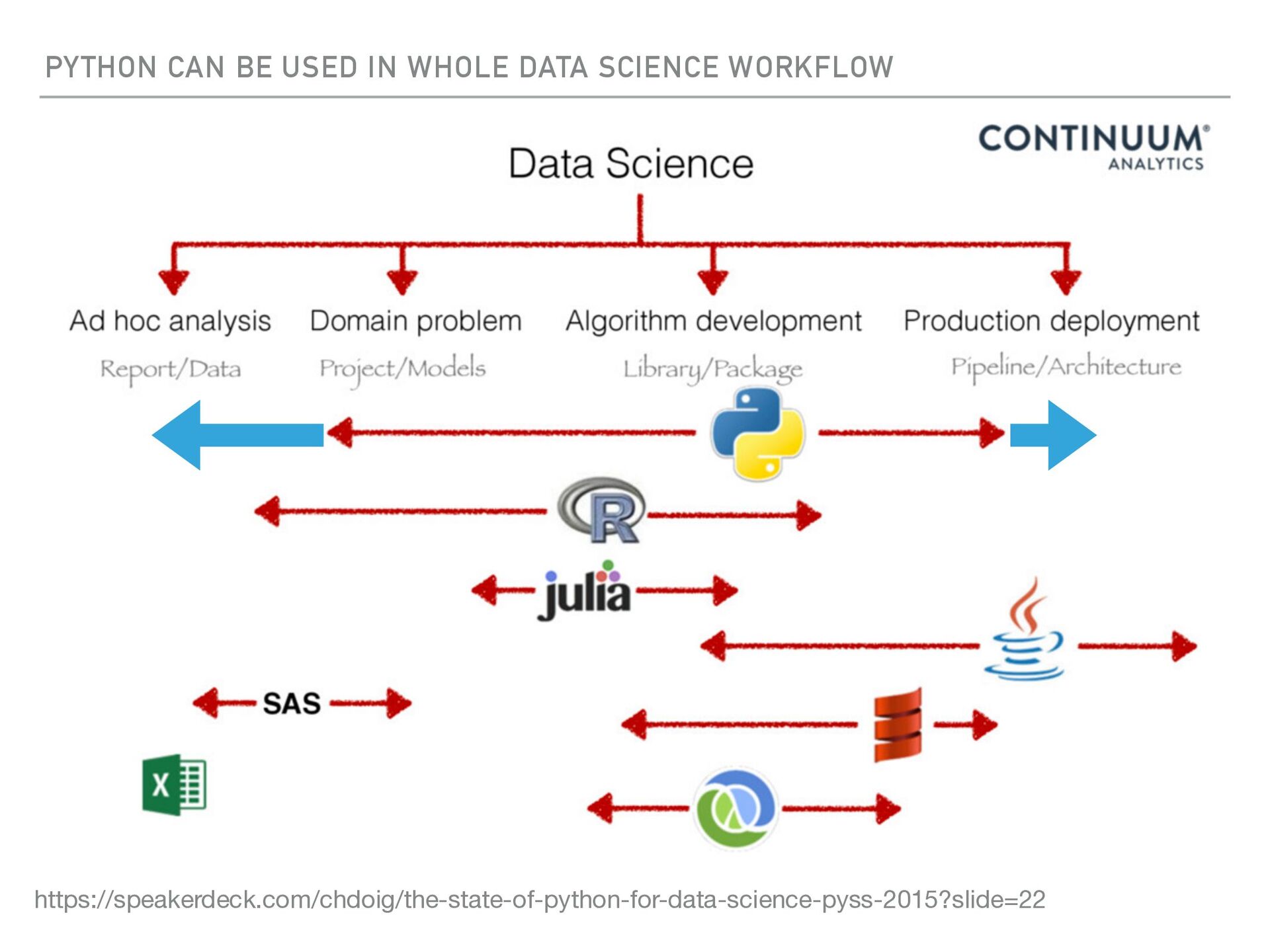{kind=link}
{kind=link}
{kind=link}
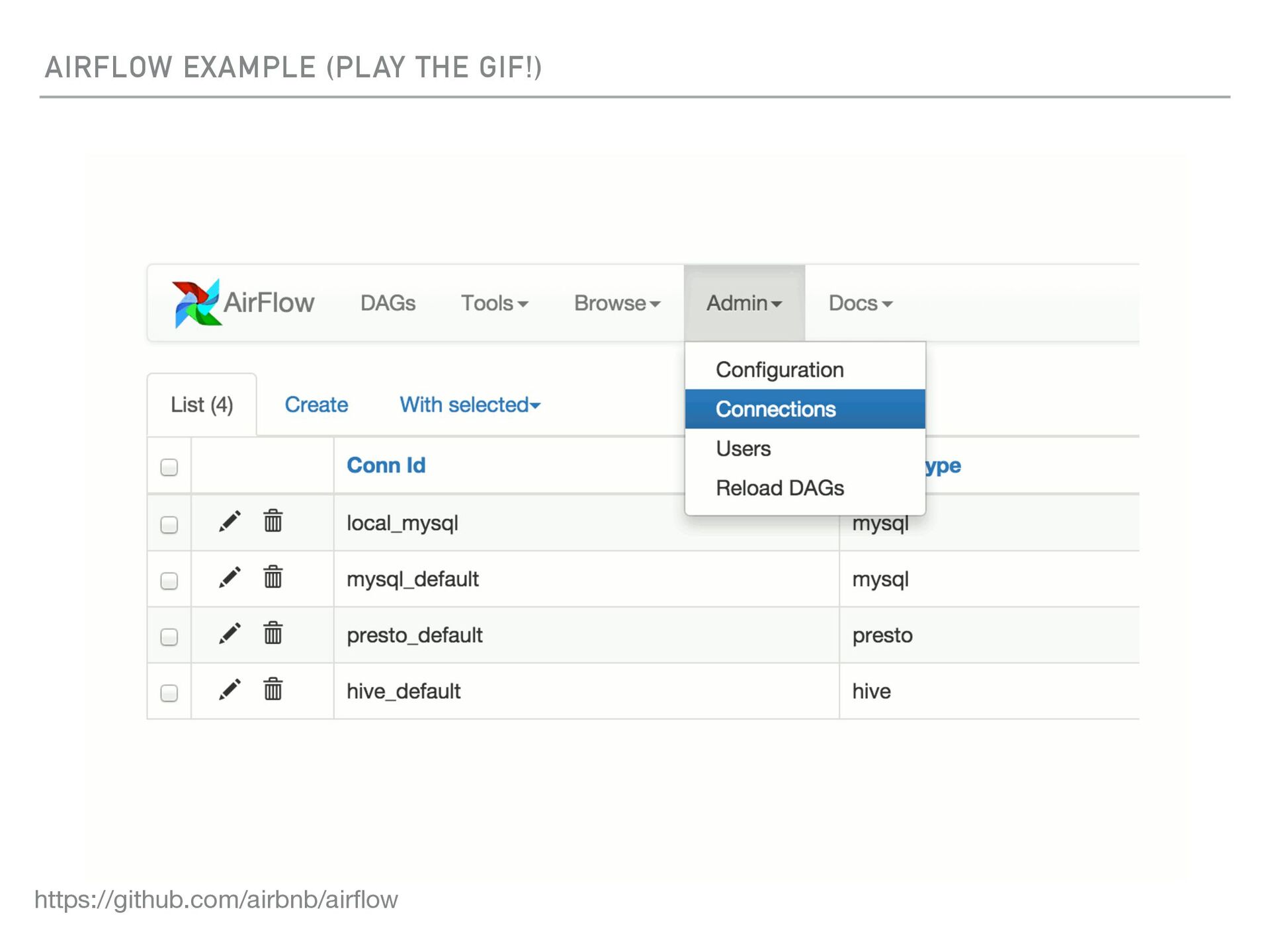{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}