Share
2023年5月27日〜28日開催の第89回日本考古学協会のセッション6「デジタル化時代の遺跡・埋蔵文化財包蔵地・遺跡地図を考える」の発表資料です。
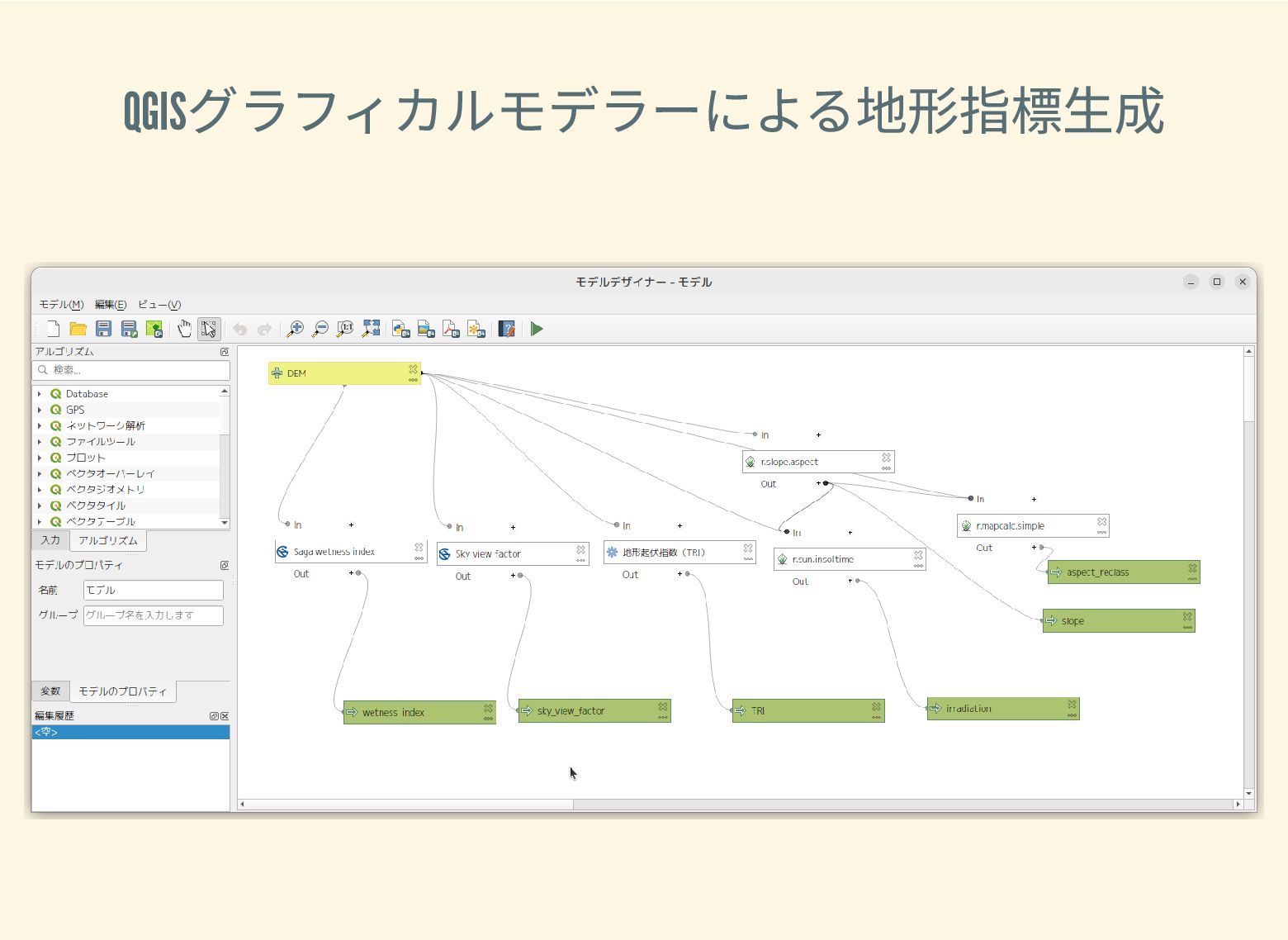
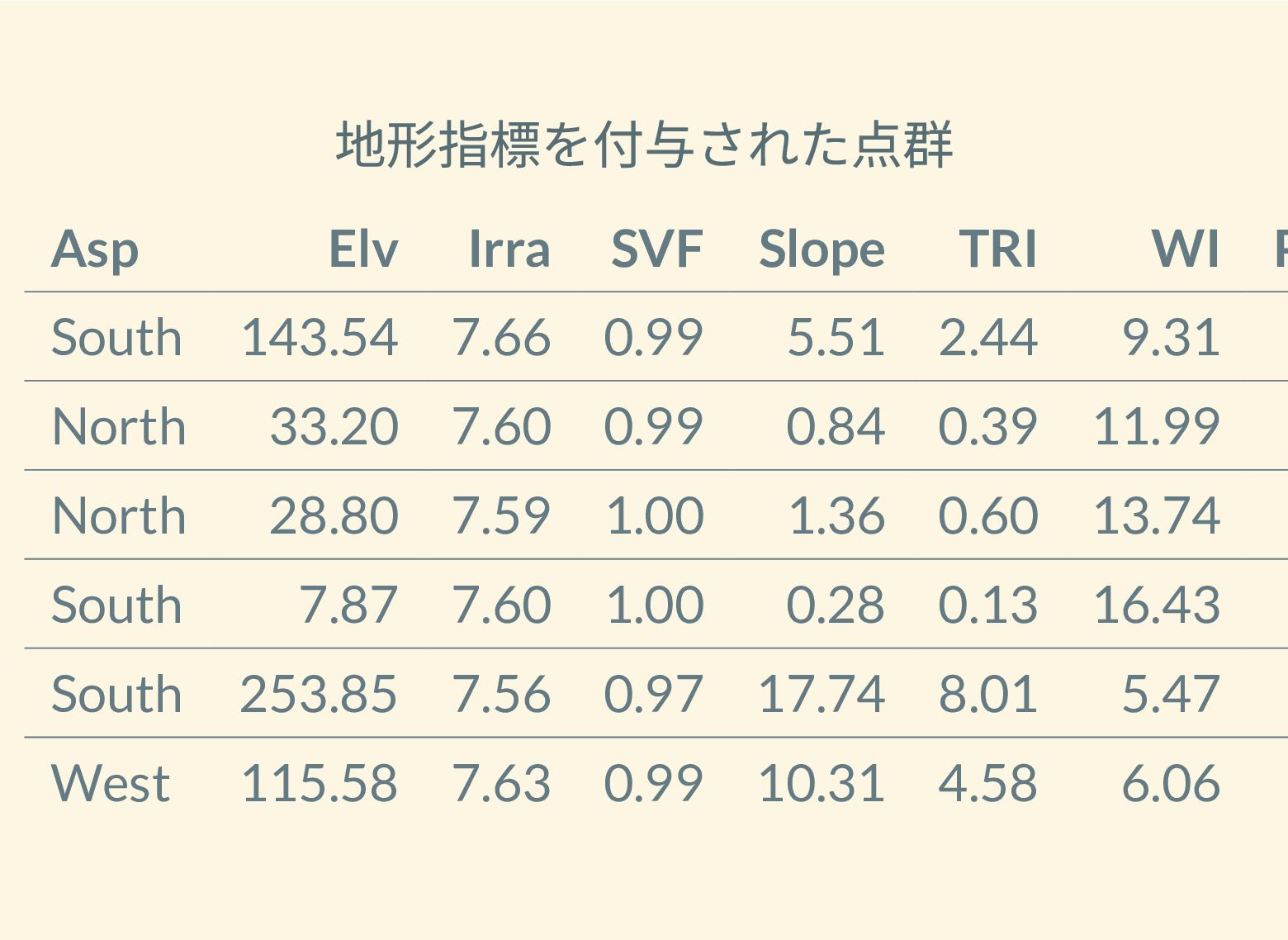
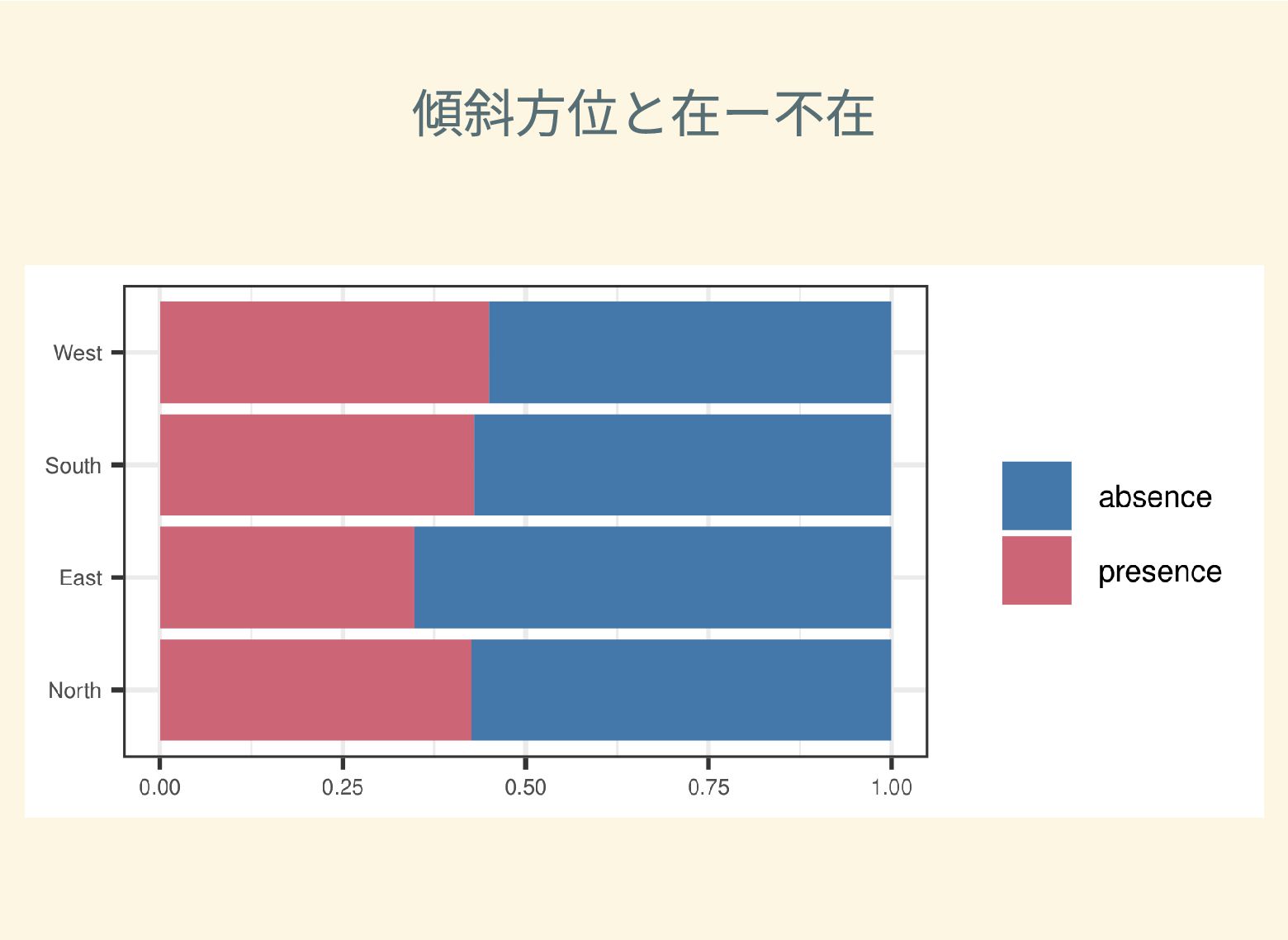
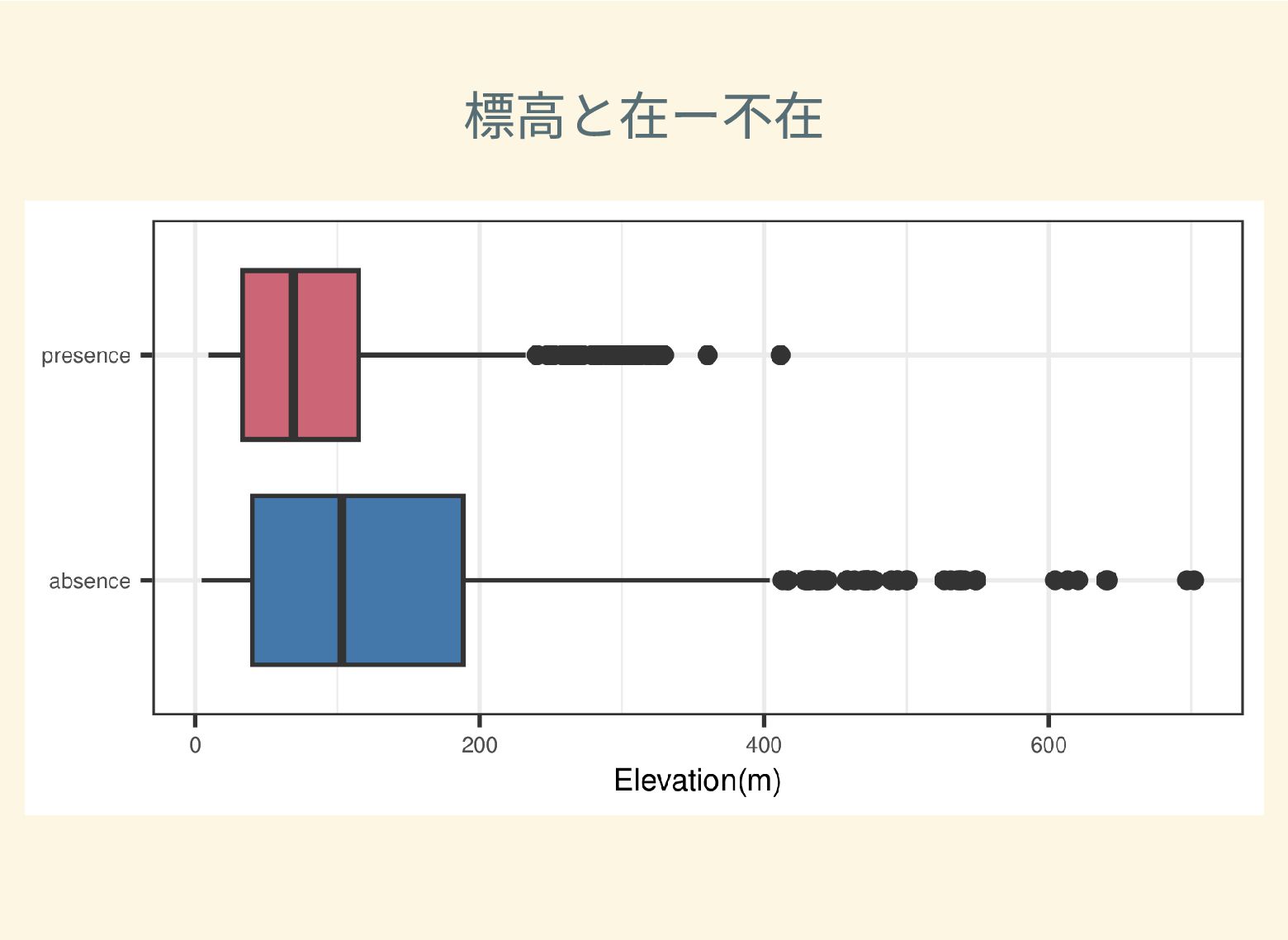
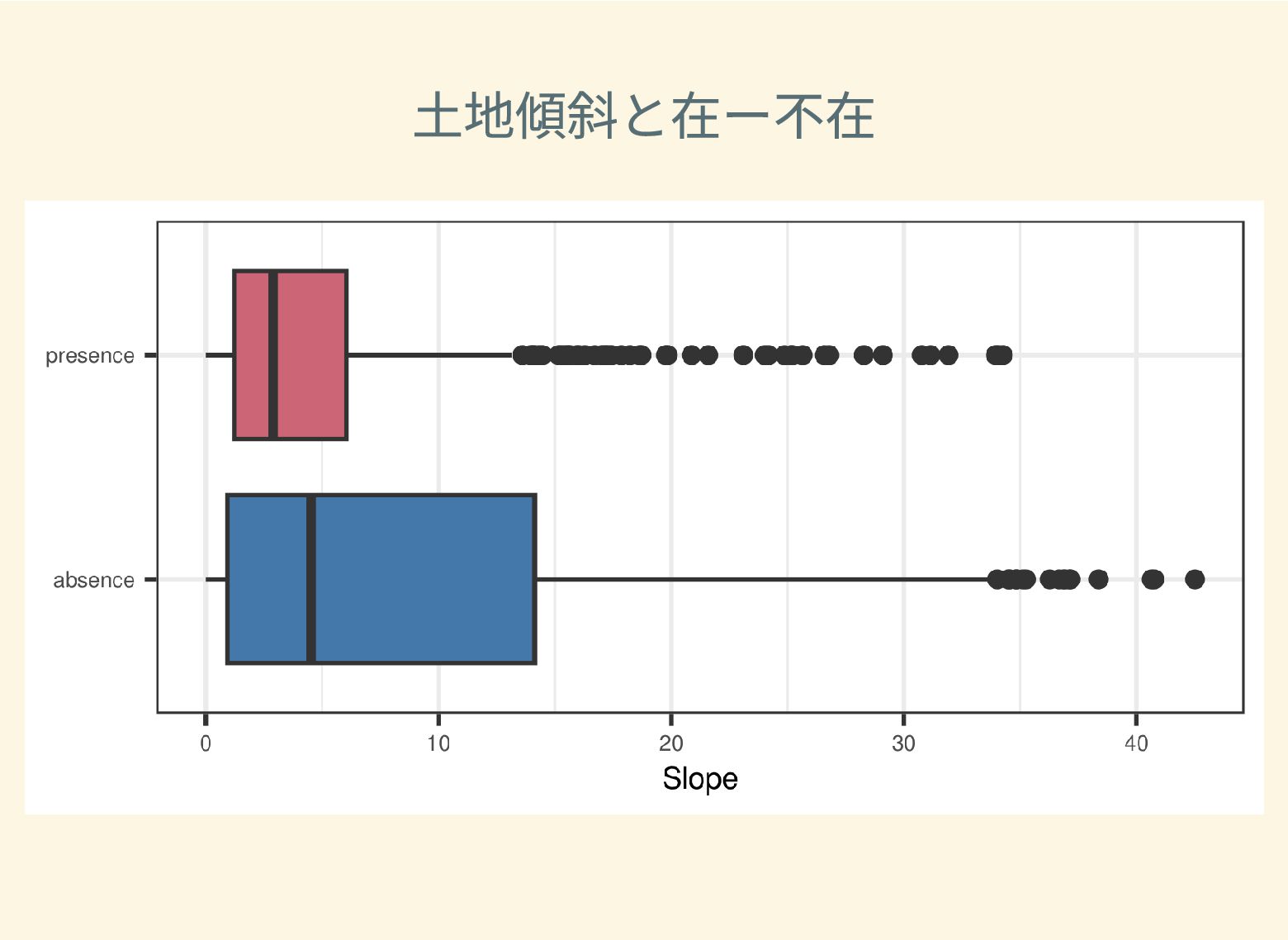
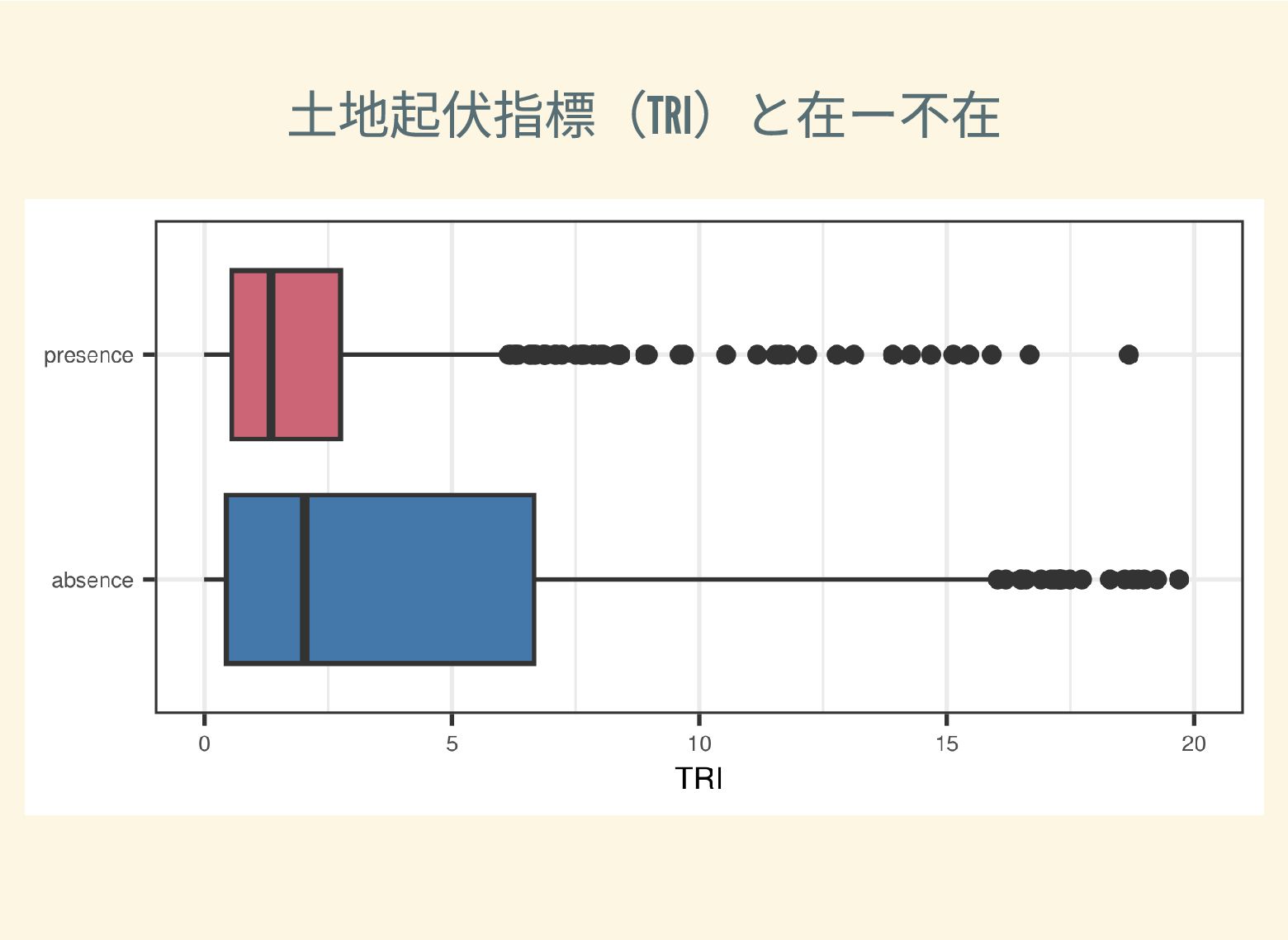
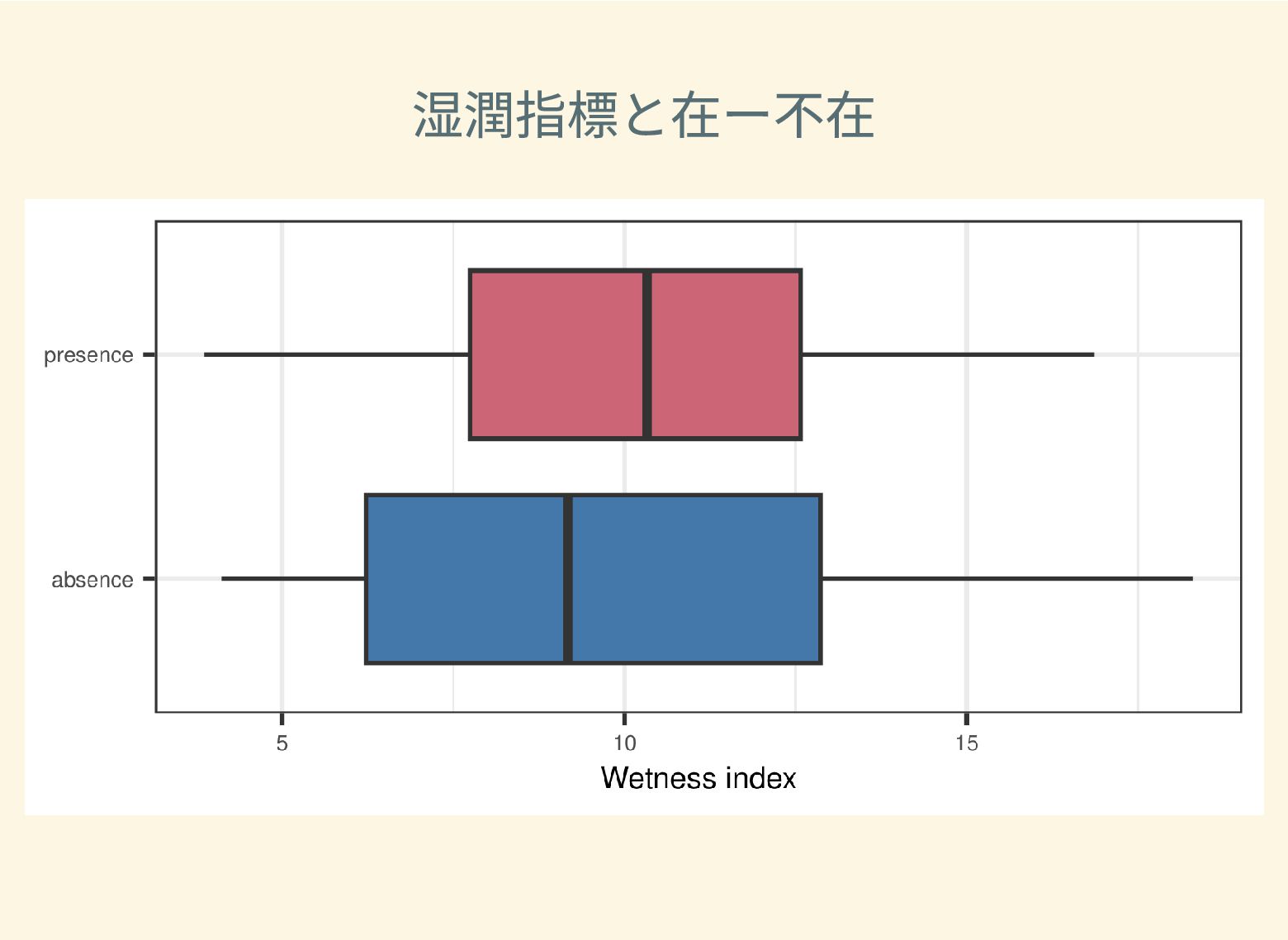
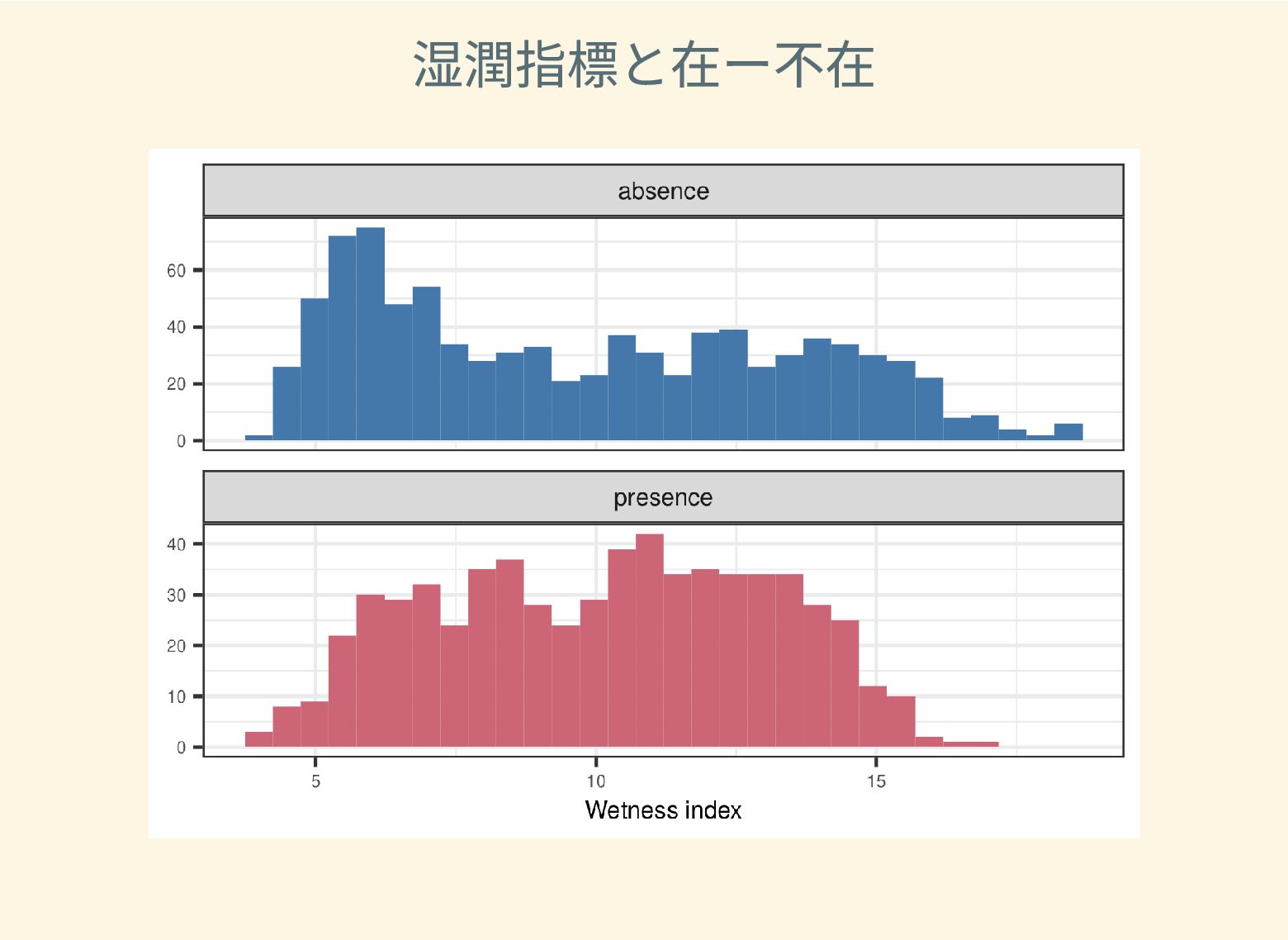
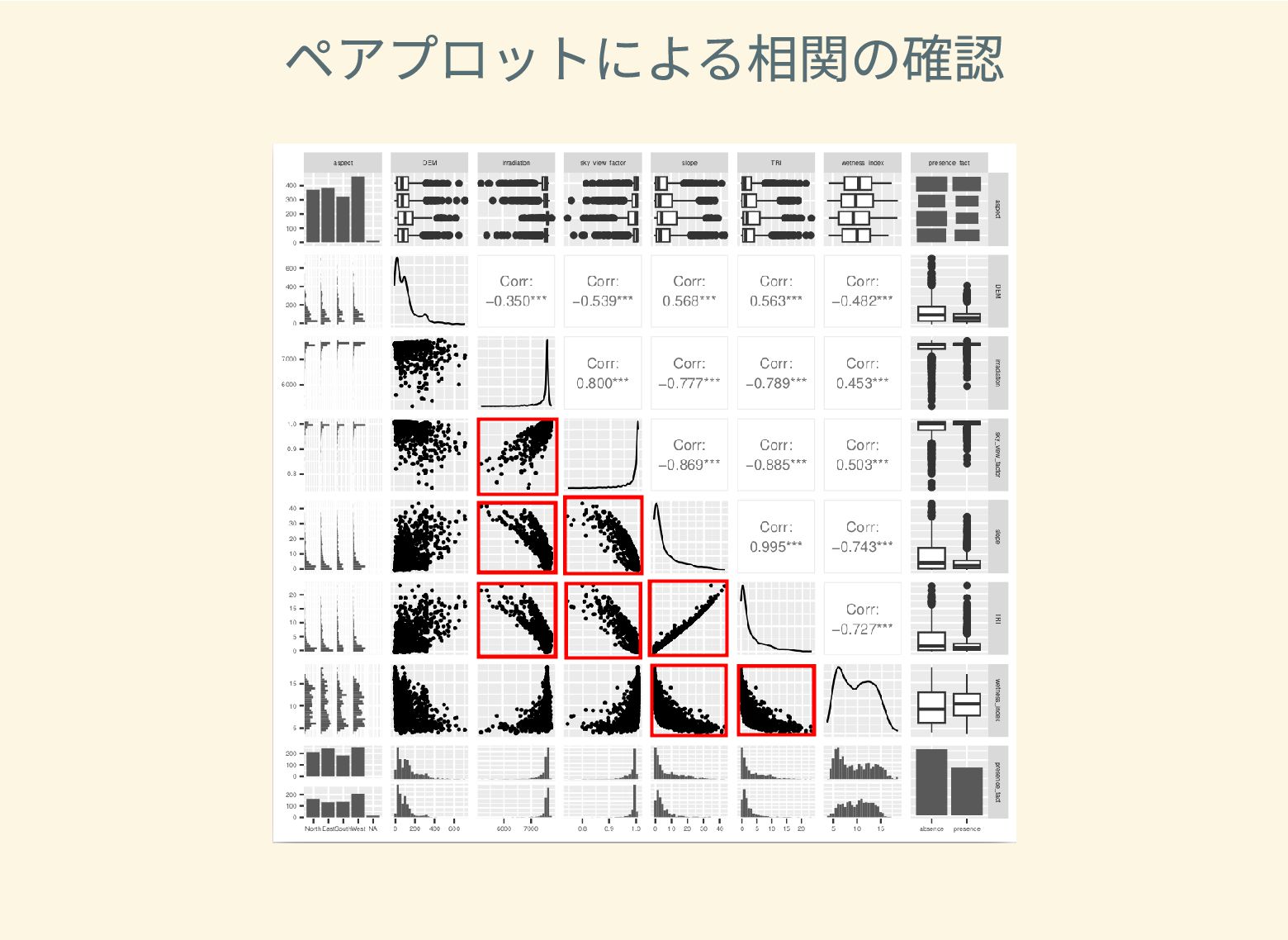
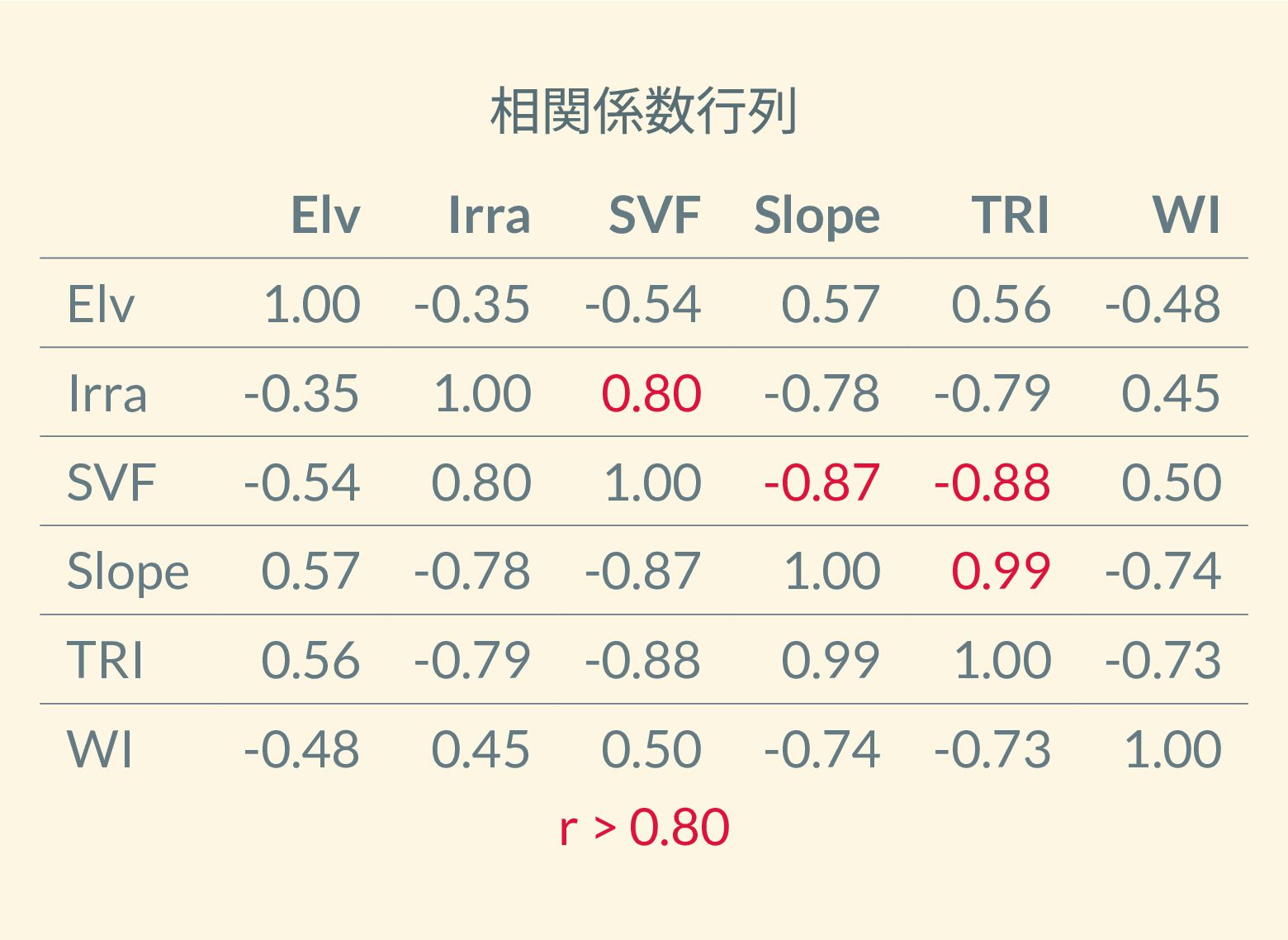
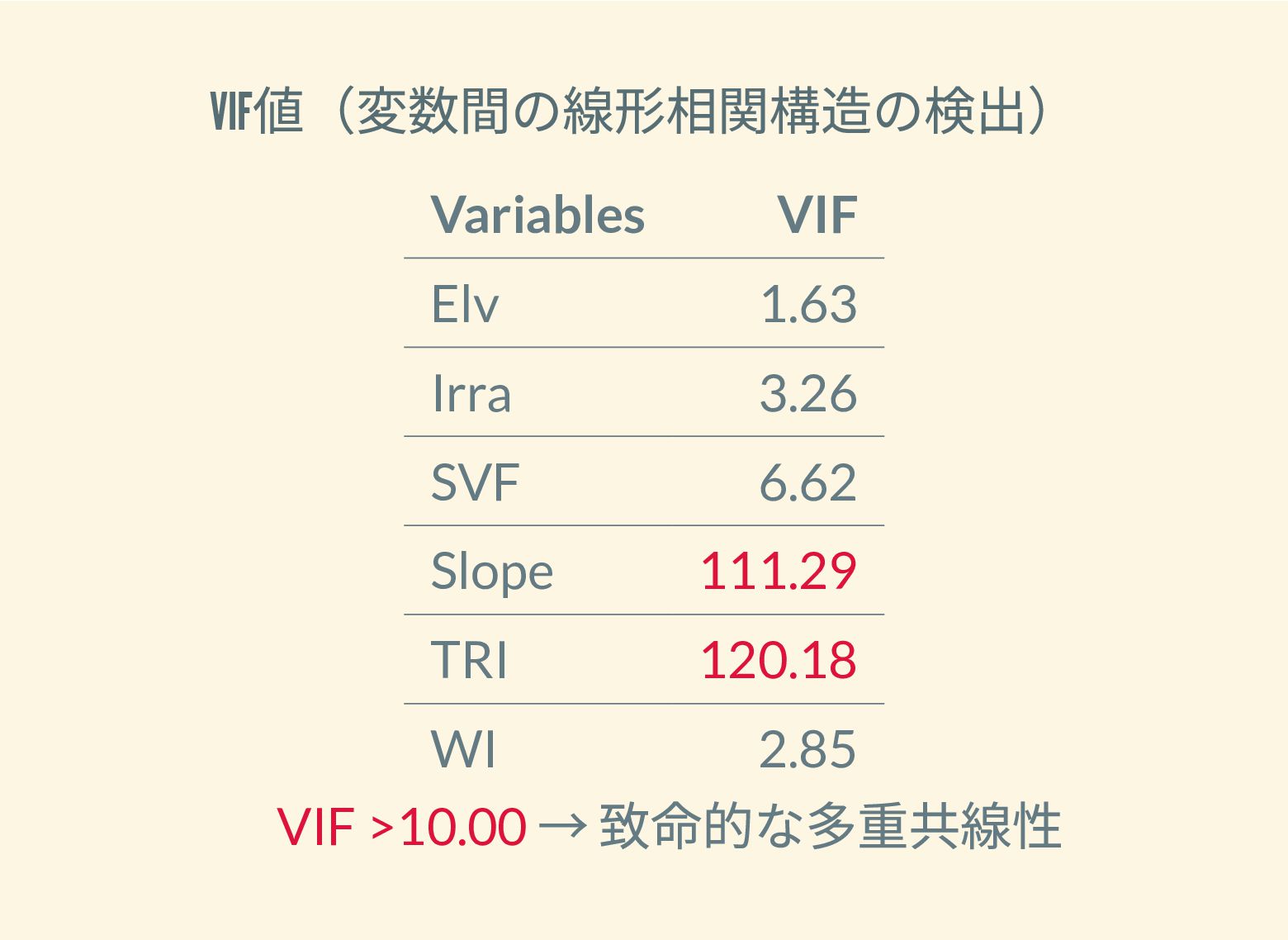
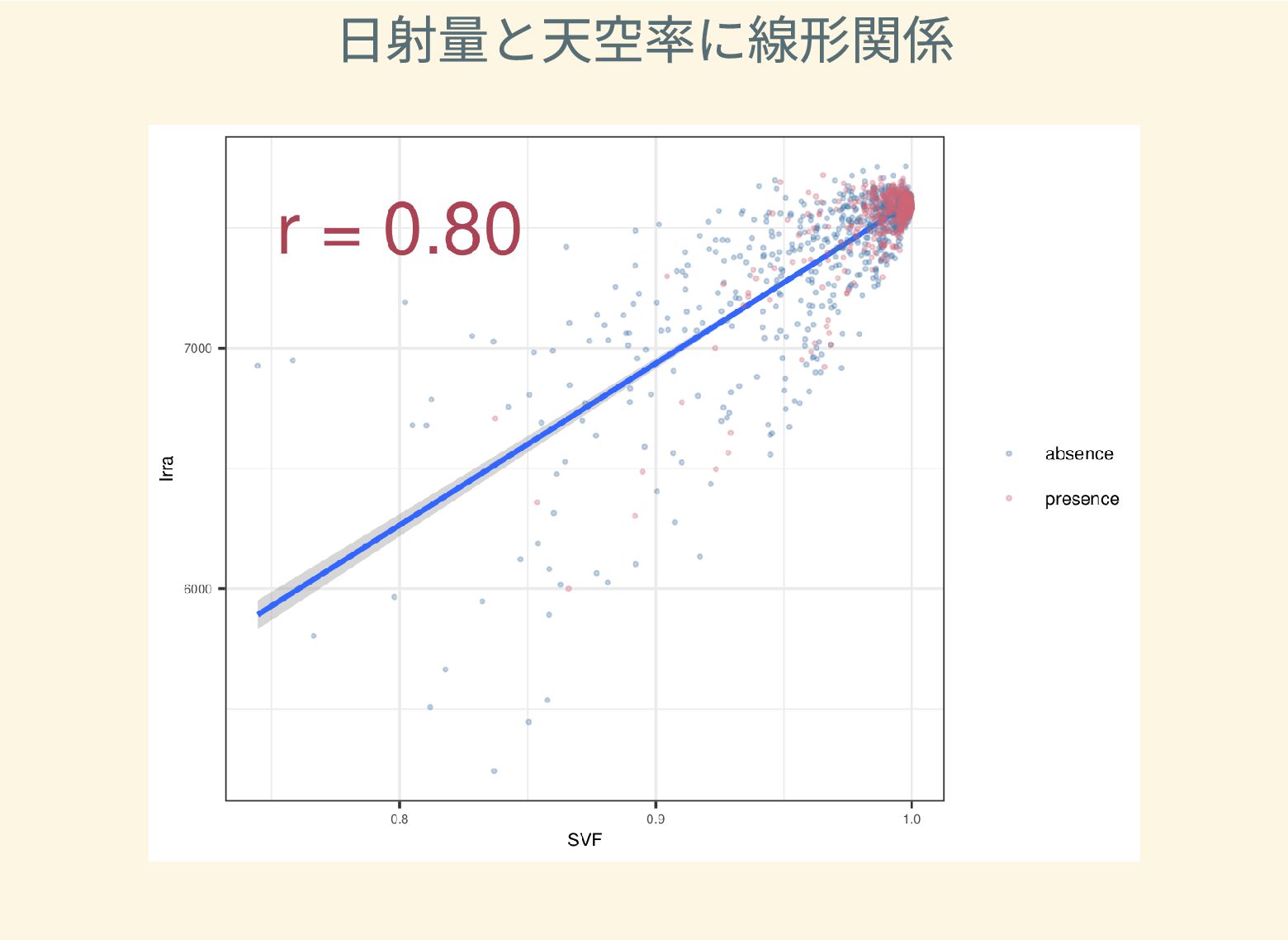
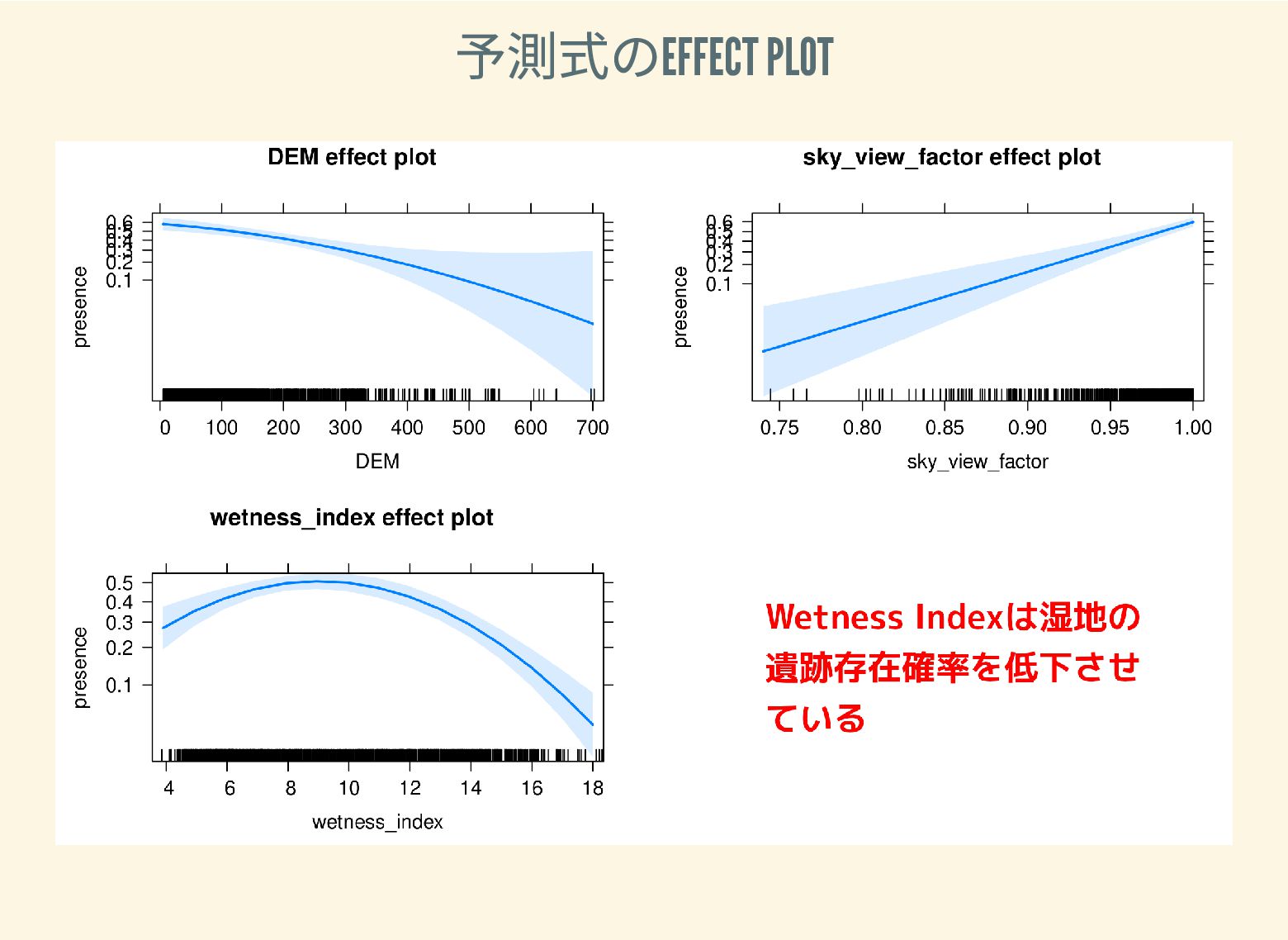
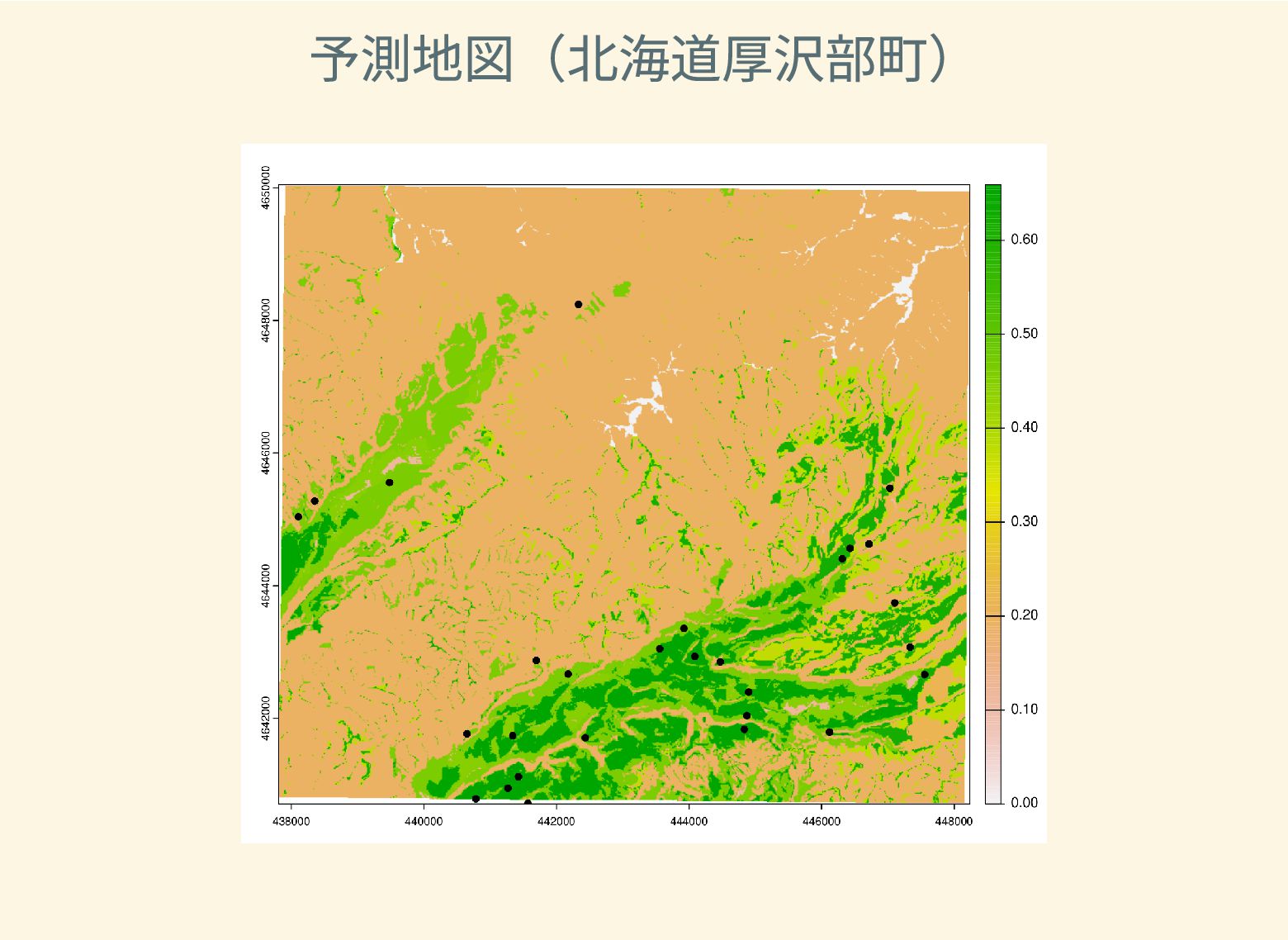
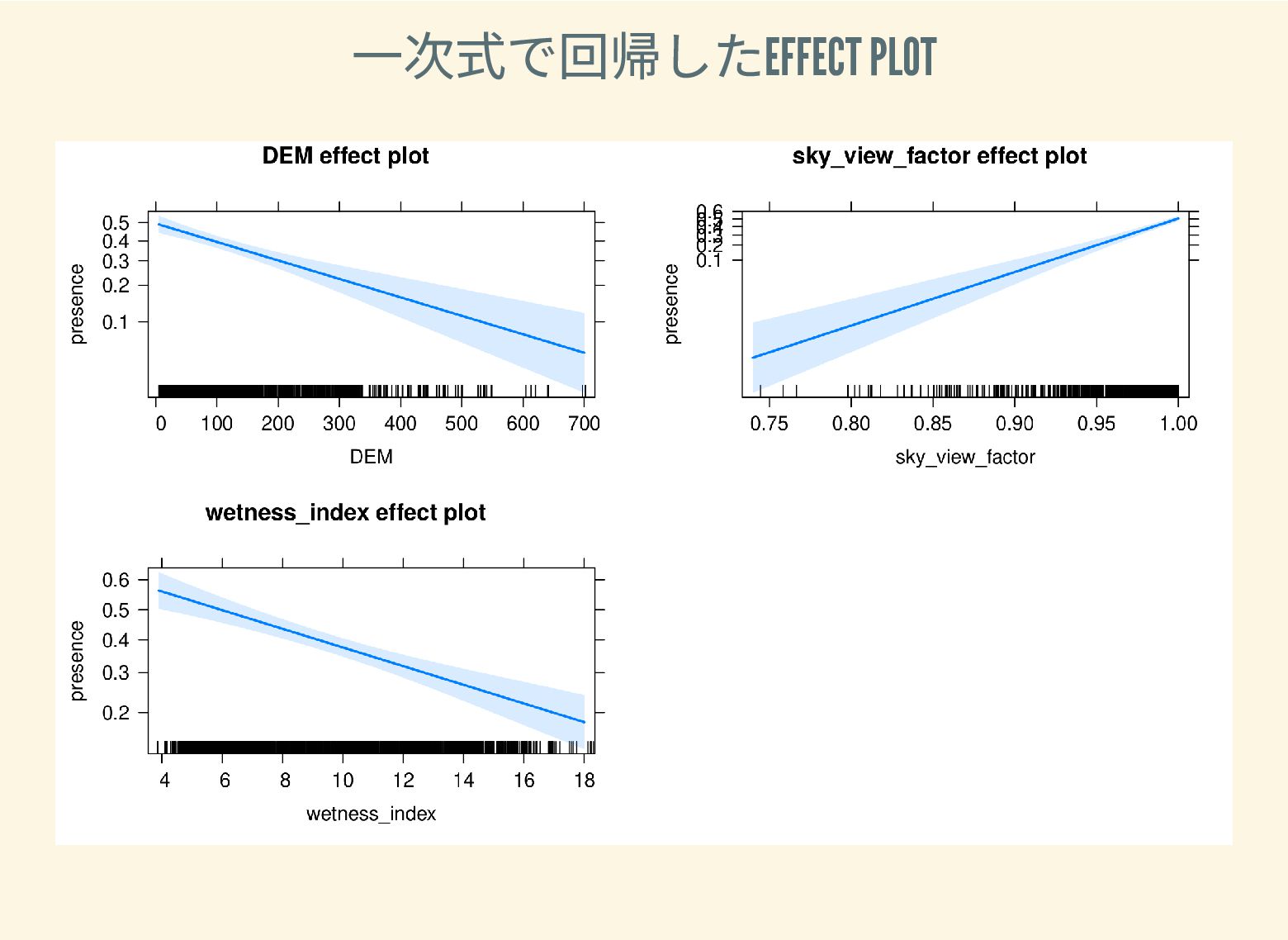
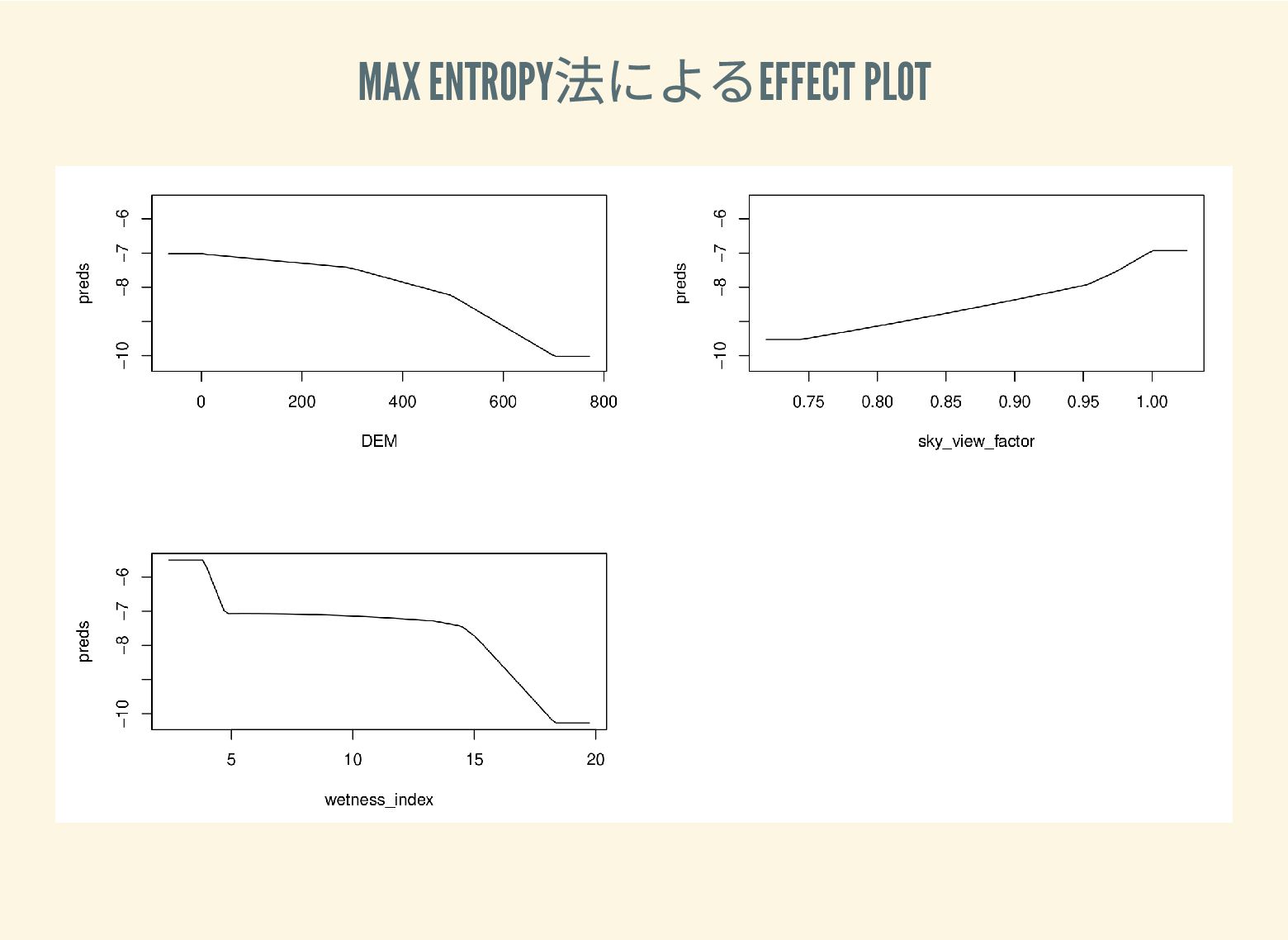
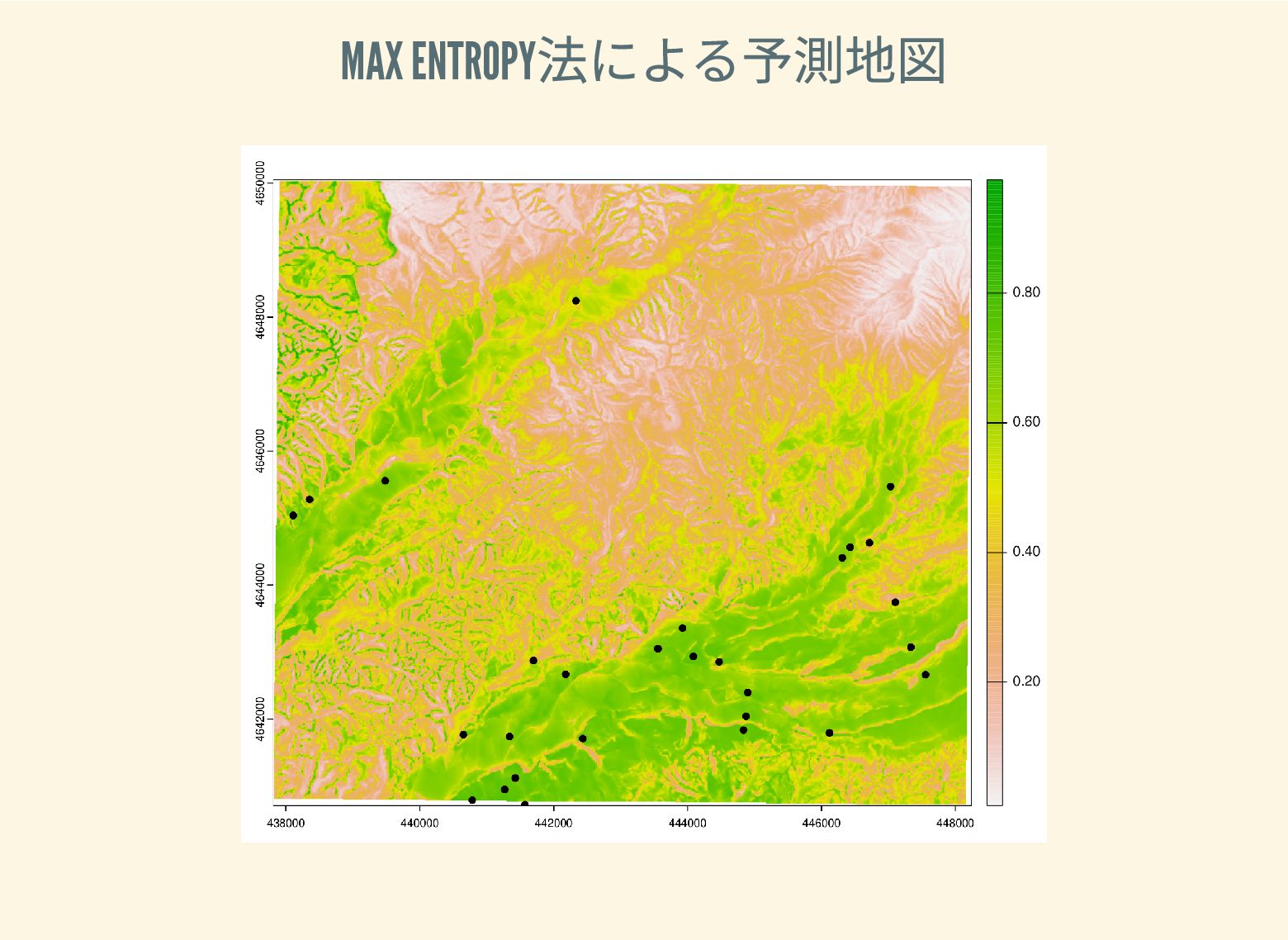
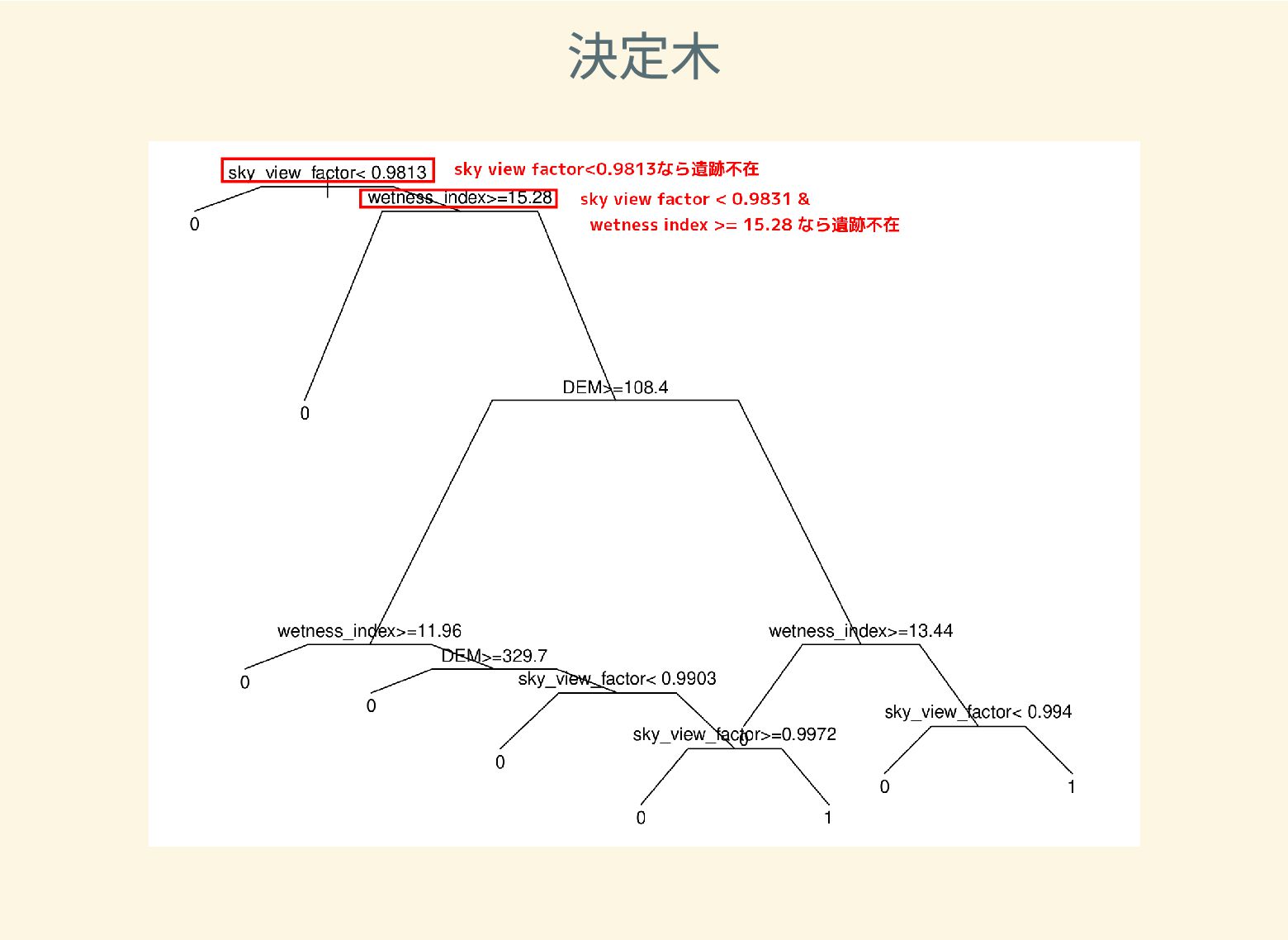
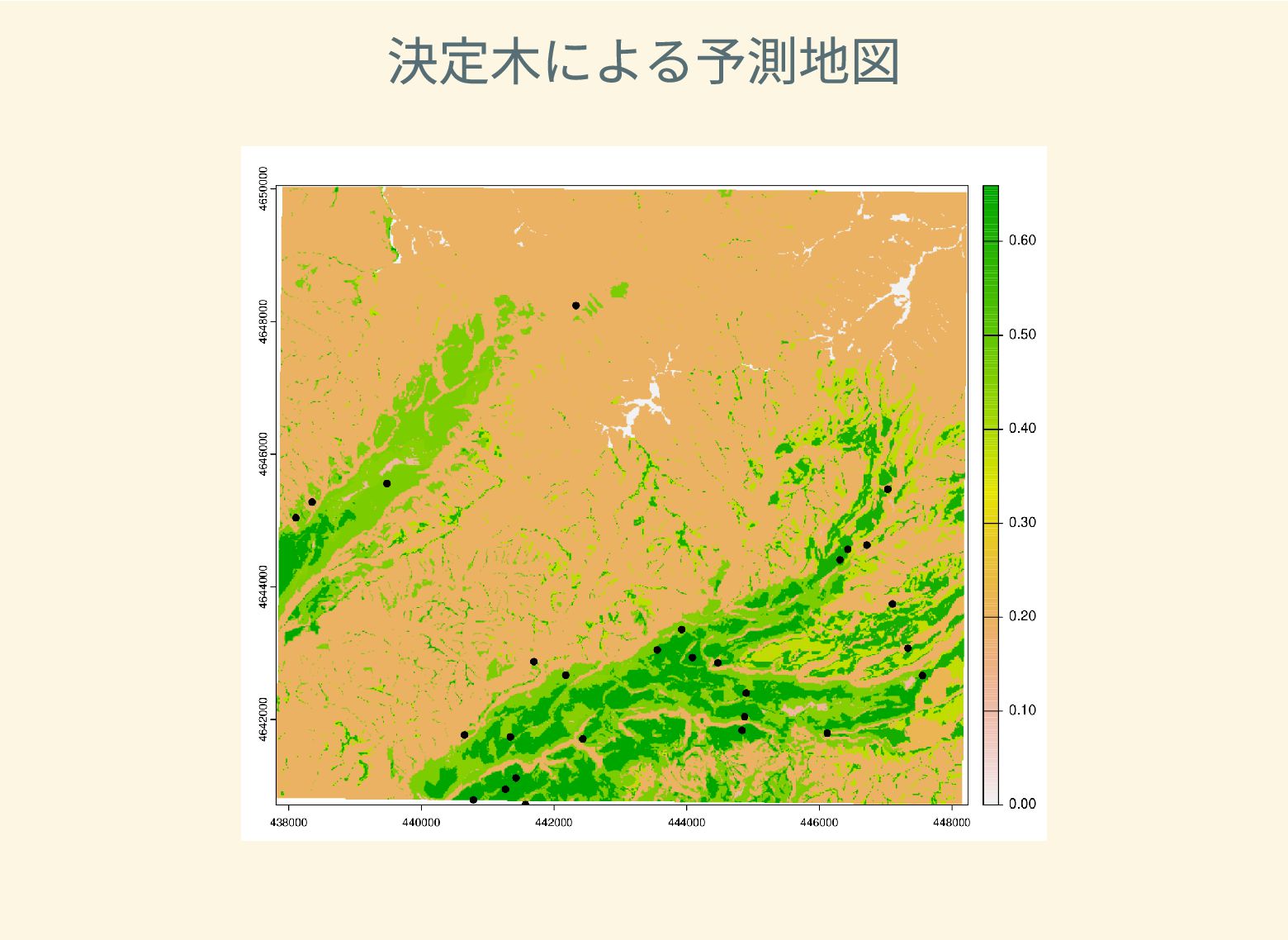
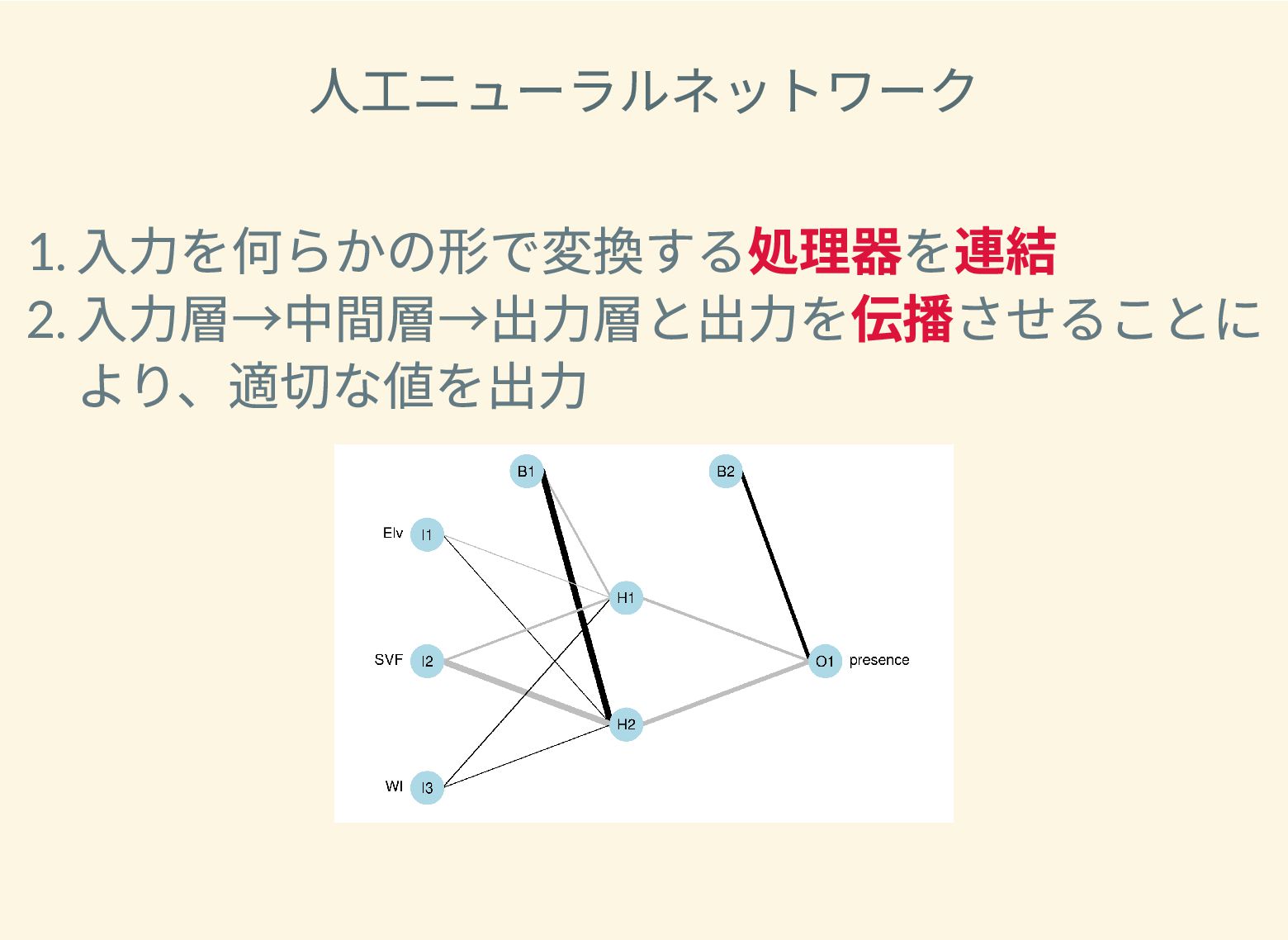
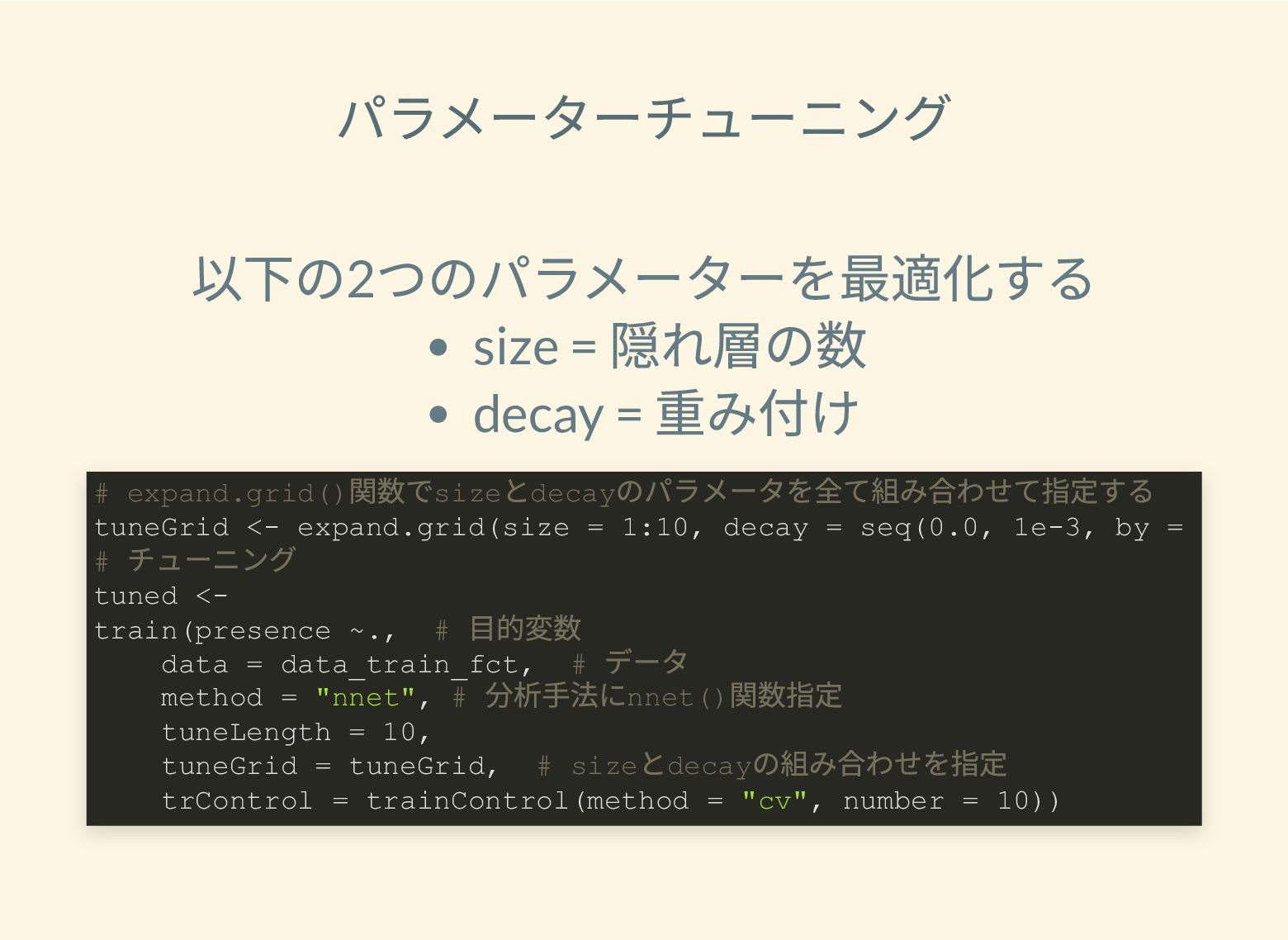
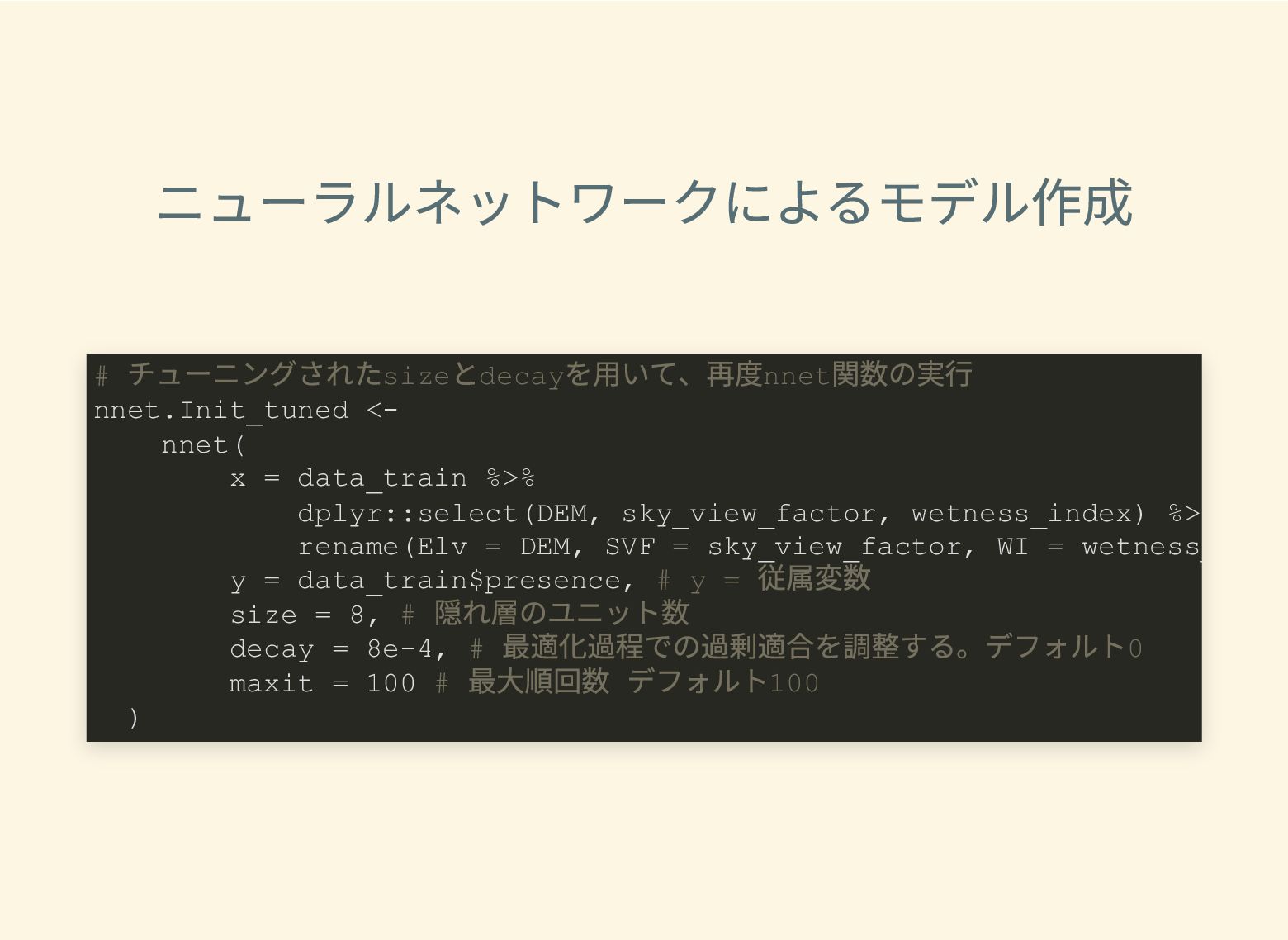
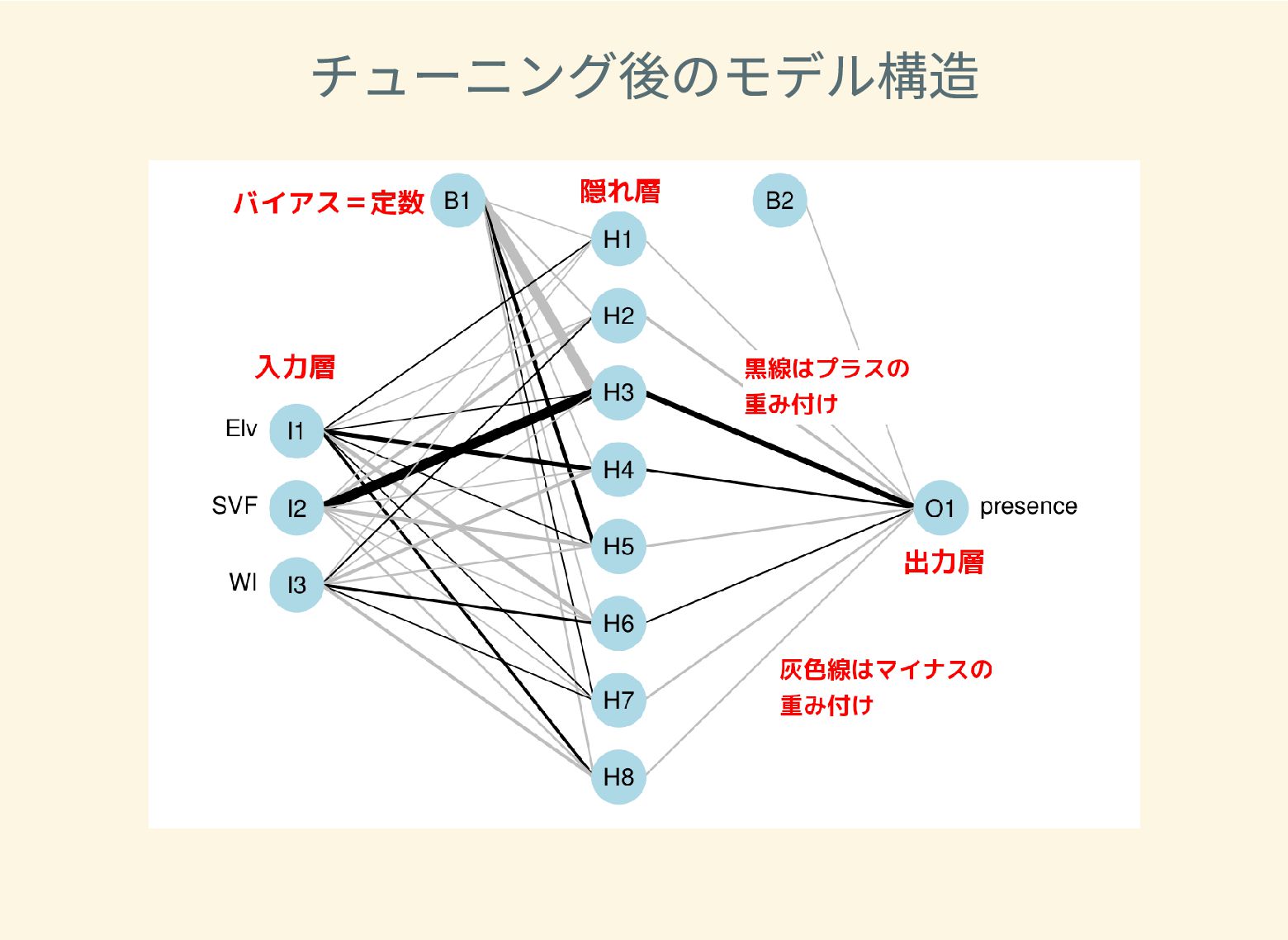
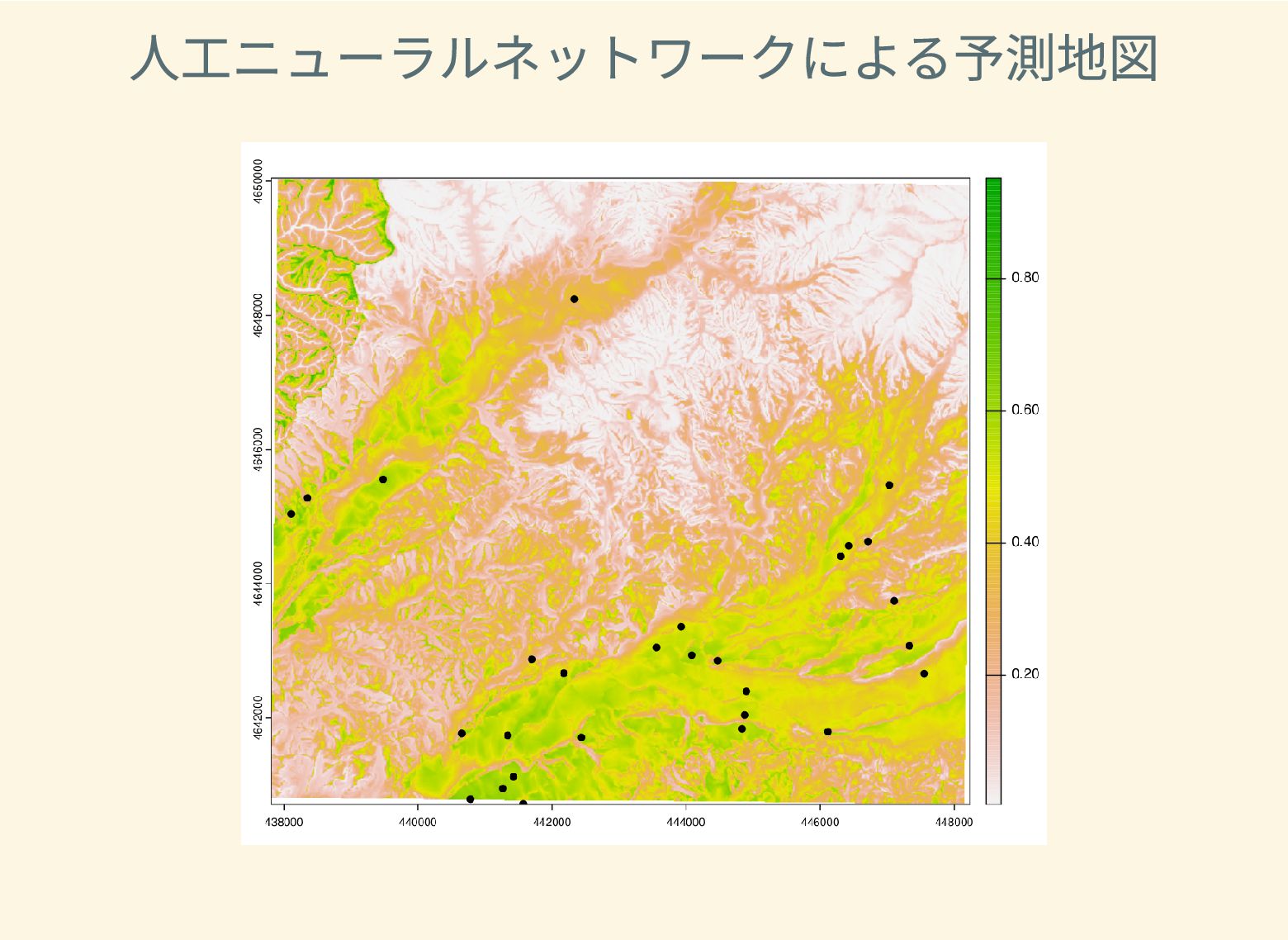
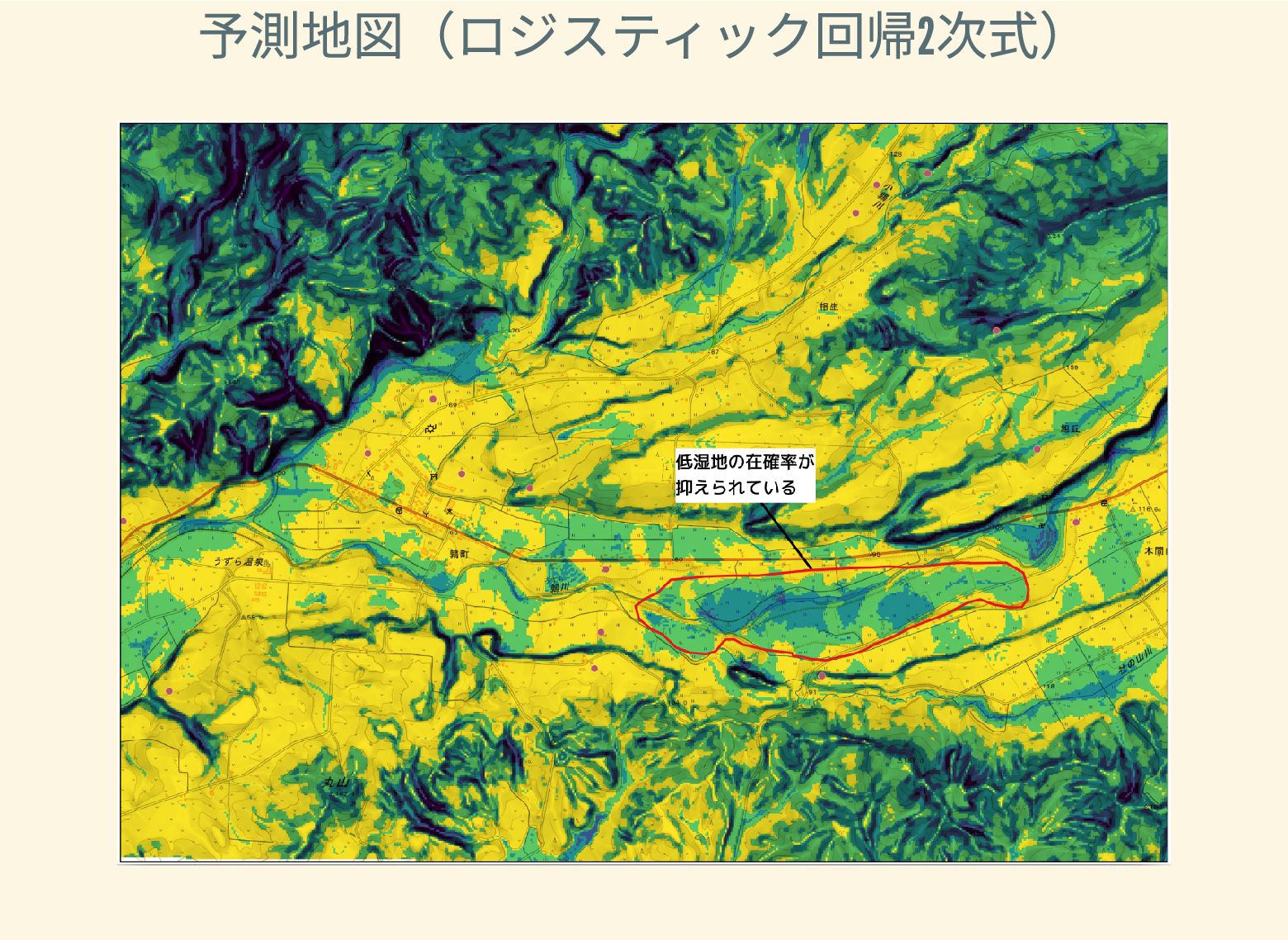
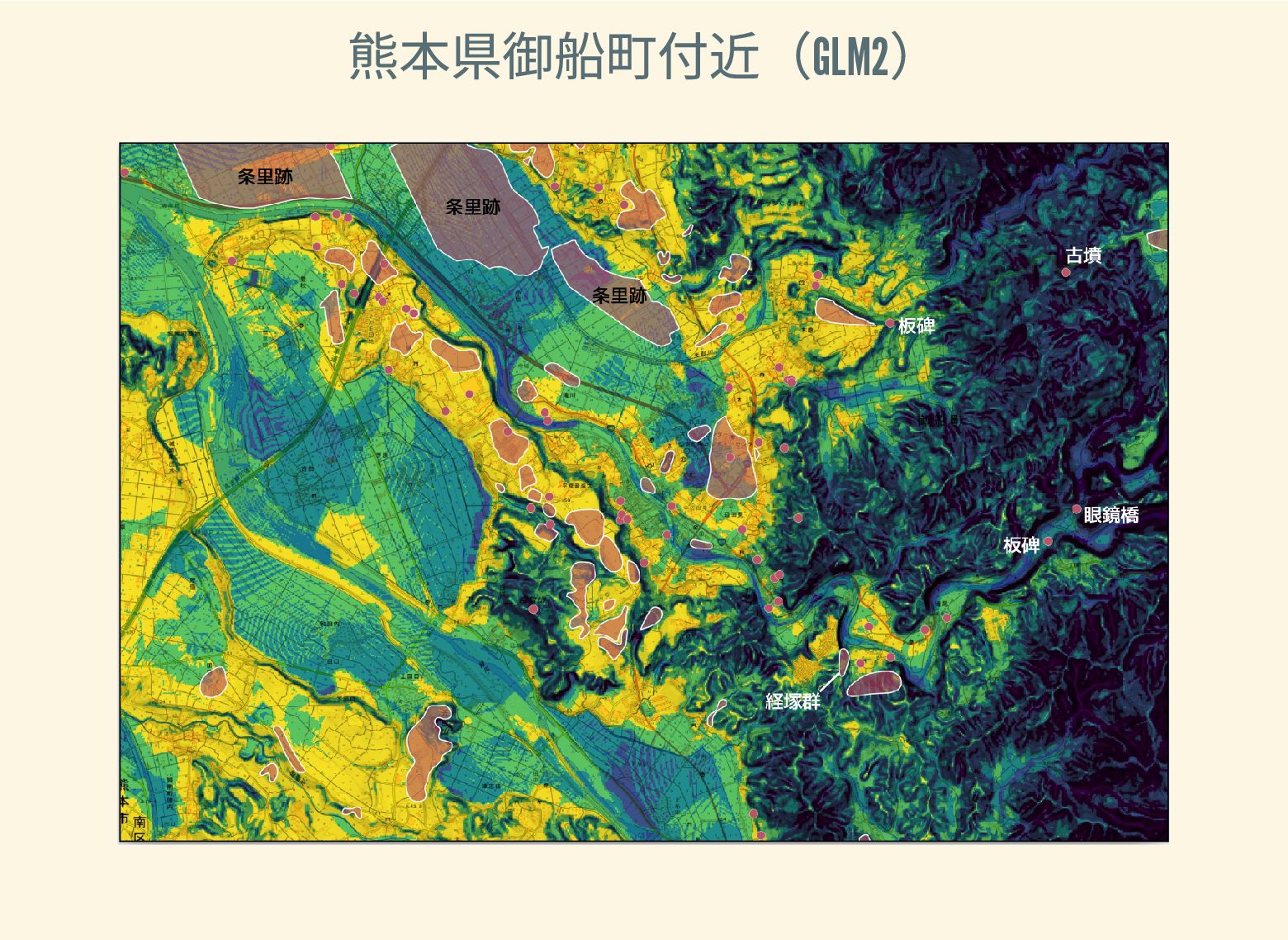
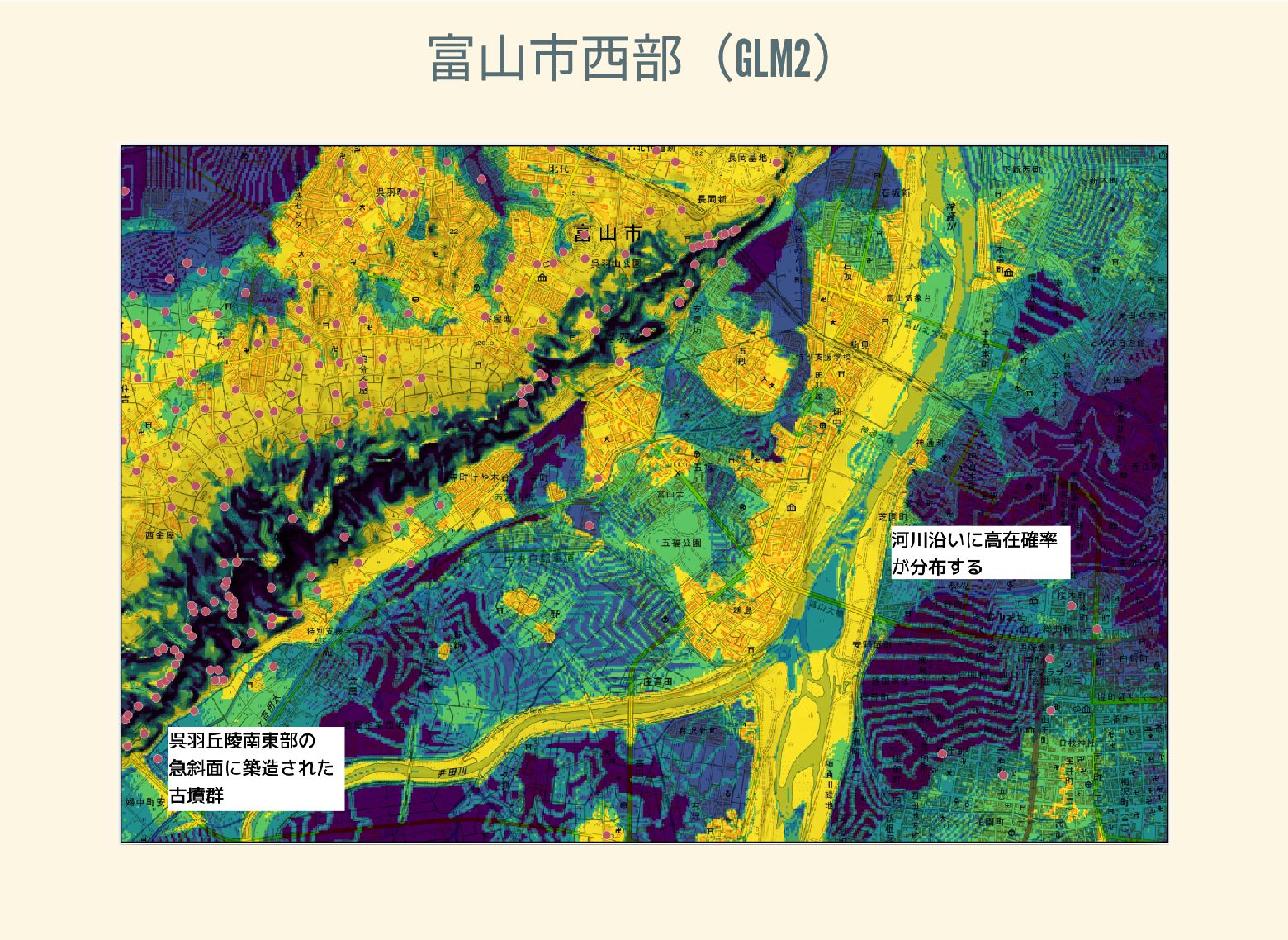
遺跡は「ある・ない」の二値的な性質ではなく、既知の遺跡や地形等によって規定される確率的な性質であることが前提となっている。遺跡立地に影響する環境要因を説明変数とし、遺跡の有無を目的変数とすることで、「隣接地」概念を確率的存在として可視化する手法について検討した。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}