Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Hybrid Reward Architecture for Reinforcement Le...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Yuko Ishizaki
November 08, 2018
160
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Hybrid Reward Architecture for Reinforcement Learning
Yuko Ishizaki
November 08, 2018
More Decks by Yuko Ishizaki
See All by Yuko Ishizaki
The Web Conference 2020 Report -多目的最適化における確率的ラベル集約-
ishizaki_yuko
1
1.4k
雲コンペで反省したノイズ除去
ishizaki_yuko
1
430
Meta Kaggleを覗いてみた
ishizaki_yuko
3
3.1k
Modeling Relational Data with Graph Convolutional Networks
ishizaki_yuko
0
230
Featured
See All Featured
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
Building the Perfect Custom Keyboard
takai
2
810
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
ラッコキーワード サービス紹介資料
rakko
1
3.9M
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
63
55k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
210
A Tale of Four Properties
chriscoyier
163
24k
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
880
Utilizing Notion as your number one productivity tool
mfonobong
4
390
GitHub's CSS Performance
jonrohan
1033
470k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Transcript
機械学習 論文輪読会 Hybrid Reward Architecture for Reinforcement Learning Ishizaki Yuko
2018/1/8
Hybrid Reward Architecture for Reinforcement Learning NIPS 2017 Accepted Paper
http://papers.nips.cc/paper/7123-hybrid-reward-architecture-for- reinforcement-learning.pdf パックマンを攻略した論文 2017年6月にarXive.orgに掲載 MicrosoftのチームMaluuba ミズ.パックマンでフルスコアの99万9990点を記録した
Topic 1. 強化学習とは 2. DQNとは 3. HRAとは 4. 実験1 フルーツゲーム
5. 実験2 パックマン
強化学習 エージェント:プレーヤー 状態:エージェントの置かれている状態 = { 1, 2, 3, … }
行動:エージェントが行う行動 = { 1, 2, 3, … } 報酬:環境から得られる報酬 = , , +1 状態遷移確率:ある状態 である行動 を起こて、ある状態+1 になる確率 +1 | , 方針:エージェントがとある状態でどんな行動を行うか : × → [0, 1]
強化学習の目的 各ステップごとに状態と行動と報酬を観測し、 累積報酬 を最大にする方針∗を見つけること : = =0 ∞ +
∈ [0,1]は時間割引率 1秒後の報酬+100の方が10秒後の報酬+100よりも高い報酬とみなす
マルコフ決定過程 , , , , モデル化したものをマルコフ決定過程(MDP)という 次の状態(の確率)が現在の状態のみで決まる : × →
[0, 1] → 過去は関係ない → 状態は全て把握できている
行動価値関数 ある状態である行動を行うことの価値を表す関数 → 価値とは報酬をもとにした、仮想的な値 , = | = , =
, という状態でという行動をとった場合の価値は、方針で得られる 累積報酬の期待値で表される。
最適行動価値関数 強化学習の目的は累積報酬が最大になる方針∗を見つけること → ∗では報酬が最大になるように行動する → 価値関数の値が最大になるように行動する ∗ , ≔ max
, ∗ , ≔ + max ′ ∗(′, ′)
Q-Learning 最適行動価値関数を見つけるために行動価値関数を更新 , ← , + + max ′ ′,
′ − , ( ∈ 0,1 ∶ 学習率) ある行動価値が一つ前の行動価値に伝播していく
DQN (Deep Q-Network) , を、とあるパラメータθを使った近似関数 , ; θ で表現 →
パラメータθをディープラーニングで求める 損失関数 = [( + max ′ ′, ′; −1 − , ; )2]
HRA ( Hybrid Reward Architecture for RL ) DQNは複雑なゲームだと、学習が遅くて安定しない →
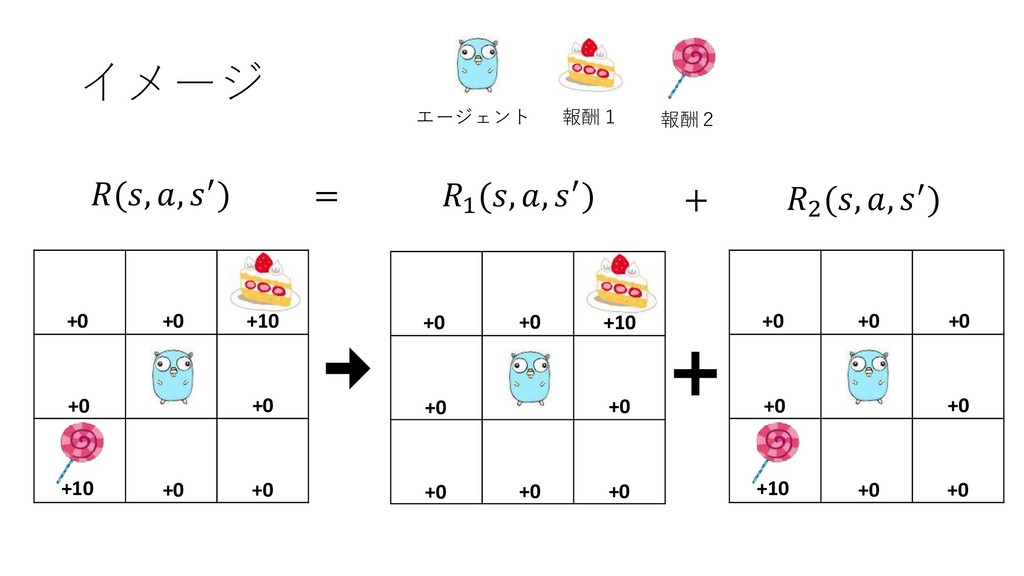
近似関数をもっと簡単にできないか? 報酬関数が分けられるときは分けて、それぞれ行動価値関数を学 習させれば、学習が容易にならないか? (, , ′) = =1 (, , ′)
イメージ エージェント 報酬1 報酬2 +10 +10 +0 +0 +0 +0
+0 +0 +10 +0 +0 +0 +0 +0 +0 +10 +0 +0 +0 +0 +0 +0 +0 +0 (, , ′) 1 (, , ′) 2 (, , ′) = +
行動価値関数 (HRAバージョン) , = =0 ∞ (+ , +
, ++1 ) | = , = , = =0 ∞ =1 + , + , ++1 | = , = , = =1 =0 ∞ + , + , ++1 | = , = , = =1 , ∶= ,
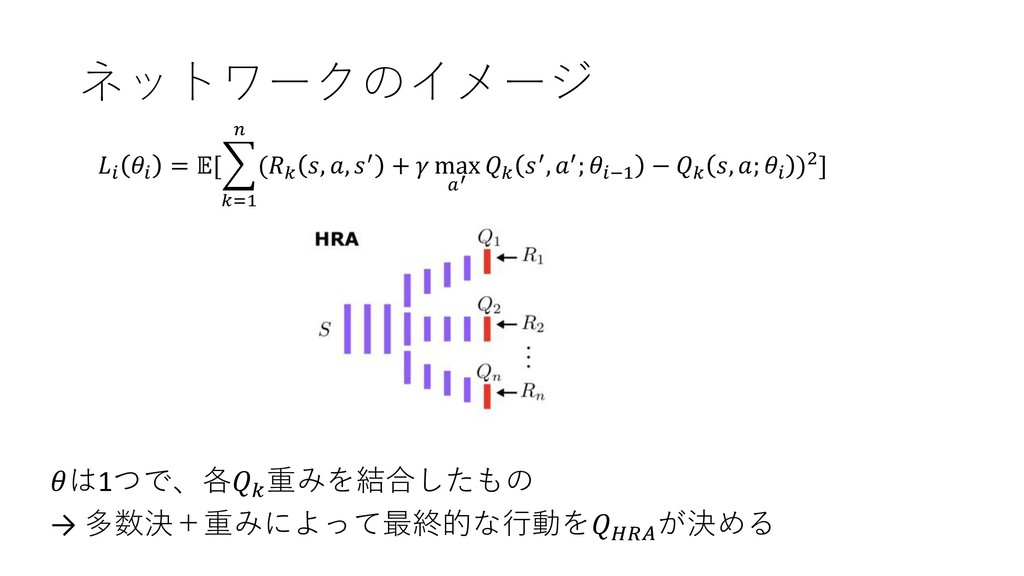
近似関数の損失関数 (HRAバージョン) DQN損失関数 = [( + max ′ ′, ′;
−1 − , ; )2] HRA損失関数 = [ =1 ( , , ′ + max ′ ′, ′; −1 − , ; )2]
ネットワークのイメージ = [ =1 ( , , ′ + max
′ ′, ′; −1 − , ; )2] は1つで、各 重みを結合したもの → 多数決+重みによって最終的な行動を が決める
問題固有の知識を活用 • 無関係な特徴量を削除する → 報酬1に対応する 1 , にとって、報酬2の情報は不要 • 最終状態を認識させる
→ 報酬1に対応する 1 , は、報酬1を得たら終了 • 擬似報酬を利用する → 報酬が得られる可能性のある場所に擬似的な報酬を設定する
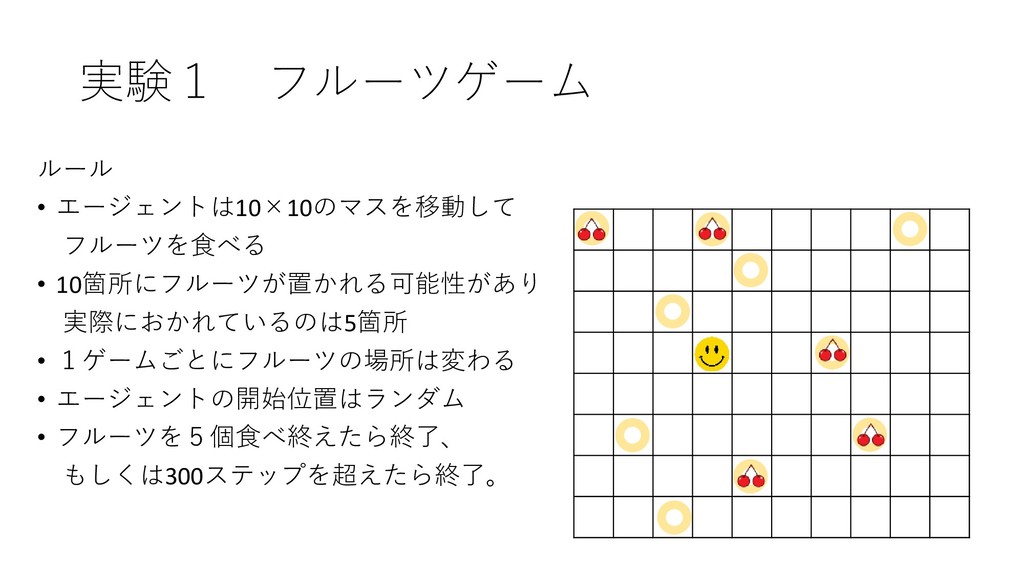
実験1 フルーツゲーム ルール • エージェントは10×10のマスを移動して フルーツを食べる • 10箇所にフルーツが置かれる可能性があり 実際におかれているのは5箇所 •
1ゲームごとにフルーツの場所は変わる • エージェントの開始位置はランダム • フルーツを5個食べ終えたら終了、 もしくは300ステップを超えたら終了。
パターン HRAではフルーツがおかれる可能性のある場所ごとに , , ′ と , 設定する。フルーツに1ポイントの報酬。 比較対象のDQNではただ単にフルーツに1ポイントの報酬 問題固有の知識を導入
• HRA+1 各 に対応するフルーツの位置だけ • HRA+2 各 に対応するフルーツが食べられない状態では学習しない • HRA+3 フルーツがおかれる可能性のある場所それぞれに擬似報酬 • DQN+1 HAR+1と同じネットワークを利用
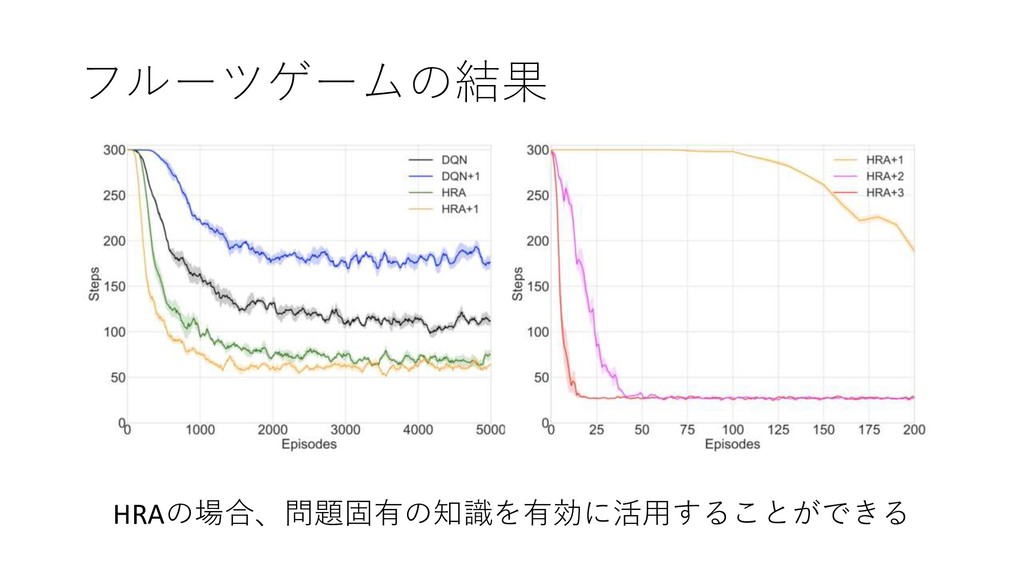
フルーツゲームの結果 HRAの場合、問題固有の知識を有効に活用することができる
実験2 パックマン • ペレットを食べるとポイントがもらえる • ゴーストに触れると死ぬ • スペシャルパワーペレットを食べると ゴーストが青くなってゴーストを食べれ てポイントがもらえる
• 全てのペレットを食べると次のレベルに いける • レベルごとにフルーツが2個食べれる。 フルーツは7種類あってポイントがそれ ぞれ違う • 4種類のエリアがある
HRA表現 状態 : ネットワークのinput部分 • エリアを160×160で表現 • ゴースト4体それぞれの位置 • 青ゴースト4体それぞれの位置
• パックマンの位置 • フルーツの位置 • ペレットの位置
HRA表現 行動:ネットワークのoutput layer (headごと)のnodes → パックマンの上下左右で4つ 報酬:それぞれ , , ′
と , 設定する • ペレット → ゲーム内でのポイント • ゴースト → -1000ポイント • 青ゴースト → ゲーム内でのポイント • フルーツ → ゲーム内でのポイント
工夫 • 各 , を合算するとき、正規化する • エリア内の特定の場所へ移動するための擬似報酬を設定する • 探索用の ,
を2つ追加 → 1つめは一様分布のランダムな値[0,20] → 2つめはとaが今までにないパターンの場合にボーナスを与える
結果
報酬を分割することで、問題固有の知識を活用でき、学習を容易 にすることが可能 結論
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}