중요하게 생각하세요? Intelligence Price Price per token, represented as USD per million Tokens. Output Speed Tokens per second received while the model is generating tokens (ie. after first chunk has been received from the API for models which support streaming). 7
helpful to think of a model card as a "nutrition label" for the underlying models that power AI applications. Nutrition labels provide essential information about food products. Model cards do the same for AI by outlining the key facts about a model in a clear, digestible format. By explaining how a model was built, tested, and performs, model cards make it easier to understand and compare models. Model cards can be thought of as a summarized and more digestible version of detailed, academic-style technical reports, A model card is not intended as a replacement for, but instead a complement to, these deeper technical reports. Model Cards 9 @source: https://modelcards.withgoogle.com/
limits The following table lists the rate limits for all standard Gemini API calls. Rate Limit Rate limits are usually measured across three dimensions: • Requests per minute (RPM) • Tokens per minute (input) (TPM) • Requests per day (RPD) Rate limits are applied per project, not per API key. Requests per day (RPD) quotas reset at midnight Pacific time. Usage tiers Rate limits are tied to the project's usage tier. As your API usage and spending increase, you'll have an option to upgrade to a higher tier with increased rate limits. 15
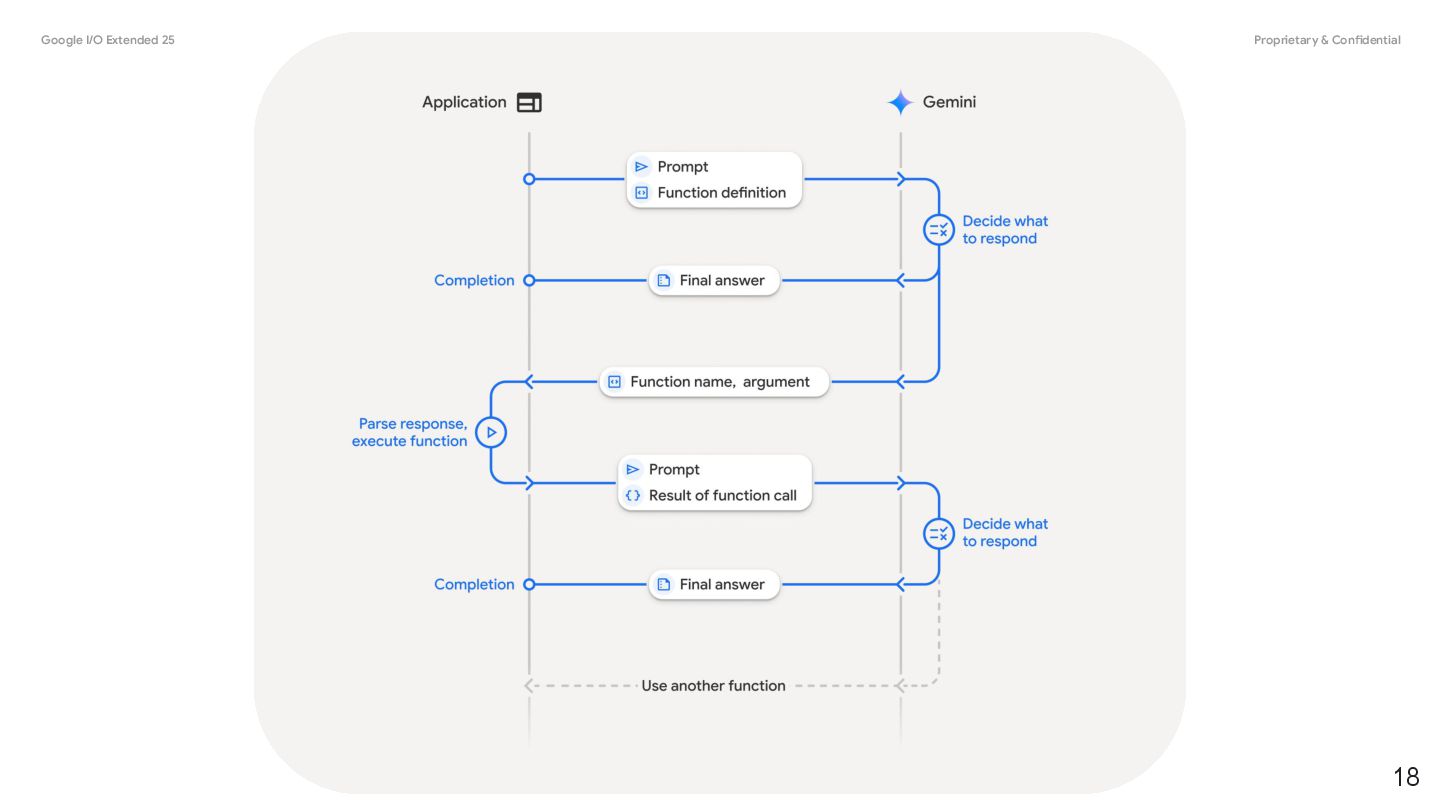
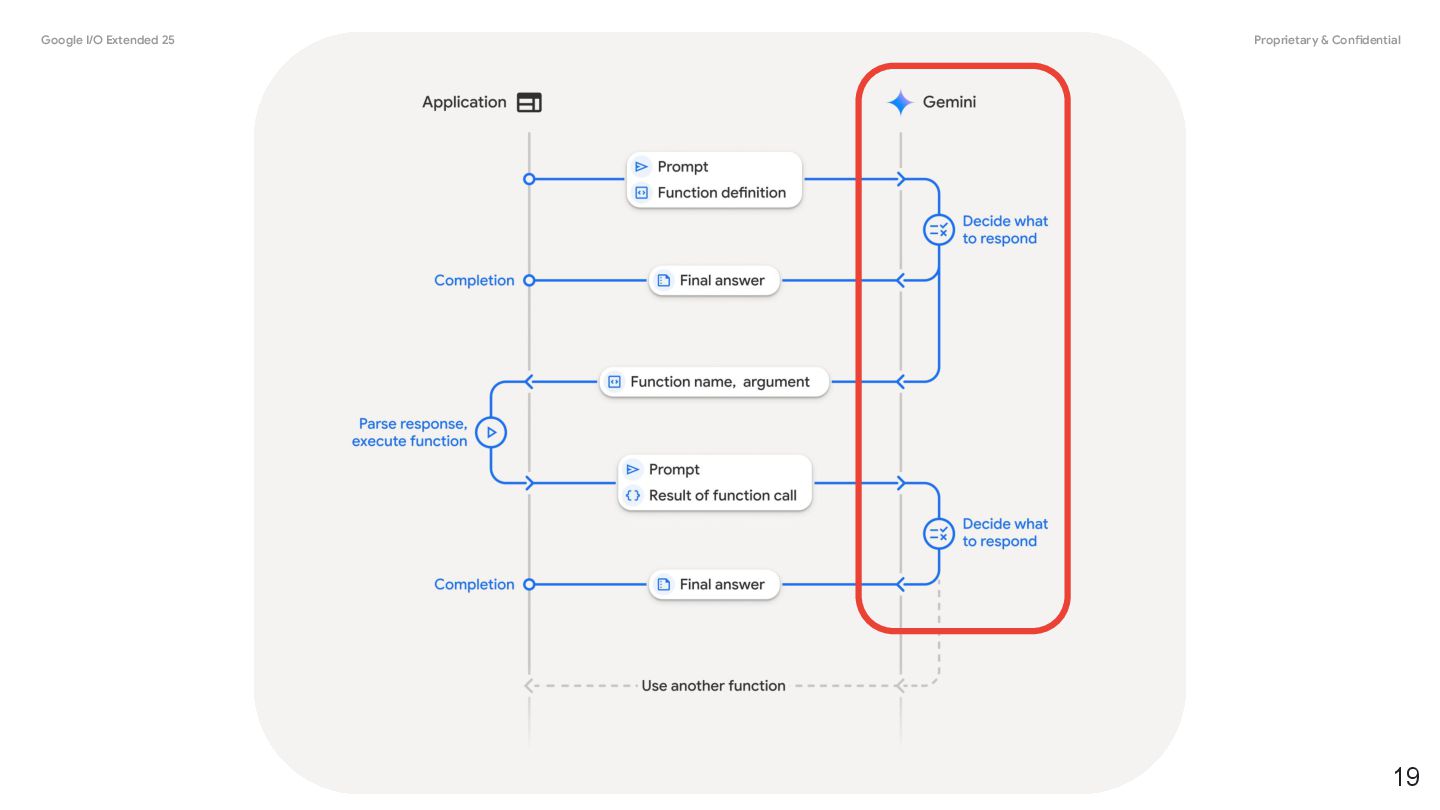
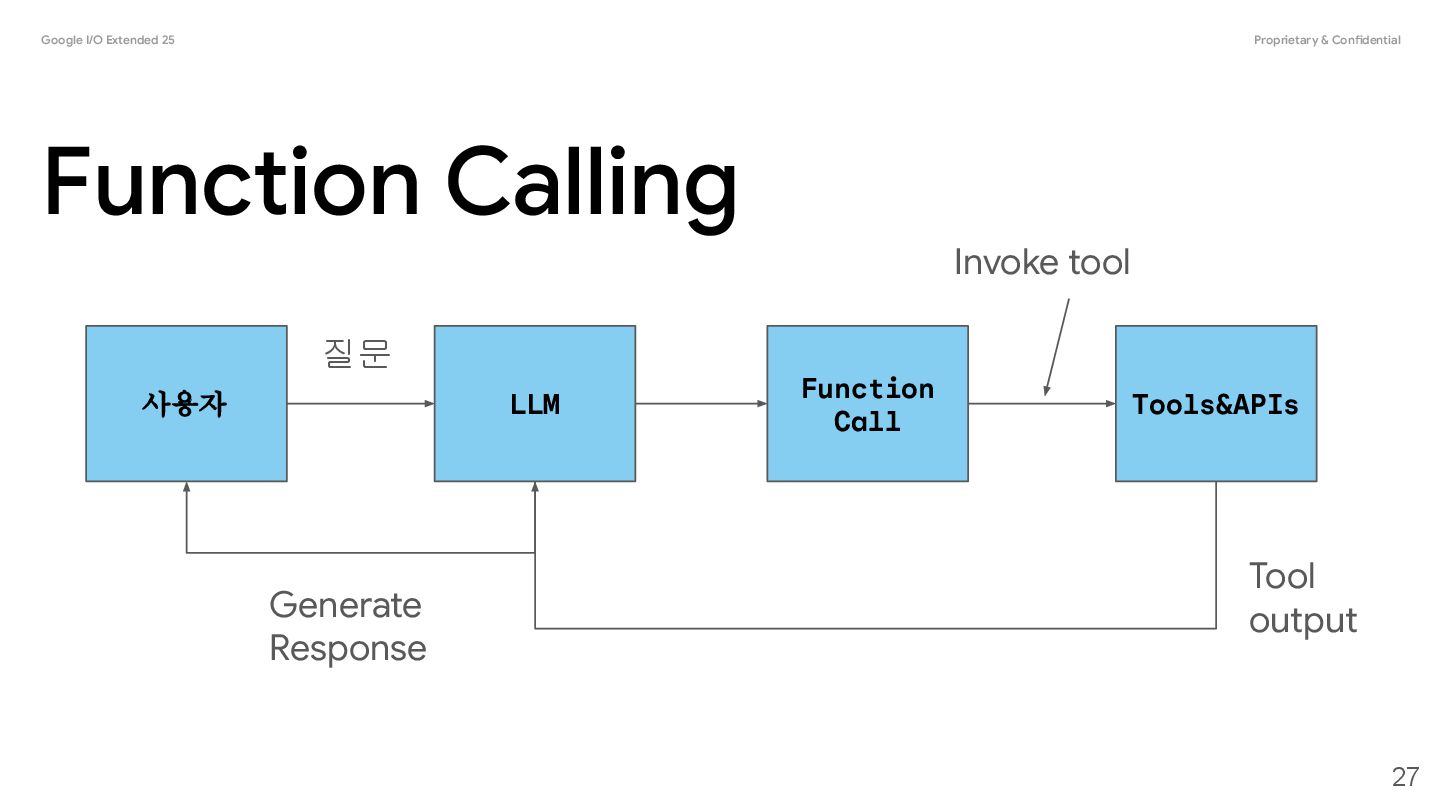
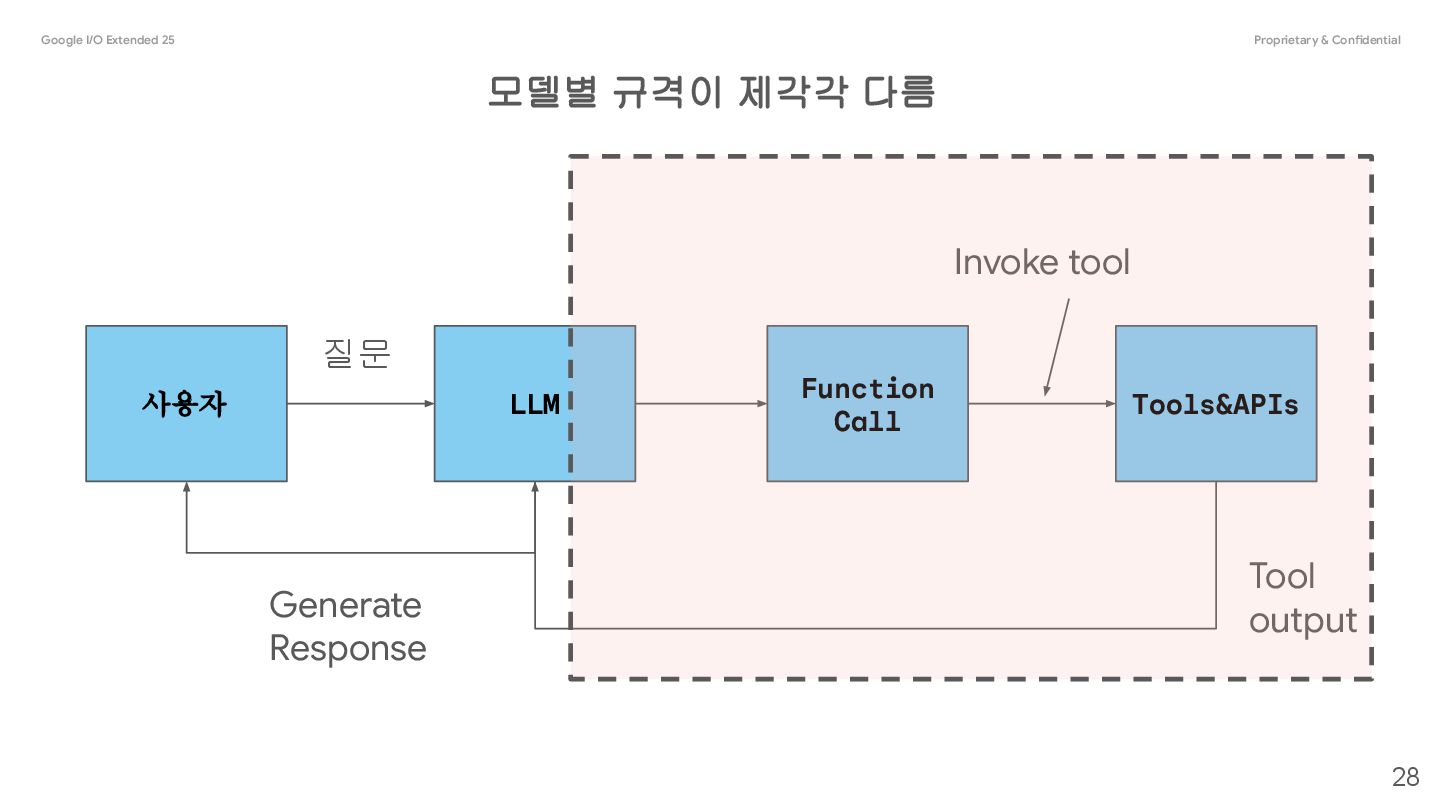
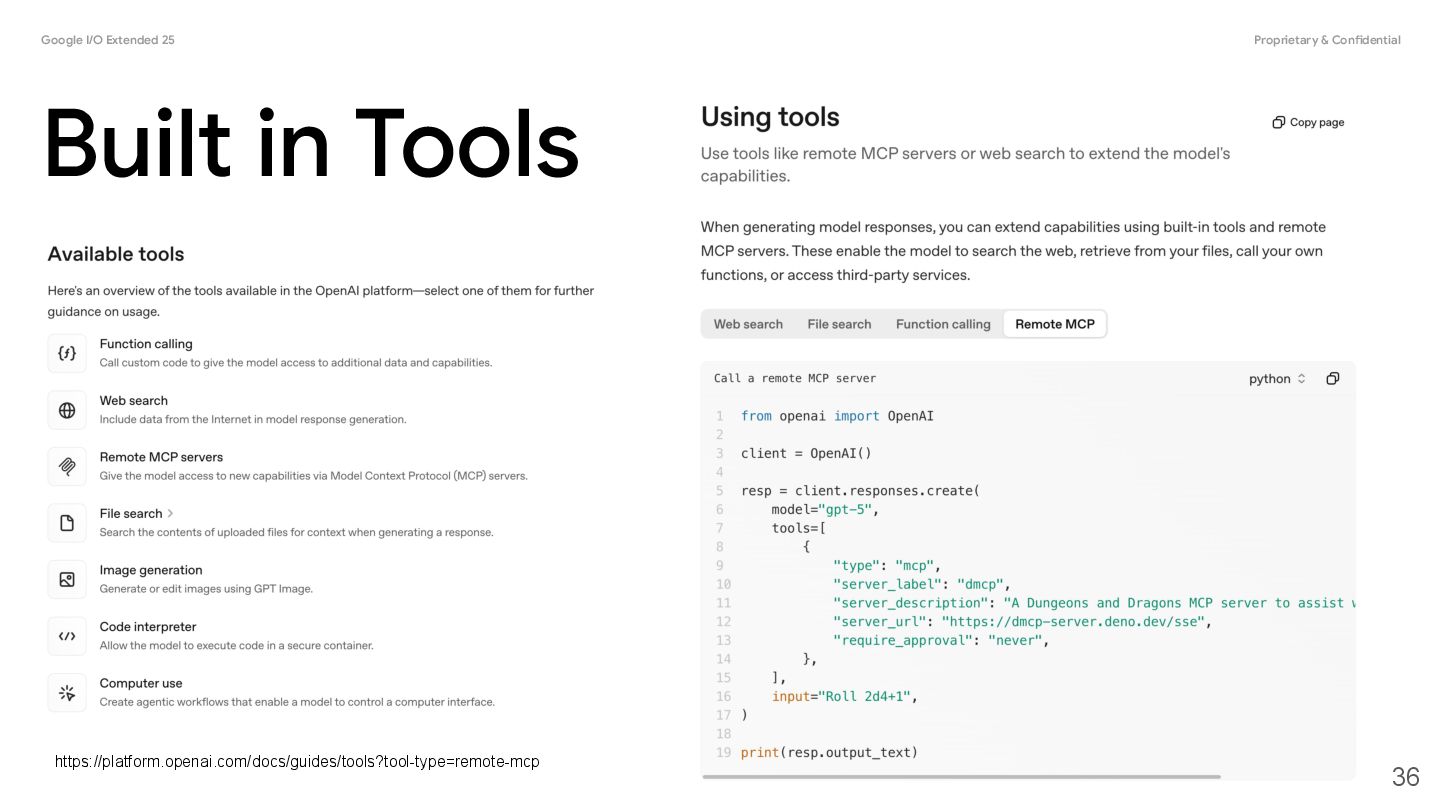
you connect models to external tools and APIs. Instead of generating text responses, the model determines when to call specific functions and provides the necessary parameters to execute real-world actions. • Augment Knowledge: Access information from external sources like databases, APIs, and knowledge bases. • Extend Capabilities: Use external tools to perform computations and extend the limitations of the model, such as using a calculator or creating charts. • Take Actions: Interact with external systems using APIs, such as scheduling appointments, creating invoices, sending emails, or controlling smart home devices. Function Calling 17 @source: https://ai.google.dev/gemini-api/docs/function-calling
a structured interaction between your application, the model, and external functions. Here's a breakdown of the process: 1. Define Function Declaration: Define the function declaration in your application code. Function Declarations describe the function's name, parameters, and purpose to the model. 2. Call LLM with function declarations: Send user prompt along with the function declaration(s) to the model. It analyzes the request and determines if a function call would be helpful. If so, it responds with a structured JSON object. 3. Execute Function Code (Your Responsibility): The Model does not execute the function itself. It's your application's responsibility to process the response and check for Function Call, if • Yes: Extract the name and args of the function and execute the corresponding function in your application. • No: The model has provided a direct text response to the prompt (this flow is less emphasized in the example but is a possible outcome). 4. Create User friendly response: If a function was executed, capture the result and send it back to the model in a subsequent turn of the conversation. It will use the result to generate a final, user-friendly response that incorporates the information from the function call. 20 @source: https://ai.google.dev/gemini-api/docs/function-calling
"""Set the brightness and color temperature of a room light. (mock API). Args: brightness: Light level from 0 to 100. Zero is off and 100 is full brightness color_temp: Color temperature of the light fixture, which can be `daylight`, `cool` or `warm`. Returns: A dictionary containing the set brightness and color temperature. """ return {"brightness": brightness, "colorTemperature": color_temp} 21 실제 Action을 수행하는 Method(Function)
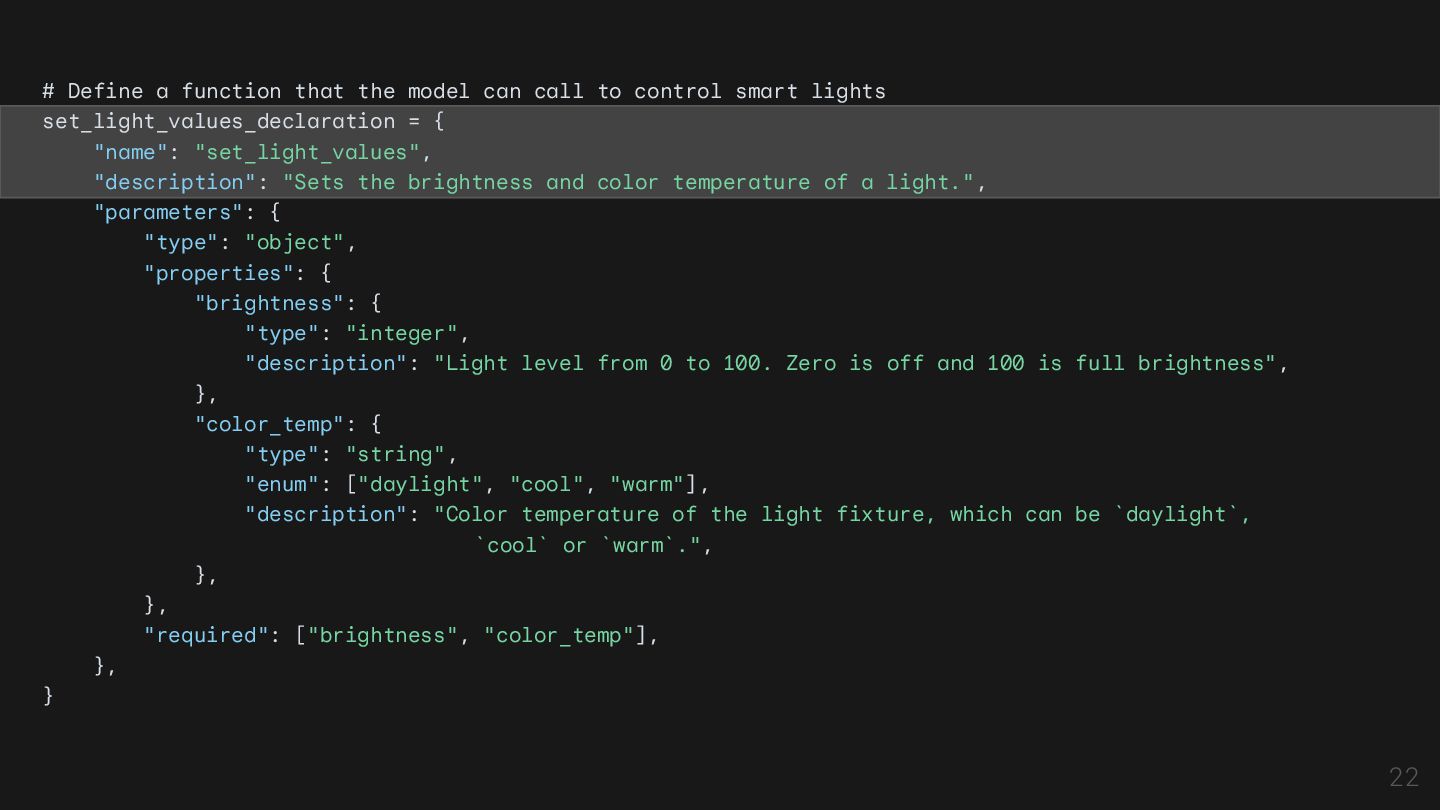
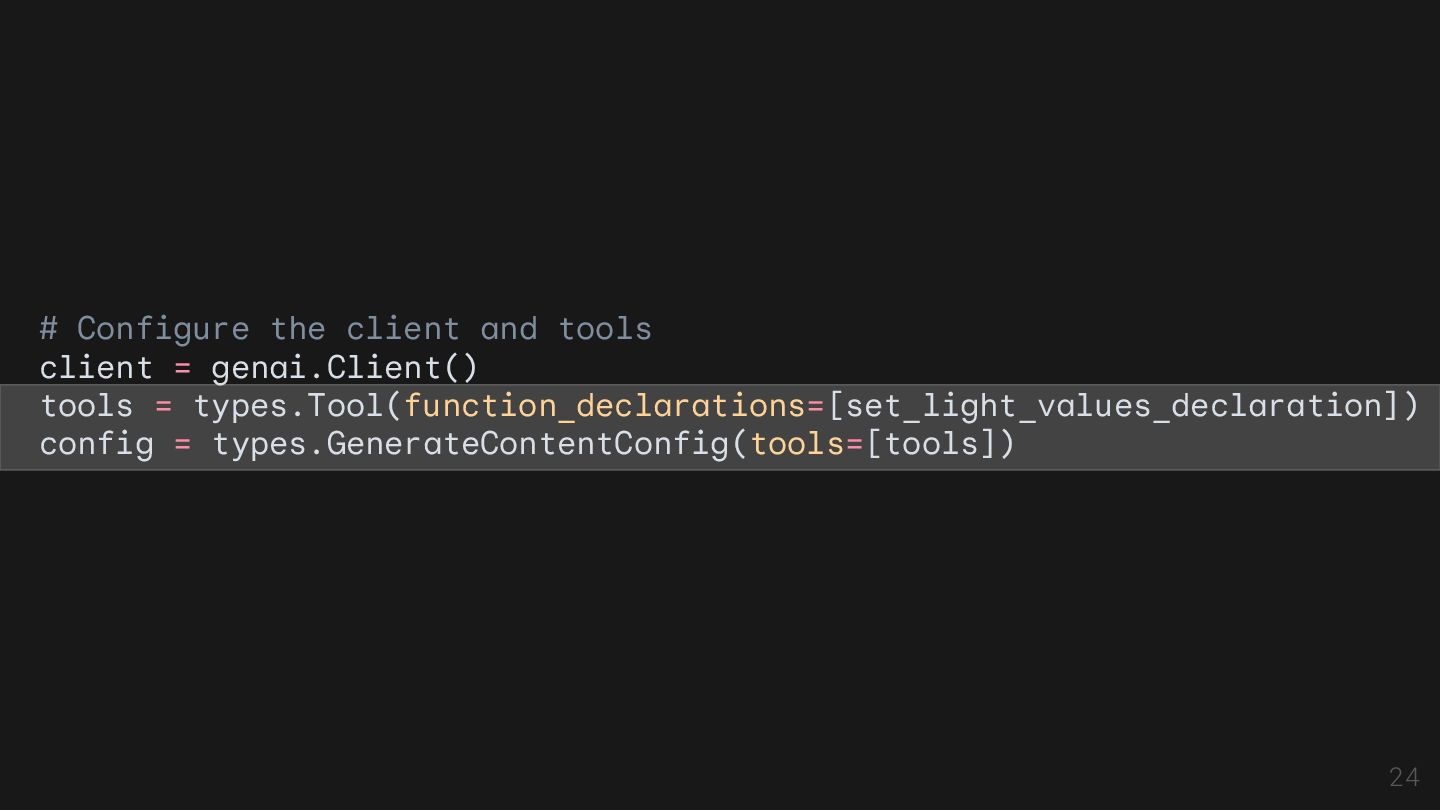
control smart lights set_light_values_declaration = { "name": "set_light_values", "description": "Sets the brightness and color temperature of a light.", "parameters": { "type": "object", "properties": { "brightness": { "type": "integer", "description": "Light level from 0 to 100. Zero is off and 100 is full brightness", }, "color_temp": { "type": "string", "enum": ["daylight", "cool", "warm"], "description": "Color temperature of the light fixture, which can be `daylight`, `cool` or `warm`.", }, }, "required": ["brightness", "color_temp"], }, } 22
control smart lights set_light_values_declaration = { "name": "set_light_values", "description": "Sets the brightness and color temperature of a light.", "parameters": { "type": "object", "properties": { "brightness": { "type": "integer", "description": "Light level from 0 to 100. Zero is off and 100 is full brightness", }, "color_temp": { "type": "string", "enum": ["daylight", "cool", "warm"], "description": "Color temperature of the light fixture, which can be `daylight`, `cool` or `warm`.", }, }, "required": ["brightness", "color_temp"], }, } 23
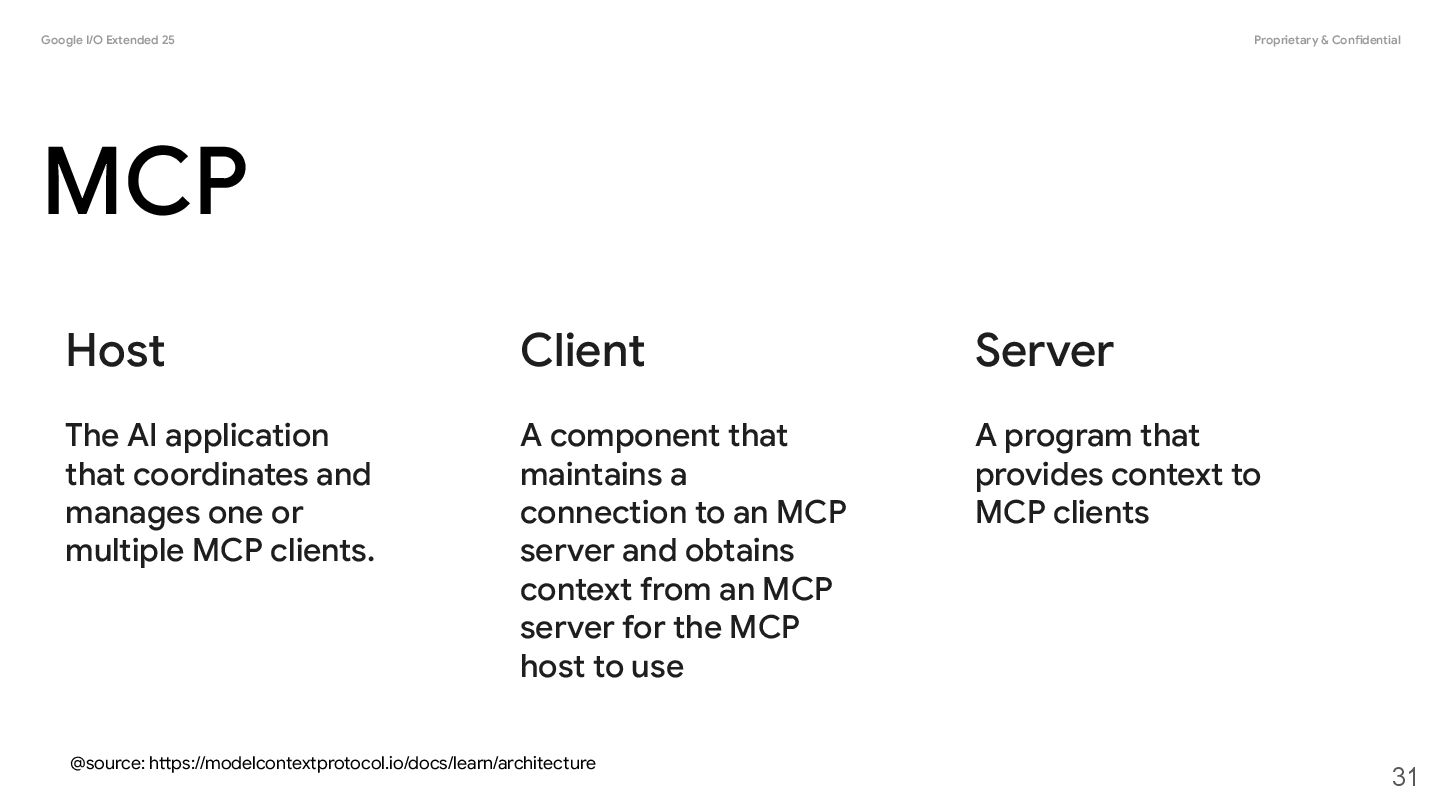
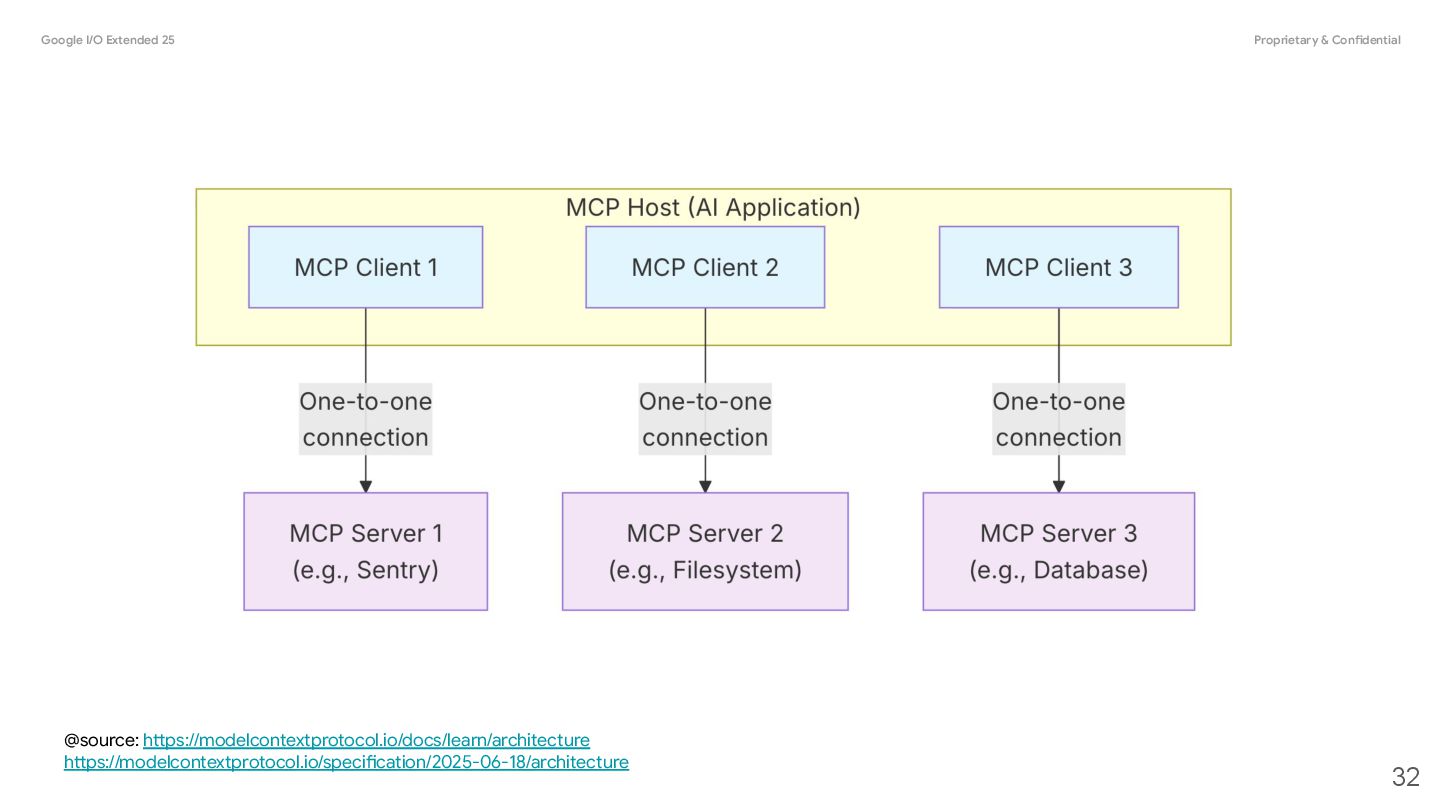
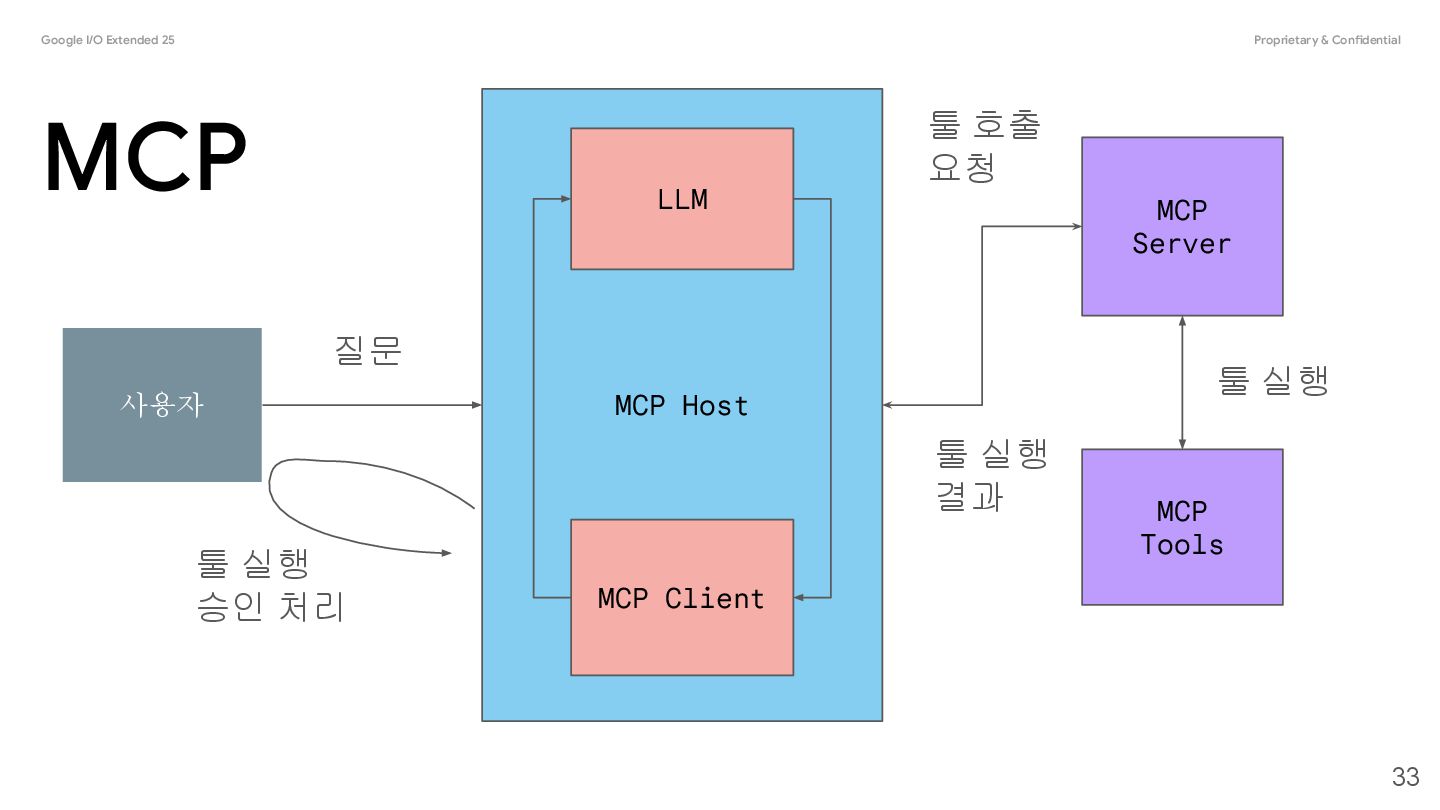
AI application that coordinates and manages one or multiple MCP clients. Client A component that maintains a connection to an MCP server and obtains context from an MCP server for the MCP host to use Server A program that provides context to MCP clients 31 @source: https://modelcontextprotocol.io/docs/learn/architecture
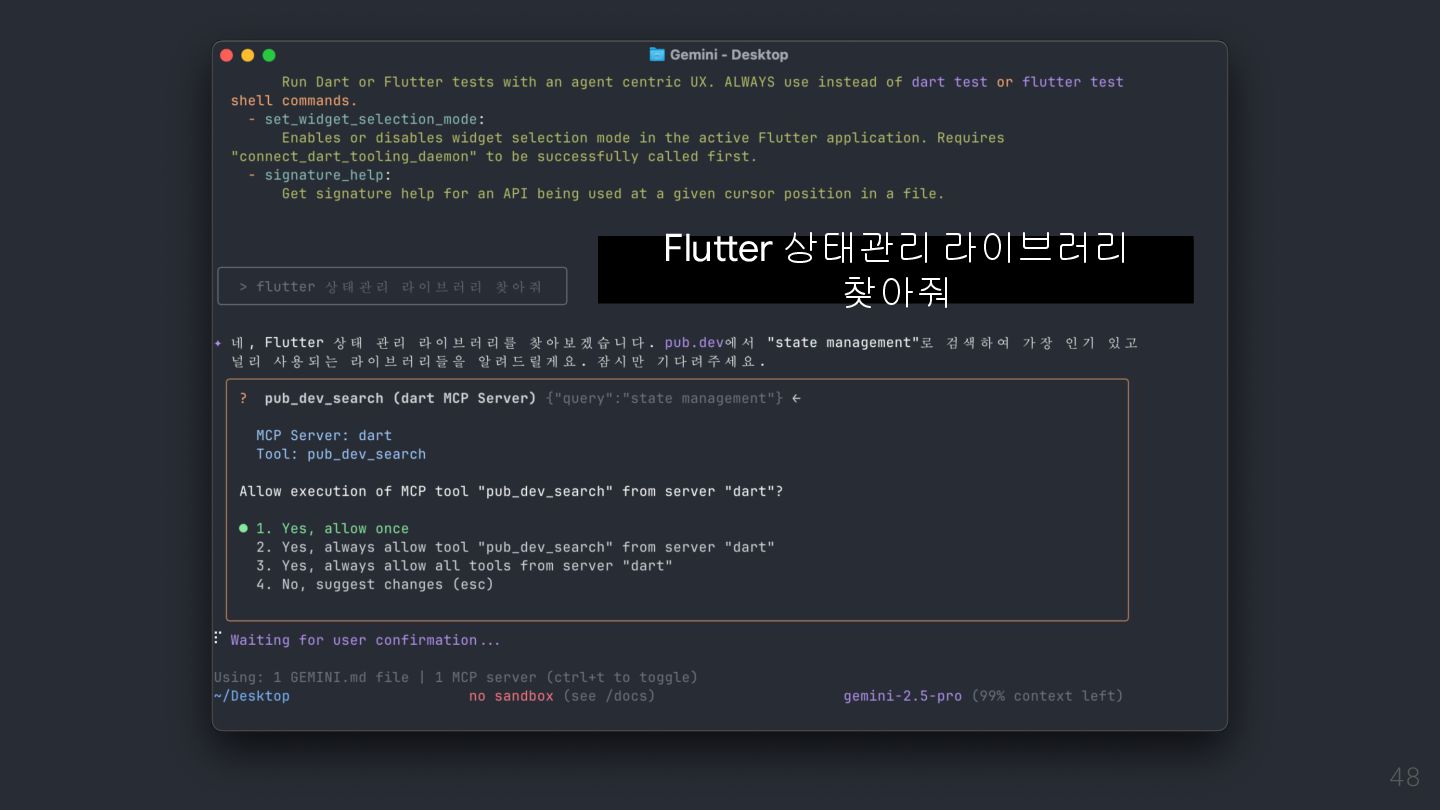
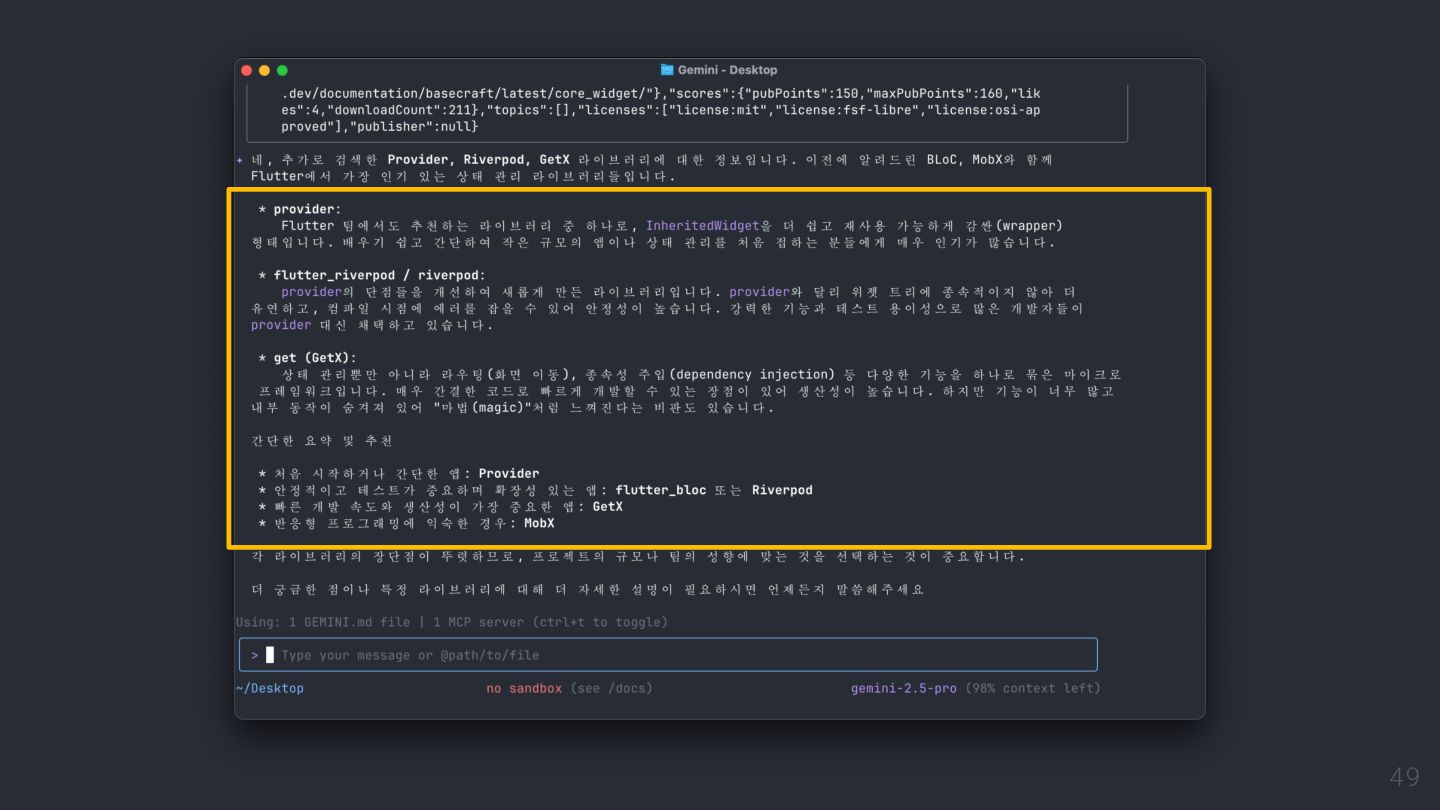
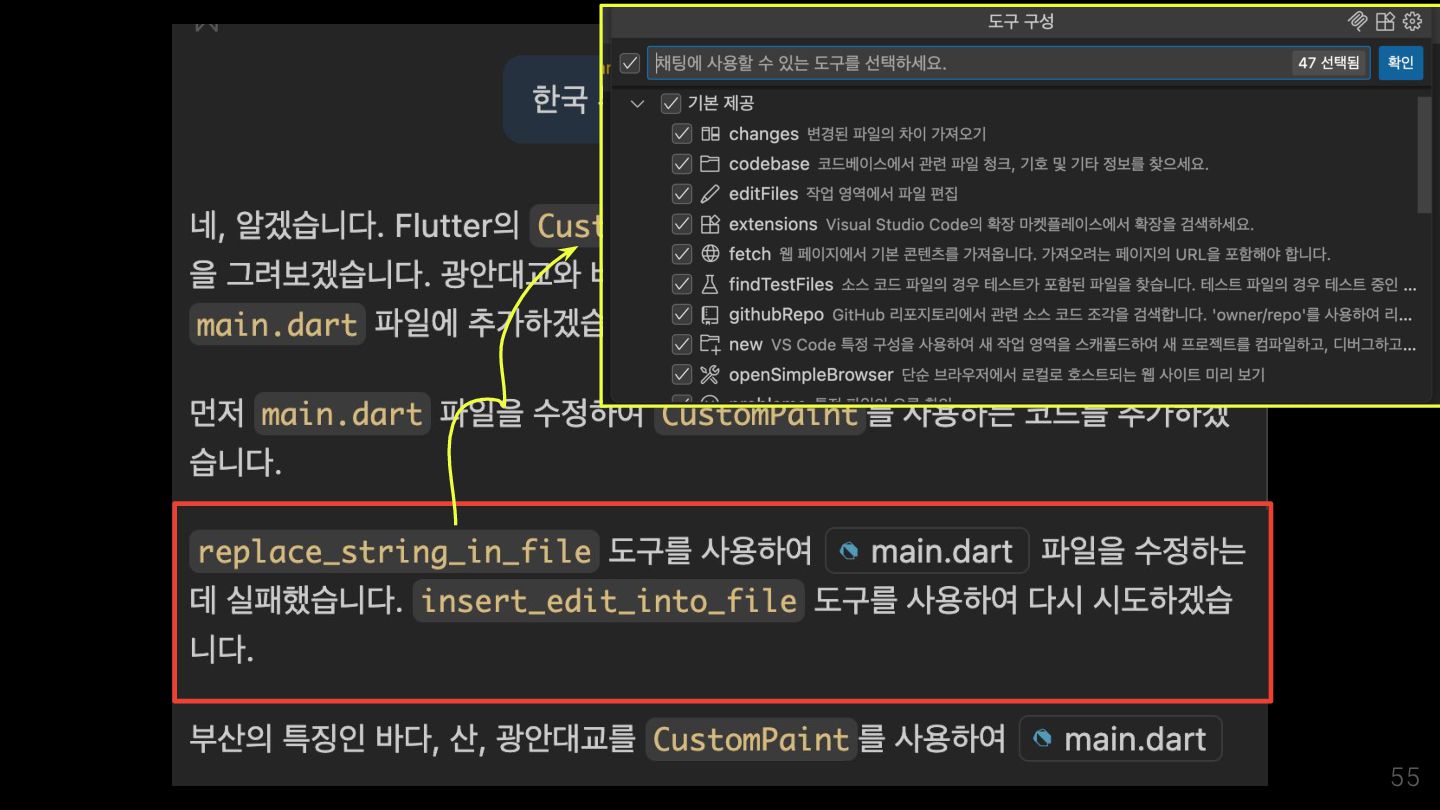
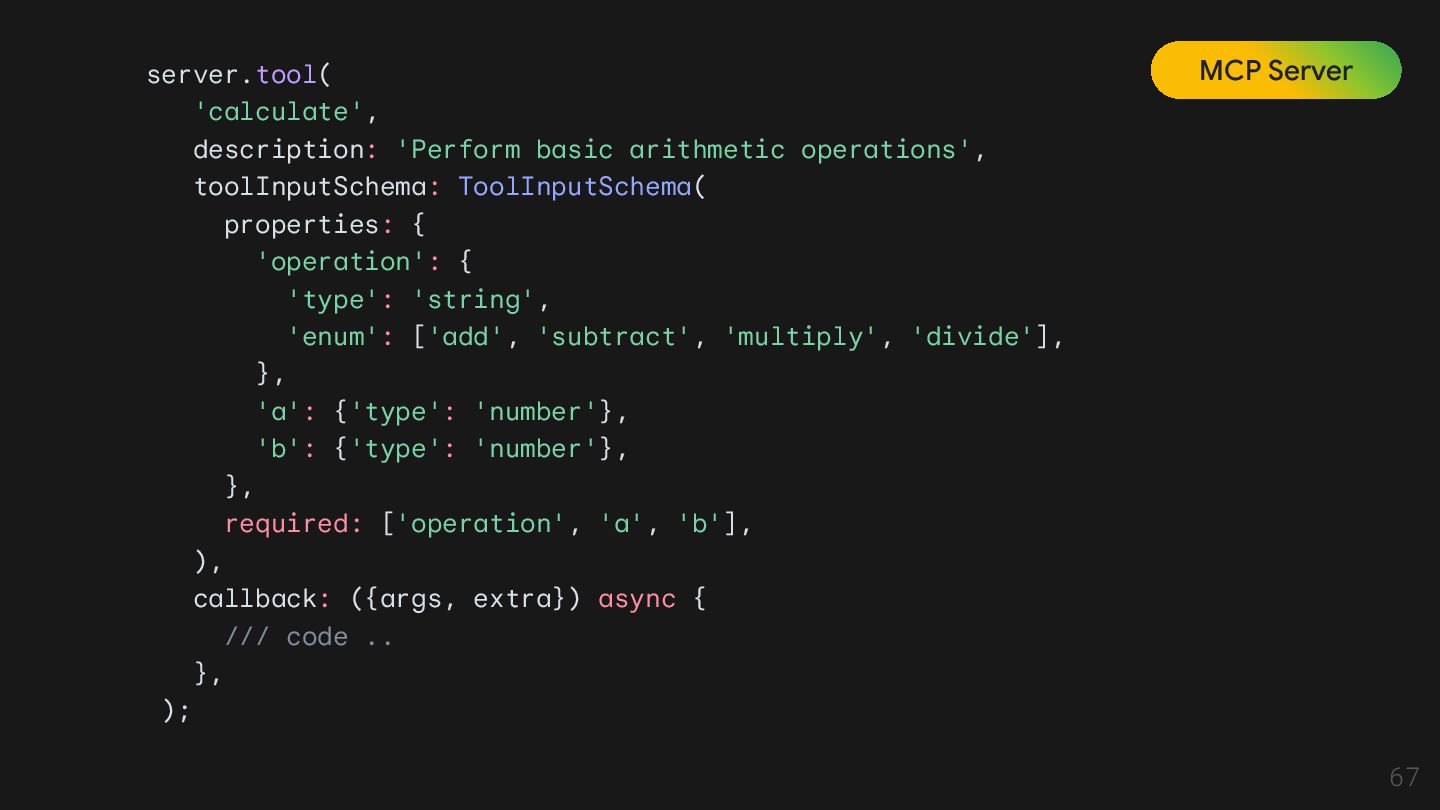
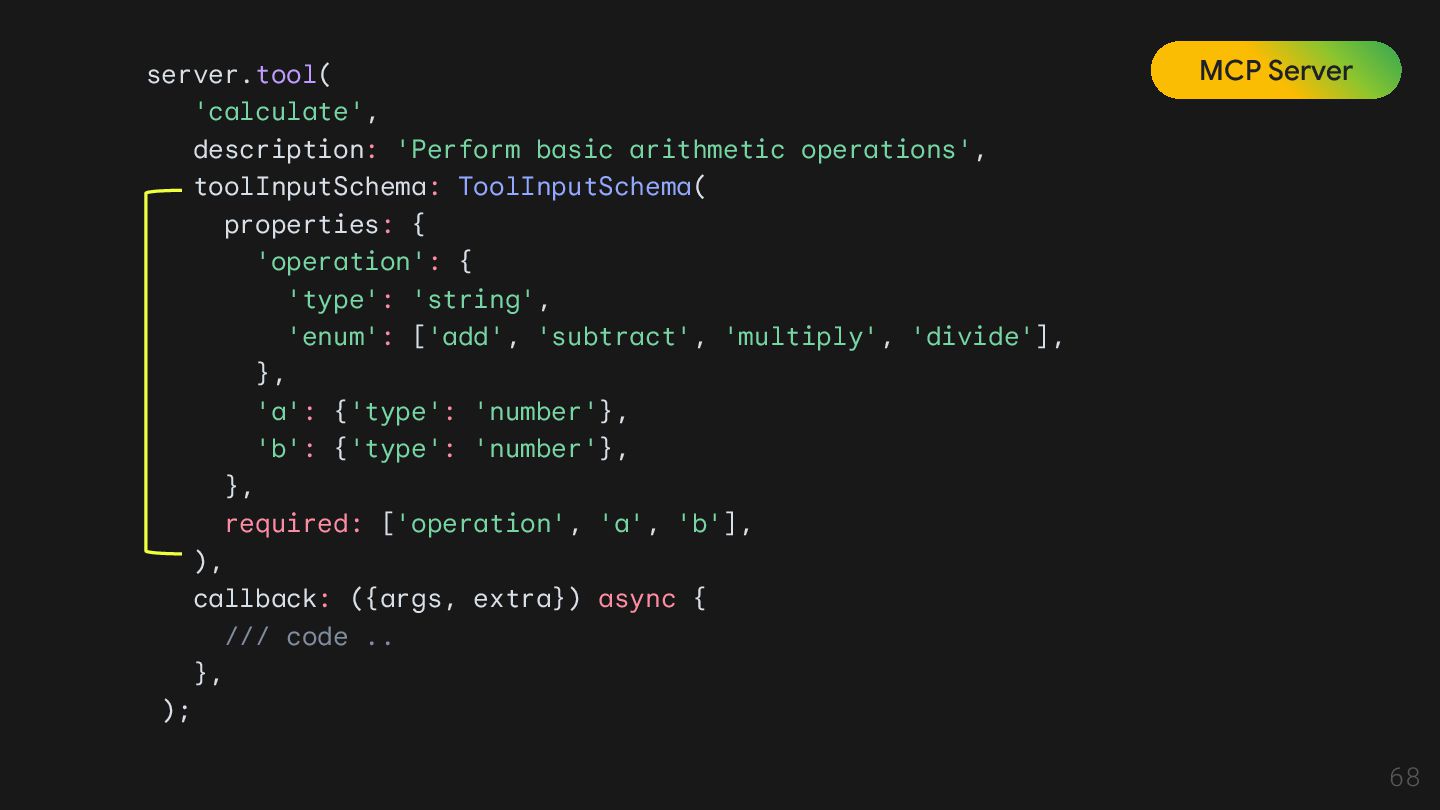
Model Context Protocol (MCP) allows servers to expose tools that can be invoked by language models. Tools enable models to interact with external systems, such as querying databases, calling APIs, or performing computations. Each tool is uniquely identified by a name and includes metadata describing its schema. @Source: https://modelcontextprotocol.io/specification/2025-06-18/server/tools
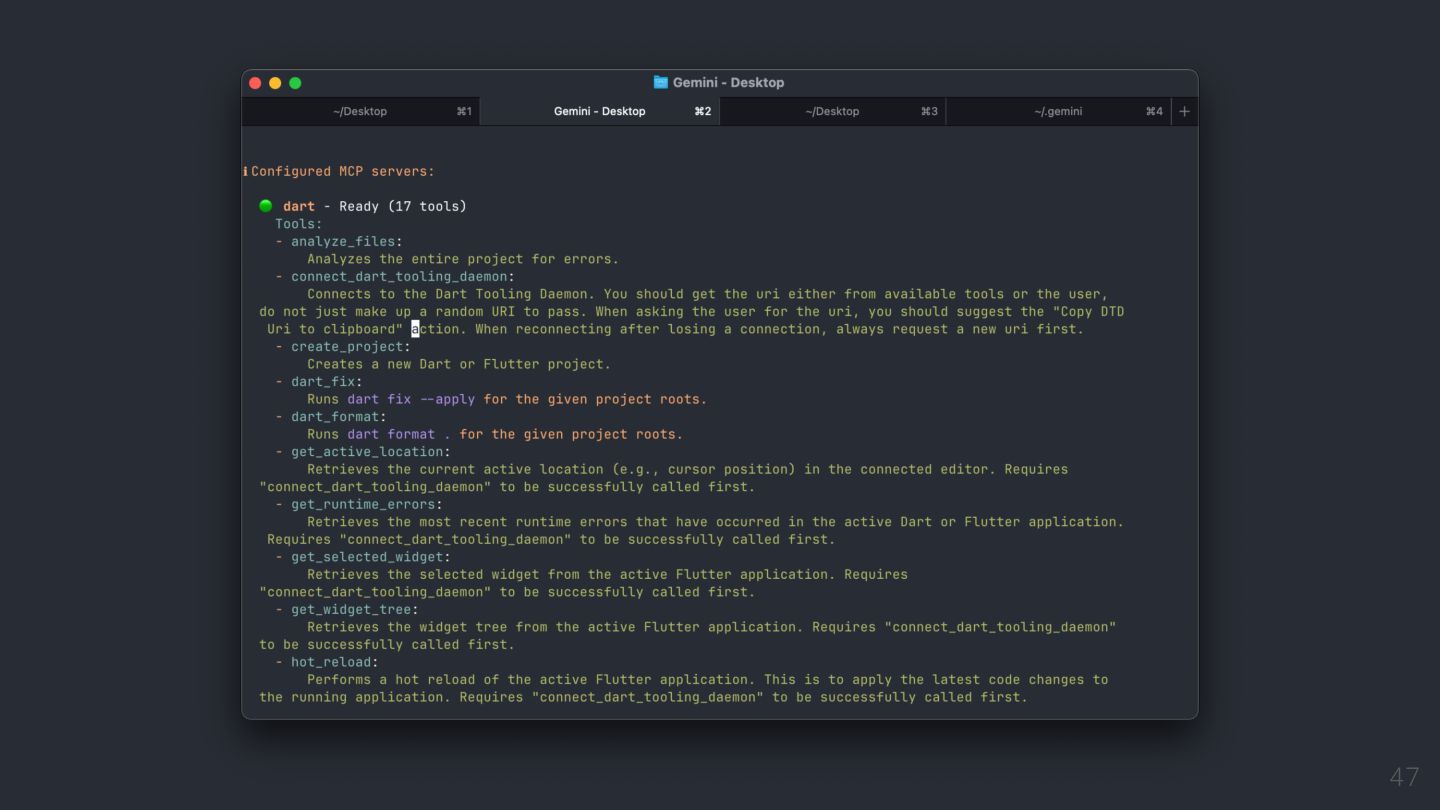
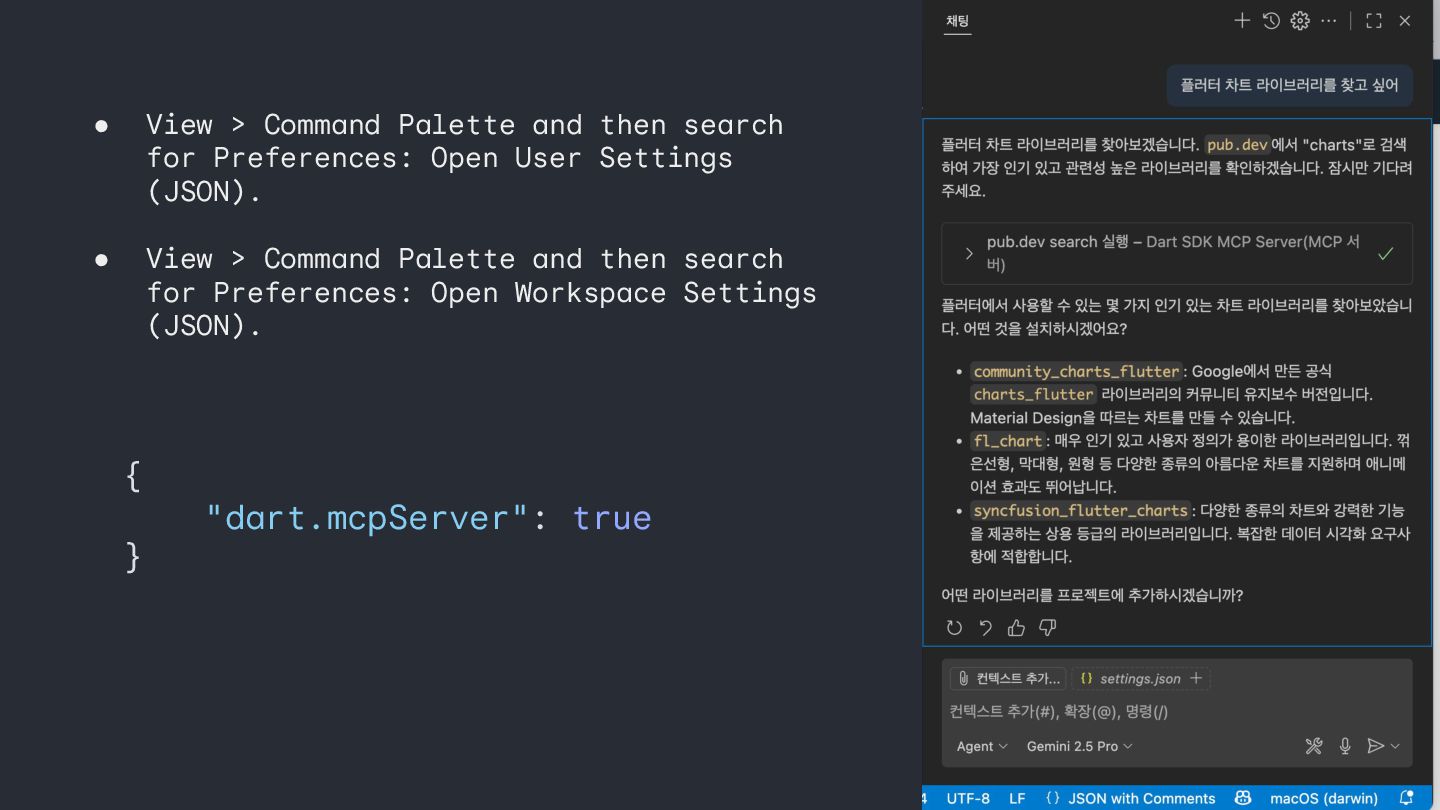
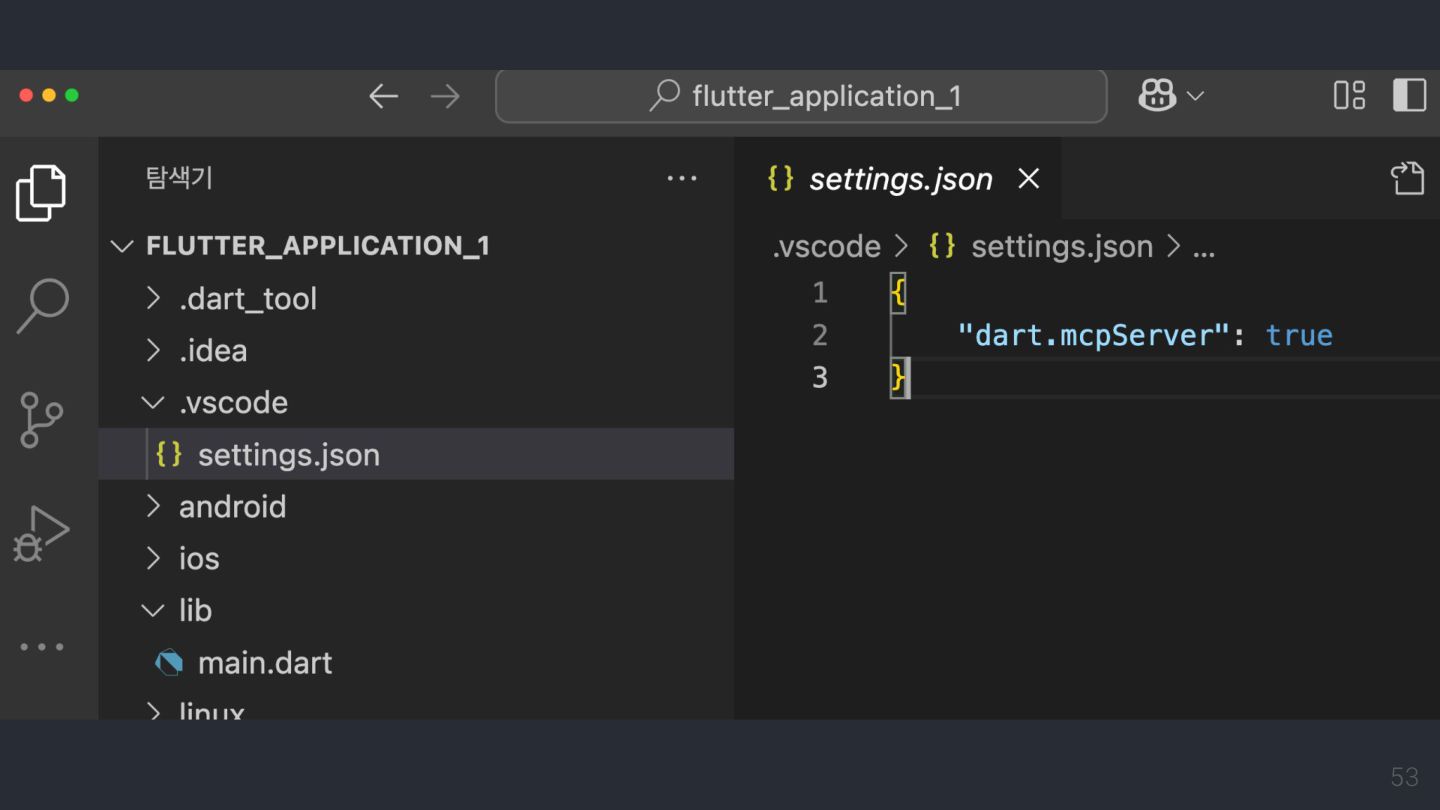
MCP Server 40 The Dart and Flutter MCP server exposes Dart (and Flutter) development tool actions to compatible AI-assistant clients. The Dart and Flutter MCP server can work with any MCP client that supports standard I/O (stdio) as the transport medium
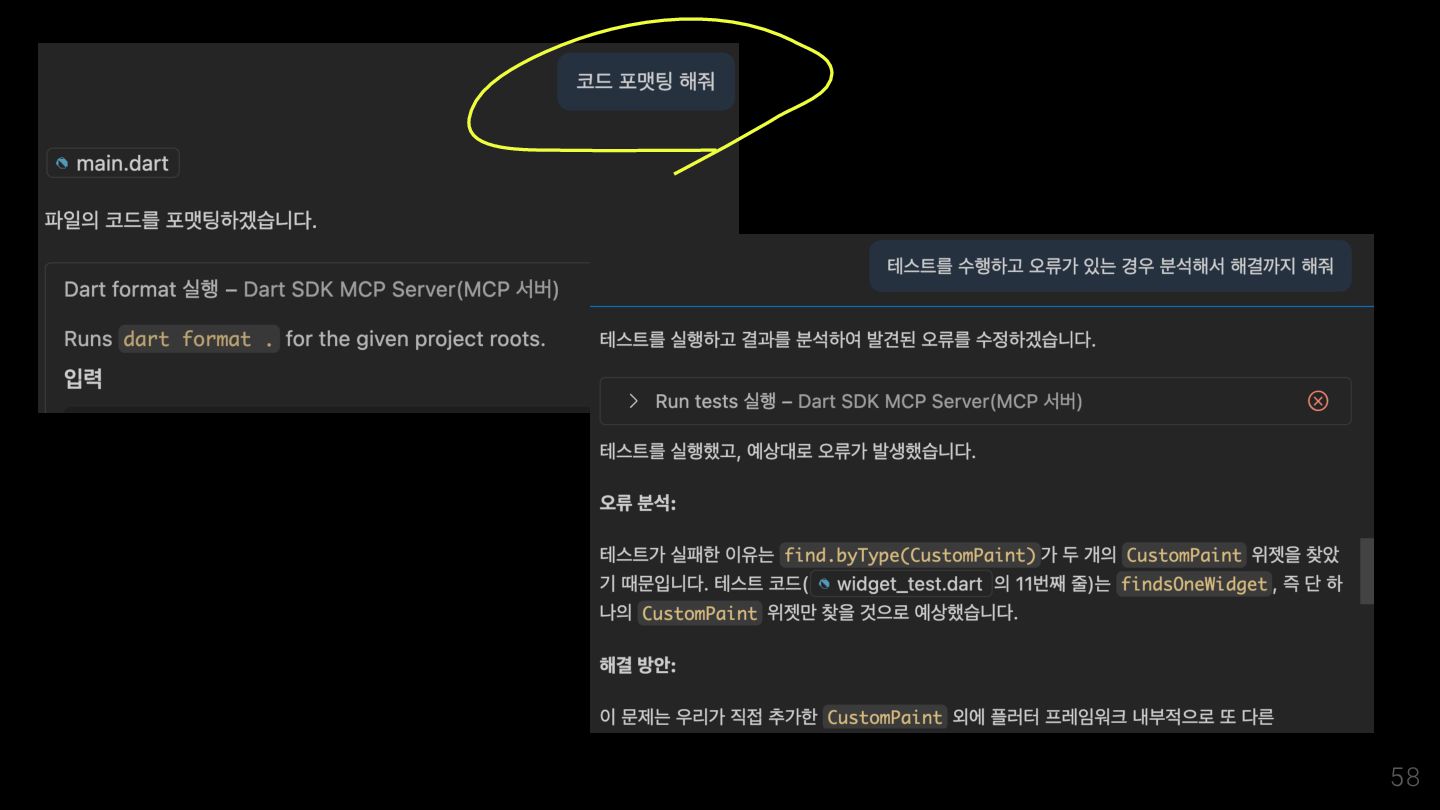
MCP Server 41 • Analyze and fix errors in your project's code. • Resolve symbols to elements to ensure their existence and fetch documentation and signature information for them. • Introspect and interact with your running application. • Search the pub.dev site for the best package for a use case. • Manage package dependencies in your pubspec.yaml file. • Run tests and analyze the results. • Format code with the same formatter and config as dart format and the Dart analysis server.
오류 분석 및 수정: 프로젝트 코드 내의 오류를 식별하고 해결합니다. • 심볼 확인 및 정보 가져오기: 심볼을 요소에 연결하여 해당 존재를 확인하고, 이에 대한 문서 및 서명 정보를 가져옵니다. • 애플리케이션 검사 및 상호 작용: 실행 중인 애플리케이션을 자세히 살펴보고 상호 작용합니다. • 패키지 검색: 특정 사용 사례에 가장 적합한 패키지를 찾기 위해 pub.dev 사이트를 검색합니다. • 종속성 관리: pubspec.yaml 파일에서 패키지 종속성을 관리합니다. • 테스트 실행 및 결과 분석: 테스트를 실행하고 그 결과를 분석합니다. • 코드 형식 지정: dart format 및 Dart 분석 서버와 동일한 포맷터 및 구성으로 코드를 형식 지정합니다.
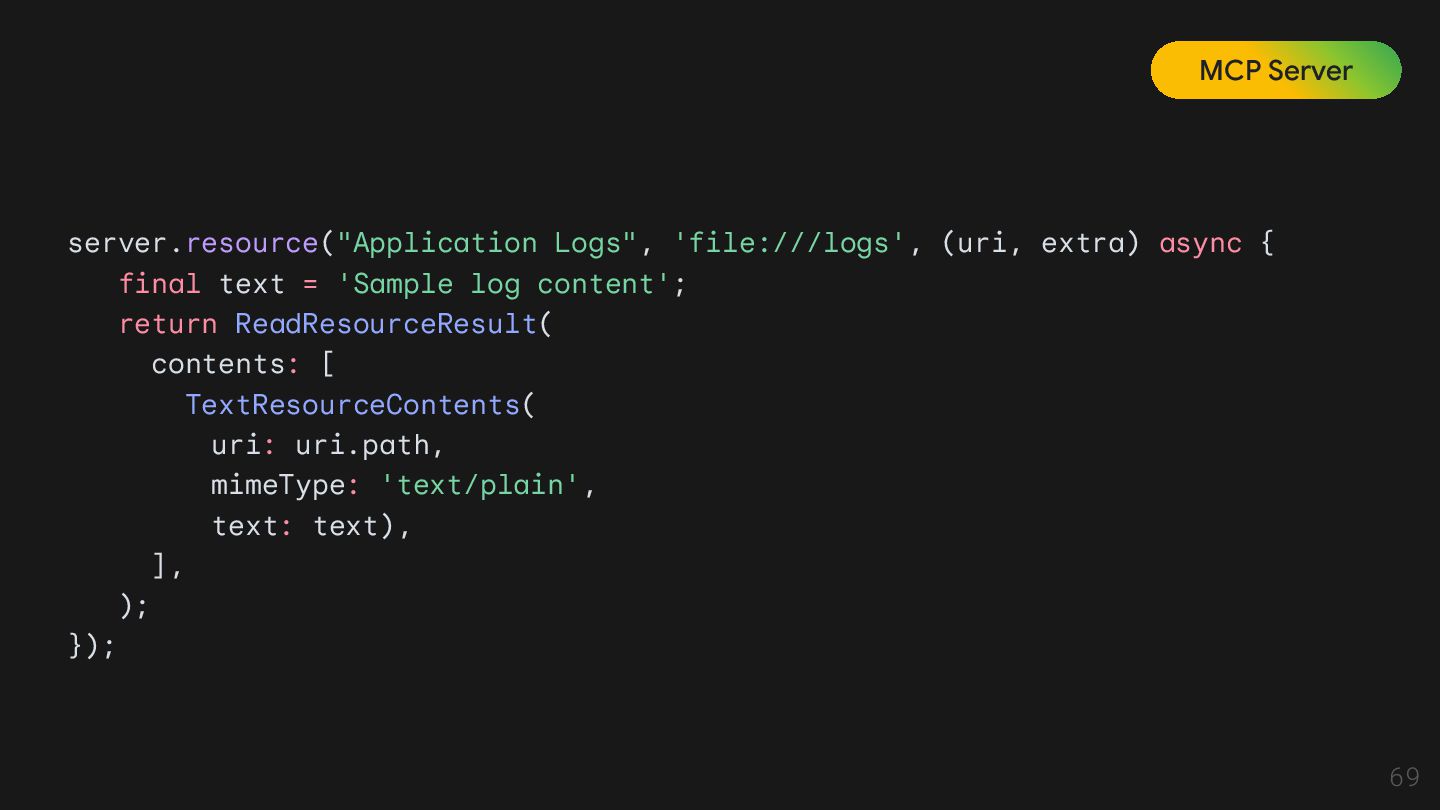
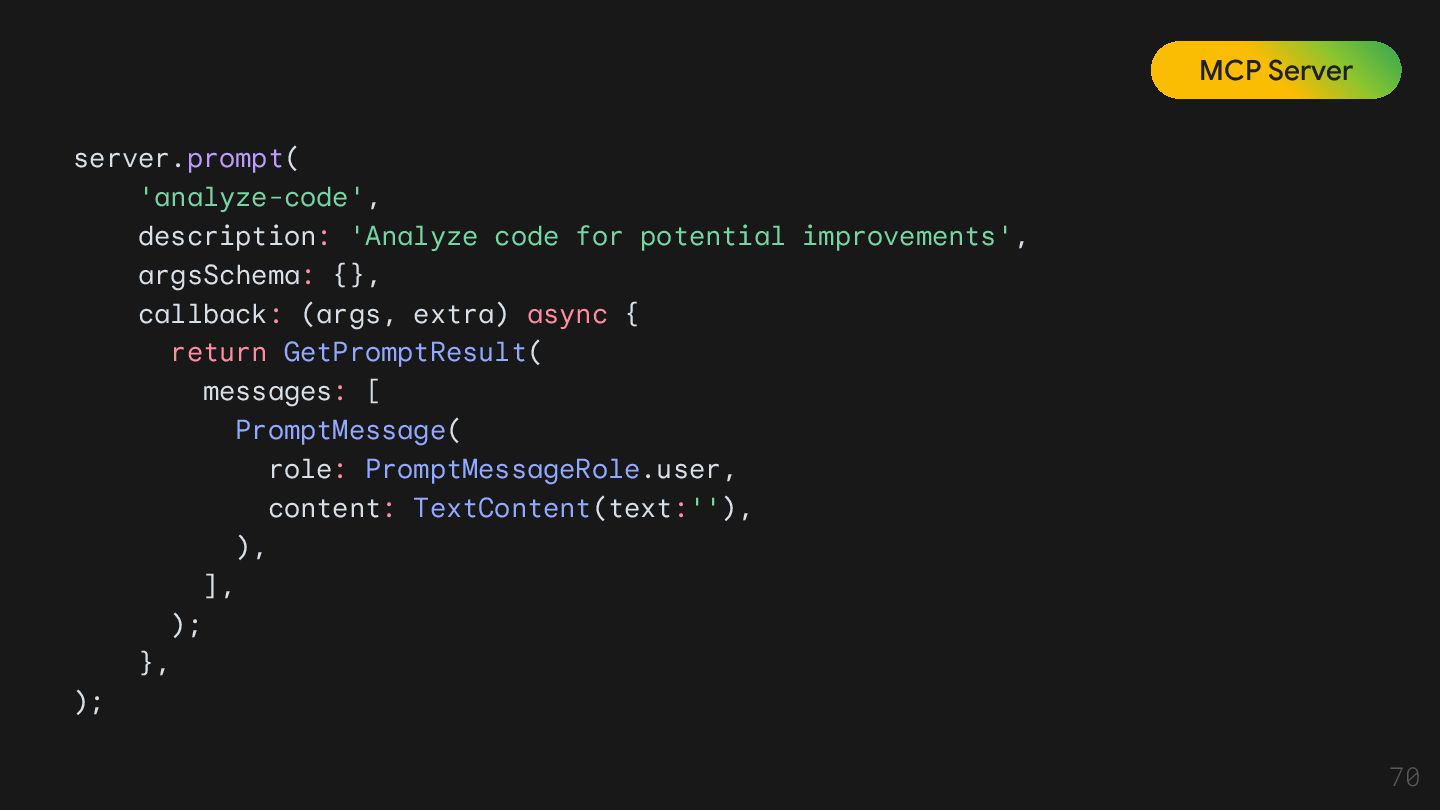
Tool Tool은 모델이 직접 실행할 수 있는 외부 기능 Resource Resource는 모델이 '읽을 수 있는' 데이터 소스를 의미함. 모델의 '배경지식' 역할을 하며, 특정 데이터에 접근하고 읽어오는 방법을 표준화한 것. 이는 모델이 실시간으로 최신 정보를 얻거나, 내부 데이터베이스에 접근할 수 있게 함. Prompt Prompt는 모델이 작업을 수행하도록 안내하는 재사용 가능한 템플릿. 사용자의 질문을 바탕으로 모델에게 어떤 툴과 리소스를 사용할지, 그리고 어떻게 응답할지 지시하는 역할.
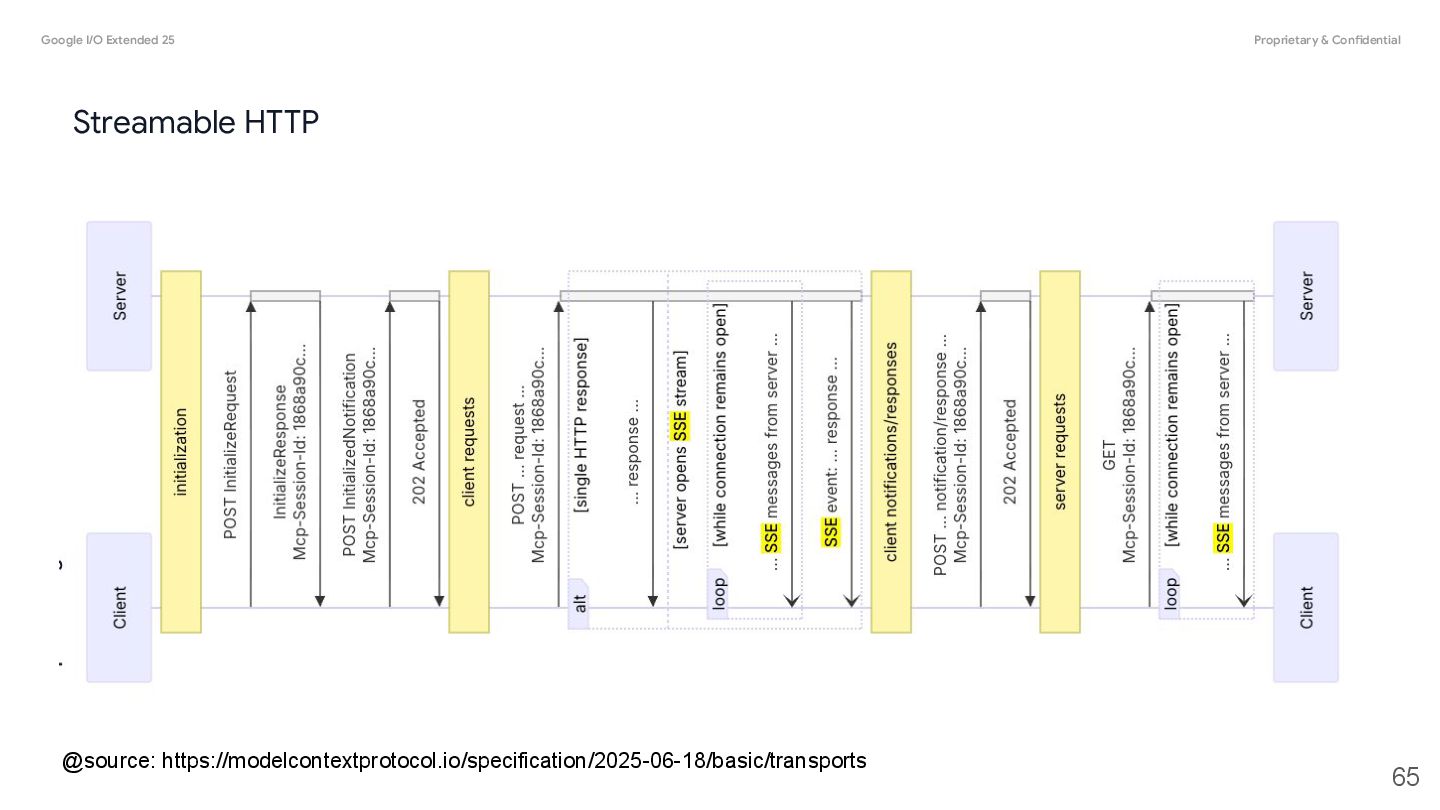
JSON-RPC to encode messages. JSON-RPC messages MUST be UTF-8 encoded. The protocol currently defines two standard transport mechanisms for client-server communication: 1. stdio, communication over standard in and standard out 2. Streamable HTTP 3. SSE (Deprecated) MCP Transports https://modelcontextprotocol.io/specification/2025-06-18/basic/transports
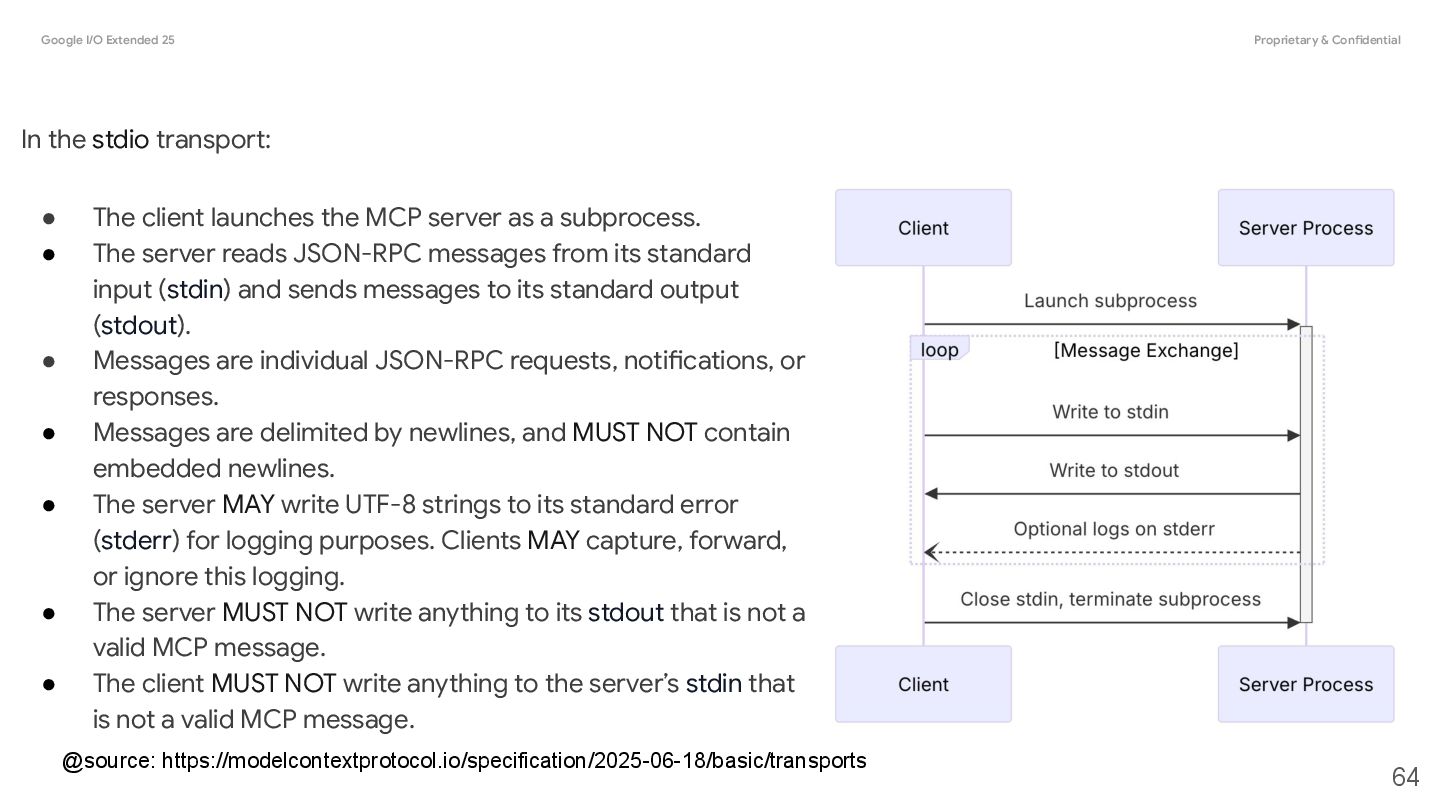
stdio transport: • The client launches the MCP server as a subprocess. • The server reads JSON-RPC messages from its standard input (stdin) and sends messages to its standard output (stdout). • Messages are individual JSON-RPC requests, notifications, or responses. • Messages are delimited by newlines, and MUST NOT contain embedded newlines. • The server MAY write UTF-8 strings to its standard error (stderr) for logging purposes. Clients MAY capture, forward, or ignore this logging. • The server MUST NOT write anything to its stdout that is not a valid MCP message. • The client MUST NOT write anything to the server’s stdin that is not a valid MCP message. @source: https://modelcontextprotocol.io/specification/2025-06-18/basic/transports
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def set_light_values(brightness: int, color_temp: str) -> dict[str, int | str]:](https://files.speakerdeck.com/presentations/b2a667faaa694d96a50a332c92e0b2d3/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![45 /Users/[UserName]/.gemini /Users/[UserName]/.gemini/settings.json](https://files.speakerdeck.com/presentations/b2a667faaa694d96a50a332c92e0b2d3/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![const serverCommand = 'dart'; const serverArgs = <String>['run', 'example/server_stdio.dart']; final](https://files.speakerdeck.com/presentations/b2a667faaa694d96a50a332c92e0b2d3/slide_71.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
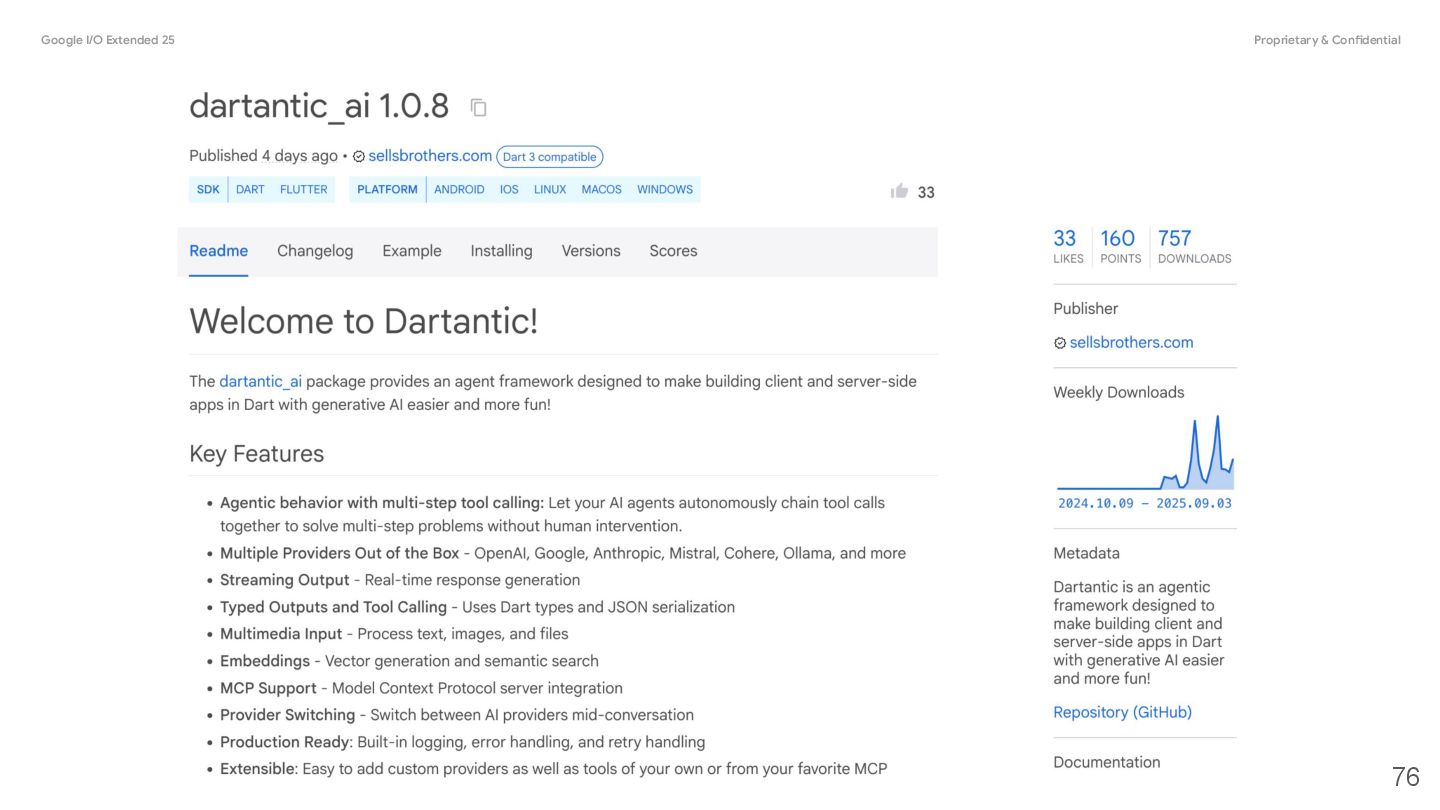{kind=link}
![final calculator = McpClient.local( 'calculator', command: 'npx', args: ['-y', '@modelcontextprotocol/server-calculator'],](https://files.speakerdeck.com/presentations/b2a667faaa694d96a50a332c92e0b2d3/slide_76.jpg){kind=link}
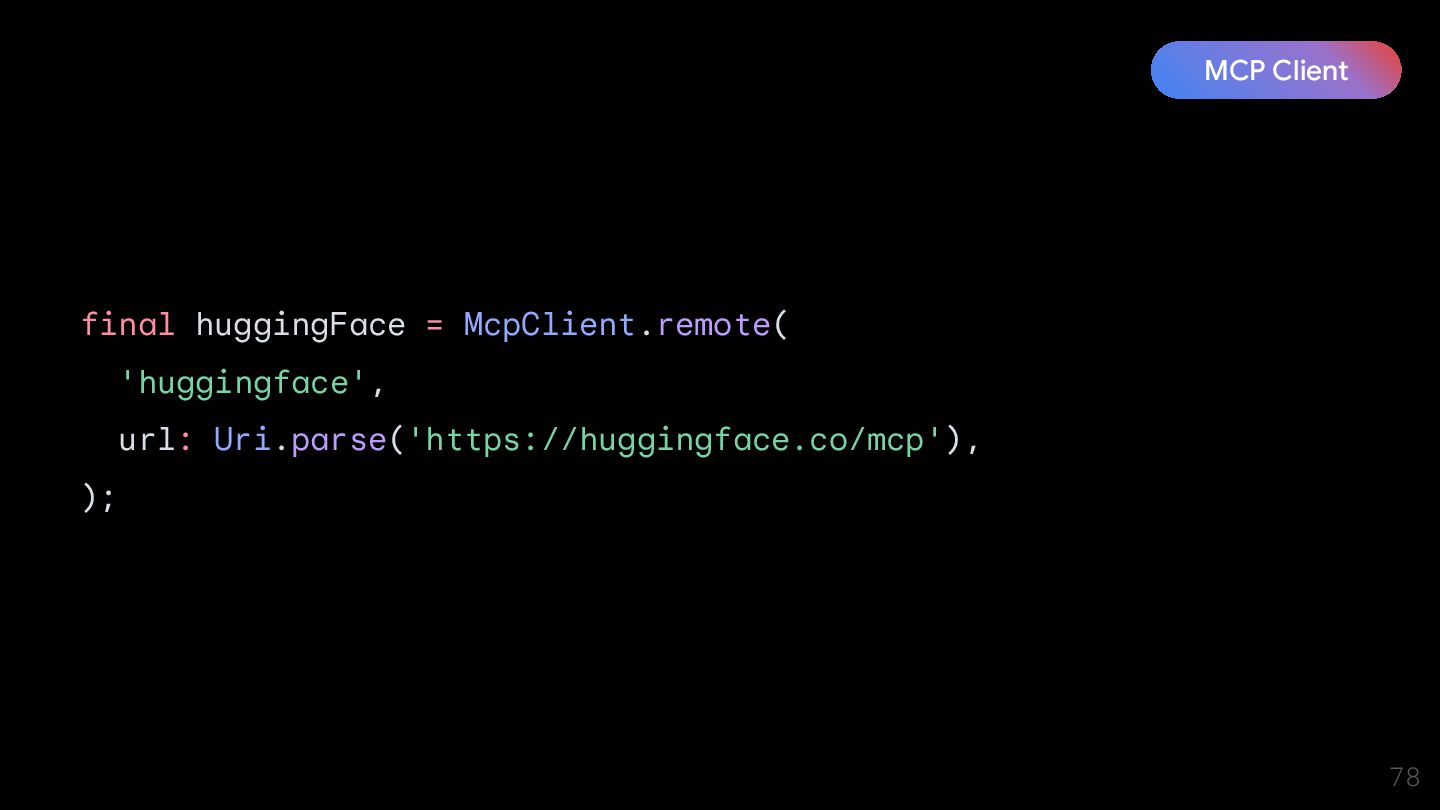{kind=link}
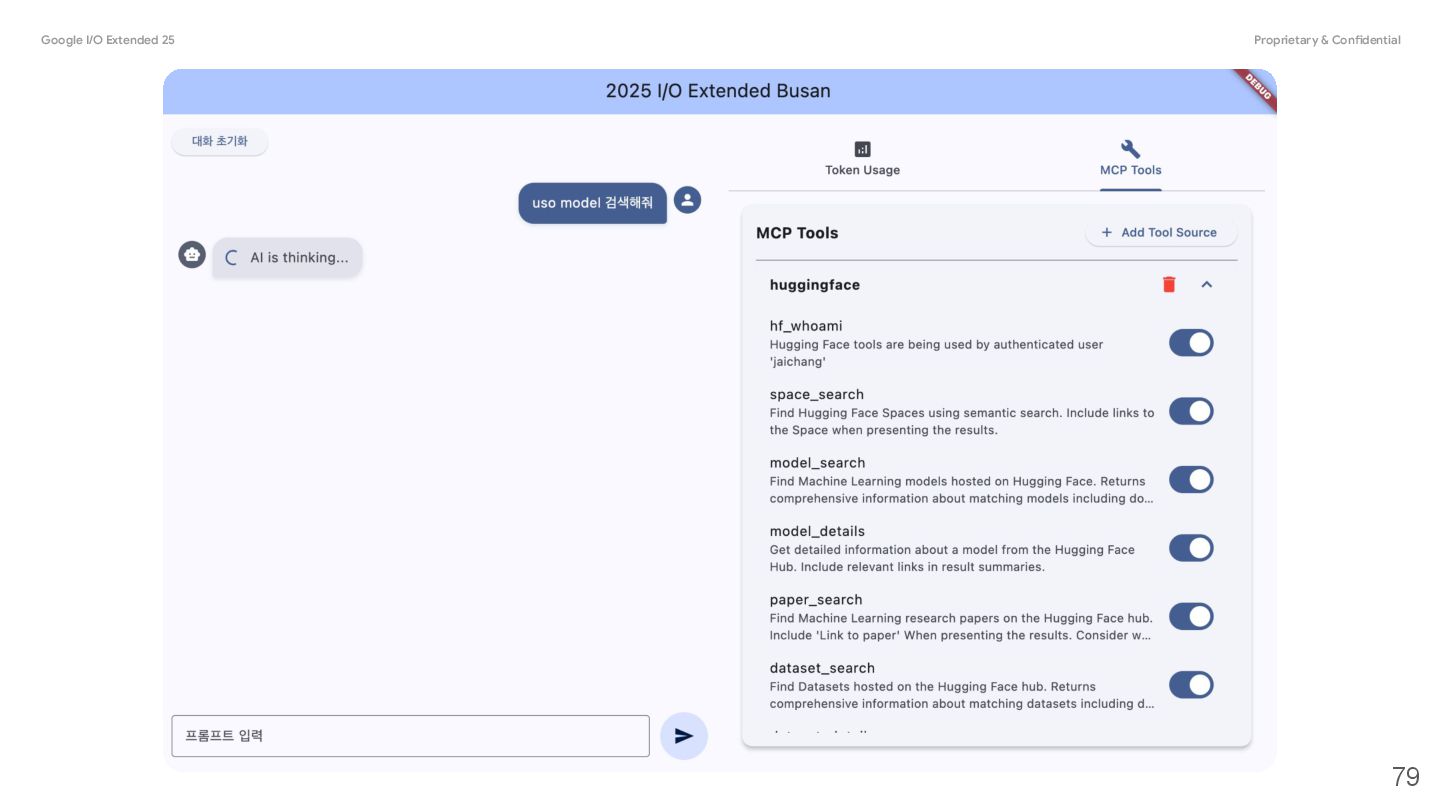{kind=link}
{kind=link}