Share
YAPC::2025 Fukuoka登壇資料 https://fortee.jp/yapc-fukuoka-2025/proposal/c76c16a2-057e-4190-923f-0f4e404f79c7
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
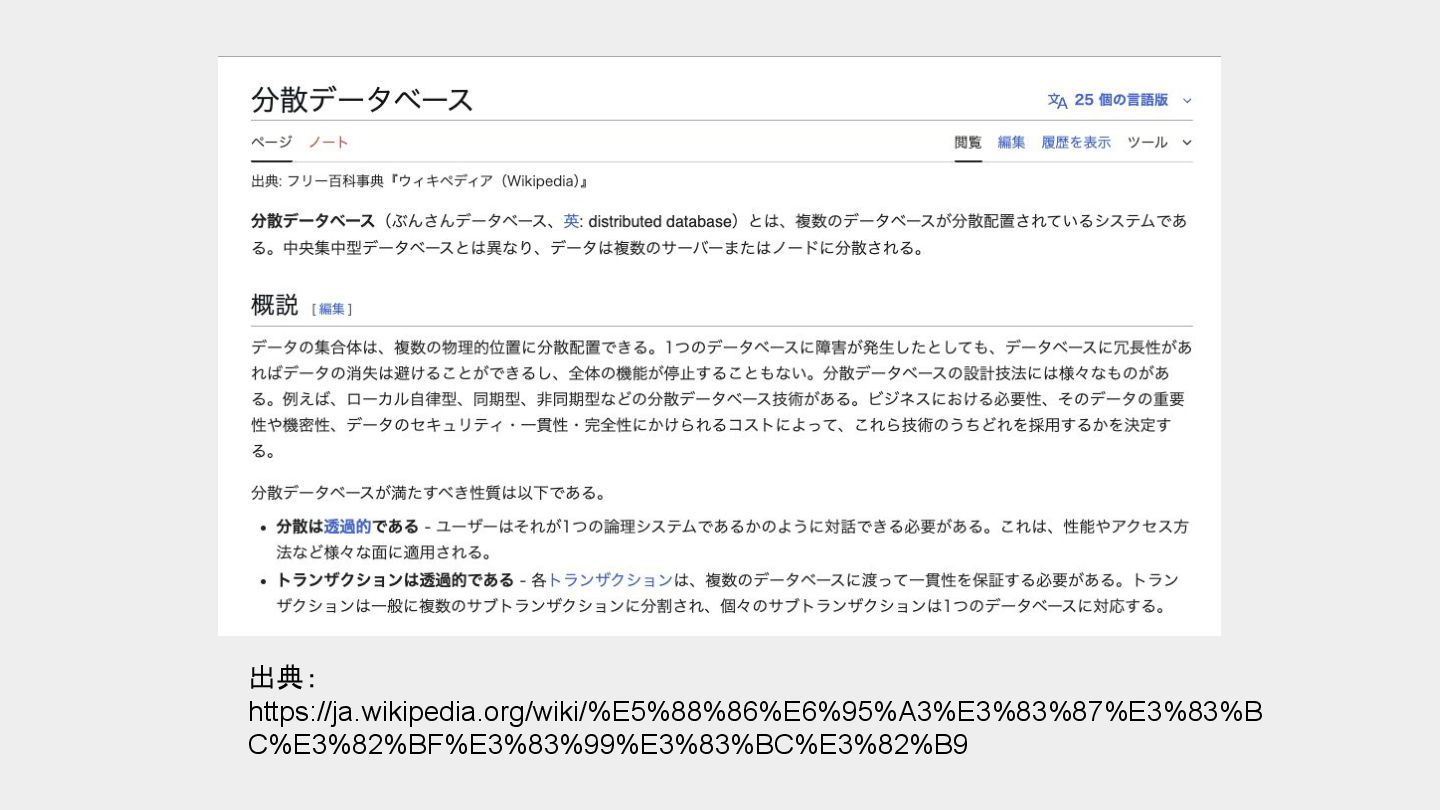{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
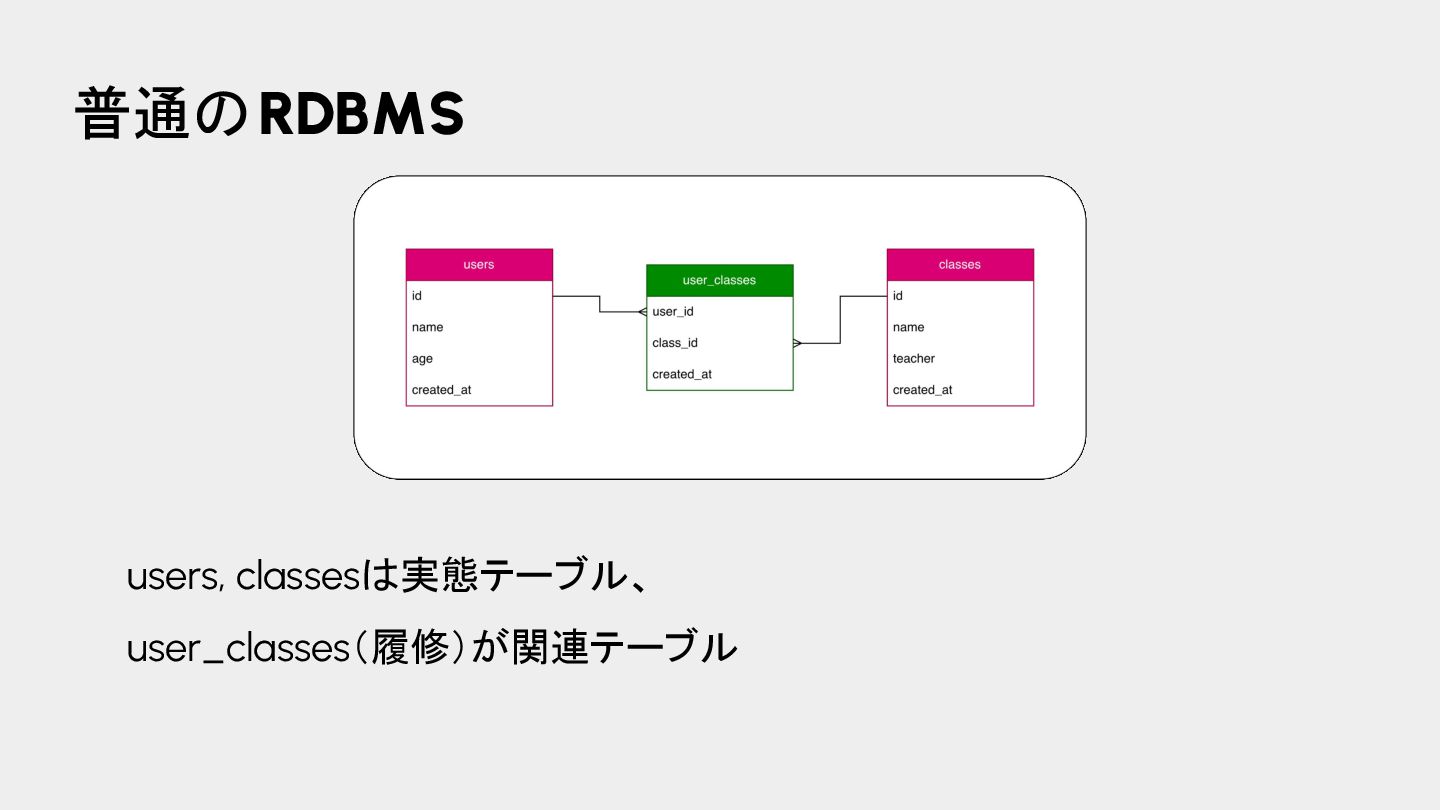{kind=link}
{kind=link}
{kind=link}
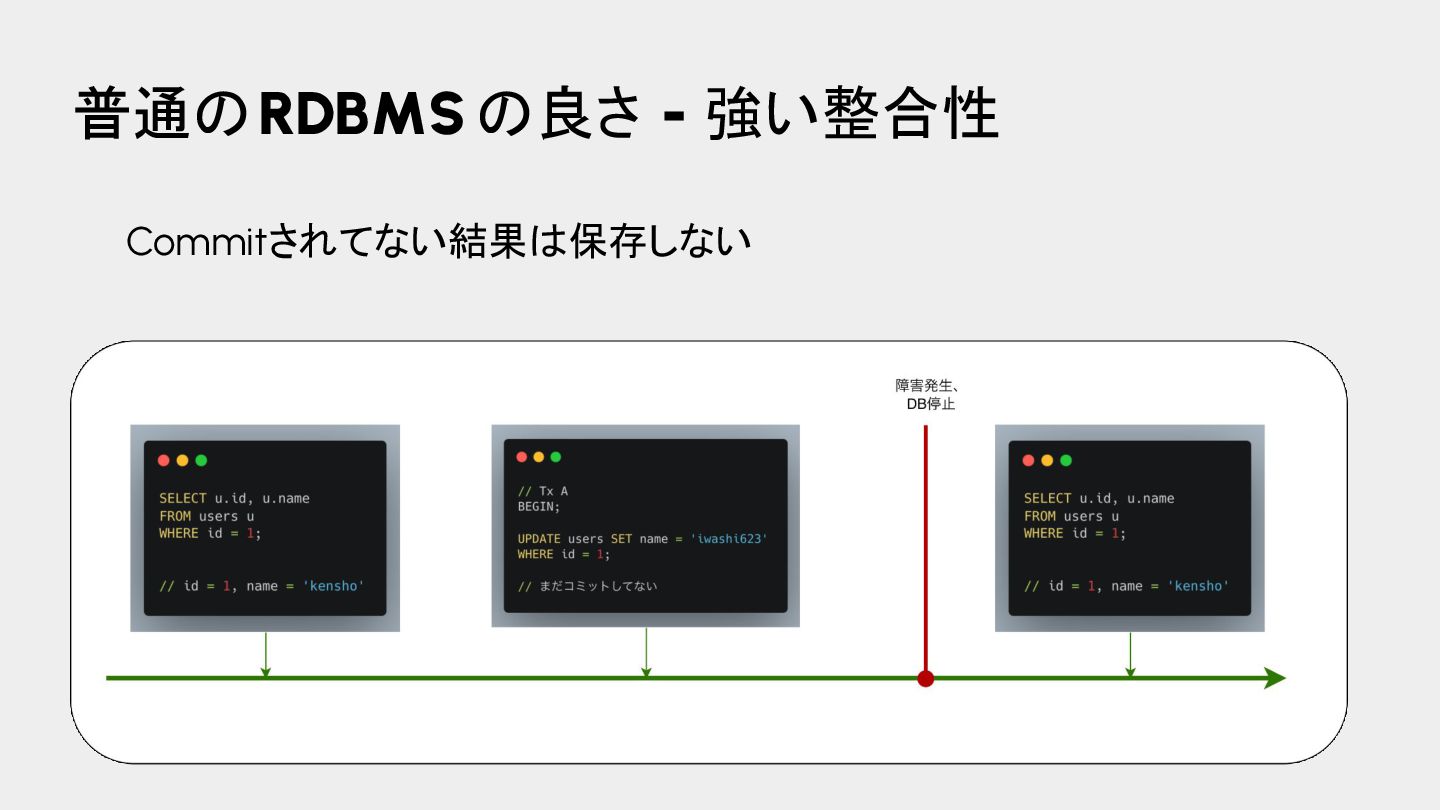{kind=link}
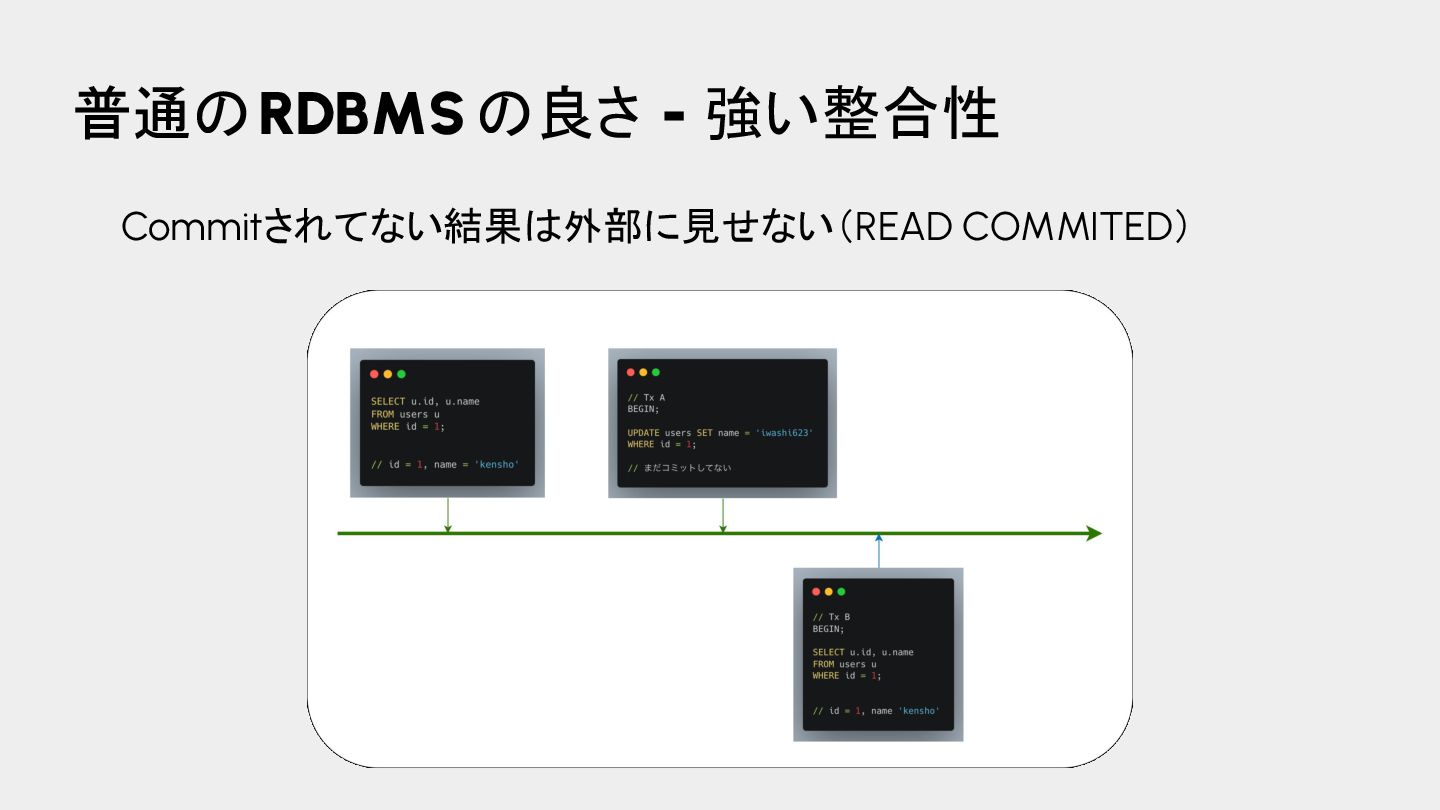{kind=link}
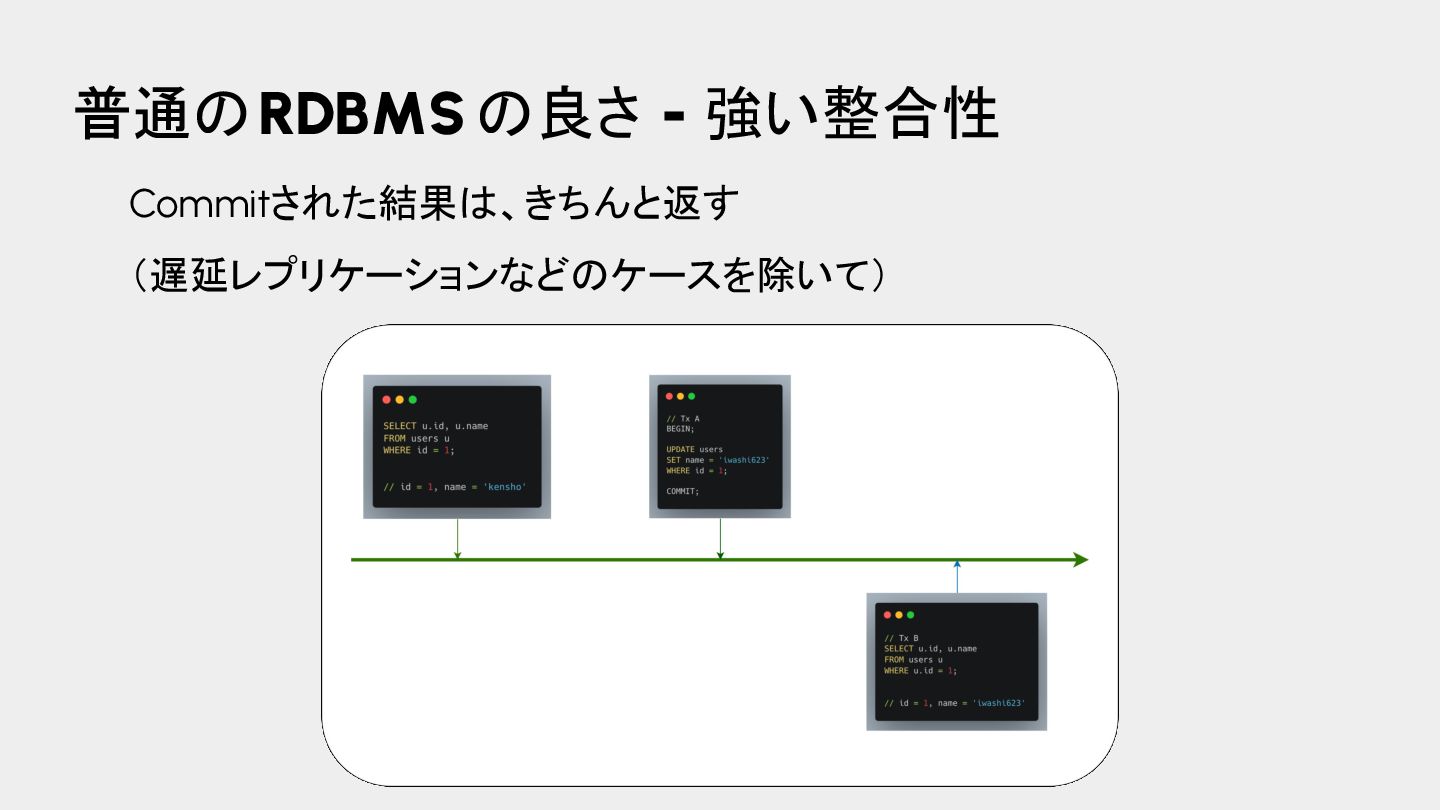{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
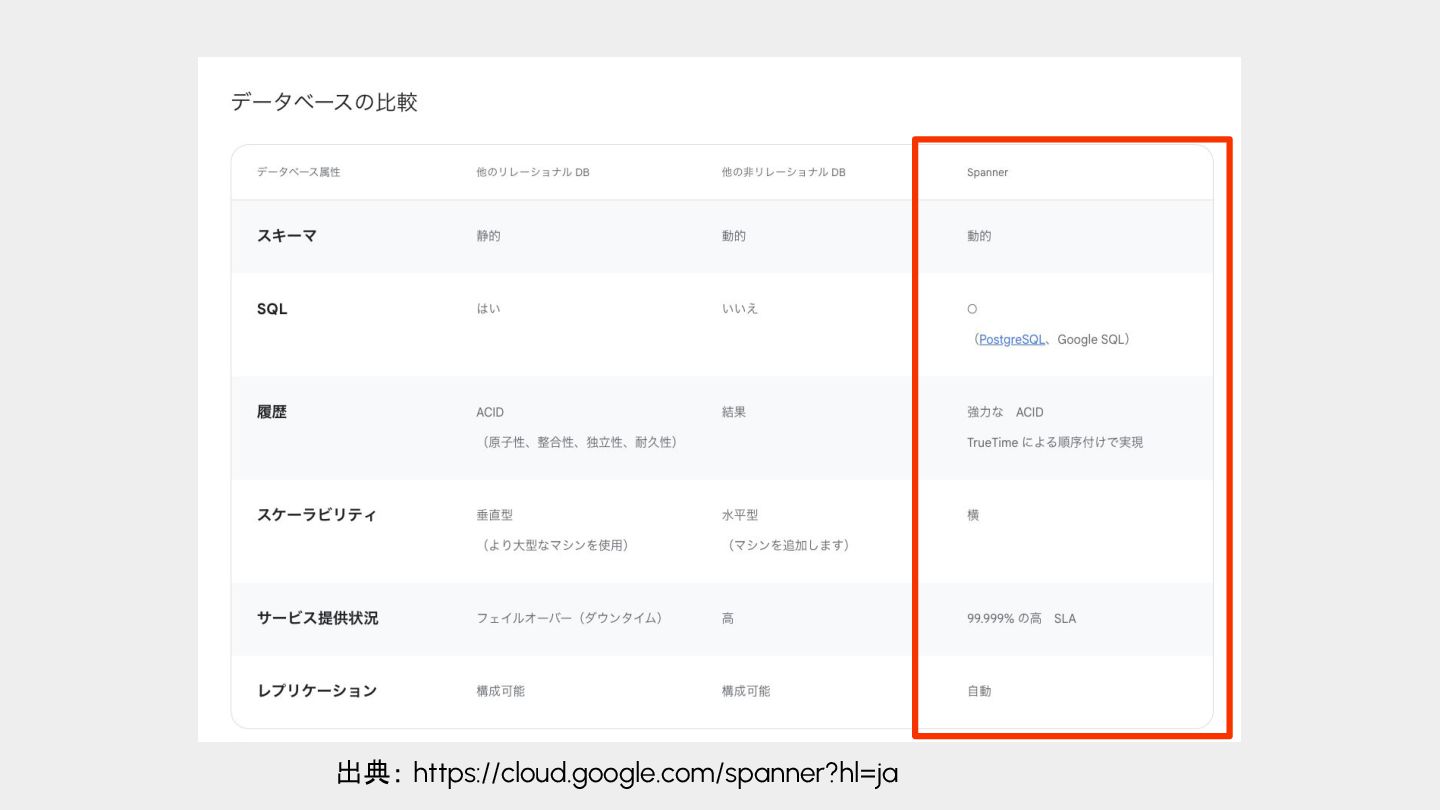{kind=link}
{kind=link}
![TrueTime APIは、 “誤差つきの時刻”を返す分散時計API(Googleの社内インフラ)。 実現にGPS受信機や原子時計を使っていることで話題。 TT.now() → [earliest, latest] 現在時刻は、earliestとlatestのどこかであることを明示する。 例:TT.now()](https://files.speakerdeck.com/presentations/ab1691bdde3c4156b9d338ca532c40da/slide_51.jpg){kind=link}
![TrueTime APIは、 “誤差つきの時刻”を返す分散時計API(Googleの社内インフラ)。 実現にGPS受信機や原子時計を使っていることで話題。 TT.now() → [earliest, latest] 現在時刻は、earliestとlatestのどこかであることを明示する。 例:TT.now()](https://files.speakerdeck.com/presentations/ab1691bdde3c4156b9d338ca532c40da/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
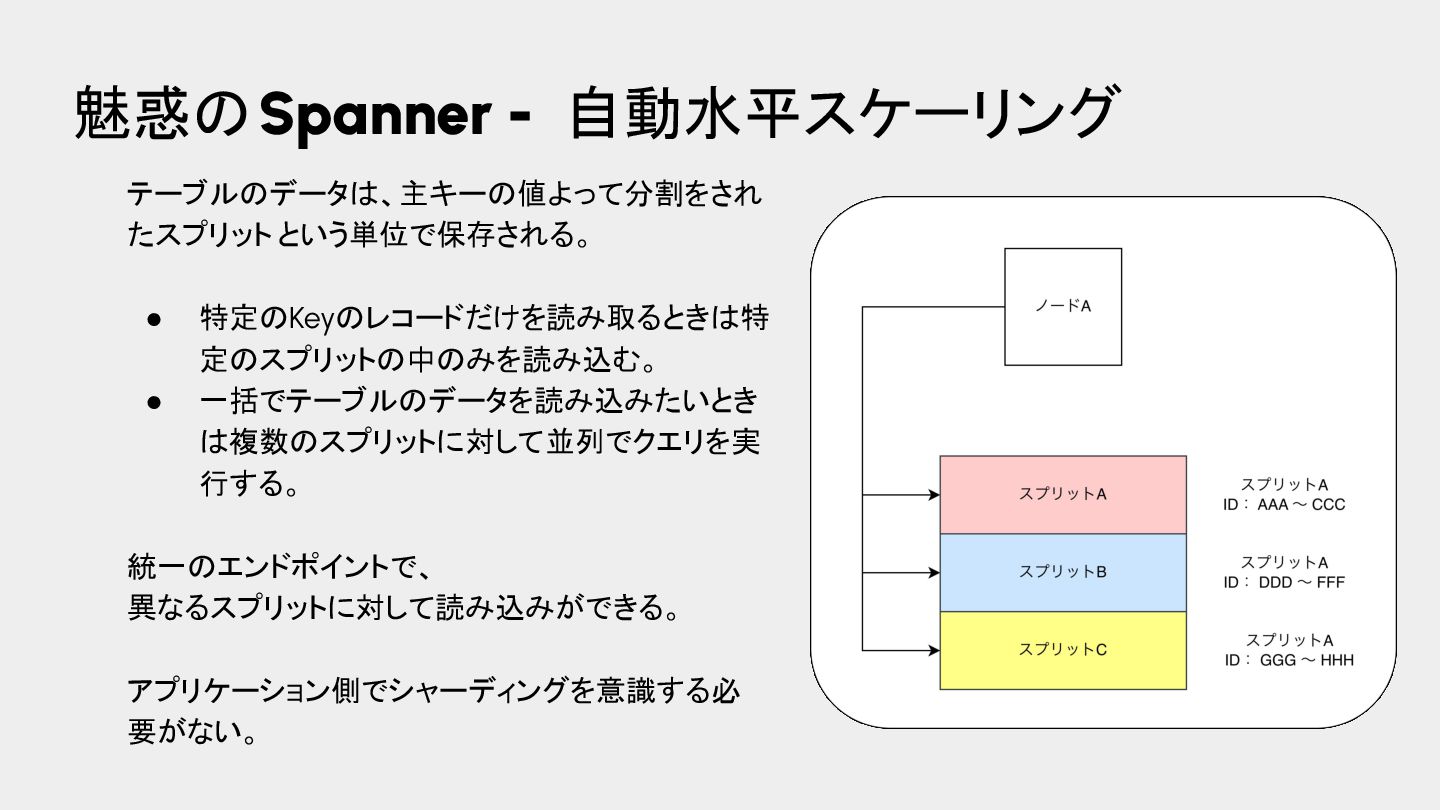{kind=link}
{kind=link}
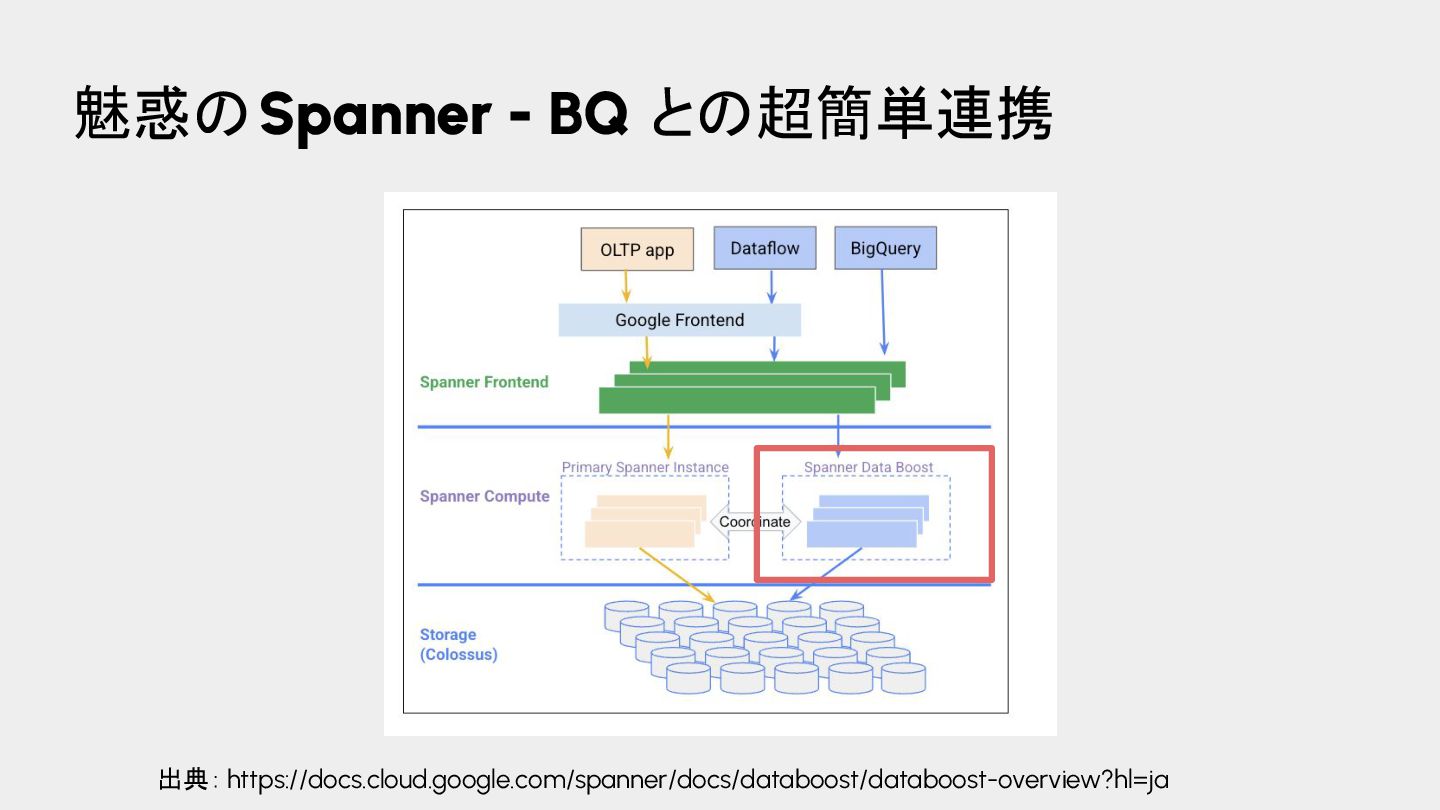{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
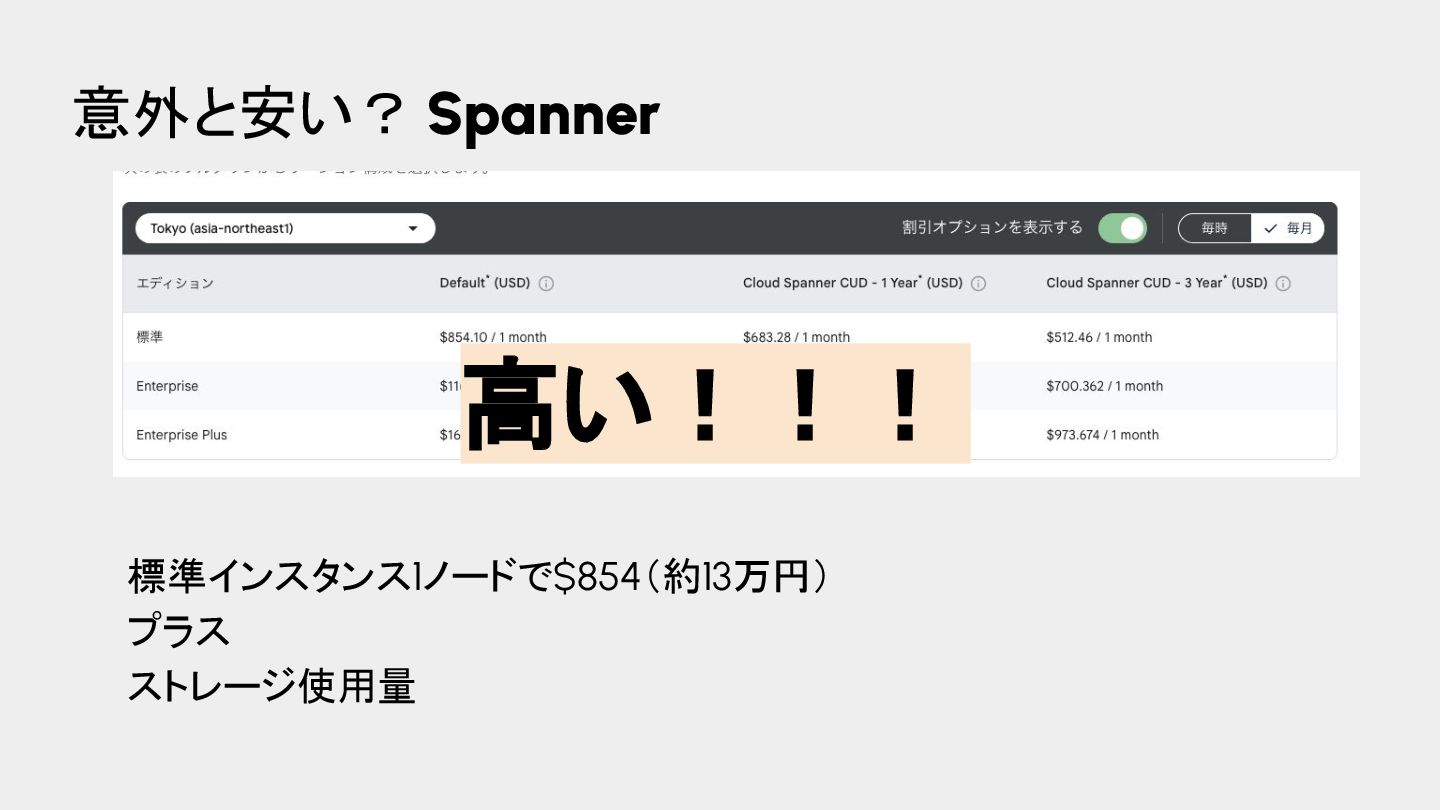{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}