Share
2024年4月に使用した、LLM超入門スライドの一部です。 LLM(大規模言語モデル)の基本について、入門者や非エンジニアの企業担当者様向けに可能な限りわかりやすくまとめてみました。
会社HP: https://www.izai.co.jp/
Googleスライド: https://docs.google.com/presentation/d/1lBdafqecUmsEwRInK4v5-8nZa9n6DjdO/edit?usp=sharing&ouid=100664251827640690524&rtpof=true&sd=true
{kind=link}
{kind=link}
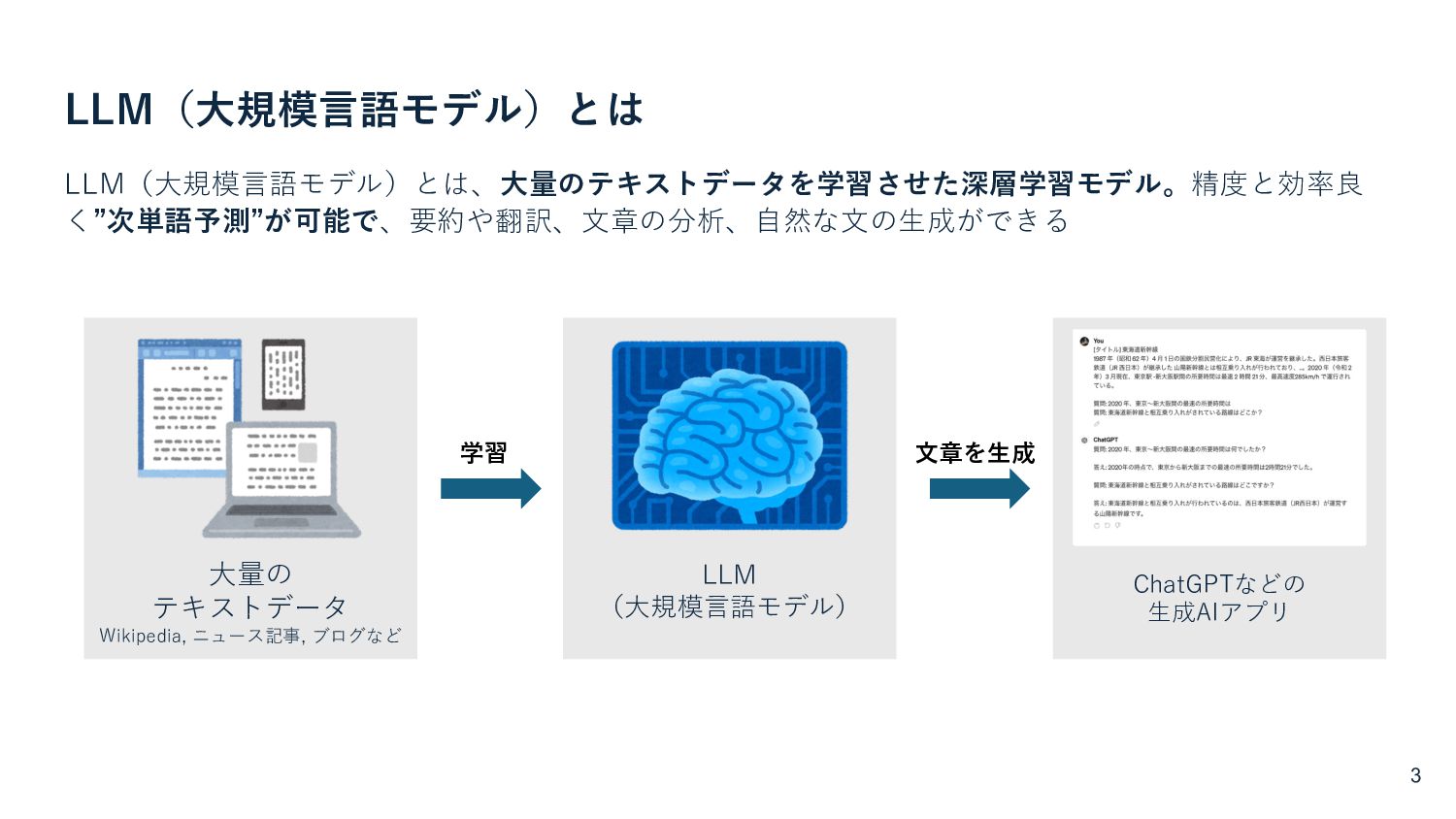{kind=link}
{kind=link}
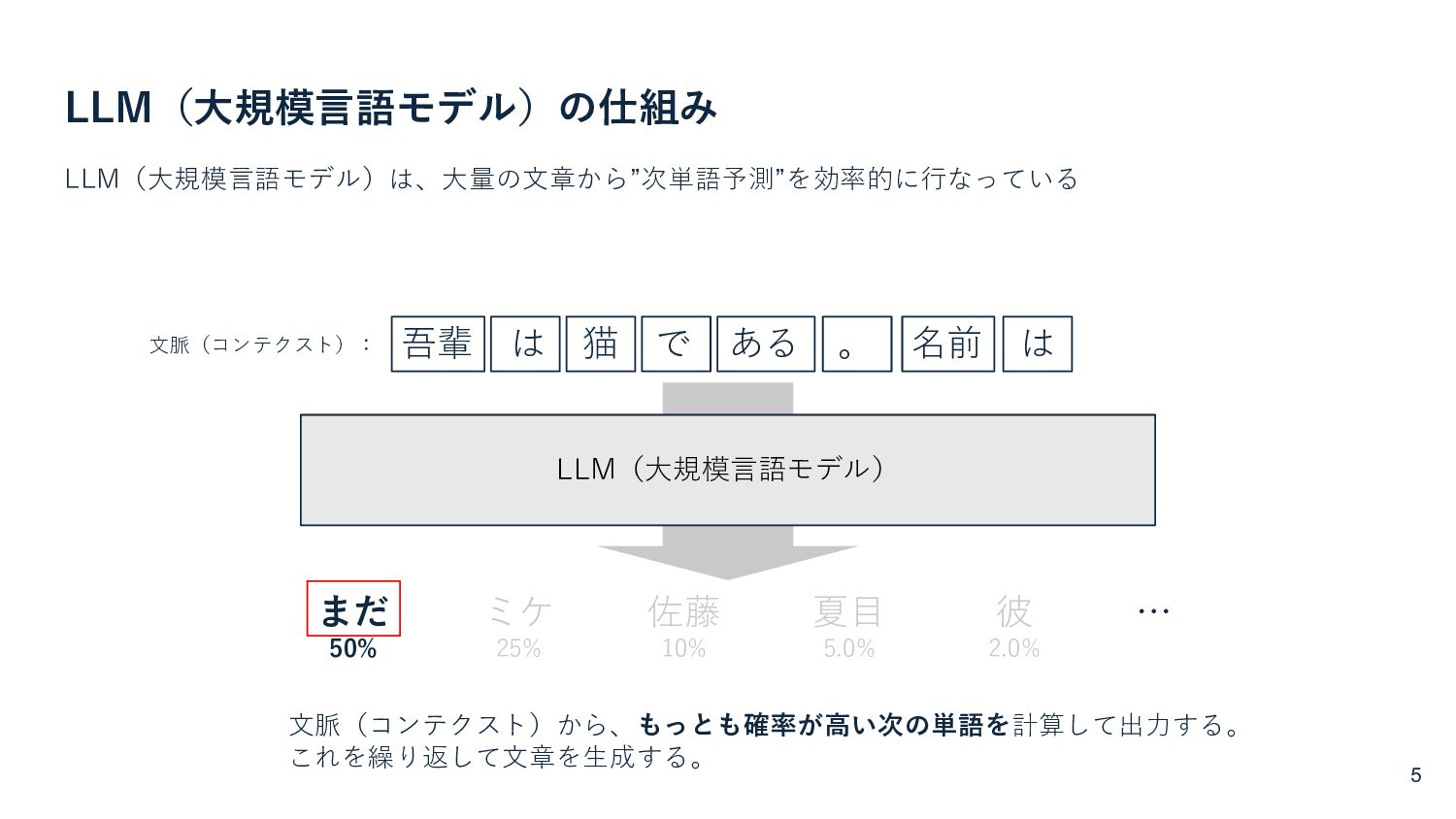{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
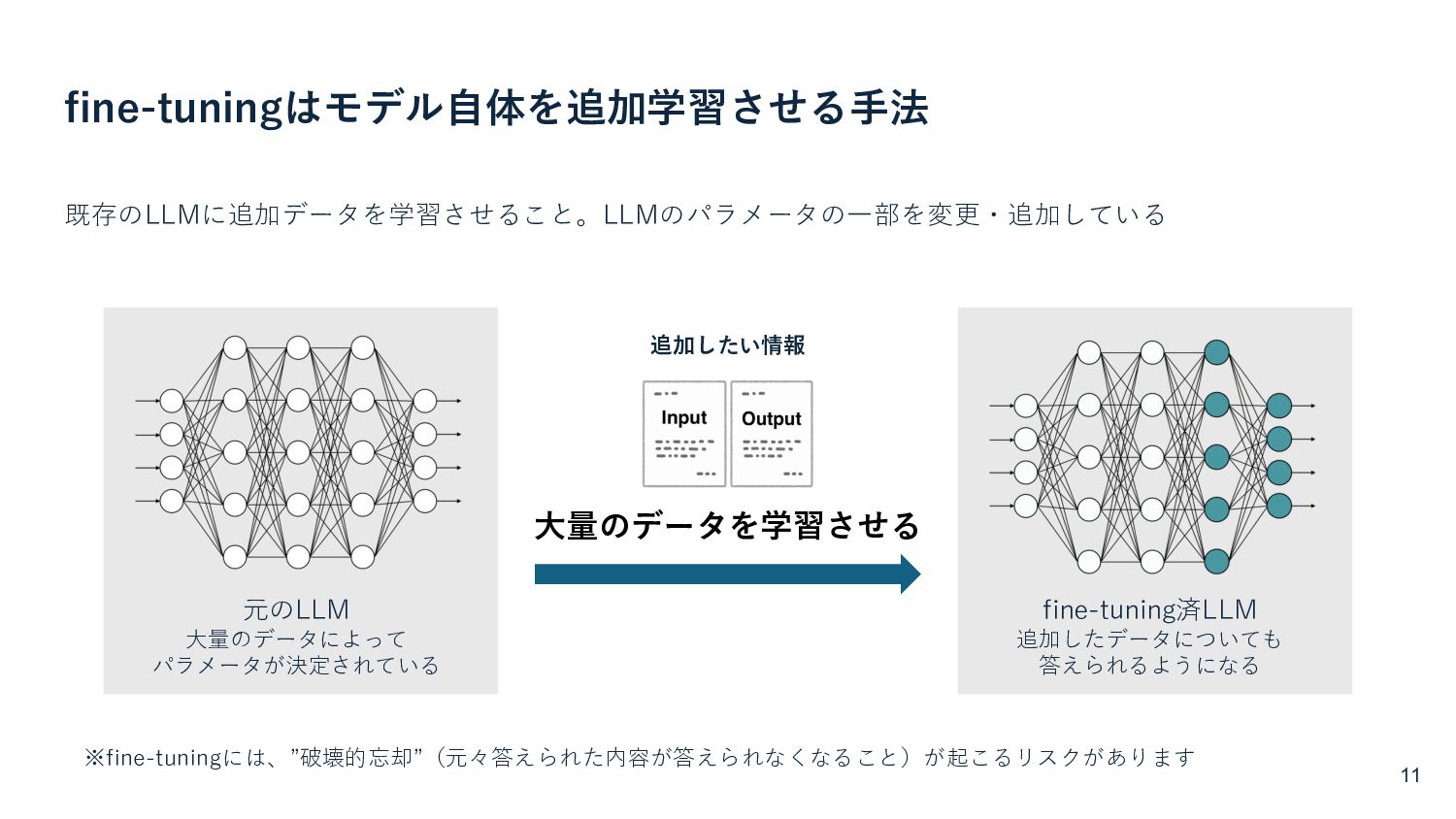{kind=link}
{kind=link}
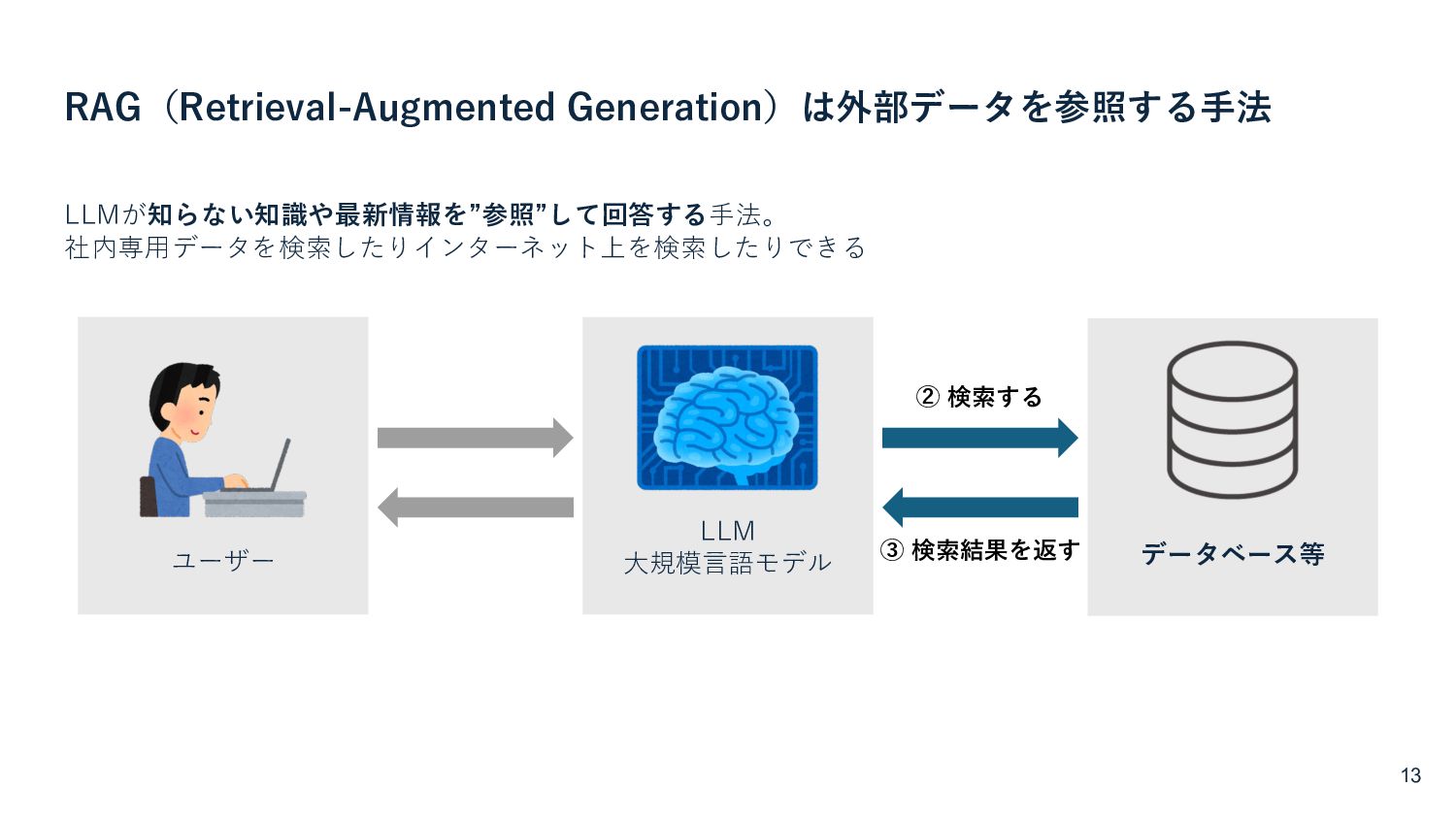{kind=link}
{kind=link}
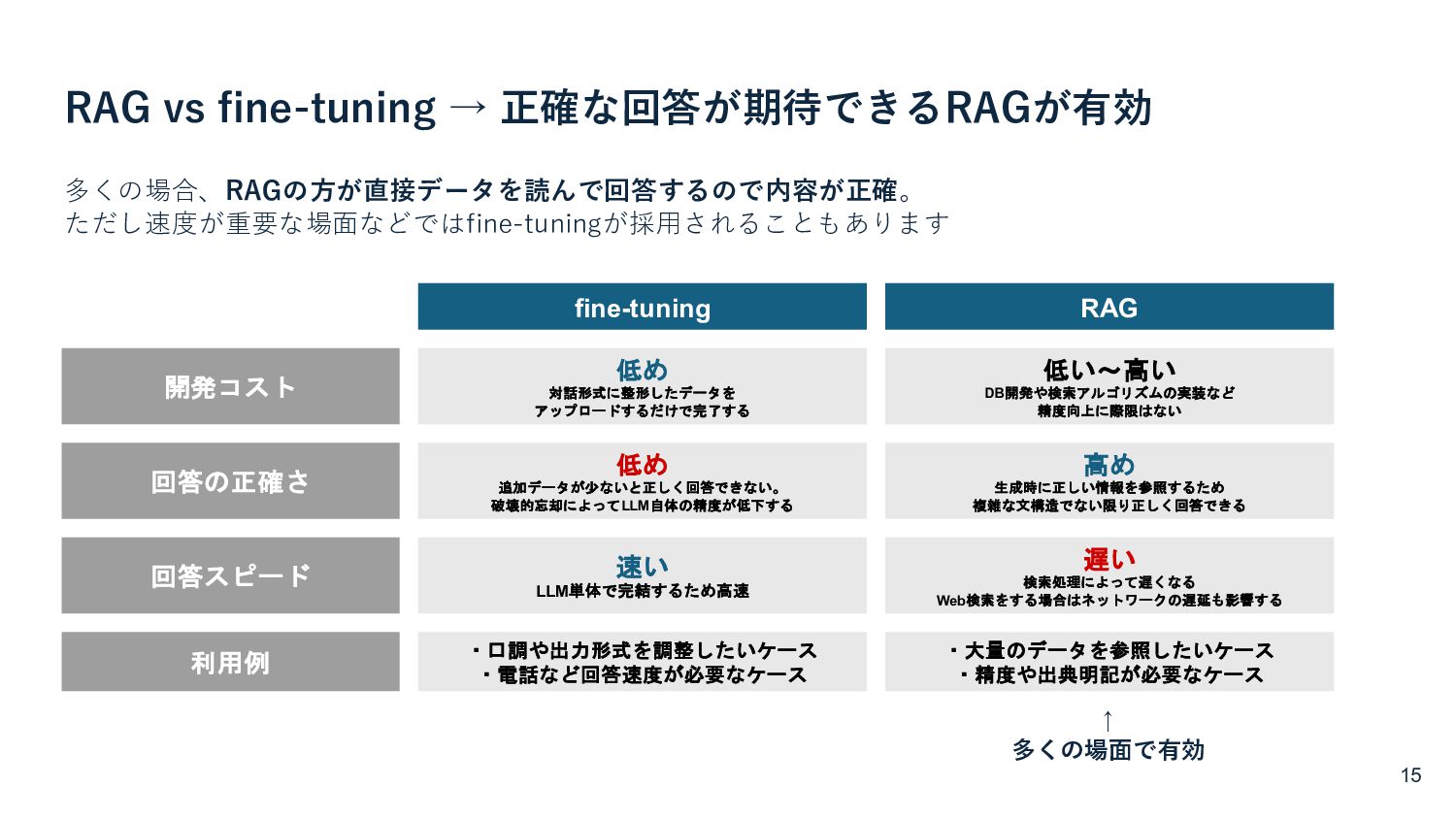{kind=link}
![まとめ LLMに社内データを回答させるにはRAGが有効 次回は RAG について、詳しく解説します 本スライドについてのお問い合わせはこちら: [email protected] 16](https://files.speakerdeck.com/presentations/7ecdeb49d24a47e2bd98b53b485f2ecf/slide_15.jpg){kind=link}