Guest lecture for "Deep Learning and Natural Language Processing" at Humboldt University Berlin.
https://colab.research.google.com/drive/1STomYwvU2Jbn1kLbwLw1YxUjZo8U9gx4
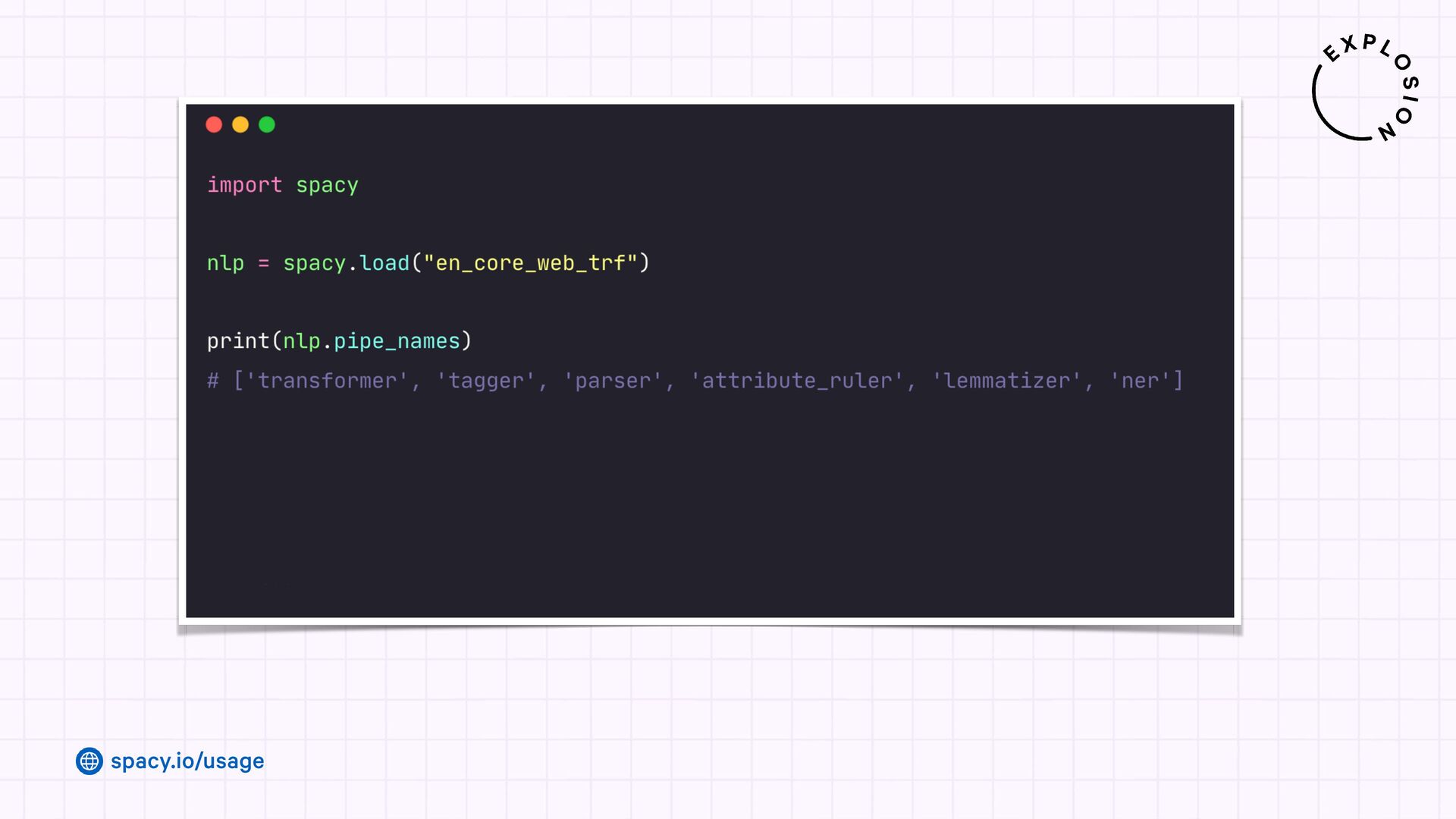
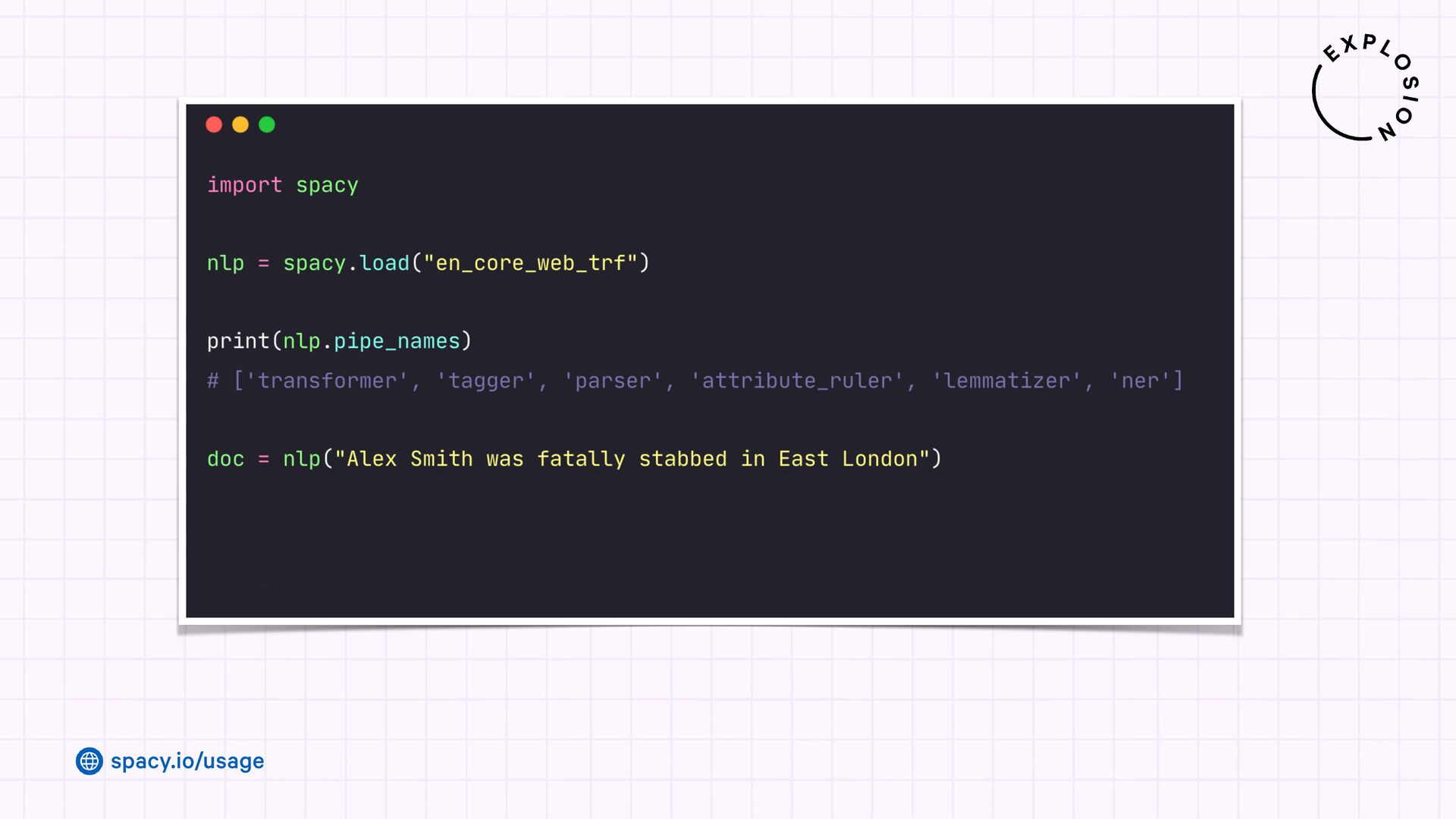
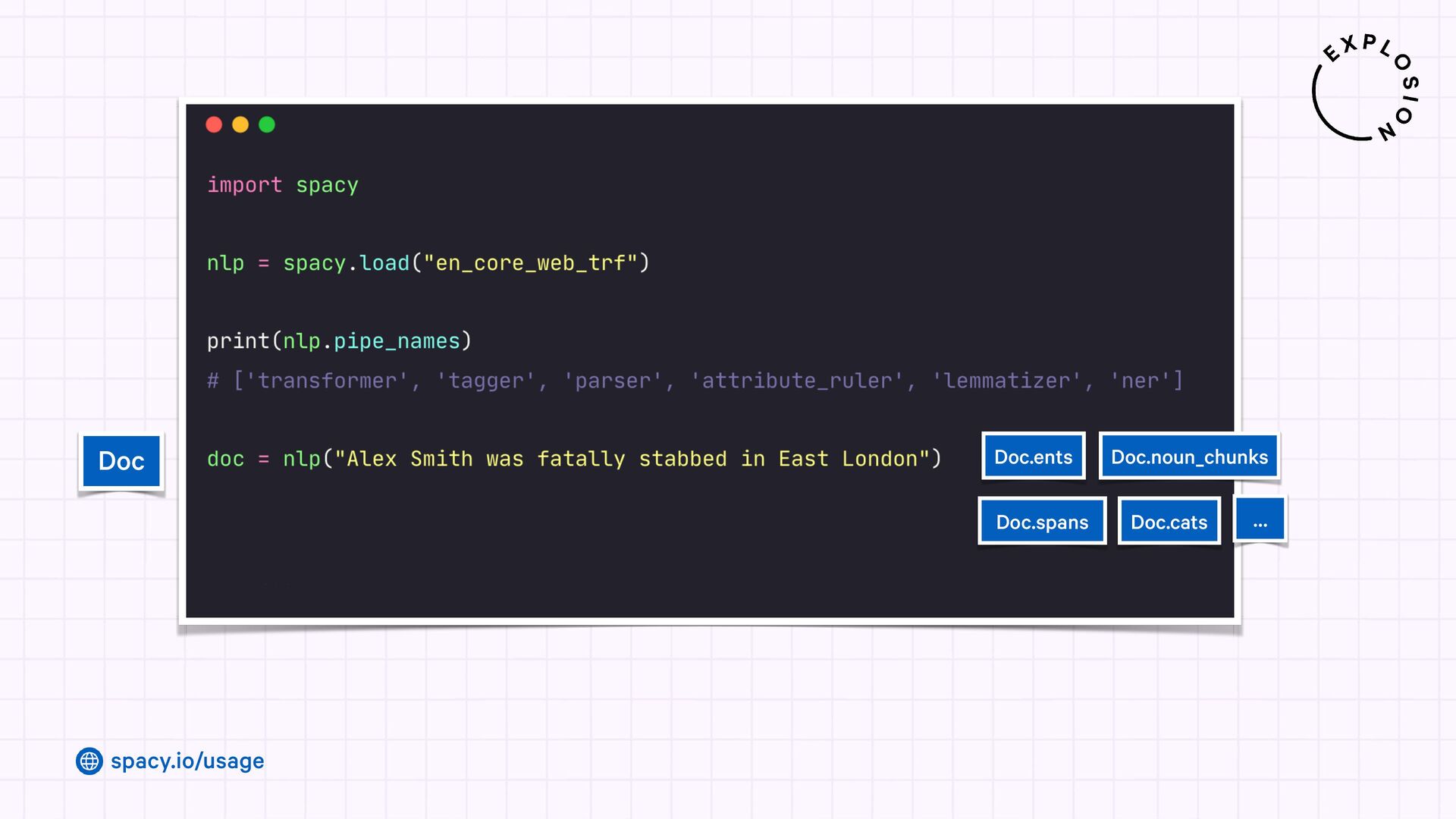
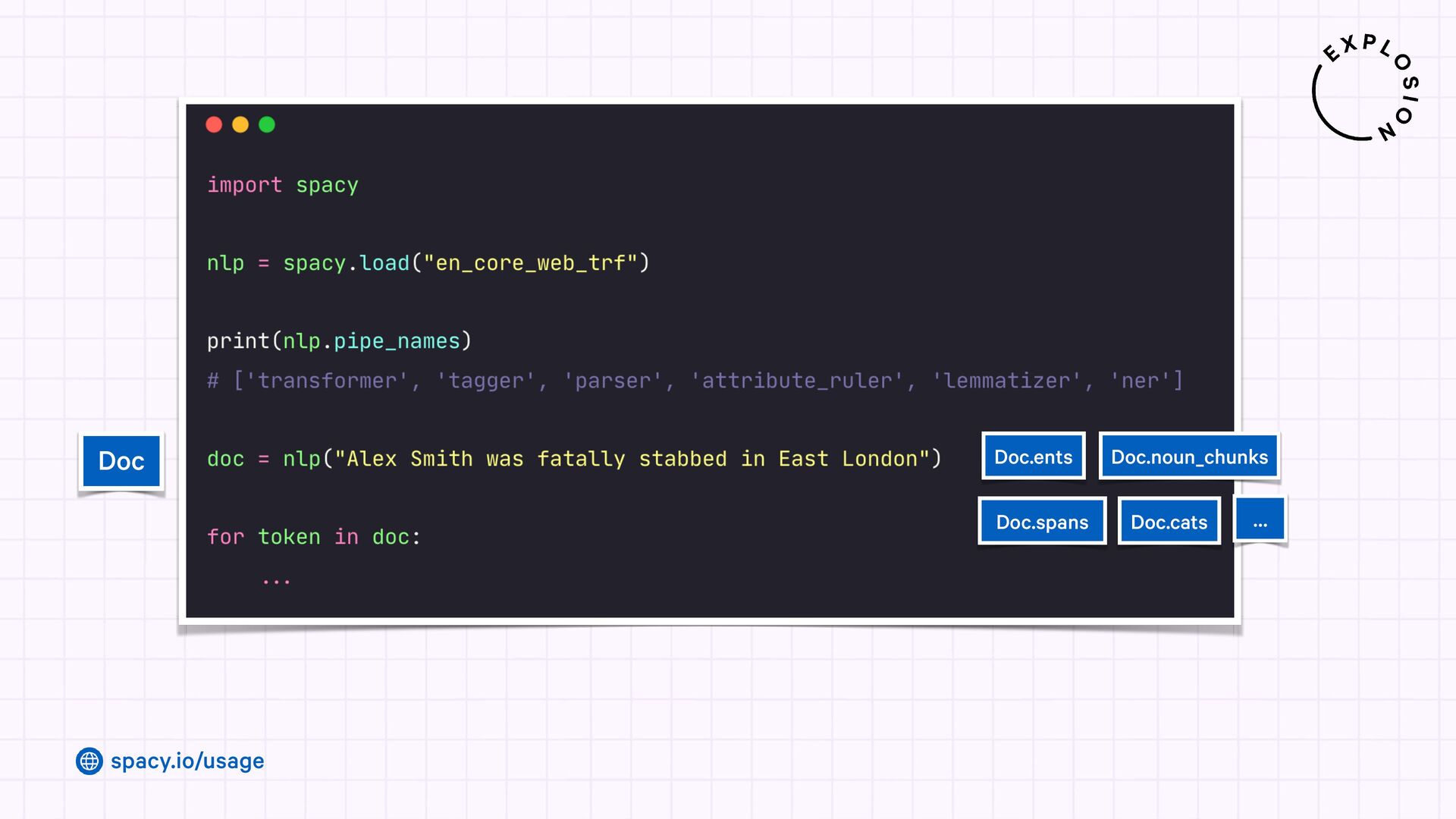
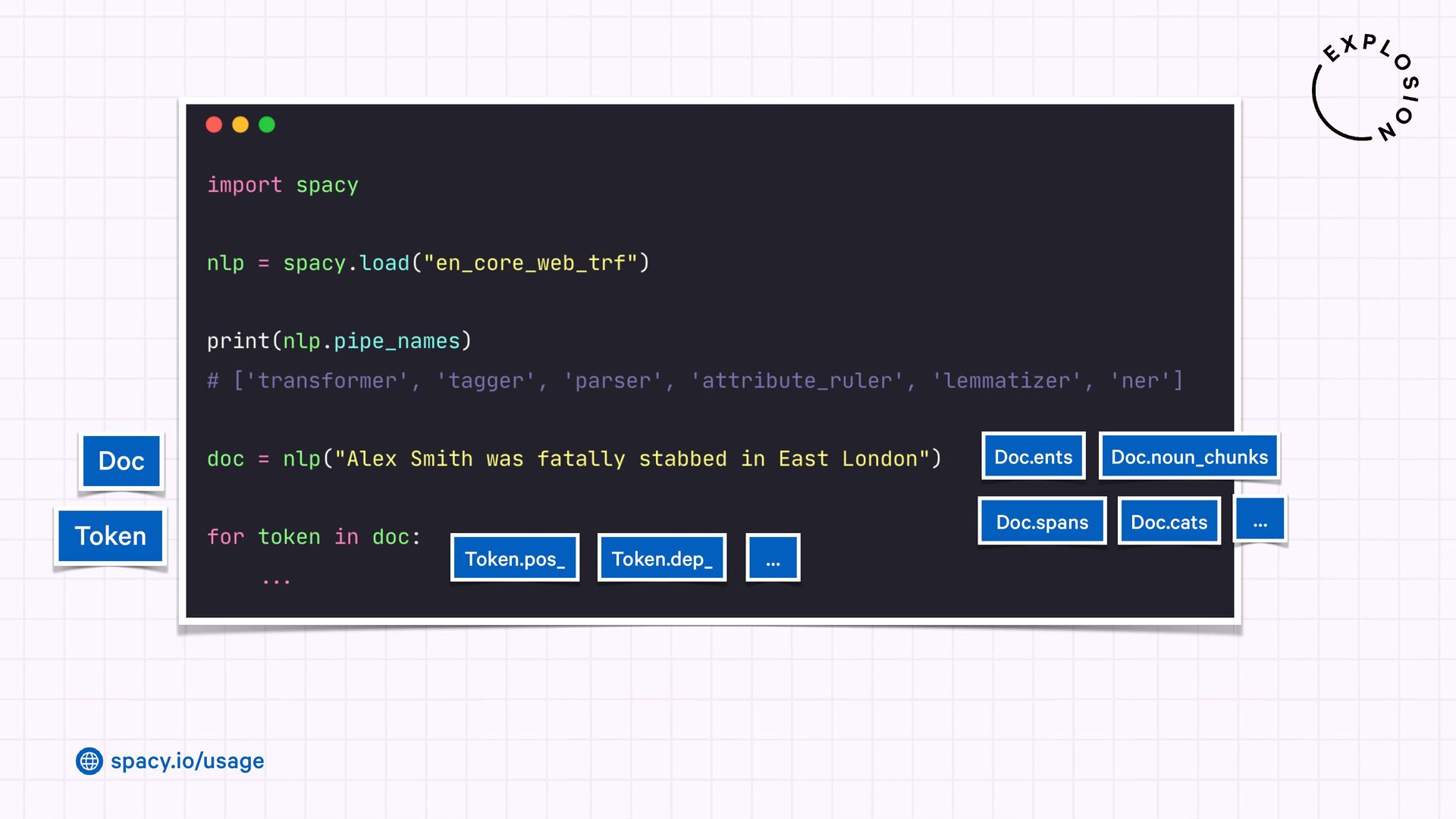
Jupyter Notebook with an overview of spaCy's linguistic features and usage examples.
Open-source library for industrial-strength Natural Language Processing and building fast and efficient information extraction pipelines using custom models, LLMs and rule-based approaches.
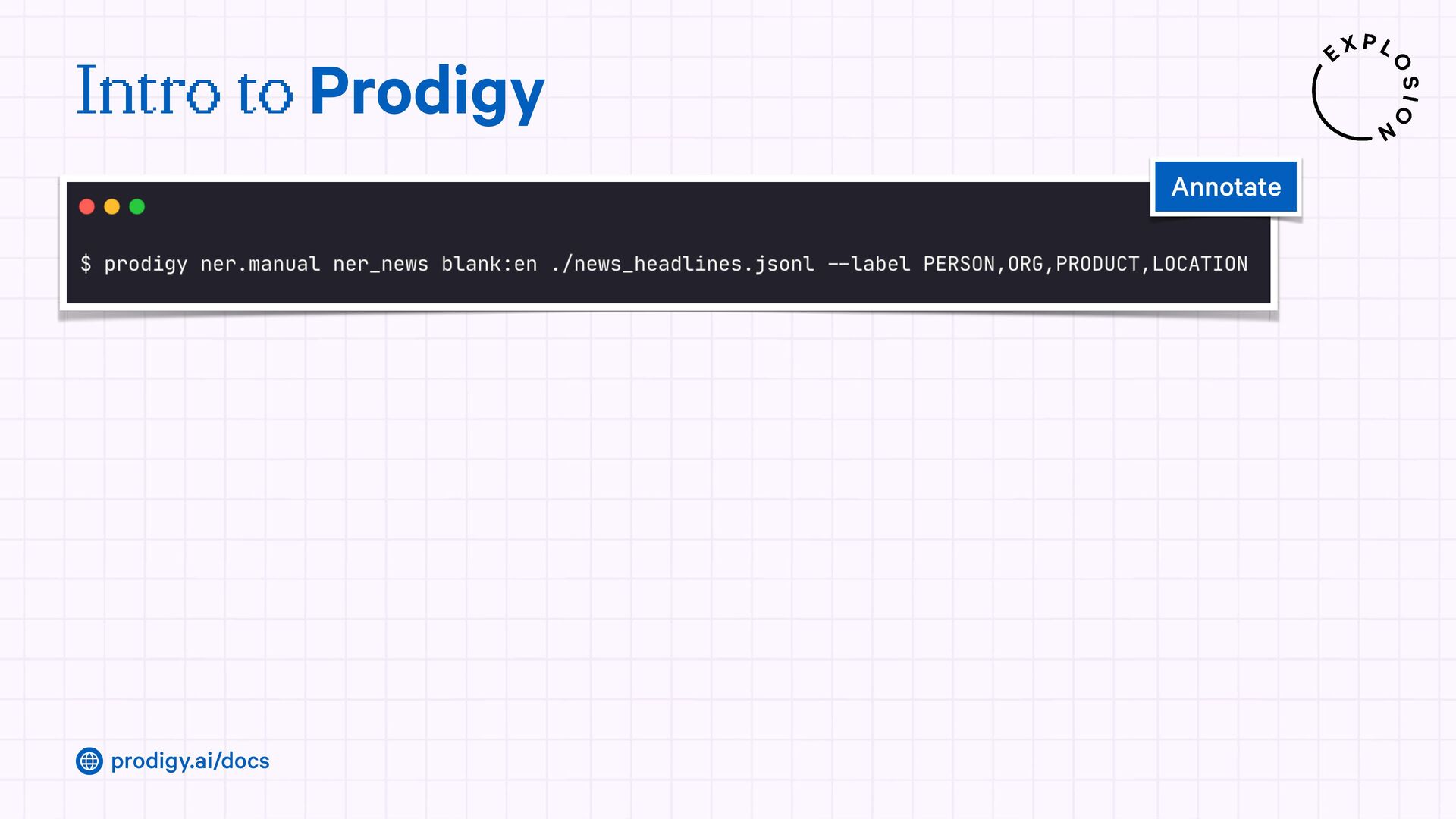
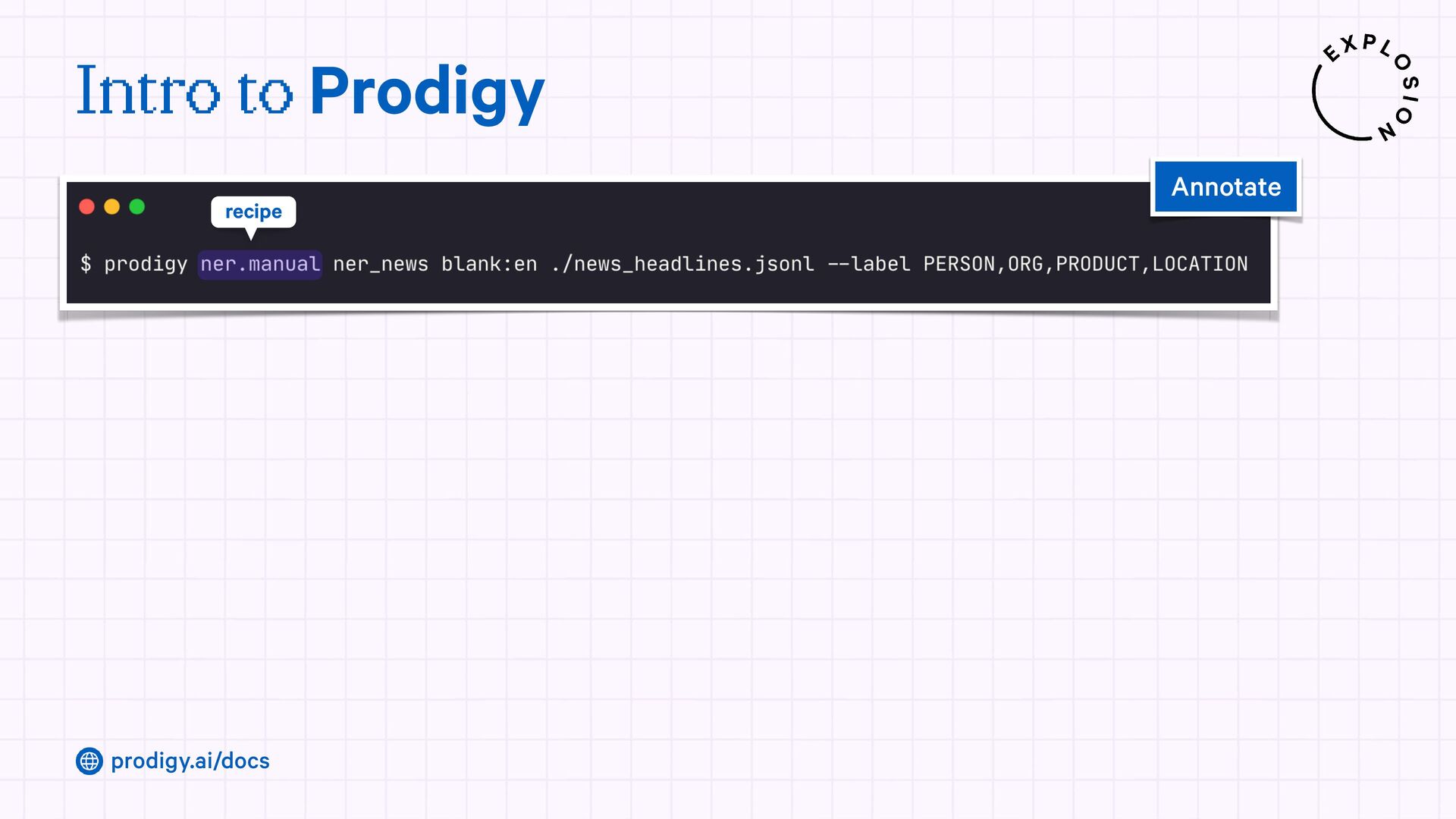
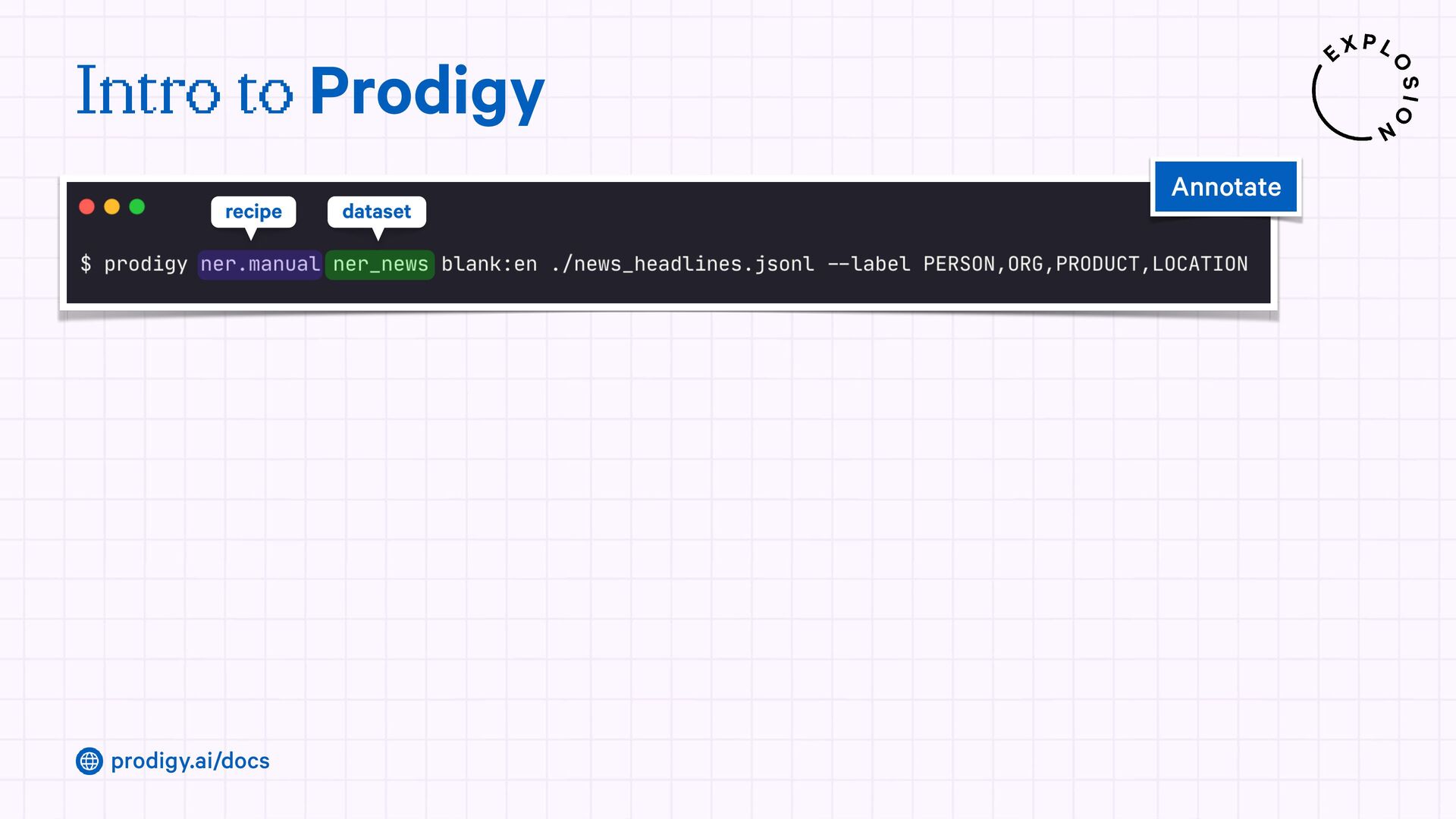
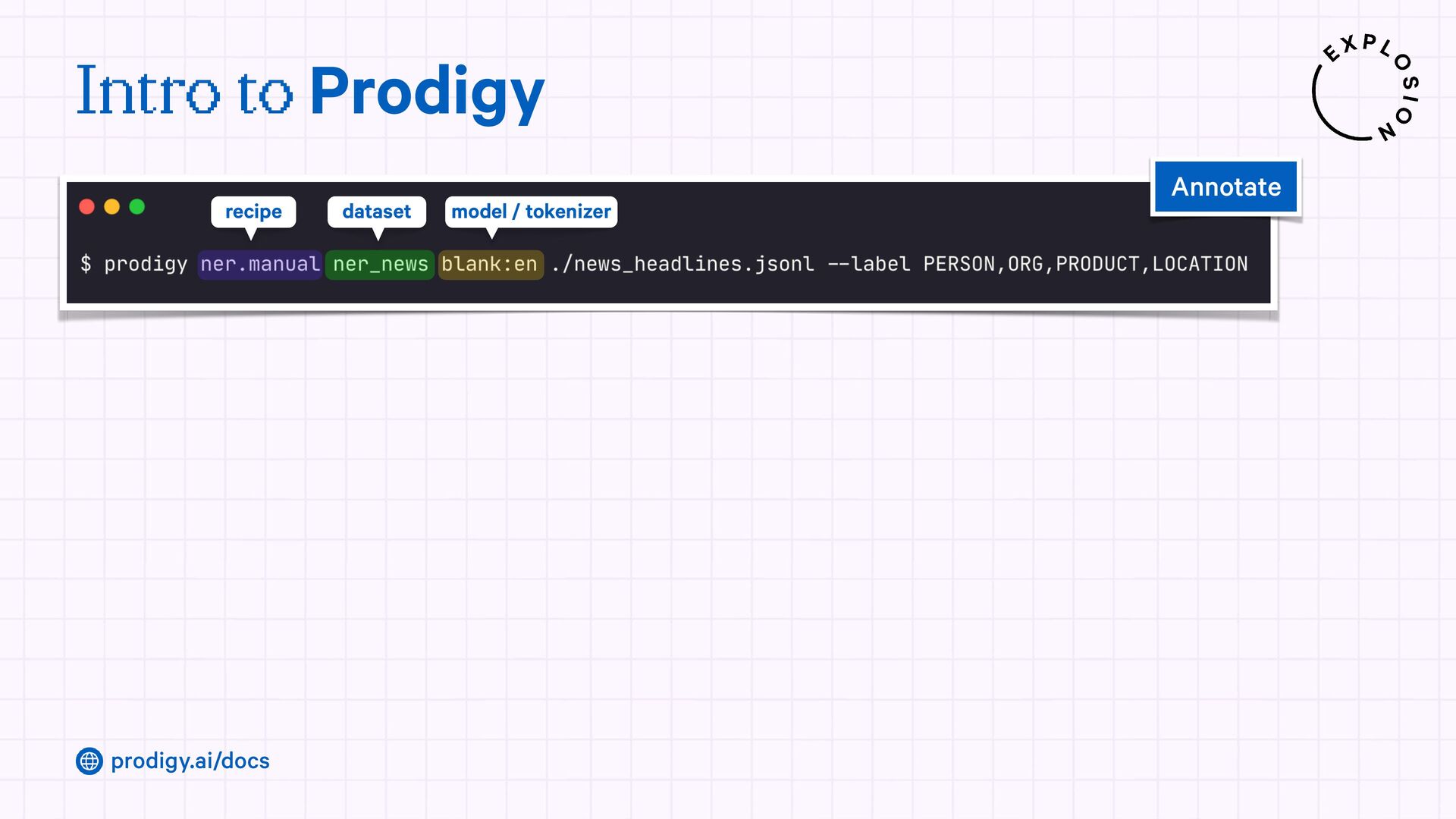
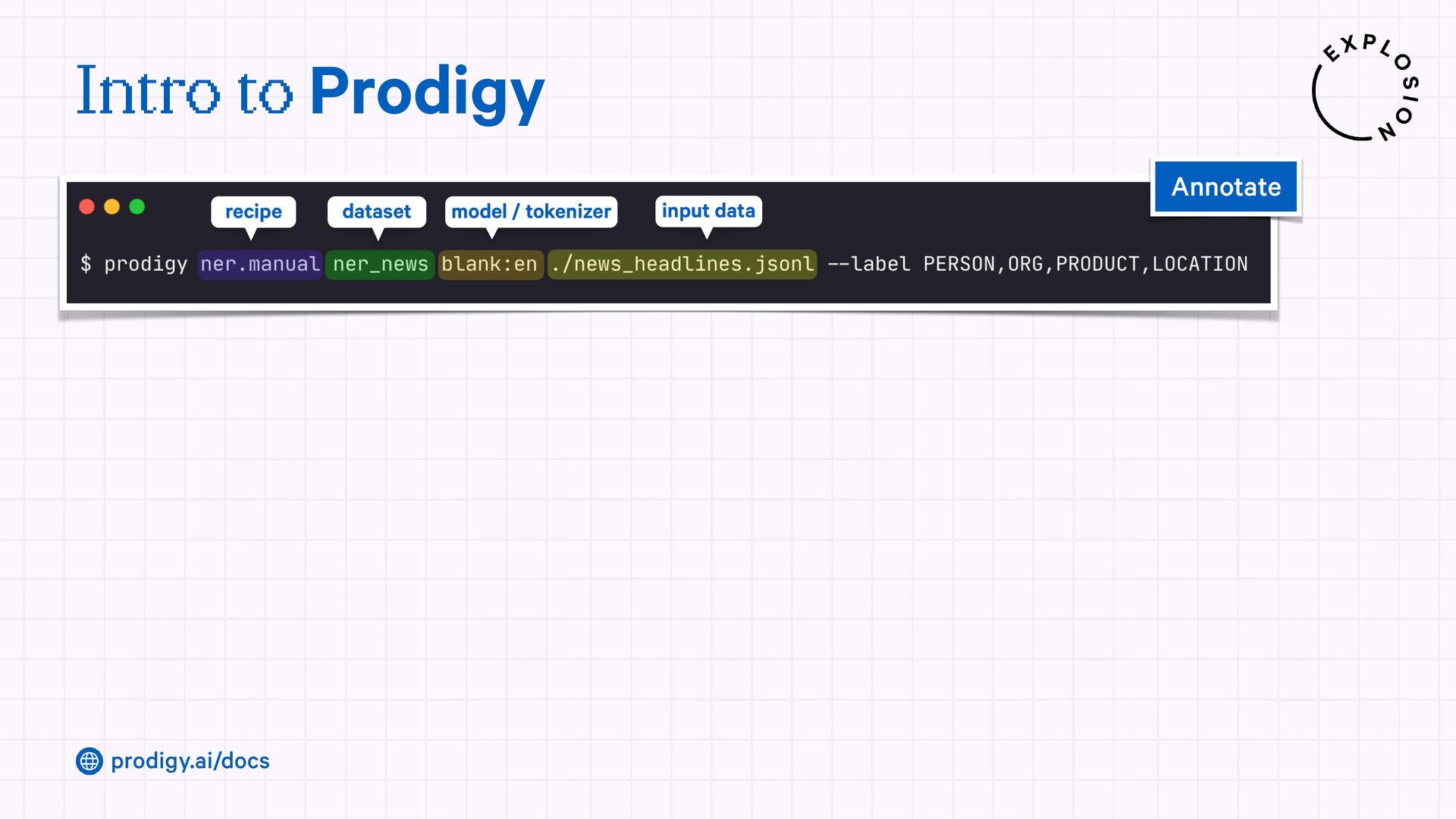
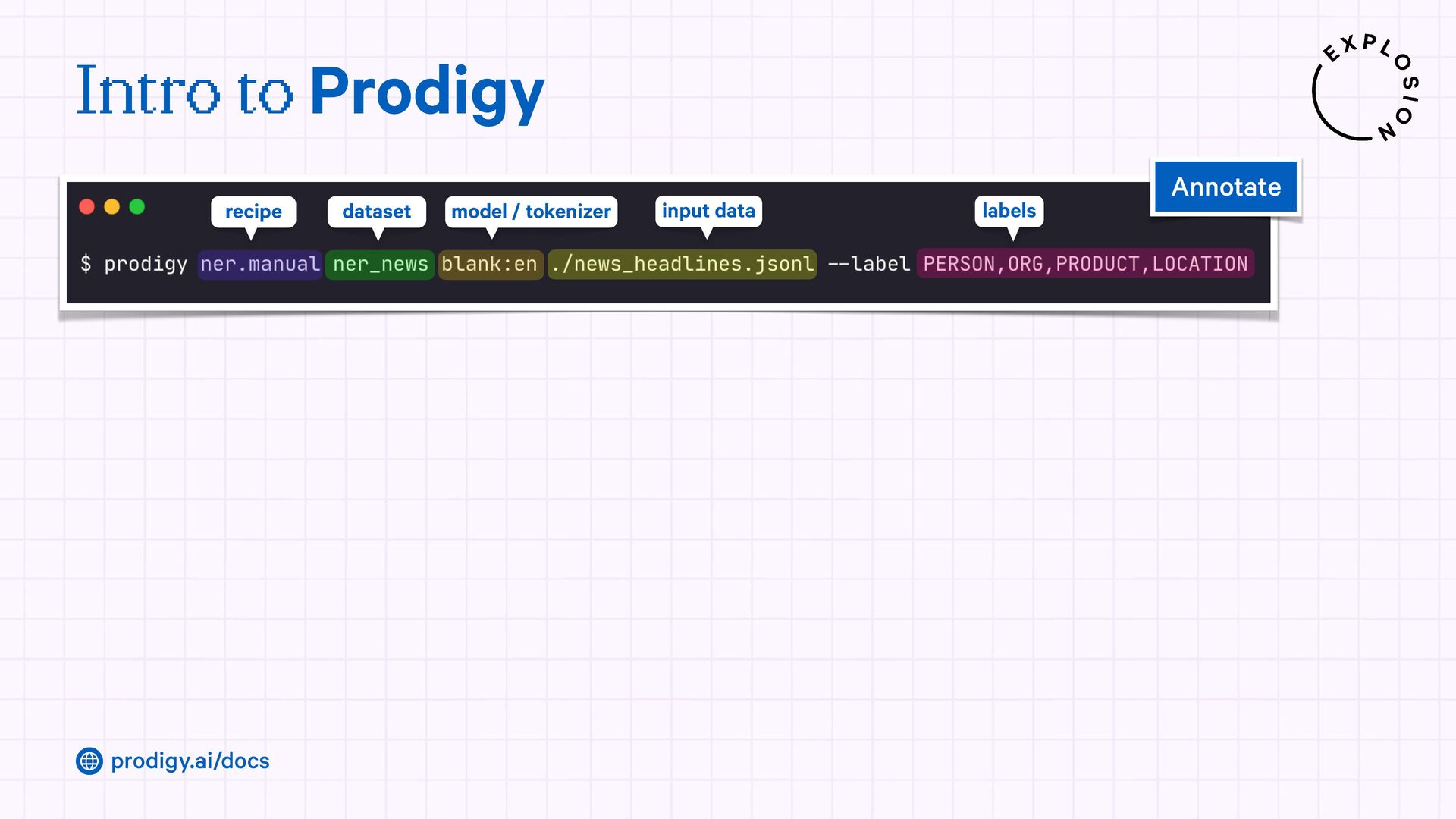
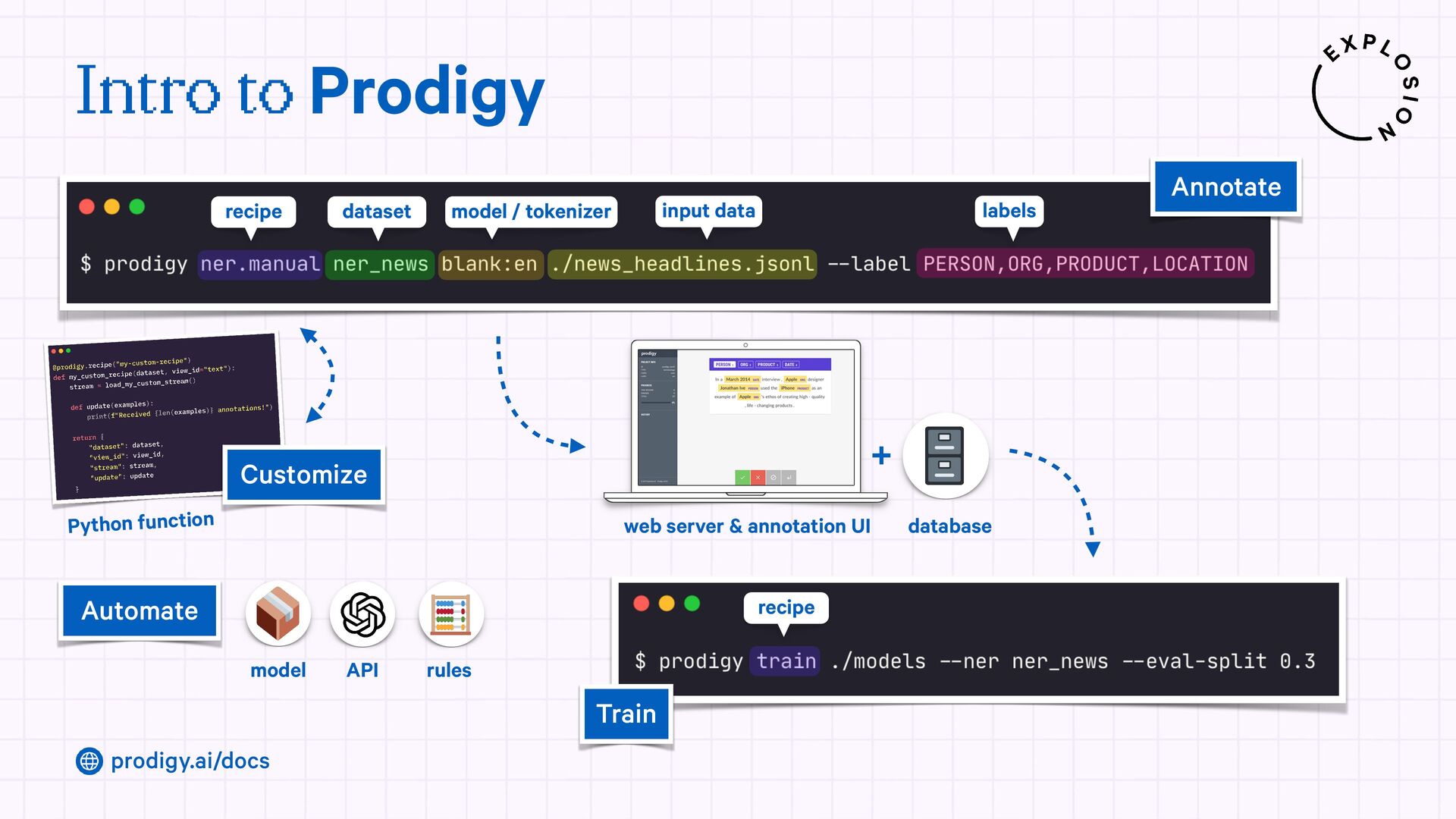
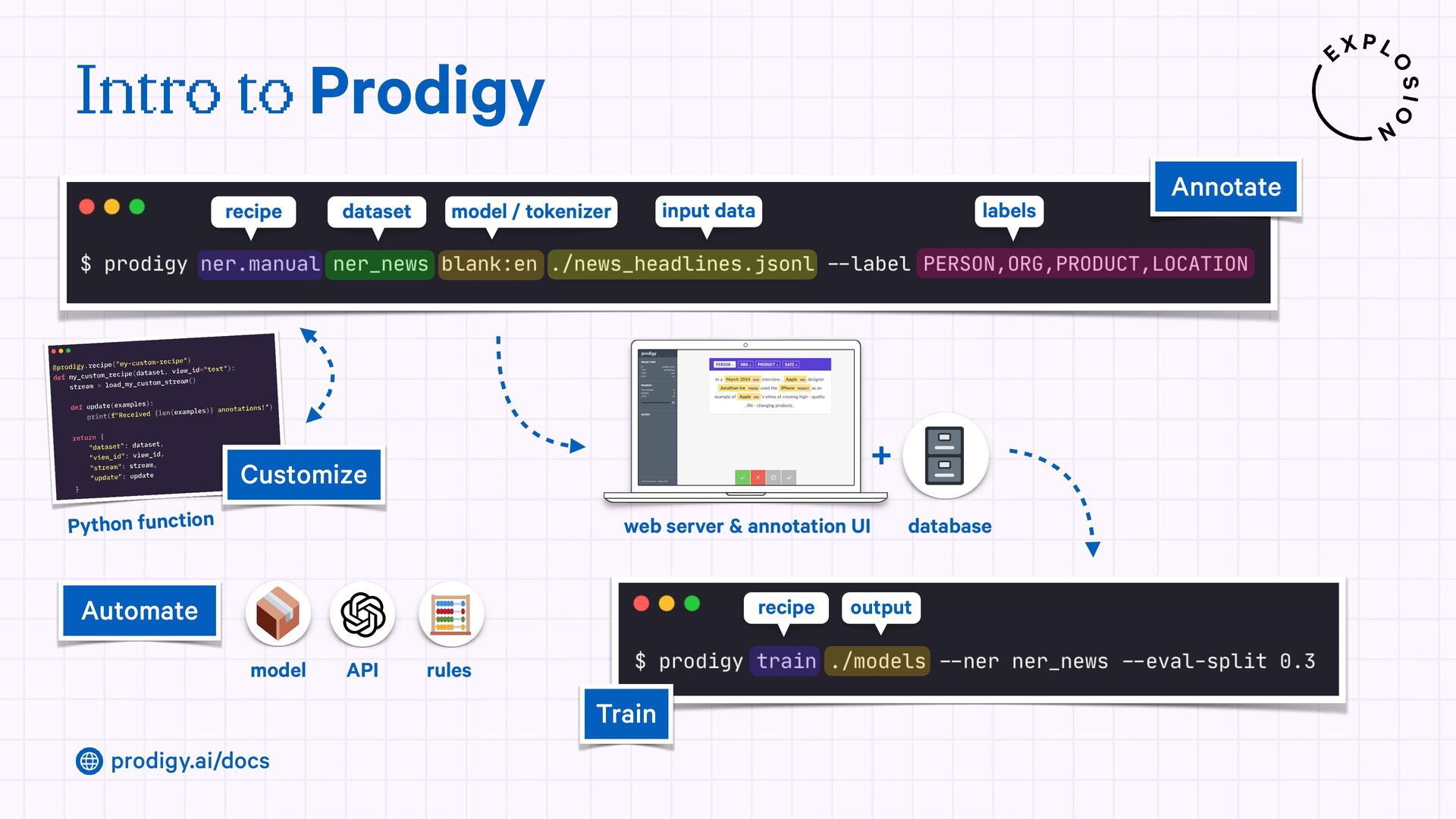
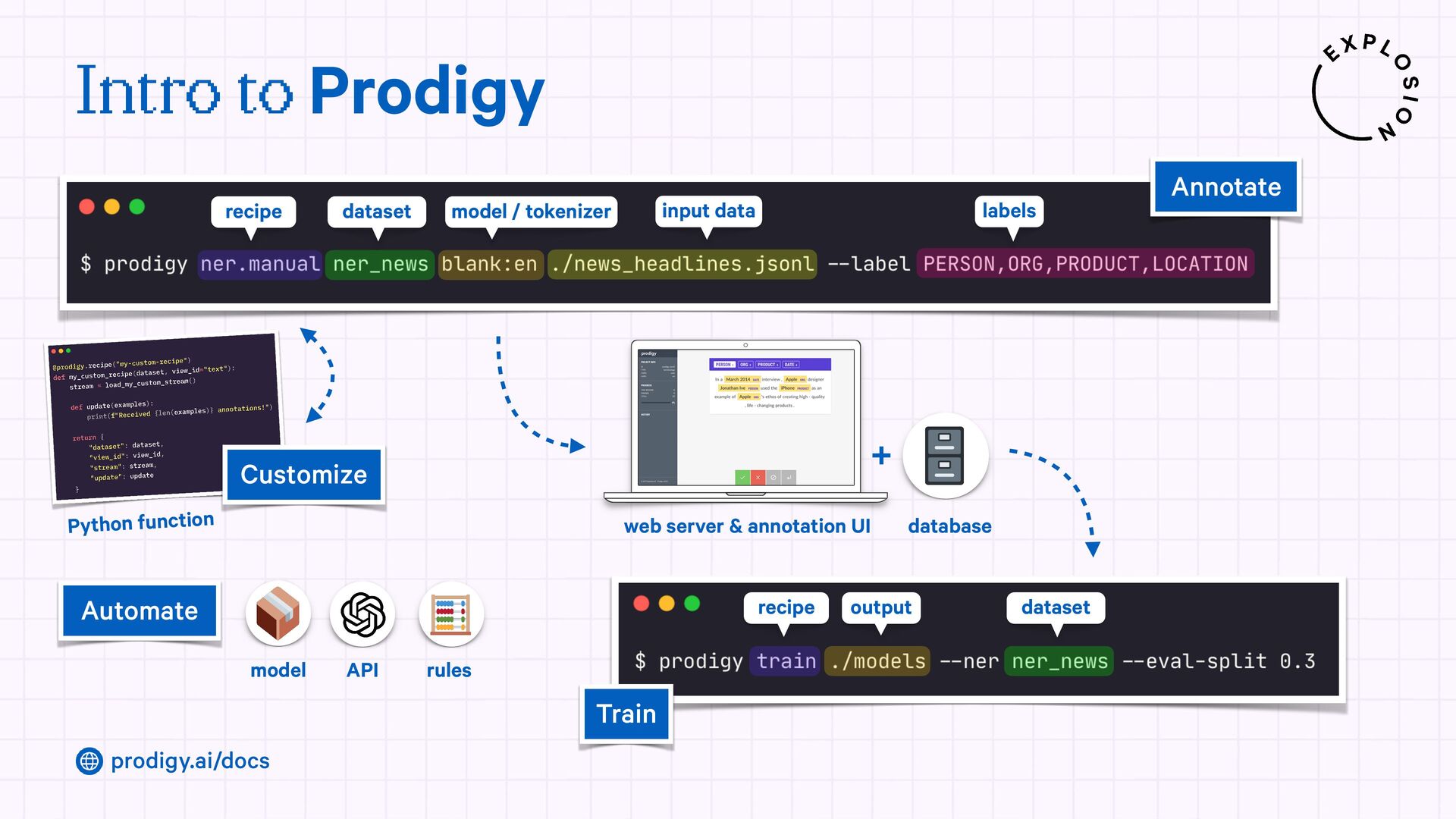
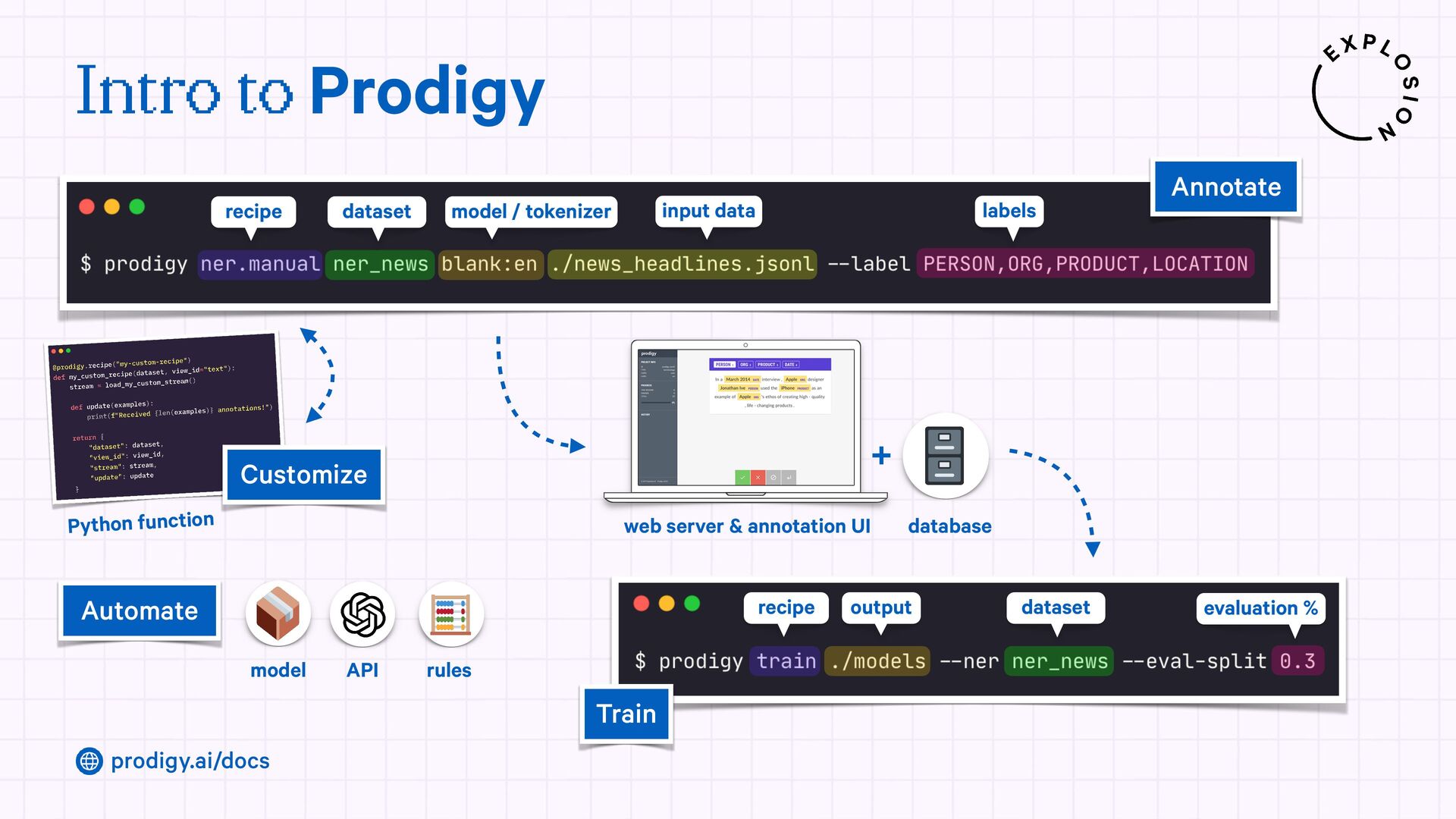
A modern and powerful annotation and model improvement tool used for human-in-the-loop training, rapid iteration, and custom NLP workflows.
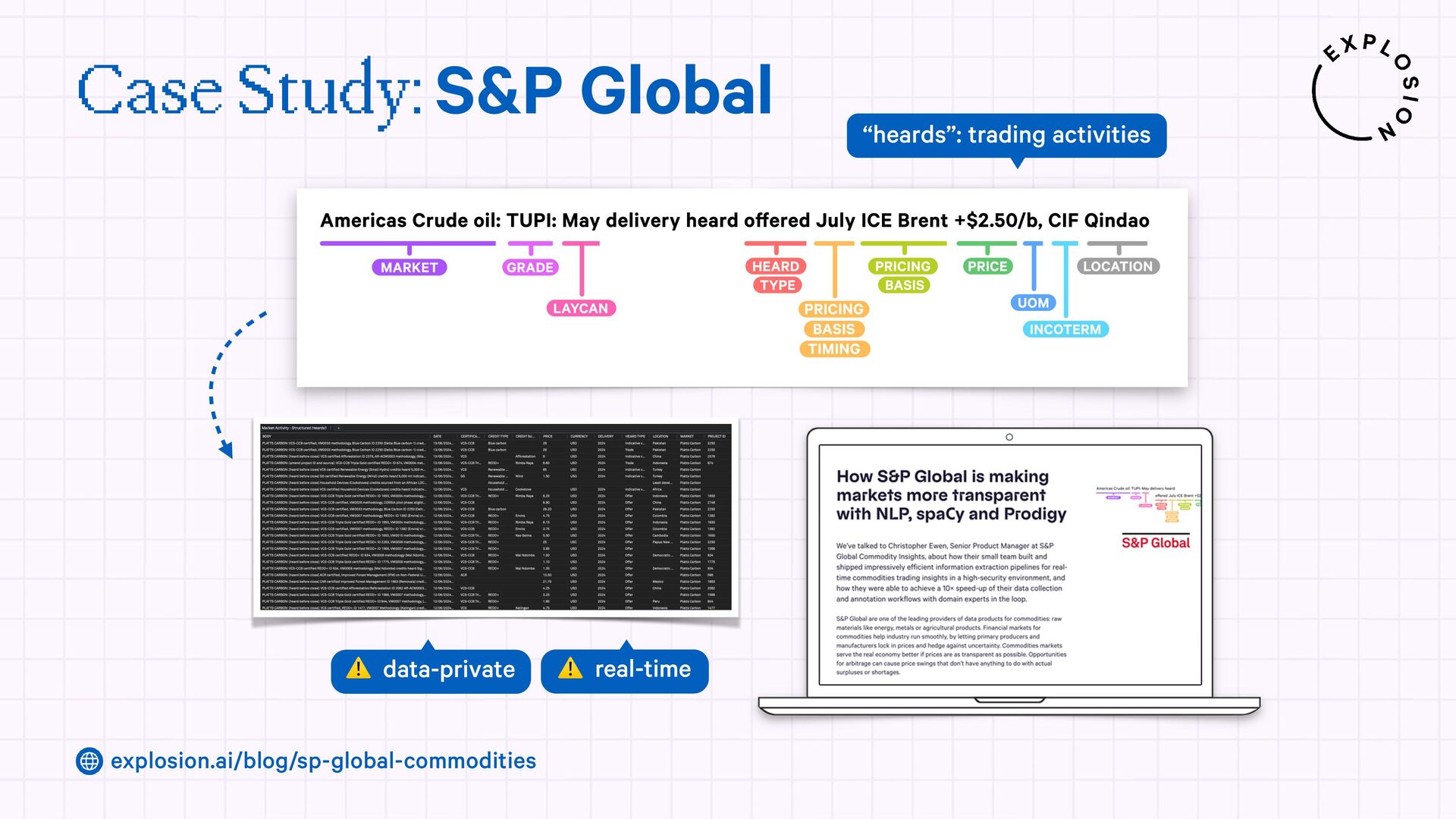
https://explosion.ai/blog/sp-global-commodities
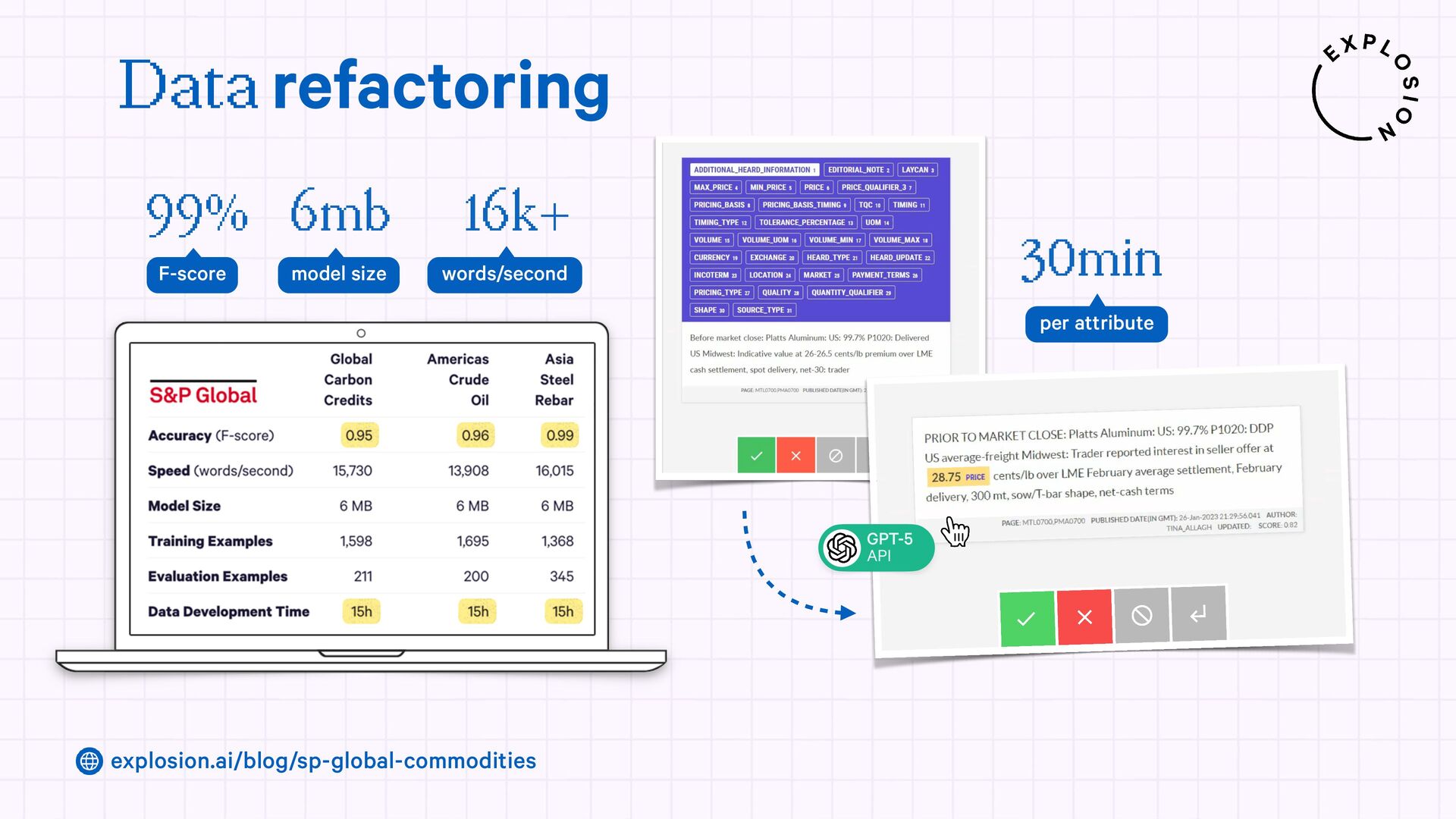
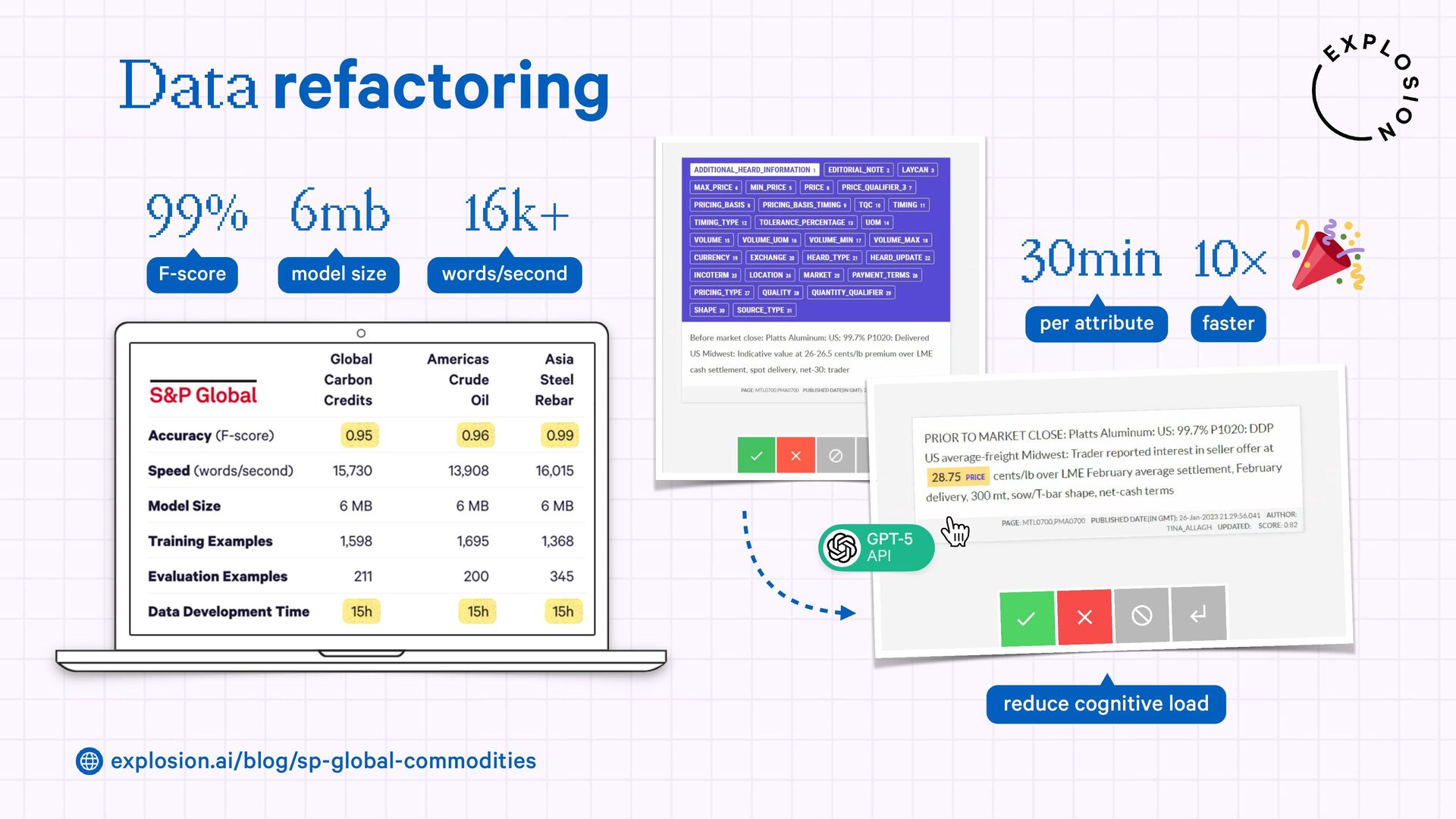
A case study on S&P Global’s efficient information extraction pipelines for real-time commodities trading insights in a high-security environment using human-in-the-loop distillation.
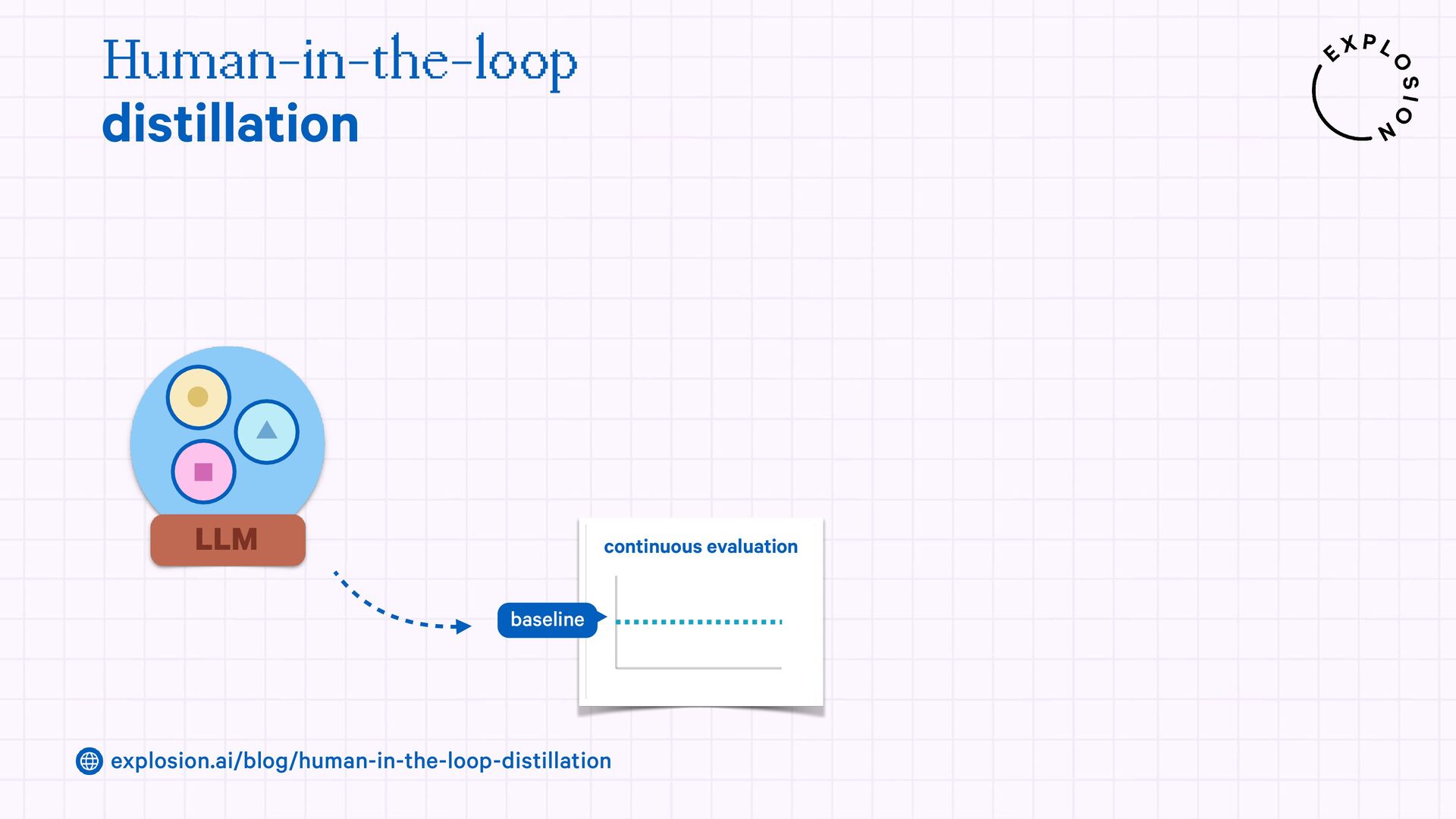
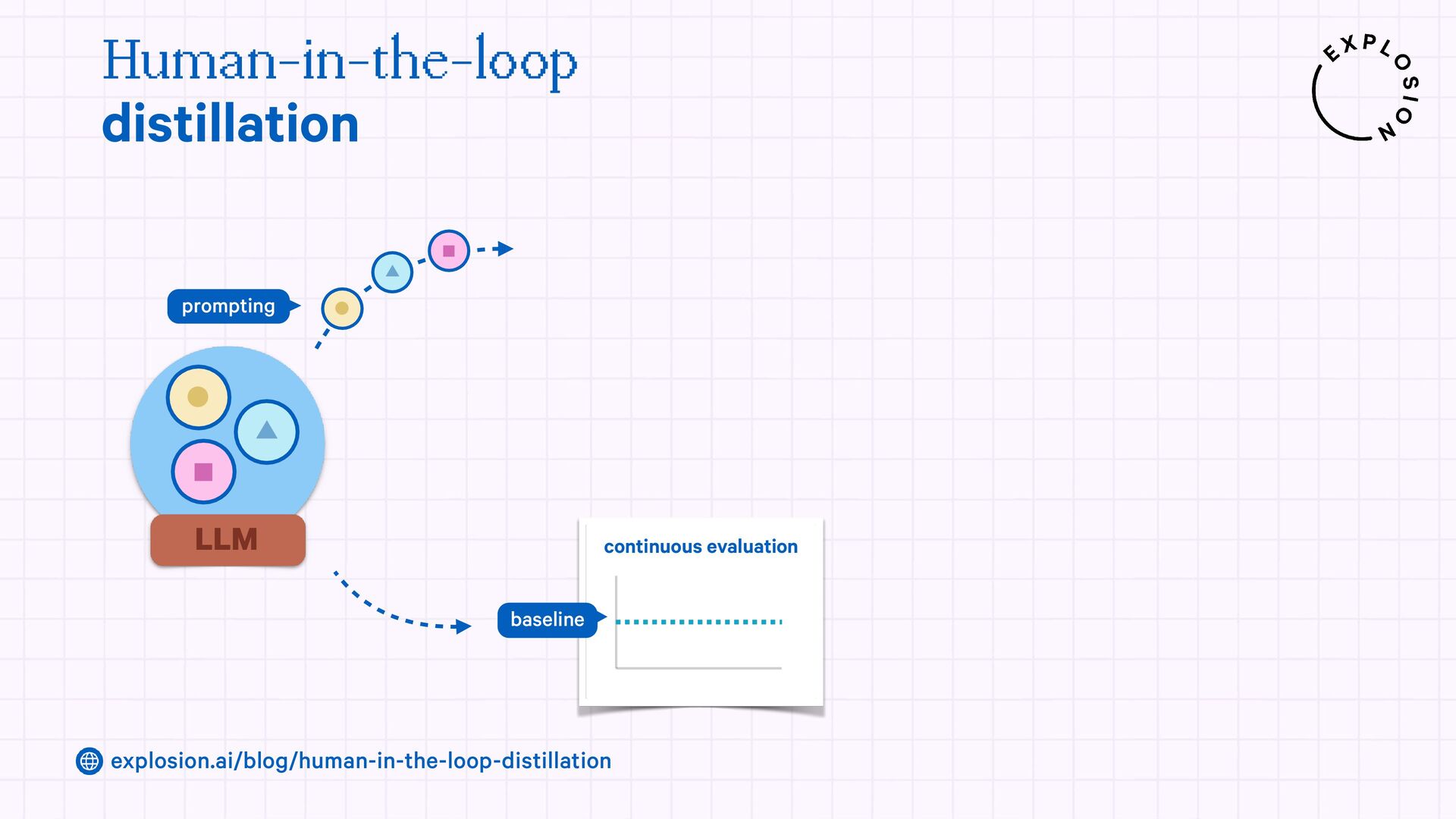
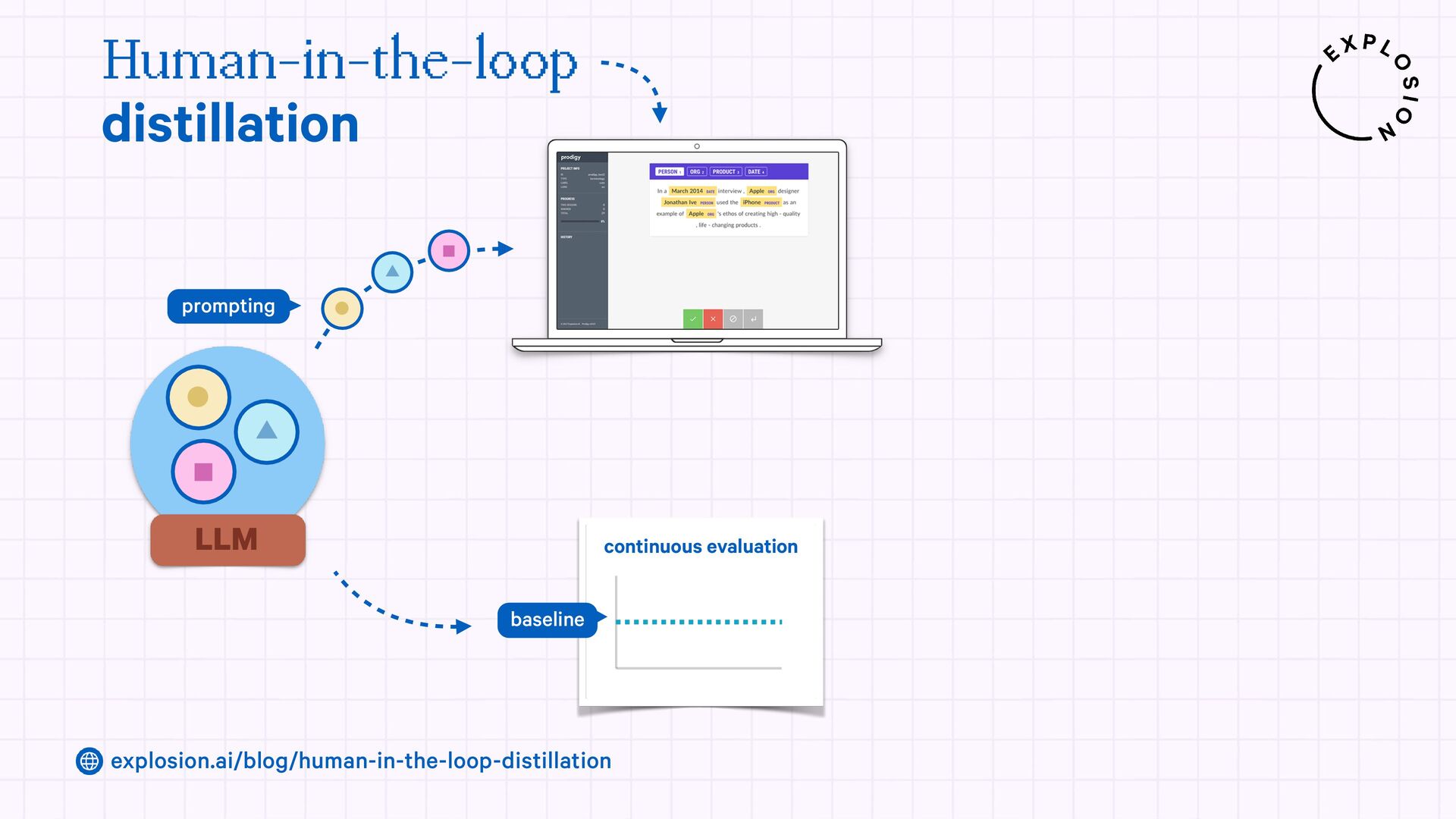
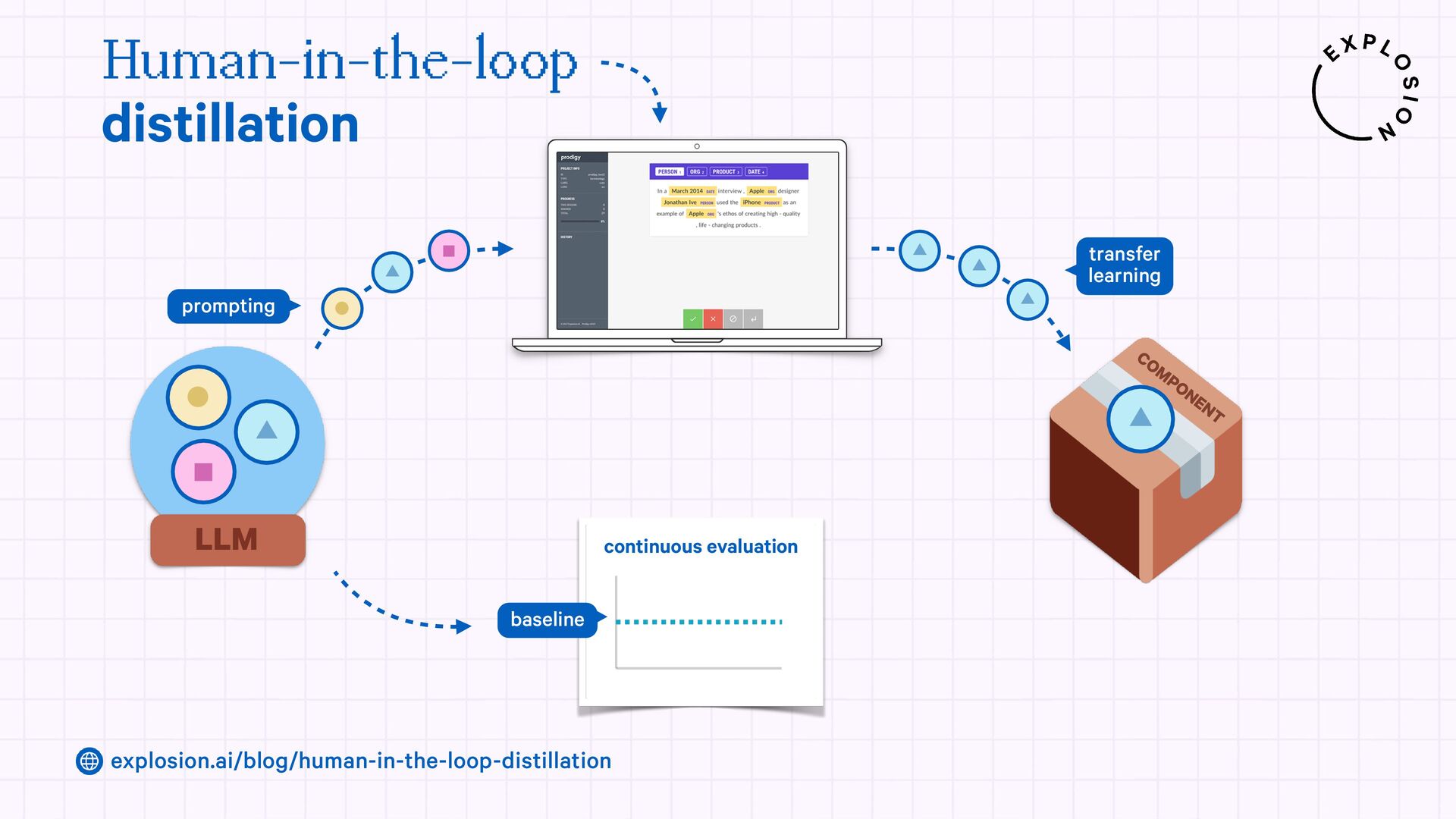
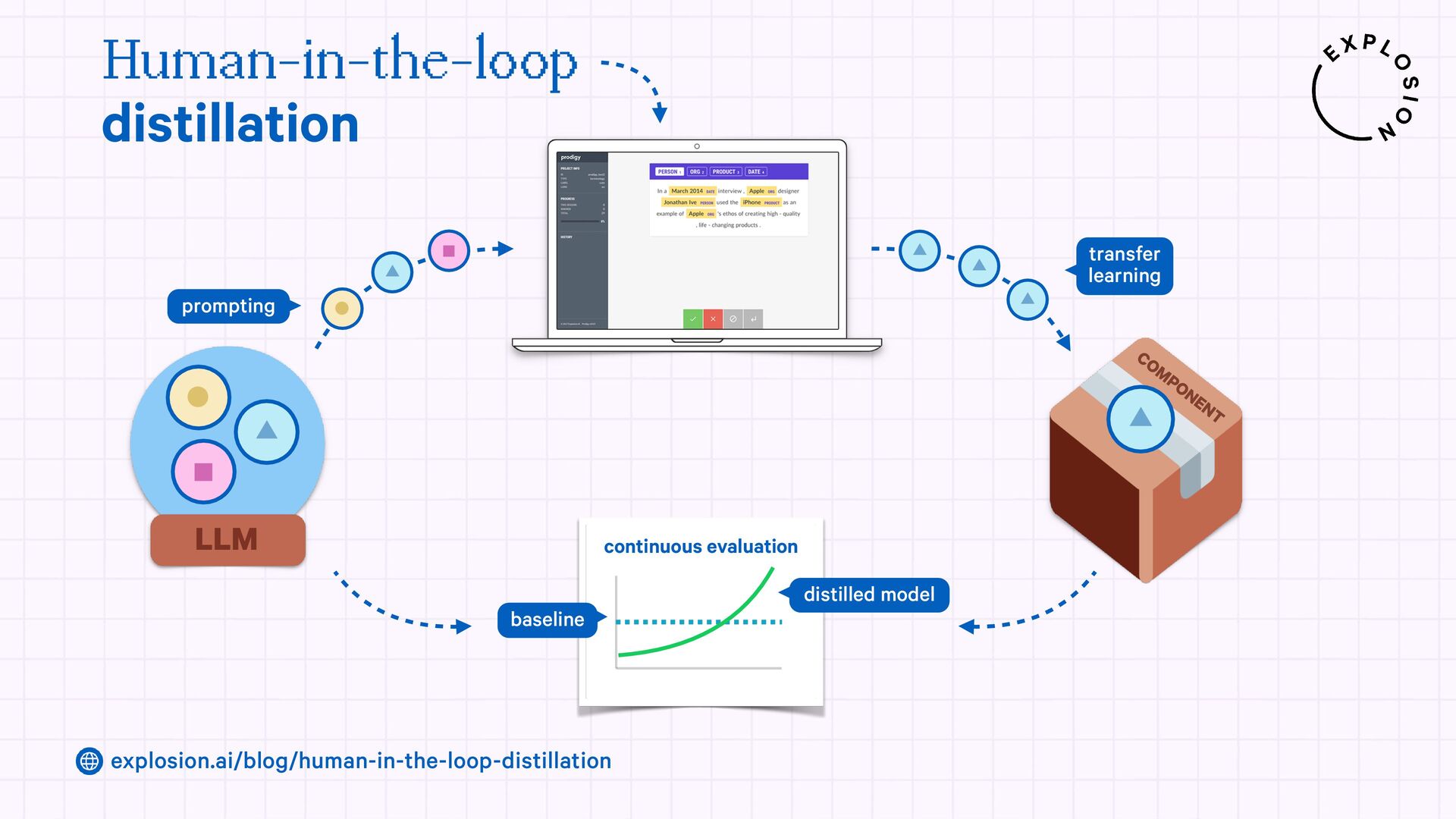
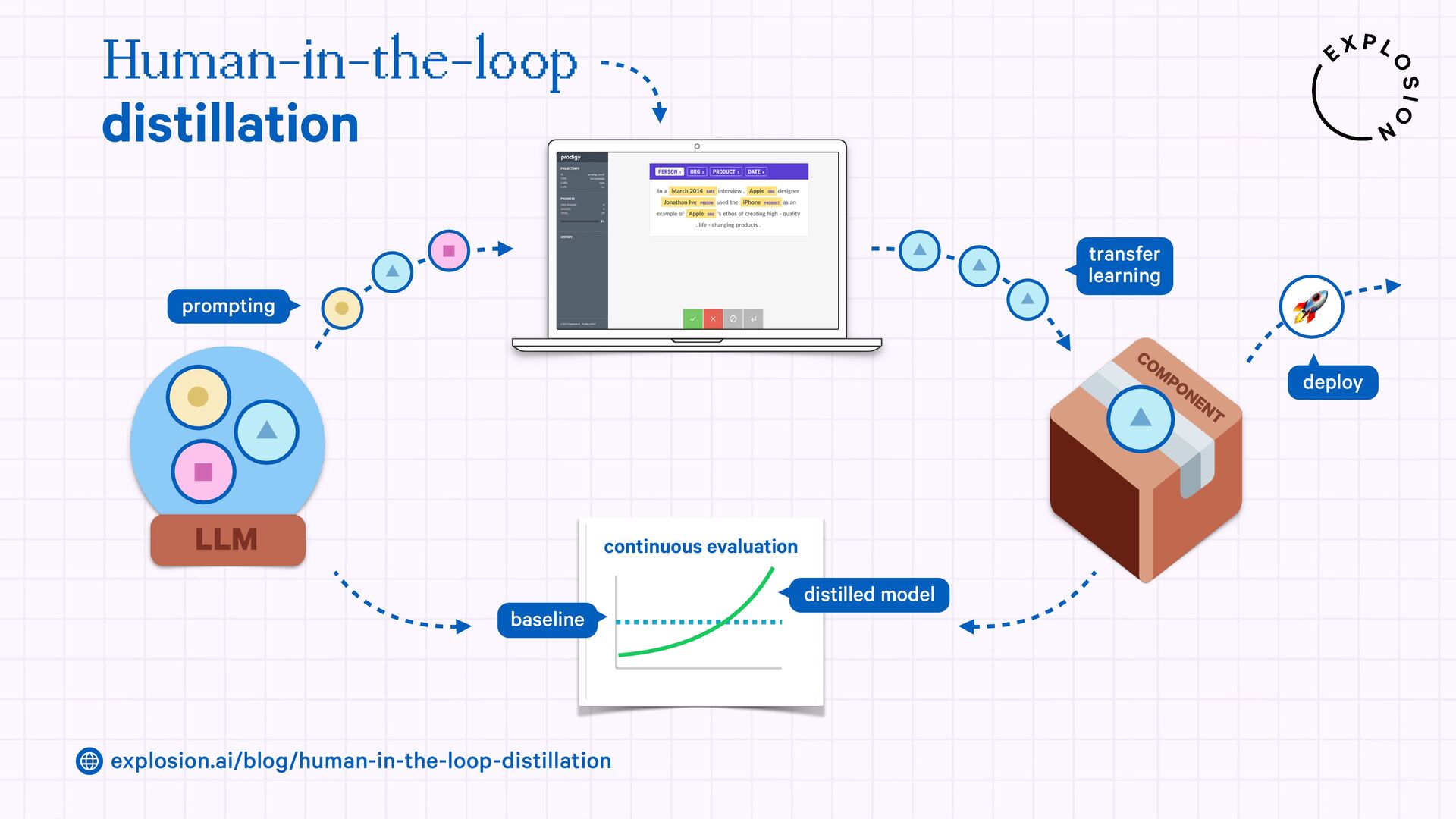
https://explosion.ai/blog/human-in-the-loop-distillation
This blog post presents practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
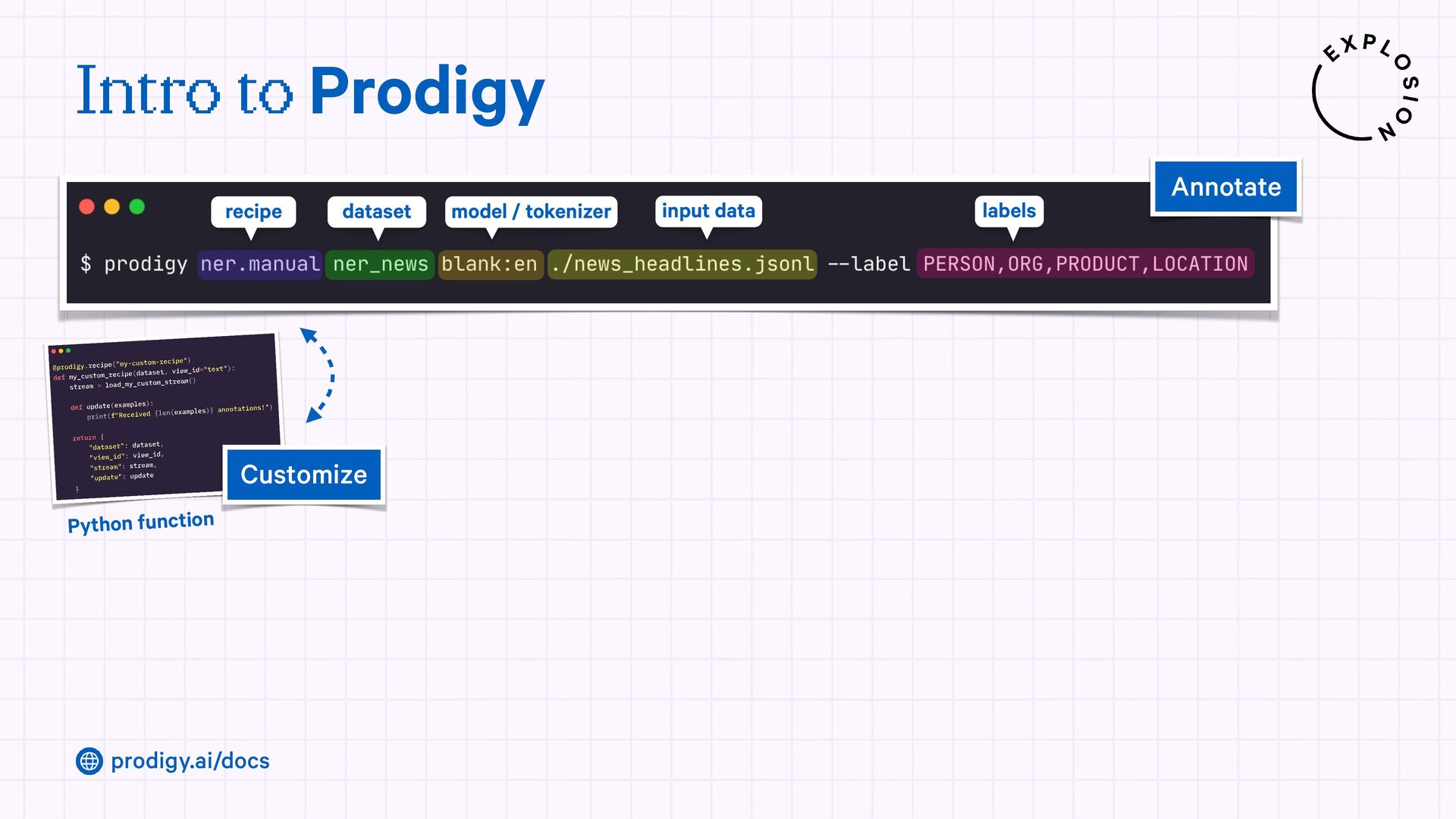{kind=link}
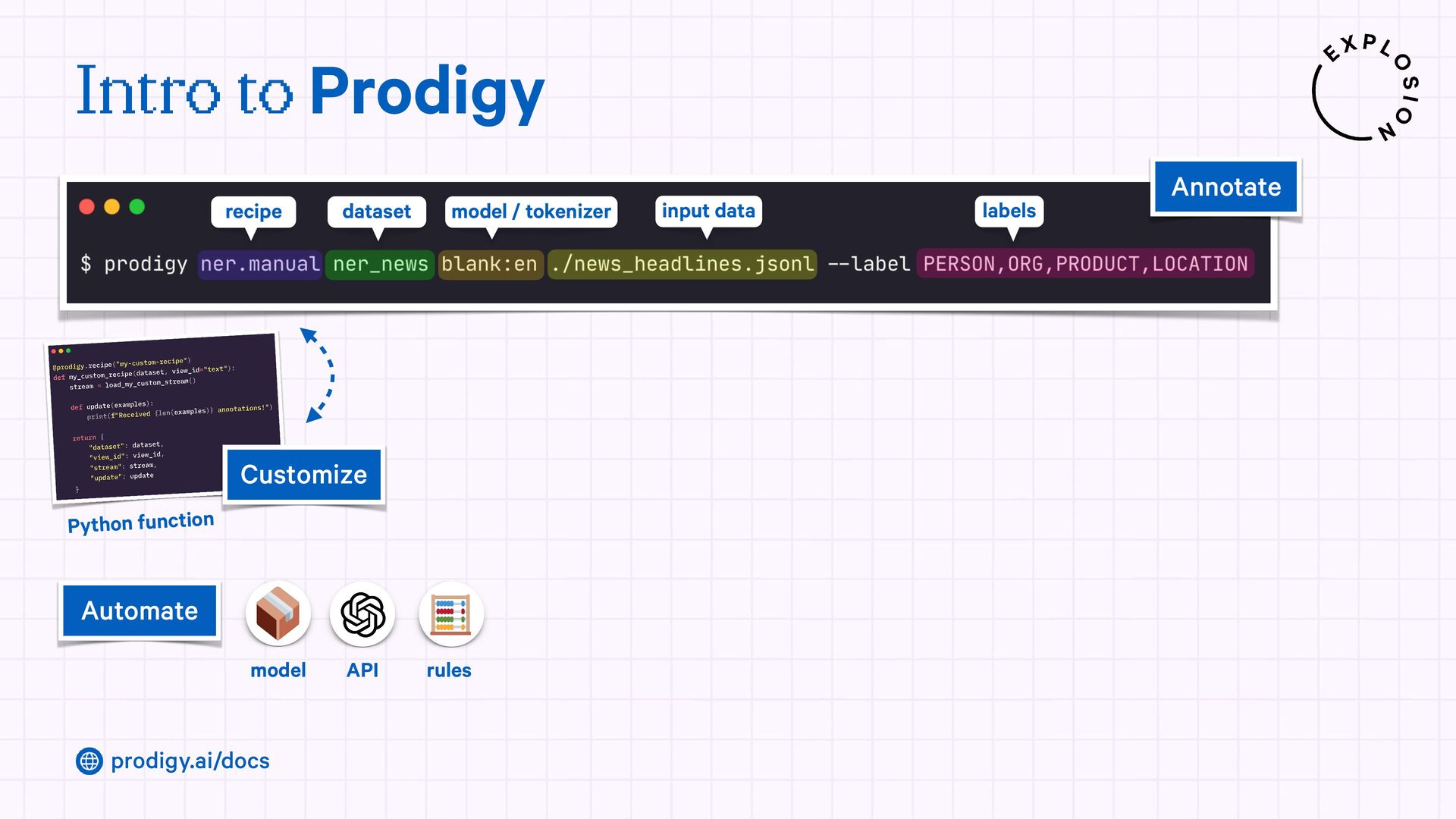{kind=link}
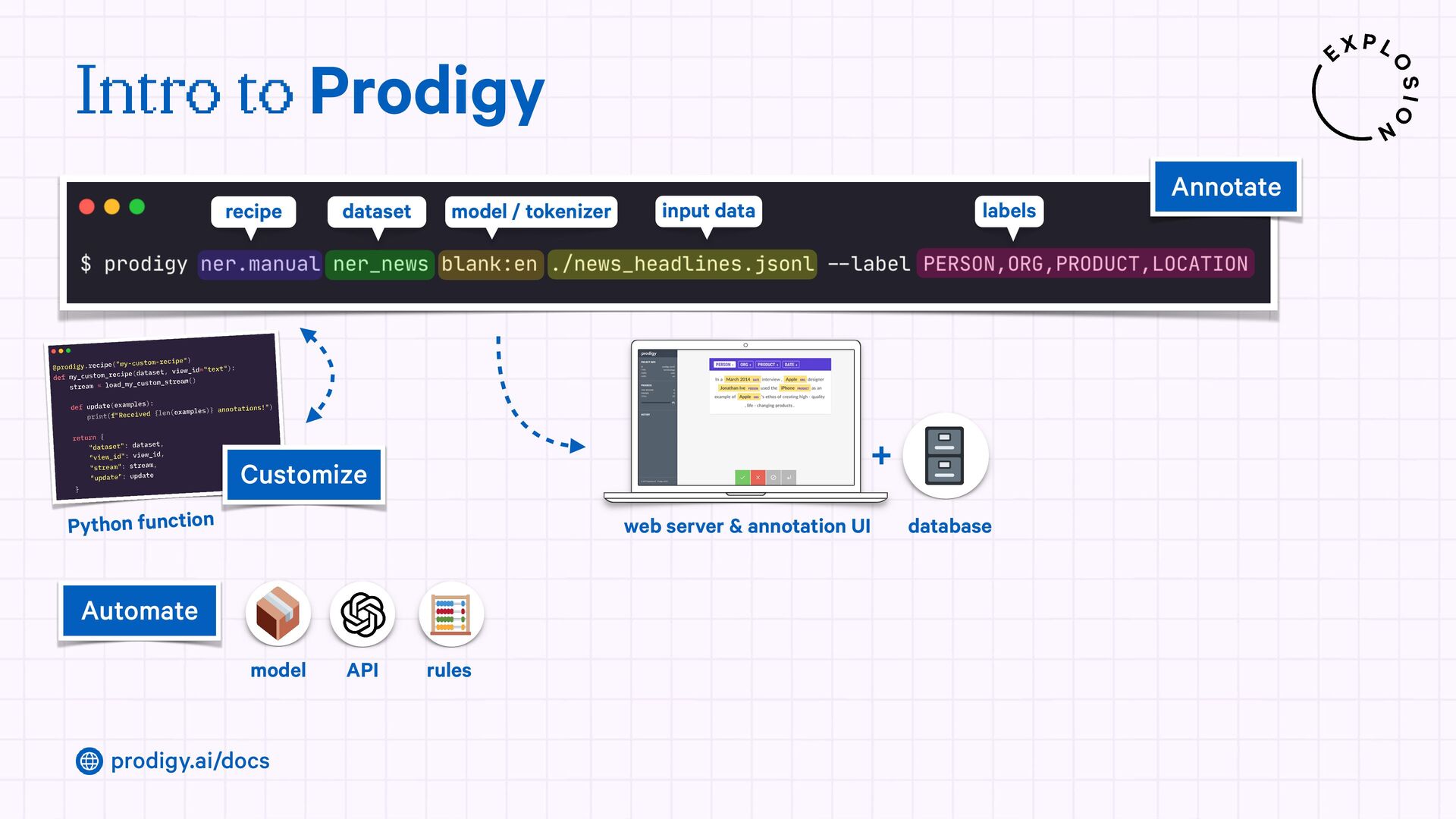{kind=link}
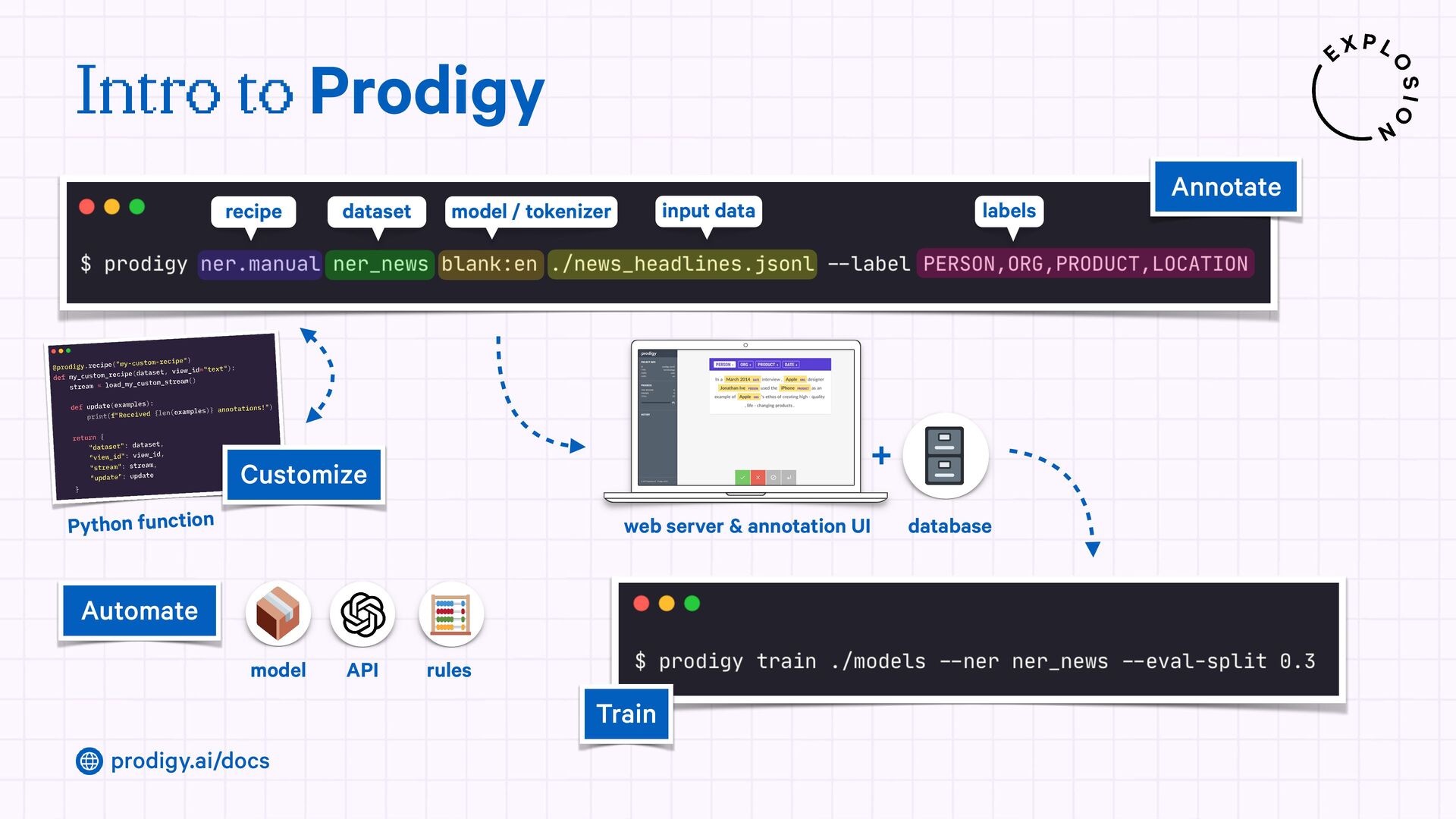{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}