Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
自宅LLMの話
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Kazuto Kusama
June 20, 2026
Technology
920
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
自宅LLMの話
第1回 みんなの自宅鯖LT会で発表した資料です
Kazuto Kusama
June 20, 2026
More Decks by Kazuto Kusama
See All by Kazuto Kusama
趣味でイベント配信をやっている者だ
jacopen
1
25
プラットフォームエンジニアリングはAI時代の開発者をどう救うのか
jacopen
9
5.5k
OpenClawで回す組織運営
jacopen
3
1.3k
SREの仕事を自動化する際にやっておきたい5つのポイント
jacopen
6
1.7k
AI時代のインシデント対応 〜時代を切り抜ける、組織アーキテクチャ〜
jacopen
4
410
AI時代の開発とPlatform Engineeringについて考える
jacopen
0
280
AI によってシステム障害が増える!? ~AI エージェント時代だからこそ必要な、インシデントとの向き合い方~
jacopen
4
420
インシデント対応に必要となるAIの利用パターンとPagerDutyの関係
jacopen
0
450
今日からはじめるプラットフォームエンジニアリング
jacopen
8
5.3k
Other Decks in Technology
See All in Technology
NYC Summit 2026 における Amazon Bedrock AgentCore のアップデート
ren8k
1
240
コンポーネント名には何を含めるべきなのか? / what-should-be-included-in-component-names
airrnot1106
0
160
AI Agent を本番環境へ―― Microsoft Foundry × Azure Serverless で作る Enterprise-Ready な基盤
shibayan
PRO
1
640
データベース研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
600
システム監視入門
grimoh
5
720
どこまでAIに任せるか 〜確率論と決定論の境界決定〜
shukob
0
550
AIで楽になるはずが、なぜ疲れる?
kinopeee
0
130
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
2.3k
エンタープライズデータへ安全につなぐ Production-ready なエージェント設計 ― AI × MCP リファレンスアーキテクチャ ― #AIDevDay
cdataj
1
180
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
170
GMOフィナンシャルゲートが挑む、「止まらない」決済インフラ構築の裏側【SORACOM Discovery 2026】
soracom
PRO
0
100
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
2
160
Featured
See All Featured
Balancing Empowerment & Direction
lara
6
1.2k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
A Soul's Torment
seathinner
6
3.1k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
470
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
RailsConf 2023
tenderlove
30
1.5k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
880
Six Lessons from altMBA
skipperchong
29
4.4k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
Code Reviewing Like a Champion
maltzj
528
40k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
390
Transcript
自宅LLMの話
Kazuto Kusama @jacopen Product Evangelist @PagerDuty Japan 理事 @一般社団法人SREコネクト 代表理事
@一般社団法人クラウドネイティブイノベーターズ協会
自分と自宅サーバー 普段の活動範囲 • クラウドネイティブ • プラットフォームエンジニアリング • インシデント管理 自宅サーバー歴はめっちゃ長い(今年で24年) 自分のキャリアは自宅サーバーに支えられて
きたと思っており、そういった登壇もした Software Designで「はじめよう、おうちク ラウド」を連載した はじめての自宅サーバーのCPUはPentiumII 400MHz
最近やっていること 3Dプリンターで自作10インチラックを 育てています これも結構面白いのでどこかでお話したい
今日のネタ 自宅LLM
自鯖愛好家として、LLMは複雑な想い
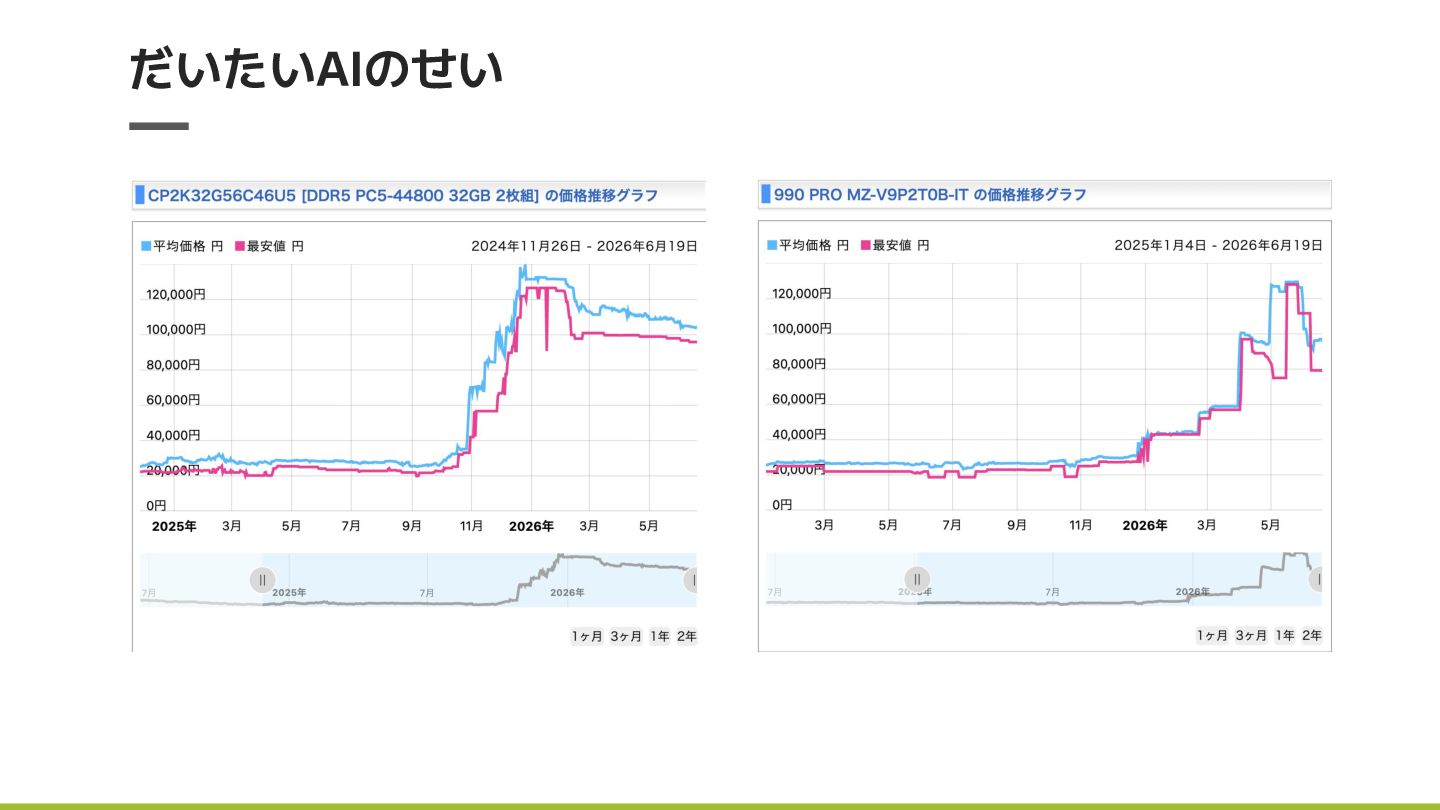
だいたいAIのせい
とはいえ、あれだけの仕組みが手元で動くのも なかなかロマンがある
自宅LLMって使い物になるの? ちょっと前まで、自分も懐疑的だった しかし2026年に入り、自宅で動かせるレベルのものでも、それなりの質が出せる ようになってきたと感じる ちょっとしたタスクの自動化であれば十分こなせる
単に「LLMを動かす」だけなら 割とどこでも動く Gemini Nano (Chrome内蔵)のようなオンデバイスLLMであれば、16GB程度のメ モリを積んだPCや4GB程度のVRAM環境で動く ・・・が、自宅サーバー派の観点でLLMを飼うのなら、この辺はスコープ外
現実的な範囲でとれる選択肢 2026年6月現在、オープンモデルで、4B〜32B程度のパラメータが提供されてい るもの • gemma4 • Qwen3.6 • GLM4.7-flash あたり
VRAM8GB〜32GBあたりで動かせる。
選択肢1: nvidia まあ鉄板 エコシステムがCUDA前提に成り立っているの で、無用なトラブル避けたければnvidia一択 ハイエンド: RTX 5090 32GB ・・・
しかし価格・・・ 次点: RTX 4090 24GB RTX 3090 24GB ・・・このあたりは中古を狙う 7B〜14B程度のモデルを動かすなら、16GB VRAMのものをチョイス。ここは選択肢が多い
選択肢2: Mac ユニファイドメモリの強みがあるのでこちらも定 番。大きいモデル動かしたいならコスパが良い 低コスト構成でM4 Mac Miniは定番。でも OpenClaw需要があったのとモデル末期なおかげ で在庫微妙 金に糸目をつけないのであればMac
StudioでM3 Ultra 512GBが定番だったが、これも買えなく なってしまった。
選択肢2: Ryzan AI MAX “Strix Halo” ユニファイドメモリの選択肢その2 最上位のRyzen AI Max+
395は128GBのメモリ を積んでいるので、96GBをVRAMに充てれば 70B〜120B程度のモデルが動かせる モバイル/ミニPC用途のAPUなので、筐体がとて も小さくできるのもメリット いいじゃん・・・
ということで買いました Strix Haloが発表された時点でLLMで遊ぶ向けだな と感じたので、先陣を切って発売されたGMKtecの EVO-X2を購入(2025年5月)。その時の金額で $1,999
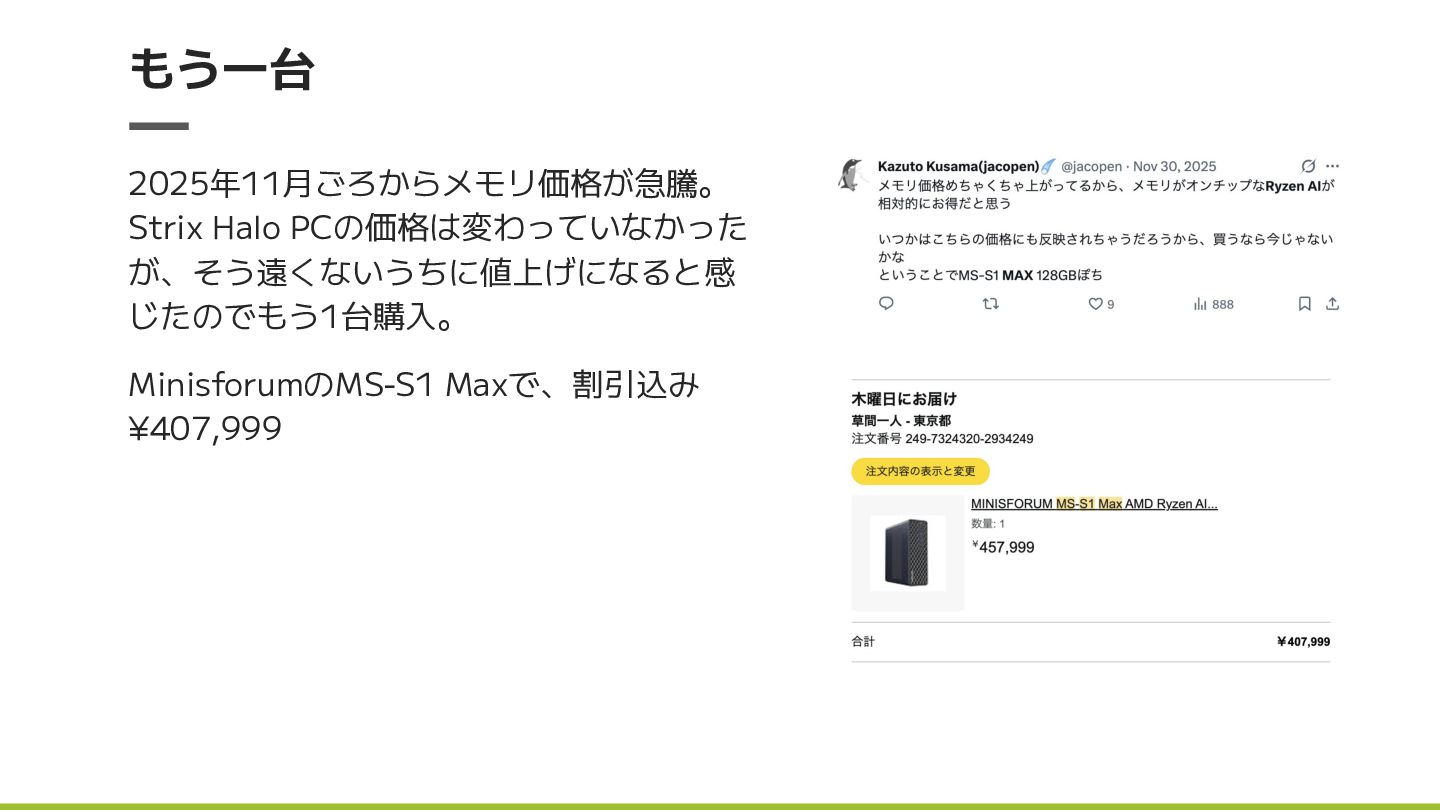
もう一台 2025年11月ごろからメモリ価格が急騰。 Strix Halo PCの価格は変わっていなかった が、そう遠くないうちに値上げになると感 じたのでもう1台購入。 MinisforumのMS-S1 Maxで、割引込み ¥407,999
なにもかも高くなった 予想通りめっちゃ高くなってしまった EVO-X2: 31万円(購入時) → 51万円(現在) MS-S1 Max 40.7万円(購入時) →
64万円(現在) でも、他の選択肢(nvidia, mac)も同様に値上がりしているので、何もかもが 高い・・・
Strix Haloで遊ぶ
LLMを動かす WindowsかLinux 自宅サーバー勢であれば、たぶんLinuxで組む方がいい。推論サーバーとして 動かしておき、ホームラボの各マシンから利用するという形 推論エンジンとしてはollamaが鉄板 インストールは簡単 curl -fsSL https://ollama.com/install.sh |
sh
注意点 Strix HaloはRyzen APUなのでCUDAは使えな い。ROCmを使うことになる そのため、ROCm向けのセットアップが必要 AMDのドキュメントをみながらセットアップ する。自宅サーバー勢からみるとそこまで難 しくはない
利用するモデル Strix Haloは128GBのうち、フレキシブルに VRAMに割り当てることが可能。 なので70Bや、量子化した120Bのモデルも動 く。 が、推論速度がめちゃ速いというわけではな いので、使い物になるのはやっぱり32Bくら いまで。 これ発表している時点では、Qwen3.6
35B-A3Bがもっとも速度のバランスがいいよ うに感じる。
OpenClaw / Hermes Agentを動かす 常時動かすワークロードとして、 OpenClawやHermes Agentが使い勝手良い ollamaで簡単にセットアップできる
LibreChatを動かす セルフホスト型のチャットプラットフォー ム。さまざまなプロバイダーのモデルを利 用できる。もちろんollamaも対応
OpenCodeを動かす OSSのコーディングエージェント さまざまなモデルが利用できる。 ollamaとopencode両方入っていれば、 ollama launch opencode するだけで使える モデルの性能差があるのでちゃんとした コード書かせるならフロンティアモデル使
いたくなるかも。ちょっとした作業程度 に。
その他の活用方法 アイディア次第でどうとでも遊べると思う やはり自宅サーバー派として、ホームラボをまとめて運用出来る、24365で 動くエージェントを作りたい気持ちあり。
ちなみに Strix Halo 2台あるけど、両方使いこなすまでに 至らなかったので片一方はForza Horizon 6で遊 ぶマシンになりました。 グラフィックかなり上げても60fps維持できま す。
AIに飽きたらゲームにも使える神APU
今後やりたいこと vLLMがROCmに対応してそれなりに使えるようになってきたらしいので、そ ちらも試したい。そうしたら2台目もまたゲーム機から推論サーバーに転身し てもらうかも
さいごにお知らせ
自宅サーバーのカンファレンスやります 11/15 (日) docomo R&D OPEN LAB ODAIBA
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}