minutos – La API S3 en 6 transparencias – Dos casos de uso basados en Ceph y RGW/S3 – Instalando y probando Ceph fácilmente – Algunos comandos habituales en Ceph – Ceph RGW S3 con Apache Libcloud, Ansible y Minio – Almacenamiento hyperescalable y diferenciación – Q&A
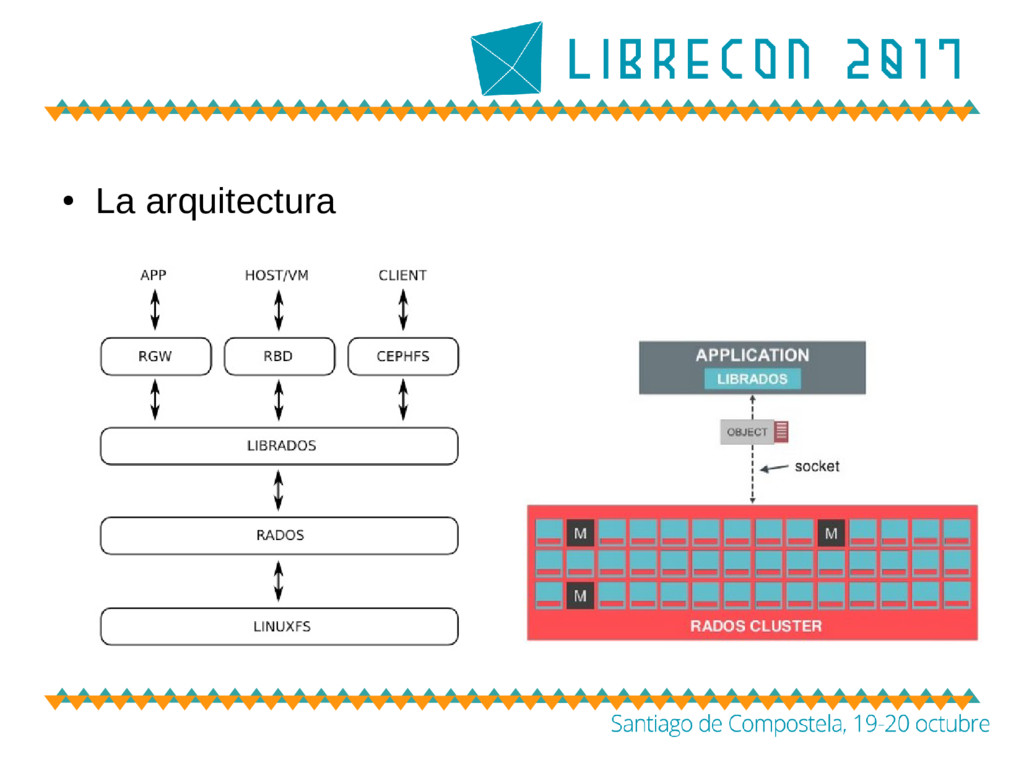
Source distribuído, escalable y tolerante a fallos – La magia detrás de Ceph • Almacenamiento basado en objetos • CRUSH – Sistema de ficheros, dispositivos de bloques y objetos de alto nivel (ej. API S3) son interfaces sobre objetos nativos
de California, Santa Cruz) – Red Hat compra Inktank en 2014 – En 2015 se forma el ‘Ceph Community Advisory Board’ (Canonical, CERN, Cisco, Fujitsu, Intel, Red Hat, SanDisk y SUSE) – ‘Releases’ • Argonaut, Bobtail, Cuttlefish… • Jewel (v10.2.0), Kraken (v11.2.0) and Luminous (v12.2.0)
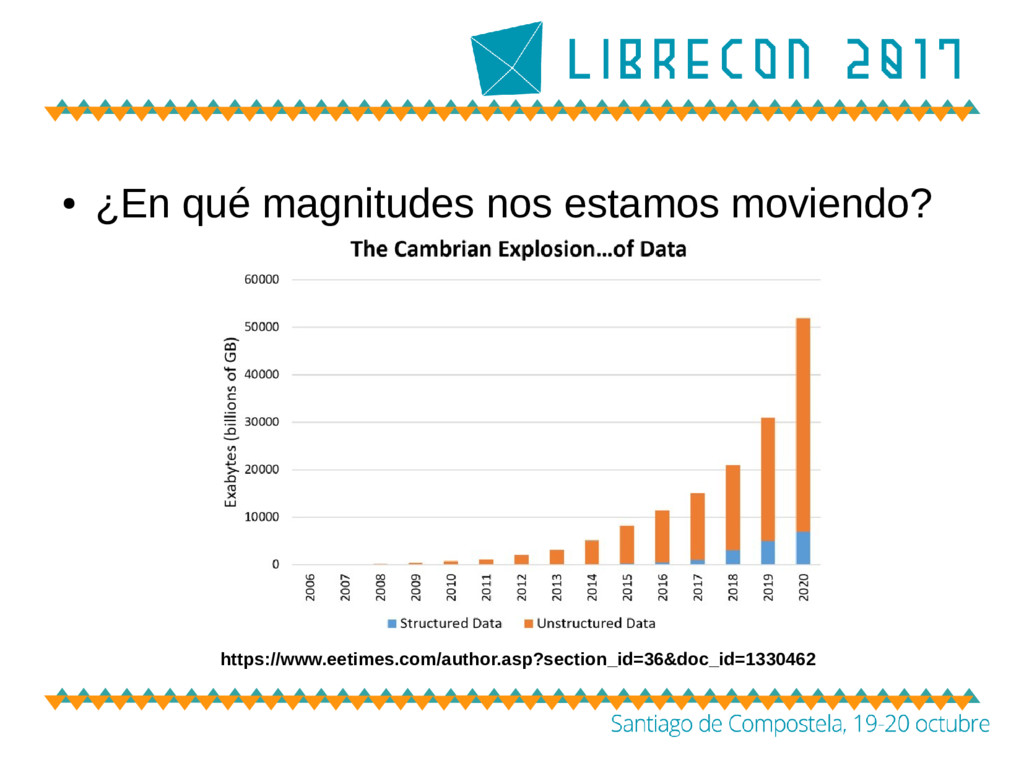
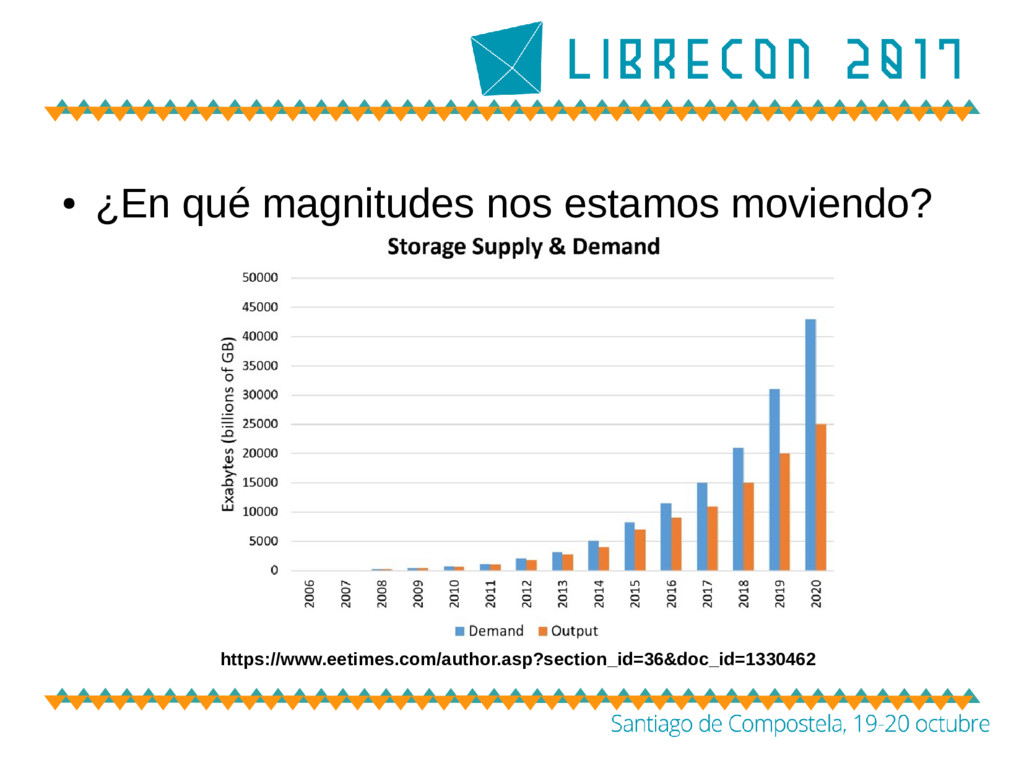
masivo de datos – Un crecimiento en hyperescala – Arquitecturas de almacenamiento tradicionales rígidas y poco flexibles • ¿Quién tiene este problema? – Actores de nube • Centros Científicos (ej. CERN) • Las llamadas ‘GAFA’ (Google, Apple, Facebook, Amazon) • Universidades (ej. OpenStack) • Proveedores Cloud independientes • ...
almacenamiento tradicionales • No gestionan de forma inteligente los metadatos • Usan y mantienen tablas de búsqueda para gestionar los metadatos • Los metadatos son datos que permiten conocer donde se almacenan los datos • Para sistemas de almacenamiento modestos puede no apreciarse problemas de rendimiento pero esto limita la escalabilidad del sistema
través de una arquitectura de almacenamiento de datos basada en objetos – Arquitectura diseñada para retener cantidades masivas de datos – Objeto • datos, metadatos y un identificador global único
emplea la abstracción de objeto como un bloque de construcción – Cualquier tipo de dato (bloque, fichero, objeto, etc) se almacena en forma de objeto en el cluster – Solución a las necesidades actuales y futuras de almacenamiento no estructurado – Ceph replica estos objetos nativos para mejorar la disponibilidad y confiabilidad de los datos – El almacenamiento de los objetos es flexible y no está predeterminado a nivel físico – Este diseño permite escalar linealmente del petabyte al exabyte
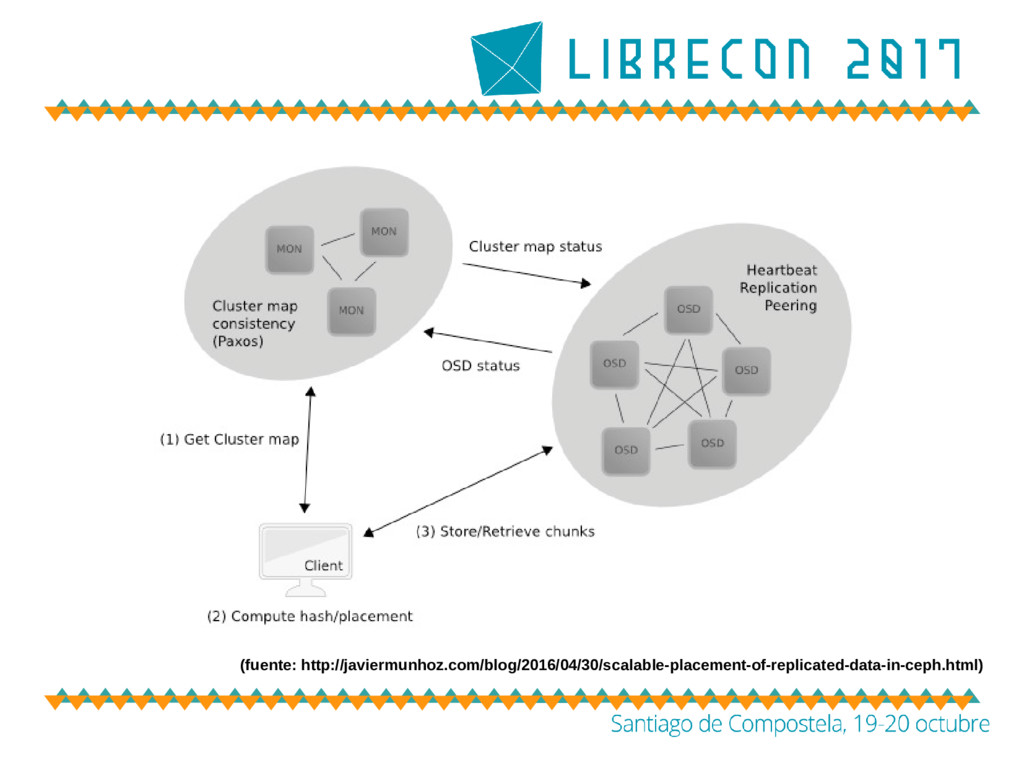
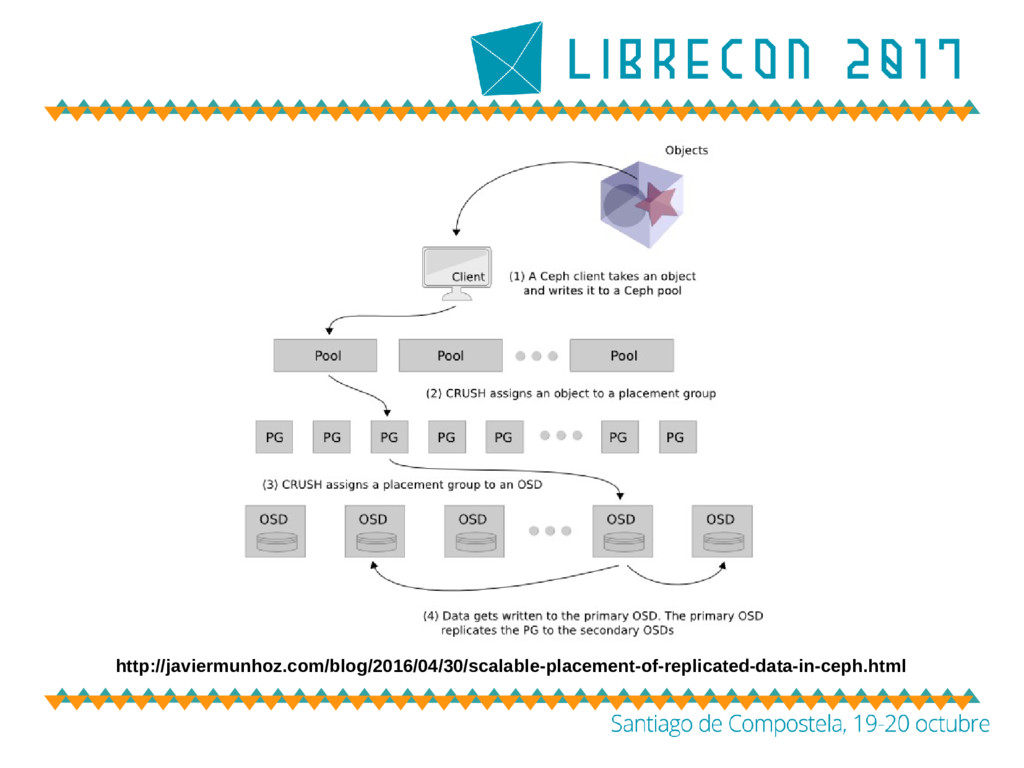
no trata de buscar la localización de un objeto a través de tablas y estructuras intermedias. Ceph computa esta localización a través de CRUSH – CRUSH es un algoritmo y un conjunto de reglas que se aplican a un estado conocido del cluster – Controlled Replication Under Scalable Hashing – CRUSH es consciente de la geometría del cluster y gestiona las zonas de fallo a través de su mapa de forma autónoma
Gestionan los mapa/s del cluster (CRUSH) • Un cluster suele tener más de un monitor. En este caso llegan a consenso a través de Paxos • Mantienen un diálogo con todos los componentes que necesiten conocer la geometría del cluster y sus actualizaciones
Device’ • Su responsabilidad principal es almacenar los bloques de datos y los metadatos • Para garantizar la disponibilidad por replicación se necesitan 3 replicas • Mantienen un diálogo entre ellos para acordar su estado de replicación, comprobar que sus datos no están corruptos, etc. • Mantienen un diálogo con los monitores para actualizar la geometría del cluster
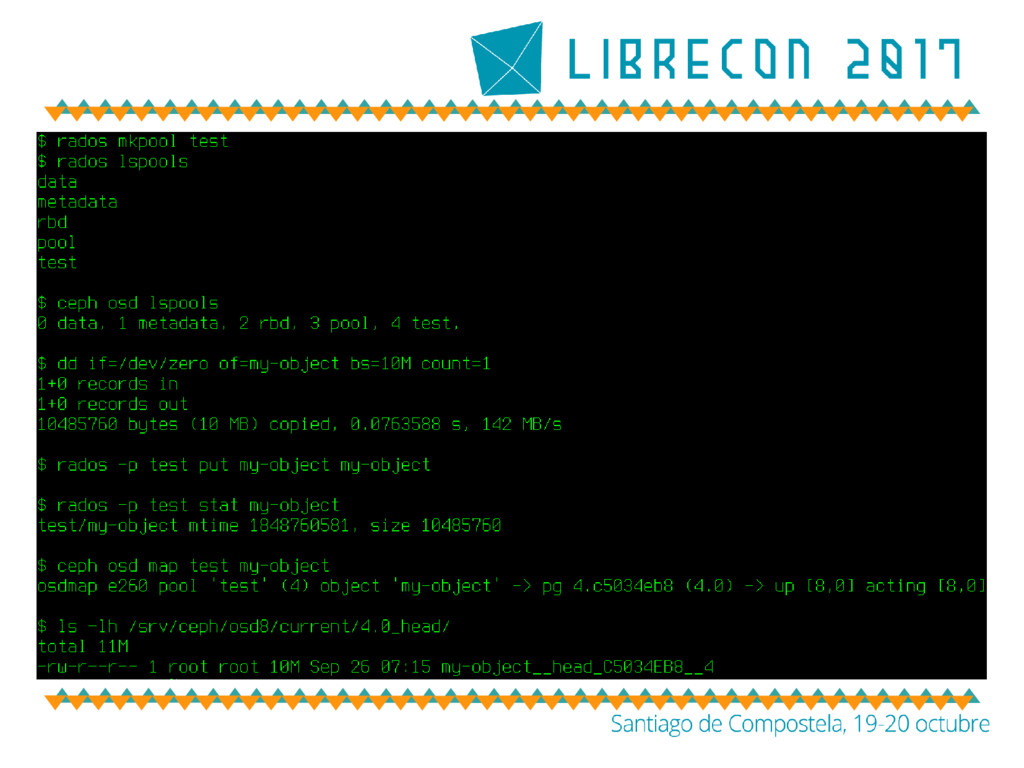
almacenamiento global en ‘pools’ • Un ‘pool’ es una división lógica • Sobre esta abstracción se aplican las políticas de replicación, el control de acceso, etc • Ceph crea un ‘pool’ por defecto tras la instalación
– Almacenamiento para Internet – Web service interface (REST, SOAP) – Permite almacenar objetos (1 byte a 5 GB) – Los objetos contienen datos y metadatos – Los objetos son almacenados y recuperados usando una clave (key) – Los objetos son accesibles vía http, bittorrent, etc.
almacenados en ‘buckets’ – Un bucket es un contenedor para objetos • mybucket.s3.amazonaws.com – Los buckets son útiles para particionar a nivel raíz – Una ‘key’ (clave) es el identificador único para un objeto dentro de un ‘bucket’ – Ejemplo: • http://mybucket.s3.amazonaws.com/myhome.html
a la API S3 (GET Object) • Obtiene los primeros 10 bytes de un objeto (test.txt) en el bucket ‘examplebucket’ GET /test.txt HTTP/1.1 Host: examplebucket.s3.amazonaws.com x-amz-date:20130524T000000Z Authorization: SignatureToBeCalculated Range: bytes=0-9 x-amz-content- sha256:e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855 x-amz-date: 20130524T000000Z
etc. (RGW/S3) • Estrategia de líder frente a perseguidor – innovación vs interoperabilidad – cobertura de RGW/S3 vs AWS/S3 • Riesgos – obsolescencia/sustitución de funcionalides • ej. AWS2/AWS4 • Innovación • ej. ‘Smart Buckets’
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}