ICIAP 2017] 12 > 料理ドメインにおいてもCNN-based featuresが有用なのかを検証する > 料理の524クラス分類のタスクでResNet-50をfine-tuning > Classification Accuracy: 69.52% for the Top-1, and 89.61% for the Top-5 > 最後のFCから特徴抽出
gist descriptors for web-scale image search." Proceedings of the ACM International Conference on Image and Video Retrieval. ACM, 2009. • [Zheng+, 2018] ◦ Zheng, Liang, Yi Yang, and Qi Tian. "SIFT meets CNN: A decade survey of instance retrieval." IEEE transactions on pattern analysis and machine intelligence 40.5 (2018): 1224-1244. • [Razavian+, 2014] ◦ Sharif Razavian, Ali, et al. "CNN features off-the-shelf: an astounding baseline for recognition." Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2014. • [Ng+, 2015] ◦ Yue-Hei Ng, Joe, Fan Yang, and Larry S. Davis. "Exploiting local features from deep networks for image retrieval." Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2015. 参考文献 35
and classification of food images." Computers in biology and medicine 77 (2016): 23-39. • [Ciocca+ , ICIAP 2017] ◦ Ciocca, Gianluigi, Paolo Napoletano, and Raimondo Schettini. "Learning cnn-based features for retrieval of food images." International Conference on Image Analysis and Processing. Springer, Cham, 2017. • [Shimoda+ , BigMM 2017] ◦ Shimoda, Wataru, and Keiji Yanai. "Learning food image similarity for food image retrieval." 2017 IEEE Third International Conference on Multimedia Big Data (BigMM). IEEE, 2017. • [Salvador+ , CVPR 2017] ◦ Salvador, Amaia, et al. "Learning cross-modal embeddings for cooking recipes and food images." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. • [Carvalho+ , SIGIR 2018] ◦ Carvalho, Micael, et al. "Cross-modal retrieval in the cooking context: Learning semantic text-image embeddings." The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. ACM, 2018. 参考文献 36
Qi Tian. "Recent advance in content-based image retrieval: A literature survey." arXiv preprint arXiv:1706.06064 (2017). • [Bromley+, 1994] ◦ Bromley, Jane, et al. "Signature verification using a" siamese" time delay neural network." Advances in neural information processing systems. 1994. • [Wang+, 2014] ◦ Wang, Jiang, et al. "Learning fine-grained image similarity with deep ranking." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014. • [Kawano+, 2014] ◦ Kawano, Yoshiyuki, and Keiji Yanai. "Automatic expansion of a food image dataset leveraging existing categories with domain adaptation." European Conference on Computer Vision. Springer, Cham, 2014. 37
{kind=link}
![自己紹介 2 • 三條 智史 [ @johshisha ] • 同志社大学大学院](https://files.speakerdeck.com/presentations/65939faa5b374d5fbb306af8055a7ef3/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
![画像検索の流れ [Zhou+, 2017] より引用 主にこの辺について話します 5](https://files.speakerdeck.com/presentations/65939faa5b374d5fbb306af8055a7ef3/slide_4.jpg){kind=link}
![> hand-craftな大域特徴 (global feature)ベース > 画像から一つの特徴ベクトルを得る > カラーヒストグラムやGISTなど [Douze+, 2009]](https://files.speakerdeck.com/presentations/65939faa5b374d5fbb306af8055a7ef3/slide_5.jpg){kind=link}
![> CNNの大域特徴ベース > 一般物体認識や様々な分野でのCNNの性能向上に触発 > pretrained modelの特徴量使ったり,fine-tuningしたり [Razavian+, 2014] >](https://files.speakerdeck.com/presentations/65939faa5b374d5fbb306af8055a7ef3/slide_6.jpg){kind=link}
![> 基本的には一般的な画像検索と同じ流れ(後追い) > hand-craftな特徴を用いた手法 [Farinella+, 2016] > CNNによる大域特徴を用いた手法 > (次はCNNによる局所特徴を用いた手法が来る?)](https://files.speakerdeck.com/presentations/65939faa5b374d5fbb306af8055a7ef3/slide_7.jpg){kind=link}
![> 基本的には一般的な画像検索と同じ流れ(後追い) > hand-craftな特徴を用いた手法 [Farinella+, 2016] > CNNによる大域特徴を用いた手法 > (次はCNNによる局所特徴を用いた手法が来る?)](https://files.speakerdeck.com/presentations/65939faa5b374d5fbb306af8055a7ef3/slide_8.jpg){kind=link}
![> 基本的には一般的な画像検索と同じ流れ(後追い) > hand-craftな特徴を用いた手法 [Farinella+, 2016] > CNNによる大域特徴を用いた手法 > (次はCNNによる局所特徴を用いた手法が来る?)](https://files.speakerdeck.com/presentations/65939faa5b374d5fbb306af8055a7ef3/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
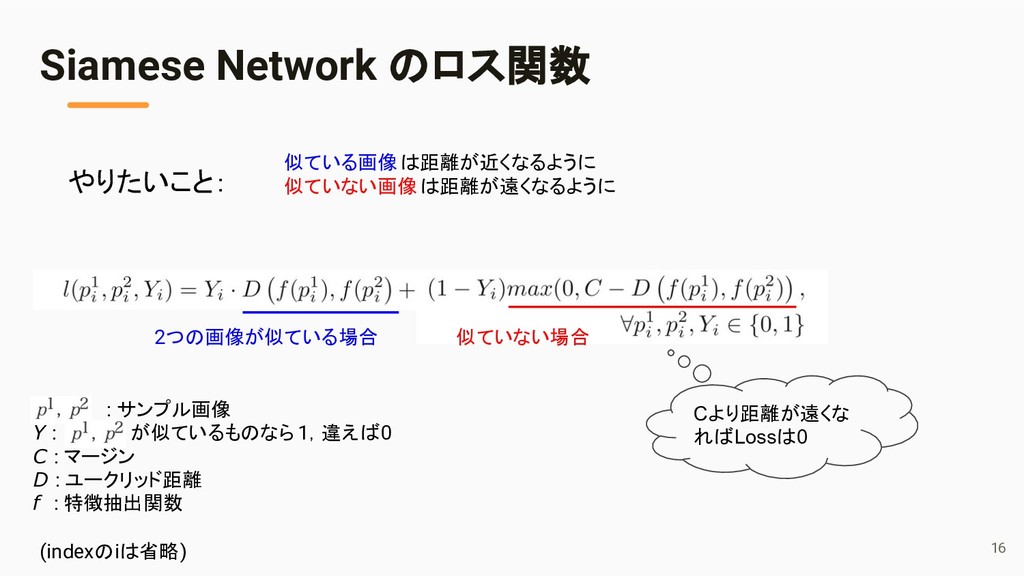
![> Siamese Network [Bromley+, 1994] > クエリと対象サンプル > 似ている場合は近くなるように >](https://files.speakerdeck.com/presentations/65939faa5b374d5fbb306af8055a7ef3/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![> データセット: UEC-FOOD256 [Kawano+, 2014] > 256クラス,100枚/class,25,600枚 > タスク >](https://files.speakerdeck.com/presentations/65939faa5b374d5fbb306af8055a7ef3/slide_18.jpg){kind=link}
![> 基本的には一般的な画像検索と同じ流れ(後追い) > hand-craftな特徴を用いた手法 [Farinella+, 2016] > CNNによる大域特徴を用いた手法 > (次はCNNによる局所特徴を用いた手法が来る?)](https://files.speakerdeck.com/presentations/65939faa5b374d5fbb306af8055a7ef3/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
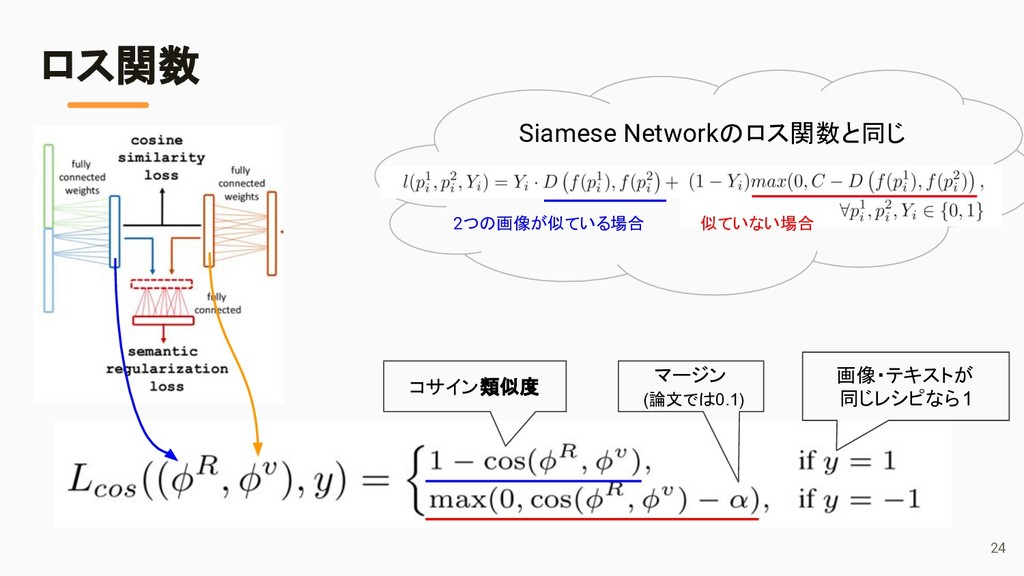{kind=link}
{kind=link}
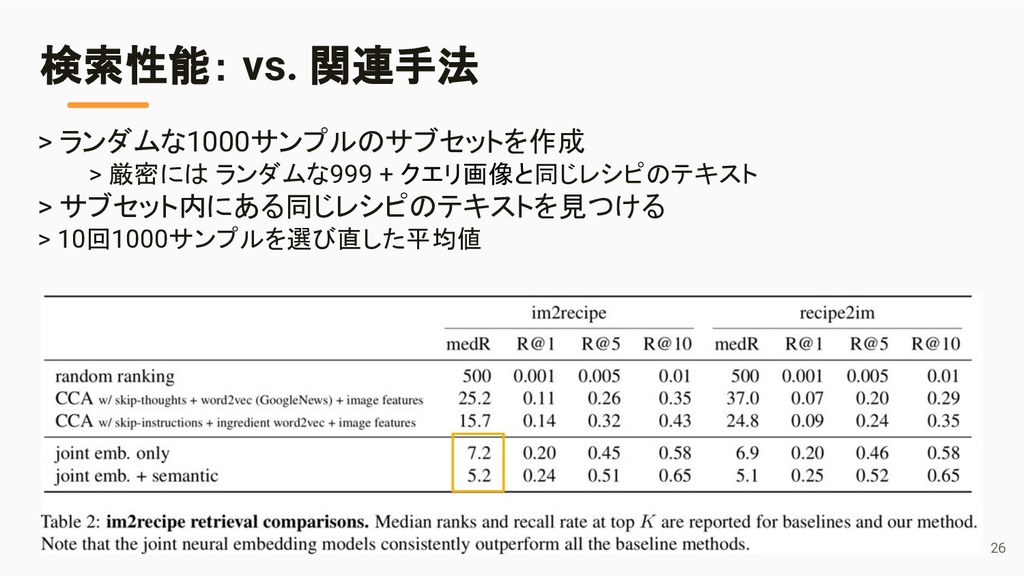{kind=link}
{kind=link}
{kind=link}
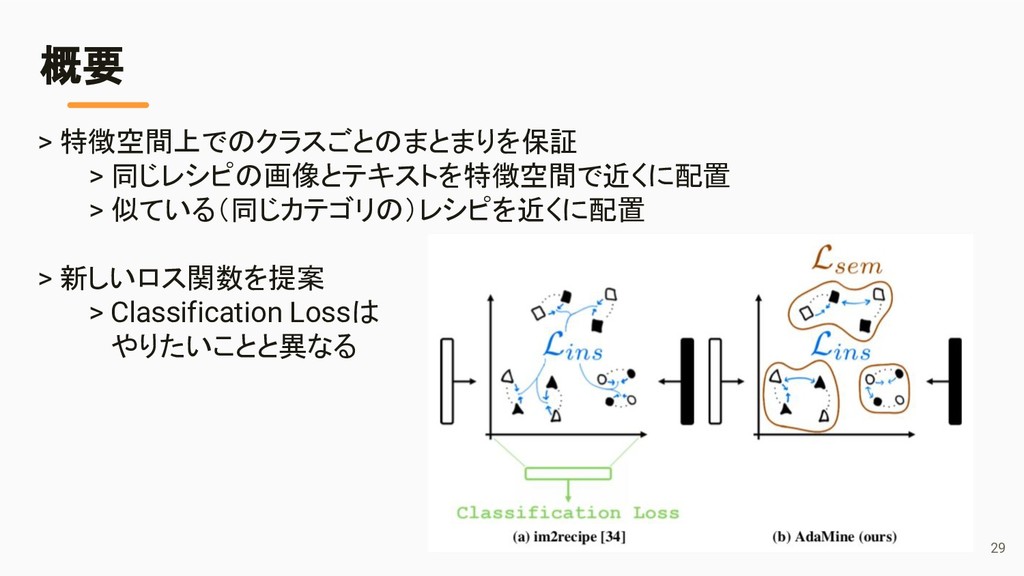{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• [Douze+, 2009] ◦ Douze, Matthijs, et al. "Evaluation of](https://files.speakerdeck.com/presentations/65939faa5b374d5fbb306af8055a7ef3/slide_34.jpg){kind=link}
![• [Farinella+, 2016] ◦ Farinella, Giovanni Maria, et al. "Retrieval](https://files.speakerdeck.com/presentations/65939faa5b374d5fbb306af8055a7ef3/slide_35.jpg){kind=link}
![参考文献 • [Zhou+, 2017] ◦ Zhou, Wengang, Houqiang Li, and](https://files.speakerdeck.com/presentations/65939faa5b374d5fbb306af8055a7ef3/slide_36.jpg){kind=link}