This is a presentation I gave about my participation in Kaggle's "Allstate Purchase Prediction Challenge."
Presentation recording: http://youtu.be/HGr1yQV3Um0
Blog post: http://dataschool.io/kaggle-allstate-purchase-prediction-challenge/
Project paper and code: https://github.com/justmarkham/kaggle-allstate
Competition website: http://www.kaggle.com/c/allstate-purchase-prediction-challenge
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
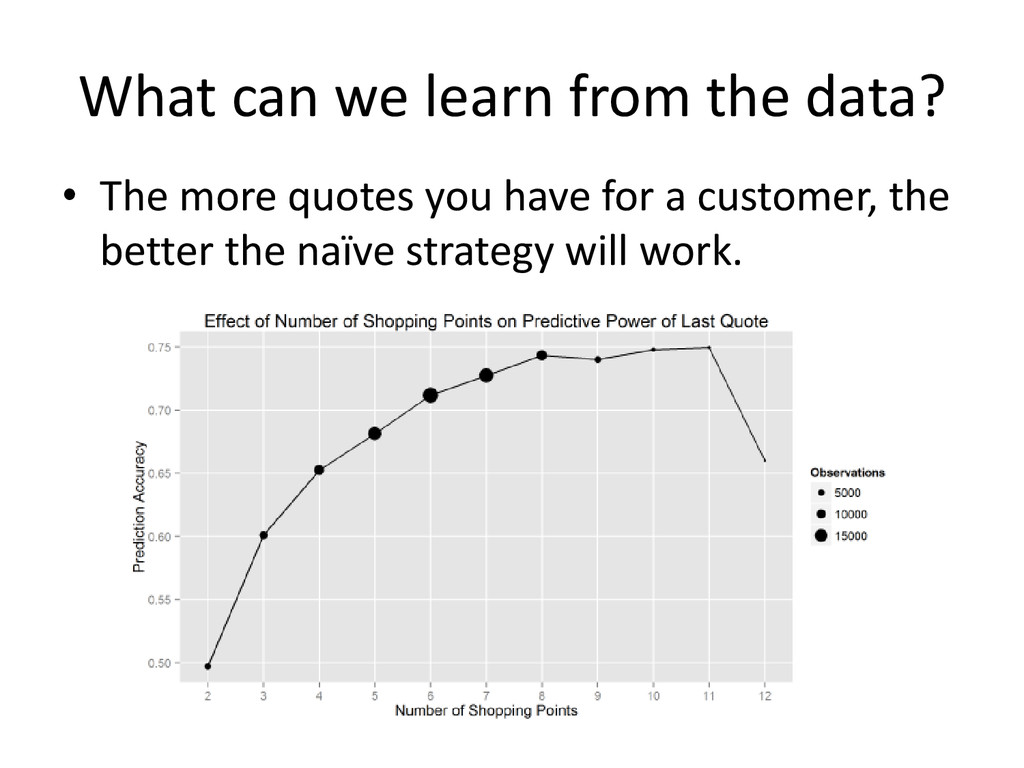{kind=link}
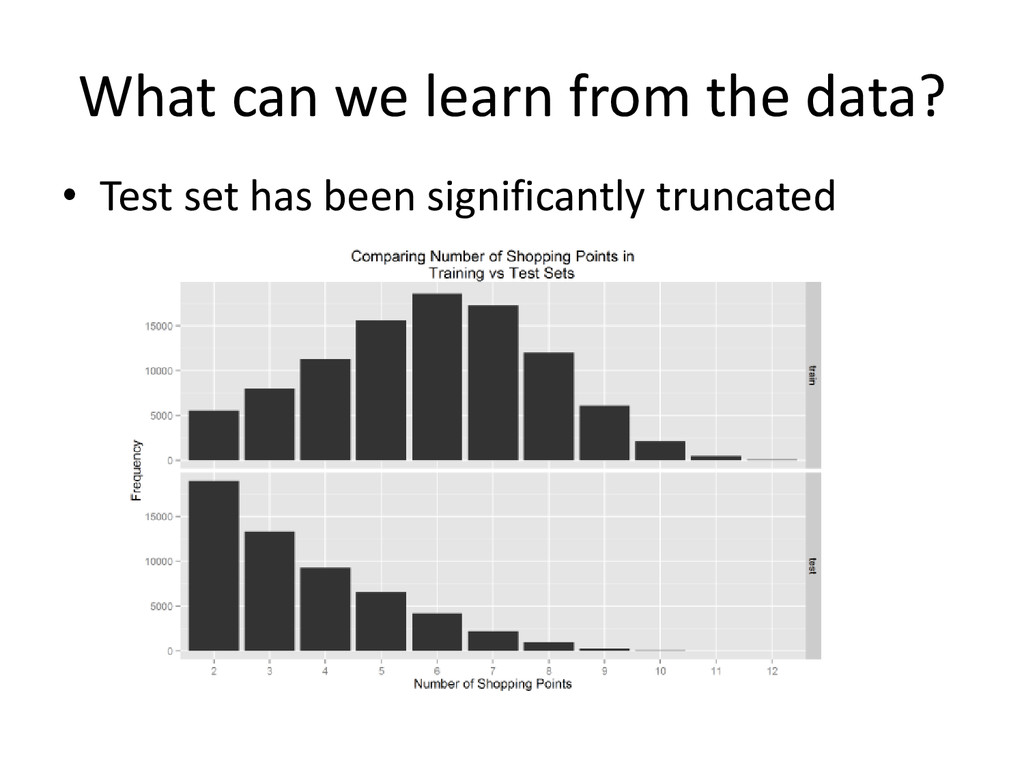{kind=link}
{kind=link}
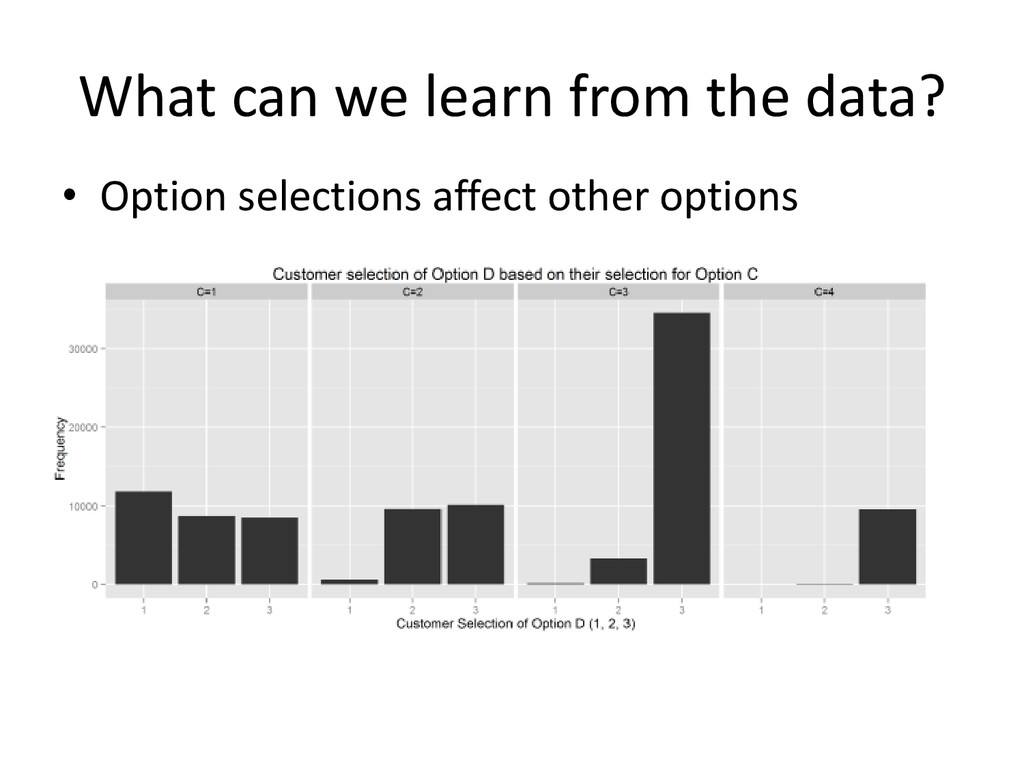{kind=link}
{kind=link}
{kind=link}
{kind=link}
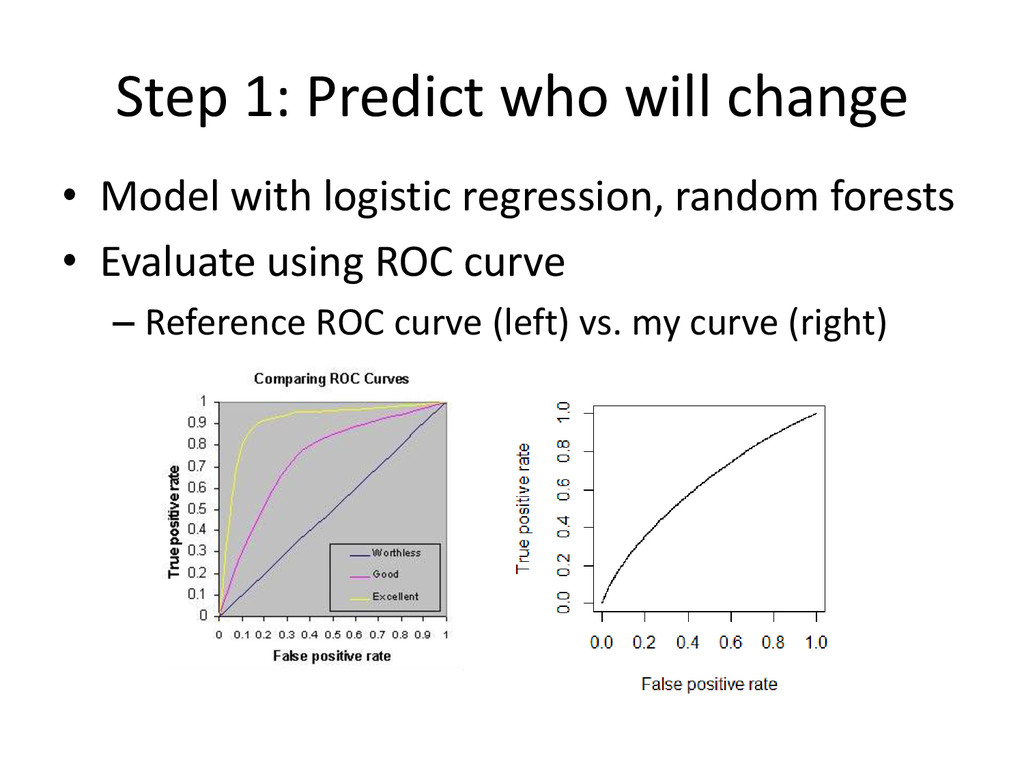{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}