Should Be Treated? Empirical Welfare Maximization Methods for Treatment Choice,” Econometrica, 86, 591–616. • Garivier, A. and Kaufmann, E. (2016), “Optimal Best Arm Identification with Fixed Confidence,” in Conference on Learning Theory. • Glynn, P. and Juneja, S. (2004), “A large deviations perspective on ordinal optimization,” in Proceedings of the 2004 Winter Simulation Conference, IEEE, vol. 1. • Chernozhukov, V., Chetverikov, D., Demirer, M., Duflo, E., Hansen, C., Newey, W., and Robins, J. (2018), “Double/debiased machine learning for treatment and structural parameters,” The Econometrics Journal. • Degenne, R. (2023), “On the Existence of a Complexity in Fixed Budget Bandit Identification,” Conference on Learning Theory (COLT). • Kasy, M. and Sautmann, A. (2021), “Adaptive Treatment Assignment in Experiments for Policy Choice,” Econometrica, 89, 113– 132. • Rubin, D. B. (1974), “Estimating causal effects of treatments in randomized and nonrandomized studies,” Journal of Educational Psychology.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
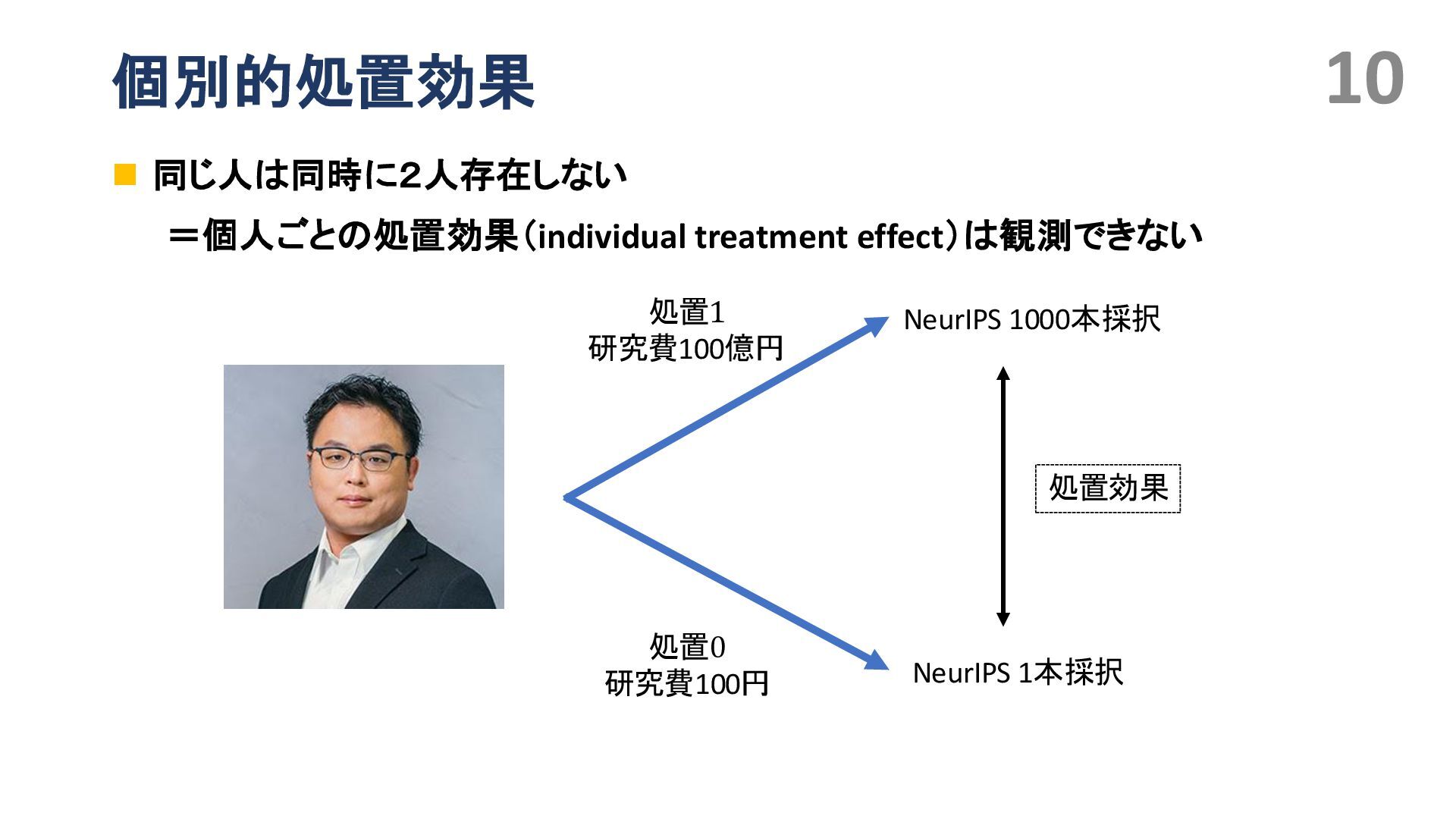{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
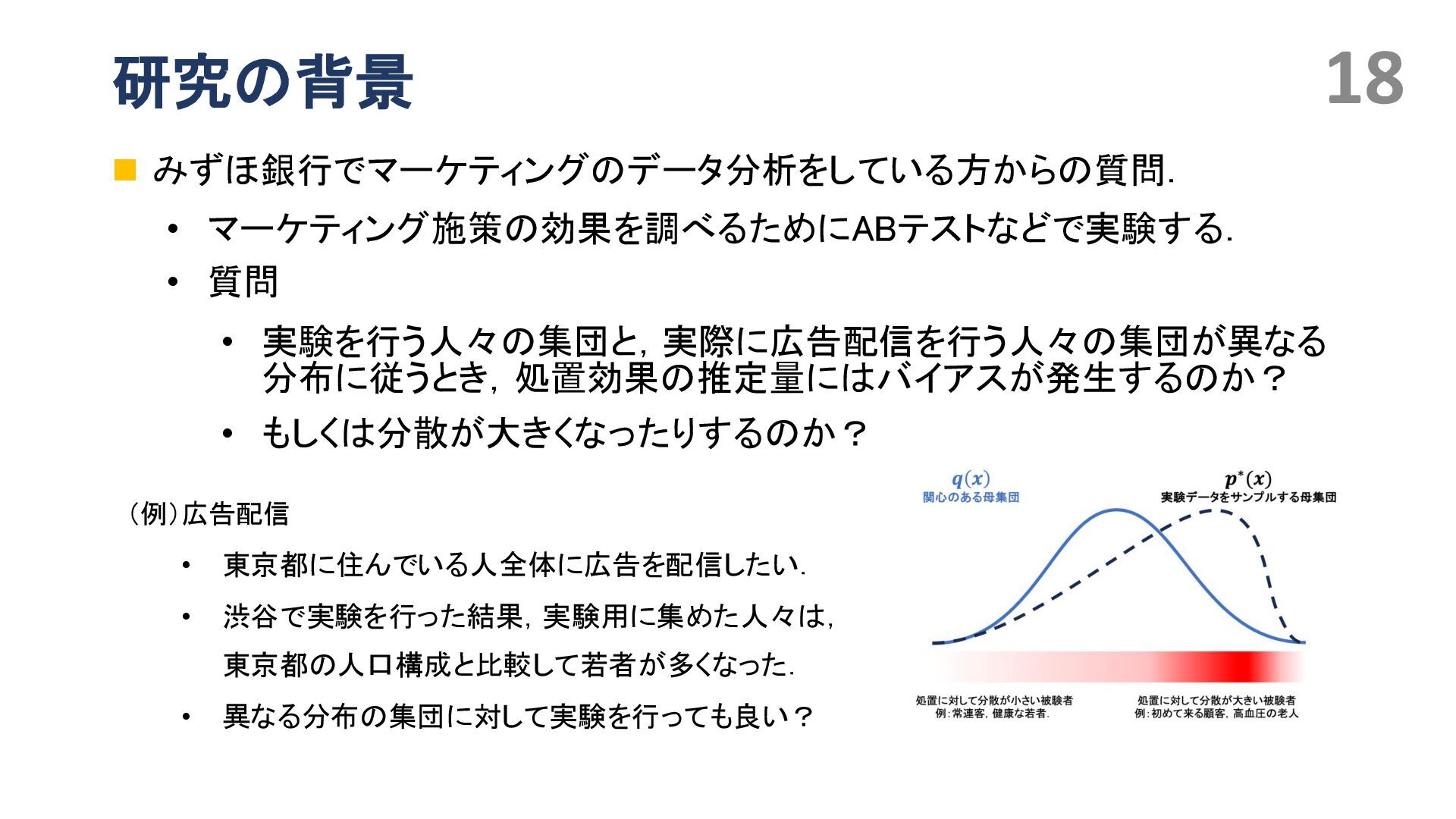{kind=link}
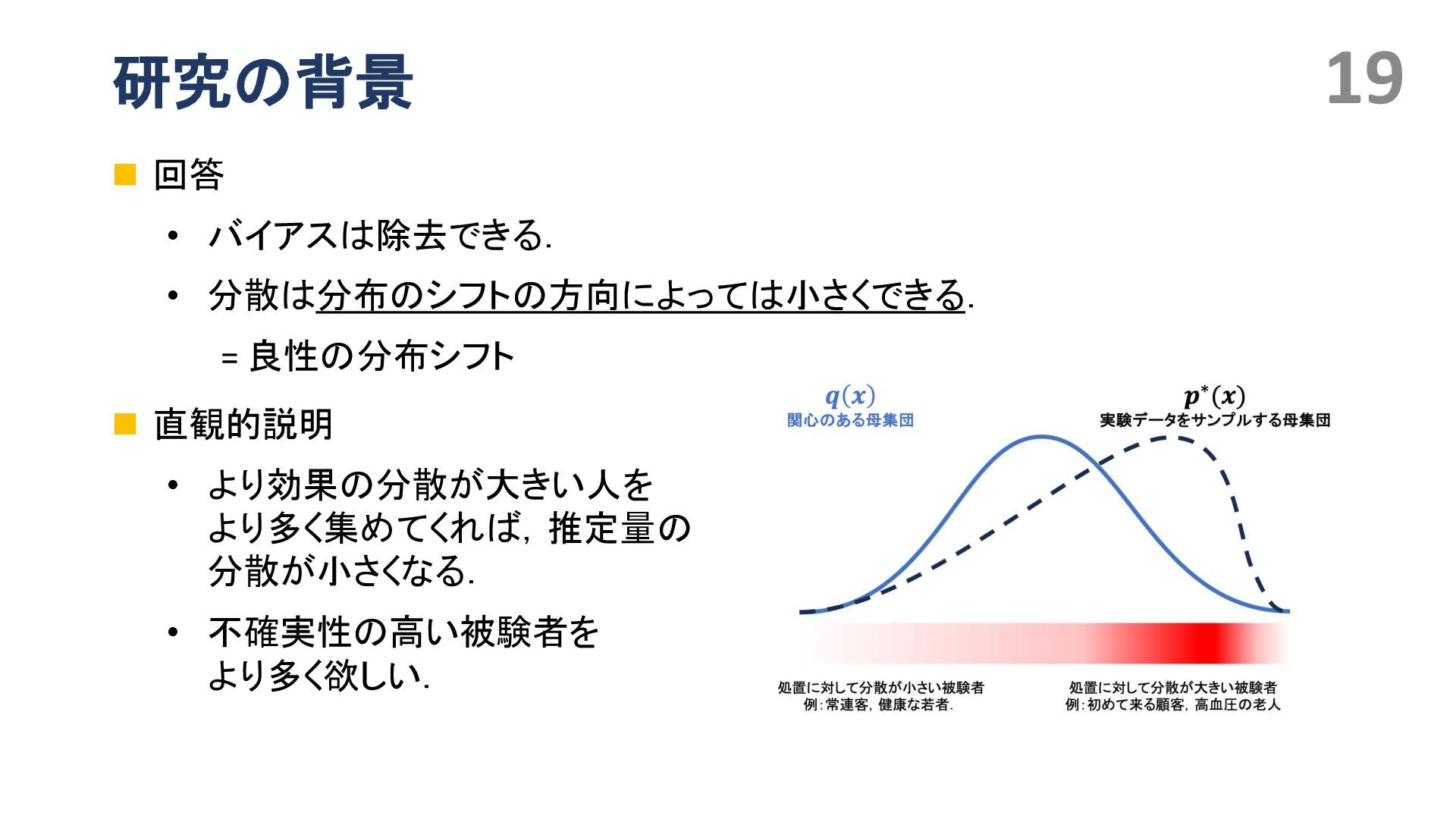{kind=link}
{kind=link}
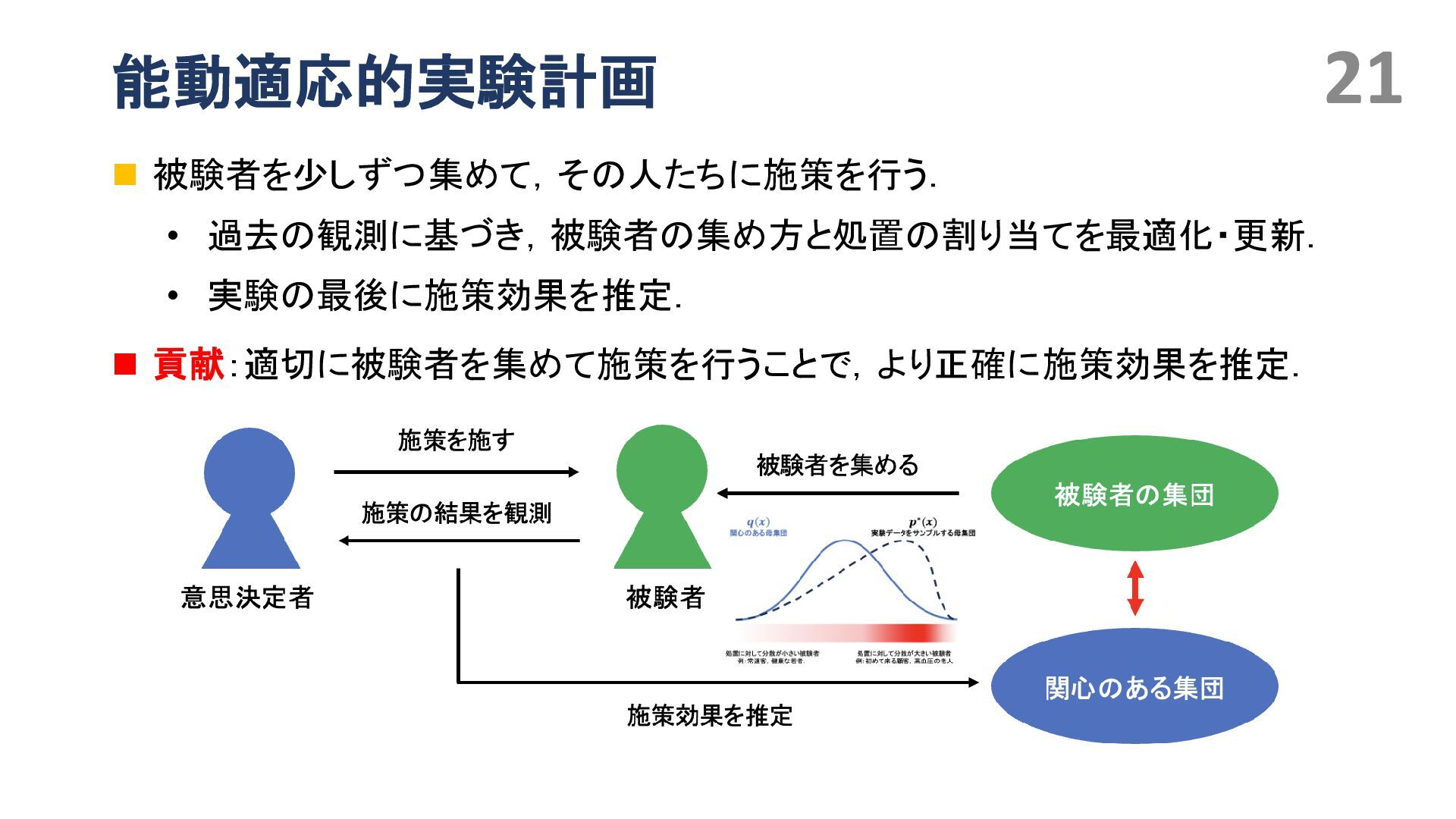{kind=link}
{kind=link}
{kind=link}
{kind=link}
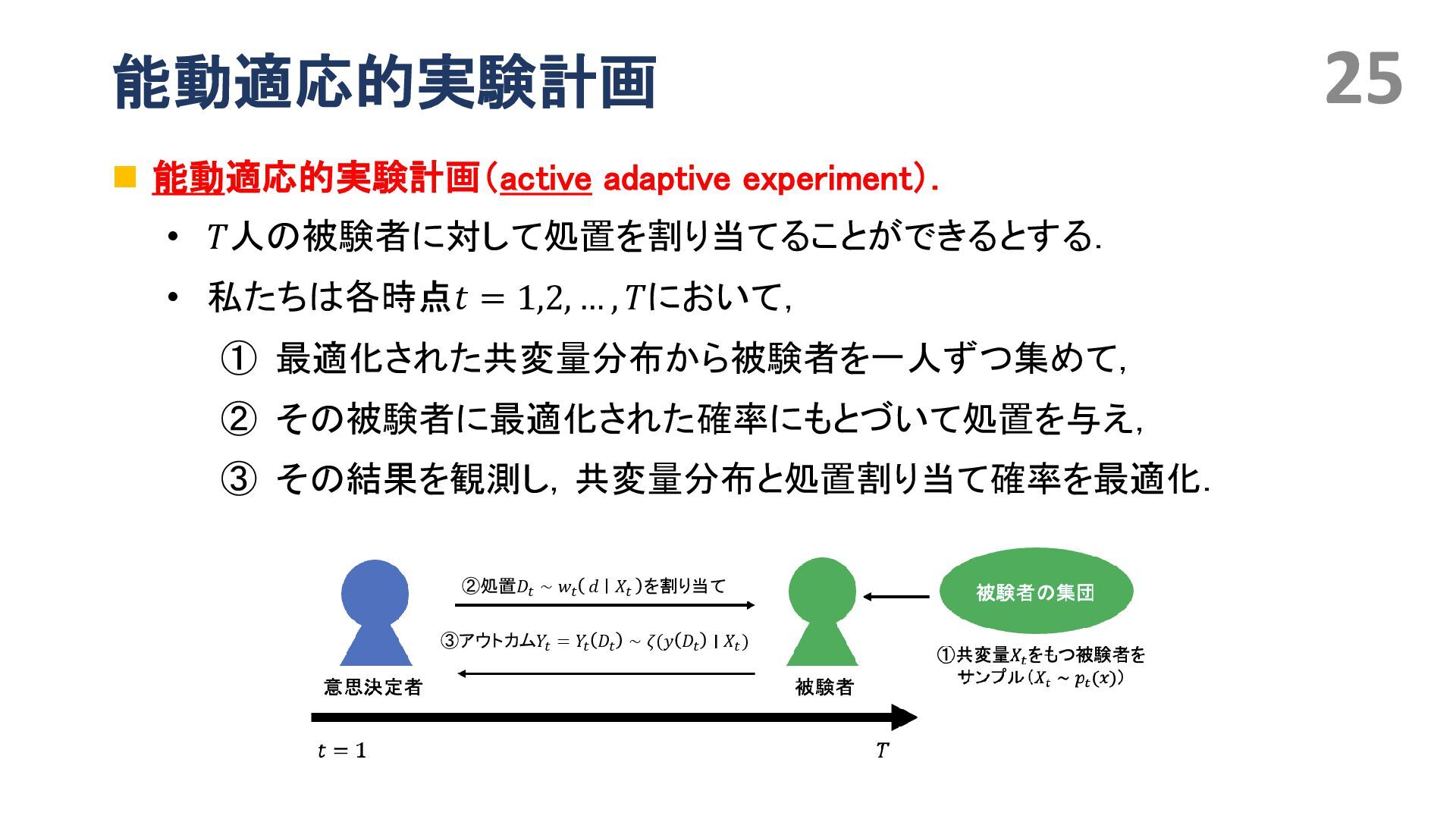{kind=link}
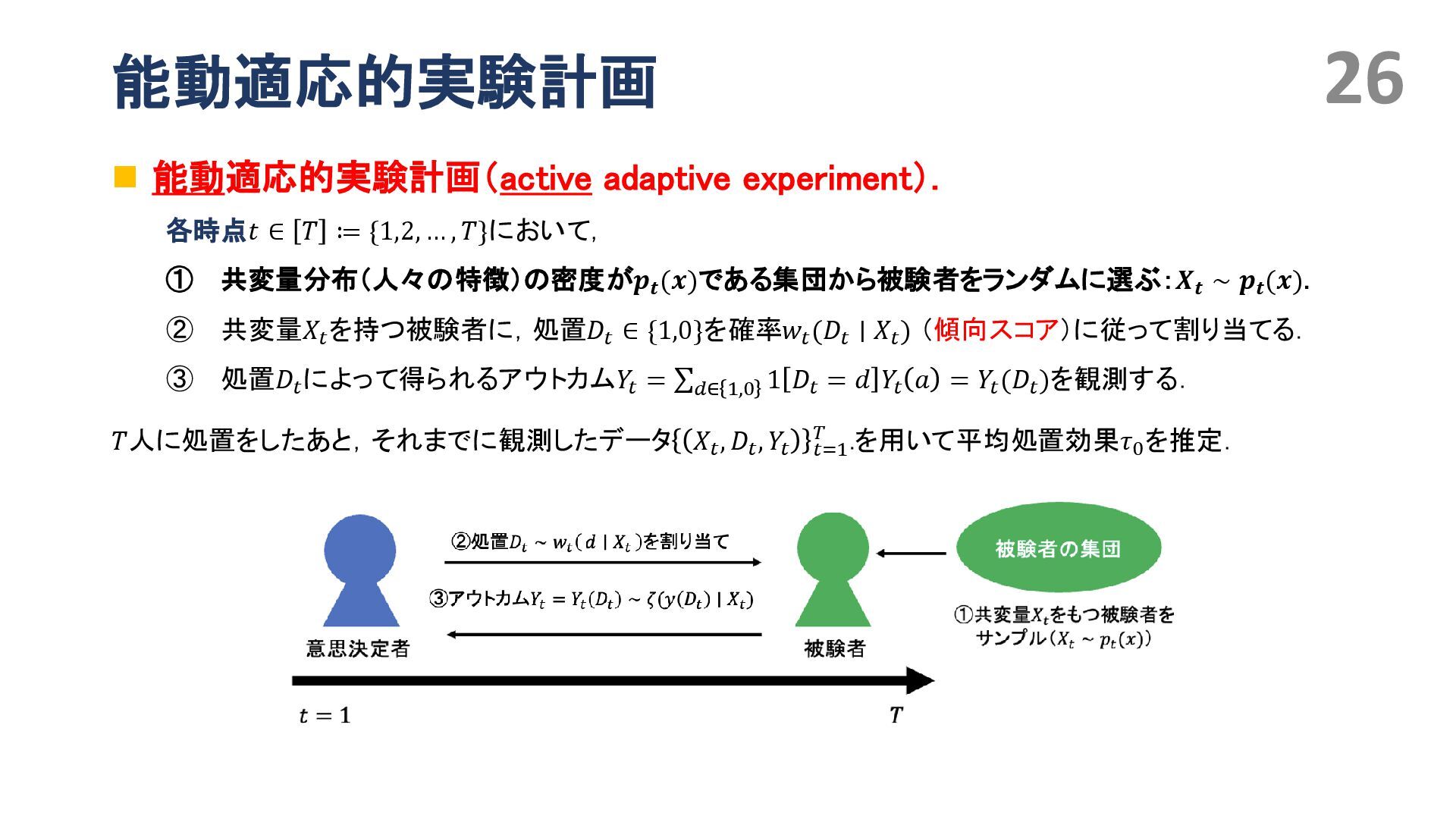{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
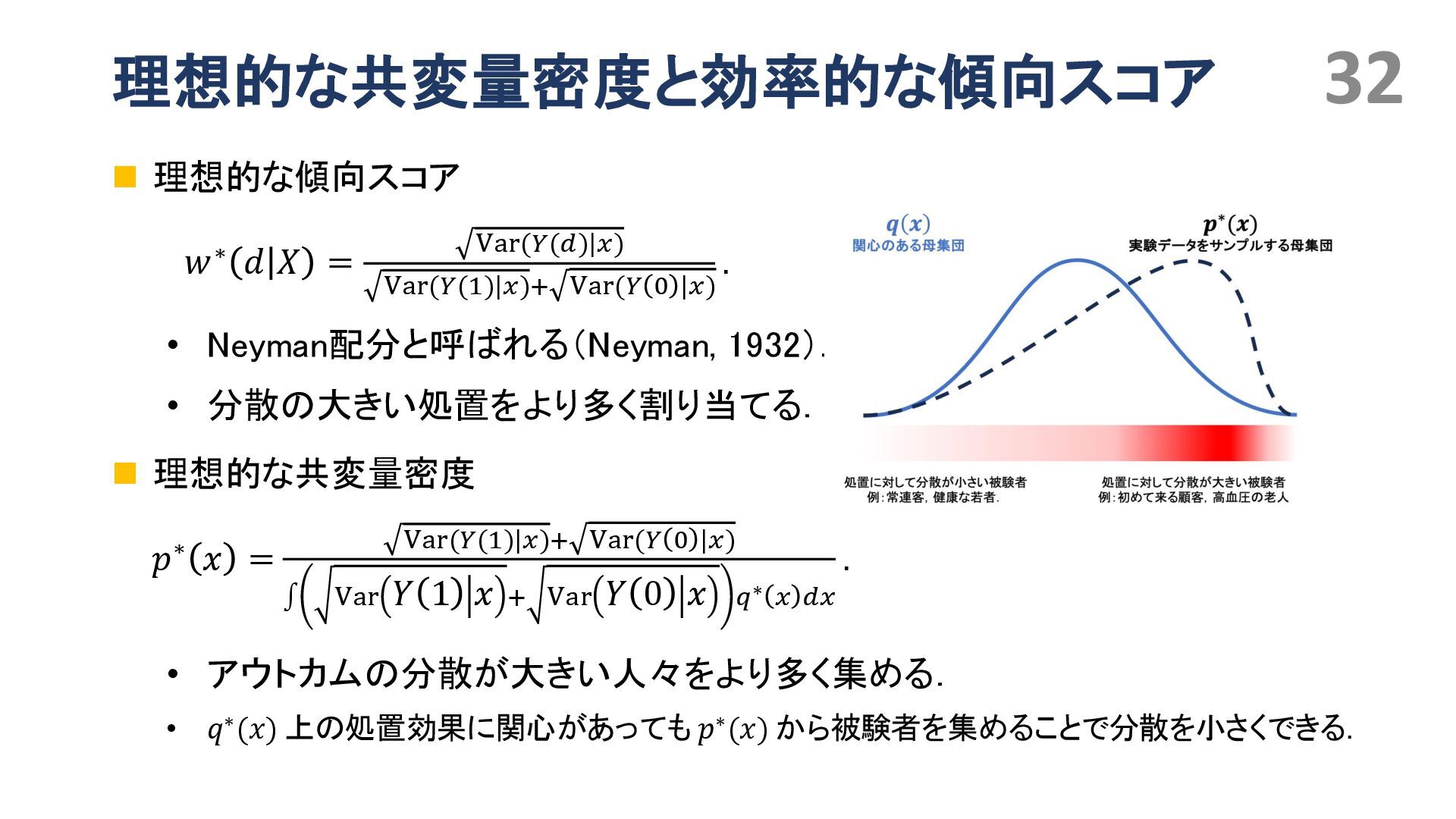{kind=link}
{kind=link}
![34 能動適応的実験計画 ◼ 条件つき分散Var(𝑌(𝑑)|𝑋)を推定し,それによって𝑝∗と𝑤∗を推定. ◼ 能動適応的実験計画: 各時点𝑡 ∈ [𝑇]において: •](https://files.speakerdeck.com/presentations/975d2d8a58864a9aa6795248efa646c4/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
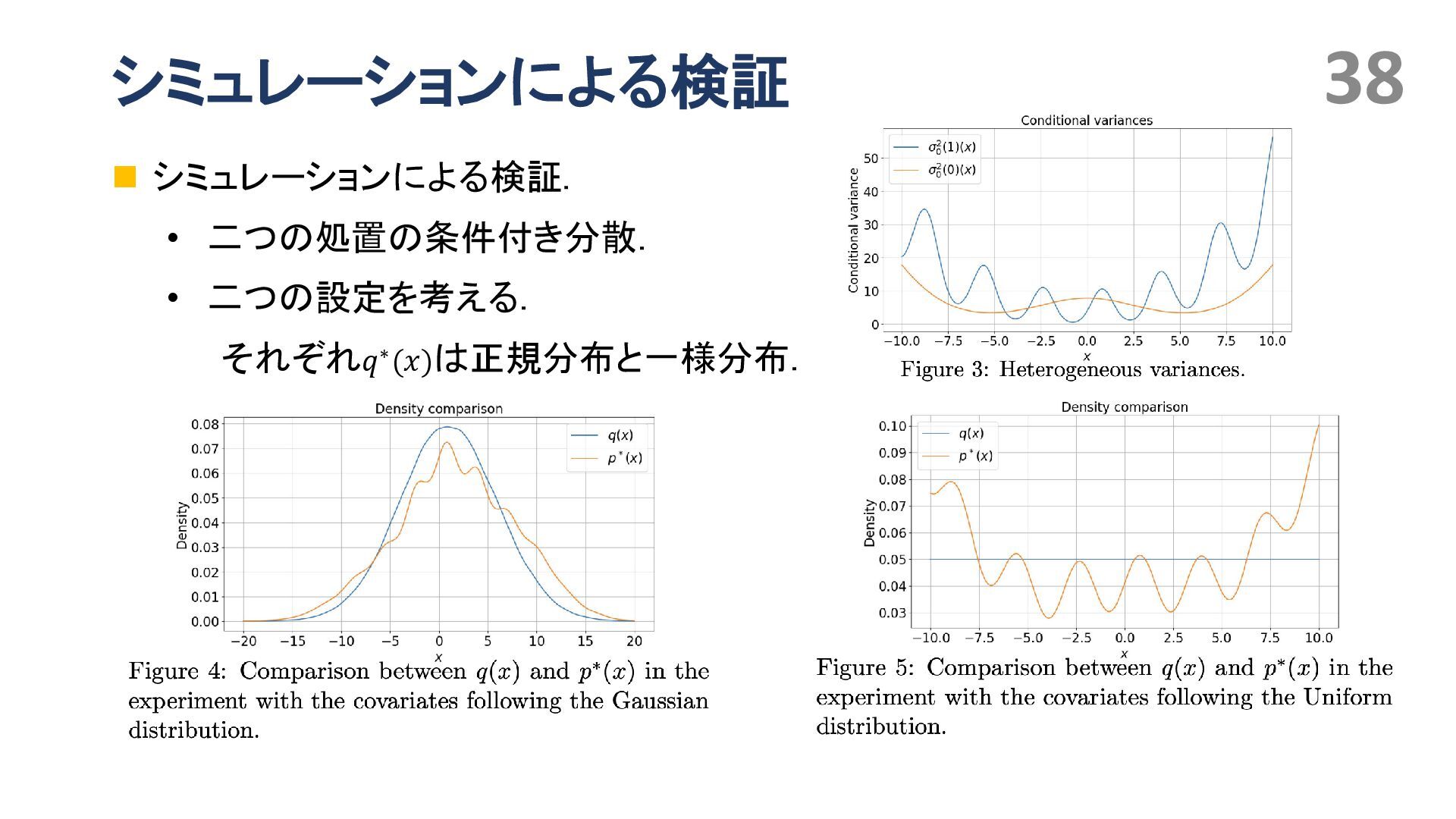{kind=link}
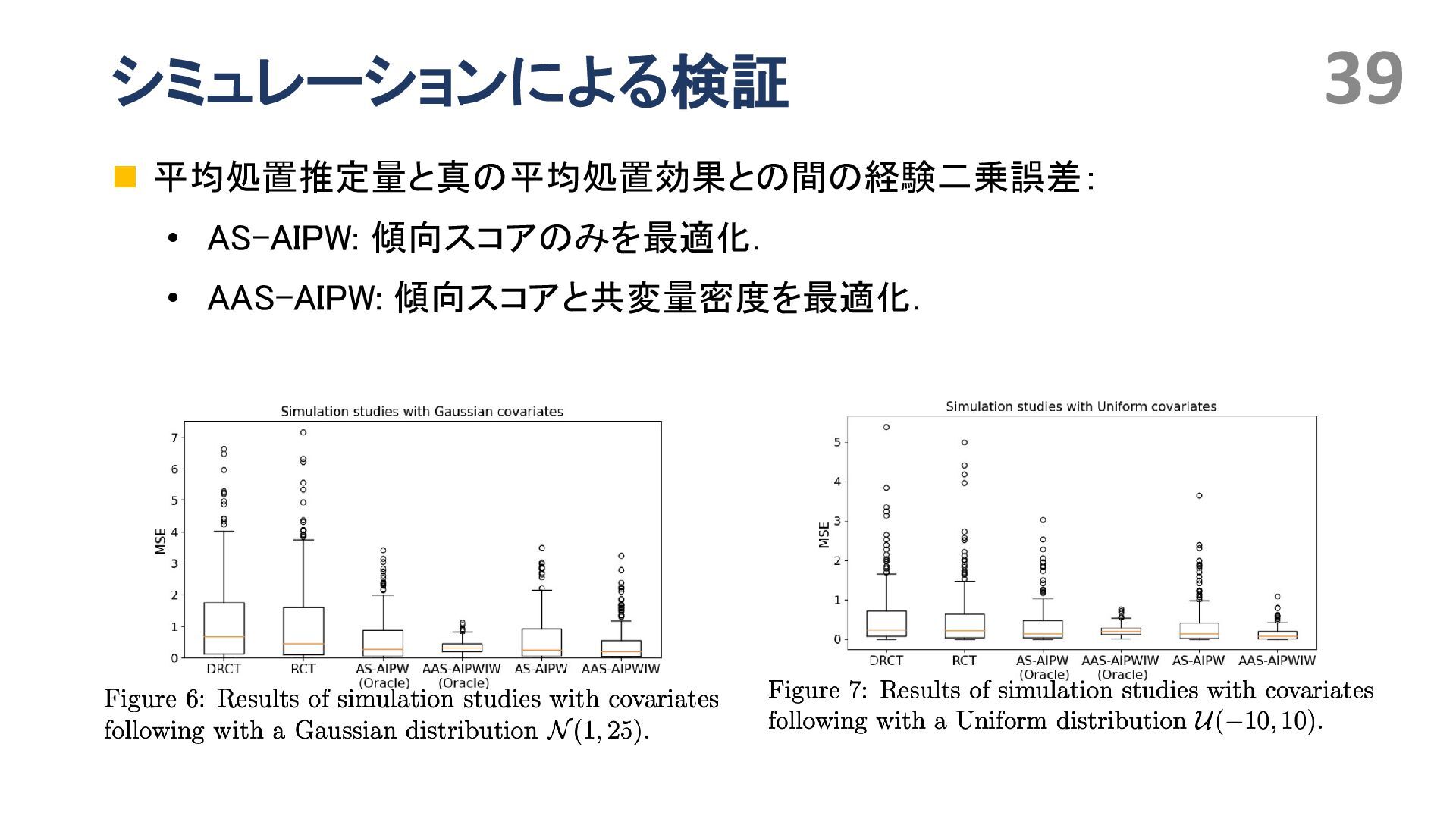{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![45 ◼ AIPW推定量: Ƹ 𝜏𝑇 = 1 𝑇 𝑡∈[𝑇]](https://files.speakerdeck.com/presentations/975d2d8a58864a9aa6795248efa646c4/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
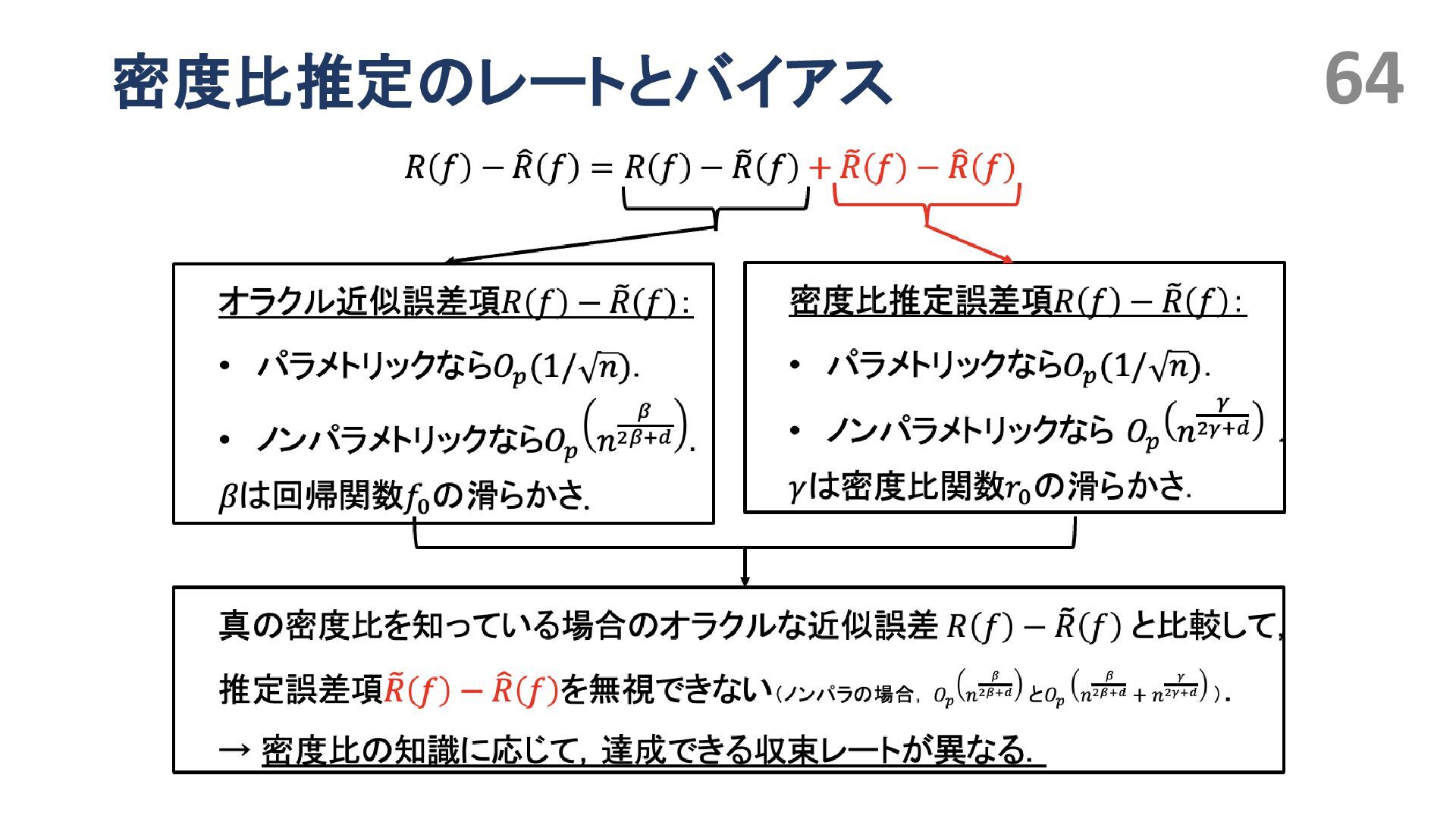{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
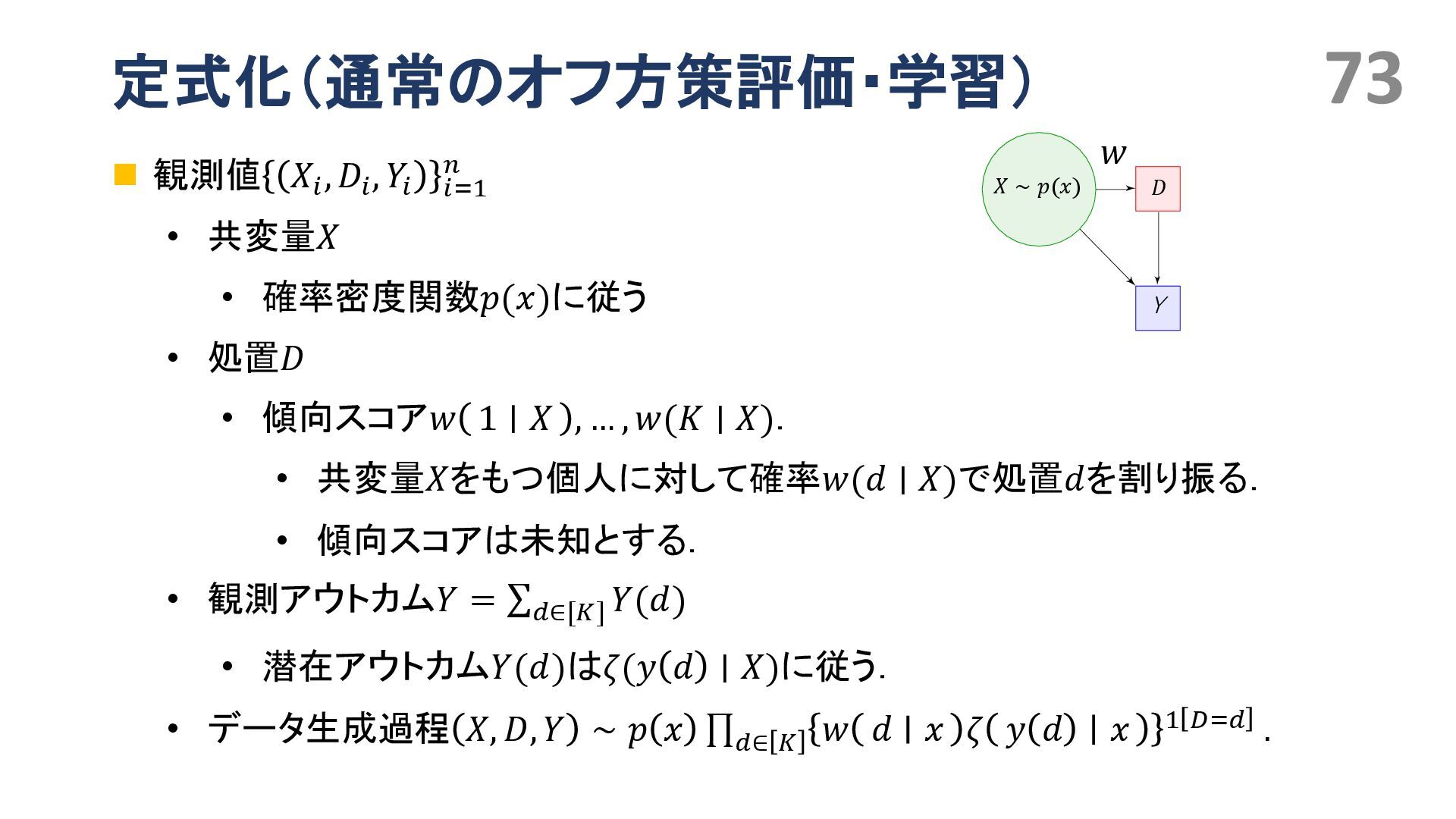{kind=link}
{kind=link}
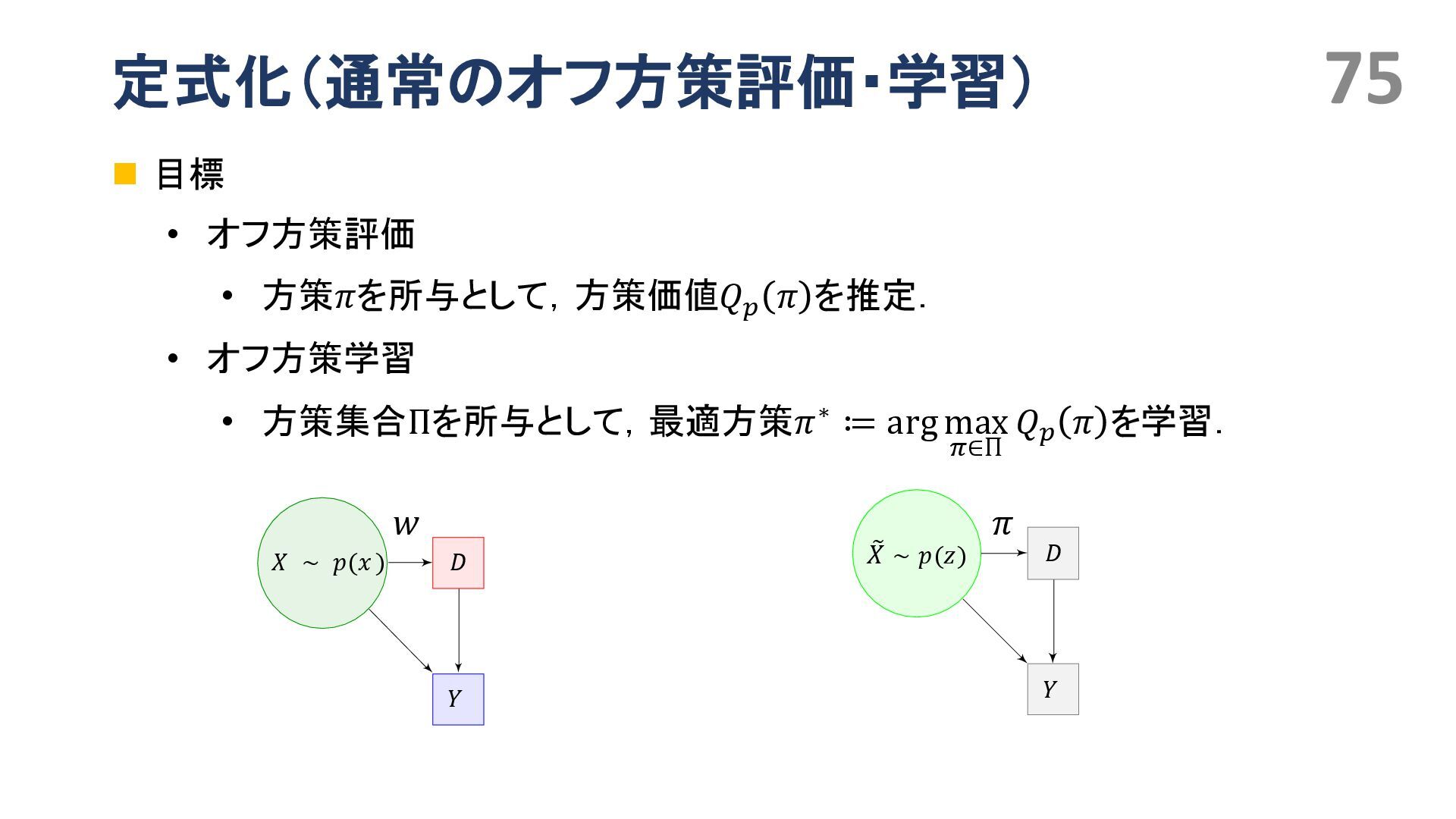{kind=link}
{kind=link}
{kind=link}
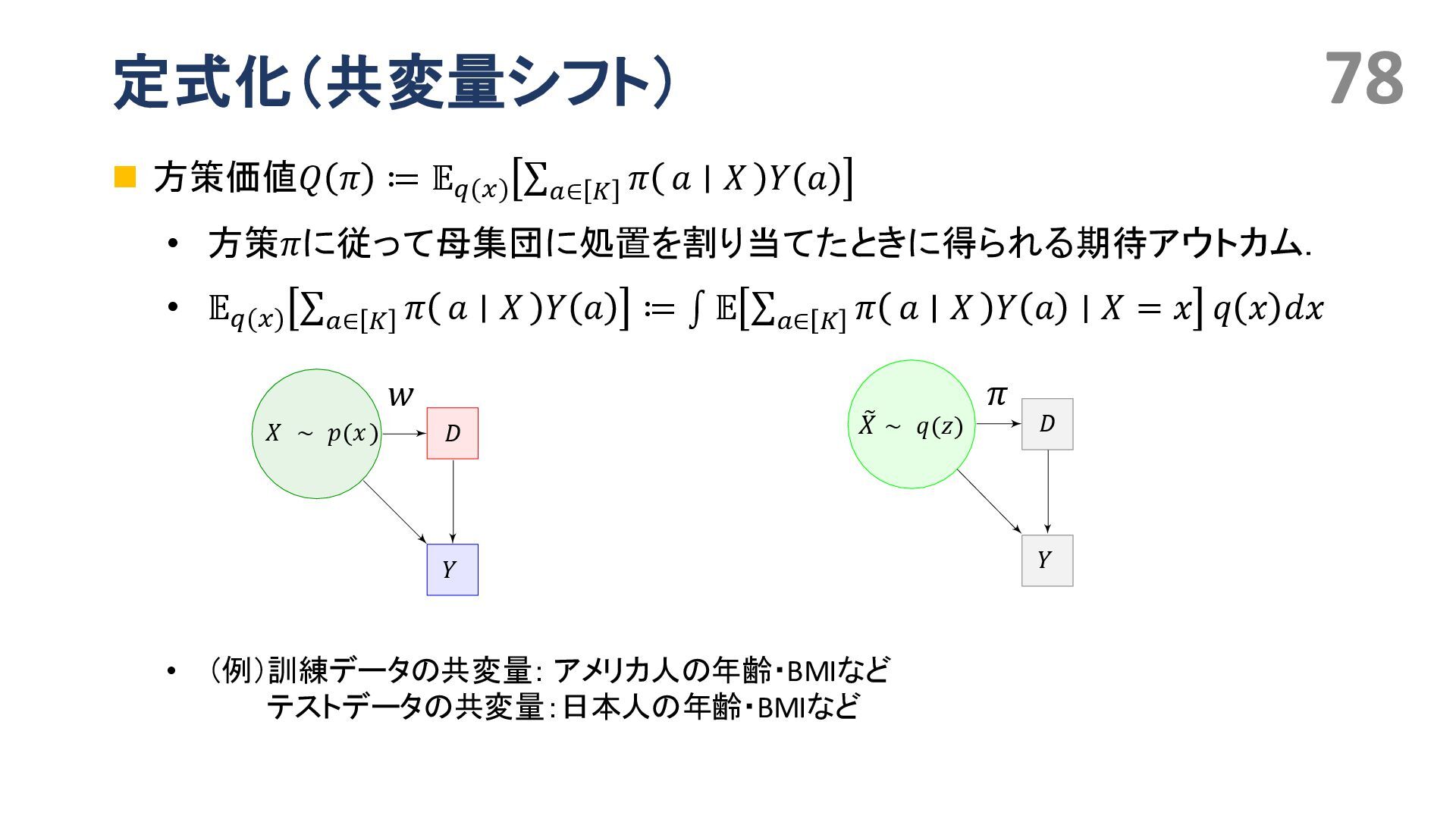{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
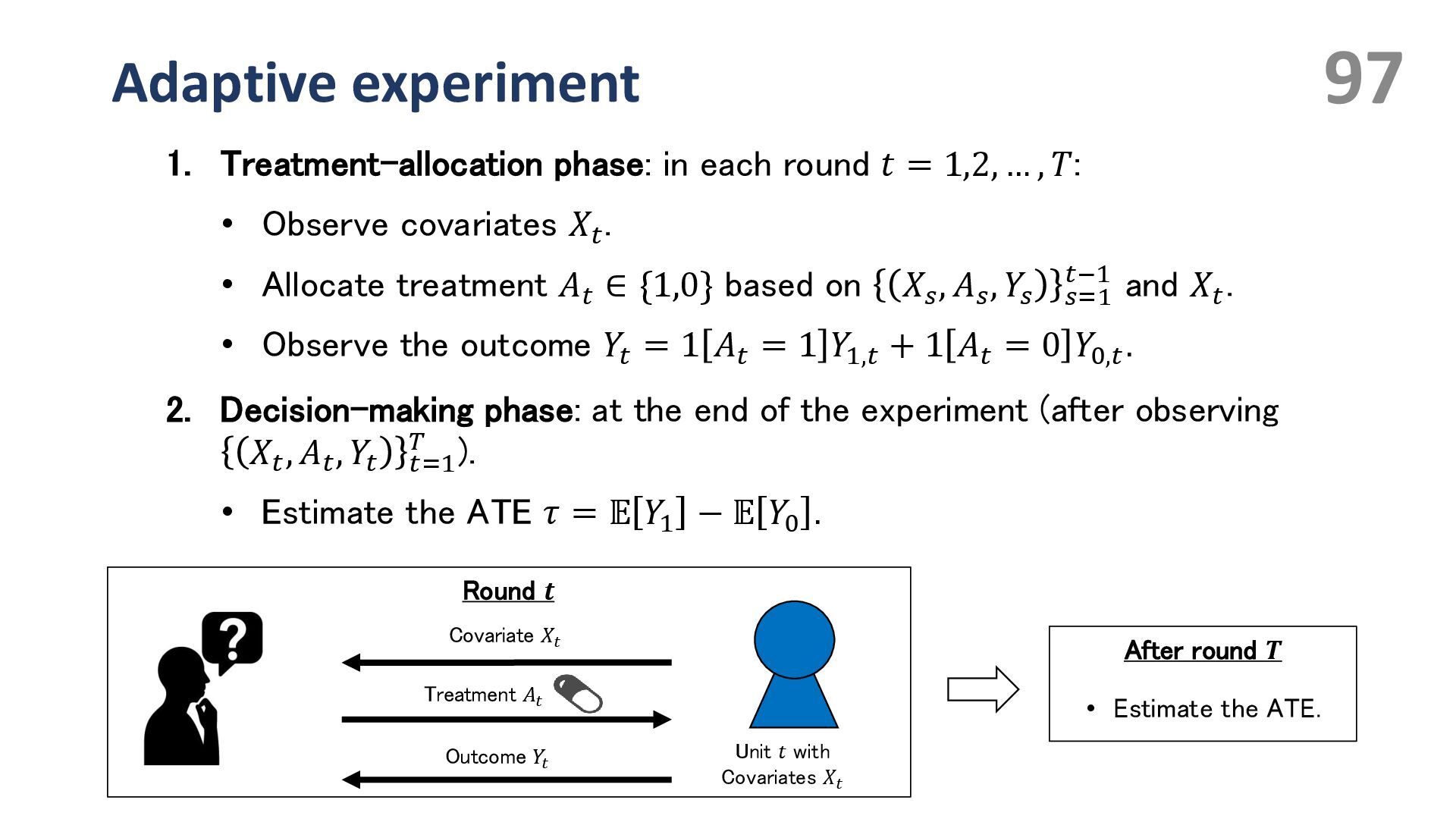{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
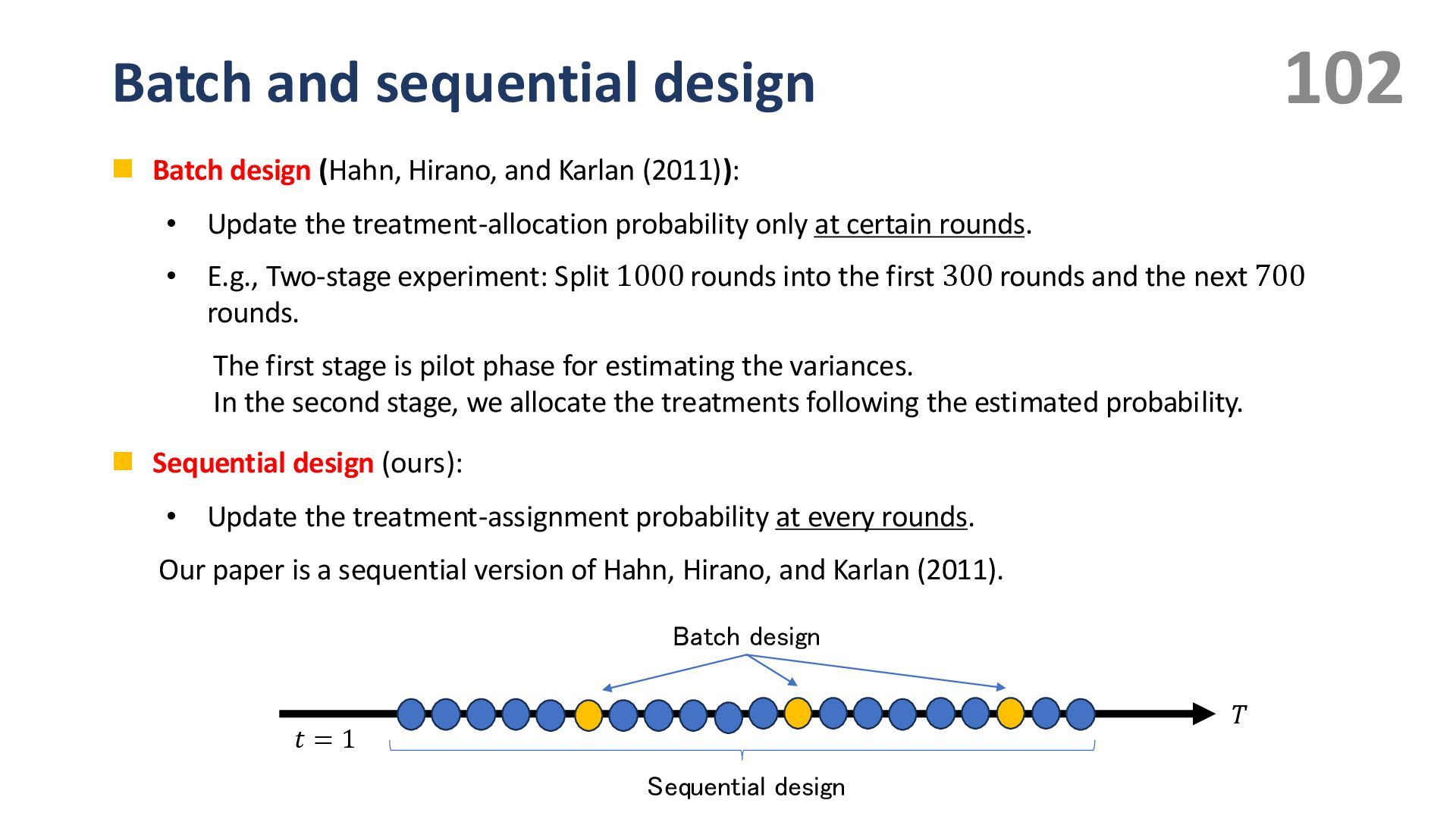{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}