Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Kaggle - Linking Writing Processes to Writing Q...
Search
Falcon
March 02, 2024
930
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Kaggle - Linking Writing Processes to Writing Quality の振り返り
関西kaggler会2024春の発表資料
Falcon
March 02, 2024
Featured
See All Featured
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
720
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
220
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
340
YesSQL, Process and Tooling at Scale
rocio
174
15k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
Thoughts on Productivity
jonyablonski
76
5.2k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
Transcript
関西kaggle会2024春 Falcon @aromani
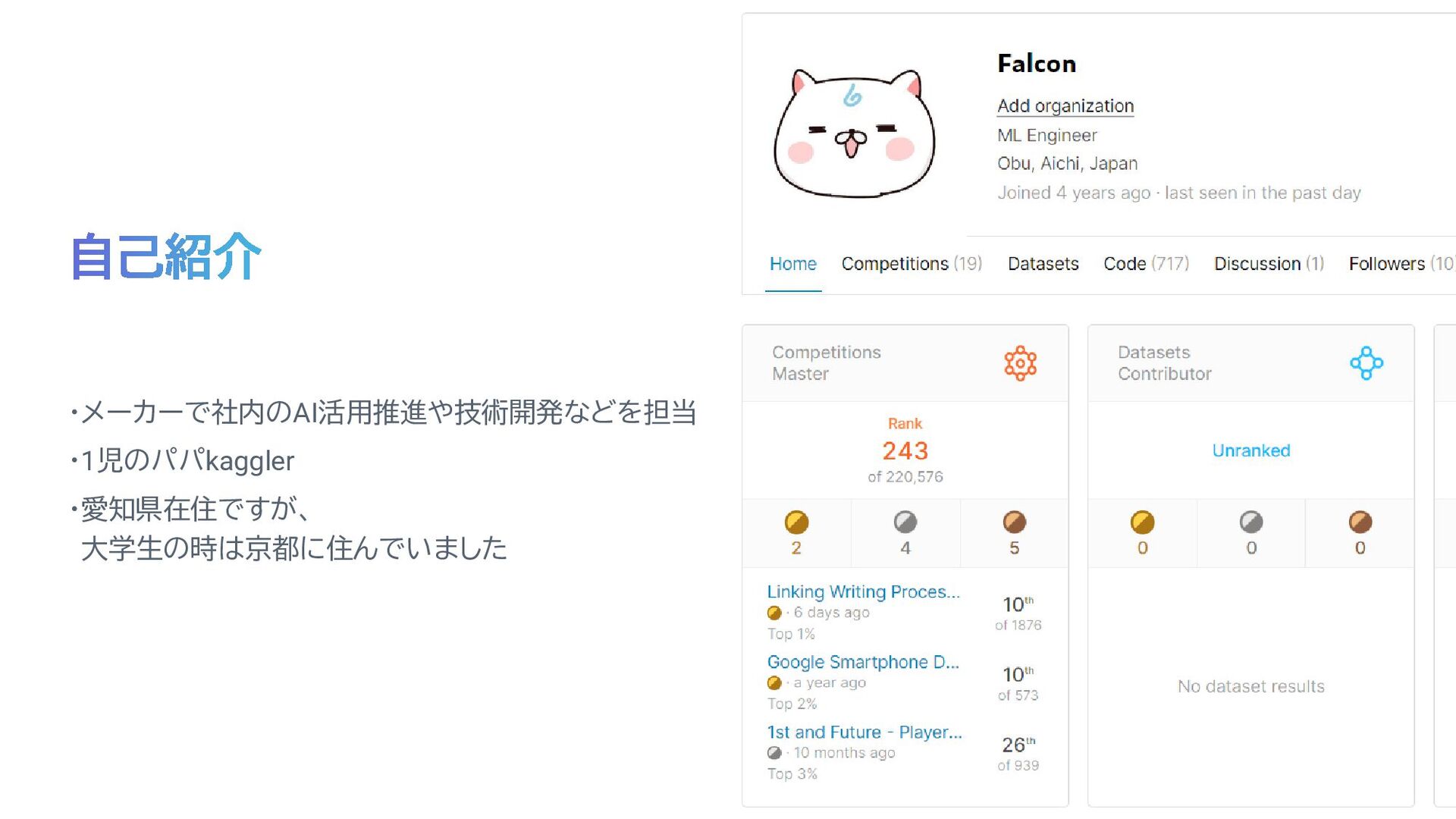
© 2023 Brother Industries, Ltd. All Rights Reserved. ・メーカーで社内のAI活用推進や技術開発などを担当 ・1児のパパkaggler
・愛知県在住ですが、 大学生の時は京都に住んでいました
23/10/23~24/1/10に開催されたLinking Writing Processes to Writing Qualityコンペにて10th(ソロ金) 本日は、コンペの概要や上位ソリューションの共有をさせていただきます
・コンペの概要 ・ソリューション共有 ・コンペを通しての学びと反省 Agenda
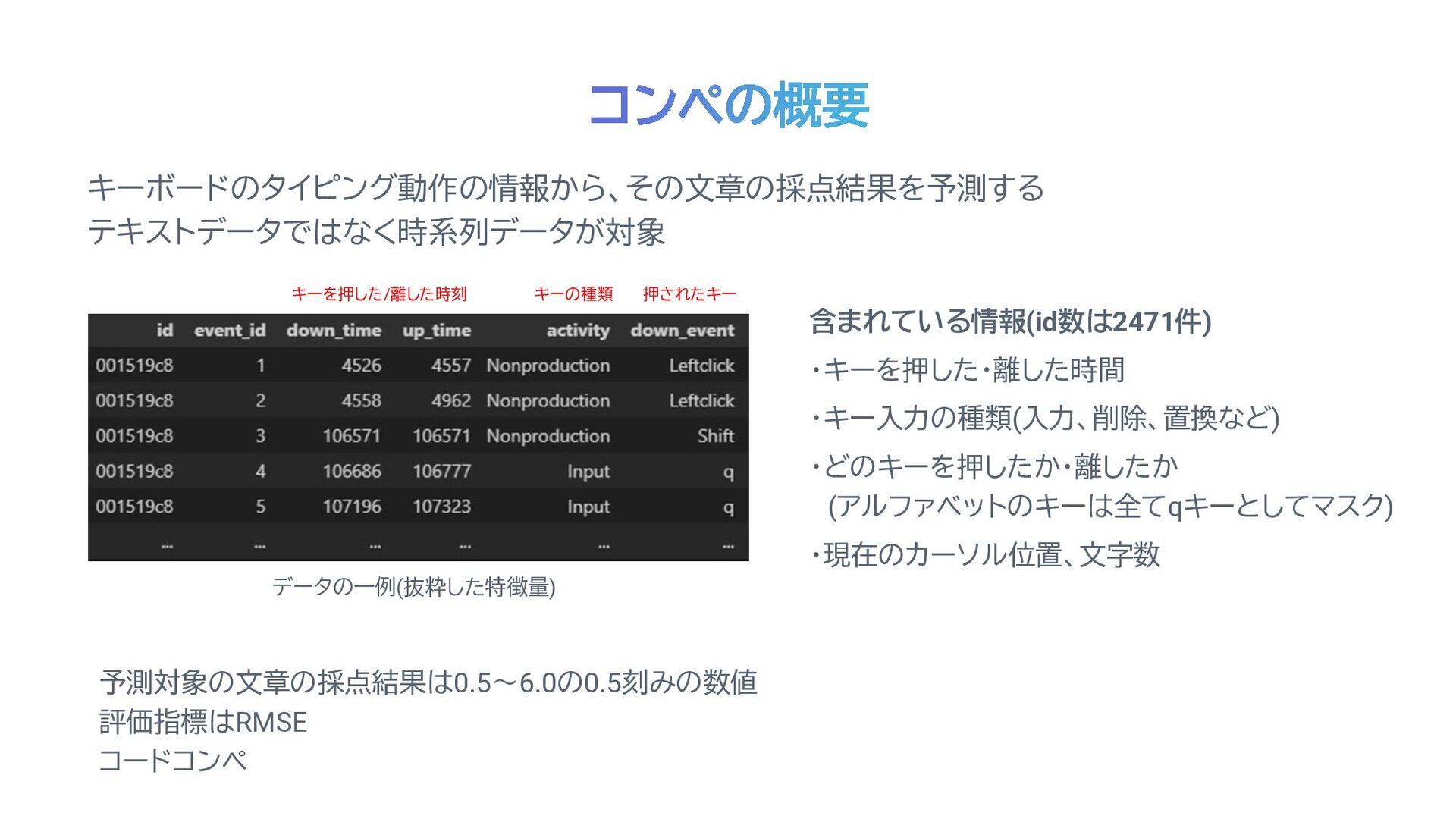
含まれている情報(id数は2471件) ・キーを押した・離した時間 ・キー入力の種類(入力、削除、置換など) ・どのキーを押したか・離したか (アルファベットのキーは全てqキーとしてマスク) ・現在のカーソル位置、文字数 キーボードのタイピング動作の情報から、その文章の採点結果を予測する テキストデータではなく時系列データが対象 データの一例(抜粋した特徴量) 押されたキー
キーの種類 キーを押した/離した時刻 予測対象の文章の採点結果は0.5~6.0の0.5刻みの数値 評価指標はRMSE コードコンペ
文章idごとに予測値を算出したいので、idで集約する方向で特徴量を作成していく 例えば、 ・idごとのqキーが押された回数 ・idごとのDeleteキーが押された回数 ・文字の入力数/文章作成にかかった時間 など データの一例(抜粋した特徴量) 網羅的に集約して特徴量を作成したり、ドメイン知識に基づくなど様々なアプローチが考えられる 押されたキー キーの種類
キーを押した/離した時刻
元の文章を知ることはできないが、マスクされた文字列であれば、再構成することができる 下記のように再構成できる Qqqqqq qqq qqqq 実際は、バックスペースや コピー&ペーストへの対処も必要 (公開ノートブックで共有されていたので、 苦労しなかった) 再構成した文章に対して、
・文や段落の数を特徴量化 ・tfidfなどでベクトル化 ・Transformerベースの言語モデルで学習 自然言語処理的なアプローチで特徴抽出が可能
・キー入力動作の時系列情報からの特徴抽出 特徴量エンジニアリングの工夫など ・テキスト情報が匿名化されている 一般的な自然言語とは異なる取り扱いが必要 抽出できる特徴に限りがある ・データが少ない 学習データが2471件しか無い テストデータも少ないことが予想され、Public LBにオーバーフィットしないことが重要
かなり揺れたコンペだった Public LBが密集していた データ数が少ないこともあり、かなり揺れた 自分のバリデーション結果を信じることが重要だった (運や最終サブの選び方も影響はしていたと思う) ・・・ Public LBで0.574x(金圏下位)~0.576x(銀圏中位)に37人 何とかしてデータから特徴を絞り出すようなコンペだった
ソリューション共有
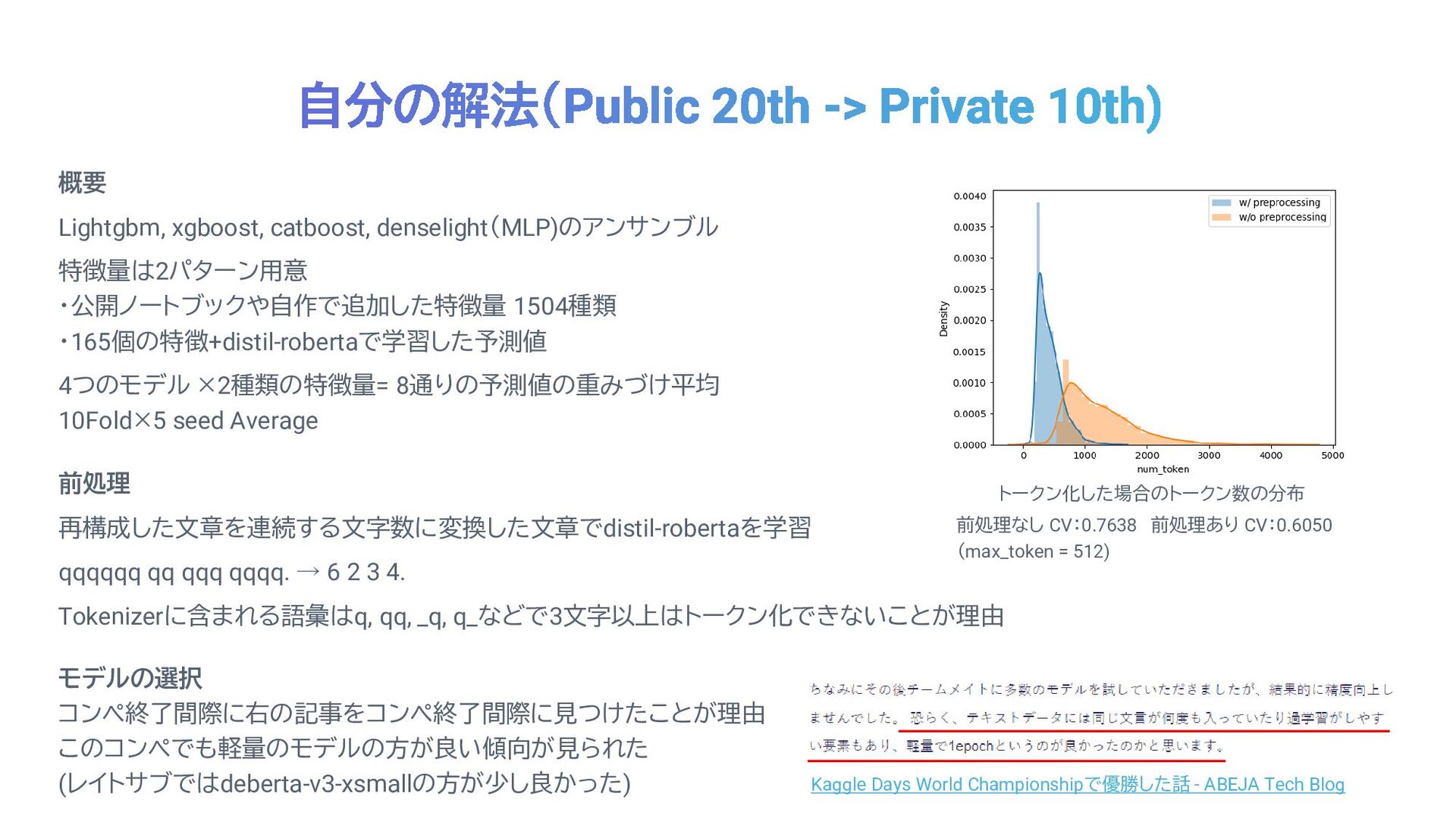
トークン化した場合のトークン数の分布 概要 Lightgbm, xgboost, catboost, denselight(MLP)のアンサンブル 特徴量は2パターン用意 ・公開ノートブックや自作で追加した特徴量 1504種類 ・165個の特徴+distil-robertaで学習した予測値
4つのモデル ×2種類の特徴量= 8通りの予測値の重みづけ平均 10Fold×5 seed Average 前処理 再構成した文章を連続する文字数に変換した文章でdistil-robertaを学習 qqqqqq qq qqq qqqq. → 6 2 3 4. Tokenizerに含まれる語彙はq, qq, _q, q_などで3文字以上はトークン化できないことが理由 Kaggle Days World Championshipで優勝した話 - ABEJA Tech Blog モデルの選択 コンペ終了間際に右の記事をコンペ終了間際に見つけたことが理由 このコンペでも軽量のモデルの方が良い傾向が見られた (レイトサブではdeberta-v3-xsmallの方が少し良かった) 前処理なし CV:0.7638 前処理あり CV:0.6050 (max_token = 512)
金圏以上ではこれらに加えて、下記の工夫が見られた 1. テキストデータからの特徴抽出の工夫 2. 外部データの活用 3. 特徴量選択の工夫とシェイクダウン対策 銀圏以上の多くのチームでは下記のアプローチが見られた ・LightgbmやMLPなど様々なモデルのアンサンブルやSeed Average
・再構成したテキスト情報からの特徴抽出 ・特徴量エンジニアリングによる、有効な特徴量の導出
・deberta-v3-baseを特徴抽出器として使用 - 最終層の埋め込みを他の特徴量と結合(2nd) - キーの入力に関する特徴量と最終層の埋め込みをCross-attentionで組み合わせる(3rd) ・マスクされた文字をq→iやxに変更することでトークン効率を向上(3rd) ・データクレンジングと正確なテキストの再構成 (1st)
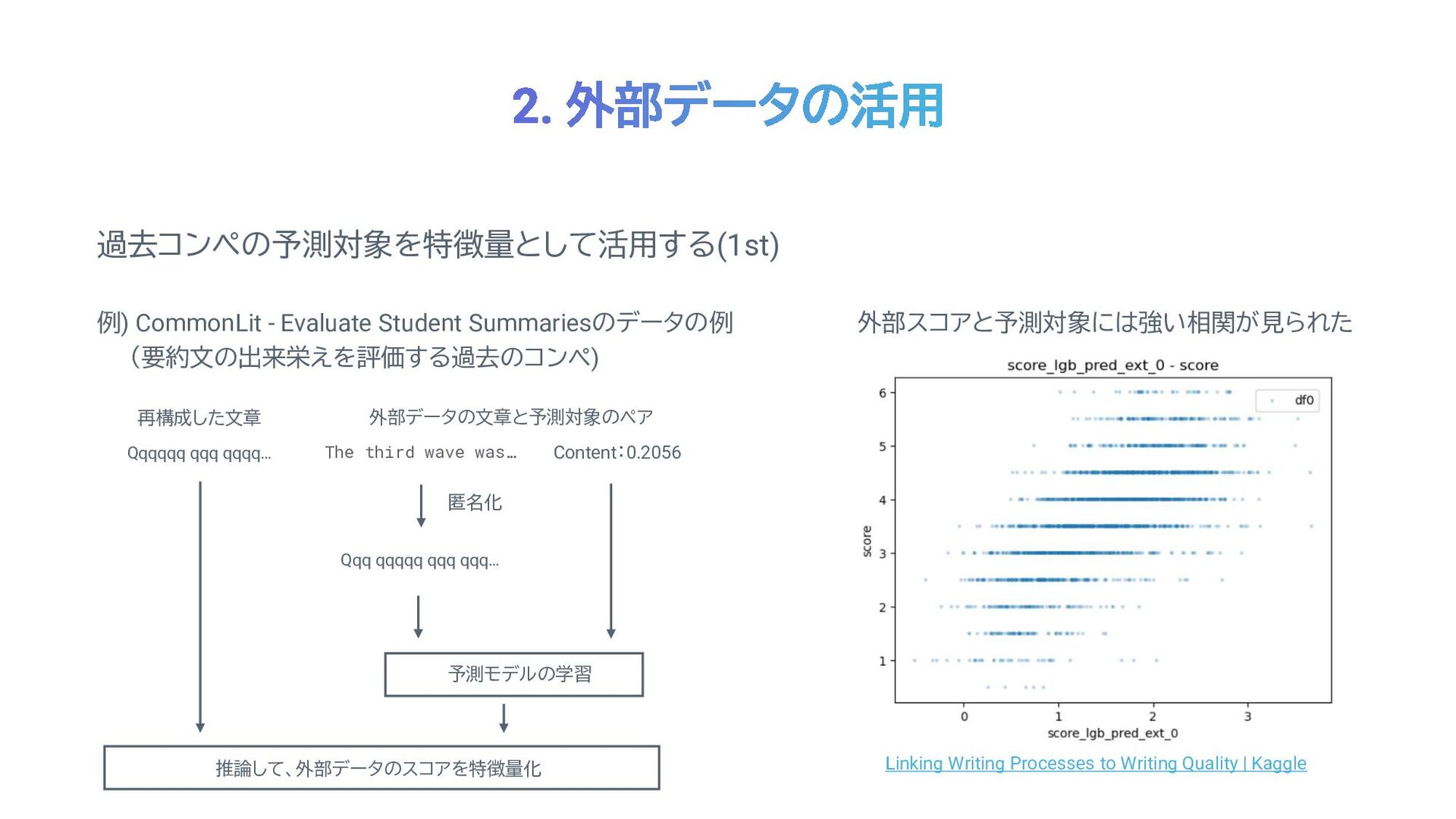
過去コンペの予測対象を特徴量として活用する(1st) The third wave was… Content:0.2056 例) CommonLit - Evaluate
Student Summariesのデータの例 (要約文の出来栄えを評価する過去のコンペ) Qqq qqqqq qqq qqq… 匿名化 外部データの文章と予測対象のペア Qqqqqq qqq qqqq… 再構成した文章 予測モデルの学習 推論して、外部データのスコアを特徴量化 Linking Writing Processes to Writing Quality | Kaggle 外部スコアと予測対象には強い相関が見られた
データ数が2471件と少ないので、1000を超えるような特徴量は適さない(次元の呪い) Public LBの評価に使用されているデータが少なく、Trust Your CVが重要 ・相関係数の大きい特徴に絞る(6th) ・Lightgbmなどのimportanceの高い特徴量に絞る(2nd, 7th) ・LB, CVの両方が上がった特徴量を採用していく(4th)
・多様なモデル/特徴量/seedのアンサンブル
2023年は金メダルにかすりもしな い状態 (4つコンペに参加して銀2銅2) 最後までやり切っていれば、メダル が降ってくることもある 継続する 自分のアイデアを信じて、上手くい くまで実験を続ける 細かいアプローチの違いが原因で 上手くいっていないことも多い
(自分の実装力が無いだけかもしれないけど) 諦めない心 育児もあり、コンペの時間があまり 取れないので、コンペ開始直後から 取り組んでコンペ期間をフルに使う ように意識している 追い込まれないと頑張れないので、 結局、コンペ終盤しか取り組めない ことも多いけど 計画的に進める
・コンペの概要 - タイピング動作(キー入力のタイミングや入力キーの種類)から文章の採点結果を予測するコンペ - 時系列コンペだが、NLPが活用できたコンペ ・ソリューション共有 - テキストデータからの特徴抽出の工夫 - 外部データの活用
- 特徴選択の工夫とシェイクダウン対策 ・コンペを通しての学びと反省 - 継続する、諦めない心、計画的に進める
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}