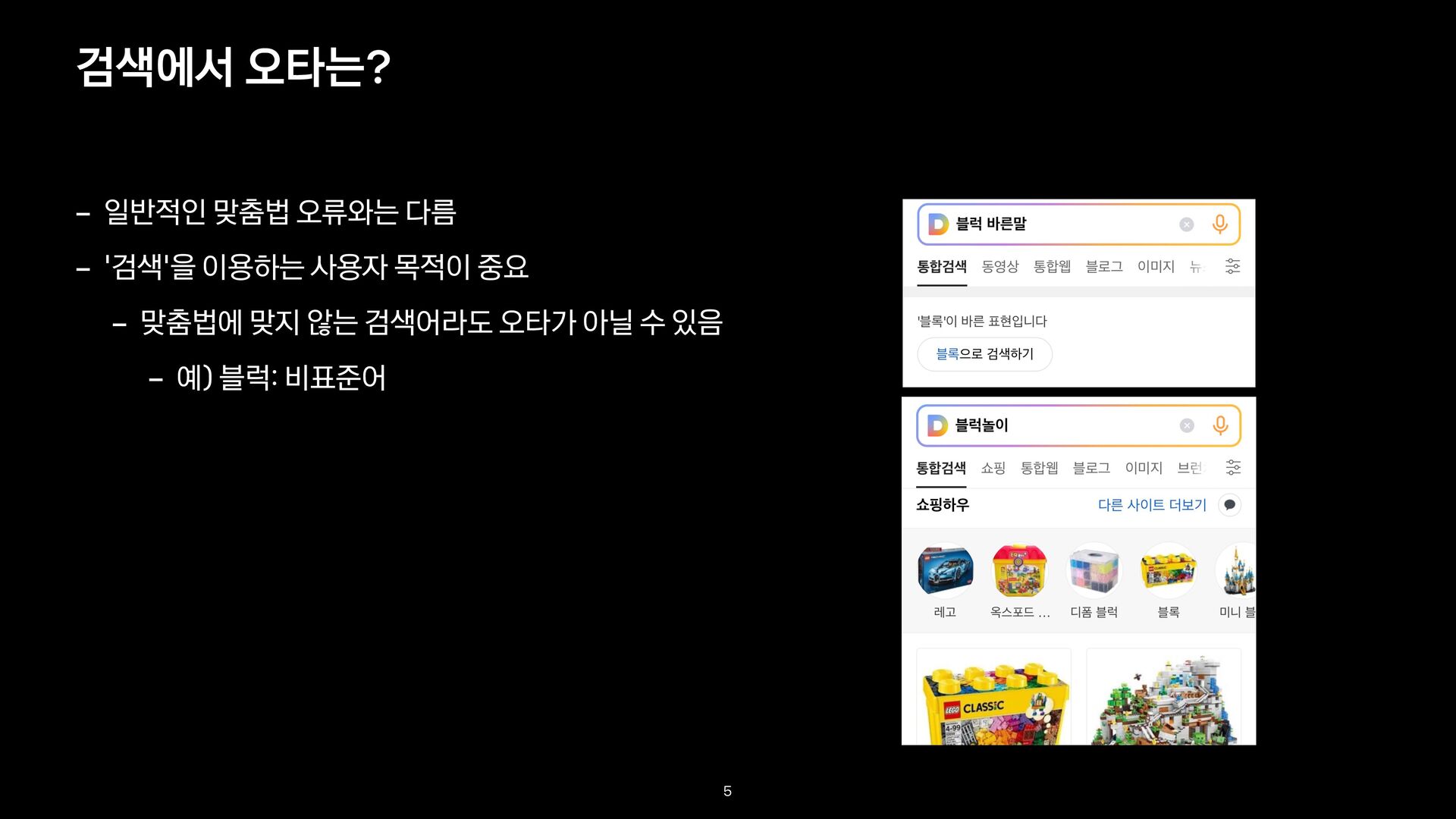
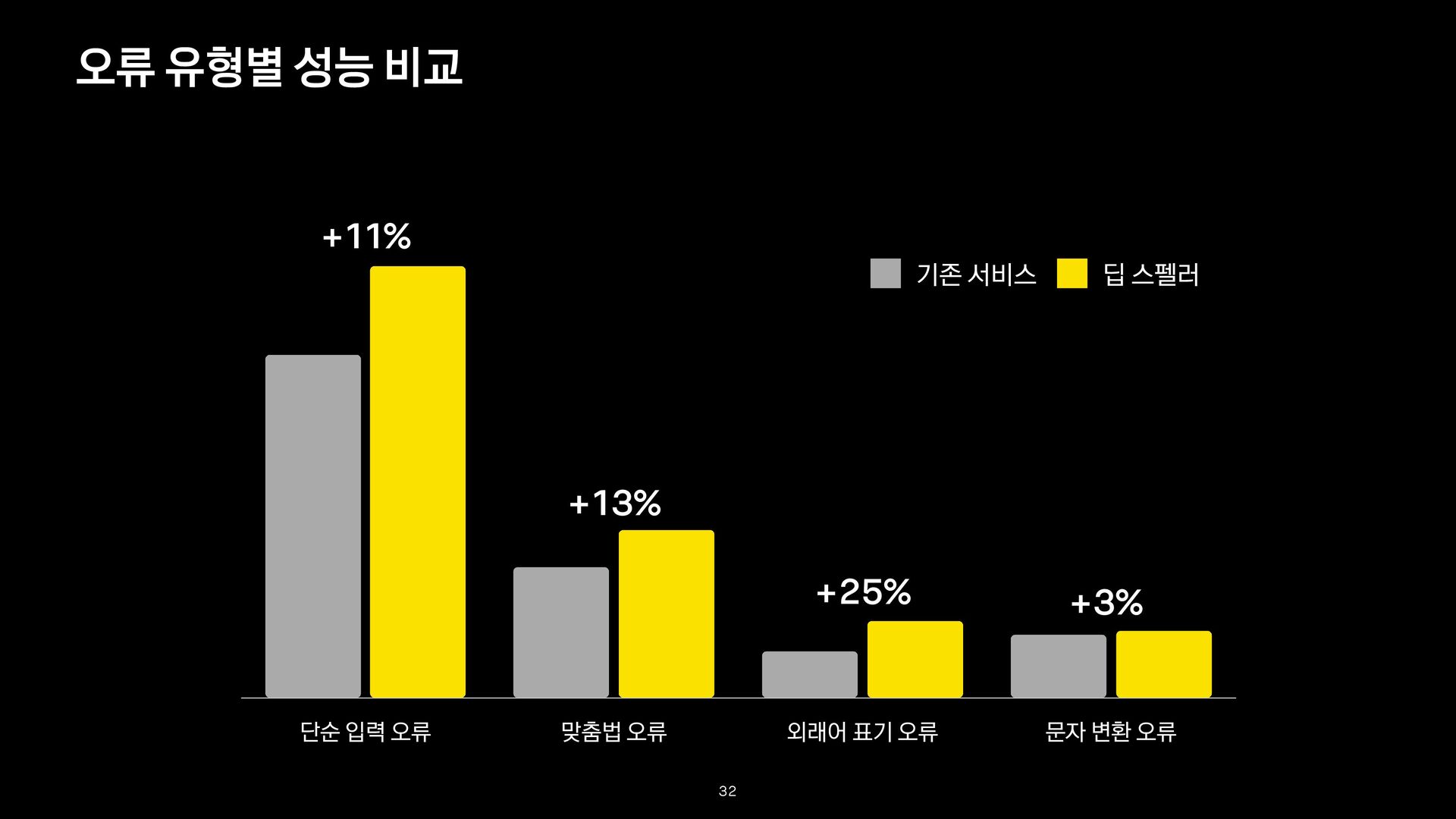
예(정타 / 오타) 단순 입력 오류 규칙성이 없는 단순한 입력 오류 카톡 / 까톡, 카턱 문자 변환 오류 한글이 영어로(또는 영어가 한글로) 변환된 오류 카카오 / zkzkdh 맞춤법 오류 맞춤법 표기법에 어긋난 오류 육개장 / 육계장 외래어 표기 오류 외래어 표기법과 관련된 오류 문화센터 / 문화센타 잘못된 배경 지식으로 인한 오류 잘못된 정보로 발생한 오류 광교 갤러리아백화점 / 판교 갤러리아백화점 7
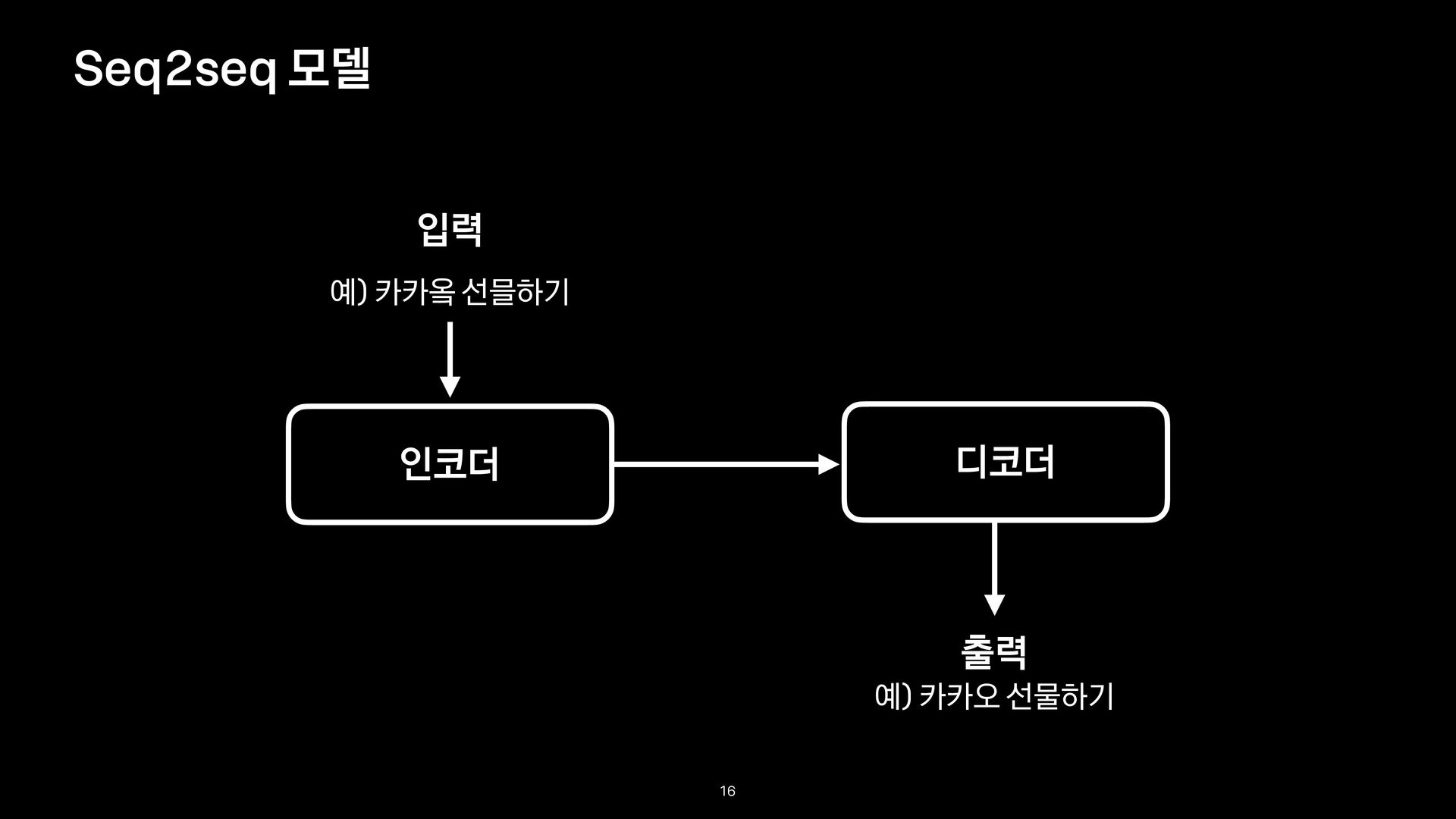
교정 모델 - 노이즈 채널 모델(Noisy channel Model) - 오류 모델, 언어 모델의 곱 결과에서 가장 큰 확률값을 가지는 결과를 정타 후보로 예측 - 오류 모델(Error Model): - 언어 모델(Language Model): P(x|w) P(w) ̂ w = argmax w∈V P(x|w)P(w) : 예측된 정타 후보 : 오타 : 정타 : 정타 후보 사전 ̂ w x w V 11
중 교정한 비율 - 높은 교정 정확률을 위해 제한된 편집 거리 사용 - 교정 정확률(precision) - 교정 결과가 정답인 비율 - 오교정이 치명적인 스펠러 특성상 매우 중요 - 참고, 편집거리(Edit Distance) - 한 문자열에서 다른 문자열로 변환시 연산 횟수 - 예) <abc, abd>의 편집 거리는 1 12 42.8% 57.2% 미교정 교정 교정 대상
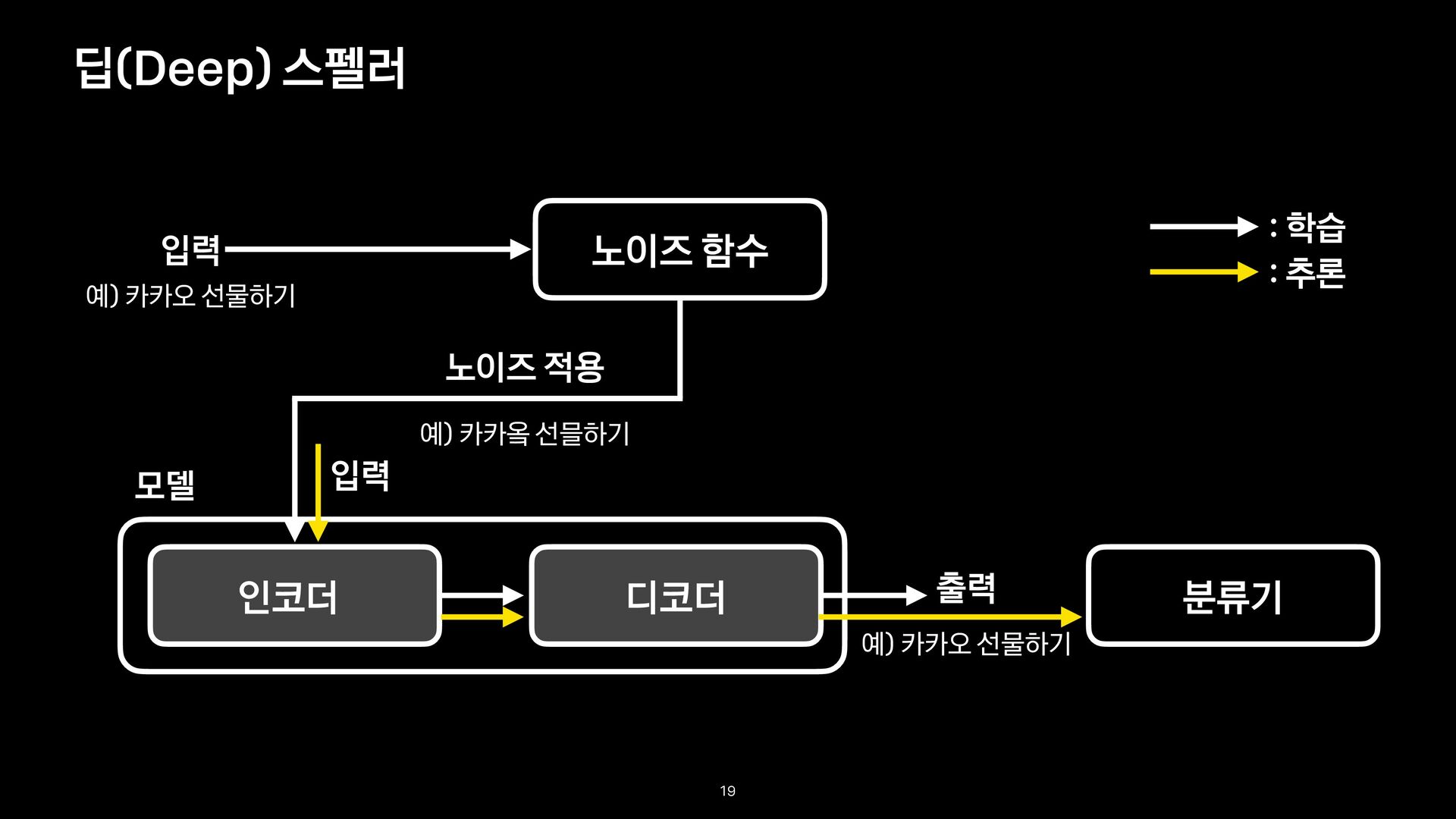
오타 교정: 오타로부터 정타를 생성하는 문제로 정의 - 디노이징 Seq2seq 모델(Denoising Seqence - to - Sequence Model)을 사용 - 기존 모델의 한계를 여러 도메인에서 좋은 성능을 내는 딥러닝 모델을 통해 극복해보고자 함 그래서… 13
지속적인 성능 개선 가능 - 학습 데이터에 따라 도메인에 특화된 모델 제공 가능 - ex) 음악, 쇼핑, 로컬 등 - (디노이징 모델을 위한) 노이즈 생성 함수 개발 - 확장이 용이하고, 여러 도메인에 적용 가능한 오타 생성 방법 개발 가능 - 학습 데이터: <오타, 정타> 쌍 데이터 기대효과 14
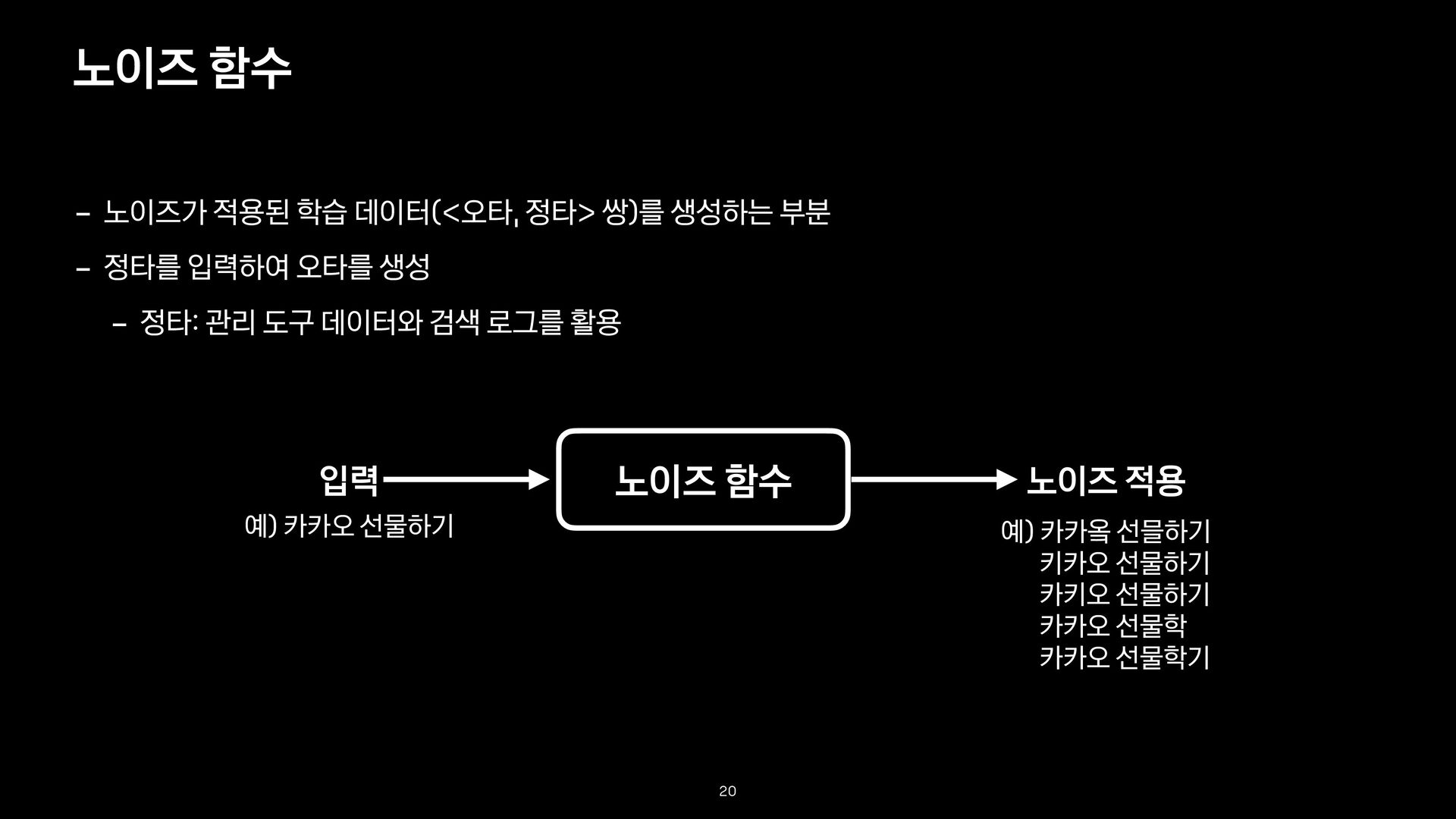
-> 쿼리2) 기존 서비스에서 사용중인 데이터 - 관리 도구 데이터 오타 생성 모델(방법)을 이용 - 정타 데이터를 입력하여 임의의 <오타, 정타> 쌍을 생성 - 데이터 양이 적을 때 효과적 - Seq2seq 모델 학습에는 쌍을 가지는 데이터가 필요 - <오타, 정타> 데이터 - 기존 검색어 로그 데이터 활용 - 기존 서비스에서 사용중인 데이터 - 오타 생성 모델(방법)을 이용 Seq2seq 모델의 학습 데이터
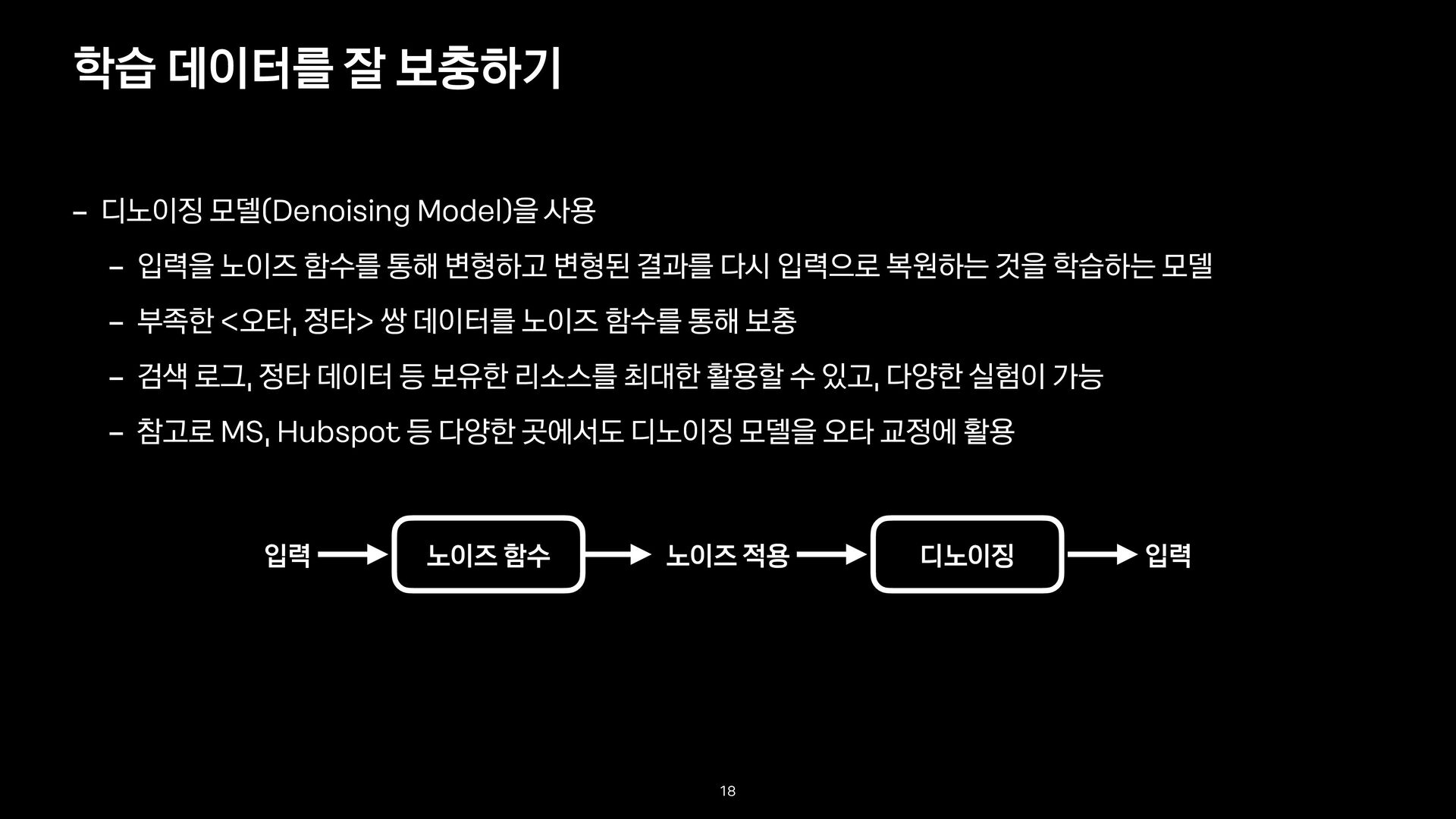
변형하고 변형된 결과를 다시 입력으로 복원하는 것을 학습하는 모델 - 부족한 <오타, 정타> 쌍 데이터를 노이즈 함수를 통해 보충 - 검색 로그, 정타 데이터 등 보유한 리소스를 최대한 활용할 수 있고, 다양한 실험이 가능 - 참고로 MS, Hubspot 등 다양한 곳에서도 디노이징 모델을 오타 교정에 활용 학습 데이터를 잘 보충하기 18 노이즈 함수 디노이징 노이즈 적용 입력 입력
keystroke로 변환 dlvm zkzkdh 오류 모델 기반 오타 생성 기존 서비스의 오류 모델을 활용 이프키카오, 이푸카카오, 니프카카오 패턴 기반 오타 생성 관리 도구 데이터, 세션 로그를 이용하여 <정타, 오타> 패턴으로 오타 생성 이프 카캉, 이프 카코오, 이프 ㅋk카오 번역 모델 기반 오타 생성 관리 도구 데이터, 세션 로그를 이용하여 <정타, 오타> 오타 생성 모델 학습 이푸 카카오, 아프 카카오, 이프 카카어 노이즈 함수 입력으로 ‘이프 카카오’가 입력된 경우 21
사용 - 정제 기준 - 숫자, 기호, 자모, url만 있는 경우 - 오타 패턴이 포함되어 있는 경우 23 관리 도구 데이터 예) 카카오 선물하기 123-456-789 zkzkdh ^^ 검색 로그 노이즈 함수 정제 로직 예) 카카오 선물하기 123-456-789 zkzkdh ^^
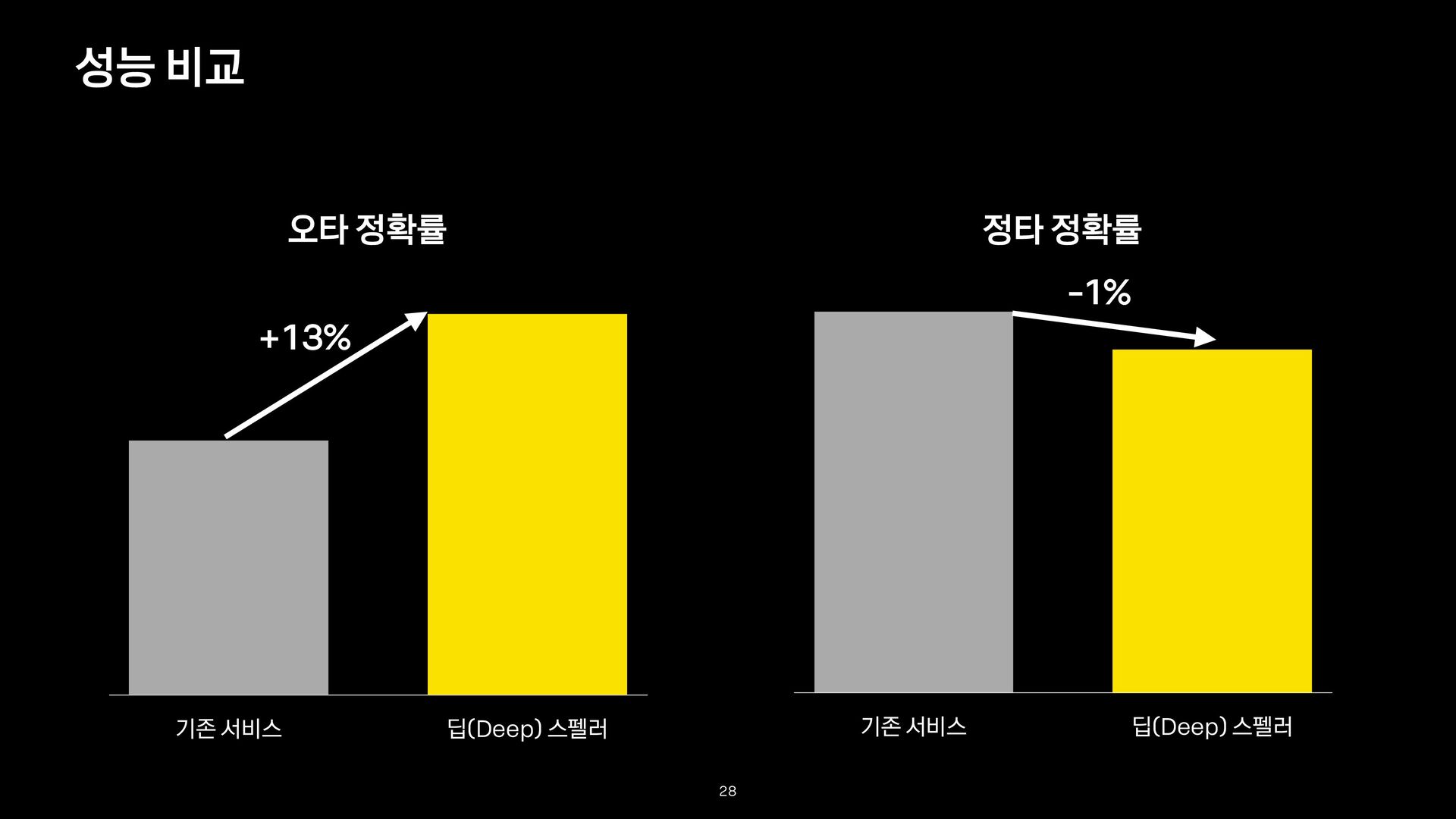
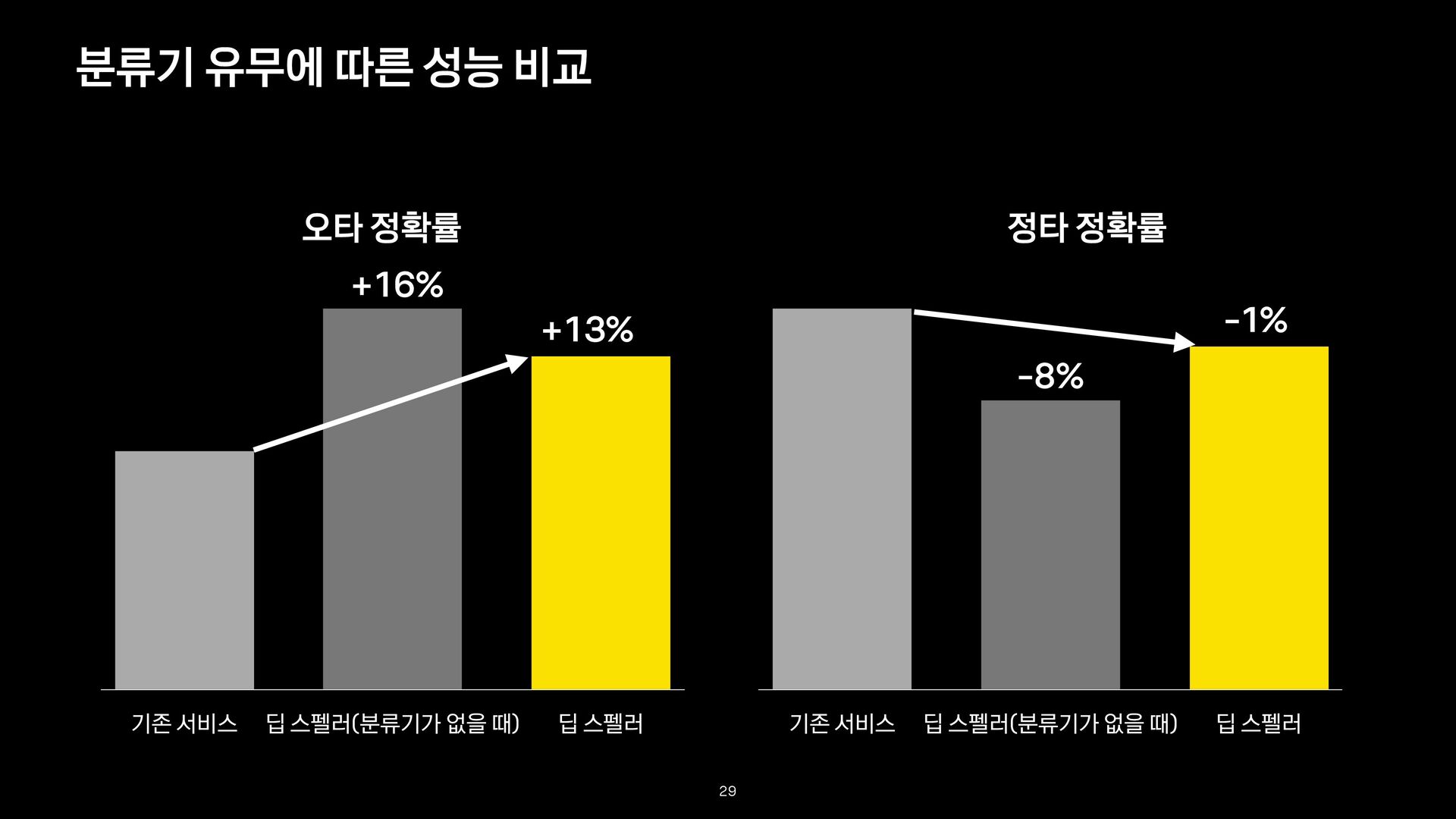
- True: 오타를 바르게 교정한 경우 - False: 오타를 교정하지 않거나, 잘못 교정한 경우 - 정타 정확률 - True: 정타를 교정하지 않은 경우 - False: 정타를 잘못 교정한 경우 평가 방법 정확률 = count(True) count(True + False) 26
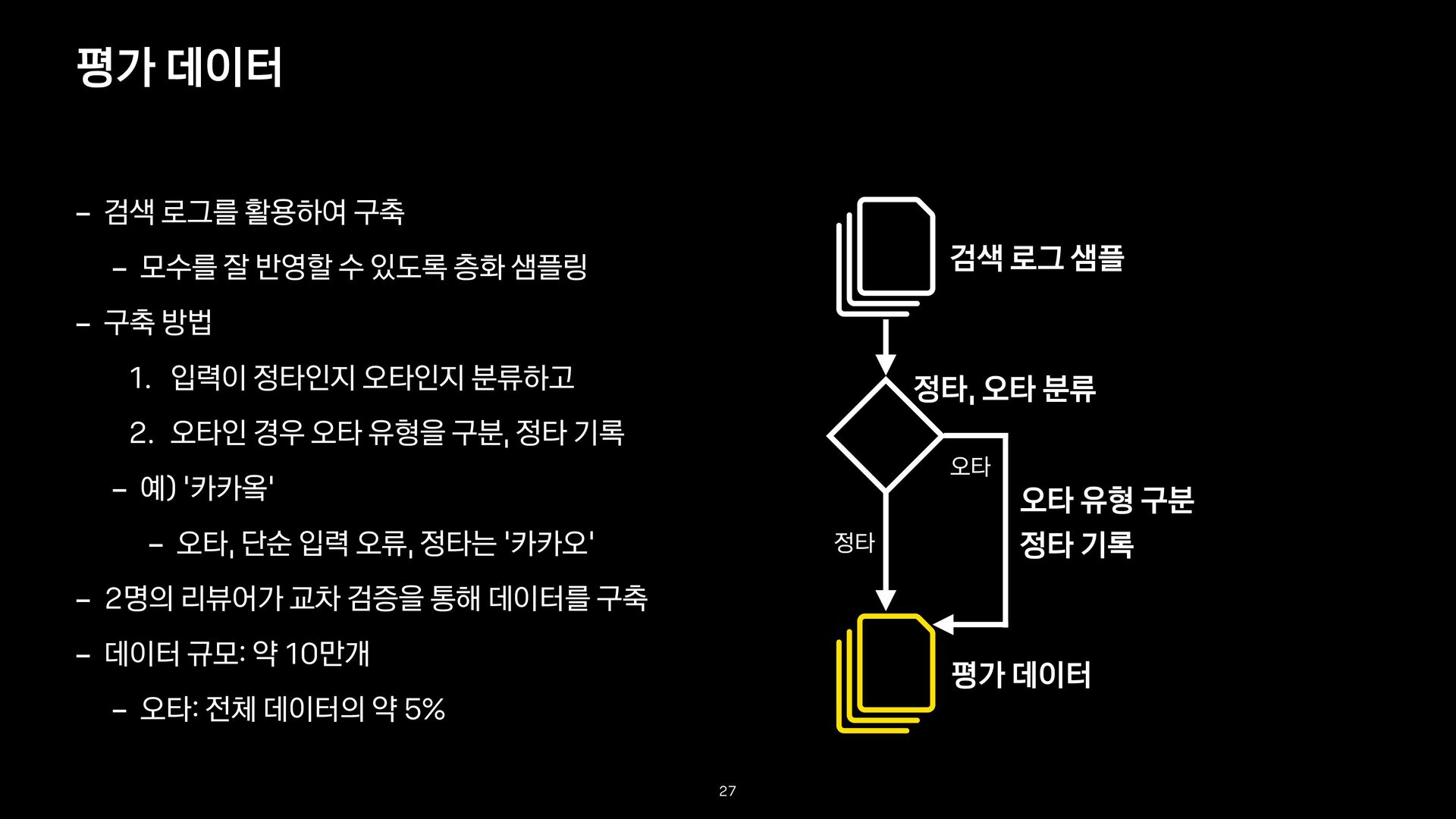
반영할 수 있도록 층화 샘플링 - 구축 방법 1. 입력이 정타인지 오타인지 분류하고 2. 오타인 경우 오타 유형을 구분, 정타 기록 - 예) ‘카카옼’ - 오타, 단순 입력 오류, 정타는 ‘카카오’ - 2명의 리뷰어가 교차 검증을 통해 데이터를 구축 - 데이터 규모: 약 10만개 - 오타: 전체 데이터의 약 5% 27 검색 로그 샘플 정타, 오타 분류 정타 오타 평가 데이터 오타 유형 구분 정타 기록
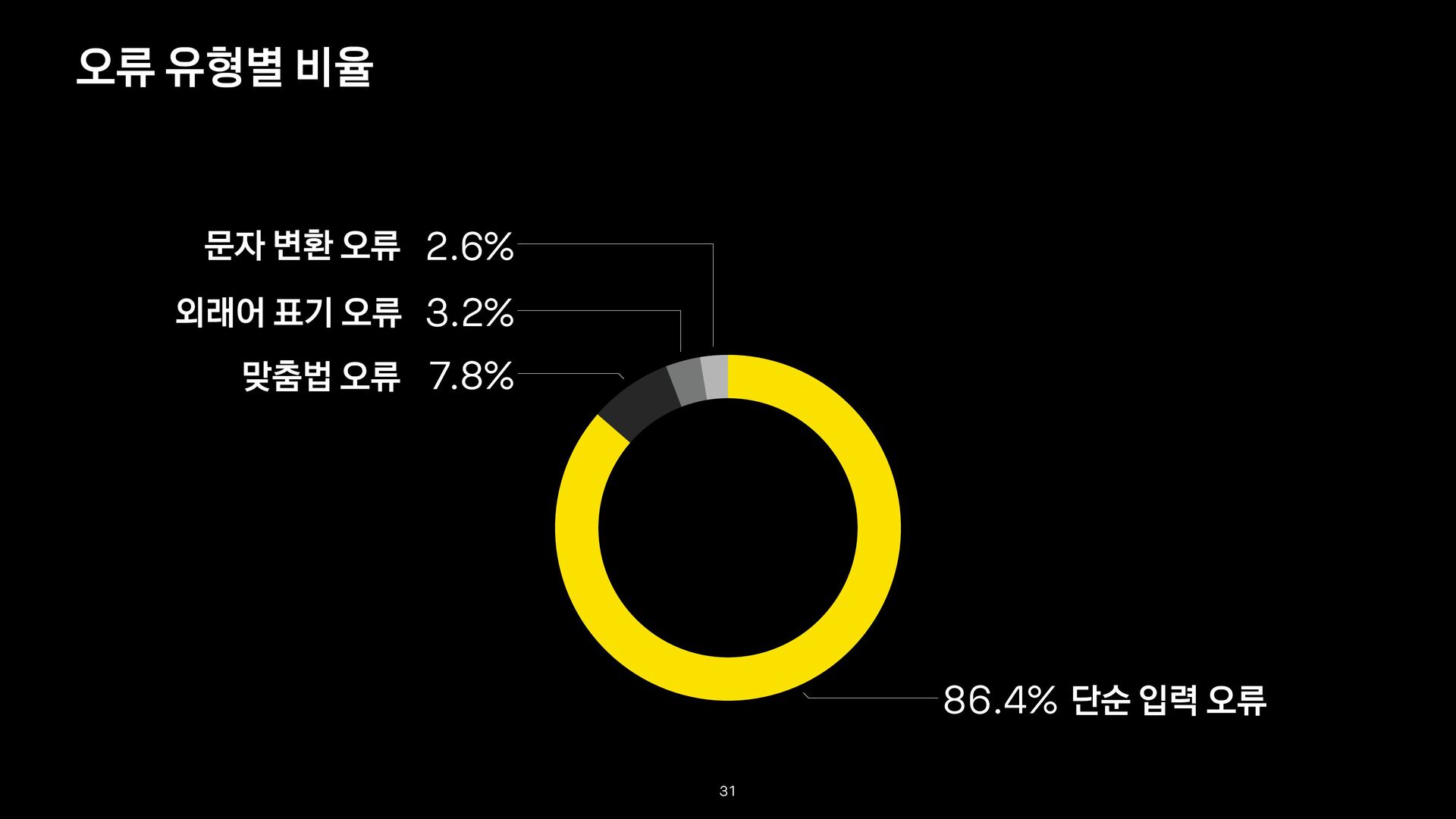
없는 단순한 입력 오류 동탄숲소헝당 / 동탄 숲속성당 문자 변환 오류 한글이 영어로(또는 영어가 한글로) 변환된 오류 rnrzktmxps 샤ㅡㄷ ㅁㄽㄷㄱ 샤ㅡㄷ / 국카스텐 time after time 맞춤법 오류 맞춤법 표기법에 어긋난 오류 공인중계사 시험일정 / 공인중개사 시험일정 외래어 표기 오류 외래어 표기법과 관련된 오류 핸드 그라인다 속도조절기 / 핸드 그라인더 속도조절기 오류 유형 케이스 30
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}