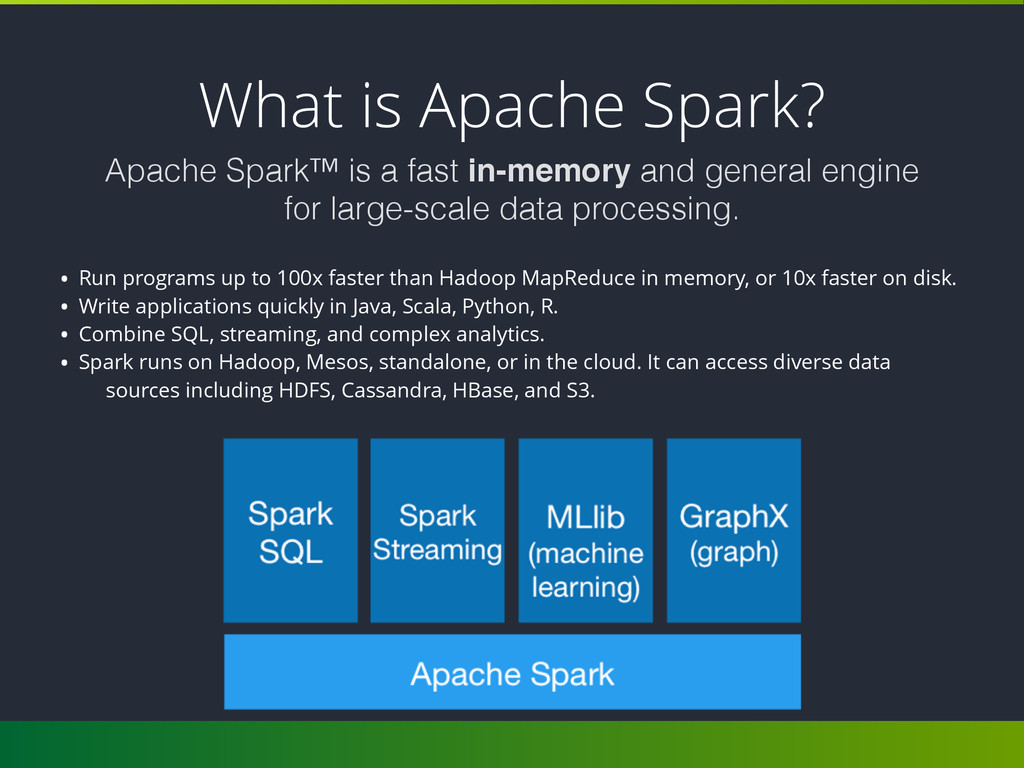
faster than Hadoop MapReduce in memory, or 10x faster on disk. • Write applications quickly in Java, Scala, Python, R. • Combine SQL, streaming, and complex analytics. • Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3. Apache Spark™ is a fast in-memory and general engine for large-scale data processing.
Computing with Working Sets" by Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica. University of California, Berkeley • "Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing" Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica. University of California, Berkeley
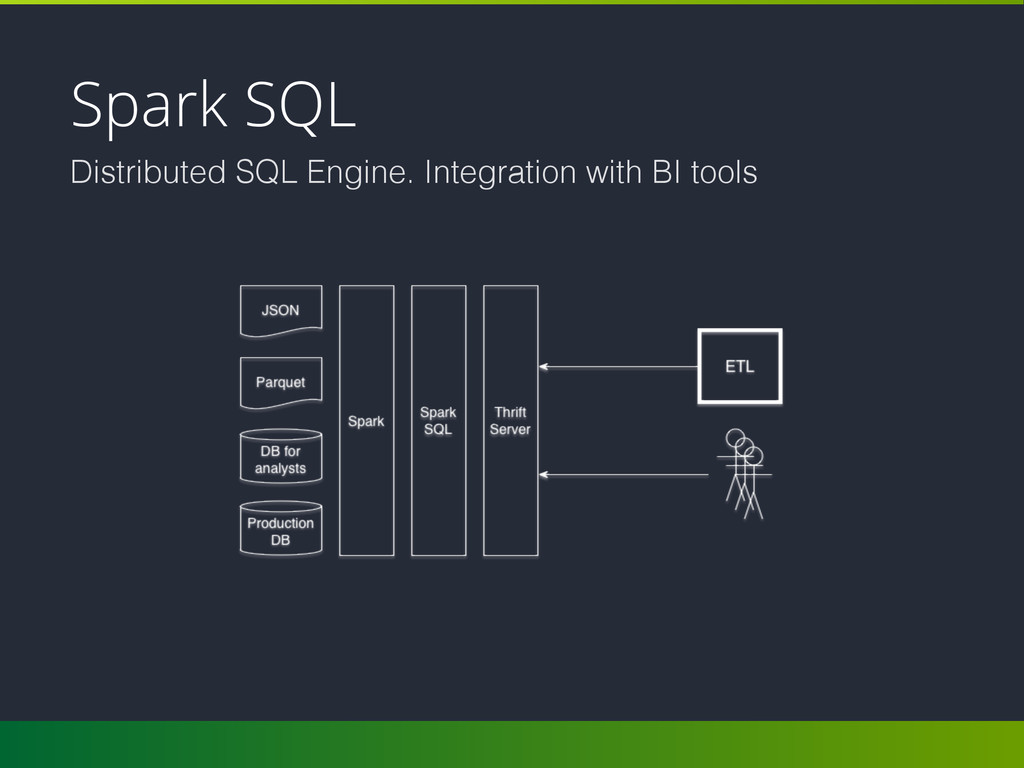
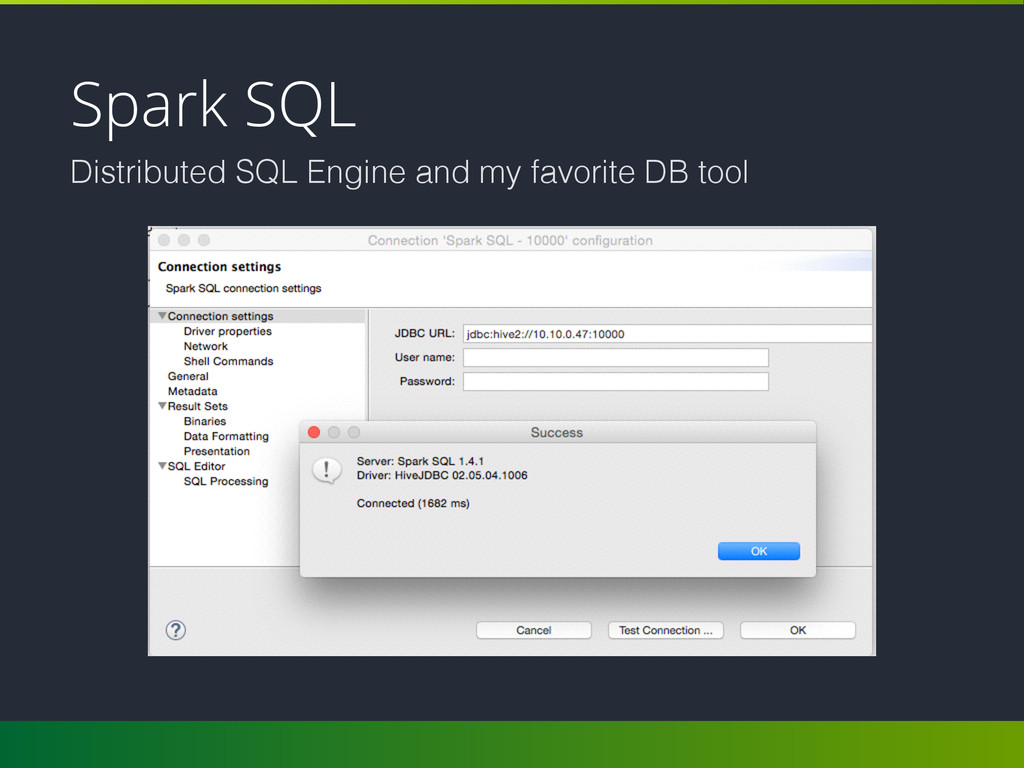
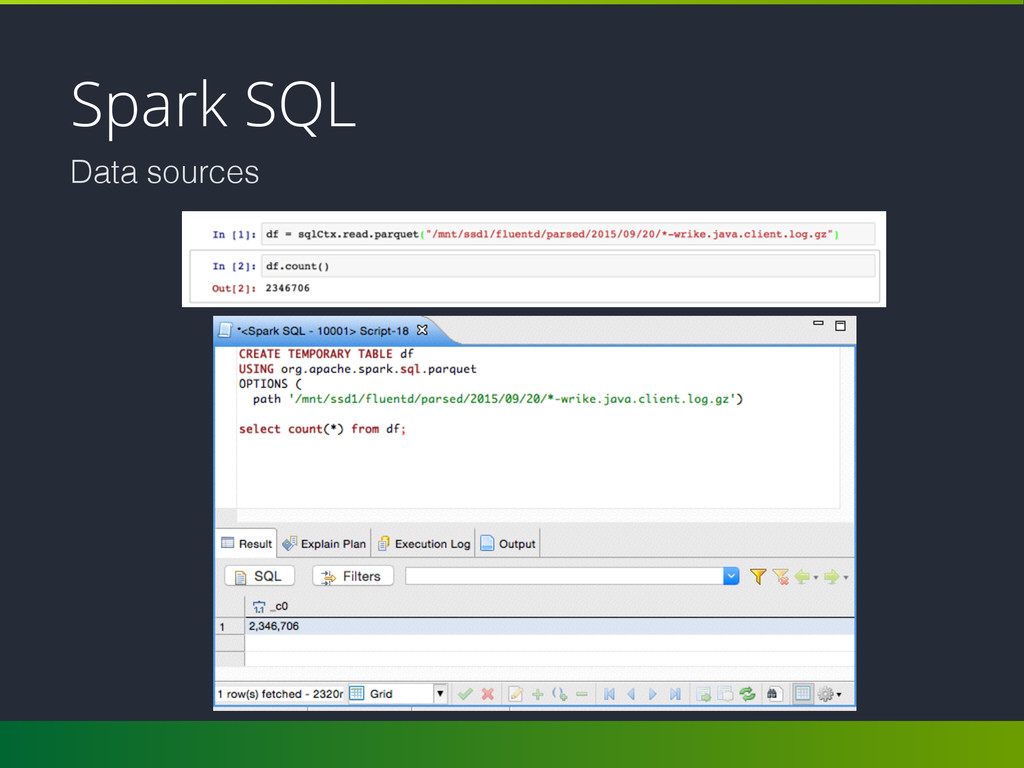
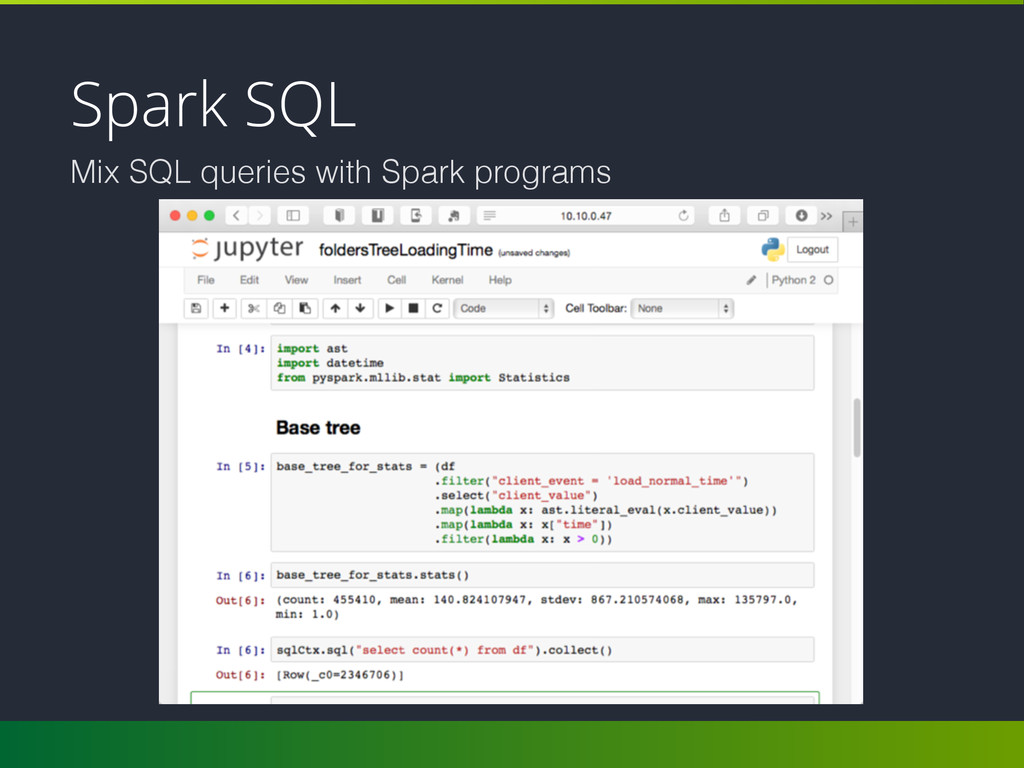
structured data. • DataFrame and seamlessly mix SQL queries with Spark programs; • Connect to any data source the same way: Hive, Avro, Parquet, JSON and JDBC; • Server mode: connect to Spark SQL with you favorite DB client over JDBC.
Relational Data Processing in Spark" by Michael Armbrust, Reynold S. Xin, Cheng Lian, Yin Huai, Davies Liu, Joseph K. Bradley, Xiangrui Meng, Tomer Kaftan‡, Michael J. Franklin‡, Ali Ghodsi, Matei Zaharia. Databricks Inc. MIT CSAIL, AMPLab, UC Berkeley
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}