Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
10分で詰め込むHadoop
Search
kanga333
April 02, 2018
Technology
160
0
Share
10分で詰め込むHadoop
MicroAd 社内LT会資料
kanga333
April 02, 2018
More Decks by kanga333
See All by kanga333
Athenaを使ったバッチ処理のTIPS
kanga333
0
910
個々のアプリのリポジトリでTerraformを管理している話
kanga333
4
3.8k
docker_and_make
kanga333
1
420
CoreOS Container Linuxで始めるベアメタルKubernetes
kanga333
3
9k
ORCについて調べた
kanga333
0
260
burrow_monitoring
kanga333
0
870
j2hの紹介
kanga333
0
6.3k
Other Decks in Technology
See All in Technology
はじめてのDatadog
kairim0
0
280
先取りMaven4 ~16年ぶりのメジャーアップデート、その進化とは?~
ogiwarat
0
140
タクシーアプリ『GO』の実践的データ活用
mot_techtalk
2
150
LLMを「主役」にしないための 3つの原則
techtekt
PRO
0
120
イベントストーミングとKiroの仕様駆動開発で実現する要件の認識合わせプロセス
syobochim
7
1.2k
関西に縁あるMicrosoft MVPsが語るCopilotの未来
kasada
0
1.2k
新規ゲーム開発におけるAI駆動開発のリアル
202409e2
0
2.5k
[モダンアプリ勉強会]今更聞けないGit/GitHub入門
tsukuboshi
0
260
そのPoC、何を検証したつもりでしたか? AIプロダクトの価値検証で陥った落とし穴
techtekt
PRO
0
150
2026.06.13_AI時代に事業会社が「SIer出身エンジニア」を求める理由 / Why Businesses Seek Engineers with a System Integrator Background in the AI Era
jumtech
0
490
さきさん文庫の書籍ができるまで
sakiengineer
0
360
製造業のクラウド活用最適解〜AI,DXを加速するデータ基盤の作り方〜
hamadakoji
0
370
Featured
See All Featured
Claude Code のすすめ
schroneko
67
230k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
390
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.3k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Docker and Python
trallard
47
3.9k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
400
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
250
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
220
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
130
Mobile First: as difficult as doing things right
swwweet
225
10k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Transcript
10分で詰め込むHadoop kagawa_shoichi
あらまし Hadoopとはなんぞやという話を10分で詰め込む ざっくり概要と用途について 厳密には違ったりするかもしれんけど、雰囲気伝わるの重視
(広義の)Hadoopとは HDFS, MapReduce等を中心としたビッグデータ処理の ミドルウェア、ライブラリなんかの総称
(狭義の)Hadoopとは 巨大なデータに対するバッチ処理ミドルウェアである HDFS, YARN, MapReduceの事を示す それぞれについては後述
Hadoopのディストリビューション LinuxにおけるRedhat,Ubuntuと同様にHadoopにも ディストリビューションがある 普通はOSSのHadoopを直で使ったりせず なんらかディストリビューションのものを使う 主要なディストリビューションベンダー Cloudera (CDH) Hortonworks (HDP)
MAPR (MARP) Pivotal (Pivotal HD)
主要Hadoopコンポーネント HDFS YARN MapReduce Spark Hive ZooKeeper
HDFS Hadoop Distributed File System 分散ファイルシステム ファイルをブロックという単位で分割して複数サーバに保持 させる
YARN 分散環境のサーバ郡のリソーススケジューラー ジョブが投入された際に、そのジョブをどのサーバ達でどの くらいのCPU/メモリを割り当てて、実行するかを決定する
MapReduce map処理とreduce処理により大規模データを処理する フレームワーク map([ , , ], cook) => [
, , ] reduce([ , , ], eat) =>
Spark ひとまずは、洗練されたMapReduceくらいに思っておけばOK 中間データをオンメモリで持つから高速 MapとReduceのTaskを行うプロセスを区別せず使い回す 色んな便利ライブラリが付いている 機械学習: Spark ML リアルタイム処理: Spark
Streaming SQL: Spark SQL リアルタイム処理 with SQL: Spark Structured Streaming
Hive SQL処理エンジン SQLをMRやSparkなどのジョブに変換してデータを操作 ちなみにHive on SparkとSpark SQLは別物
Zookeeper 対障害性を高めた分散KVS Hadopコンポーネントのメタデータを管理する 分散環境において、どれがマスタなのか?などを管理
その他Hadoopコンポーネント解説 HBase Kudu Kafka Storm/SparkStreaming Impara/Presto
HBase オンメモリ分散列指向DB HDFSではできないデータの更新などができる ただし、メモリに乗り切るくらいのデータしか扱えない とはいえクラスタを組むのでスケールは可能
Kude 分散列指向ストレージ HDFSとHBaseのギャップを埋めるストレージ TB規模のデータをディスクとして持ちながら更新可能 とはいえ HBaseの方が早い HDFSの方が大規模データに対するスループットはある 用途 リアルタイムに更新などが発生する大規模データに対し て分析などのスキャン的な操作もしたい
Kafka 分散キューイングシステム スケール可能なFIFOでPubSubなキュー
Storm / Spark Streaming 分散リアルタイムバッチ処理フレームワーク リアルデータに対して細かくバッチ処理を行う リアルタイム処理フレームワークは乱立していてカオス リアルタイム処理フレームワーク Apache Flink,
Apache Apex, Heron, Kafka streams 各種リアルタイム処理をDSLで書ける Apache Beam リアルタイム処理をGUIで定義 Apache Nifi, Stream Sets リアルタイム処理 with SQL KSQL, Spark Structured Streaming
Impara / Presto 高速な分散SQL処理エンジン SQLをMRやSparkに変換するHiveと比較してSQLを処理する ことに特化して作られており高速 基本的には耐障害性を犠牲にしてスループットを高める設計 データを全部メモリに乗せて処理する バッチよりアドホッククエリ向き 多分Imparaの方が早いし、CDHと親和性高いけど
Prestoの方が汎用性高い
SQL処理エンジン使い分けの一例 ディスクIO多い単純なSQLジョブ > Hive on MR JOINなどの操作を含める複雑なSQLジョブ > Hive on
Spark アドホッククエリ実行環境 > Presto or Impala 機械学習 > Spark SQL と Spark ML
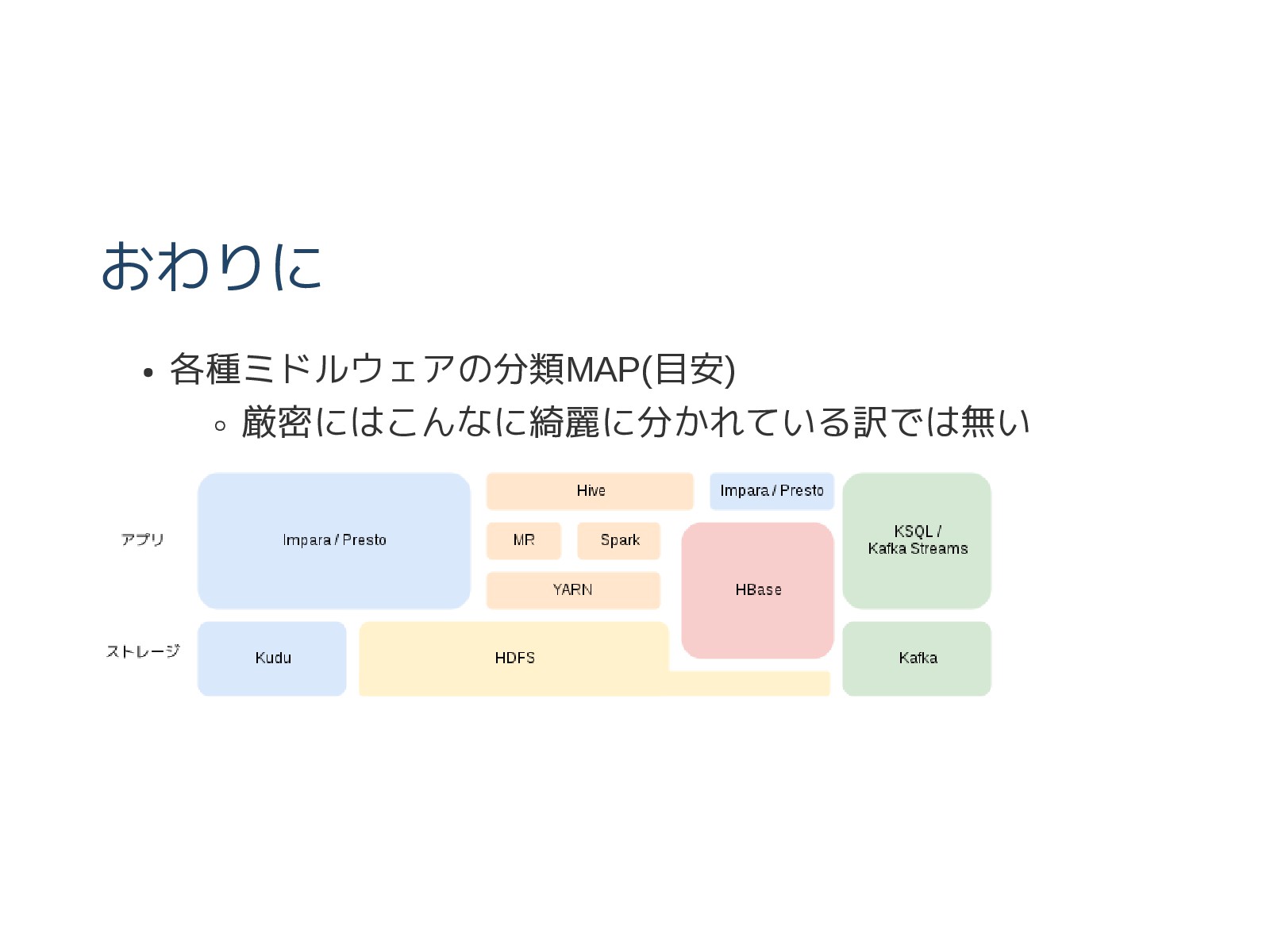
おわりに 各種ミドルウェアの分類MAP(目安) 厳密にはこんなに綺麗に分かれている訳では無い
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MapReduce map処理とreduce処理により大規模データを処理する フレームワーク map([ , , ], cook) => [](https://files.speakerdeck.com/presentations/5bde6b20702e40a8a257fb2400a53b03/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}