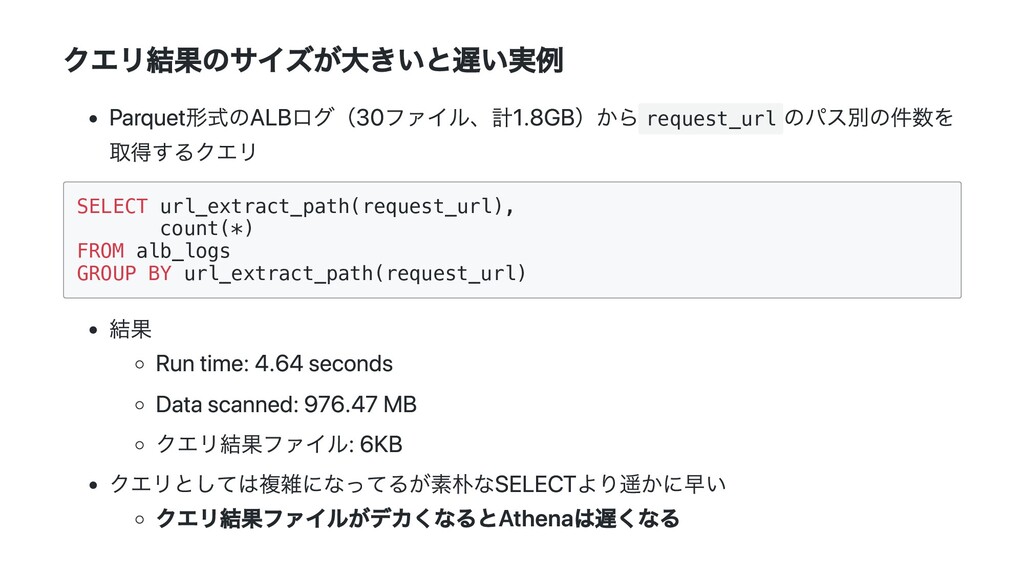
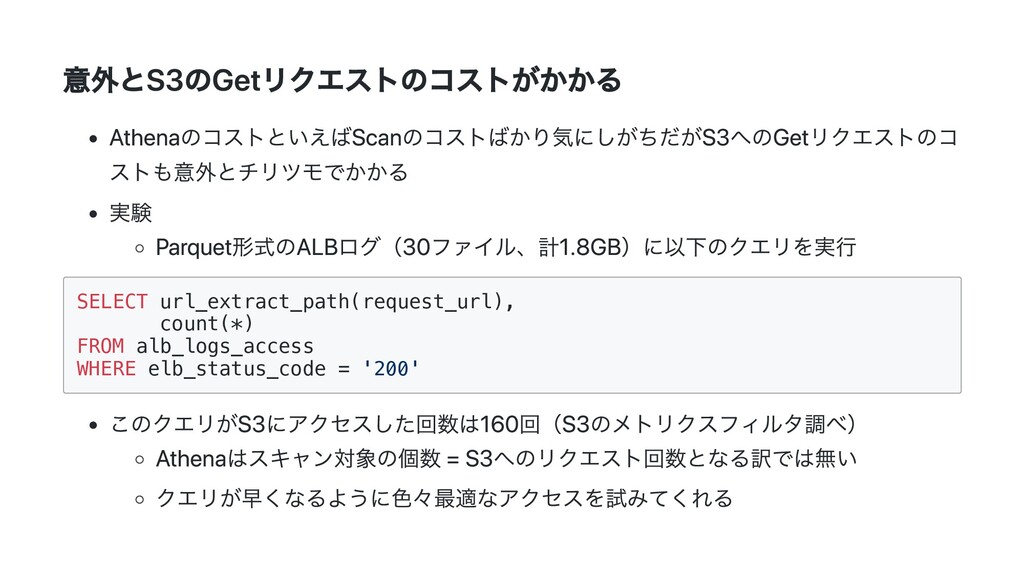
GROUP BY url_extract_path(request_url) 結果 Run time: 4.64 seconds Data scanned: 976.47 MB クエリ結果ファイル: 6KB クエリとしては複雑になってるが素朴なSELECTより遥かに早い クエリ結果ファイルがデカくなるとAthenaは遅くなる
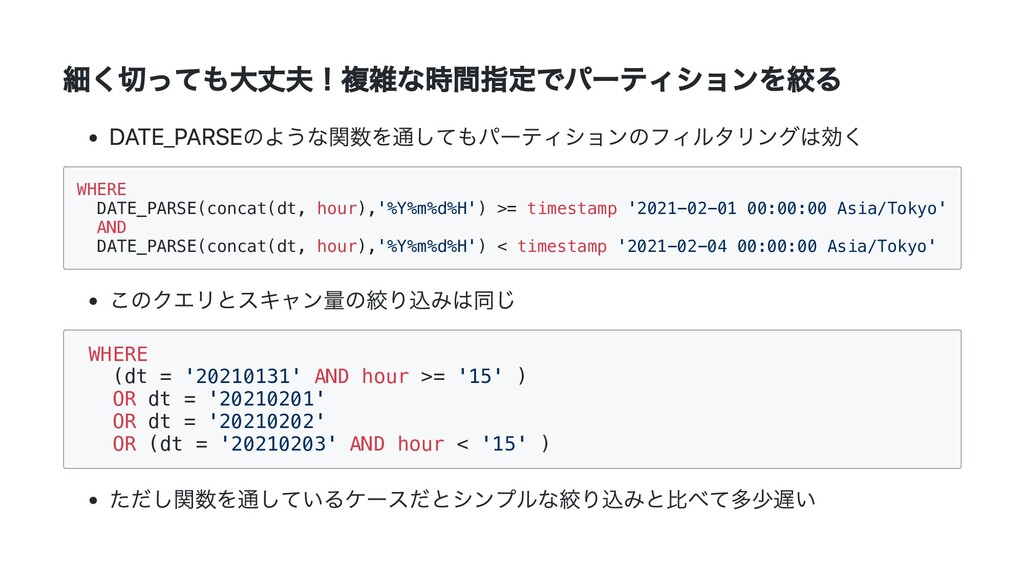
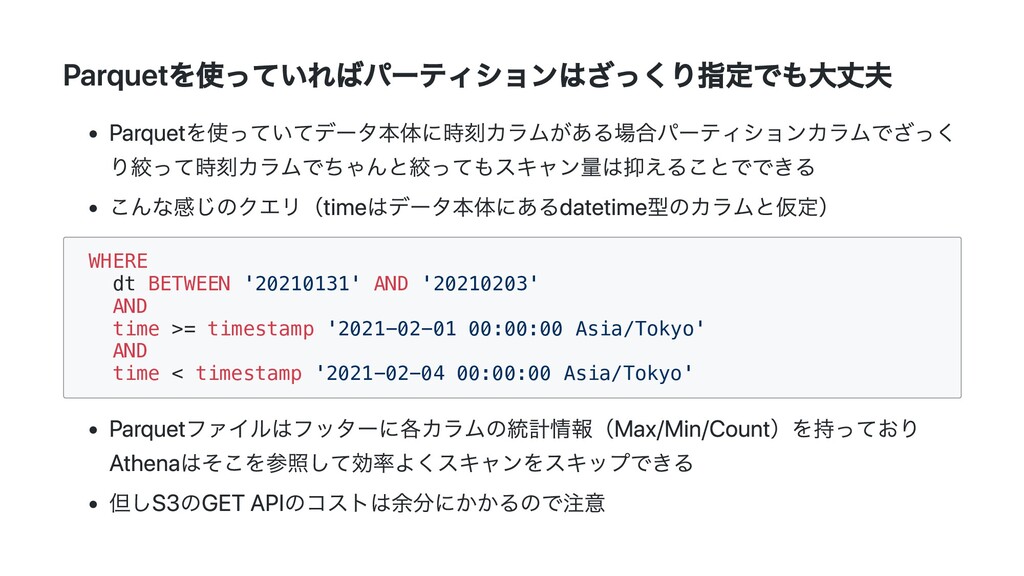
AND time >= timestamp '2021-02-01 00:00:00 Asia/Tokyo' AND time < timestamp '2021-02-04 00:00:00 Asia/Tokyo' Parquetファイルはフッターに各カラムの統計情報(Max/Min/Count)を持っており Athenaはそこを参照して効率よくスキャンをスキップできる 但しS3のGET APIのコストは余分にかかるので注意
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}