Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Introduction__to_Multimodal_RAG.pdf
Search
Miki Katsuragi
December 02, 2024
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Introduction__to_Multimodal_RAG.pdf
Miki Katsuragi
December 02, 2024
More Decks by Miki Katsuragi
See All by Miki Katsuragi
Vertex AI Gemini Prompt Engineering Tips
katsuragi
0
330
TensorFlow Probability ではじめる 確率的プログラミング入門
katsuragi
2
2.1k
Featured
See All Featured
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
650
Building an army of robots
kneath
306
46k
Designing for Timeless Needs
cassininazir
1
360
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
220
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.7k
Design in an AI World
tapps
1
260
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
Transcript
Proprietary + Confidential Multimodal RAG (Retrieval Augmented Generation) 入門 Miki
Katsuragi 5-Dec-2024
生成 AI による grounding の問題点
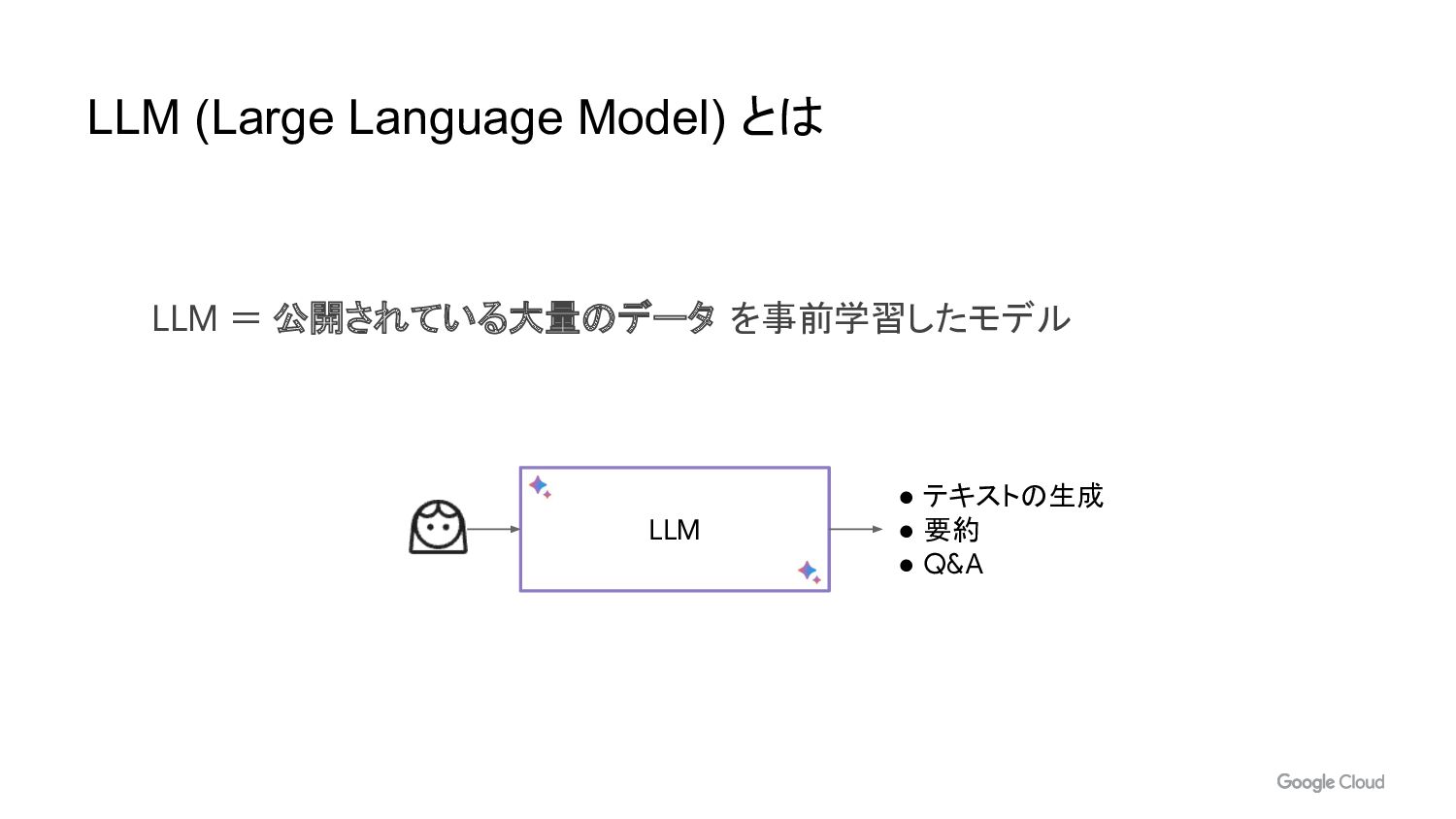
LLM = 公開されている大量のデータ を事前学習したモデル LLM (Large Language Model) とは LLM
• テキストの生成 • 要約 • Q&A
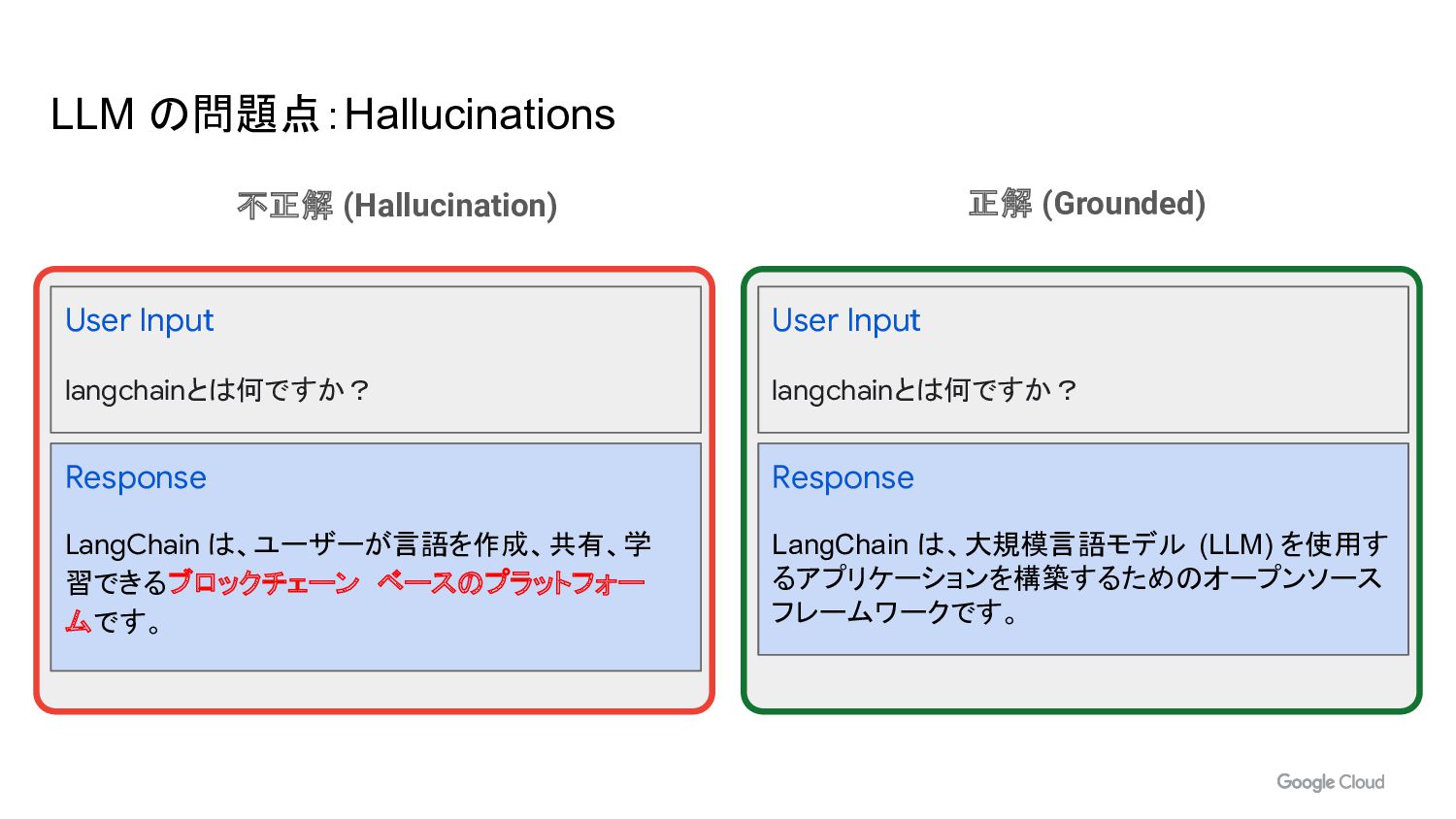
LLM の問題点:Hallucinations User Input langchainとは何ですか? Response LangChain は、ユーザーが言語を作成、共有、学 習できるブロックチェーン ベースのプラットフォー
ムです。 User Input langchainとは何ですか? Response LangChain は、大規模言語モデル (LLM) を使用す るアプリケーションを構築するためのオープンソース フレームワークです。 不正解 (Hallucination) 正解 (Grounded)
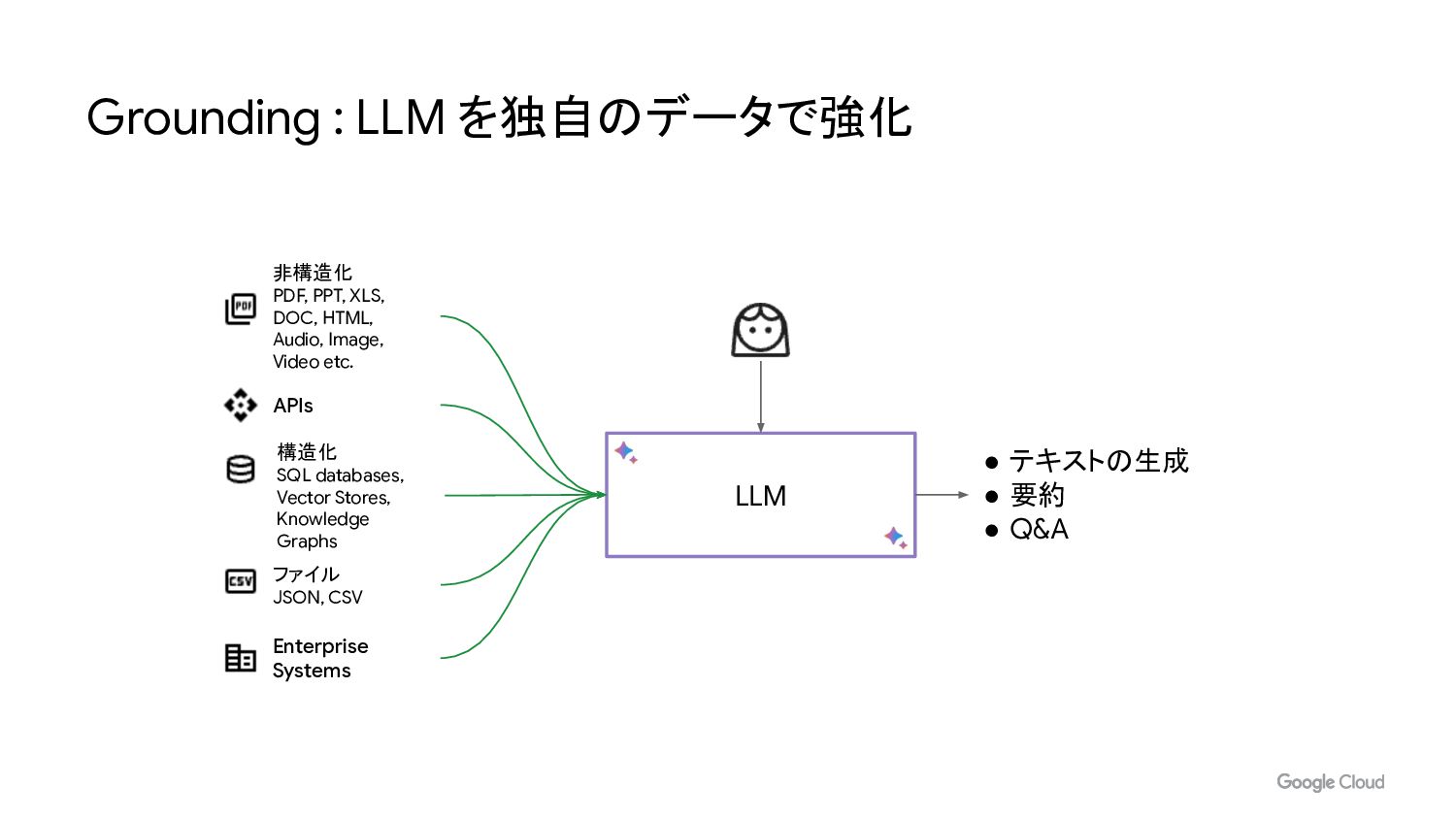
• テキストの生成 • 要約 • Q&A Grounding : LLM を独自のデータで強化
LLM 構造化 SQL databases, Vector Stores, Knowledge Graphs APIs 非構造化 PDF, PPT, XLS, DOC, HTML, Audio, Image, Video etc. ファイル JSON, CSV Enterprise Systems
(Full) Fine-Tuning 人間がチェックする Prompt Engineering fine-tuning を実行 ネットワークの重みを調整 してで LLM
を学習 - データ準備が必要 - 費用がかかる - データの更新に対応 が必要 - 期待したように動作 しない可能性あり LLM の出力を人間が確認 - 非常に工数がかかる - 人によるミスや誤りのリ スク 既知の情報をプロンプトに 追加して、LLM を誘導 - LLM のトークン制限 - エラーが発生しやすい: - 適切なコンテキストの取 得 - パフォーマンス、レイテ ンシー、コスト が犠牲に なる Hallucination の対応例
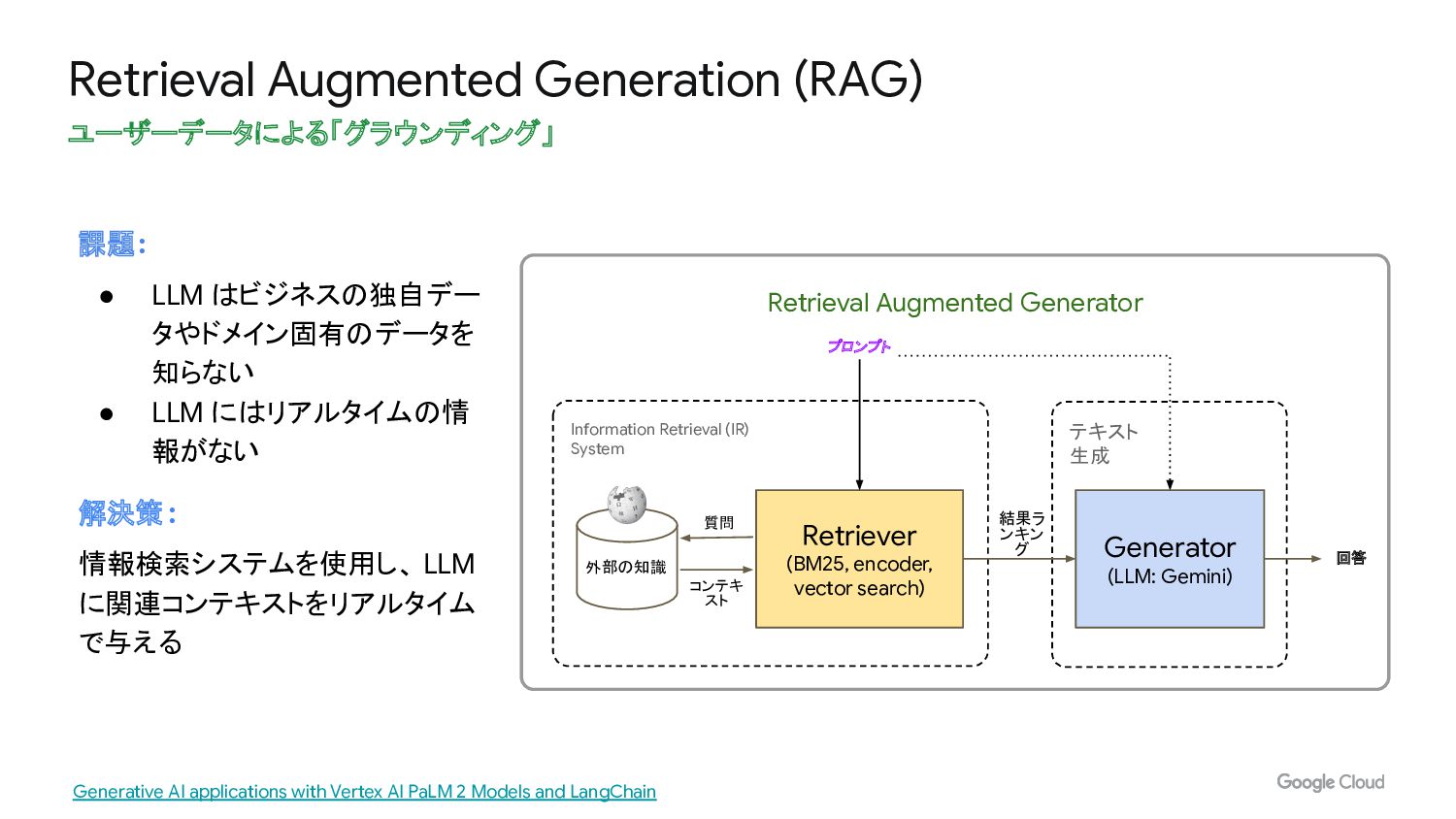
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) ユーザーデータによる「グラウンディング」 課題: • LLM はビジネスの独自デー タやドメイン固有のデータを
知らない • LLM にはリアルタイムの情 報がない 解決策: 情報検索システムを使用し、 LLM に関連コンテキストをリアルタイム で与える テキスト 生成 Information Retrieval (IR) System 外部の知識 Retriever (BM25, encoder, vector search) Generator (LLM: Gemini) 質問 コンテキ スト プロンプト 結果ラ ンキン グ Retrieval Augmented Generator 回答 Generative AI applications with Vertex AI PaLM 2 Models and LangChain
あなたは、{{company | 研究論文 | …}} に関するユーザーの質問をサポートするイン テリジェントなアシスタントです。次の context のみを使用して質問に回答してくださ い。
なお、事実と異なる回答は捏造しないでください: - 質問に対する答えが文脈だけから判断できない場合は、「それに対する答えは判 断できません」と回答してください - 文脈が空の場合は「それに対する答えがわかりません」とだけ回答してください context: {{retrieved_information}} 質問:{{question} 回答: RAG における回答生成時のプロンプト例
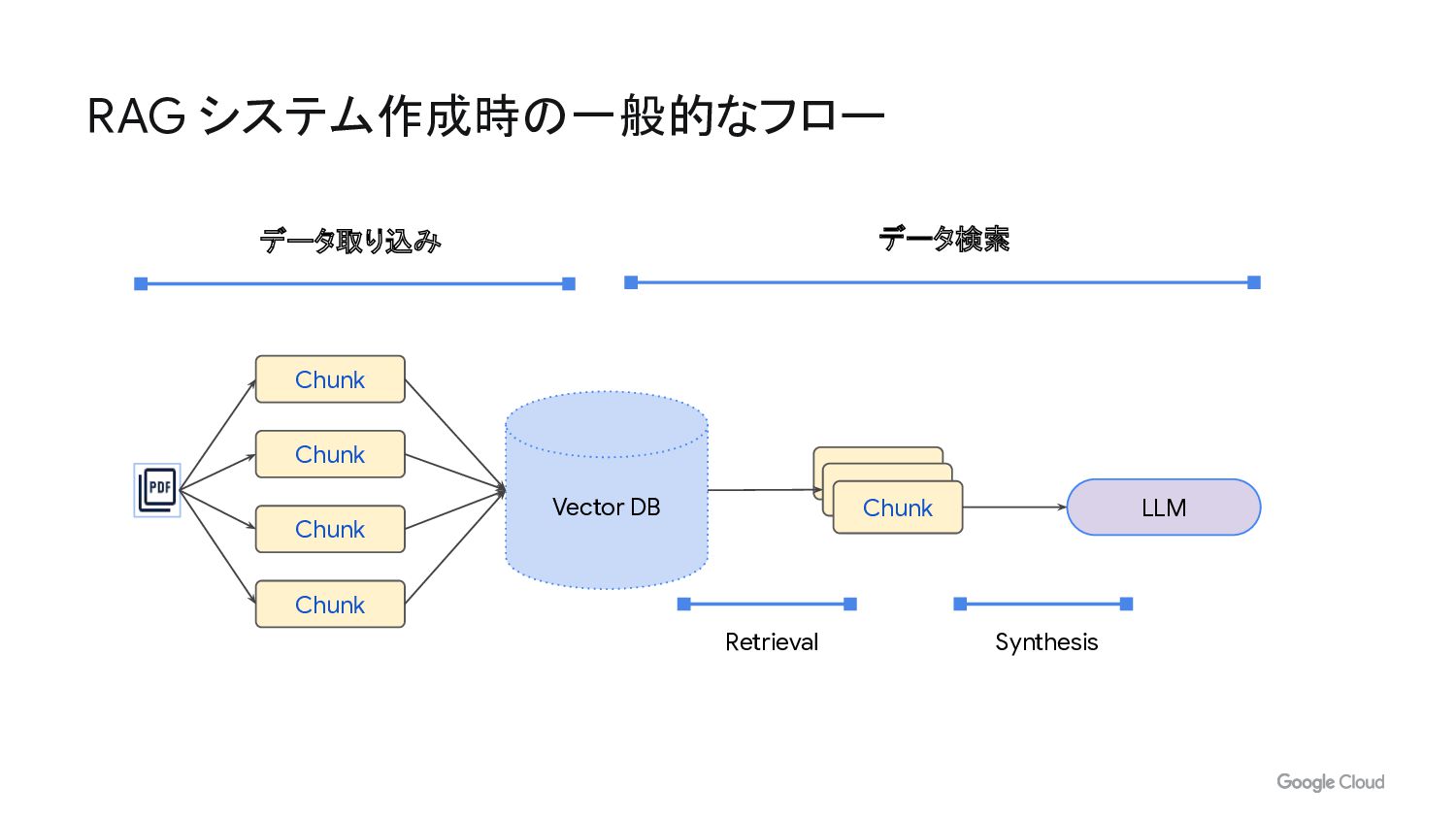
RAG システム作成時の一般的なフロー データ取り込み データ検索 Chunk Chunk Chunk Chunk Vector DB
Chunk LLM Retrieval Synthesis
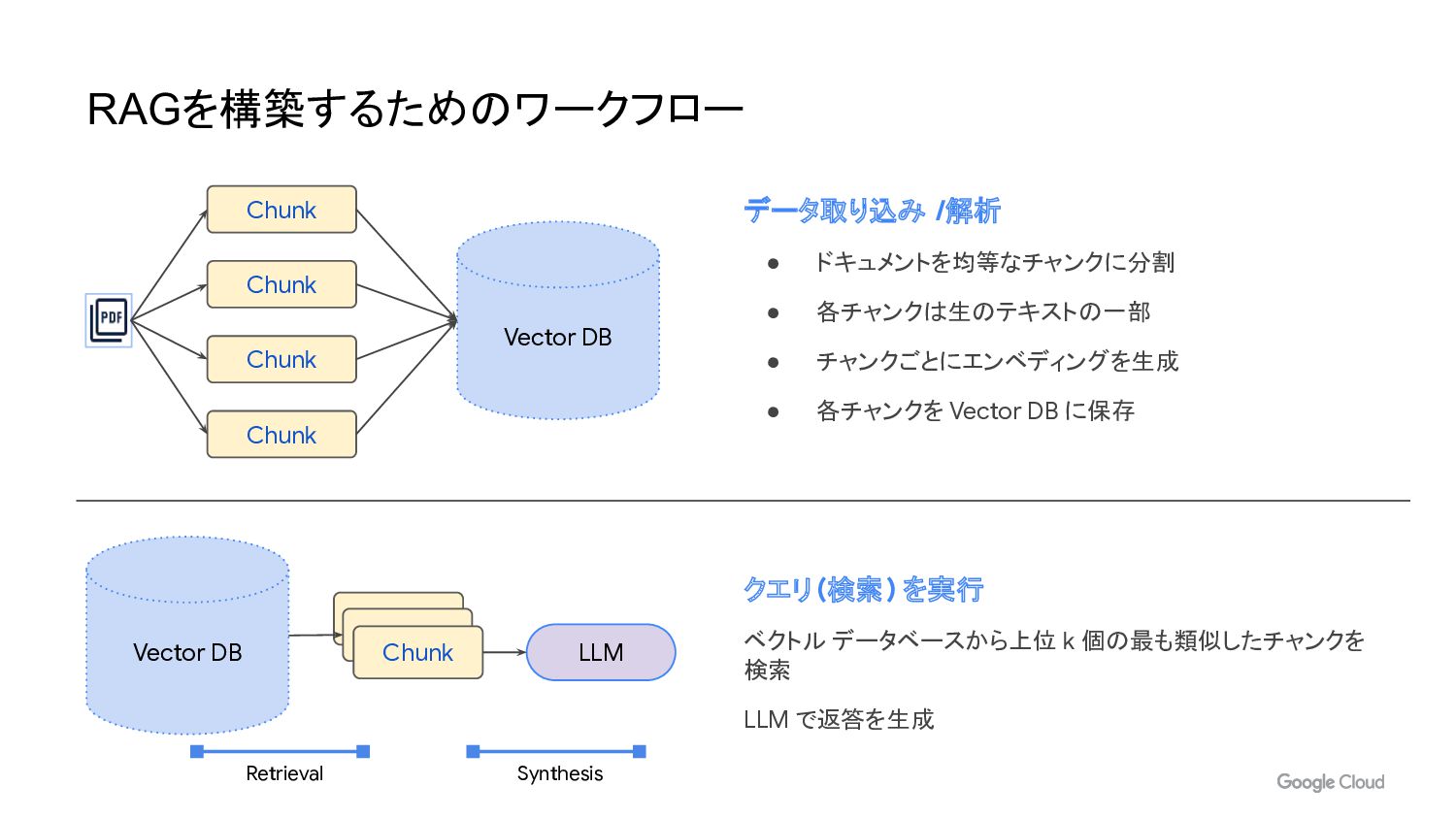
データ取り込み /解析 • ドキュメントを均等なチャンクに分割 • 各チャンクは生のテキストの一部 • チャンクごとにエンベディングを生成 • 各チャンクを
Vector DB に保存 RAGを構築するためのワークフロー Chunk Chunk Chunk Chunk Vector DB Vector DB Chunk LLM クエリ(検索) を実行 ベクトル データベースから上位 k 個の最も類似したチャンクを 検索 LLM で返答を生成 Retrieval Synthesis
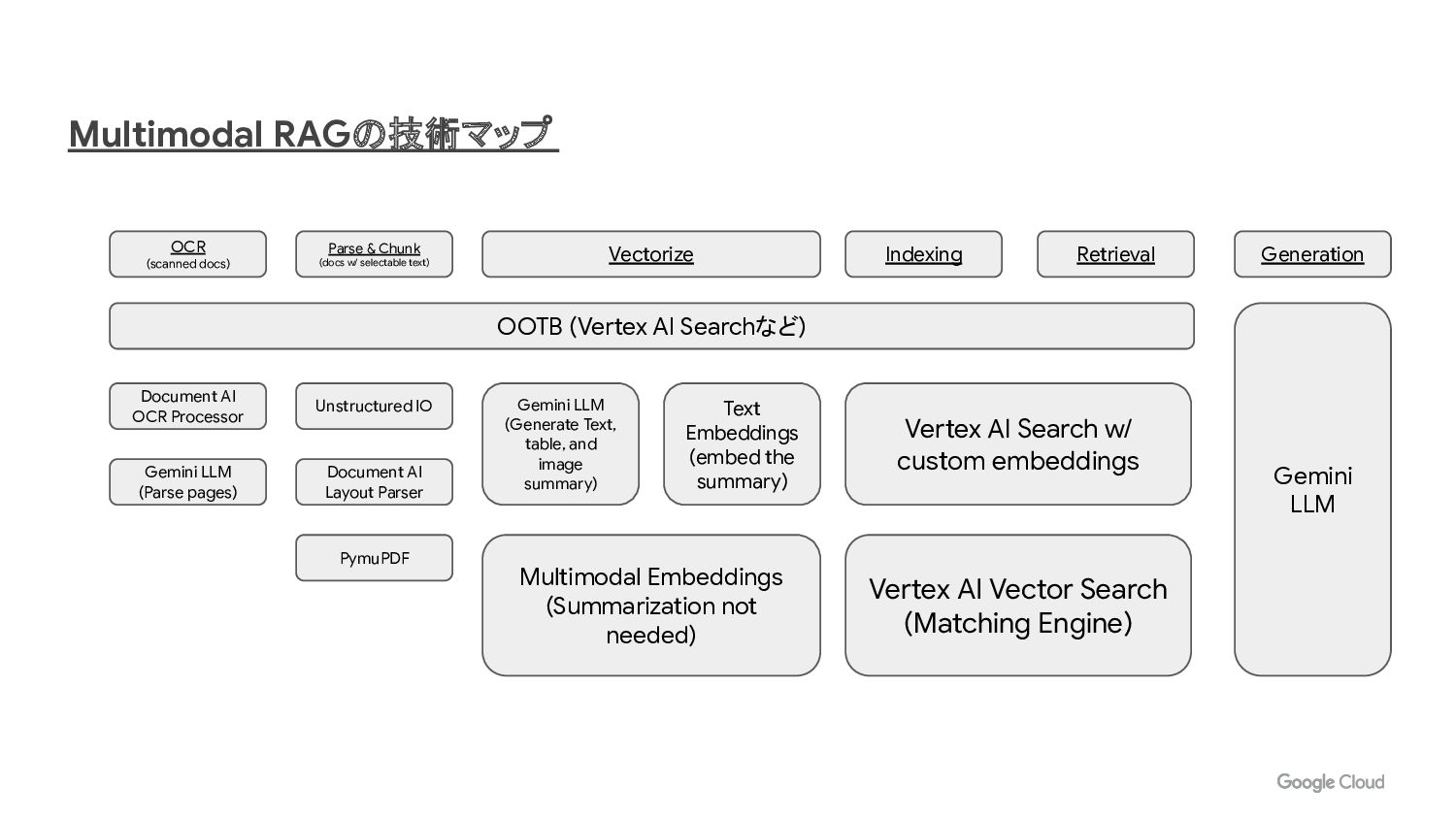
Multimodal RAGの技術マップ Parse & Chunk (docs w/ selectable text) Vectorize
Indexing Retrieval Generation OOTB (Vertex AI Searchなど) Vertex AI Search w/ custom embeddings Vertex AI Vector Search (Matching Engine) Text Embeddings (embed the summary) Gemini LLM (Generate Text, table, and image summary) Gemini LLM Unstructured IO Document AI Layout Parser PymuPDF Multimodal Embeddings (Summarization not needed) OCR (scanned docs) Document AI OCR Processor Gemini LLM (Parse pages)
Embeddings によるマルチモーダル RAG(Retrieval-Augmented Generation)構築
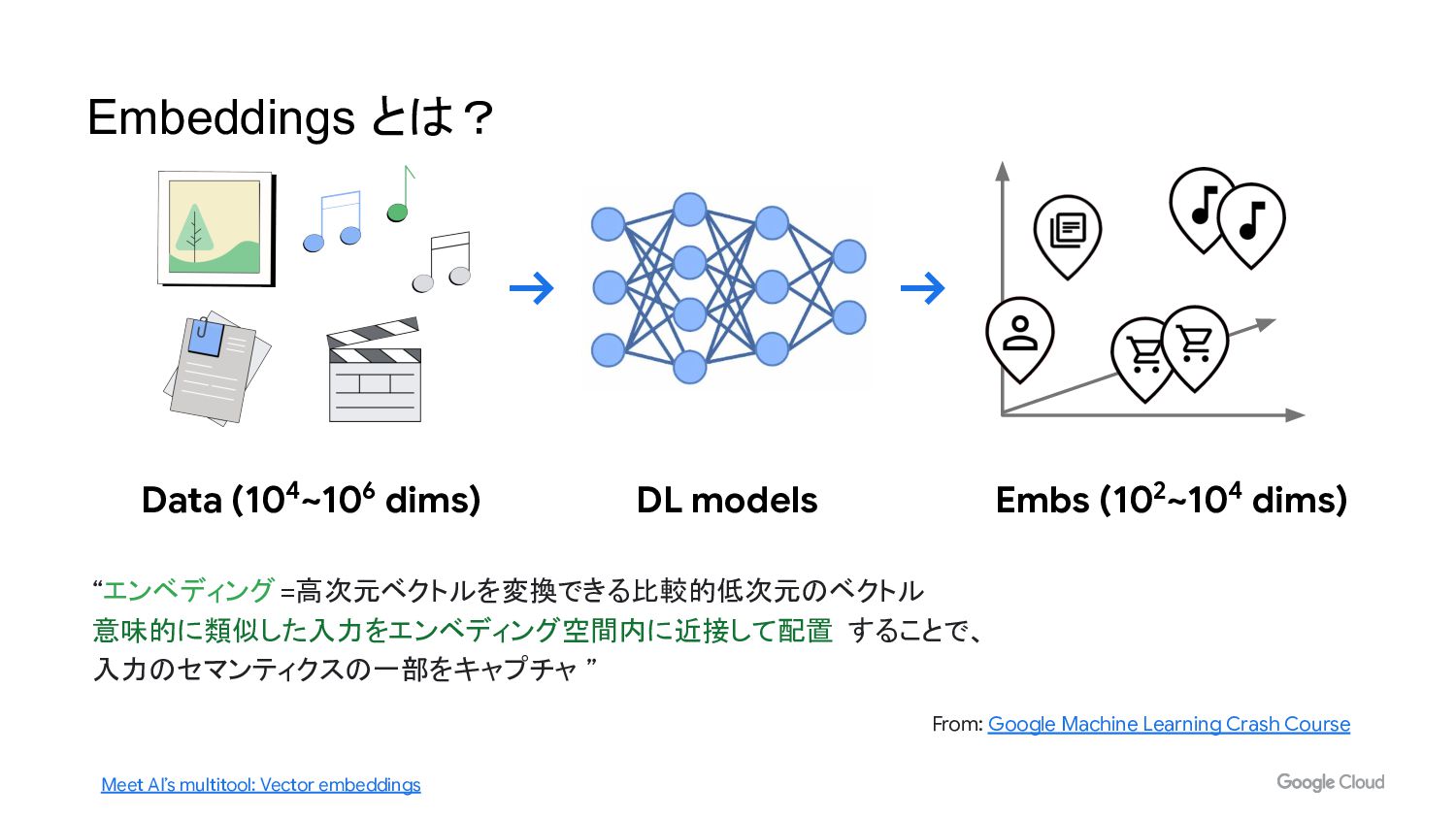
“エンベディング=高次元ベクトルを変換できる比較的低次元のベクトル 意味的に類似した入力をエンベディング空間内に近接して配置 することで、 入力のセマンティクスの一部をキャプチャ ” From: Google Machine Learning Crash
Course Data (104~106 dims) DL models Embs (102~104 dims) Meet AI’s multitool: Vector embeddings Embeddings とは?
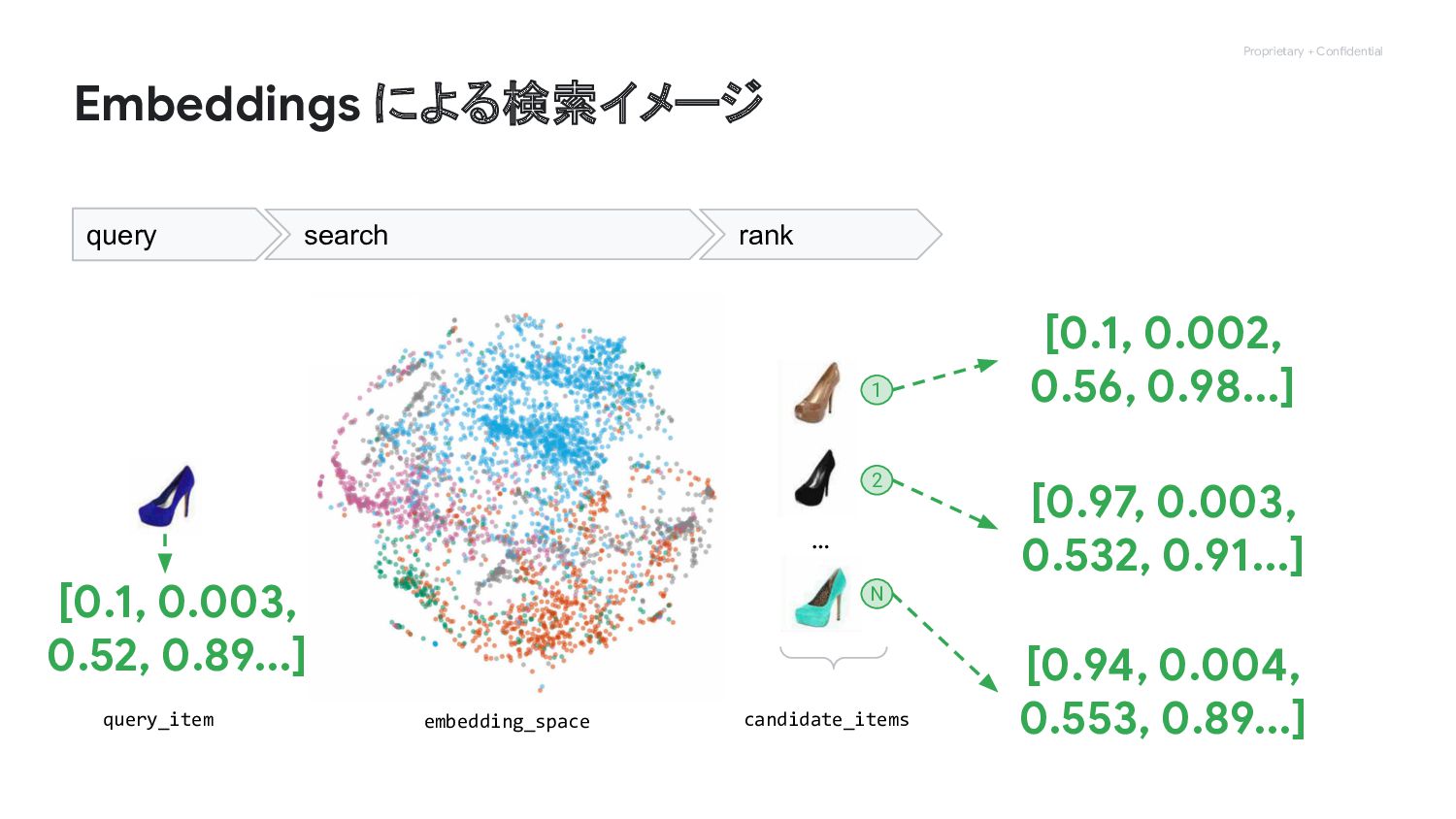
Proprietary + Confidential Embeddings による検索イメージ … 1 2 N embedding_space
query_item candidate_items query search rank [0.1, 0.002, 0.56, 0.98...] [0.97, 0.003, 0.532, 0.91...] [0.94, 0.004, 0.553, 0.89...] [0.1, 0.003, 0.52, 0.89...]
Proprietary + Confidential 従来の検索手法:Exact search/brute force search クエリが与えられた際、最も関連性の高い候補アイテムをアイテムのコーパスから検索 query search
rank … 1 2 N Brute force (exhaustive) search 数百万・数十億の商品を含む大規模 DBで は実行不可能 計算の非効率性 → 関連するのは小さなサブセットのみ → リアルタイムのランキングは不可能 embedding_space query_item candidate_items
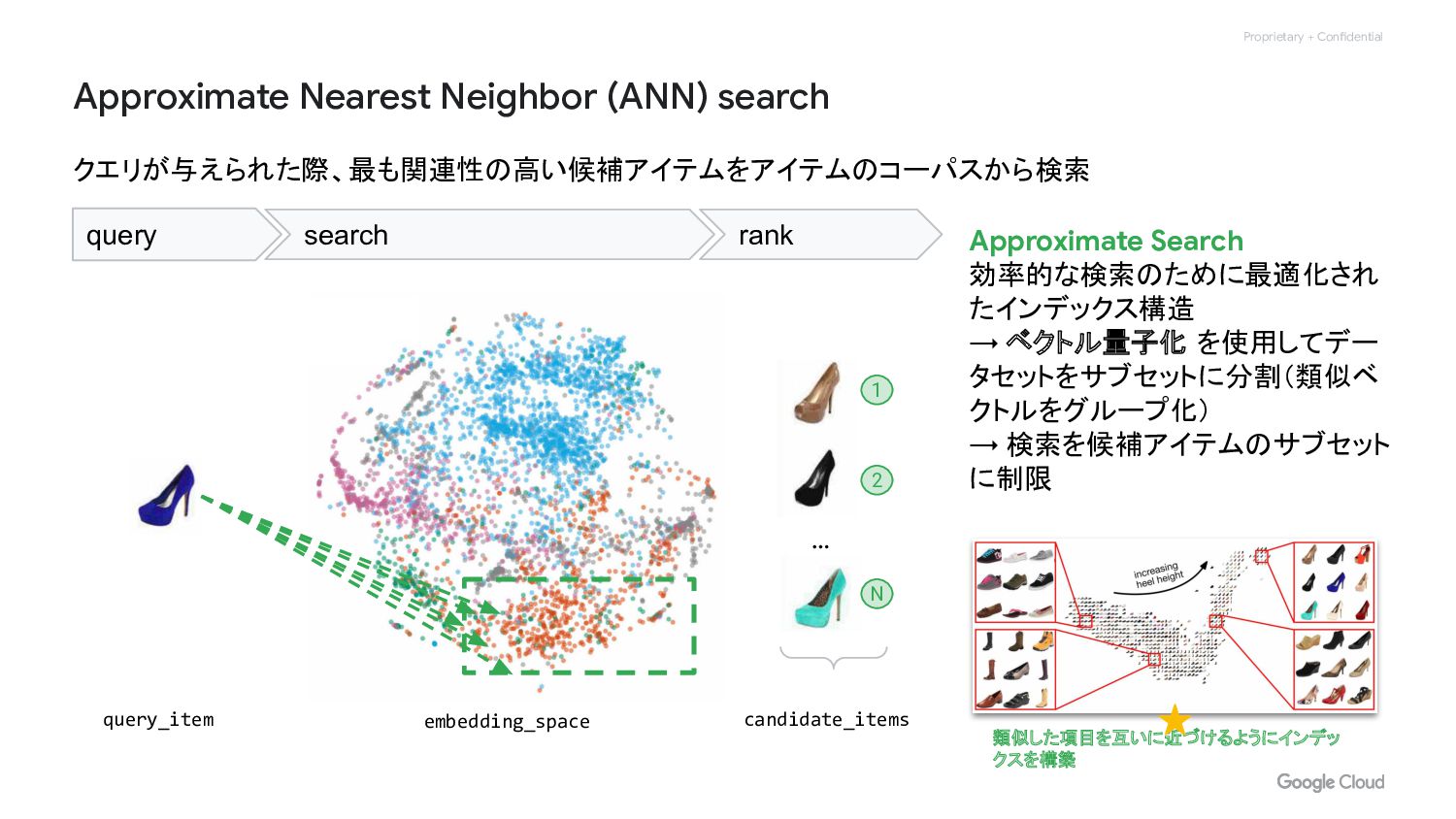
Proprietary + Confidential Approximate Nearest Neighbor (ANN) search クエリが与えられた際、最も関連性の高い候補アイテムをアイテムのコーパスから検索 query
search rank … 1 2 N Approximate Search 効率的な検索のために最適化され たインデックス構造 → ベクトル量子化 を使用してデー タセットをサブセットに分割(類似ベ クトルをグループ化) → 検索を候補アイテムのサブセット に制限 類似した項目を互いに近づけるようにインデッ クスを構築 embedding_space query_item candidate_items
イベント告知 [年内ラスト ] 一番いいのを頼む !? 生成AIによる推薦 !! 応募方法:connpass 開催日時:2024/12/18(木) 18:00〜予定
現地会場:Google渋谷オフィス (ハイブリッド開催) 定員:現地20名/オンライン無制限 41 概要 申込はこちら ※connpassへ登録の上お申込み下さい! ML女子部とは 機械学習やデータ分析をゆるく学ぶ会で す。数ヶ月に1回程度初心者向けのハンズ オンイベントを開催予定です。 初心者向けのグループなので,はじめての 方でも大丈夫です! ML/データ分析に興 味ある方はぜひどなたでもご参加ください。 女性メンバー中心で運営しているグループ ですが、男性の参加もお待ちしてます♪ ▼対象 ・Pythonの基本的な知識がある方 ・chromeブラウザが動作する PCを お持ちの方 ・男性の参加も OKです!
Proprietary + Confidential THANK YOU!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![イベント告知 [年内ラスト ] 一番いいのを頼む !? 生成AIによる推薦 !! 応募方法:connpass 開催日時:2024/12/18(木) 18:00〜予定](https://files.speakerdeck.com/presentations/5c7ff5ed92a341019faae8e5f576d66b/slide_17.jpg){kind=link}
{kind=link}