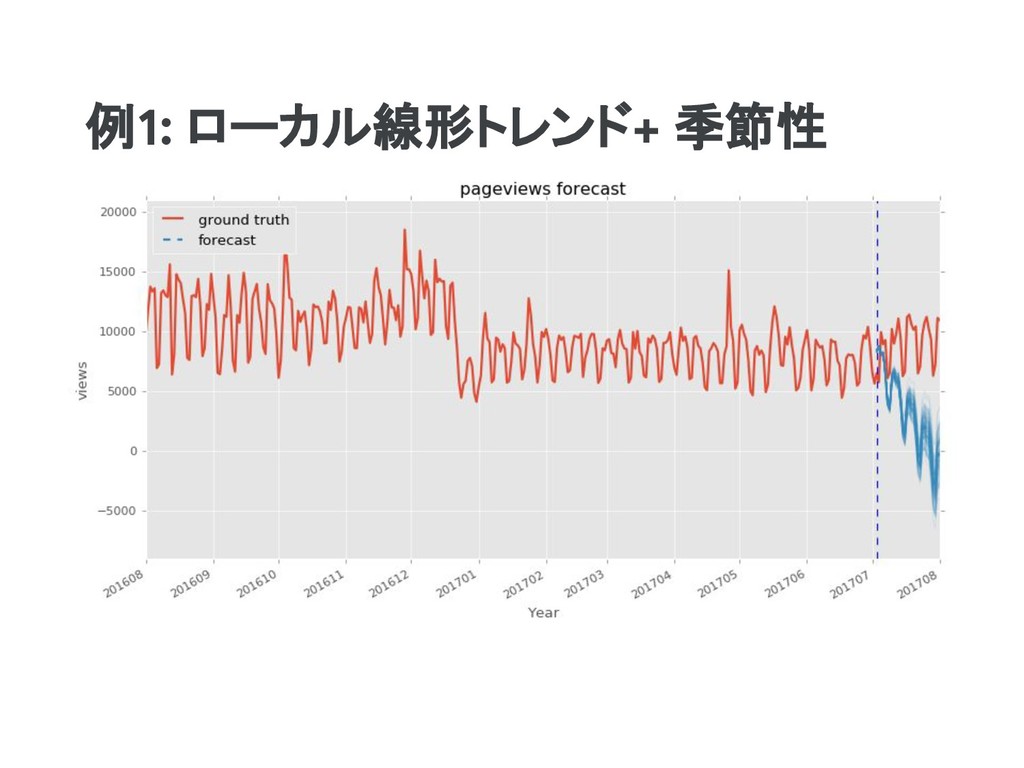
tfp.sts.Seasonal( num_seasons=7, observed_time_series=observed_time_series) model = sts.Sum([trend, seasonal], observed_time_series=observed_time_series) return model
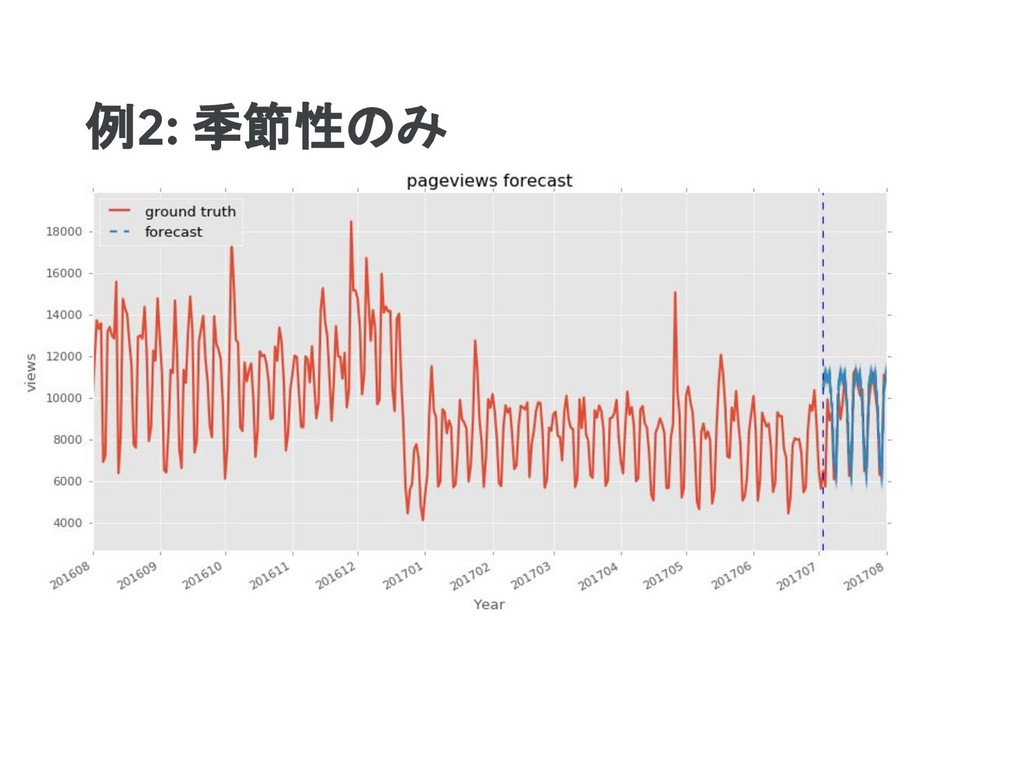
observed_time_series=observed_time_series) model = sts.Sum([seasonal], observed_time_series=observed_time_series) return model tf.reset_default_graph() model = build_model(training_data)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![事後サンプリング [lambda_1, lambda_2, tau], _ = tfp.mcmc.sample_chain( num_results=int(10e3), num_burnin_steps=int(1e3), current_state=initial_chain_state,](https://files.speakerdeck.com/presentations/67c8bb510bf3443c9142177cb6e4227a/slide_60.jpg){kind=link}
![事後サンプリング [lambda_1, lambda_2, tau], _ = tfp.mcmc.sample_chain( num_results=int(10e3), num_burnin_steps=int(1e3), current_state=initial_chain_state,](https://files.speakerdeck.com/presentations/67c8bb510bf3443c9142177cb6e4227a/slide_61.jpg){kind=link}
![事後サンプリング [lambda_1, lambda_2, tau], _ = tfp.mcmc.sample_chain( num_results=int(10e3), num_burnin_steps=int(1e3), current_state=initial_chain_state,](https://files.speakerdeck.com/presentations/67c8bb510bf3443c9142177cb6e4227a/slide_62.jpg){kind=link}
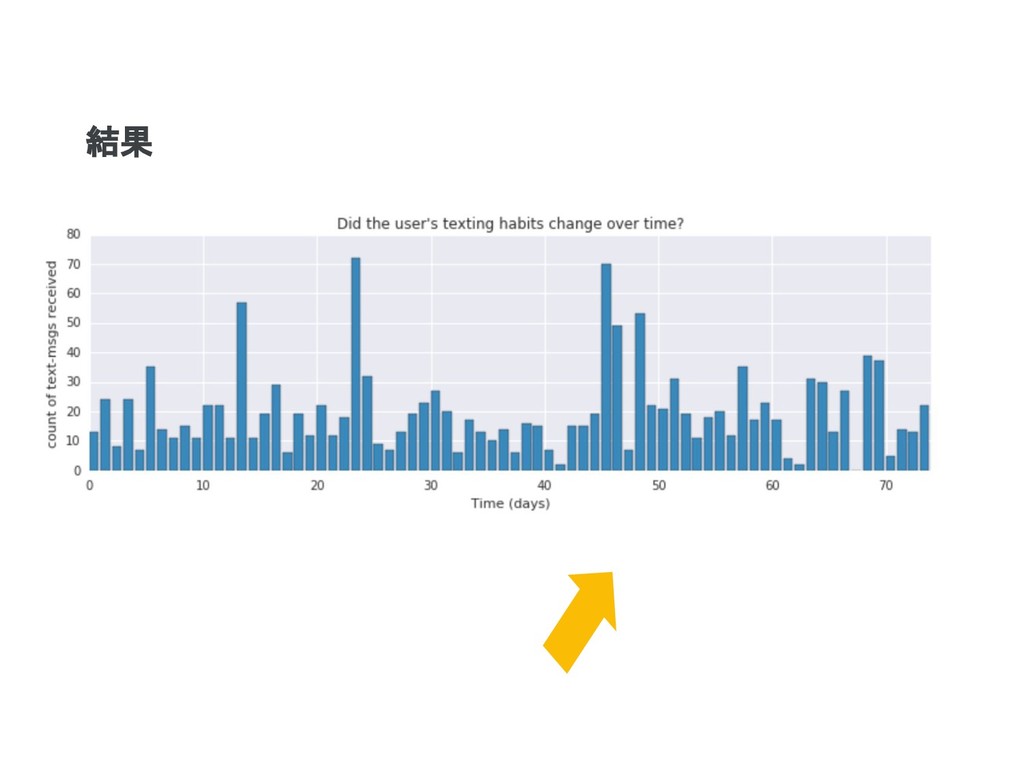{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}