of characters which may or may not predict (match) a given string. • Use the pattern match/no match for conditional branching • Scan for a pattern • String substitutions • Split strings
letter a, followed by a digit • Any uppercase letter, followed by at least one lowercase letter • Three digits, followed by a hyphen, followed by four digits • The beginning of a line, followed by one or more whitespace characters • The character . (period) at the end of a string • An uppercase letter at the beginning of a word
/Neo/.match "Neo is in the Matrix" puts "Neo" if "Neo is in the Matrix".match /Neo/ Returns a match object (more on this later) if true. /Neo/.match "Neo is in the Matrix" in irb would show a match object returned. If no match occurs a nil object is returned which has an implicit value of false (in Ruby).
the Matrix" puts "Neo" if "Neo is in the Matrix" =~ /Neo/ Using =~ differs in that it returns the index of the string where the regular expression was found. /Neo/ =~ "Neo is in the Matrix" in irb gives us 0
well as any string containing the letter "a" Weird characters like ^,$,?,.,/,\,[,],{,},(,),+, and * need a special \ to make it literal. Reason being is that these characters are special in regular expression syntax. In order to match a literal ? the regular expression would have to look like this: /\?/
of square brackets /[dr]ejected/ Match either 'd' or 'r' and no other characters followed by 'ejected' Match /[dr]ejected/ =~ "dejected" /[dr]ejected/ =~ "rejected" No match /[dr]ejected/ =~ "bejected"
digit you can do this: /[0-9]/ You can accomplish the same thing with: /\d/ Other useful escape sequences are: \w matches any digit, alphabetical character, or _ \s matches any whitespace character (space, tab, newline)
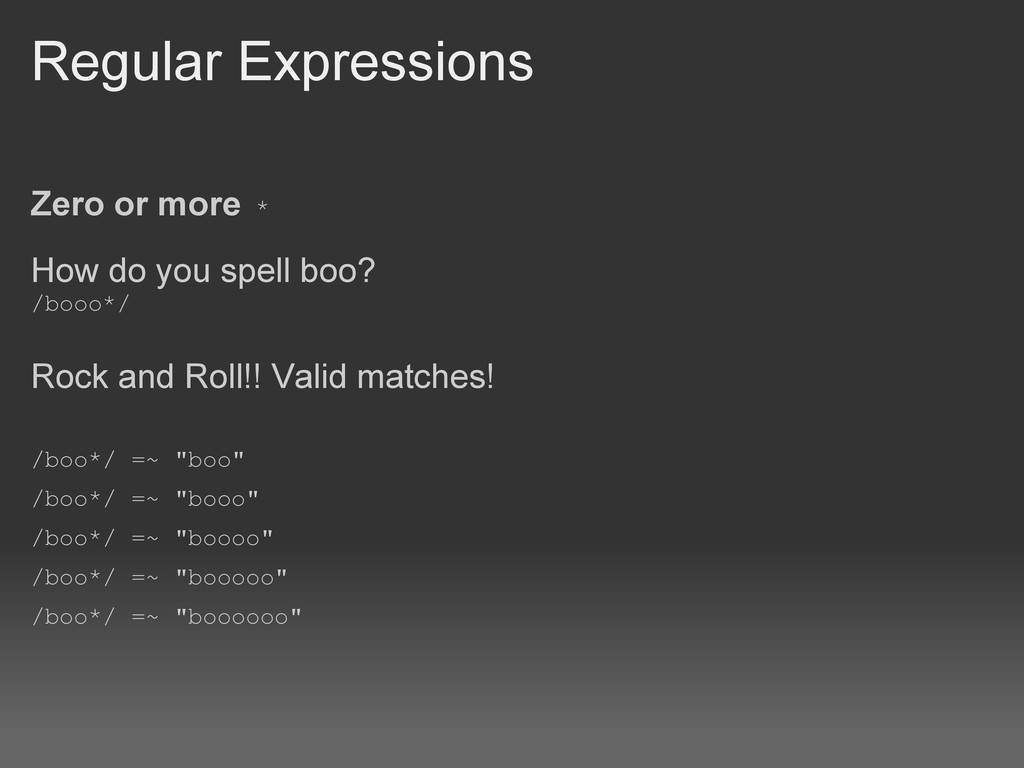
English pattern: blake,karmen blake, karmen "last name followed by a comma followed by an optional space followed by first name" /^[A-Za-z]+,\s*[A-Za-z]+$/ * optional (zero or more) + (one or more, or at least one)
rule and get contents out after evaluation. :-) This /^[A-Za-z]+,\s*[A-Za-z]+$/ may turn into /(^[A-Za-z]+),\s*([A-Za-z]+$)/ Test it in irb: /(^[A-Za-z]+),\s*([A-Za-z]+$)/.match "blake, karmen" puts $1 outputs "blake" puts $2 outputs "karmen"
learn soon my young padawans. Quantifiers!! Zero or one I want to match Mr, Mr., Mrs, Mrs. English version the character M, followed by the character r, followed by zero or one of the character s, followed by zero or one of the character '.'
file "123 karmen\n234 john\n456 mary". scan(/\d{3}/) => ["123", "234", "456"] Create permalink "john doe 1234 hello message". gsub(/\s/,"-") => "john-doe-1234-hello-message" Capitalize my string "a title of a book".gsub(/\b\w/) {|s| s.upcase}
extract information out of collections. ["JOHN","Doe","Mary","SWANSON"].find_all {|name| /[a-z]/ =~ name} OR ["JOHN","Doe","Mary","SWANSON"].grep(/[a-z]/) Both return a result array: => ["Doe", "Mary"]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Regular Expressions Character classes Range of characters /[a-z]/ Match any](https://files.speakerdeck.com/presentations/4e80dc815cc0ec0063001560/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Regular Expressions What the heck is this???!!!?? /^x?[yz]{2}.*\z/ You will](https://files.speakerdeck.com/presentations/4e80dc815cc0ec0063001560/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Regular Expressions Let's get real! Grepilicious ["JOHN","Doe","Mary","SWANSON"].find_all{|name| name =~ /[a-z]/}.](https://files.speakerdeck.com/presentations/4e80dc815cc0ec0063001560/slide_24.jpg){kind=link}