松田一起 Chaoyang Zhu1 , Yiyi Zhou1 , Yunhang Shen3 , Gen Luo1, Xingjia Pan3, Mingbao Lin3, Chao Chen3, Liujuan Cao1*, Xiaoshuai Sun1,4, Rongrong Ji1,2,4 1MAC Lab, Department of Artificial Intelligence, School of Informatics, Xiamen University. 2Institute of Energy Research, Jiangxi Academy of Sciences. 3Tencent Youtu Lab. 3Institute of Artificial Intelligence, Xiamen University. ECCV 2022 C. Zhu, Y. Zhou, Y. Shen, G. Luo, X. Pan, M. Lin, C. Chen, L. Cao, X. Sun, and R. Ji, “SeqTR: A Simple yet Universal Network for Visual Grounding,” in ECCV, 2022.
{kind=link}
{kind=link}
![3 背景 – 既存手法は複雑でタスク依存のものが多い ✔ V&Lタスクにおいて既存手法はネットワーク設計や損失関数における専門知識が必要 ✔ 例えばMAttNet[Yu+, CVPR18]では言語表現をSubject, Location,](https://files.speakerdeck.com/presentations/8c7a2a16723e496cbddc5c20ea6d5325/slide_2.jpg){kind=link}
{kind=link}
![5 関連研究 – Pix2Seq, MAttNet 手法 概要 Pix2Seq [Chen+, ICLR22]](https://files.speakerdeck.com/presentations/8c7a2a16723e496cbddc5c20ea6d5325/slide_4.jpg){kind=link}
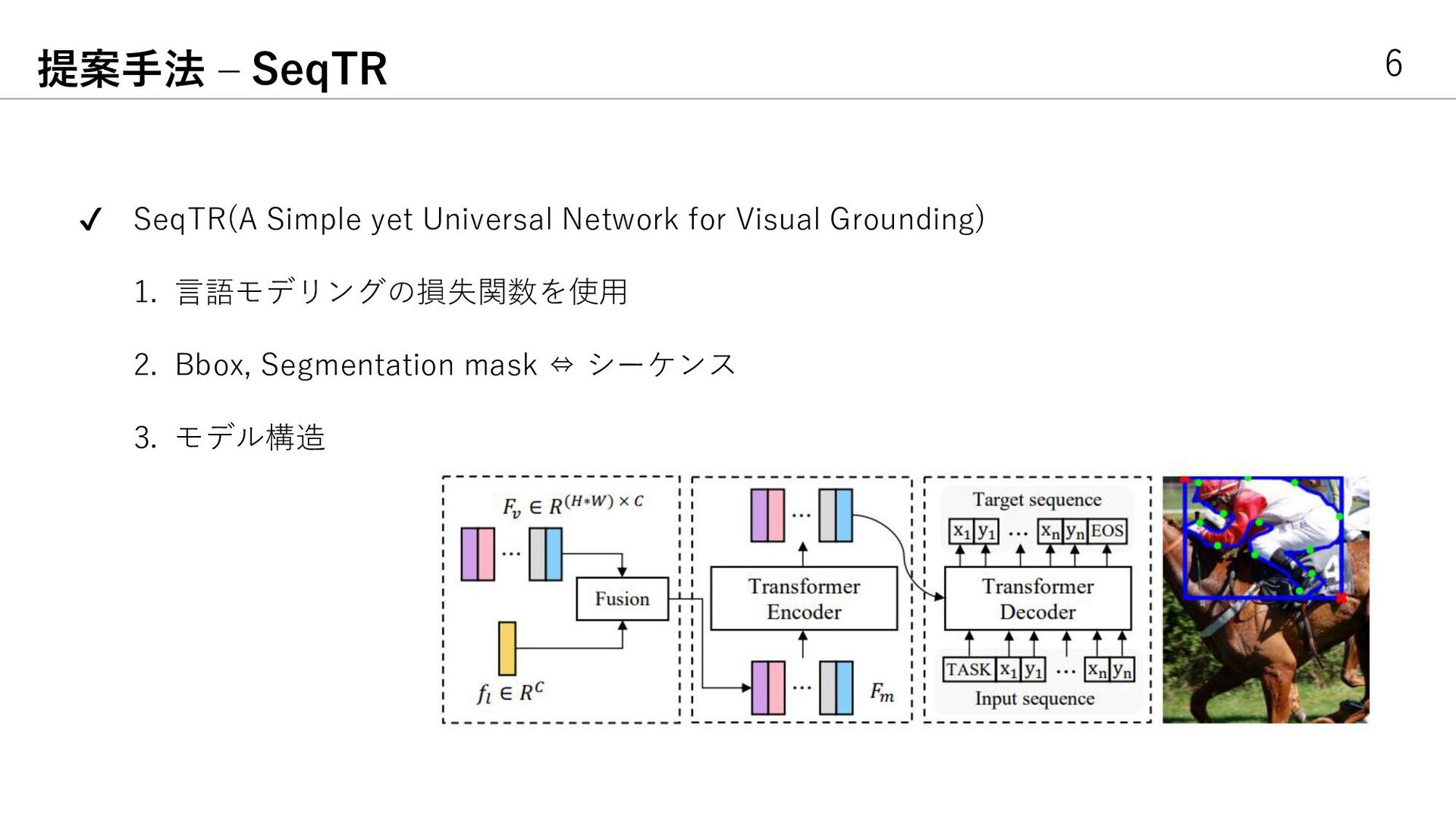{kind=link}
{kind=link}
![8 提案1 -言語モデリングの損失関数(2/4) ✔ SeqTRは既存手法と異なり、Bbox, Segmentation maskを離散座標として扱う ✔ [TASK]: シーケンスの始点&どのタスクに取り組んでいるか](https://files.speakerdeck.com/presentations/8c7a2a16723e496cbddc5c20ea6d5325/slide_7.jpg){kind=link}
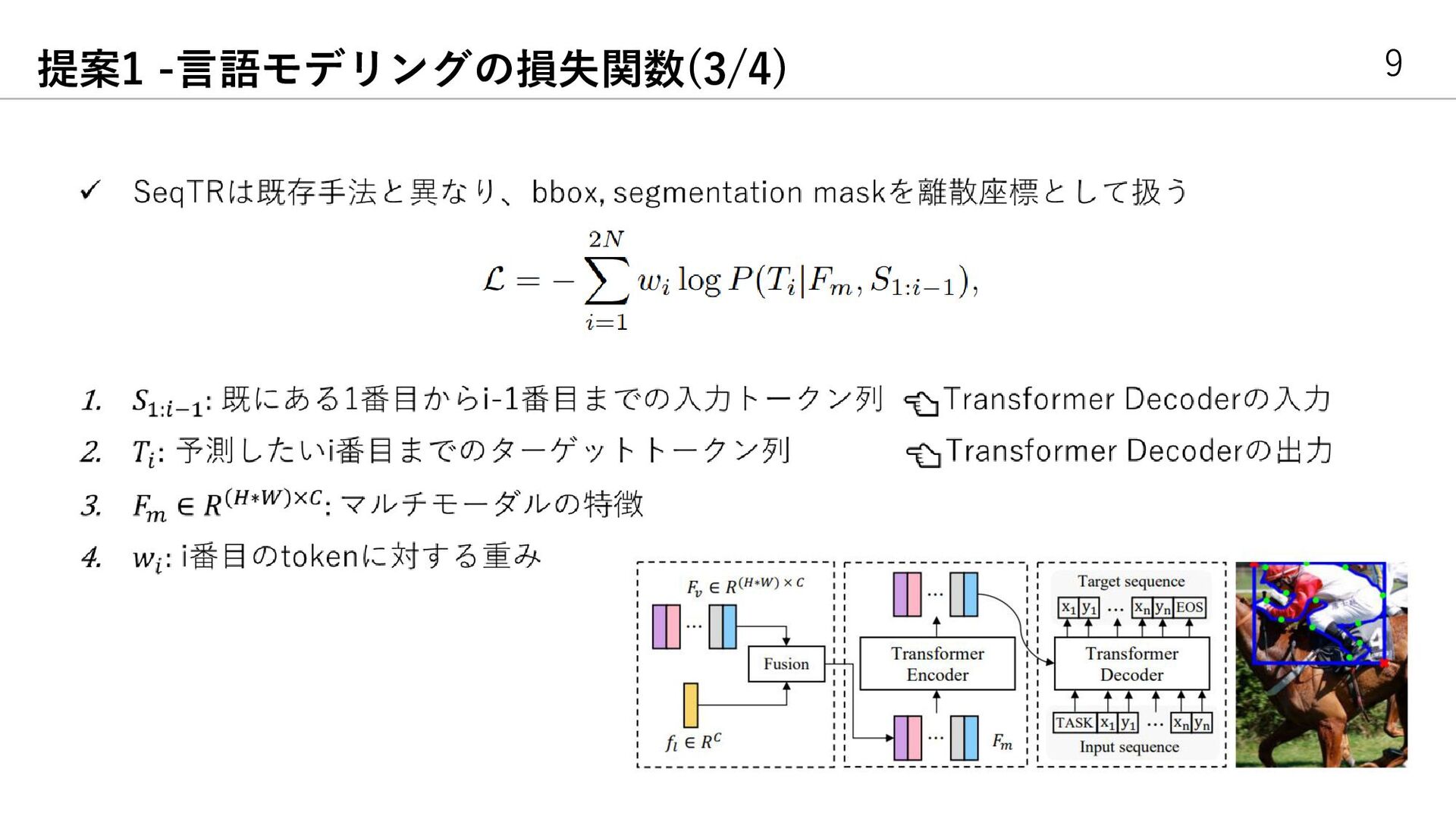{kind=link}
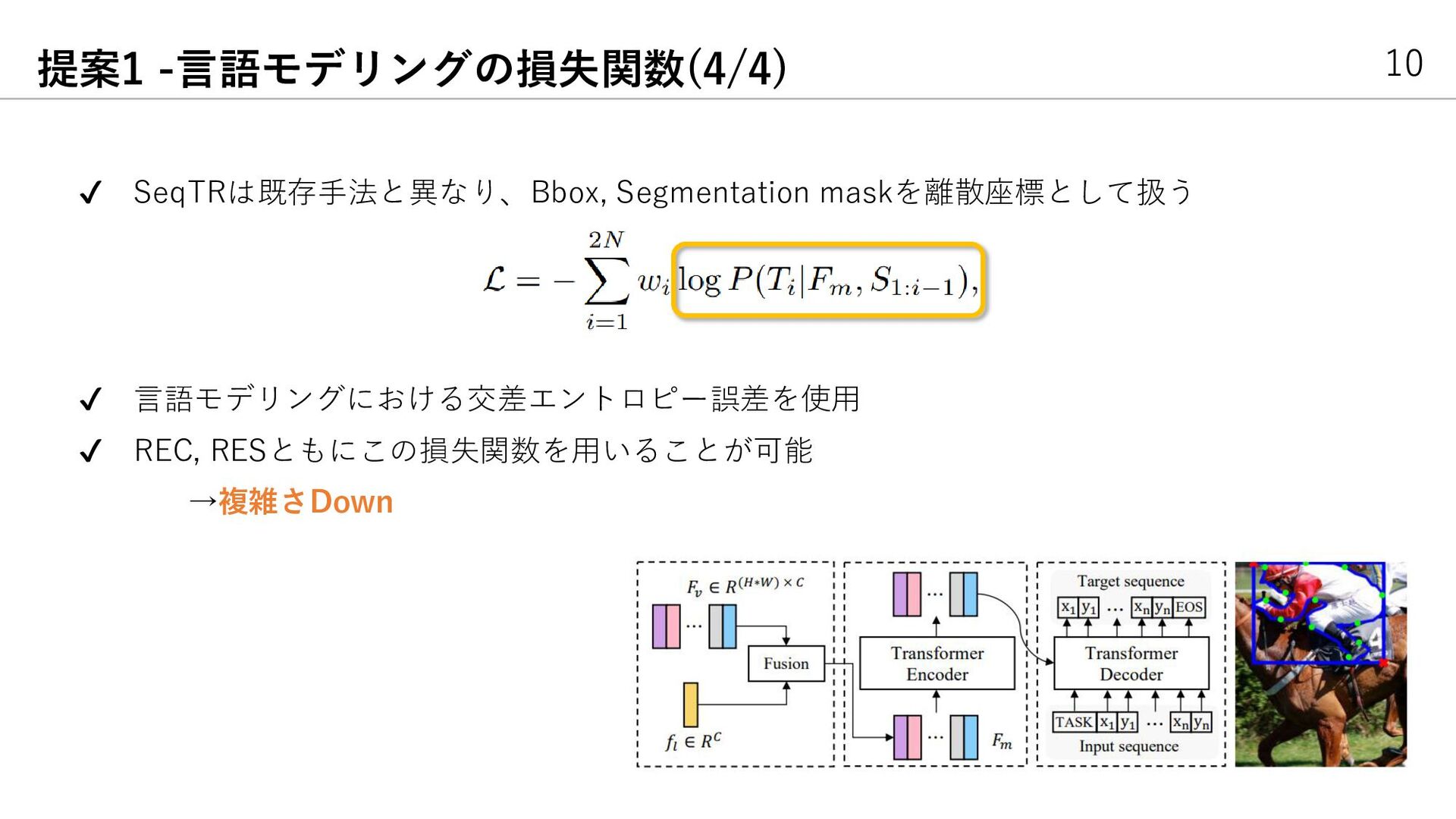{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
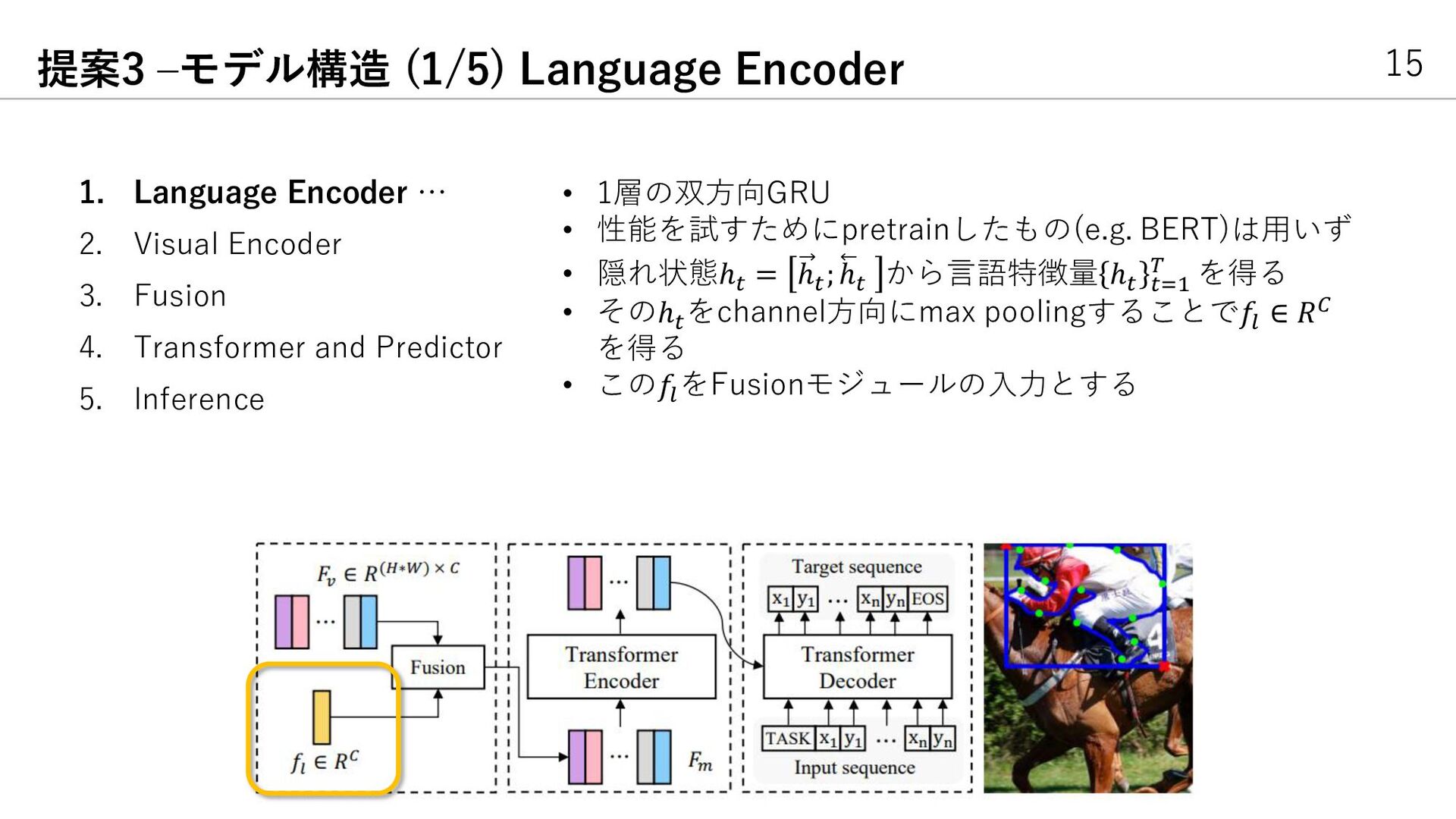{kind=link}
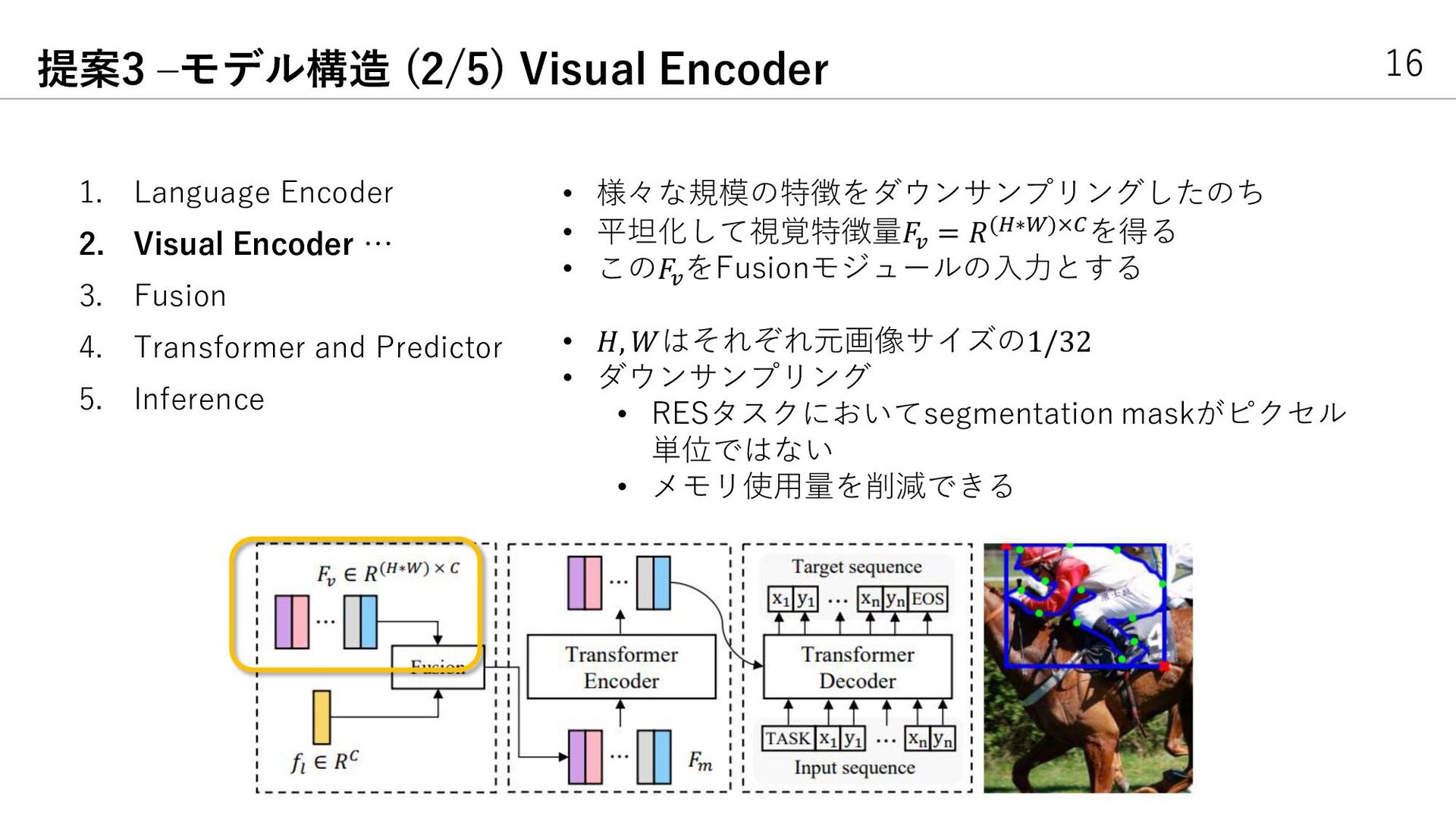{kind=link}
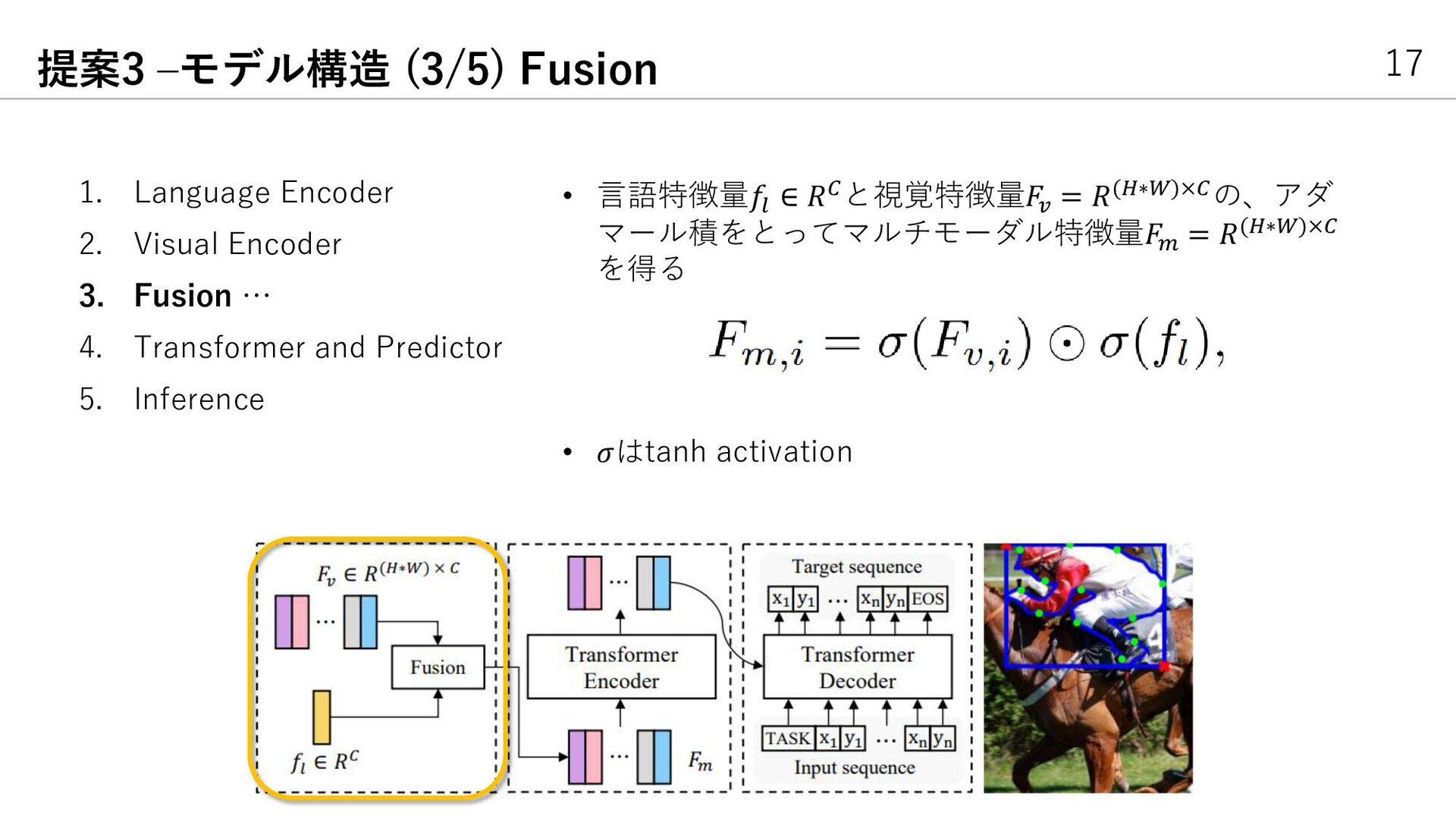{kind=link}
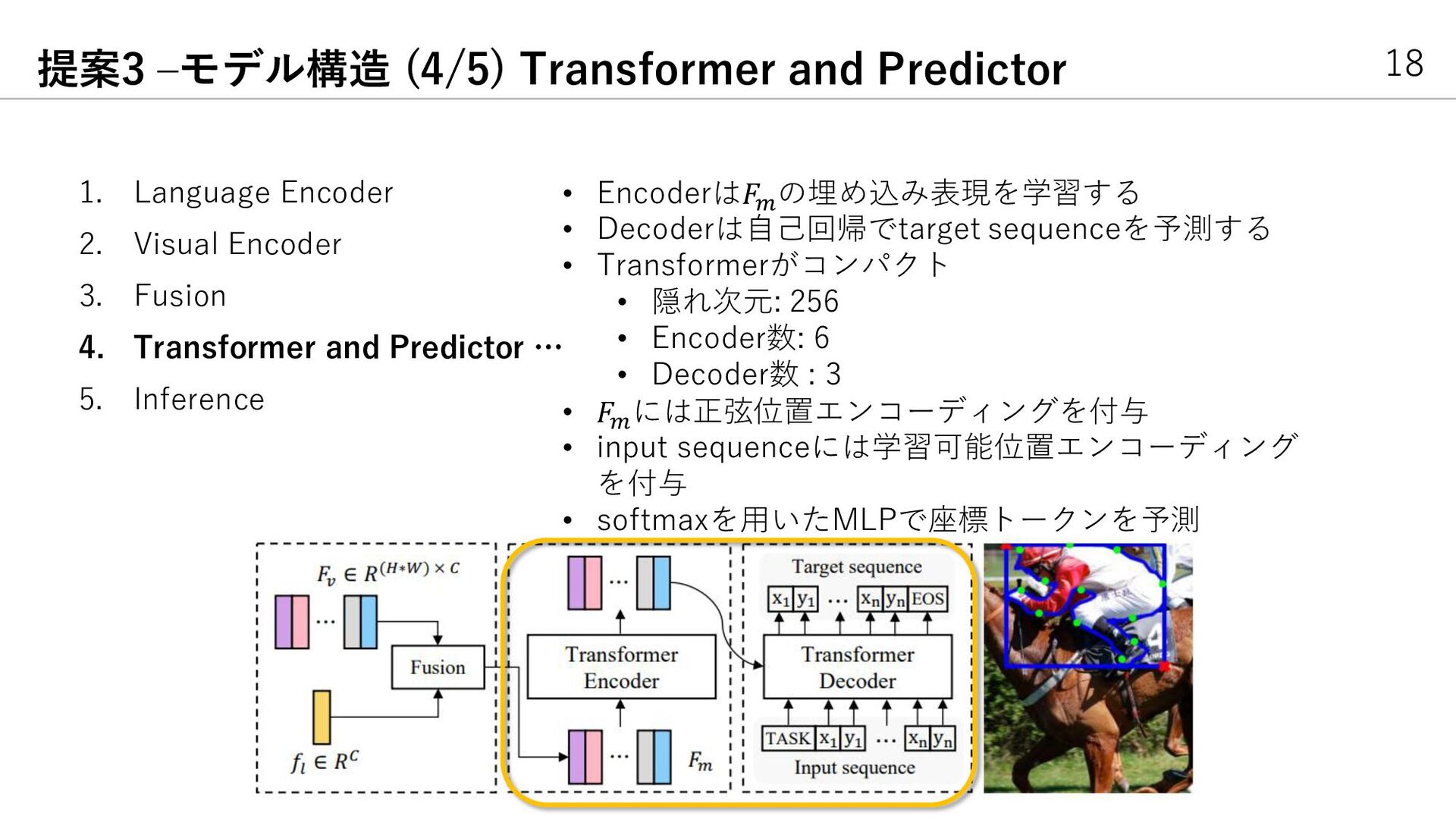{kind=link}
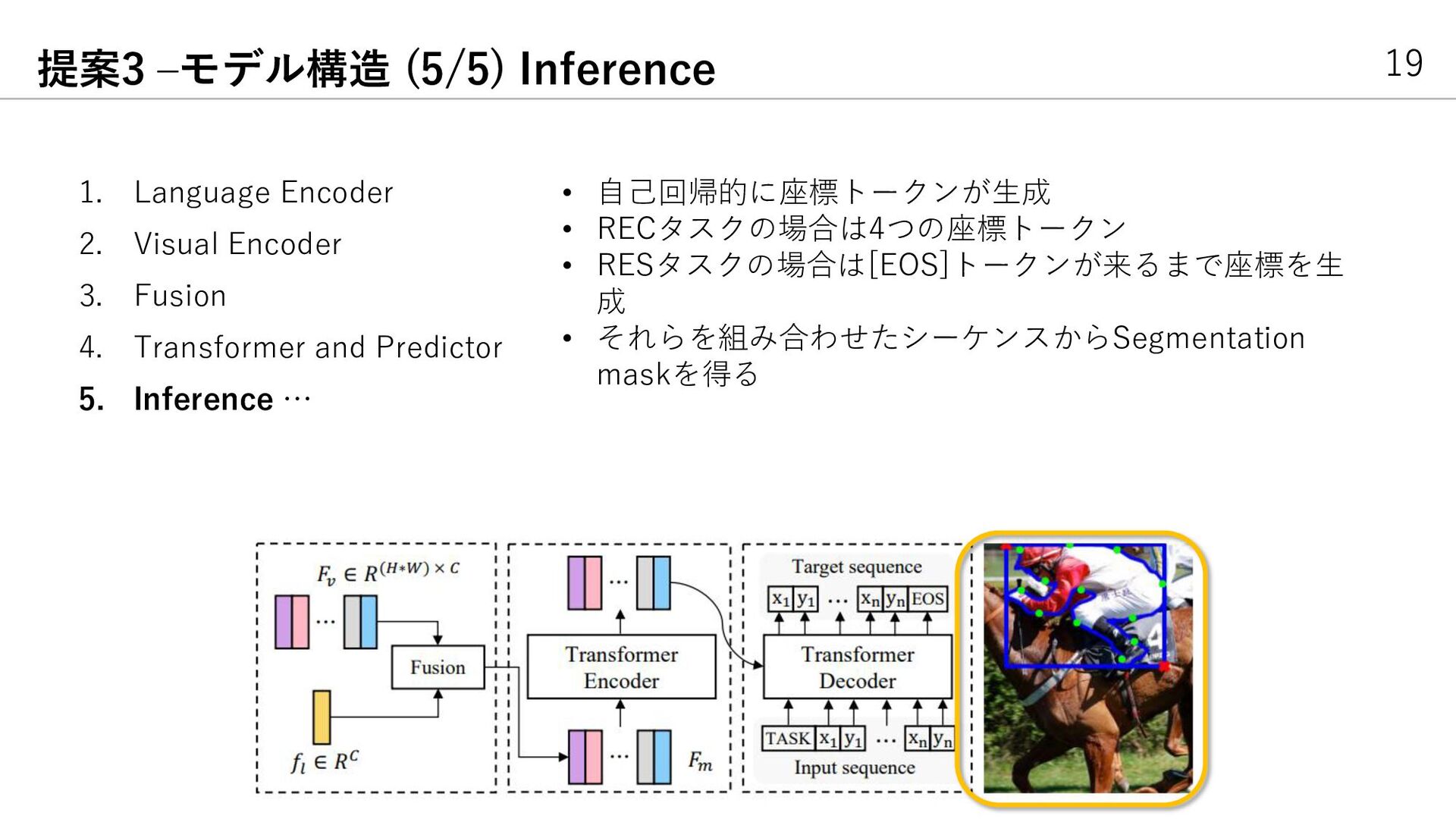{kind=link}
![20 実験設定 評価指標 ✔ REC(参照表現理解)タスク: [email protected] ✔ RES(参照表現セグメンテーション)タスク: mIoU データセット](https://files.speakerdeck.com/presentations/8c7a2a16723e496cbddc5c20ea6d5325/slide_19.jpg){kind=link}
![21 定量的結果 – 参照表現理解(REC)でSOTA達成 ✔ 評価指標:[email protected] 予測Bboxと正解BboxのIoUが0.5以上のとき予測が正しいとみなす ✔ SeqTR†はVisual Encoderを3つのデータセットのval/test画像を含めてpretrainしたもの](https://files.speakerdeck.com/presentations/8c7a2a16723e496cbddc5c20ea6d5325/slide_20.jpg){kind=link}
![22 定量的結果 – 参照表現セグメンテーション(RES)でSOTA達成 ✔ 評価指標:mIoU ✔ SOTAであるVLT[Ding+, ICCV21]を超えた ✔](https://files.speakerdeck.com/presentations/8c7a2a16723e496cbddc5c20ea6d5325/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
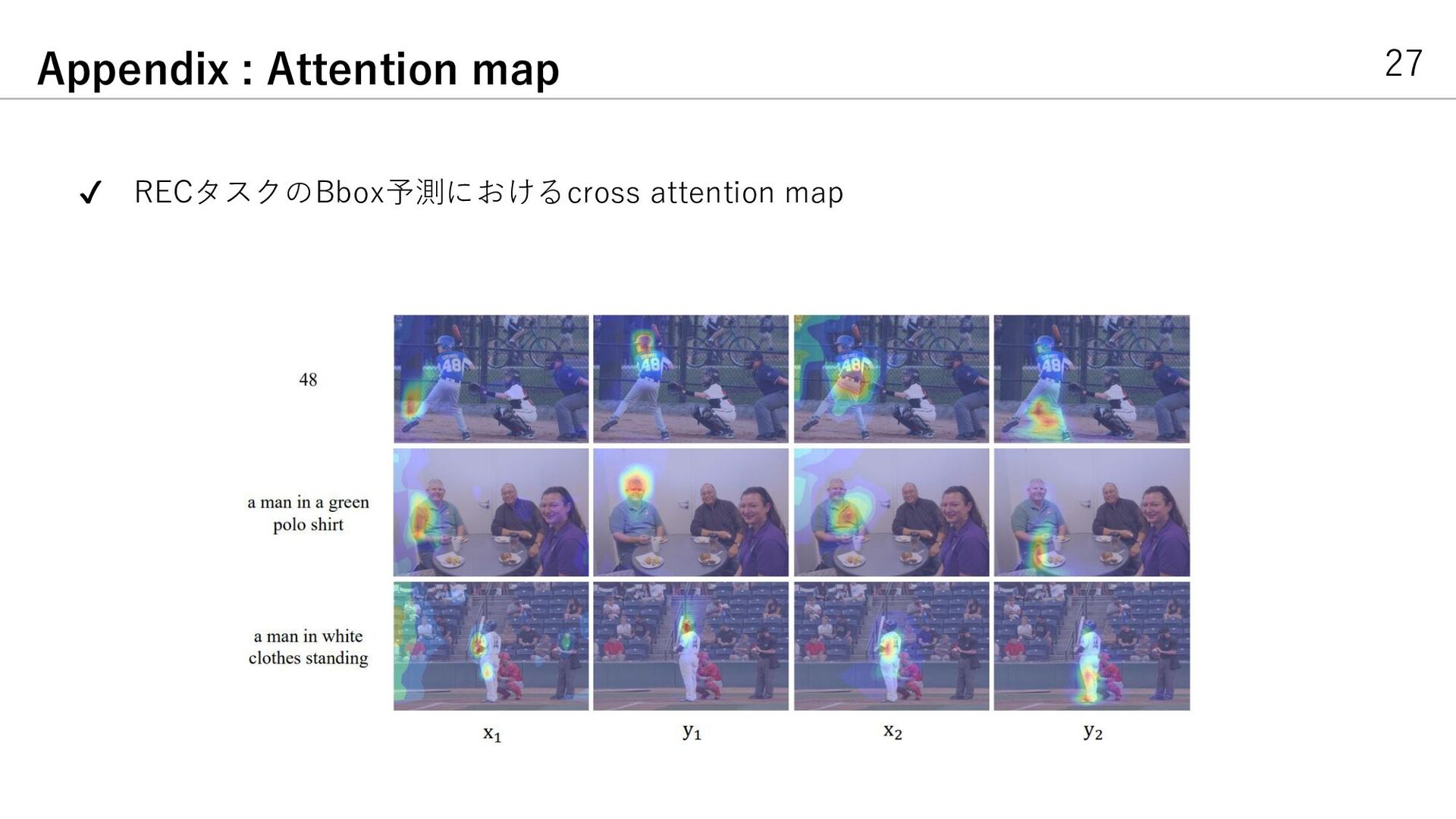{kind=link}
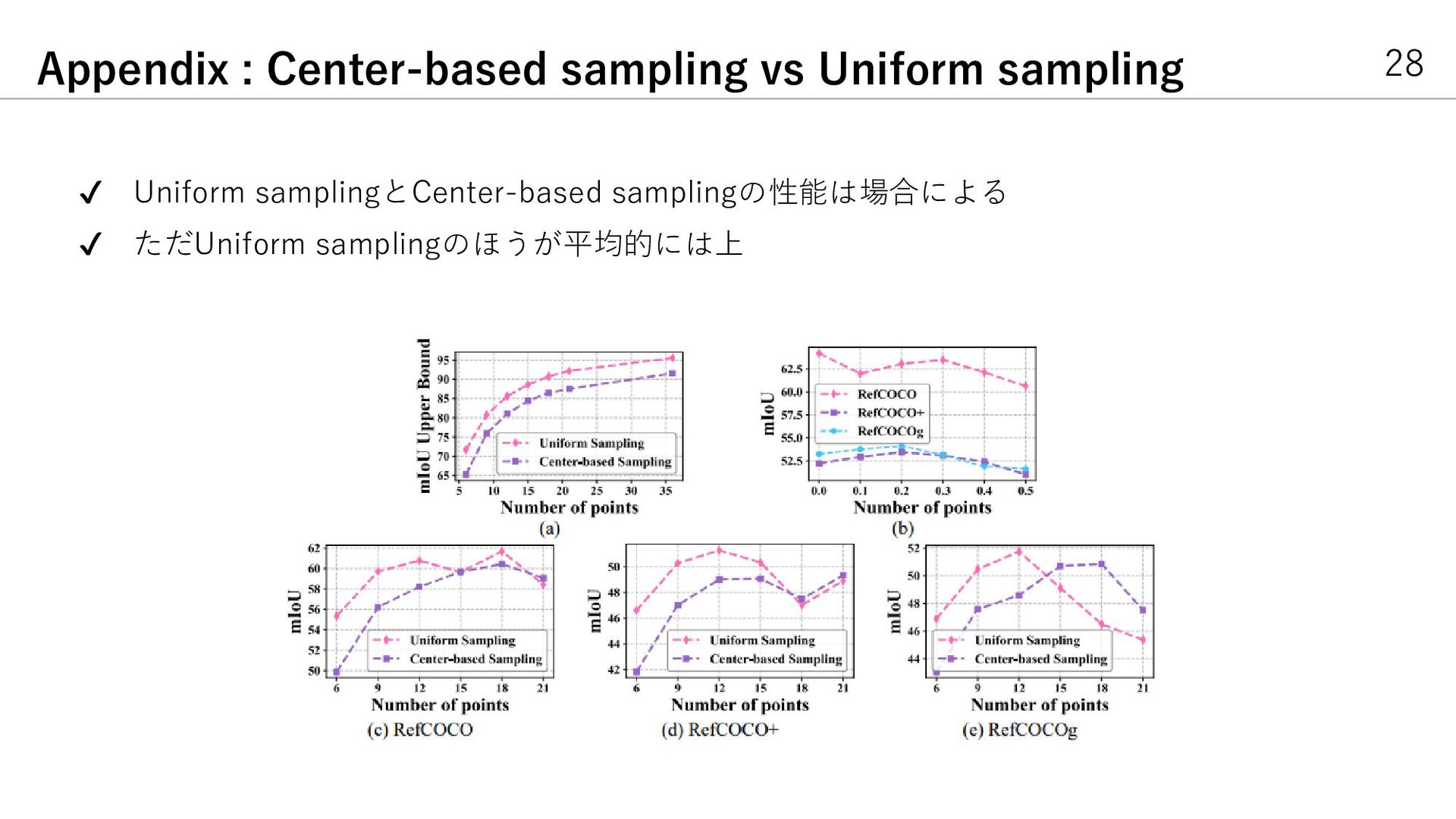{kind=link}
![29 Appendix : Token weight ✔ 最初のtoken weightを少し上げると精度が向上した →1st tokenは[TASK]トークン](https://files.speakerdeck.com/presentations/8c7a2a16723e496cbddc5c20ea6d5325/slide_28.jpg){kind=link}
{kind=link}