Zhang1,2, Fangyun Wei2, Han Hu2, Xiang Bai1 1Huazhong University of Science and Technology, 2Microsoft Research Asia, CVPR, 2023 慶應義塾大学 飯岡雄偉 Xu Mengde, Zheng Zhang, Fangyun Wei, Han Hu, Xiang Bai. “Side Adapter Network for Open-Vocabulary Semantic Segmentation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
{kind=link}
{kind=link}
{kind=link}
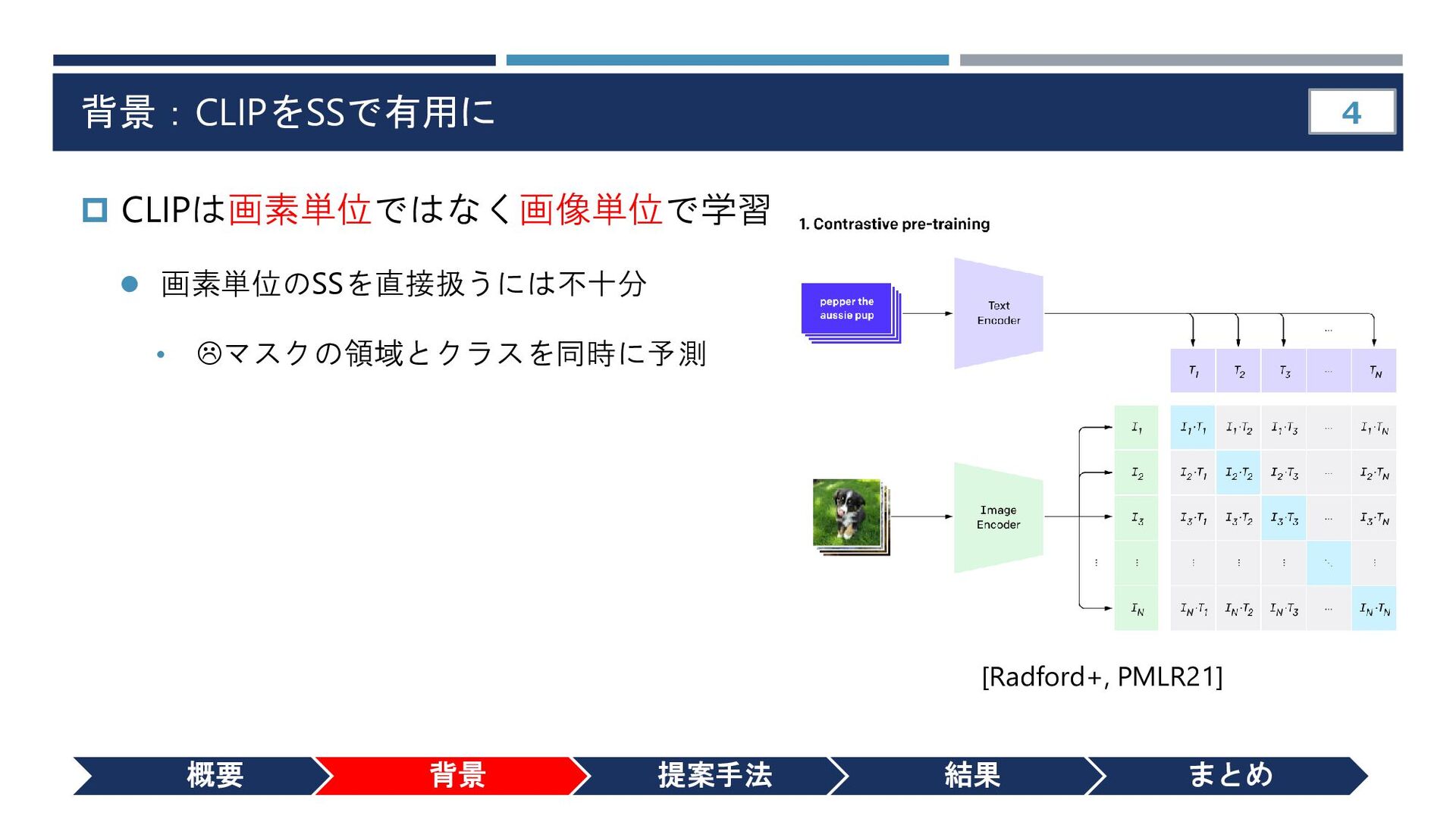{kind=link}
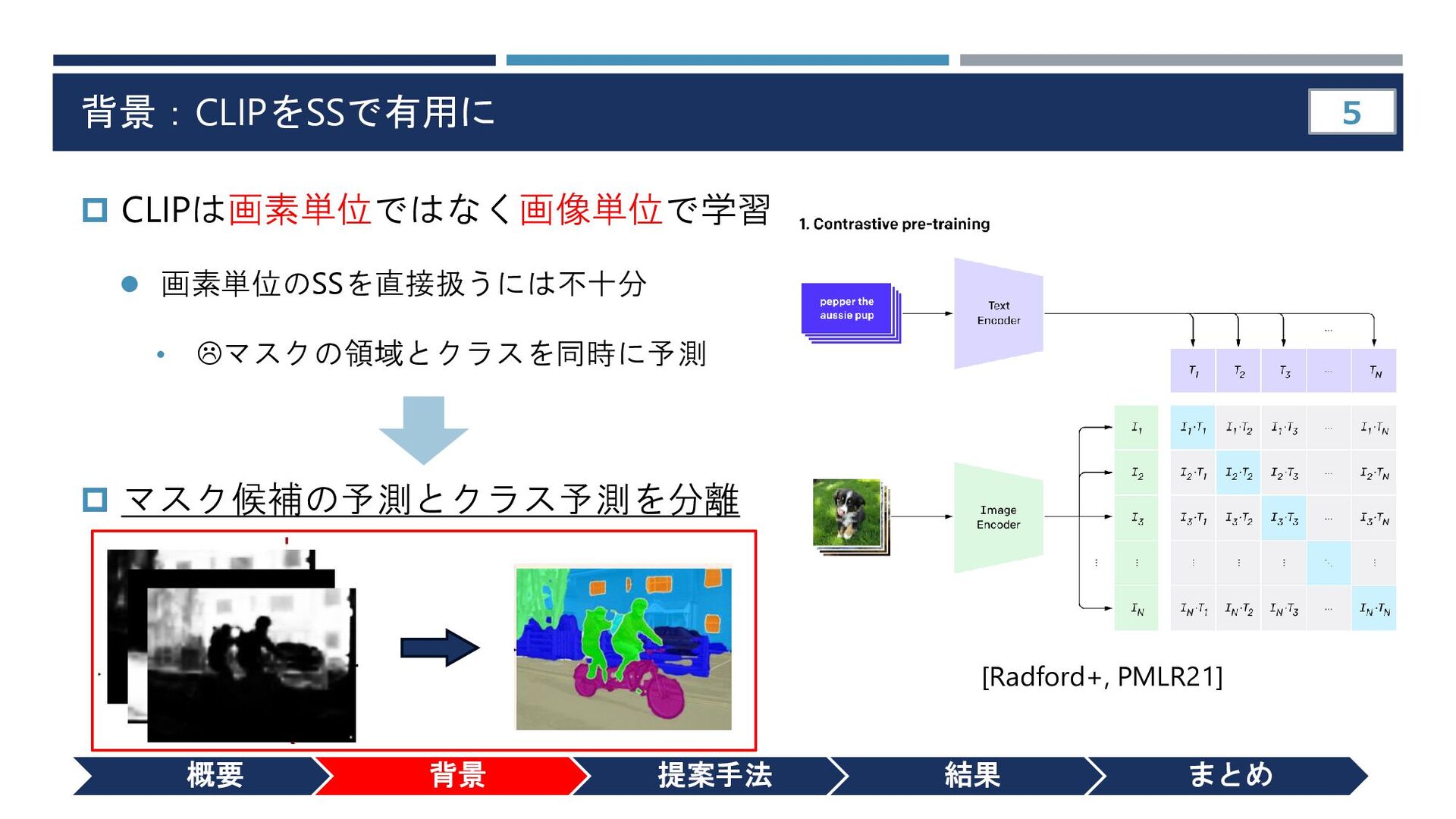{kind=link}
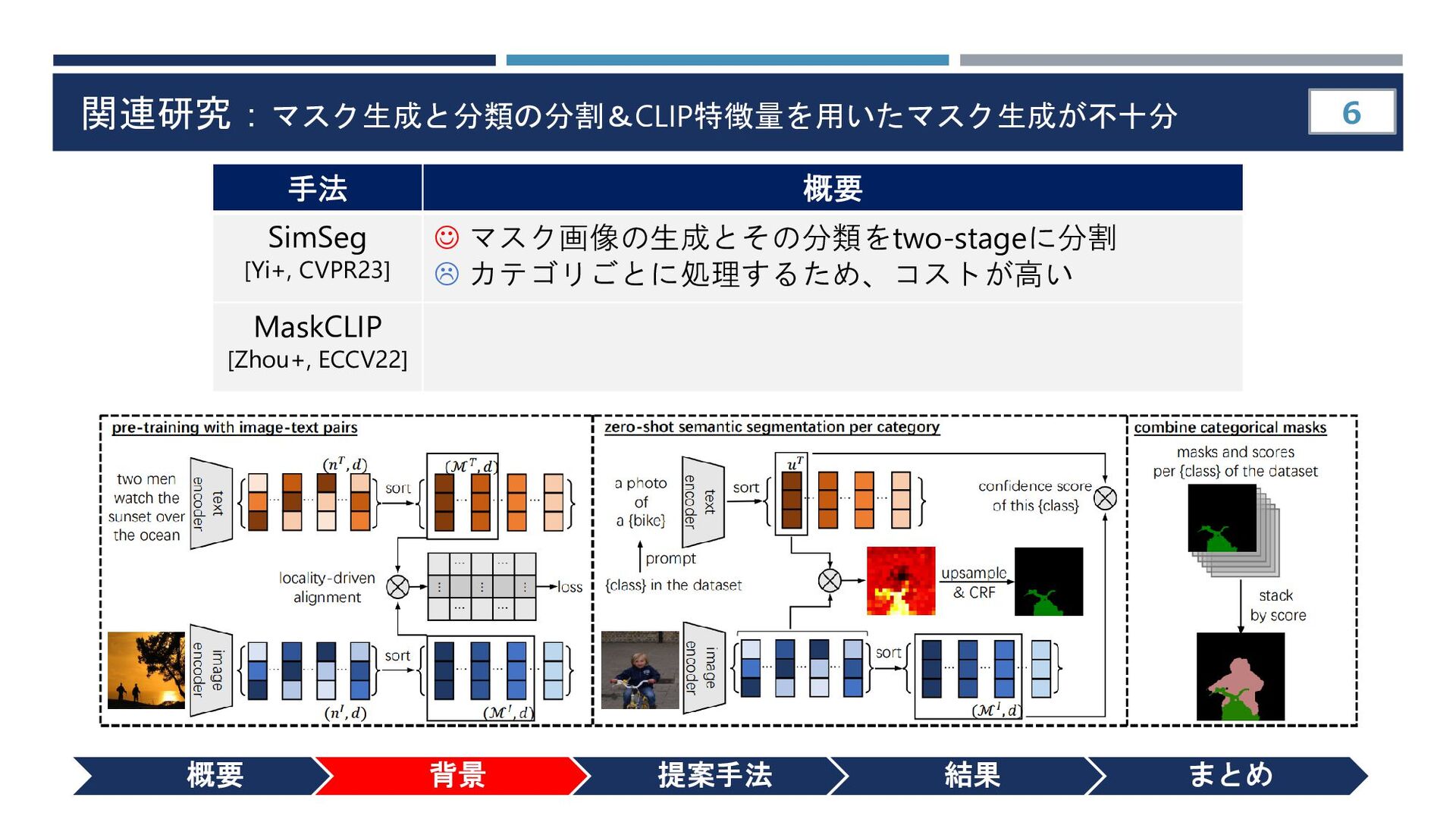{kind=link}
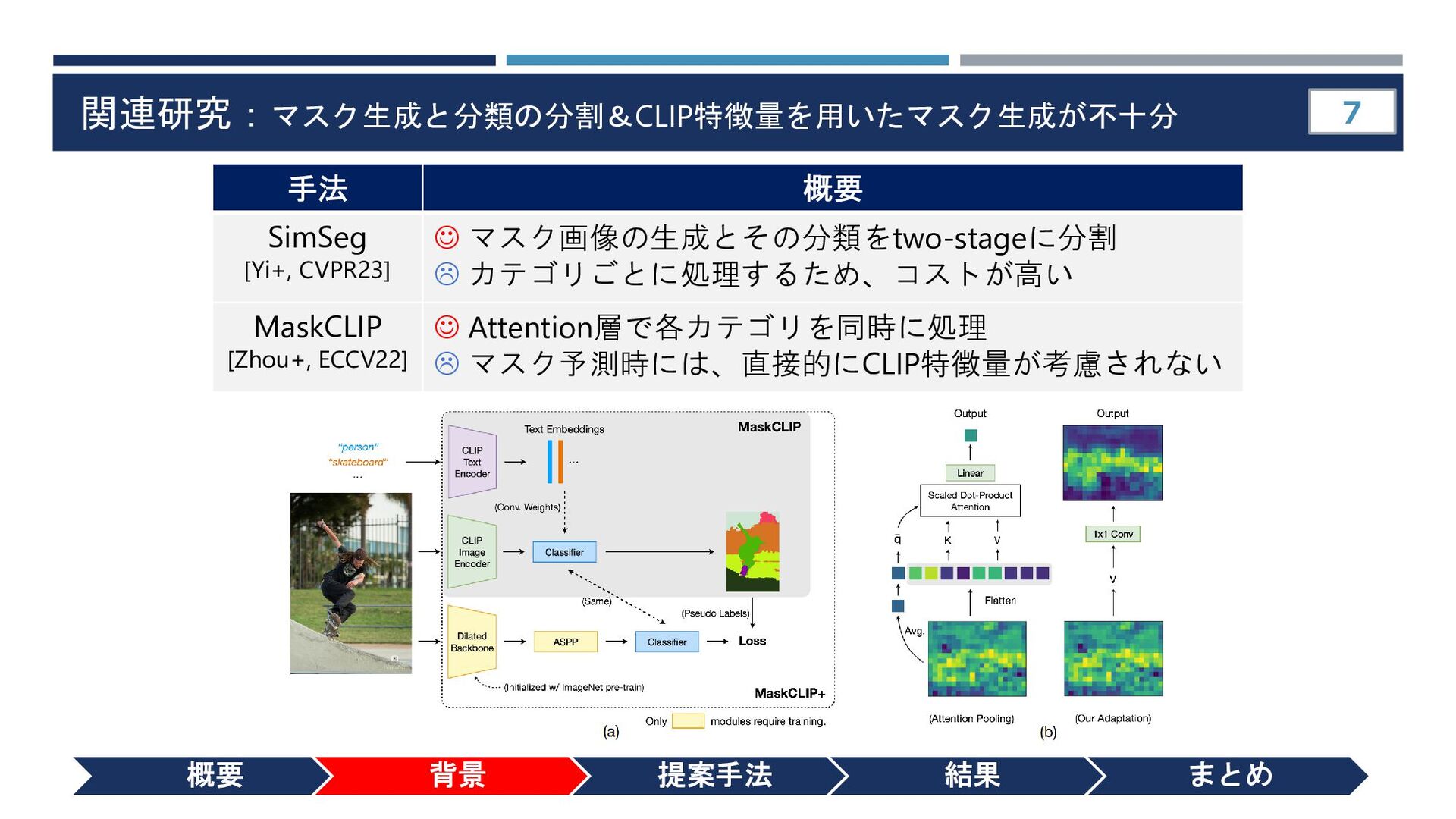{kind=link}
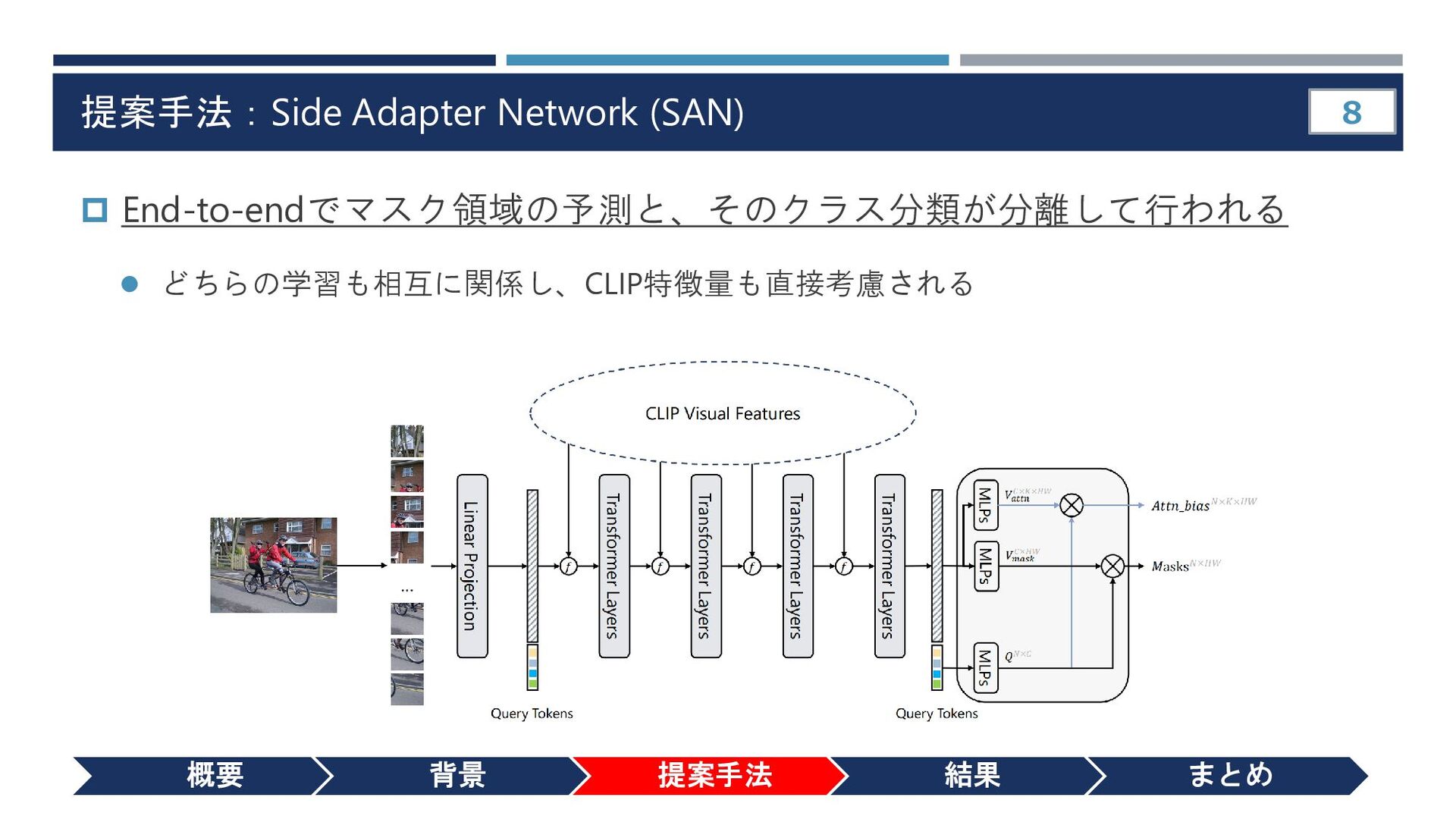{kind=link}
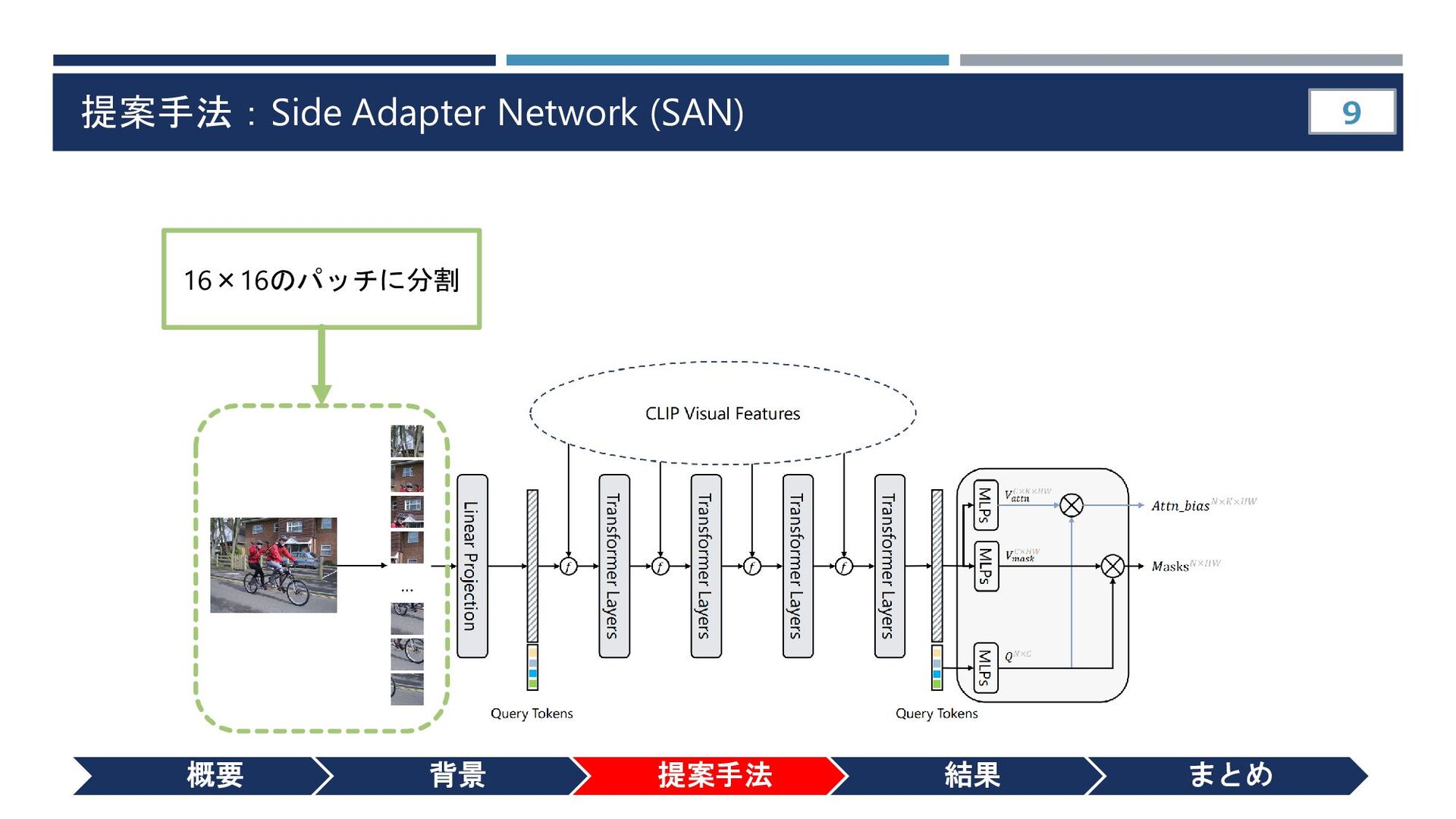{kind=link}
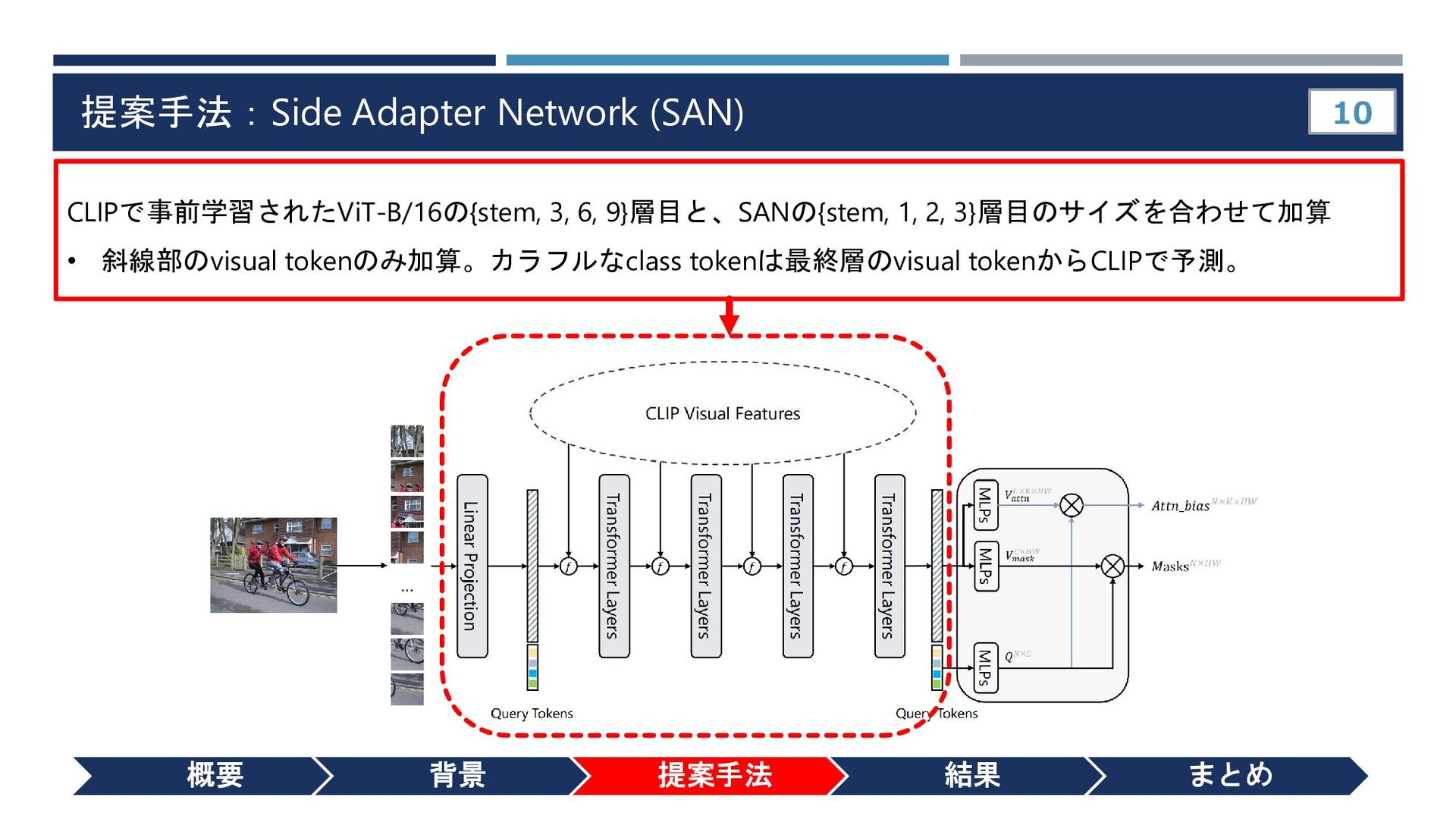{kind=link}
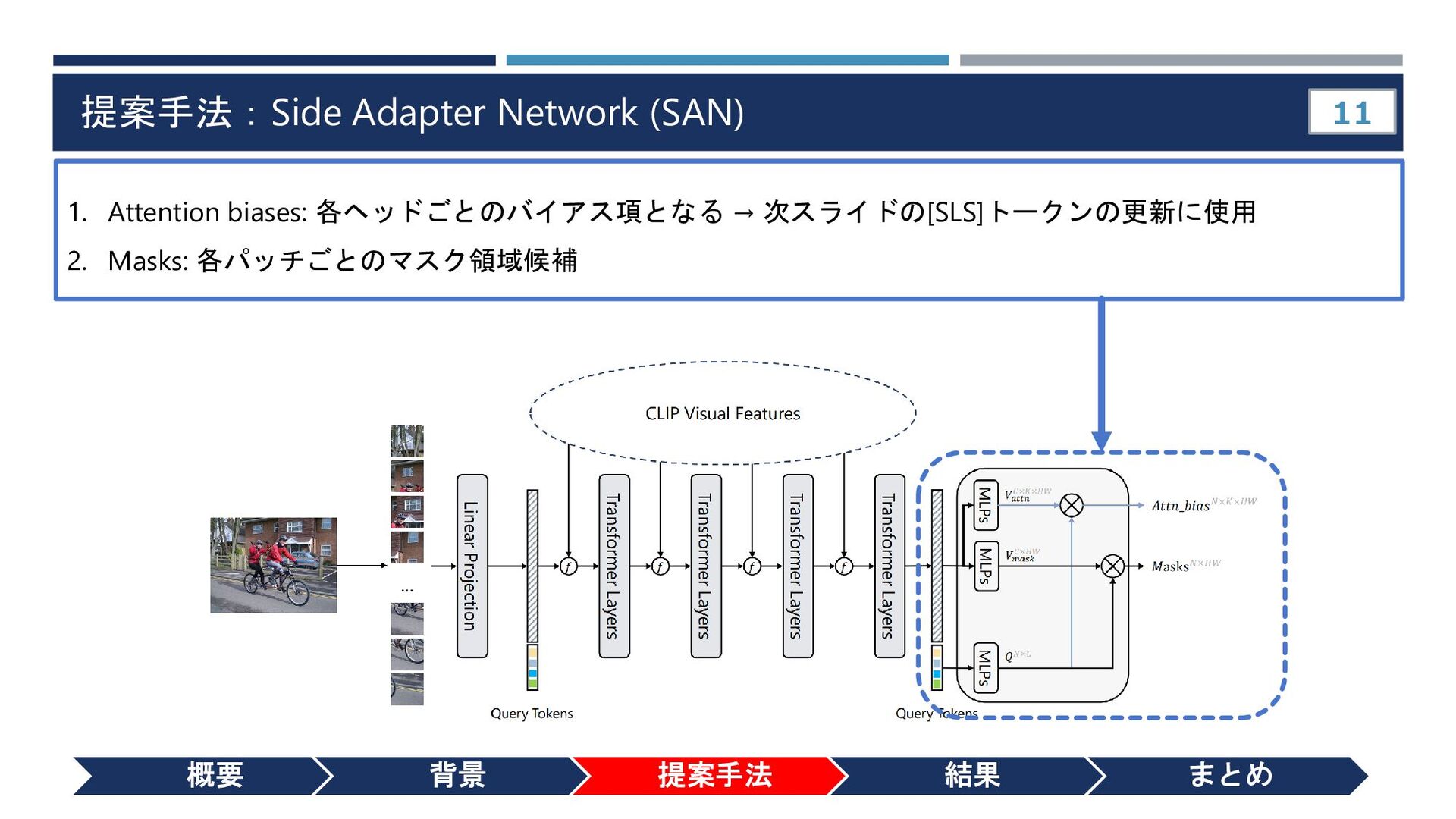{kind=link}
![概要 背景 提案手法 結果 まとめ 提案手法:Self-attention時にAttention biasを用いてSLSを更新 12 [SLS]](https://files.speakerdeck.com/presentations/71b0b41493ae4eafb9fa0fbc6acb75d2/slide_11.jpg){kind=link}
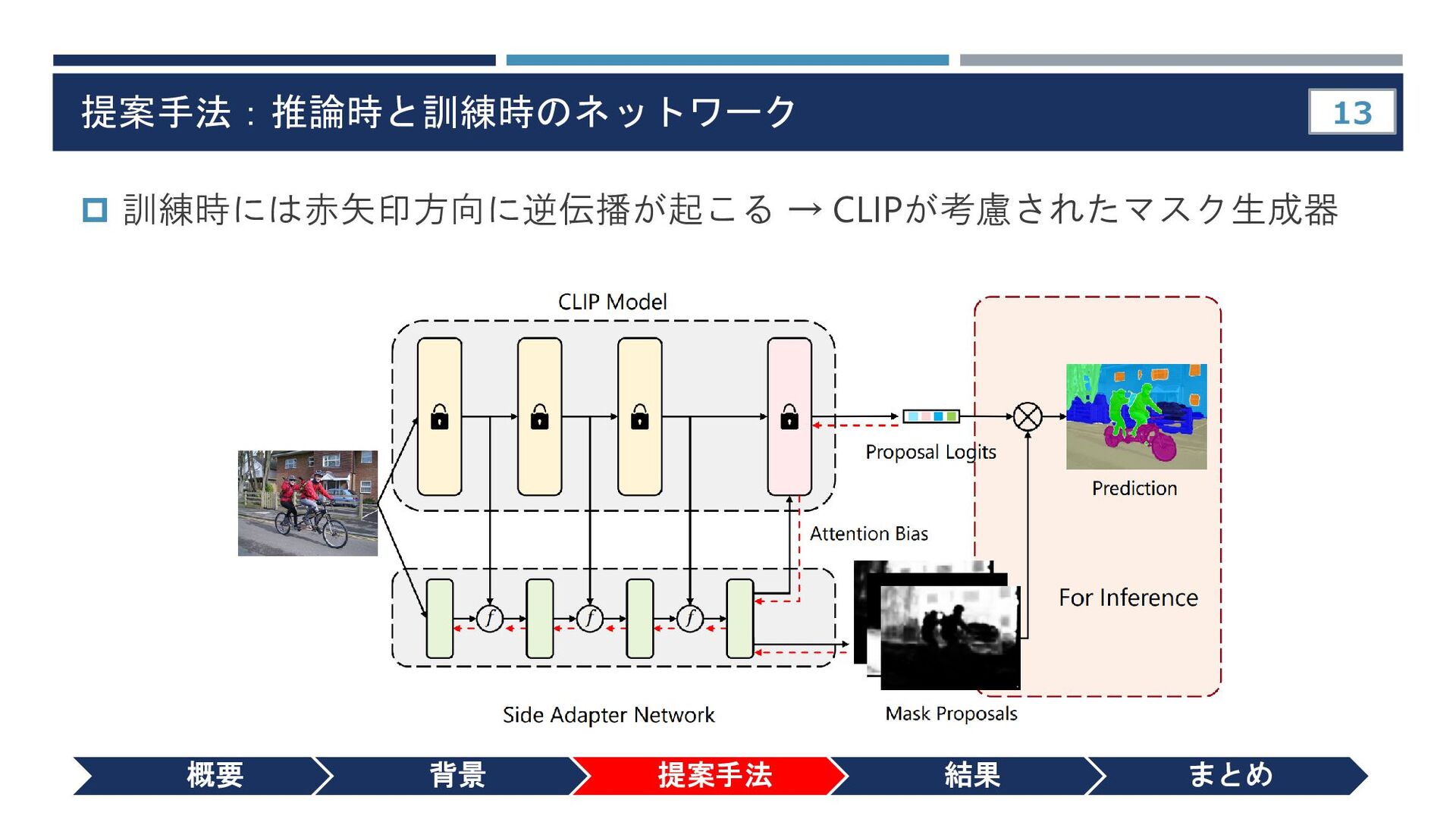{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}