危険性の説明文 L 説明文生成時には,ユーザに判断を仰ぐ 時間的余裕が残っていない 5 ・・・ 入力 t-k t RFCM The robot hits the plastid bottle because the robot tried to put a red bottle on it. 出力 説明文生成時は 衝突の直前
(Obama was senator for, lllinois) (Barack is married to, Michelle) (Obama was born in, Hawaii) … (Obama is a native of, Hawaii) 推論時 (Obama’s birthplace is, ??) 利用して出力をrescore
{kind=link}
{kind=link}
{kind=link}
![関連研究 : タスク実行前に衝突を予測し説明することは困難 4 SAM RFCM PonNet[Magassouba+, AR21] Attention Branch](https://files.speakerdeck.com/presentations/00a04b3dc397402a87d44e2d32d2f1ac/slide_3.jpg){kind=link}
![既存手法の問題点 : 衝突直前の画像を用いる • RFCM[kambara+, ICIP21] 入力: 時刻t-kから時刻𝑡の画像 出力: 時刻t+1に発生する](https://files.speakerdeck.com/presentations/00a04b3dc397402a87d44e2d32d2f1ac/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
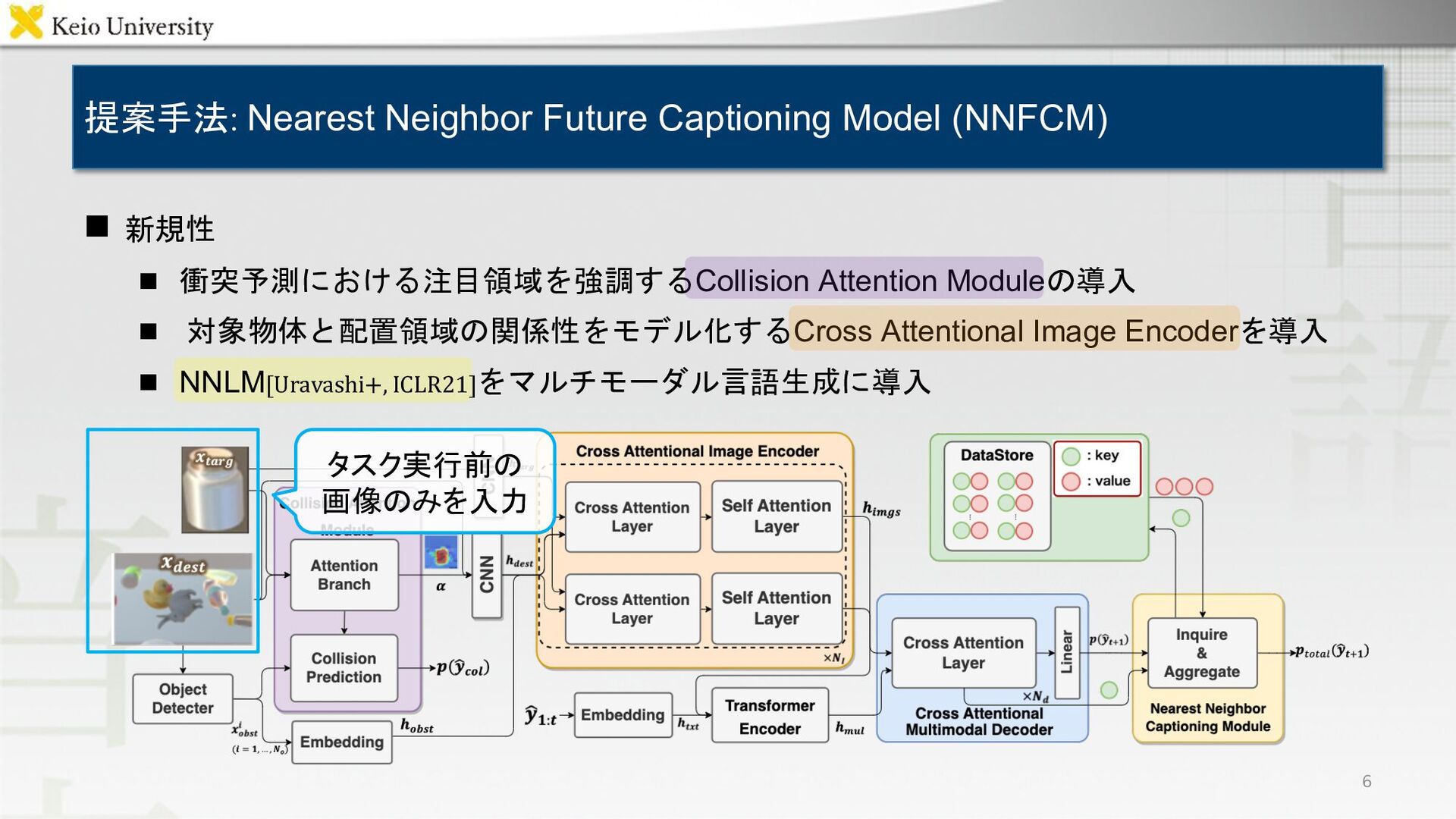
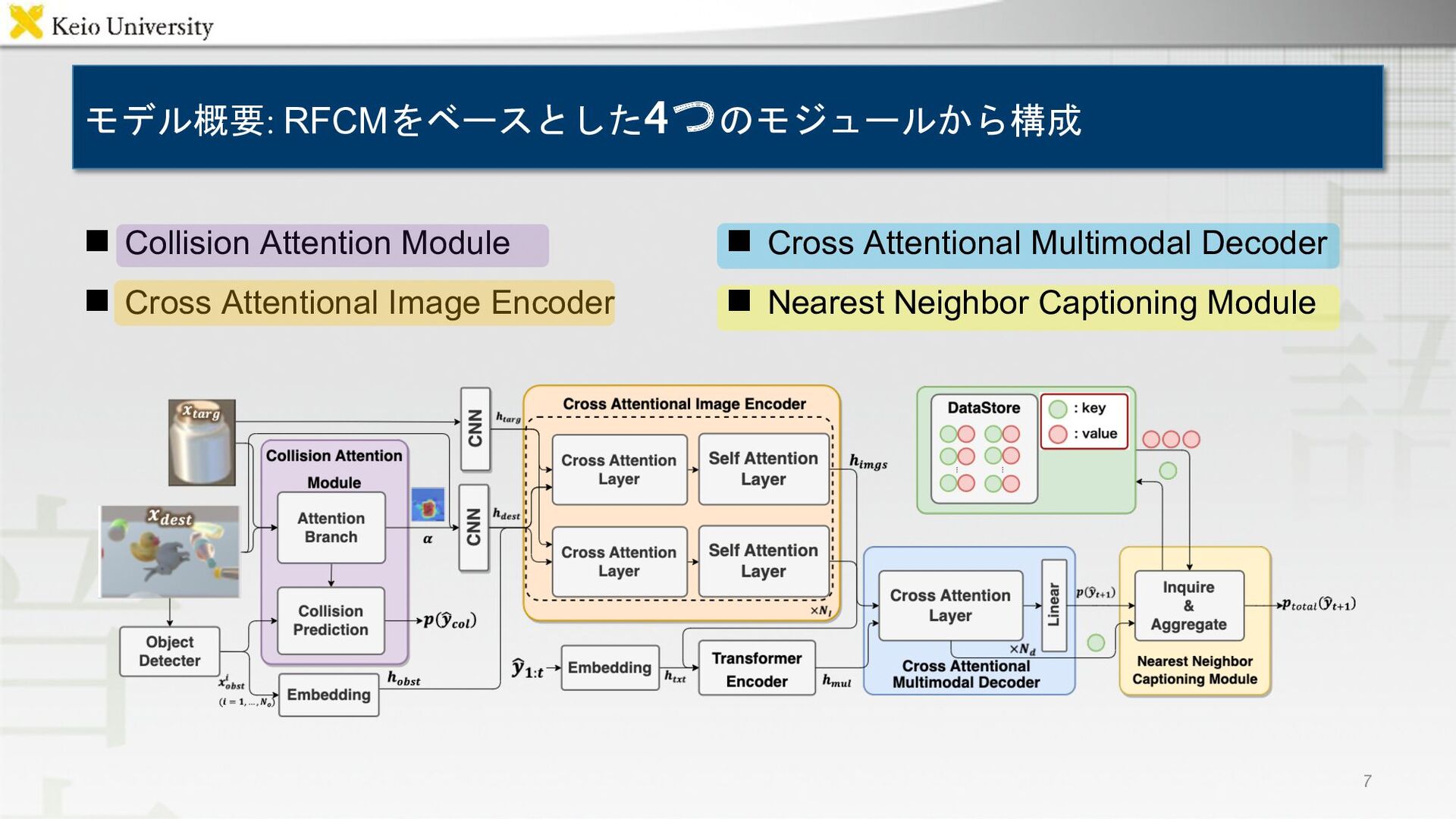
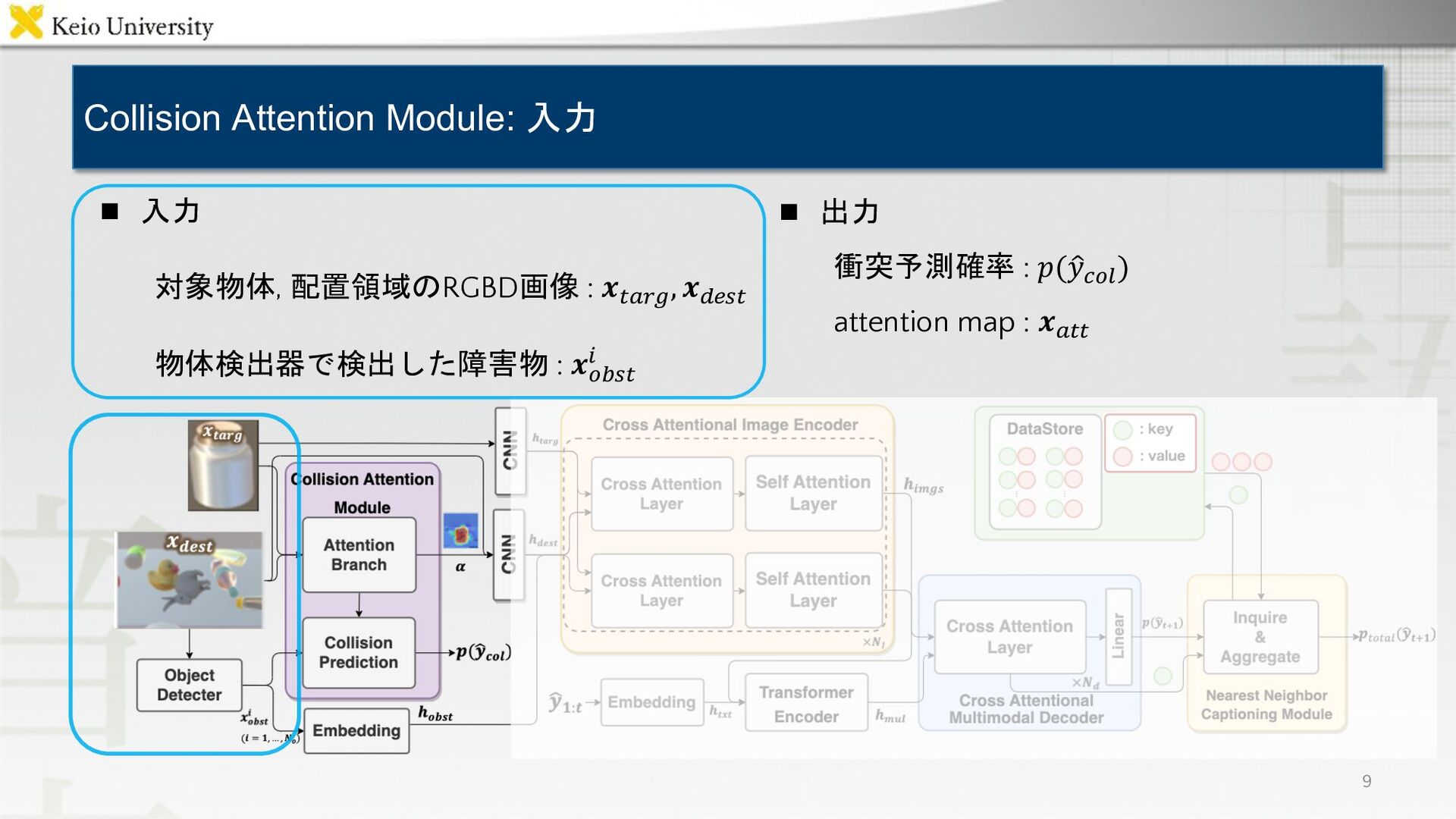
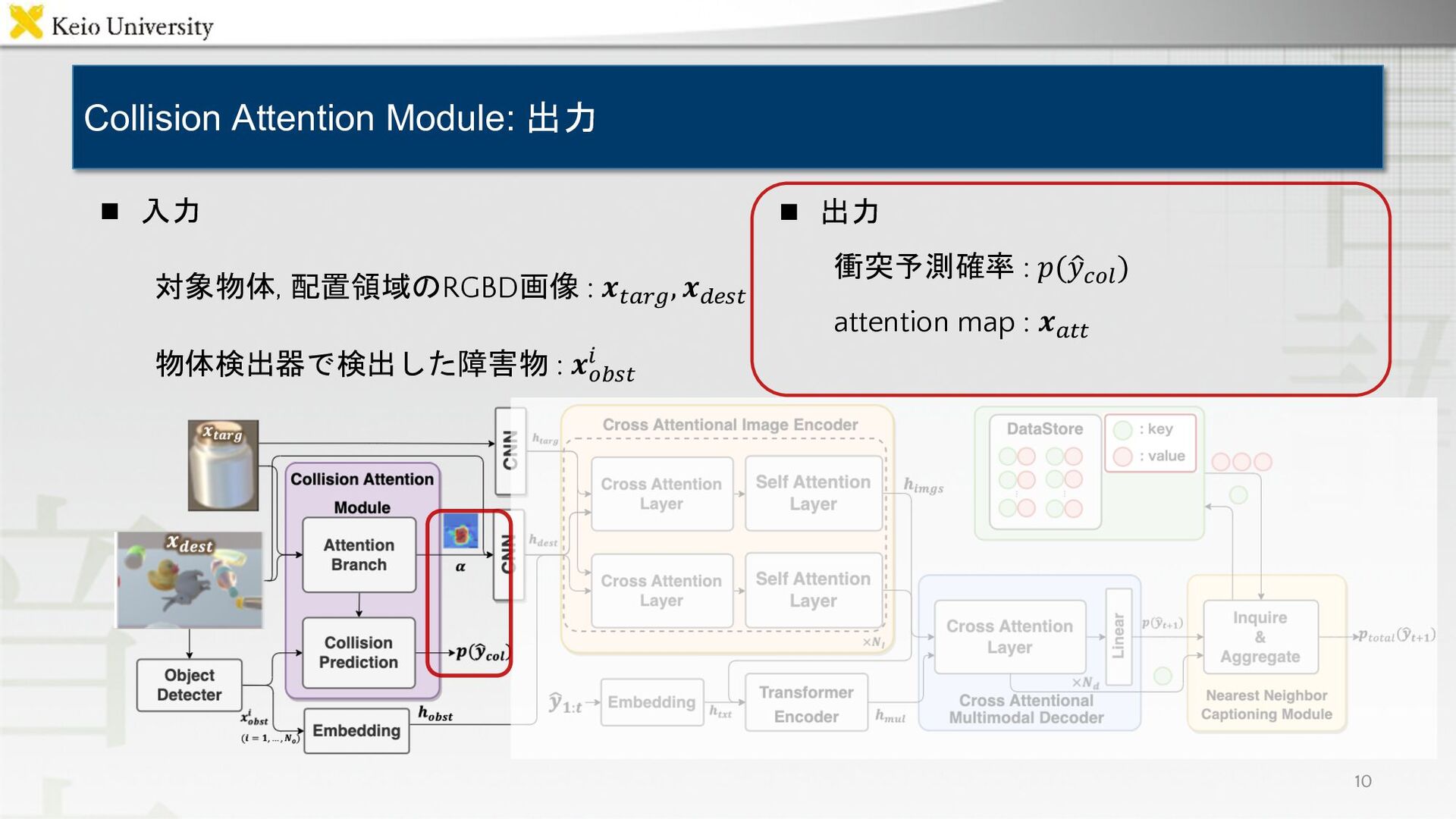
![n PonNet[Magassouba+, AR21]を拡張 n Collision Prediction Branch -- 衝突予想を行う n](https://files.speakerdeck.com/presentations/00a04b3dc397402a87d44e2d32d2f1ac/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
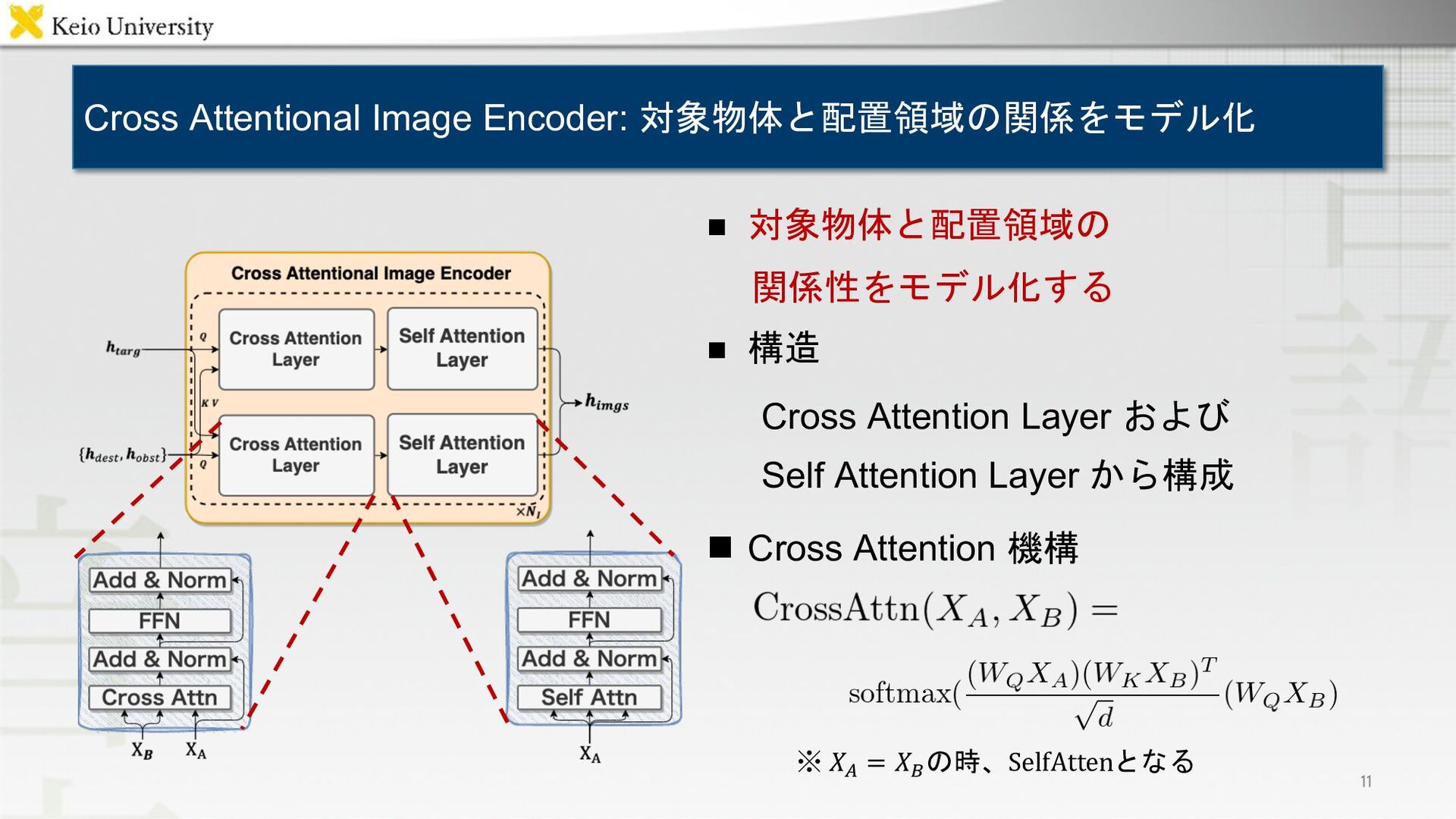{kind=link}
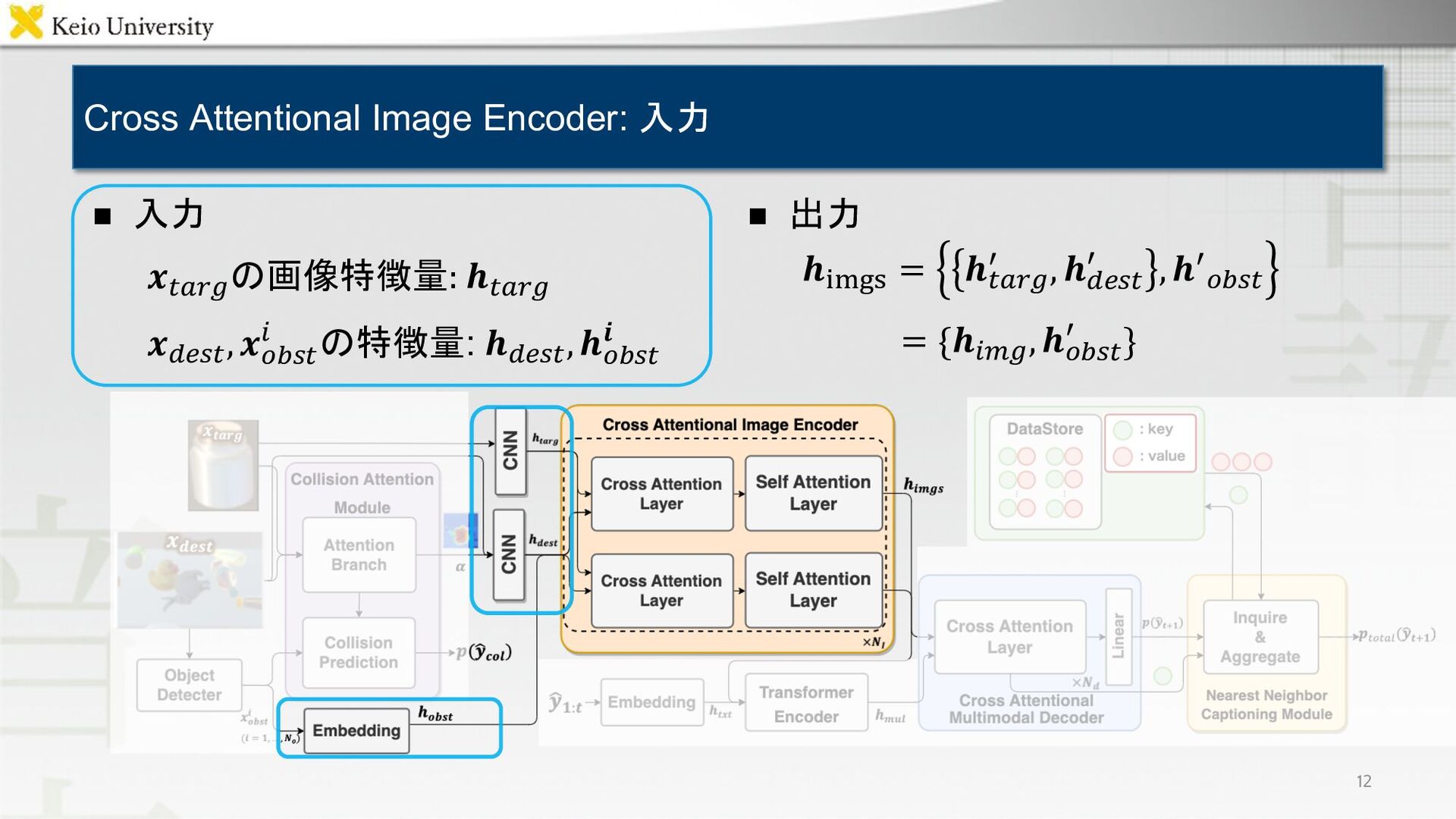{kind=link}
{kind=link}
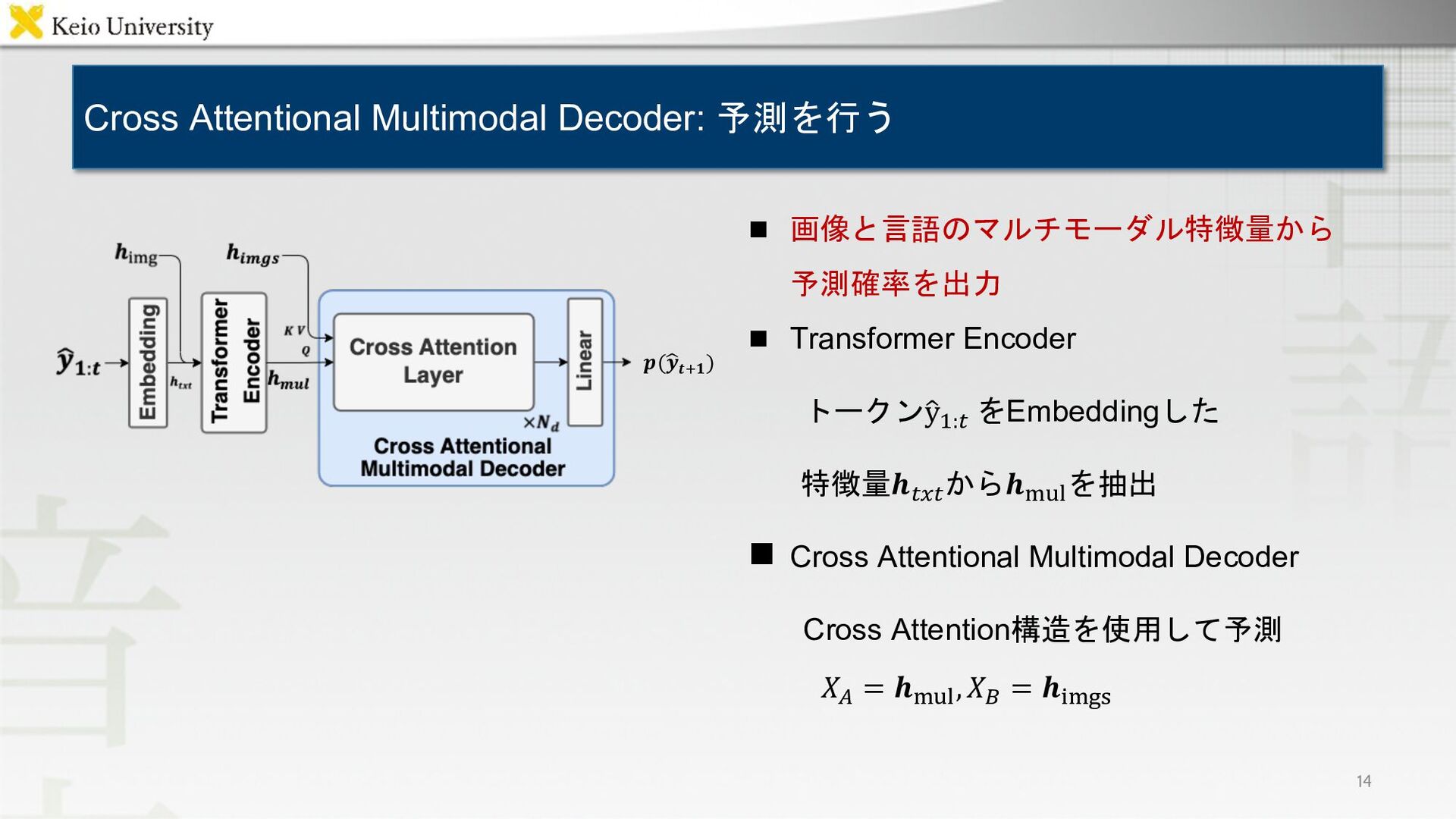{kind=link}
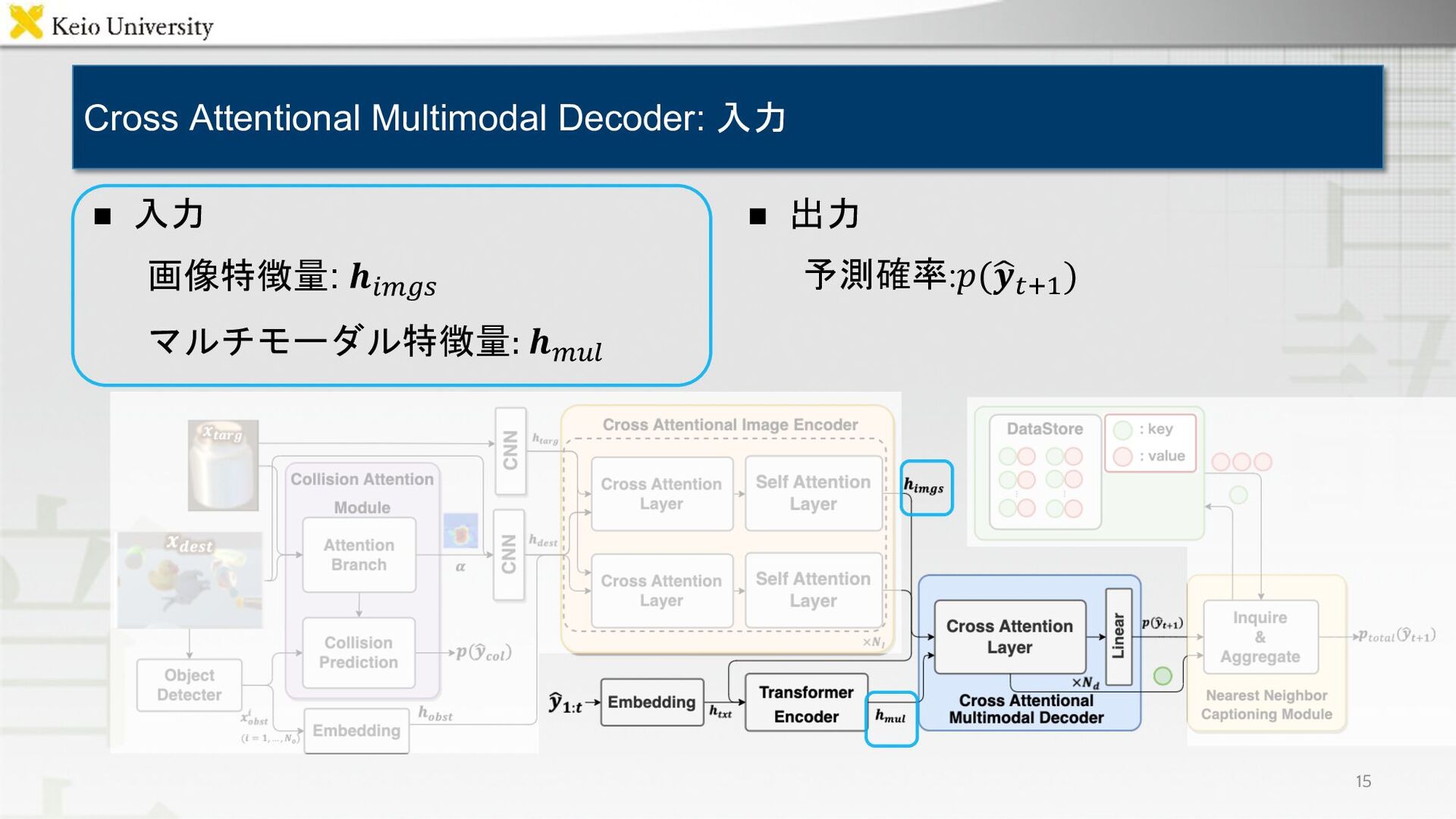{kind=link}
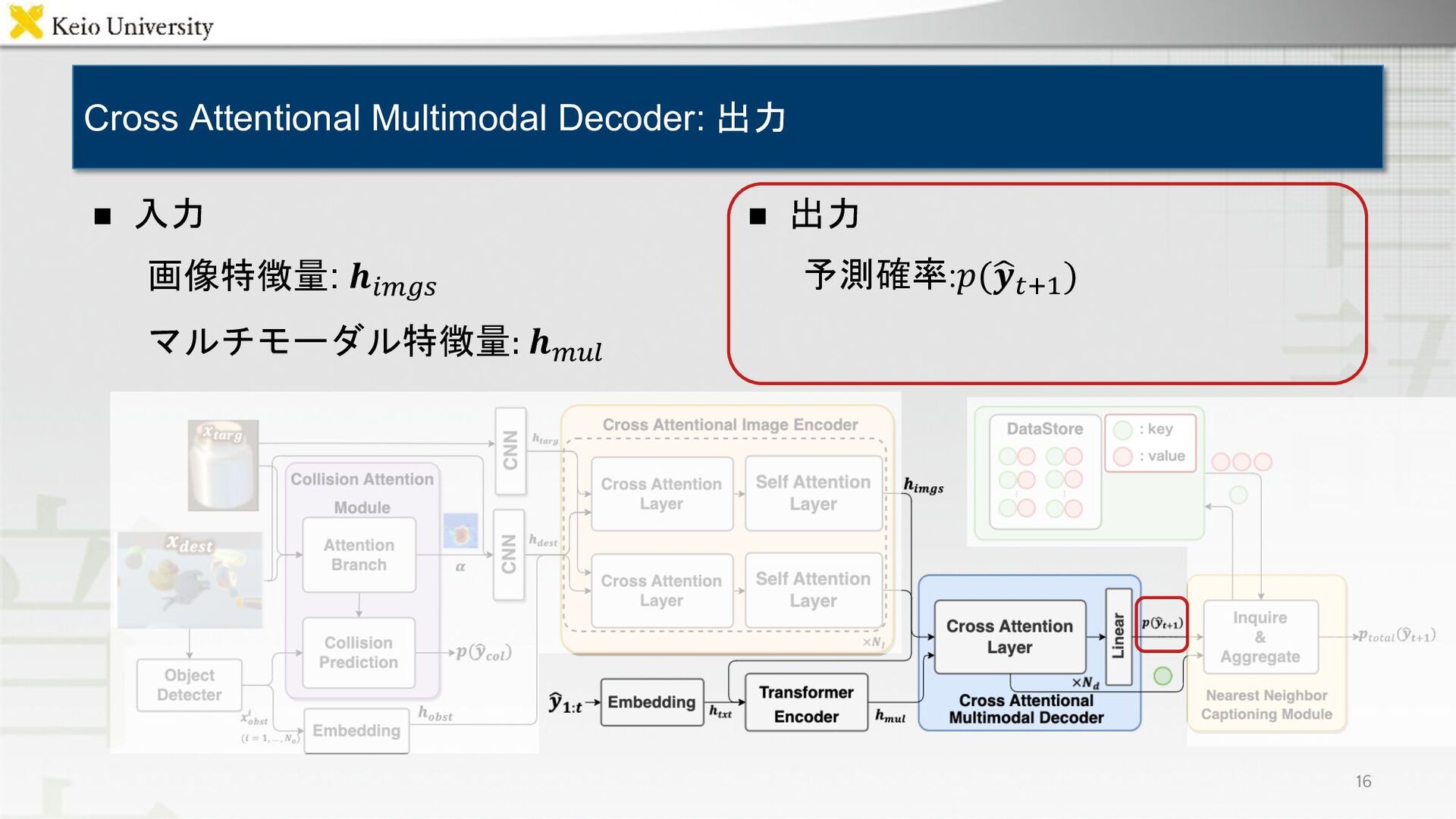{kind=link}
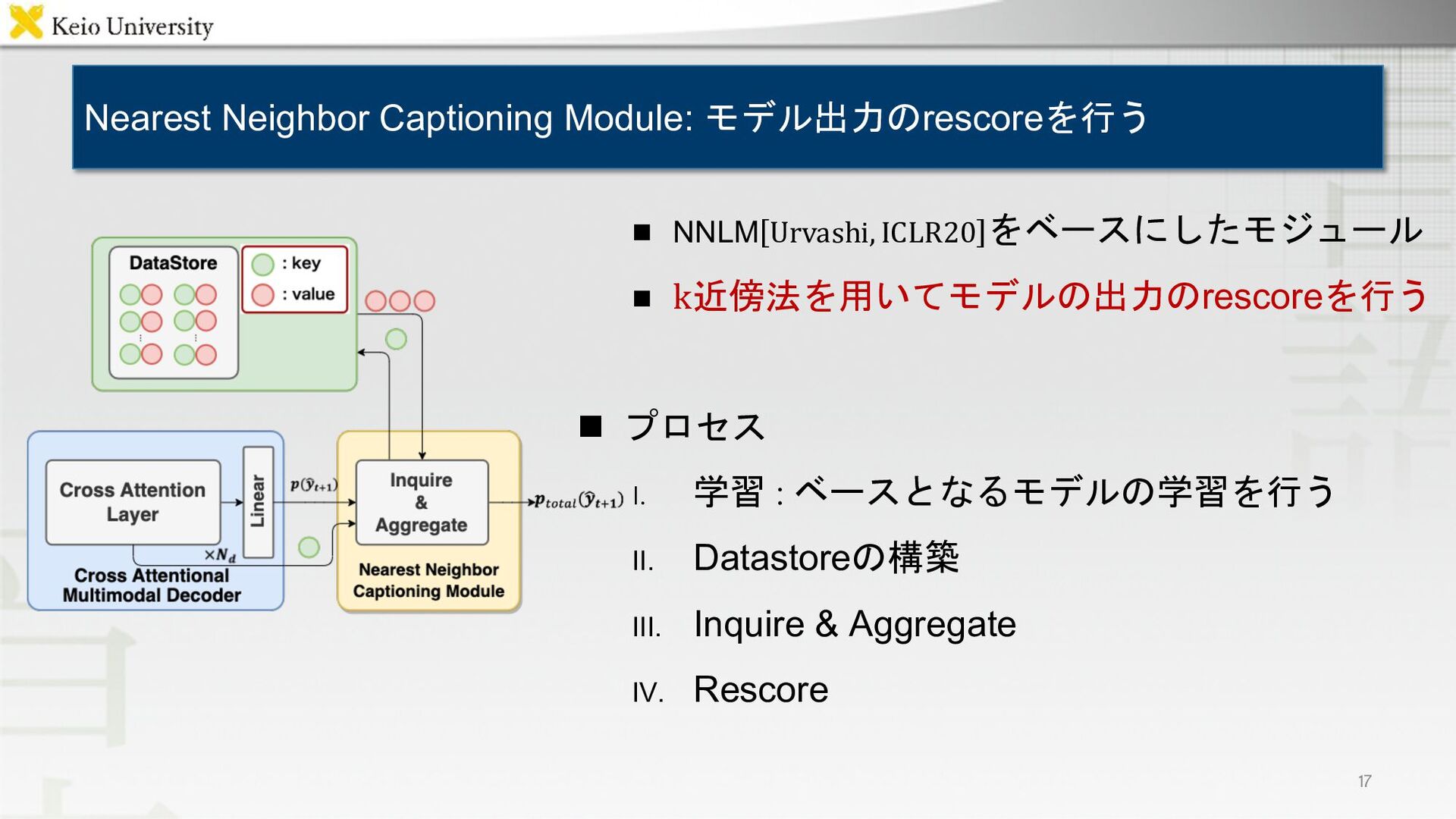{kind=link}
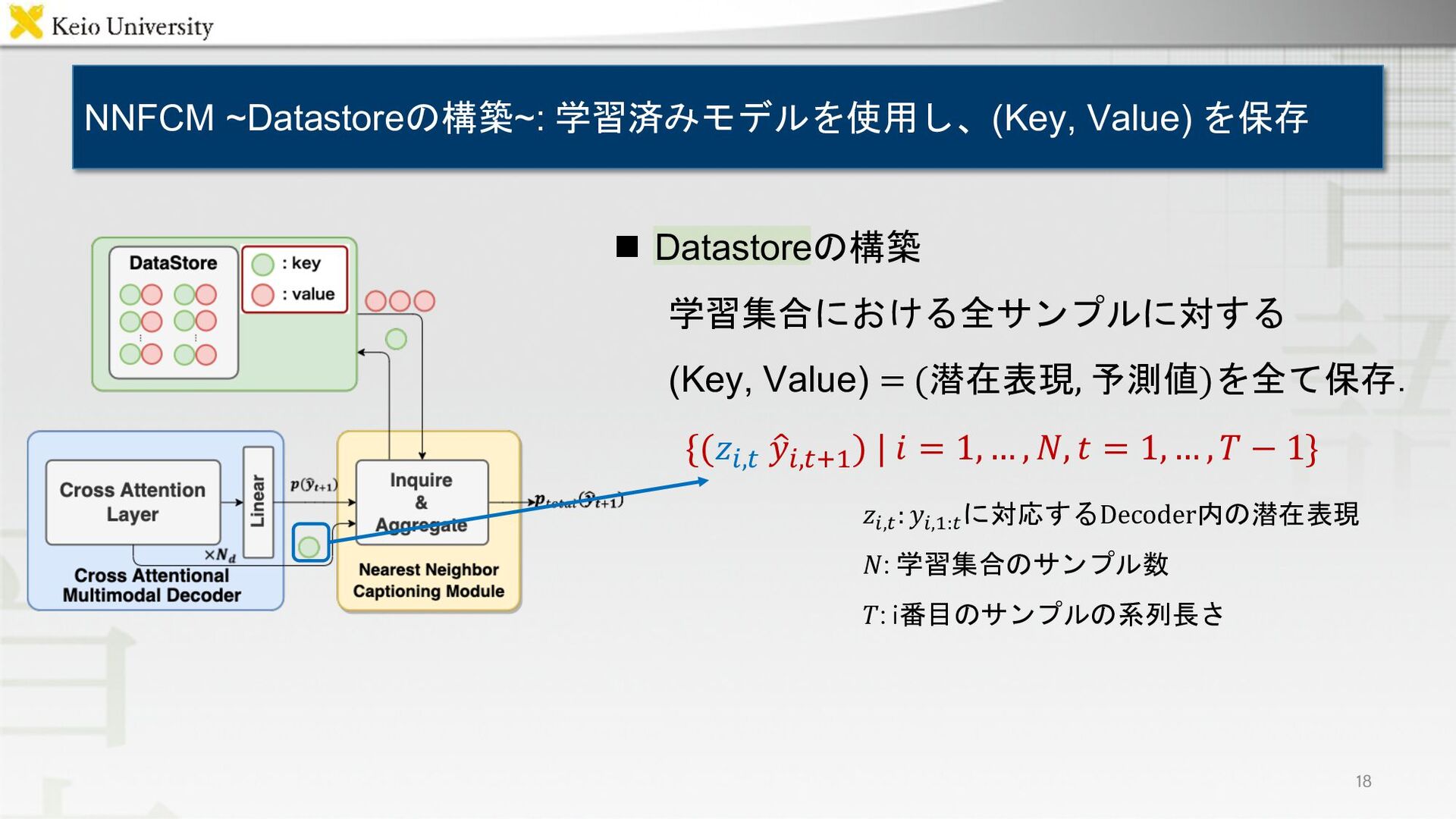{kind=link}
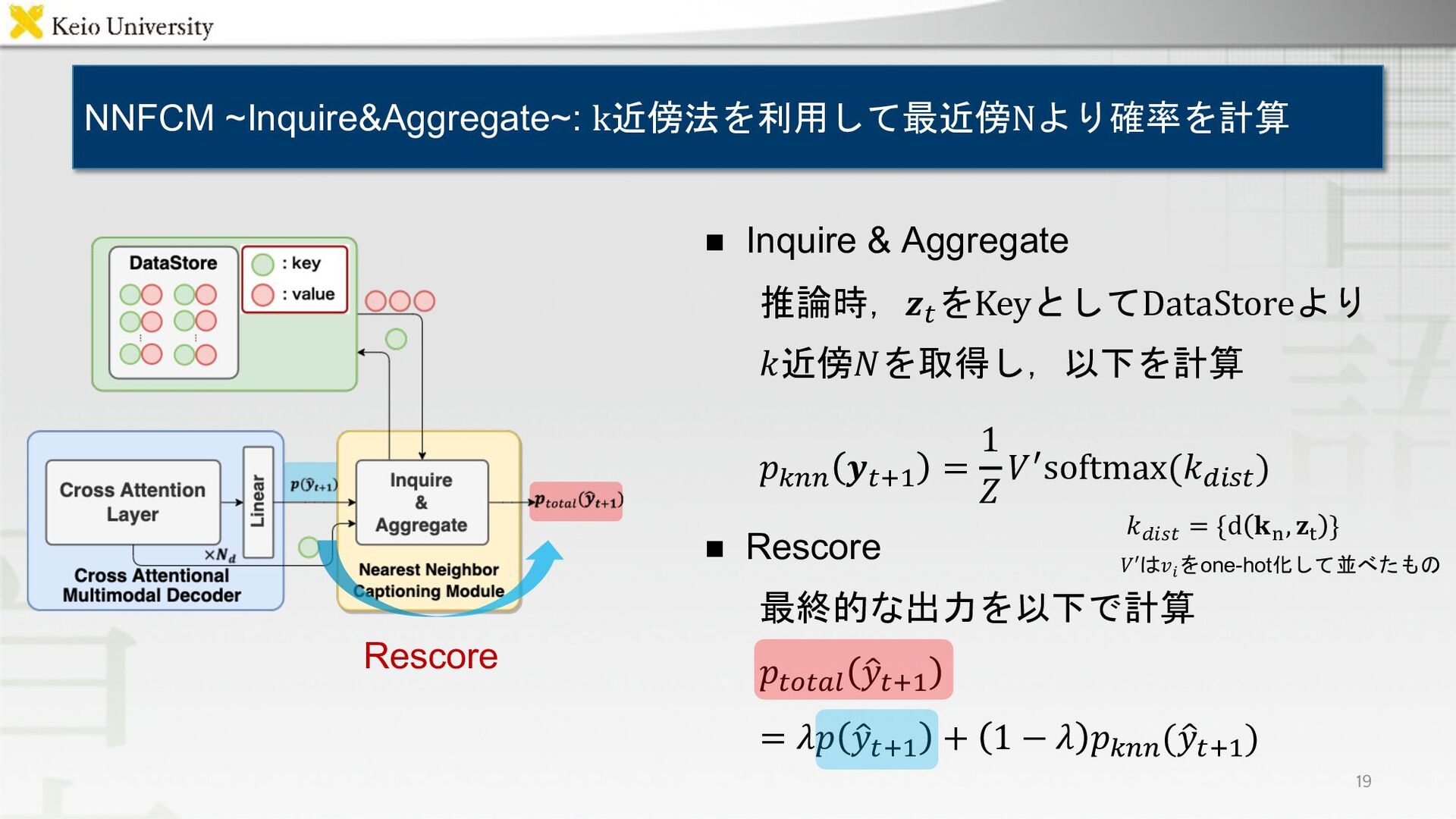{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![定性的結果 : 衝突する物体を正しく表現できている 26 正解文 把持中のペットボトルをおもちゃの木の車の上に配置しようとして、 うまく置けずにペットボトルが倒れる SAT[Xu+ ICML15] おもちゃの木の車がアームと衝突する](https://files.speakerdeck.com/presentations/00a04b3dc397402a87d44e2d32d2f1ac/slide_25.jpg){kind=link}
{kind=link}
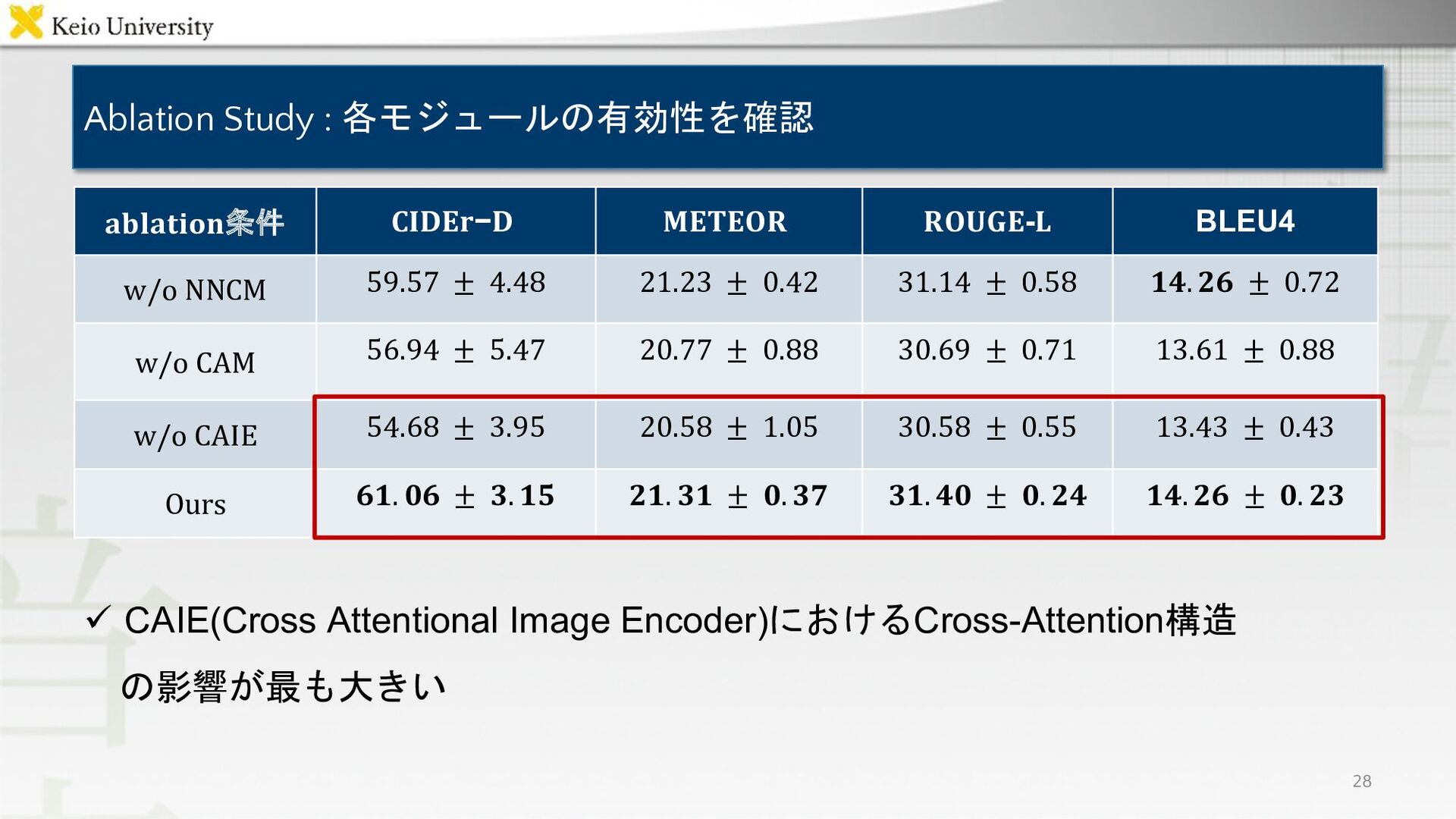{kind=link}
{kind=link}
![Appendix : Nearest Neighbor Language Model [Uravashi+, ICLR20] 30 学習集合](https://files.speakerdeck.com/presentations/00a04b3dc397402a87d44e2d32d2f1ac/slide_29.jpg){kind=link}
![Appendix : NNLM [Uravashi+, ICLR20]をマルチモーダル生成に適用 n NNMT [Uravashi+, ICLR21] --](https://files.speakerdeck.com/presentations/00a04b3dc397402a87d44e2d32d2f1ac/slide_30.jpg){kind=link}
{kind=link}
![Appendix : Attention Branch Network [Fukui+, CVPR19] n Attention Branch](https://files.speakerdeck.com/presentations/00a04b3dc397402a87d44e2d32d2f1ac/slide_32.jpg){kind=link}
![Appendix : PonNet[Magassouba+, AR21] n PonNet 物体配置時の 衝突 / 非衝突](https://files.speakerdeck.com/presentations/00a04b3dc397402a87d44e2d32d2f1ac/slide_33.jpg){kind=link}
![Appendix : Retrieval機構の関連研究 (REALM[Guu+, ICML20] , RAG[NeuraIPS20]) • 推論時、明示的に知識コーパスから文書を抽出し、入力に加える ことによって予測を行う手法](https://files.speakerdeck.com/presentations/00a04b3dc397402a87d44e2d32d2f1ac/slide_34.jpg){kind=link}