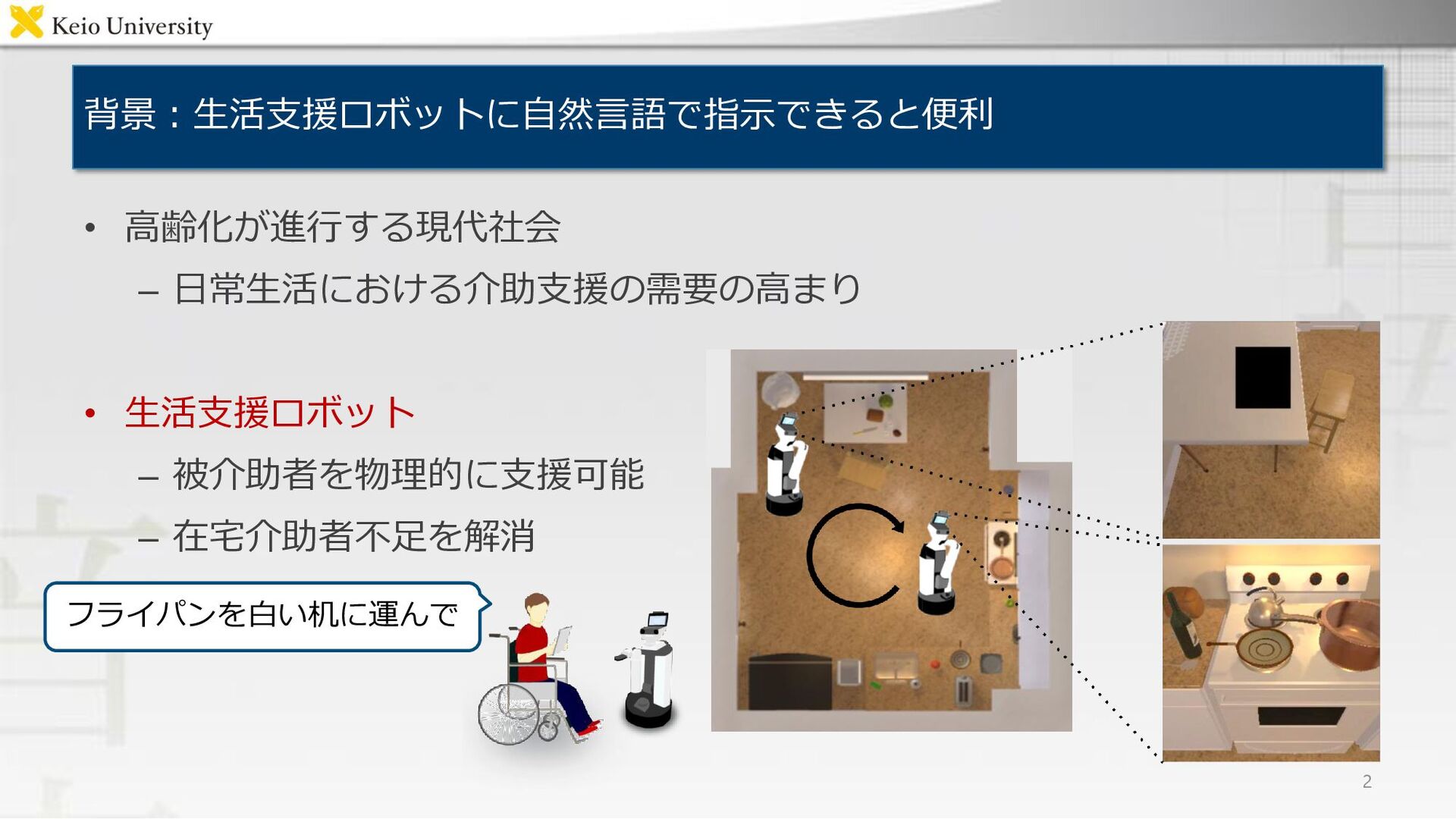
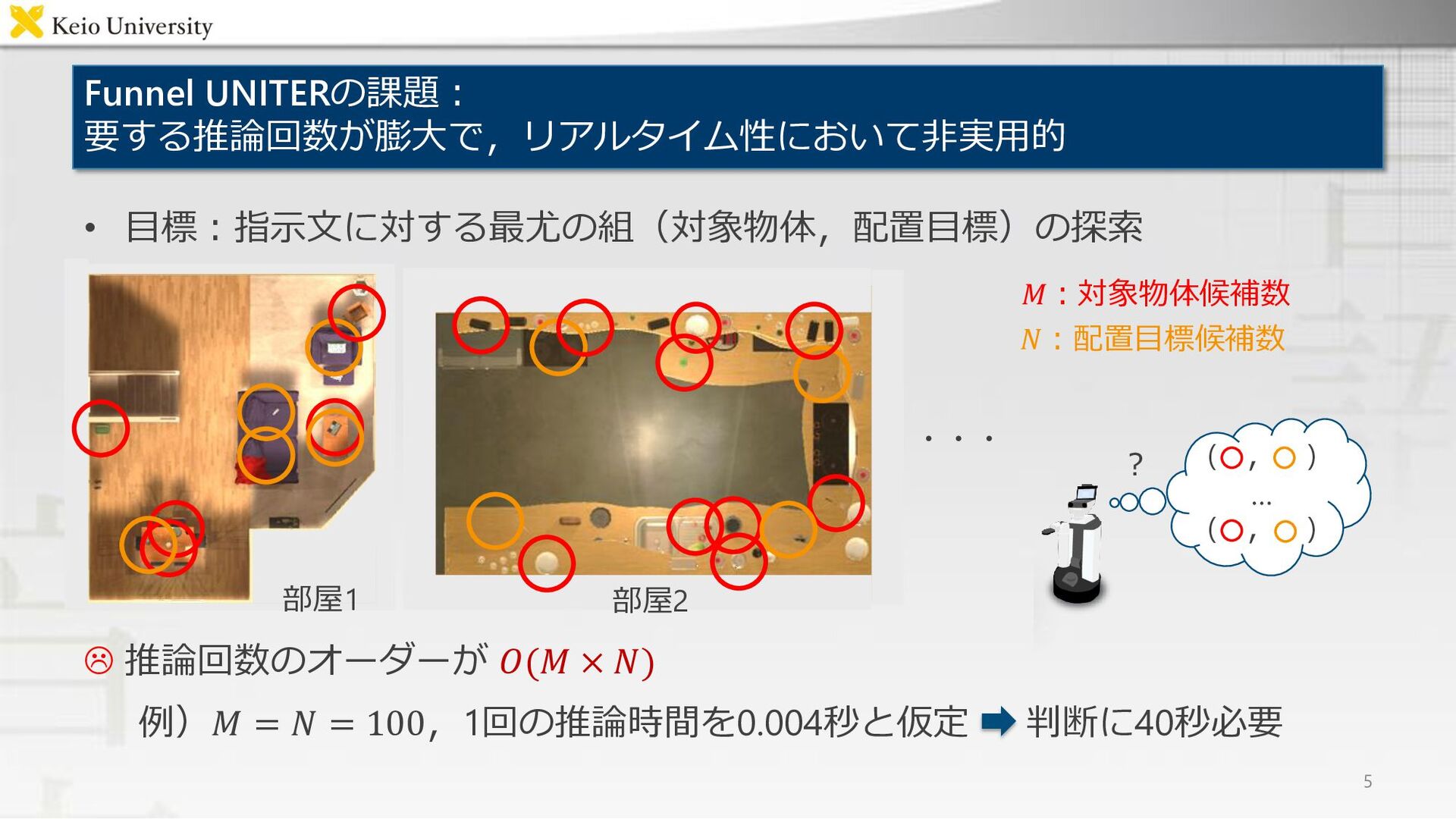
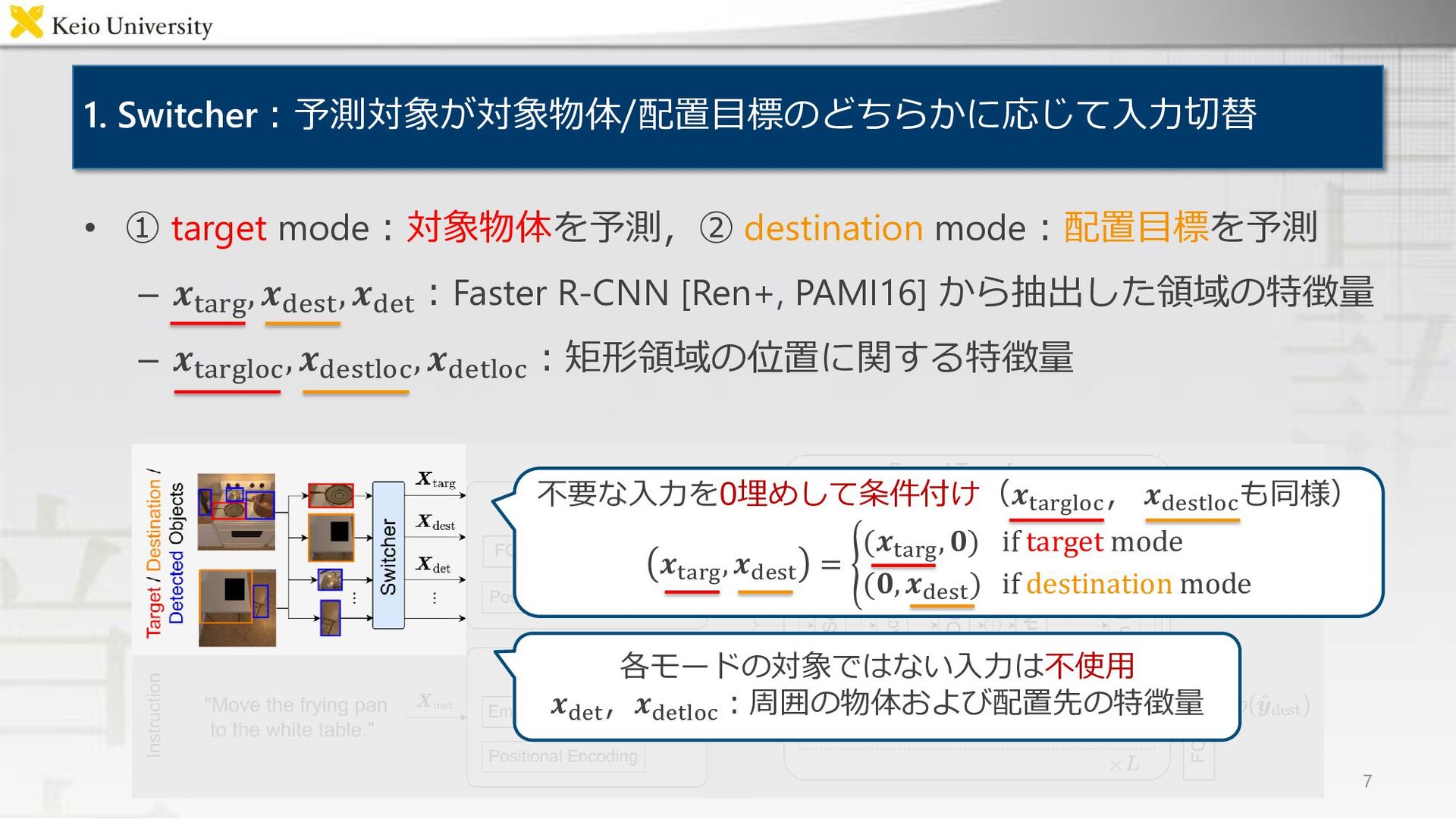
入力 ① 指示文 ② 対象物体候補の領域 ③ 配置目標候補の領域 ④ 画像中の各物体および配置先の領域 • 出力 – 対象物体候補および配置目標候補が,ともに指示文のGround Truthに一致する確率 – 望ましい出力:一致すれば1,しなければ0 “Move the to the .” 対象物体候補の画像 配置目標候補の画像 3 対象物体 配置目標 frying pan white table
the metal rack.” “Put a towel in the bath tub.” • 負例に対する失敗例 ☺ 対象物体候補が鏡に映った ものであると判断する難しさ 12 対象物体候補/配置目標候補が, ともにGround Truthに一致すると正しく予測 対象物体候補が、 Ground Truthに一致すると誤って予測
{kind=link}
{kind=link}
{kind=link}
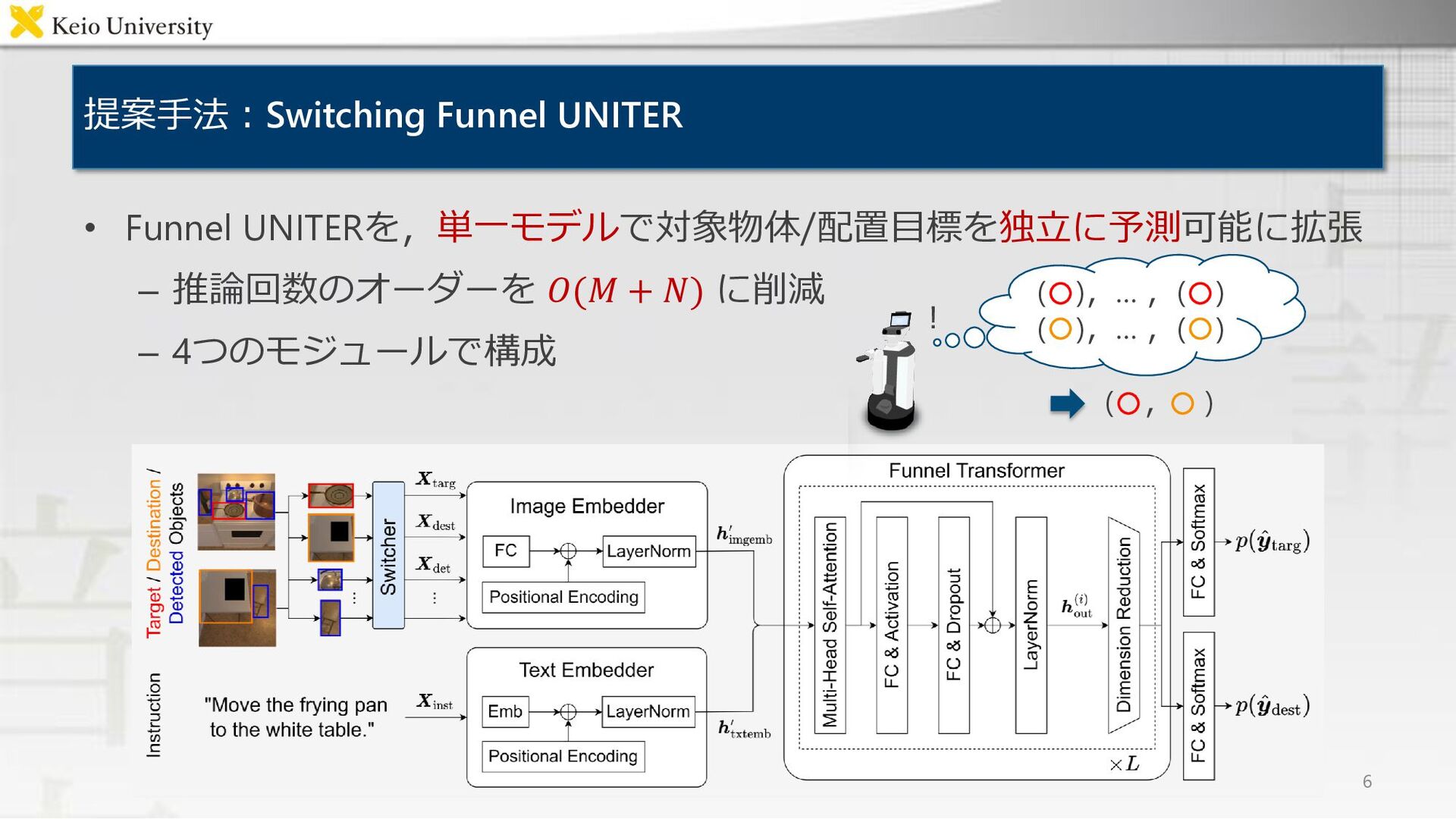
![関連研究 手法 概要 MTCM [Magassouba+, RA-L19] ・自然言語による指示文と全体画像を入力とし,対象物体を特定 ・VGG-16およびLSTMを使用 Target-dependent UNITER](https://files.speakerdeck.com/presentations/f2c580e6cf104d799d1c09b40165abf1/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
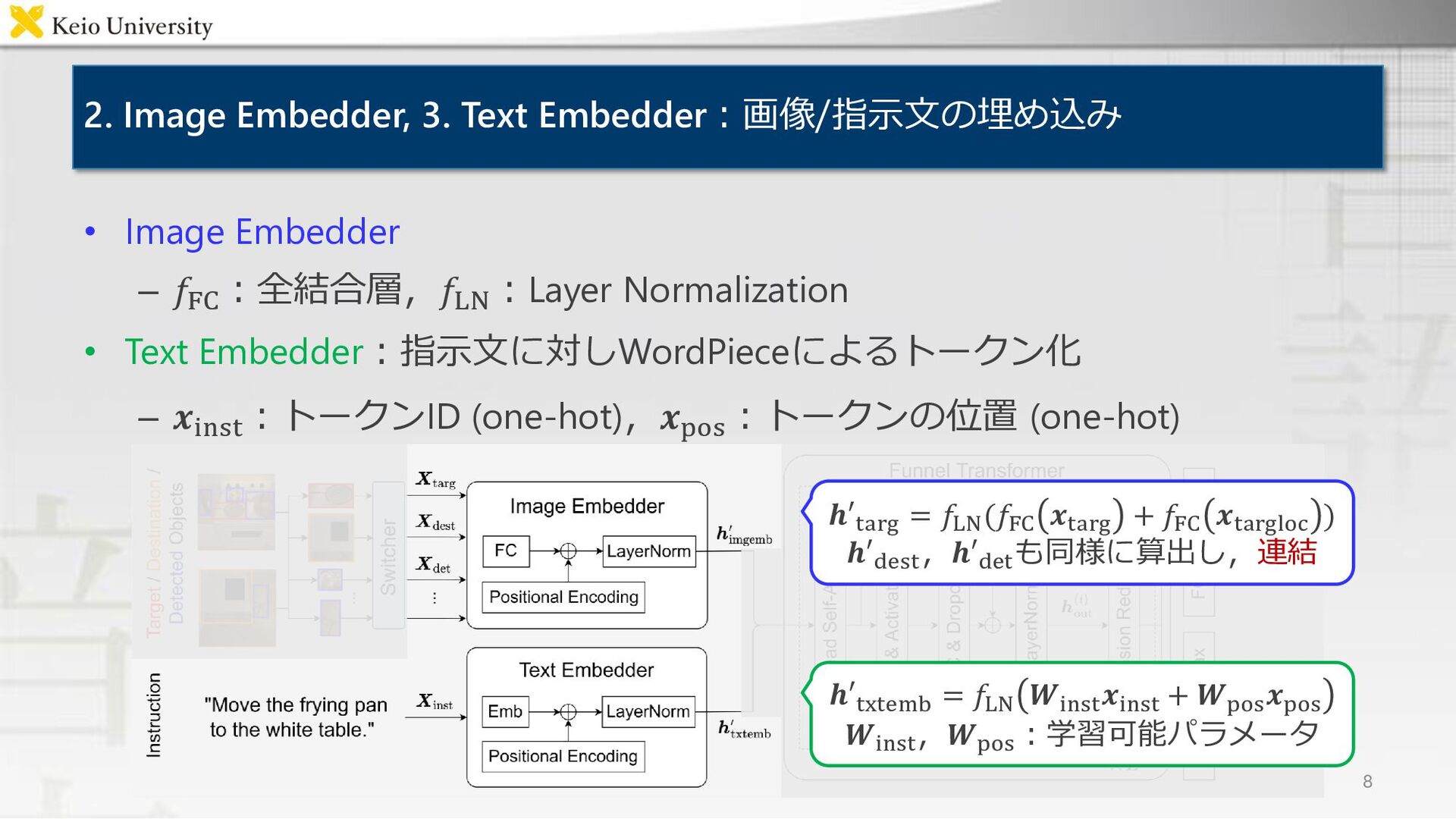{kind=link}
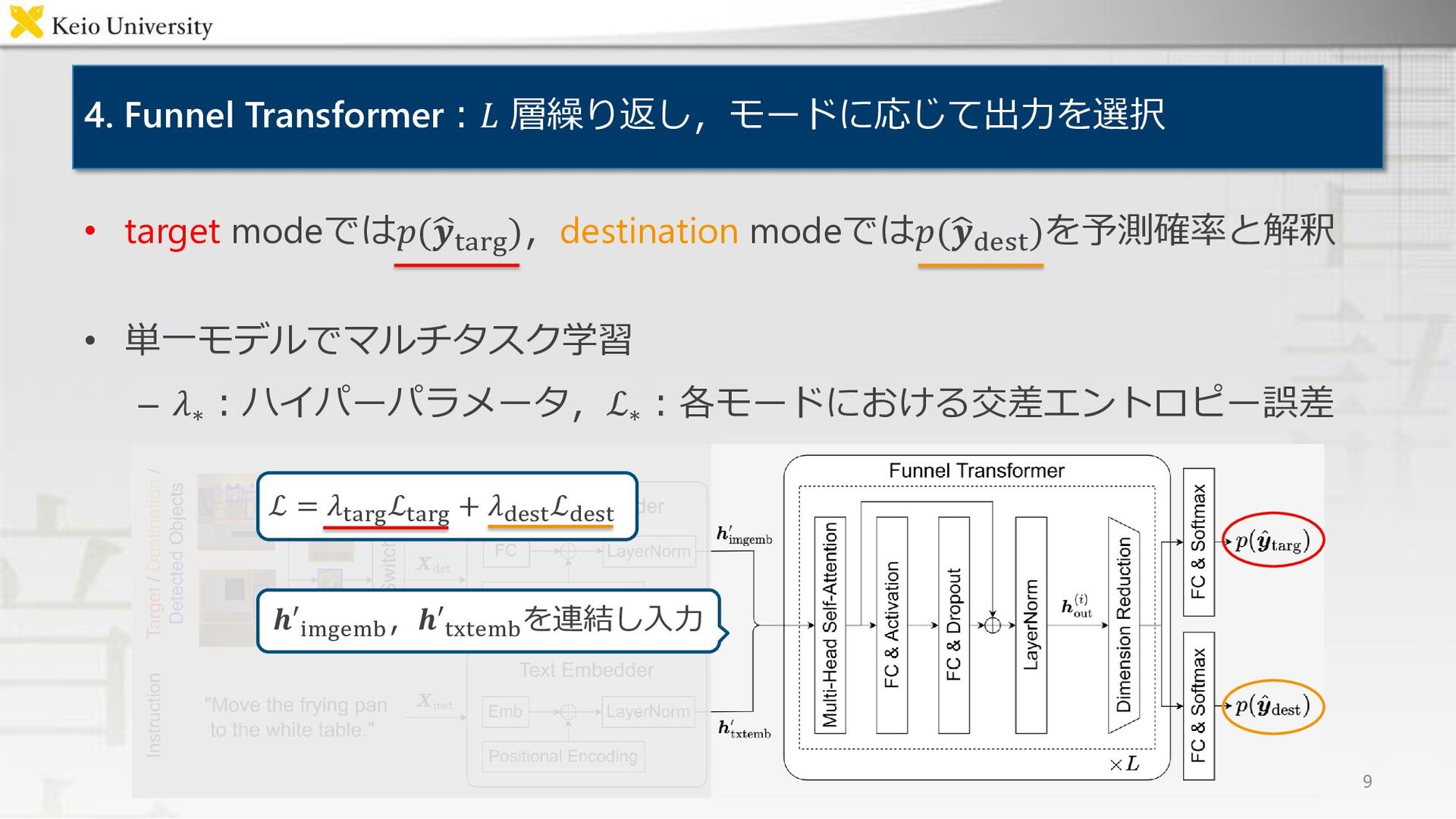{kind=link}
![実験設定:”ALFRED-fc” データセットを収集し,性能を評価 • ALFRED [Shridhar+, CVPR20] – 物体操作を含むVision-Language Navigationの標準ベンチマーク •](https://files.speakerdeck.com/presentations/f2c580e6cf104d799d1c09b40165abf1/slide_9.jpg){kind=link}
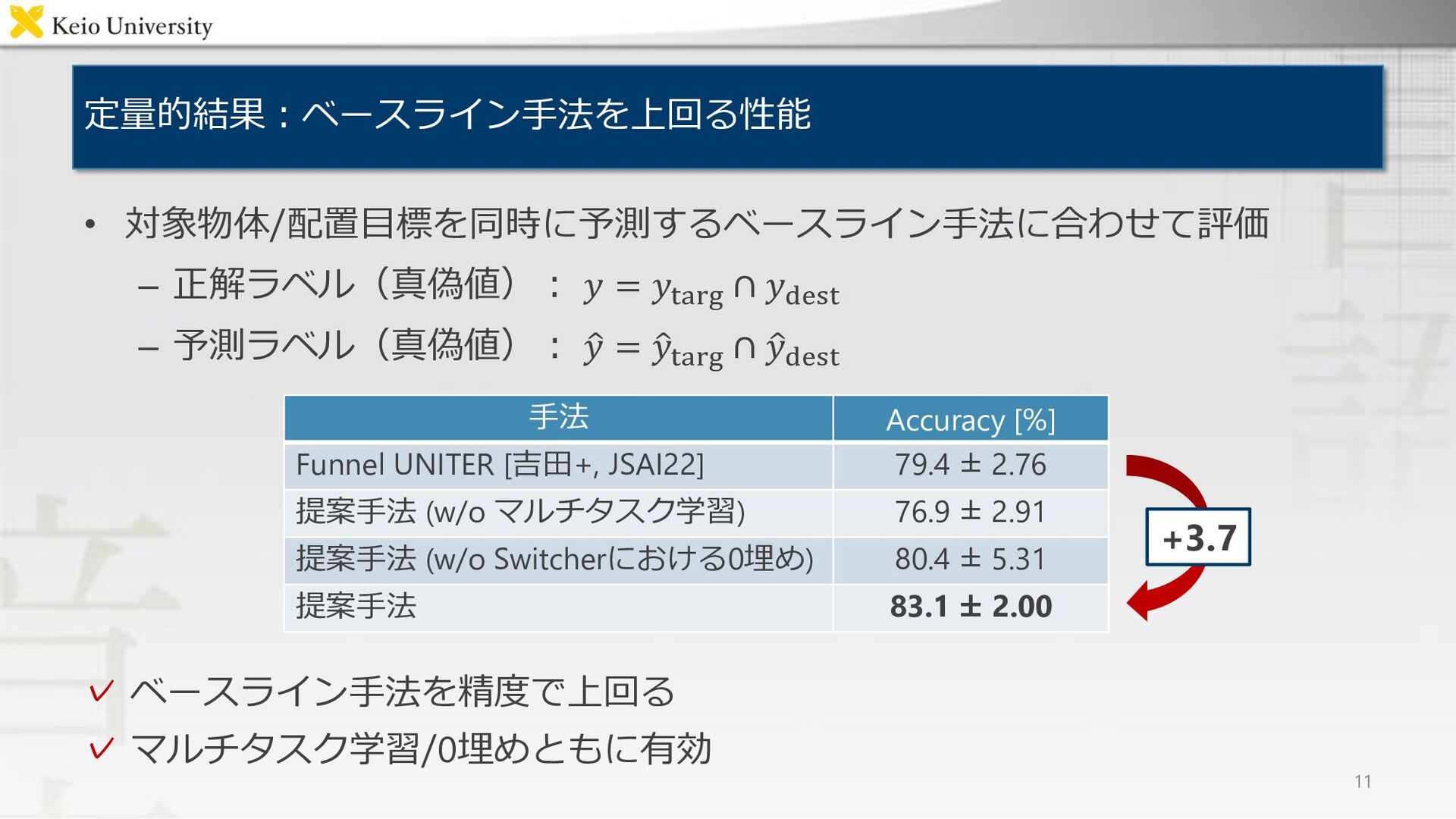{kind=link}
{kind=link}
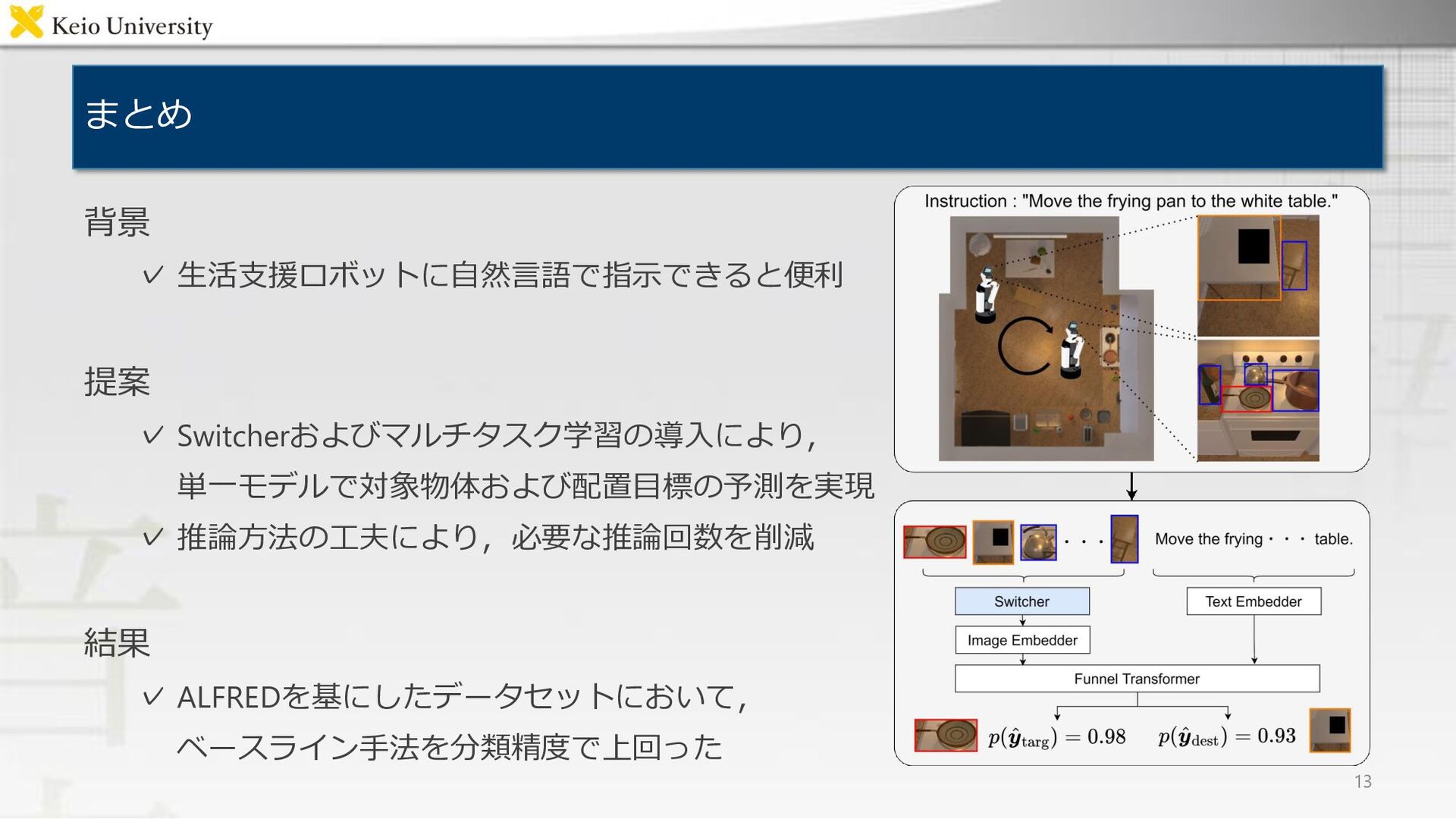{kind=link}