– INET_NTOA(653235463) = 38.239.149.7 • 优先使用ENUM或SET – ENUM占用1个字节 – SET视界节点,最多占用8字节 – `sex` enum(‘F’,’M’) • 避免使用NULL字段 – 很难进行查询优化 – NULL列添加索引需要额外空间 – 含NULL复合索引无效 • 使用timestamp而不是datetime – UNIX_TIMESTAMP('2012-07-17 15:01:15') = 1342508475 – FROM_UNIXTIME(1342508475) = 2012-07-17 15:01:15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
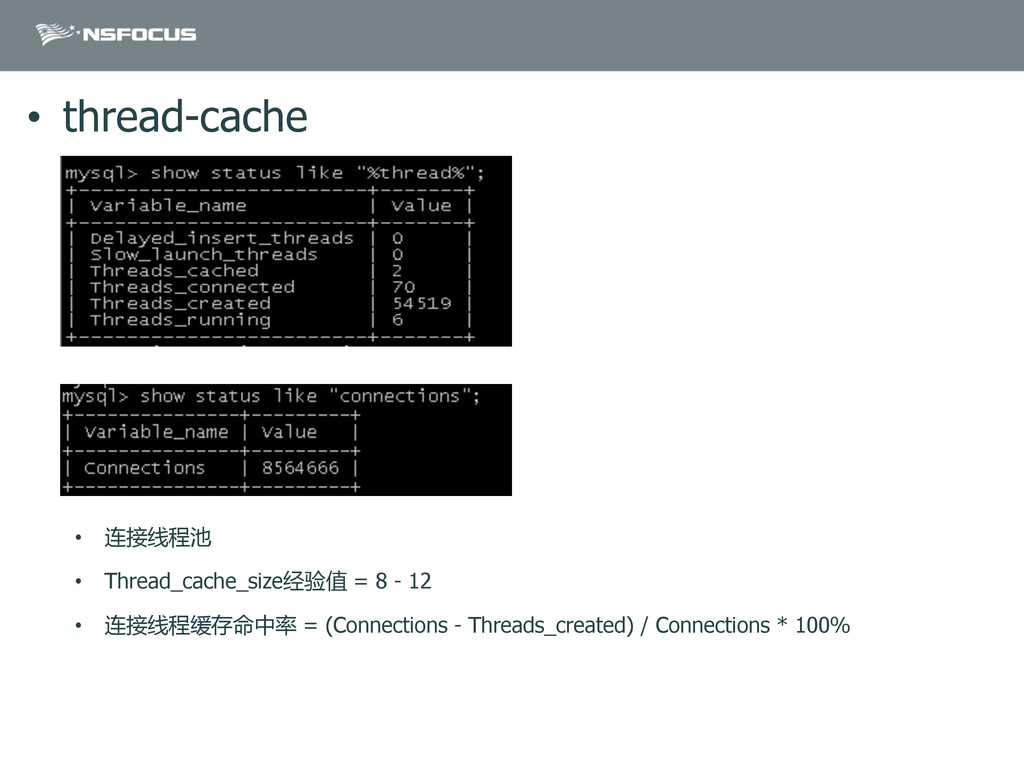{kind=link}
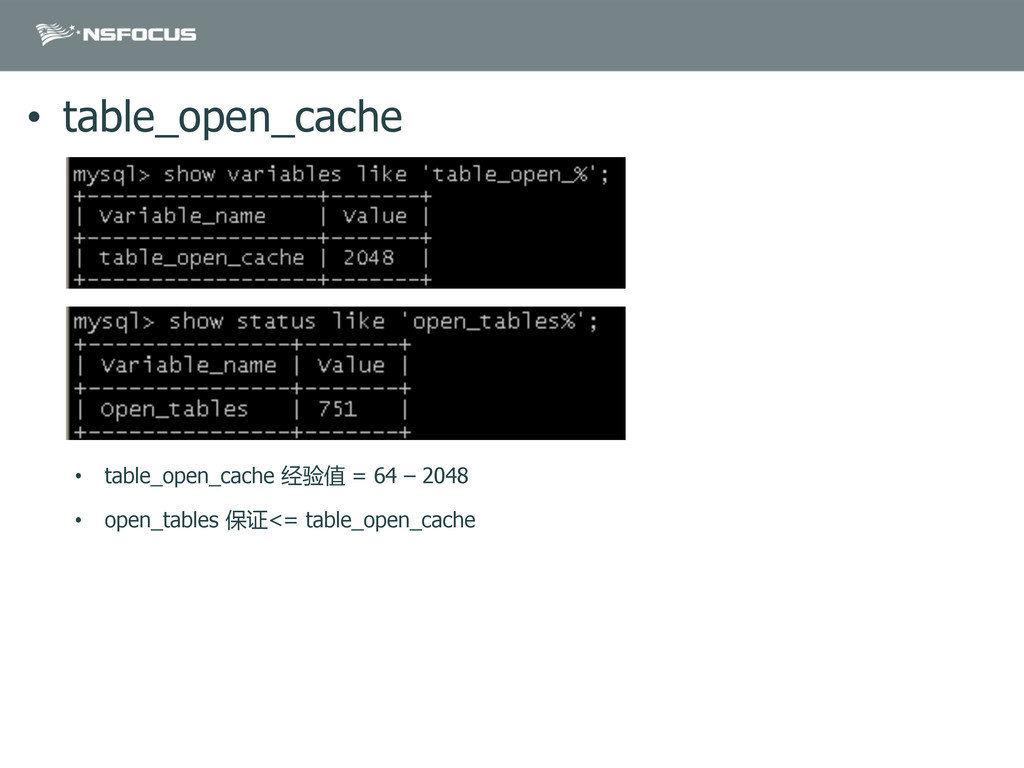{kind=link}
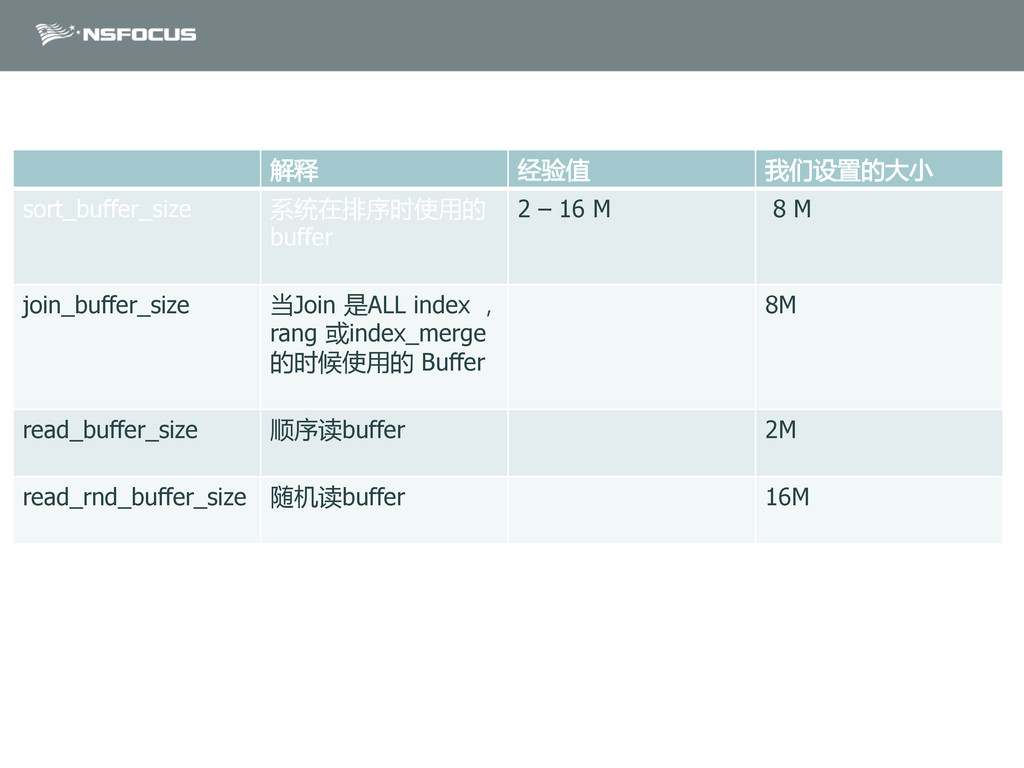{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
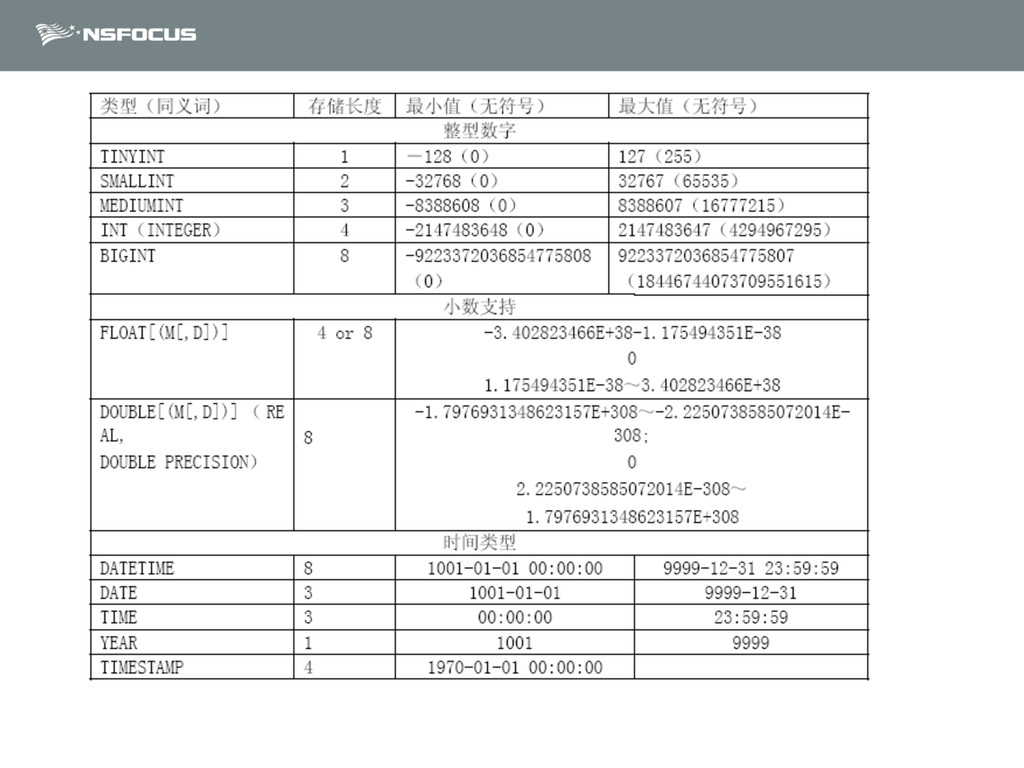{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
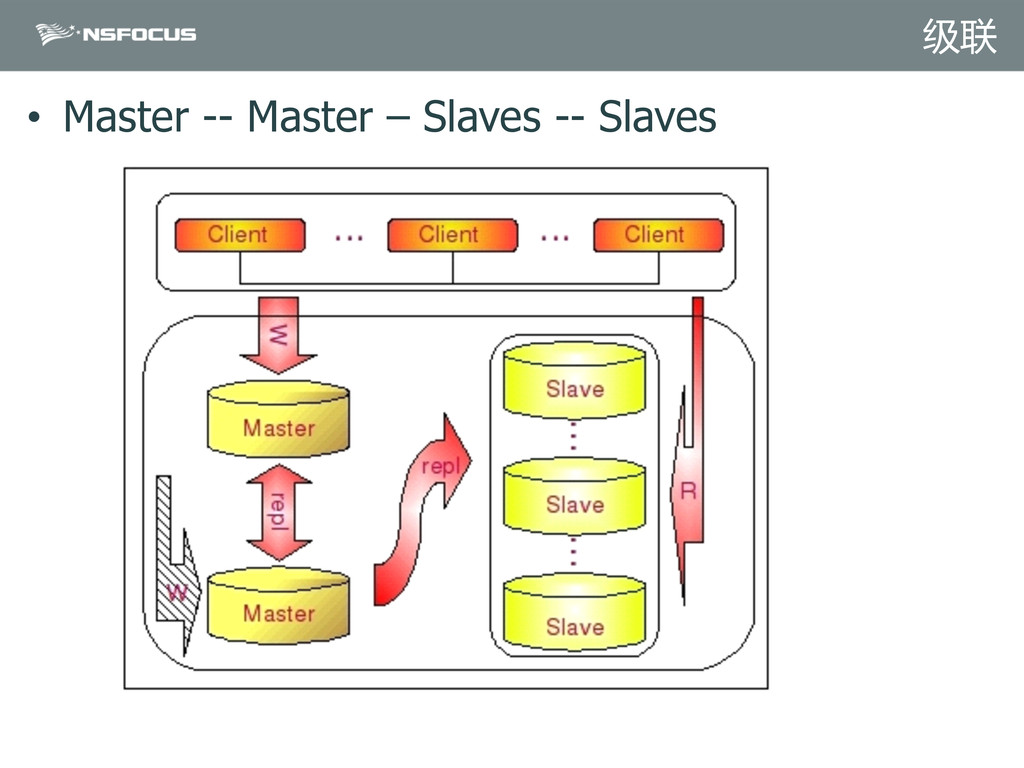{kind=link}
{kind=link}
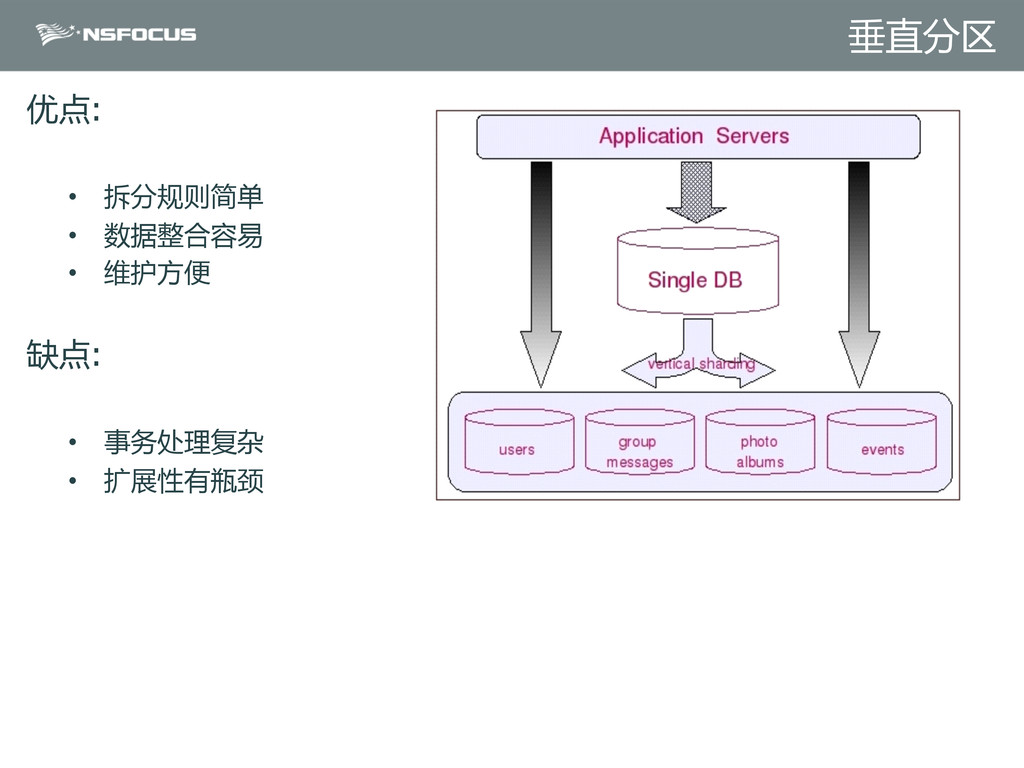{kind=link}
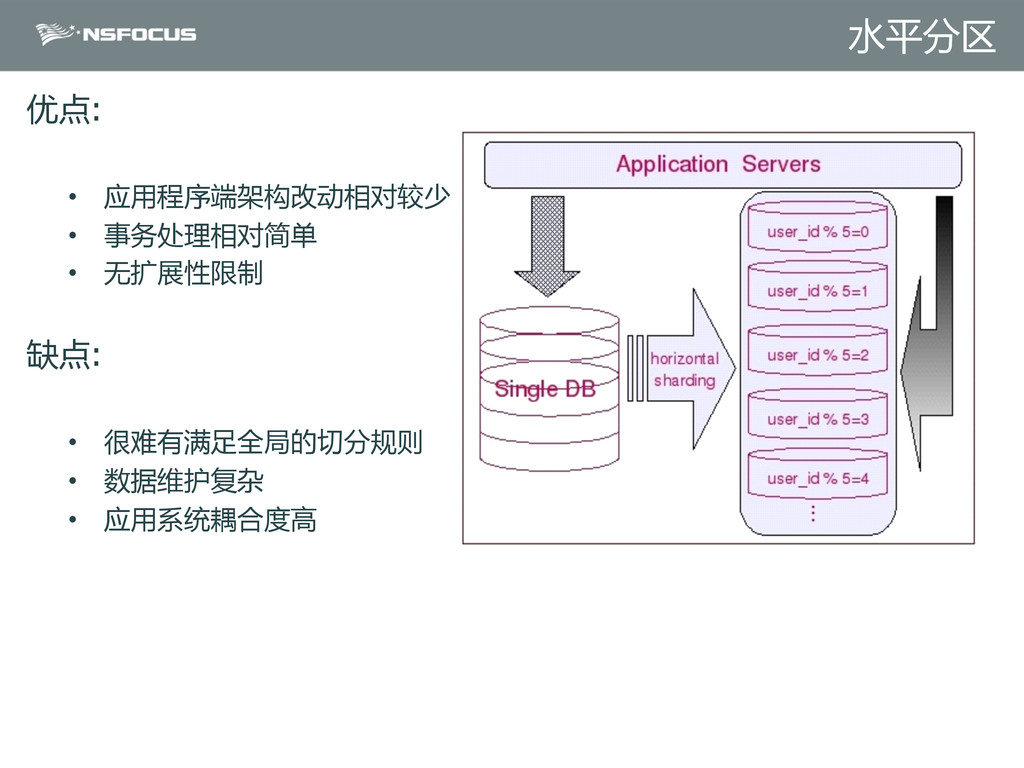{kind=link}
{kind=link}
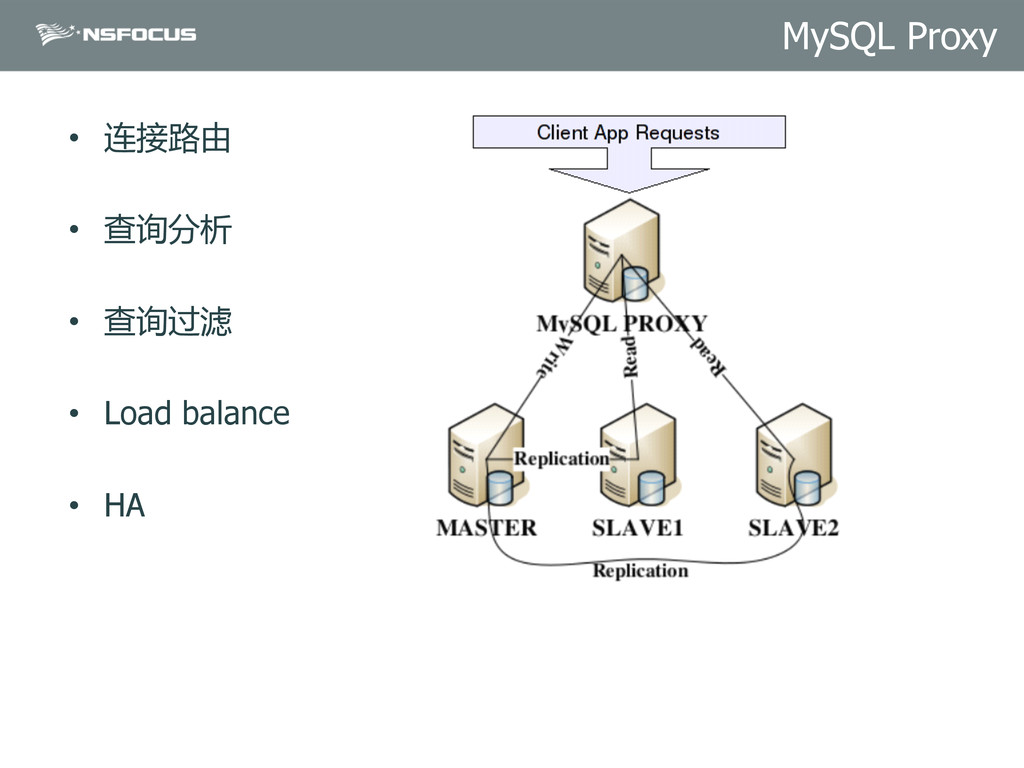{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
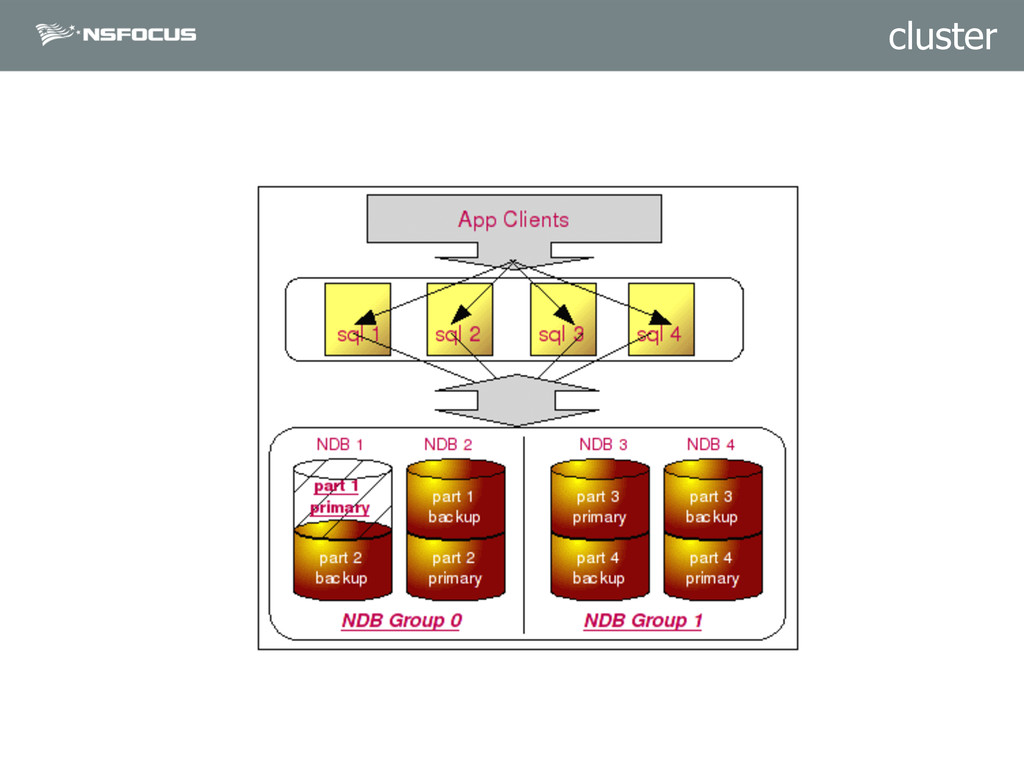{kind=link}
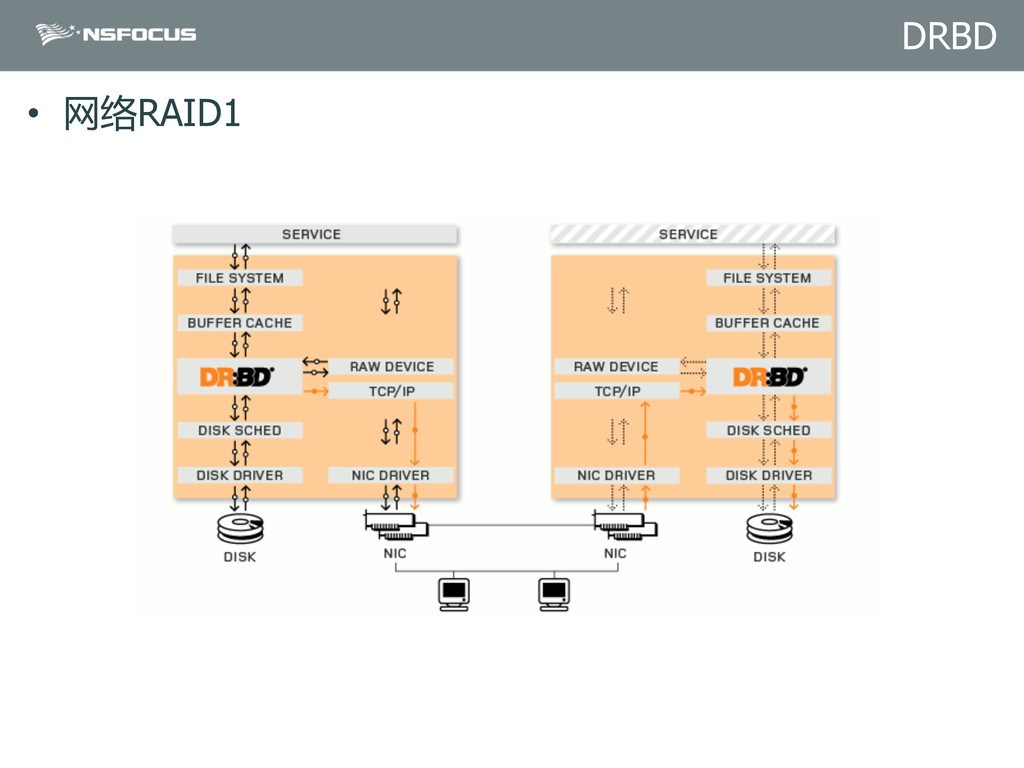{kind=link}
{kind=link}