Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AI エージェント間の自然な会話に向けたテキストからの音声対話生成
Search
Kentaro Mitsui
March 06, 2024
330
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AI エージェント間の自然な会話に向けたテキストからの音声対話生成
日本音響学会第151回(2024年春季)研究発表会での発表スライドです。
Kentaro Mitsui
March 06, 2024
More Decks by Kentaro Mitsui
See All by Kentaro Mitsui
Interspeech2023 参加報告
kentaro321
0
780
Featured
See All Featured
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Docker and Python
trallard
47
4k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.4k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
1k
Raft: Consensus for Rubyists
vanstee
141
7.6k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
The Limits of Empathy - UXLibs8
cassininazir
1
520
Transcript
1 © rinna Co.,Ltd. All rights reserved. AI エージェント間の自然な会話に 向けたテキストからの音声対話
生成 三井 健太郎、法野 行哉、沢田 慶 日本音響学会 2024年春季研究発表会 2024/03/07 rinna株式会社 三井 健太郎
2 © rinna Co.,Ltd. All rights reserved. 本発表の概要 ⚫ 背景
◆ 大規模言語モデル (LLM) の発展により計算機の(テキスト)対話能力が向上 ◆ 人-AI間だけでなく、AI-AI間の対話にも需要 ◆ AI間の音声対話はそれほど開拓されていない ⚫ テキスト音声合成 (TTS) ベース:聞き手の発話(相槌・笑い)や話者交替に課題 ⚫ 言語モデルベース [Nguyen+, 2023]:テキストでの制御ができず、意味性に課題 ⚫ 提案手法 ◆ テキスト対話が与えられたとき、2人のAI間の音声対話を生成するシステム Chatty Agents Text-to-Speech: CHATSを提案 ◆ 2チャネルの音声を扱うことで、聞き手の発話(相槌・笑い)も同時にモデル化 ◆ データの前処理の工夫により、重複を含む話者交替を統一的に表現
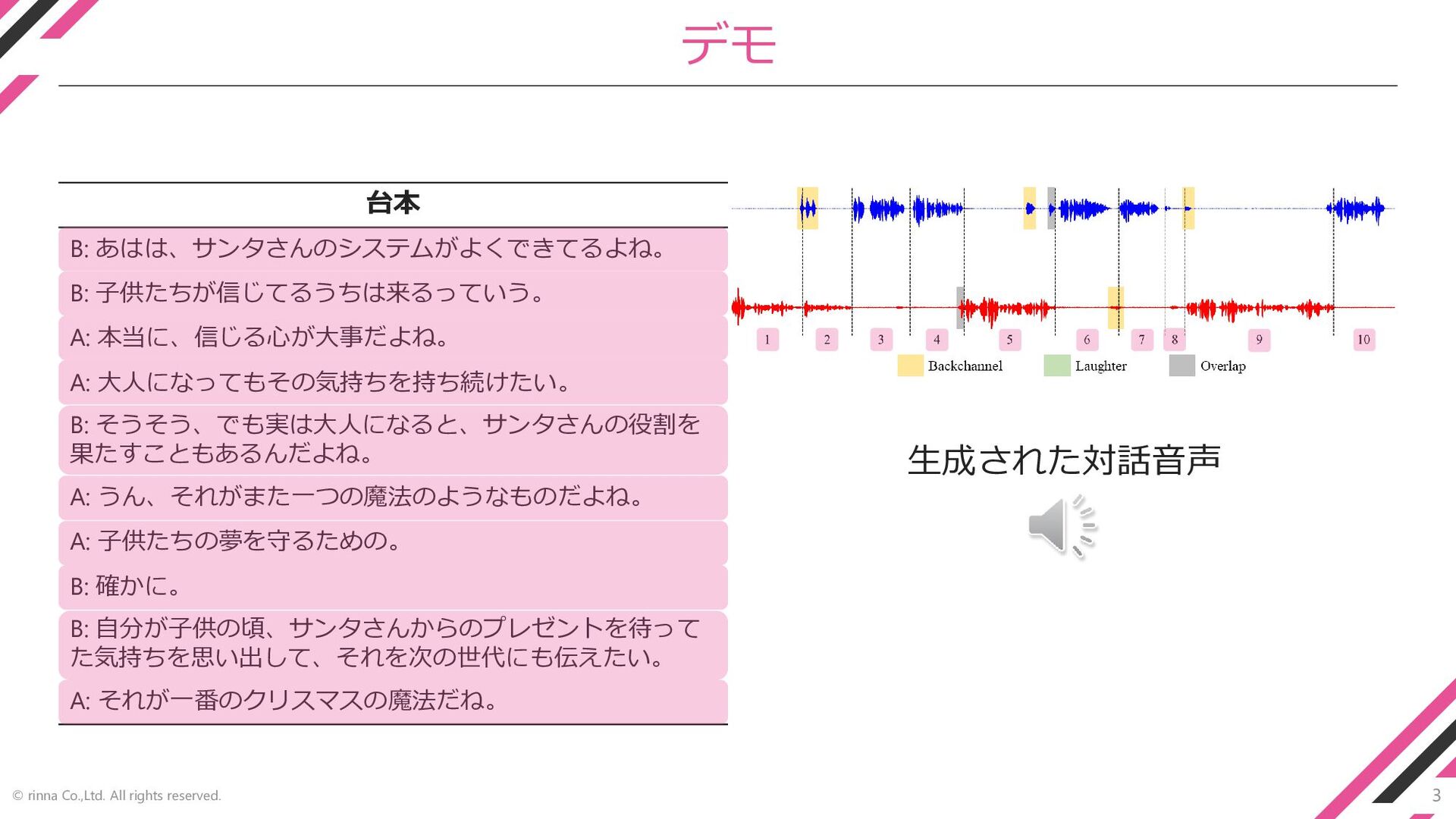
3 © rinna Co.,Ltd. All rights reserved. デモ 台本 B:
あはは、サンタさんのシステムがよくできてるよね。 B: 子供たちが信じてるうちは来るっていう。 A: 本当に、信じる心が大事だよね。 A: 大人になってもその気持ちを持ち続けたい。 B: そうそう、でも実は大人になると、サンタさんの役割を 果たすこともあるんだよね。 A: うん、それがまた一つの魔法のようなものだよね。 A: 子供たちの夢を守るための。 B: 確かに。 B: 自分が子供の頃、サンタさんからのプレゼントを待って た気持ちを思い出して、それを次の世代にも伝えたい。 A: それが一番のクリスマスの魔法だね。 生成された対話音声
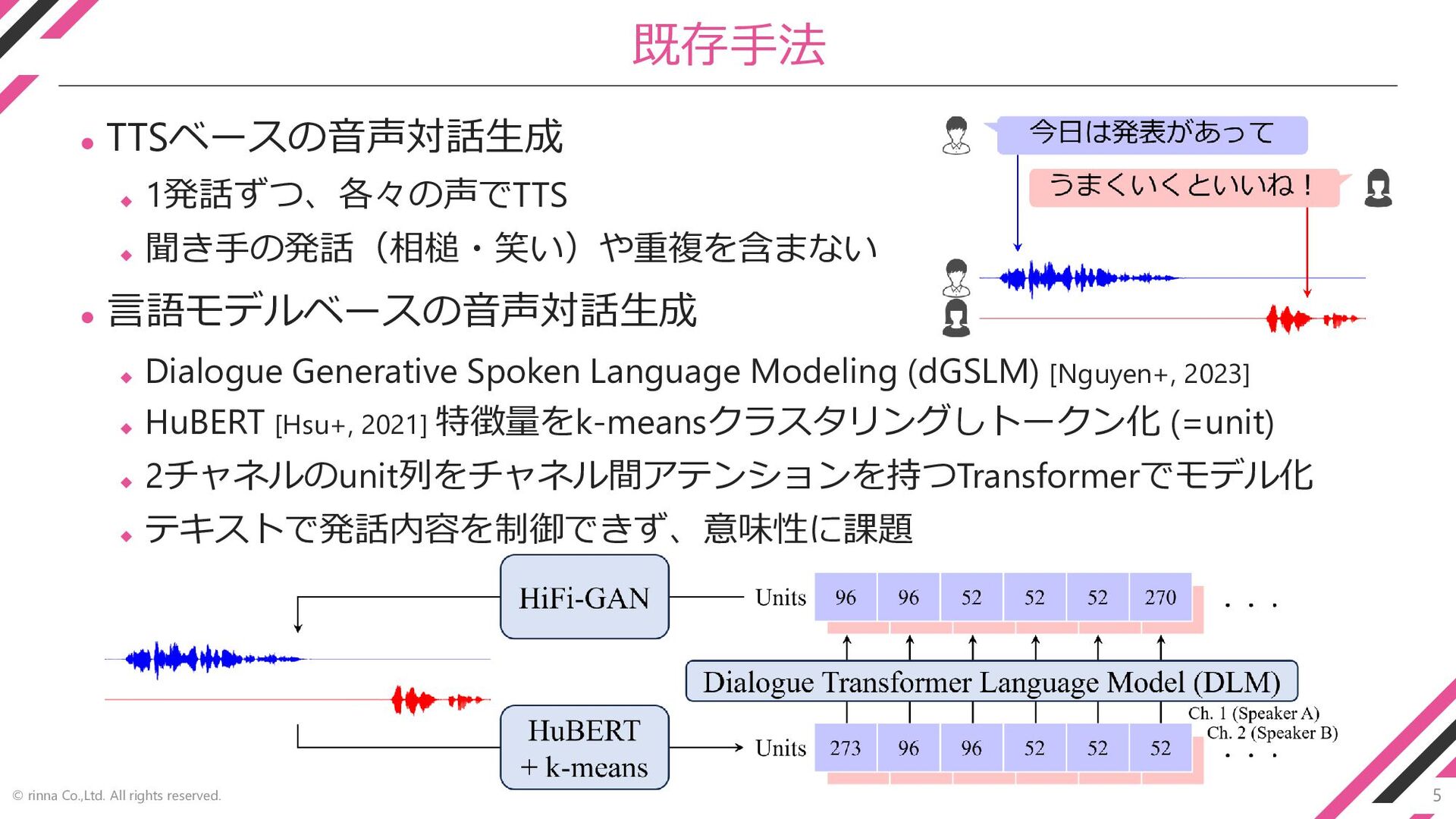
5 © rinna Co.,Ltd. All rights reserved. 既存手法 ⚫ TTSベースの音声対話生成
◆ 1発話ずつ、各々の声でTTS ◆ 聞き手の発話(相槌・笑い)や重複を含まない ⚫ 言語モデルベースの音声対話生成 ◆ Dialogue Generative Spoken Language Modeling (dGSLM) [Nguyen+, 2023] ◆ HuBERT [Hsu+, 2021] 特徴量をk-meansクラスタリングしトークン化 (=unit) ◆ 2チャネルのunit列をチャネル間アテンションを持つTransformerでモデル化 ◆ テキストで発話内容を制御できず、意味性に課題
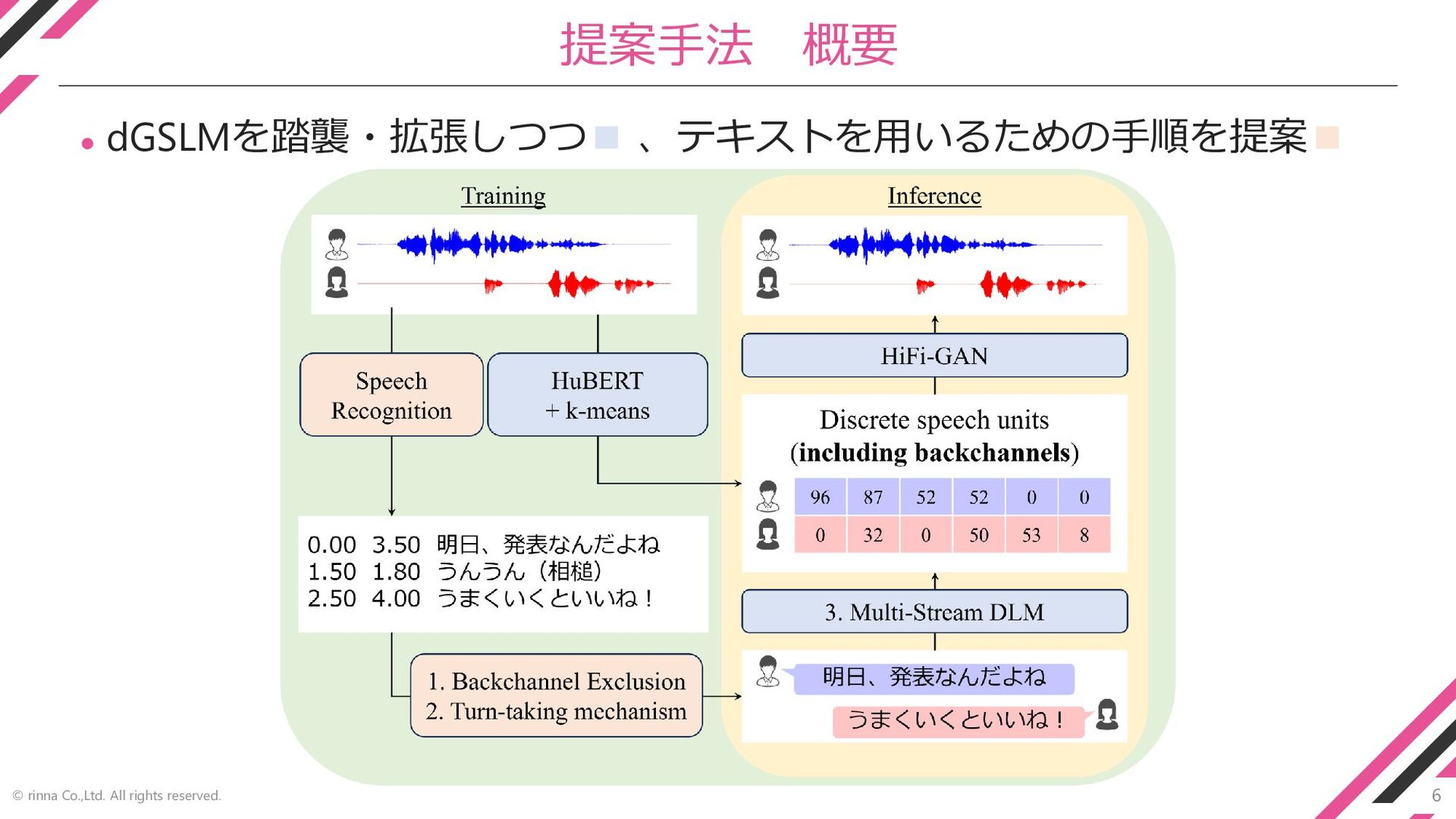
6 © rinna Co.,Ltd. All rights reserved. 提案手法 概要 ⚫
dGSLMを踏襲・拡張しつつ▪ 、テキストを用いるための手順を提案▪
7 © rinna Co.,Ltd. All rights reserved. 提案手法 1. 入力となるテキスト対話の準備
⚫ 以下の方法で入力となるテキスト対話を準備 1. 各チャネルに音声認識を適用 2. テキスト対話の形式に近づけるため 時間情報と聞き手の発話を削除 ⚫ 話し手・聞き手は以下のアルゴリズムで分類 1. 200ms以上の無音で区切られた各Inter-Pausal Unit (IPU) について 𝐼𝑃𝑈𝐴 ⊃ 𝐼𝑃𝑈𝐵 を満たすとき、前者を話し手、後者を聞き手と定義 2. IPUに対応するunit列から話し手・聞き手を判定する二値分類器を学習 3. 1で分類されなかったIPUに対し、2を用いて話し手・聞き手を分類 0.00 3.50 A: 明日、発表なんだよね 1.50 1.80 B: うんうん(相槌) 2.50 4.00 B: うまくいくといいね! A: 明日、発表なんだよね B: うまくいくといいね!
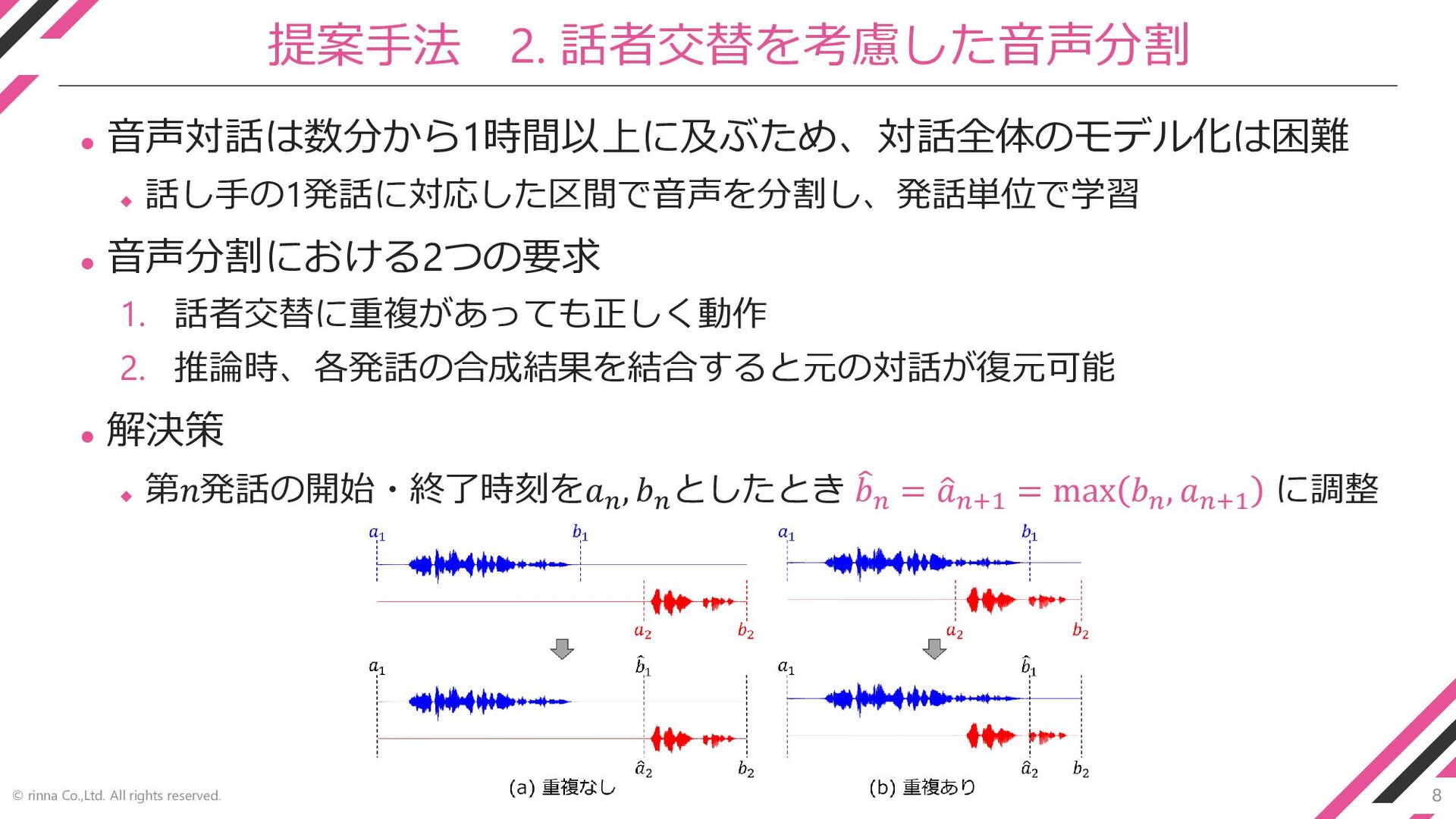
8 © rinna Co.,Ltd. All rights reserved. 提案手法 2. 話者交替を考慮した音声分割
⚫ 音声対話は数分から1時間以上に及ぶため、対話全体のモデル化は困難 ◆ 話し手の1発話に対応した区間で音声を分割し、発話単位で学習 ⚫ 音声分割における2つの要求 1. 話者交替に重複があっても正しく動作 2. 推論時、各発話の合成結果を結合すると元の対話が復元可能 ⚫ 解決策 ◆ 第𝑛発話の開始・終了時刻を𝑎𝑛 , 𝑏𝑛 としたとき 𝑏𝑛 = ො 𝑎𝑛+1 = max 𝑏𝑛 , 𝑎𝑛+1 に調整
9 © rinna Co.,Ltd. All rights reserved. 提案手法 3. 言語モデルの条件付けと拡張
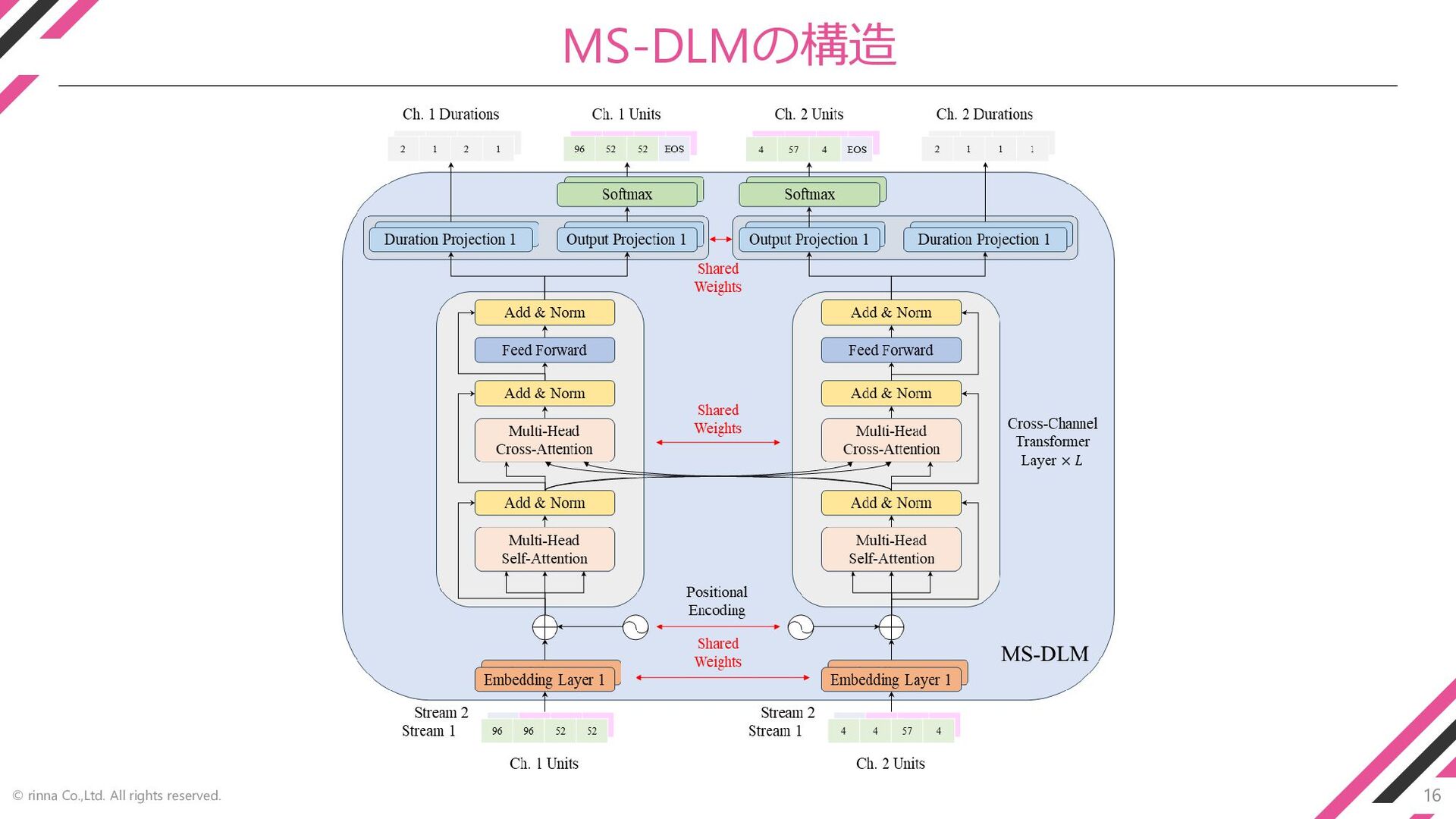
⚫ dGSLMの言語モデル (DLM) を拡張 ◆ 話者ID、当該発話の音素、次発話の音素、過去のunitで条件付け ◆ Content unit (HuBERT) に加えpitch unitを同時にモデル化 [Kharitonov+, 2022] ◆ 複数の系列を扱えるよう入出力層を拡張 = Multi-Stream DLM
10 © rinna Co.,Ltd. All rights reserved. 提案手法 推論 ⚫
各発話のunit列を生成し、HiFi-GANで音声波形に変換 ◆ 第𝑛発話の音声生成には第𝑛 + 1発話までのテキストがあれば十分
11 © rinna Co.,Ltd. All rights reserved. 実験条件 ⚫ データセット
◆ 32組54話者(一部重複あり)による538対話、計74時間の雑談音声対話を収録 ◆ 日本語話し言葉コーパス (CSJ) の3244話者・523時間のデータをMS-DLMの 事前学習に利用 ⚫ モデル ◆ 話し手・聞き手の二値分類器:3層・512次元の双方向LSTMを利用 ◆ HuBERT:rinna/japanese-hubert-baseの12層目の特徴量を利用 ◆ HiFi-GAN:分割済みの音声対話データで一から学習 ◆ MS-DLM:6層、8ヘッド、512次元のTransformer Decoder (うち4層はチャネル間アテンションあり) ⚫ 学習 ◆ A100 (80GB) 2枚で事前学習5時間、本学習11時間(HiFi-GANは1枚で32時間)
12 © rinna Co.,Ltd. All rights reserved. 発話レベルの評価:音素誤り率 ⚫ 単一の発話を合成した際の音素誤り率
(Phoneme Error Rate: PER) を算出 ◆ 音素認識器はjapanese-hubert-baseをCSJでファインチューニングして利用 ◆ MS-DLMを(話者、音素列、unit列)の組で学習したもの (TTS) と比較 ⚫ 結果 ◆ TTSと比べ、CHATSはわずかにPERが劣化 ◆ 大規模データ (CSJ) を用いた事前学習はTTS, CHATSいずれにおいても有効 Method PER↓ Ground Truth 8.95 Resynthesized 11.49 TTS 12.13 w/o pretraining 14.10 CHATS 13.03 w/o pretraining 15.32
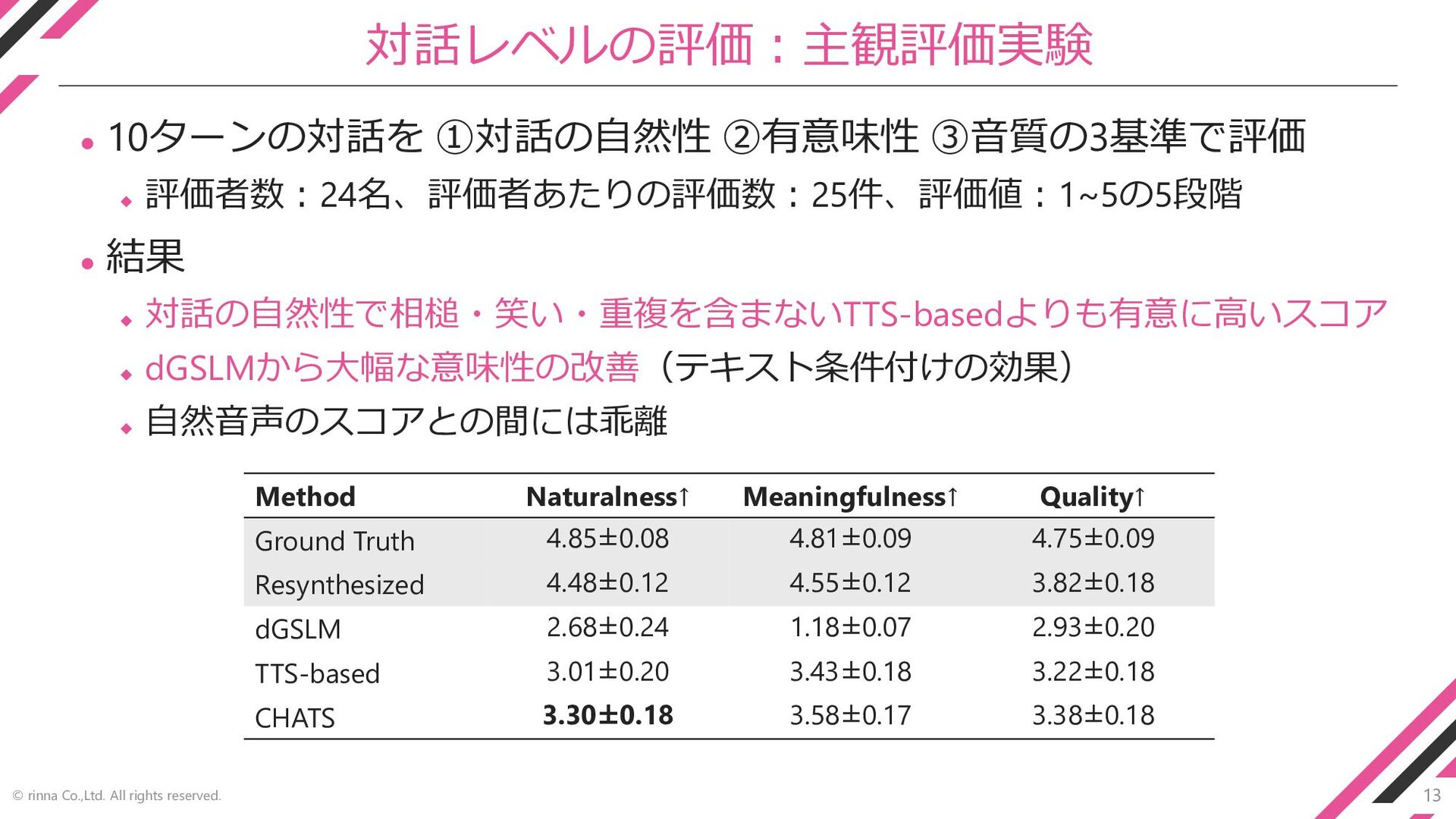
13 © rinna Co.,Ltd. All rights reserved. 対話レベルの評価:主観評価実験 ⚫ 10ターンの対話を
①対話の自然性 ②有意味性 ③音質の3基準で評価 ◆ 評価者数:24名、評価者あたりの評価数:25件、評価値:1~5の5段階 ⚫ 結果 ◆ 対話の自然性で相槌・笑い・重複を含まないTTS-basedよりも有意に高いスコア ◆ dGSLMから大幅な意味性の改善(テキスト条件付けの効果) ◆ 自然音声のスコアとの間には乖離 Method Naturalness↑ Meaningfulness↑ Quality↑ Ground Truth 4.85±0.08 4.81±0.09 4.75±0.09 Resynthesized 4.48±0.12 4.55±0.12 3.82±0.18 dGSLM 2.68±0.24 1.18±0.07 2.93±0.20 TTS-based 3.01±0.20 3.43±0.18 3.22±0.18 CHATS 3.30±0.18 3.58±0.17 3.38±0.18
14 © rinna Co.,Ltd. All rights reserved. 結論 ⚫ テキスト対話から自然な音声対話を生成するシステム、CHATSを提案
◆ テキスト対話と音声対話の関係を適切にモデル化するための工夫を導入 ◆ 聞き手の発話(相槌・笑い)や重複含む話者交替が対話の自然性向上に寄与 ⚫ 提案手法の限界 ◆ 2人の音声が2チャネルに分かれて収録されていることが必要 ◆ 雑談以外のドメインでは未検証(相槌の頻度や内容、笑いの有無に変化?) ◆ 次に読み上げるテキストが既知であることが必要 ⚫ 今後の展望 ◆ 1チャネルに混ざって収録された対話音声の利用方法の検討 ◆ 他ドメインデータでの学習、およびドメイン情報による条件付けの検討 ◆ 人-AI間の音声対話への応用
15 © rinna Co.,Ltd. All rights reserved. 補足資料
16 © rinna Co.,Ltd. All rights reserved. MS-DLMの構造
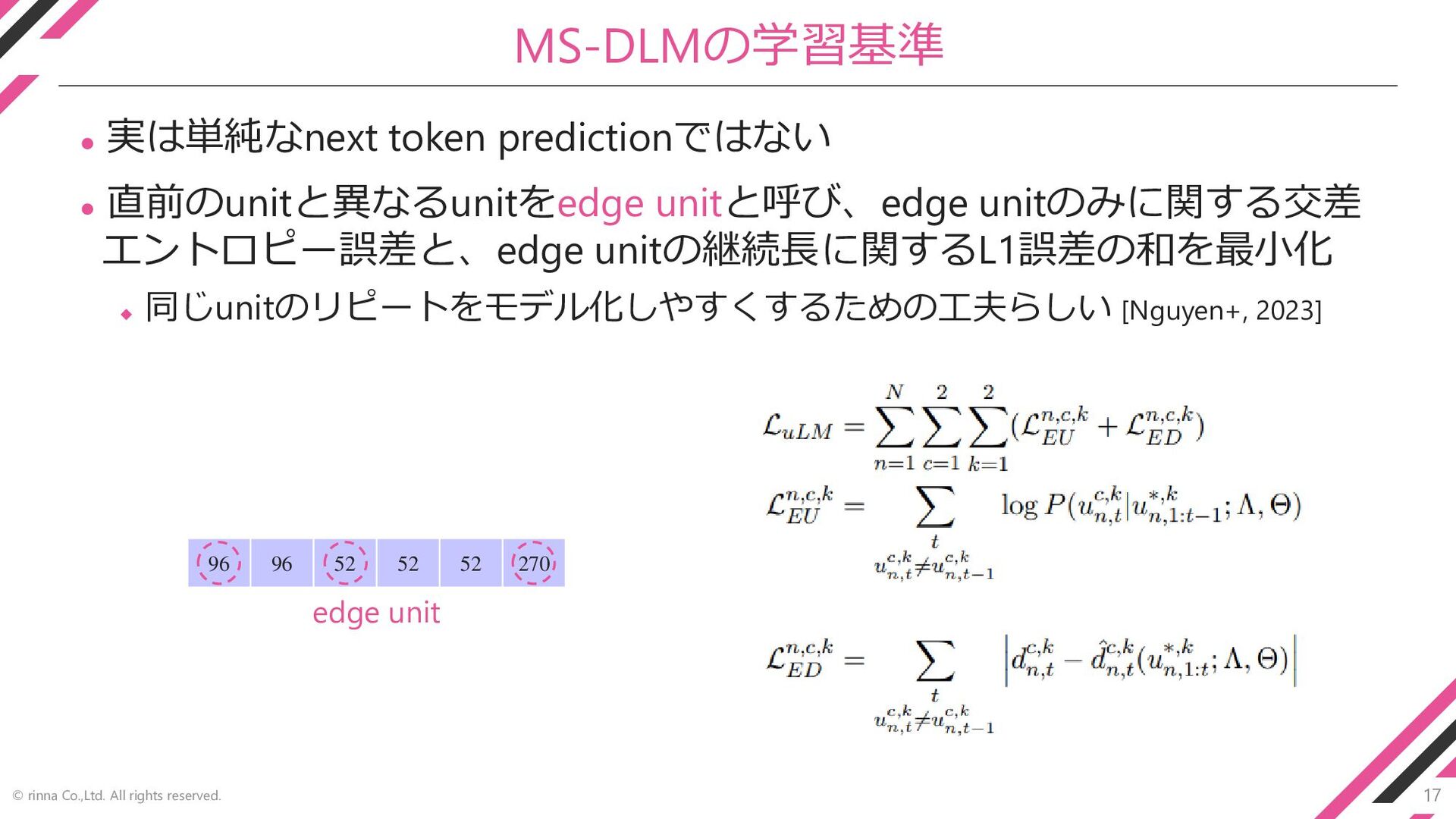
17 © rinna Co.,Ltd. All rights reserved. MS-DLMの学習基準 ⚫ 実は単純なnext
token predictionではない ⚫ 直前のunitと異なるunitをedge unitと呼び、edge unitのみに関する交差 エントロピー誤差と、edge unitの継続長に関するL1誤差の和を最小化 ◆ 同じunitのリピートをモデル化しやすくするための工夫らしい [Nguyen+, 2023] 96 96 52 52 52 270 edge unit
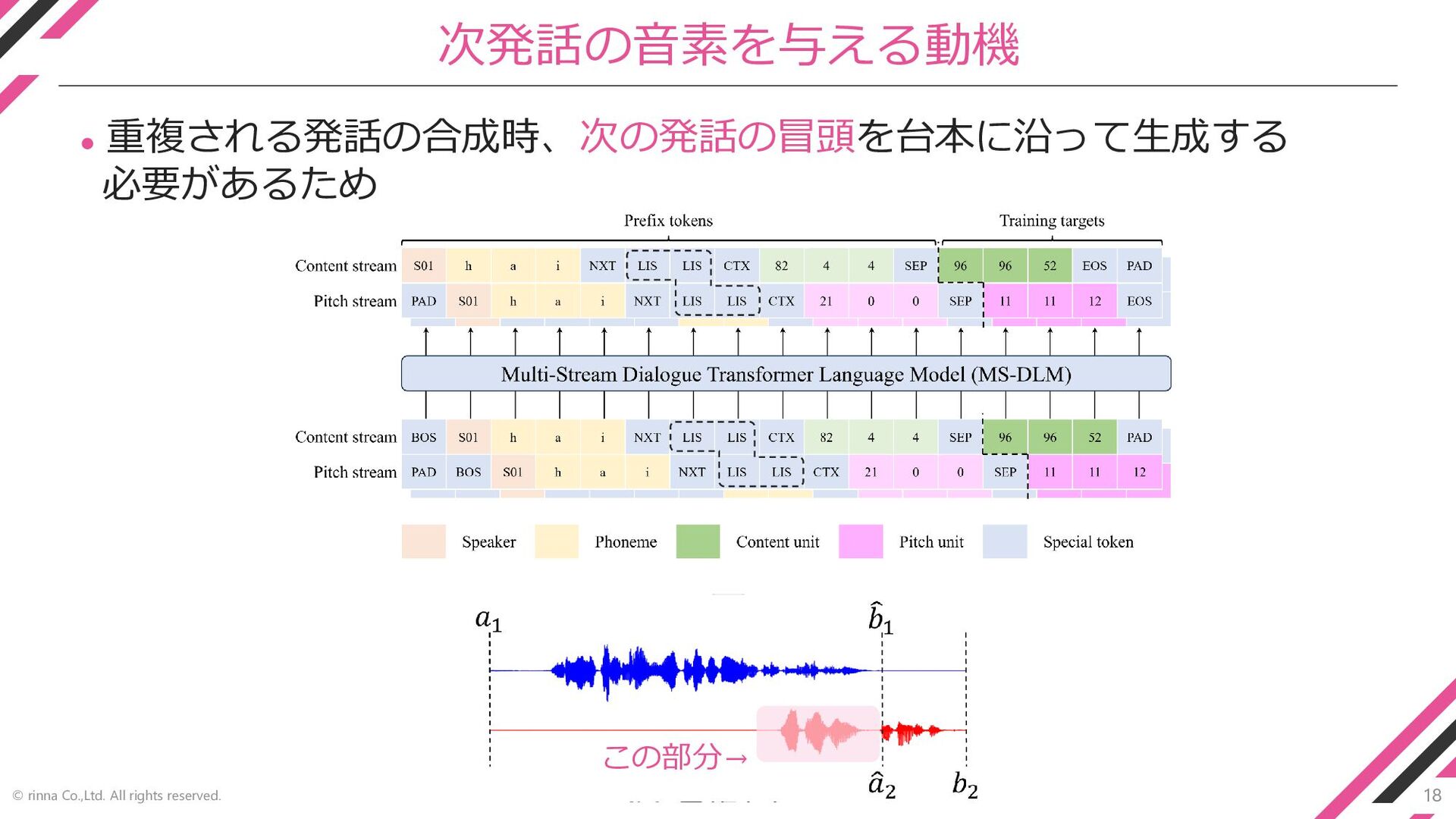
18 © rinna Co.,Ltd. All rights reserved. 次発話の音素を与える動機 ⚫ 重複される発話の合成時、次の発話の冒頭を台本に沿って生成する
必要があるため この部分→
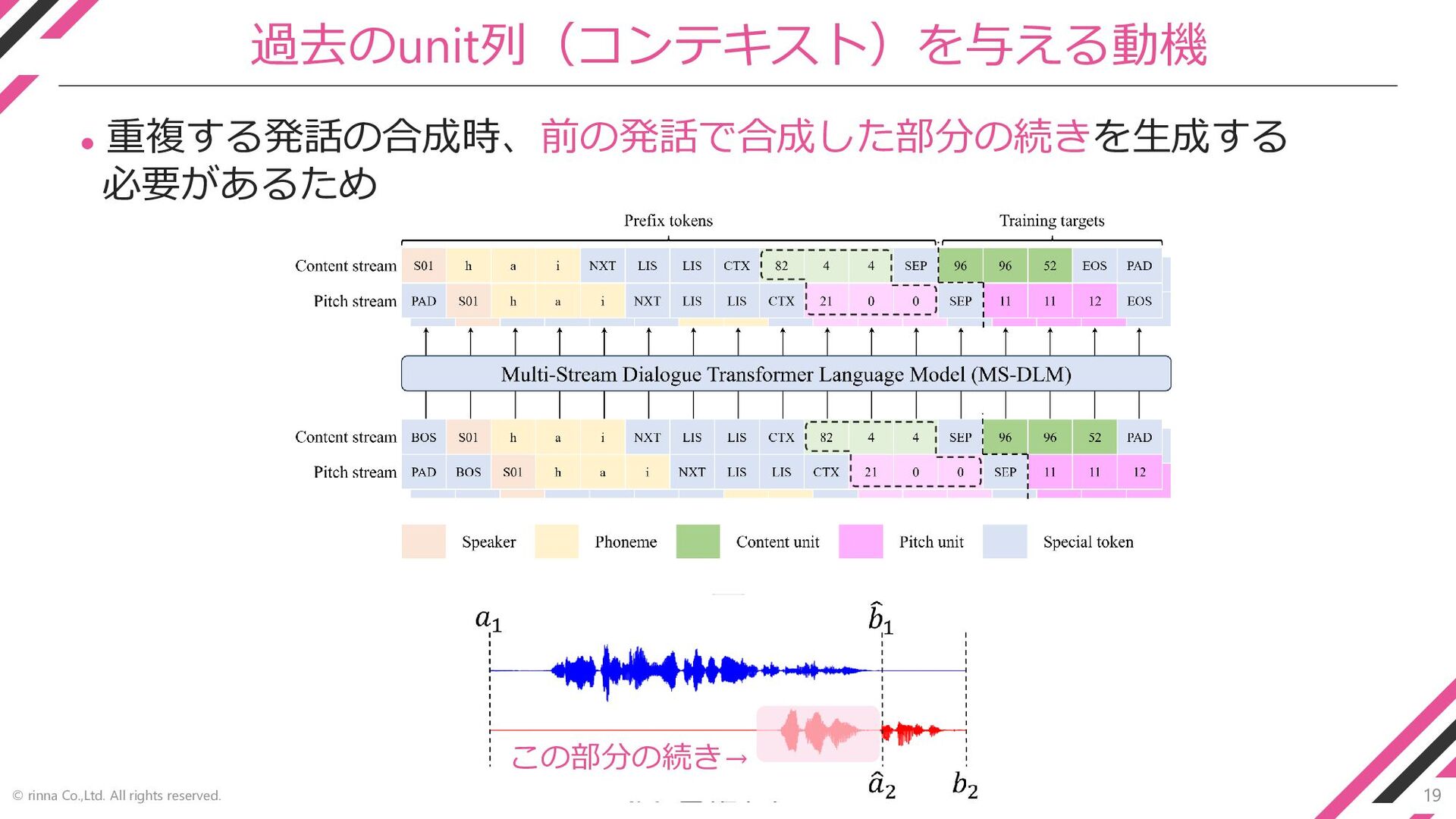
19 © rinna Co.,Ltd. All rights reserved. 過去のunit列(コンテキスト)を与える動機 ⚫ 重複する発話の合成時、前の発話で合成した部分の続きを生成する
必要があるため この部分の続き→
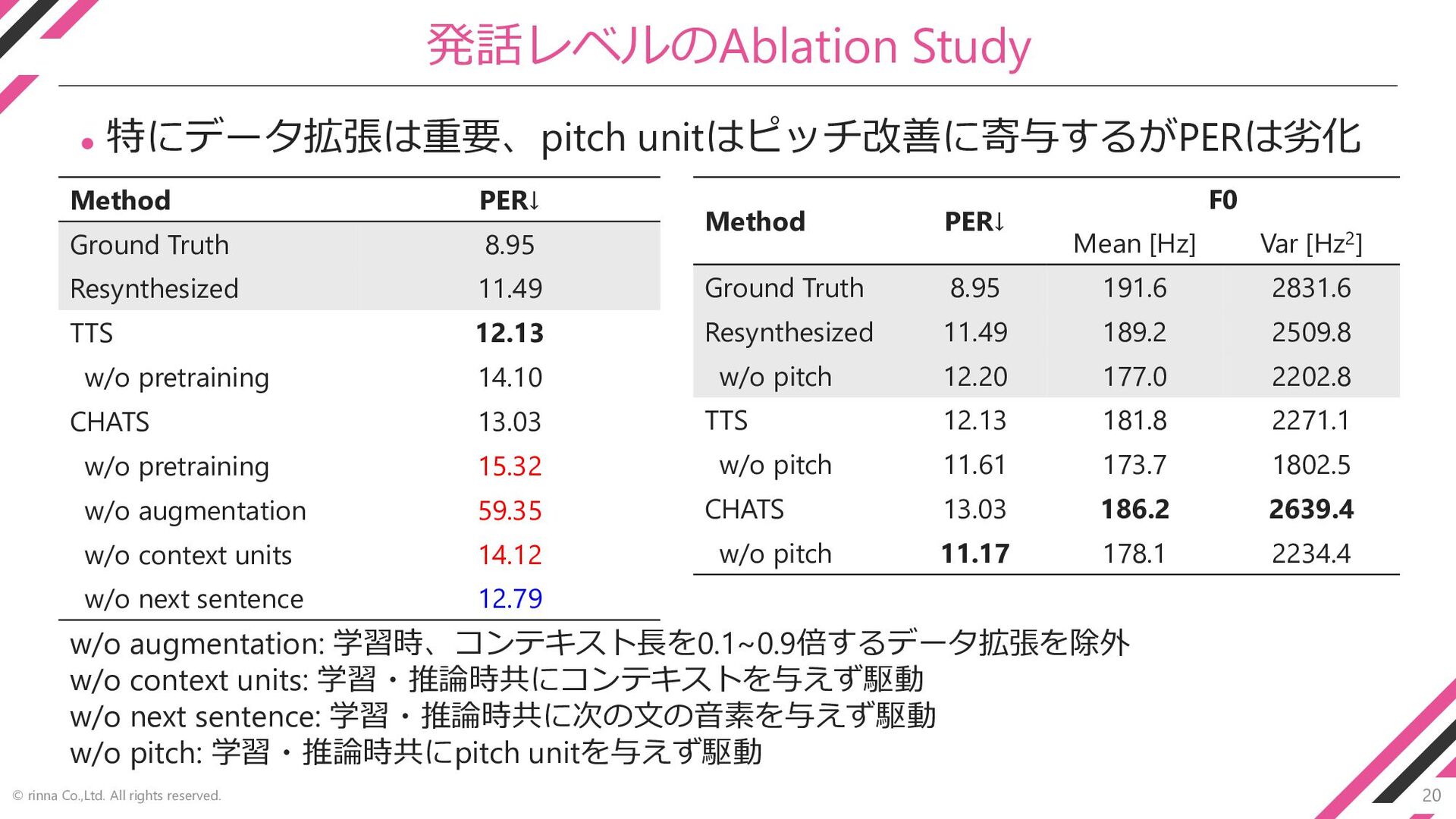
20 © rinna Co.,Ltd. All rights reserved. 発話レベルのAblation Study ⚫
特にデータ拡張は重要、pitch unitはピッチ改善に寄与するがPERは劣化 Method PER↓ Ground Truth 8.95 Resynthesized 11.49 TTS 12.13 w/o pretraining 14.10 CHATS 13.03 w/o pretraining 15.32 w/o augmentation 59.35 w/o context units 14.12 w/o next sentence 12.79 w/o augmentation: 学習時、コンテキスト長を0.1~0.9倍するデータ拡張を除外 w/o context units: 学習・推論時共にコンテキストを与えず駆動 w/o next sentence: 学習・推論時共に次の文の音素を与えず駆動 w/o pitch: 学習・推論時共にpitch unitを与えず駆動 Method PER↓ F0 Mean [Hz] Var [Hz2] Ground Truth 8.95 191.6 2831.6 Resynthesized 11.49 189.2 2509.8 w/o pitch 12.20 177.0 2202.8 TTS 12.13 181.8 2271.1 w/o pitch 11.61 173.7 1802.5 CHATS 13.03 186.2 2639.4 w/o pitch 11.17 178.1 2234.4
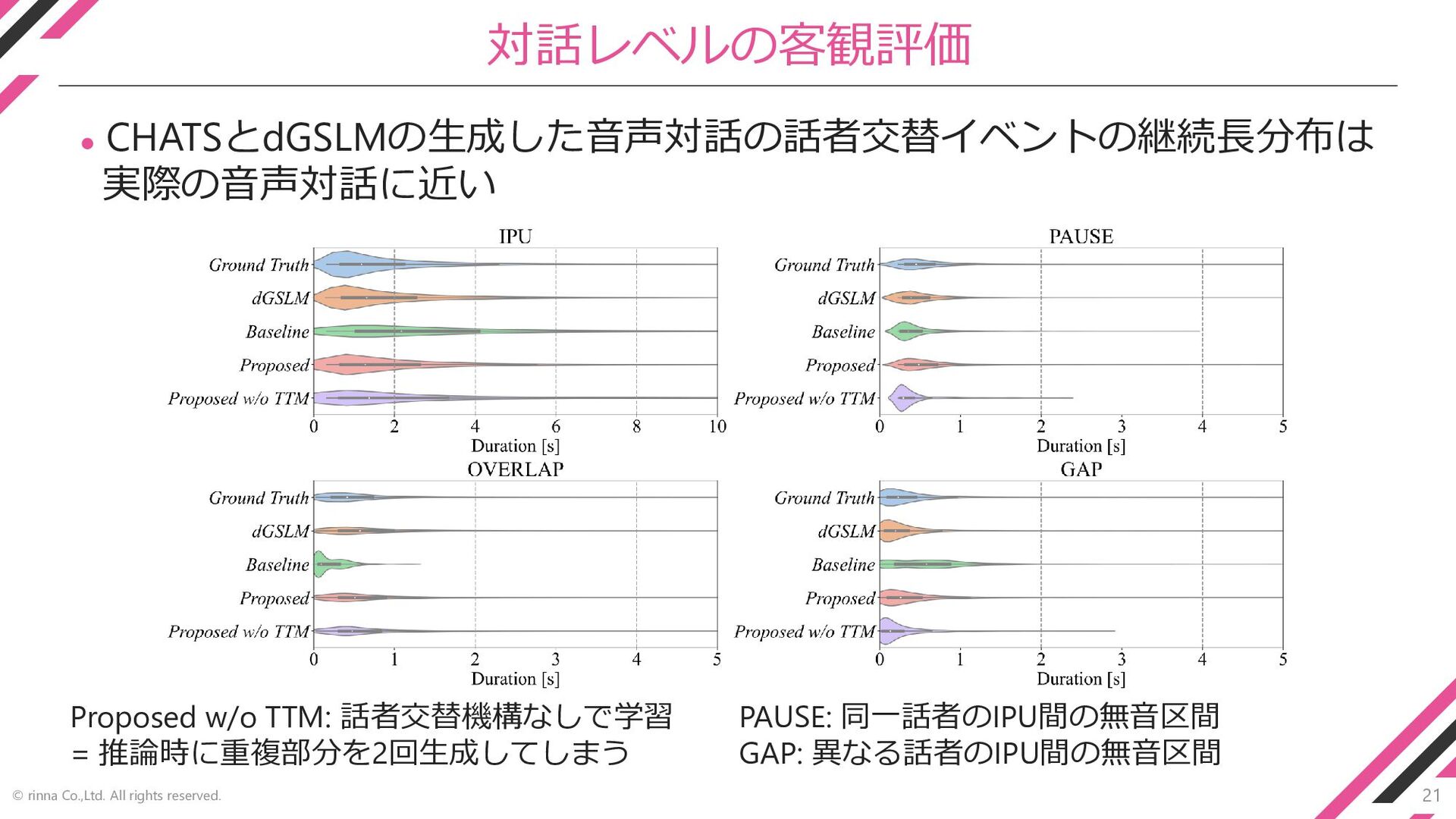
21 © rinna Co.,Ltd. All rights reserved. 対話レベルの客観評価 ⚫ CHATSとdGSLMの生成した音声対話の話者交替イベントの継続長分布は
実際の音声対話に近い Proposed w/o TTM: 話者交替機構なしで学習 = 推論時に重複部分を2回生成してしまう PAUSE: 同一話者のIPU間の無音区間 GAP: 異なる話者のIPU間の無音区間
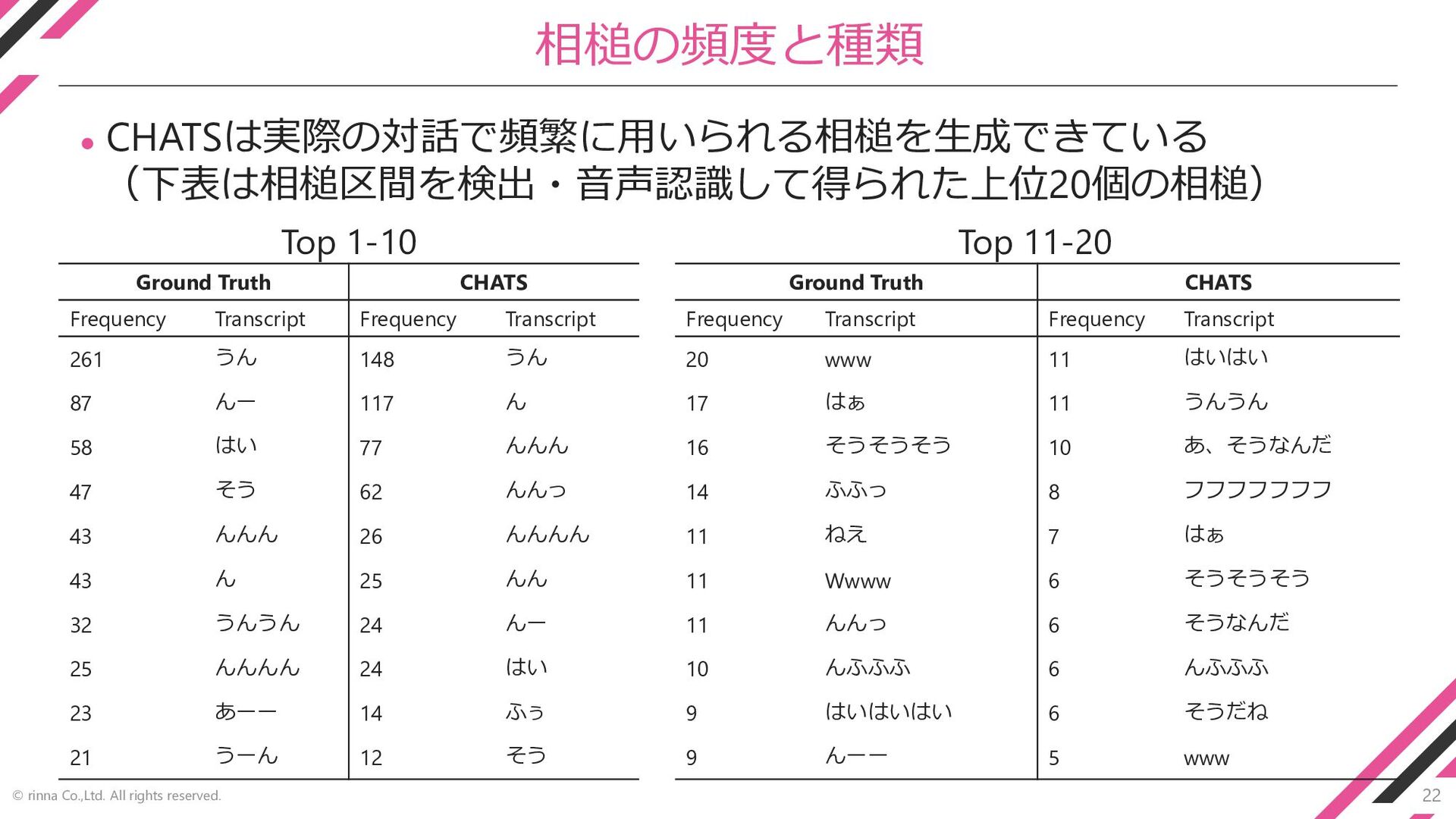
22 © rinna Co.,Ltd. All rights reserved. 相槌の頻度と種類 ⚫ CHATSは実際の対話で頻繁に用いられる相槌を生成できている
(下表は相槌区間を検出・音声認識して得られた上位20個の相槌) Ground Truth CHATS Frequency Transcript Frequency Transcript 261 うん 148 うん 87 んー 117 ん 58 はい 77 んんん 47 そう 62 んんっ 43 んんん 26 んんんん 43 ん 25 んん 32 うんうん 24 んー 25 んんんん 24 はい 23 あーー 14 ふぅ 21 うーん 12 そう Ground Truth CHATS Frequency Transcript Frequency Transcript 20 www 11 はいはい 17 はぁ 11 うんうん 16 そうそうそう 10 あ、そうなんだ 14 ふふっ 8 フフフフフフフ 11 ねえ 7 はぁ 11 Wwww 6 そうそうそう 11 んんっ 6 そうなんだ 10 んふふふ 6 んふふふ 9 はいはいはい 6 そうだね 9 んーー 5 www Top 1-10 Top 11-20
23 © rinna Co.,Ltd. All rights reserved. 主観評価に用いた評価基準 ⚫ 友人同士が雑談している次の音声をヘッドホンで聴き、その品質を以下
の3つの基準で評価してください。各項目は1(悪い)から5(良い)の5 段階で評価してください。各基準について評価するとき、他の基準は考 慮に入れないでください。例えば、意味の分からない内容でも人間らし い掛け合いであった場合、対話の自然性の値は高く評価してください。 ◆ 対話の自然性 (Dialogue Naturalness): 相槌や笑いが適切に挿入され人間らしい 掛け合いになっているか、適切なタイミングで話し手と聞き手が切り替わって いるか、会話の流れはスムーズか ◆ 有意味性 (Meaningfulness): 対話の内容に意味があり、言っていることを理解す ることができるか ◆ 音質 (Sound Quality): 音がクリアであり、聞き取りやすいか
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}