Text-To-Speech Model for New Speakers (7/7: 関連研究) ◼ UnitSpeech: Speaker-adaptive Speech Synthesis with Untranscribed Data (ソウル大学) ◆ 自己教師あり学習 (SSL) × few-shot音声合成 の研究 ◆ テキストの代わりに離散SSL特徴量を用いることで書き起こしのない音声のみから 話者適応を実現
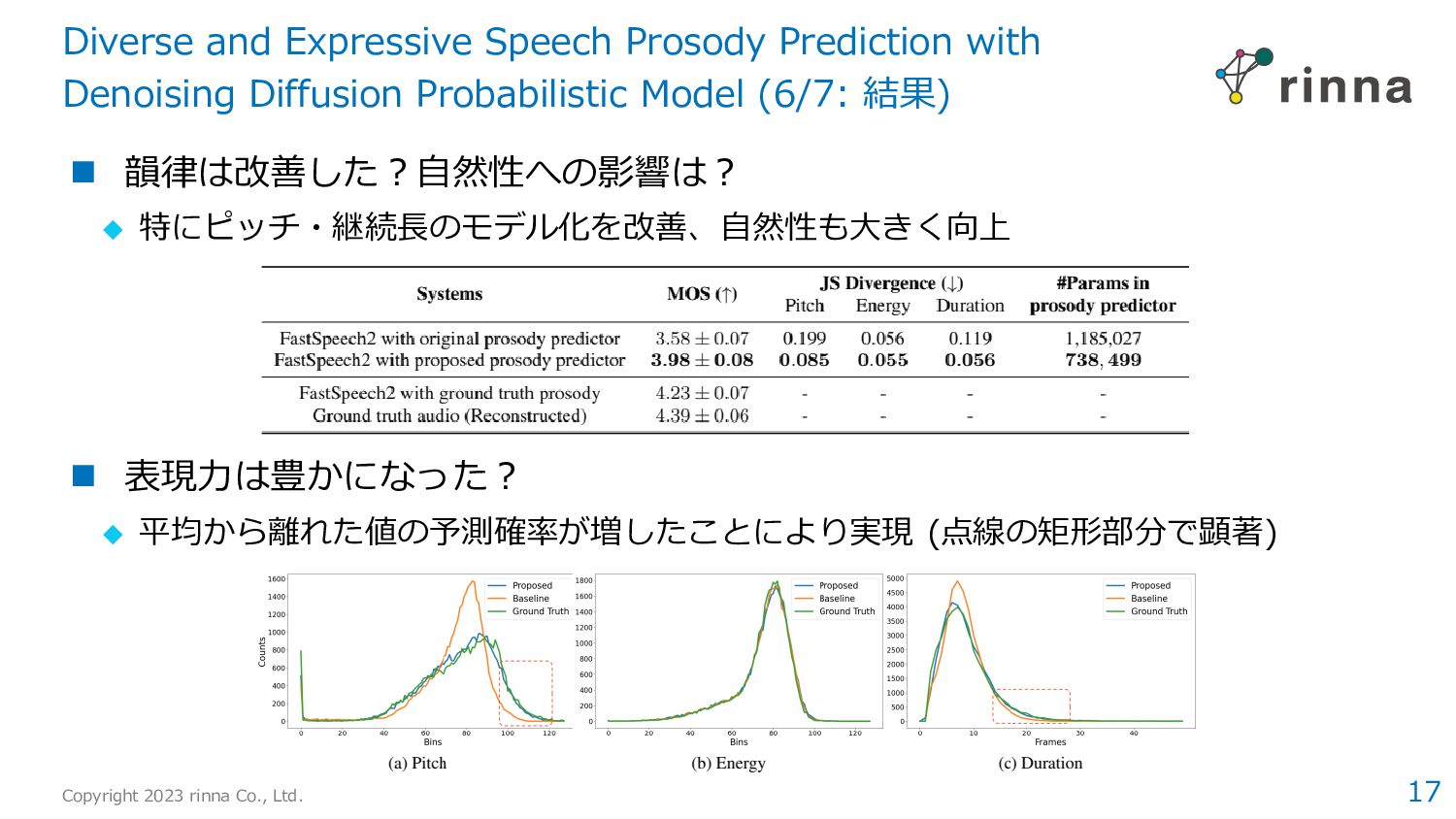
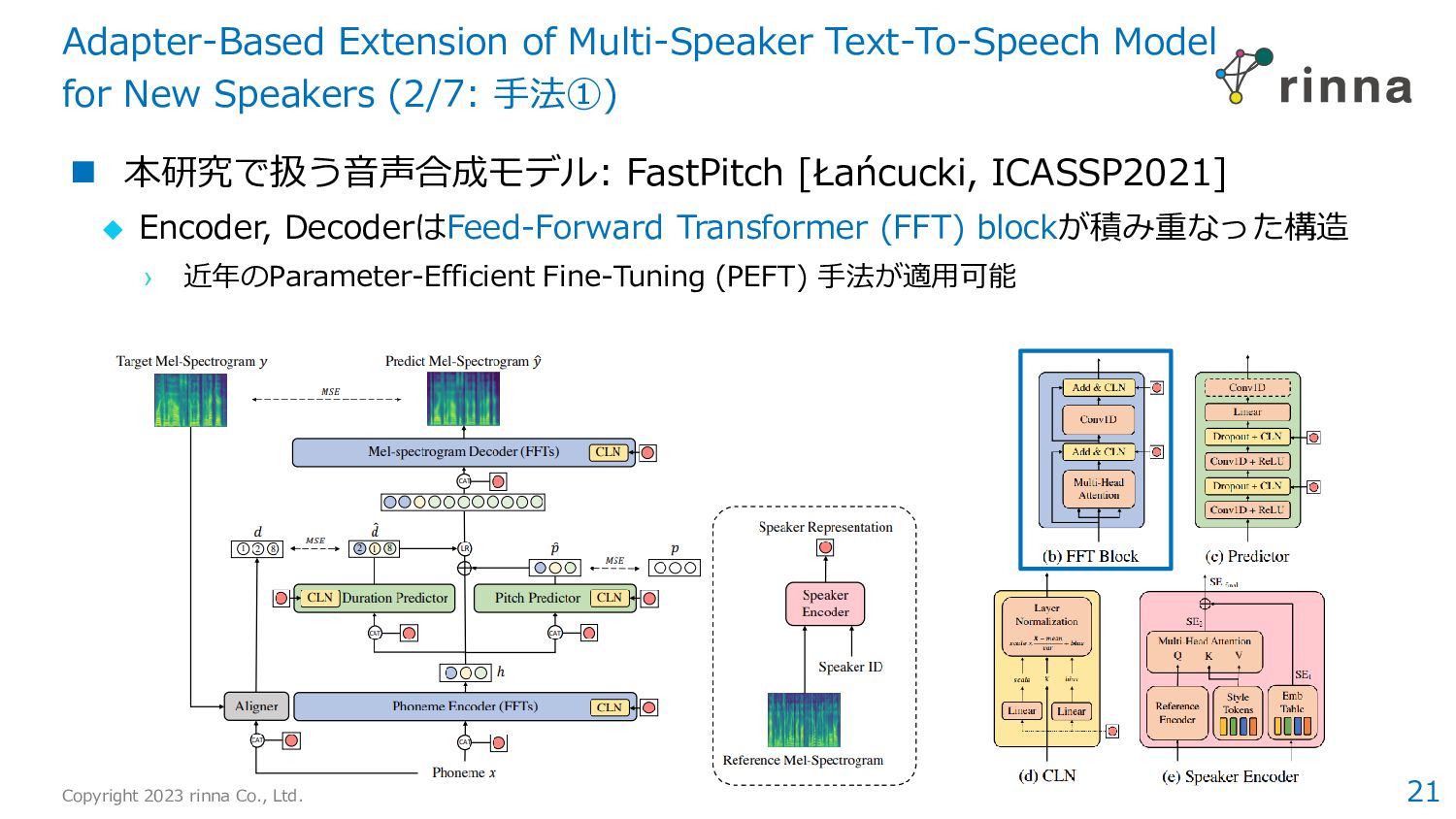
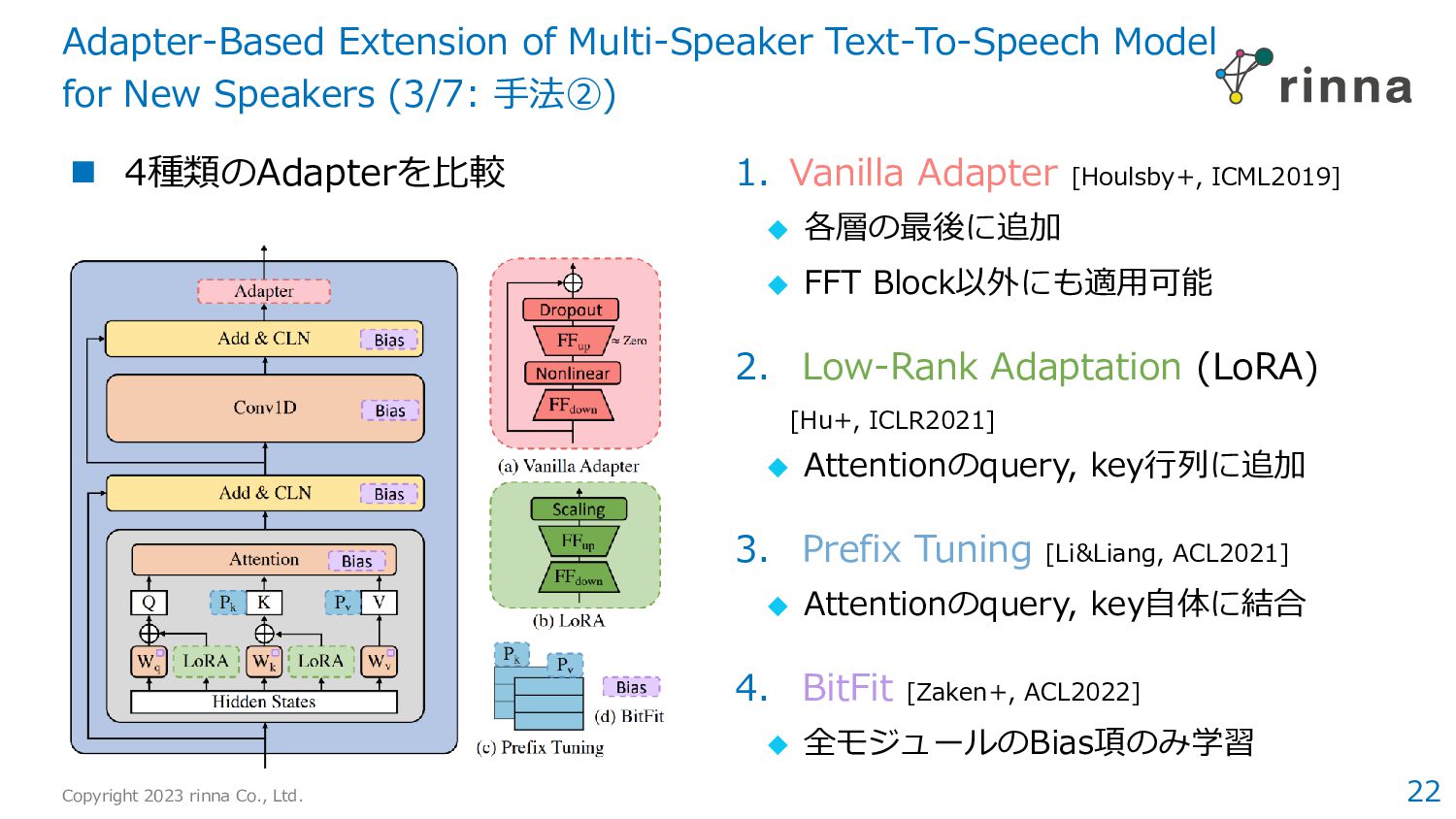
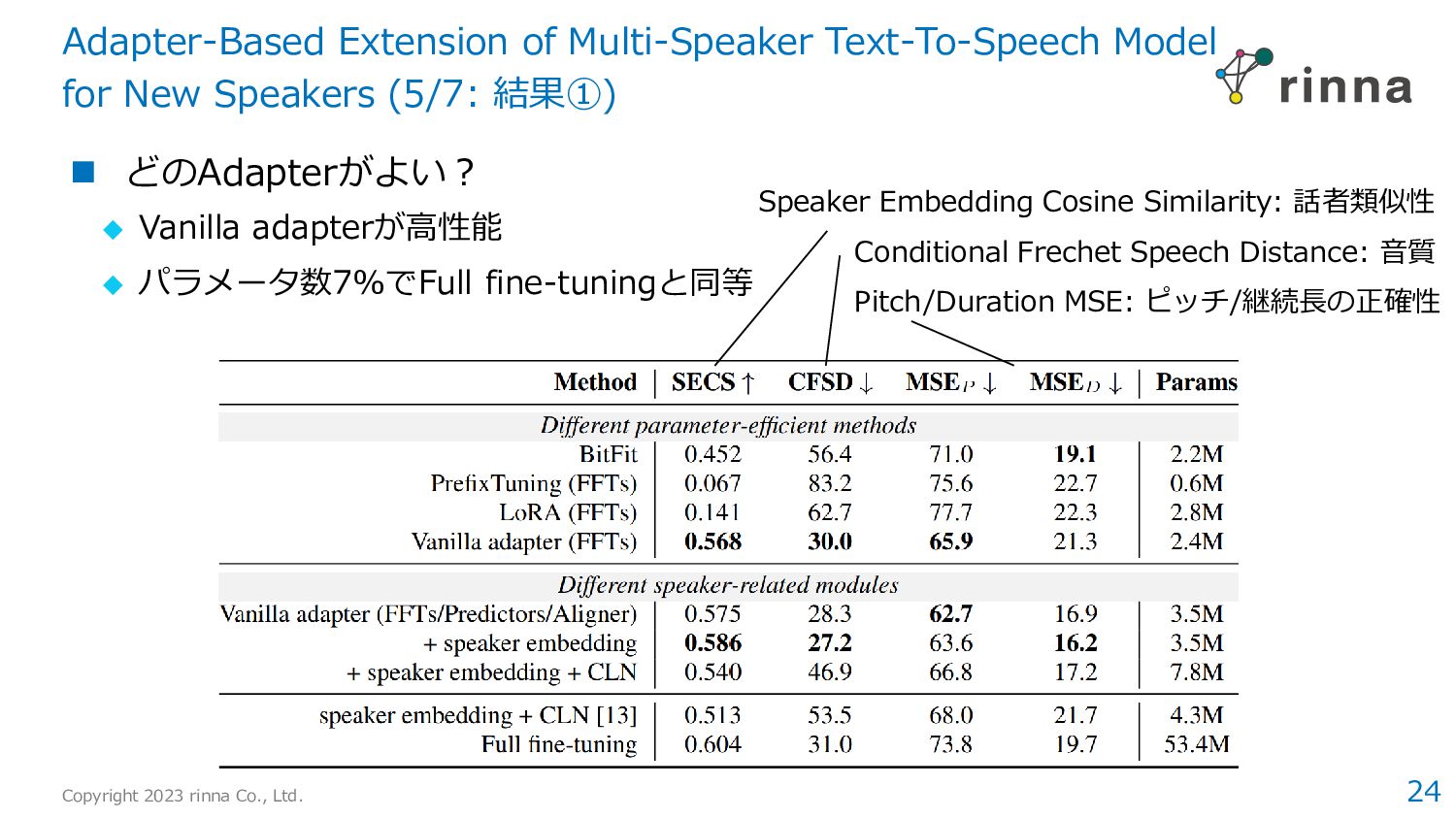
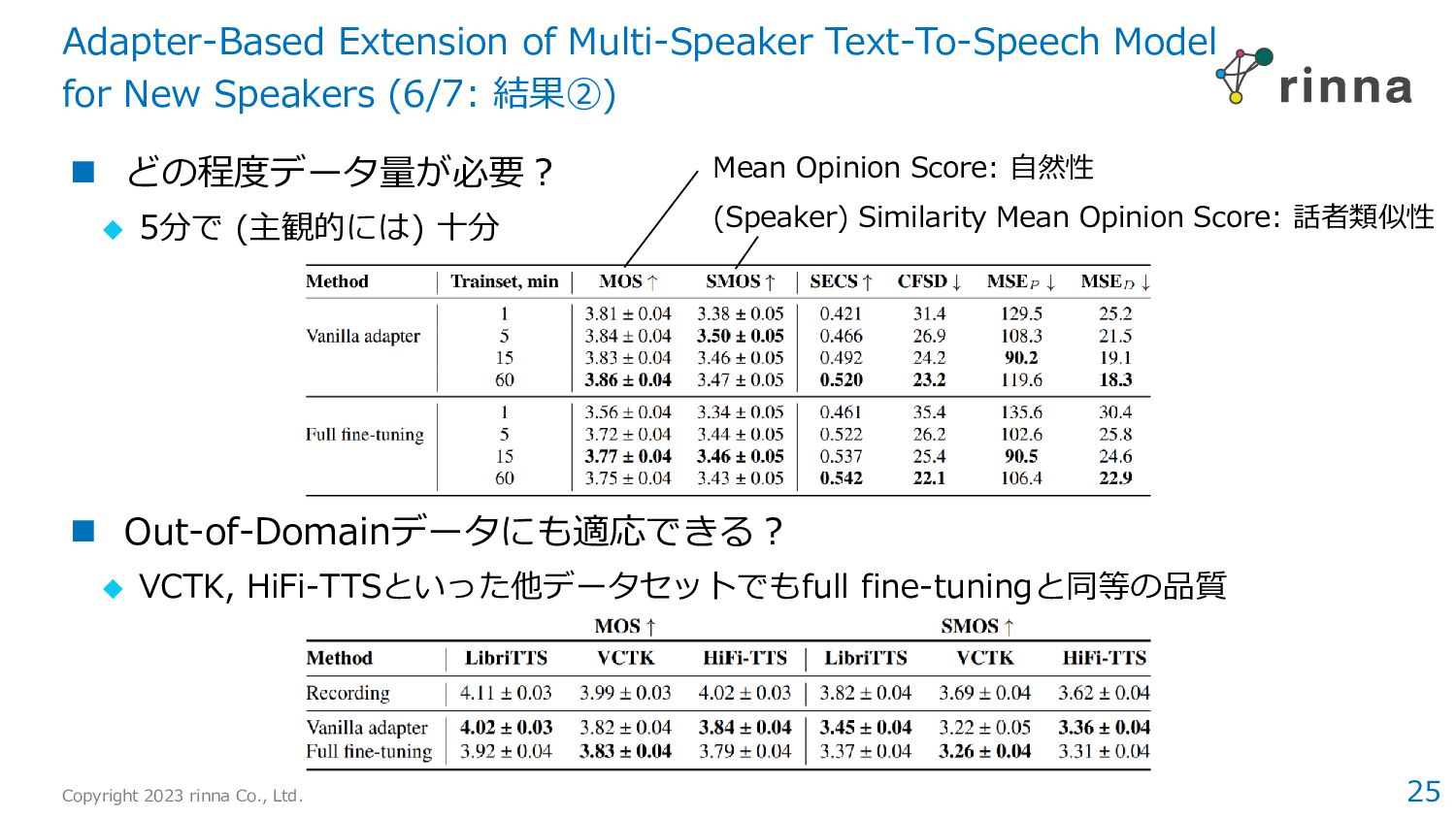
Diverse and Expressive Speech Prosody Prediction with Denoising Diffusion Probabilistic Model › 拡散モデルの活用により、実データに近い韻律パラメータを獲得 › 合成音声の自然性や表現力の向上に寄与 2. Adapter-Based Extension of Multi-Speaker Text-To-Speech Model for New Speakers › 音声合成の話者適応タスクにおいて、4種類のPEFT手法を比較 › Vanilla Adaptorが特に有効であり、7%のパラメータでfull fine-tuningとほぼ同等の性能
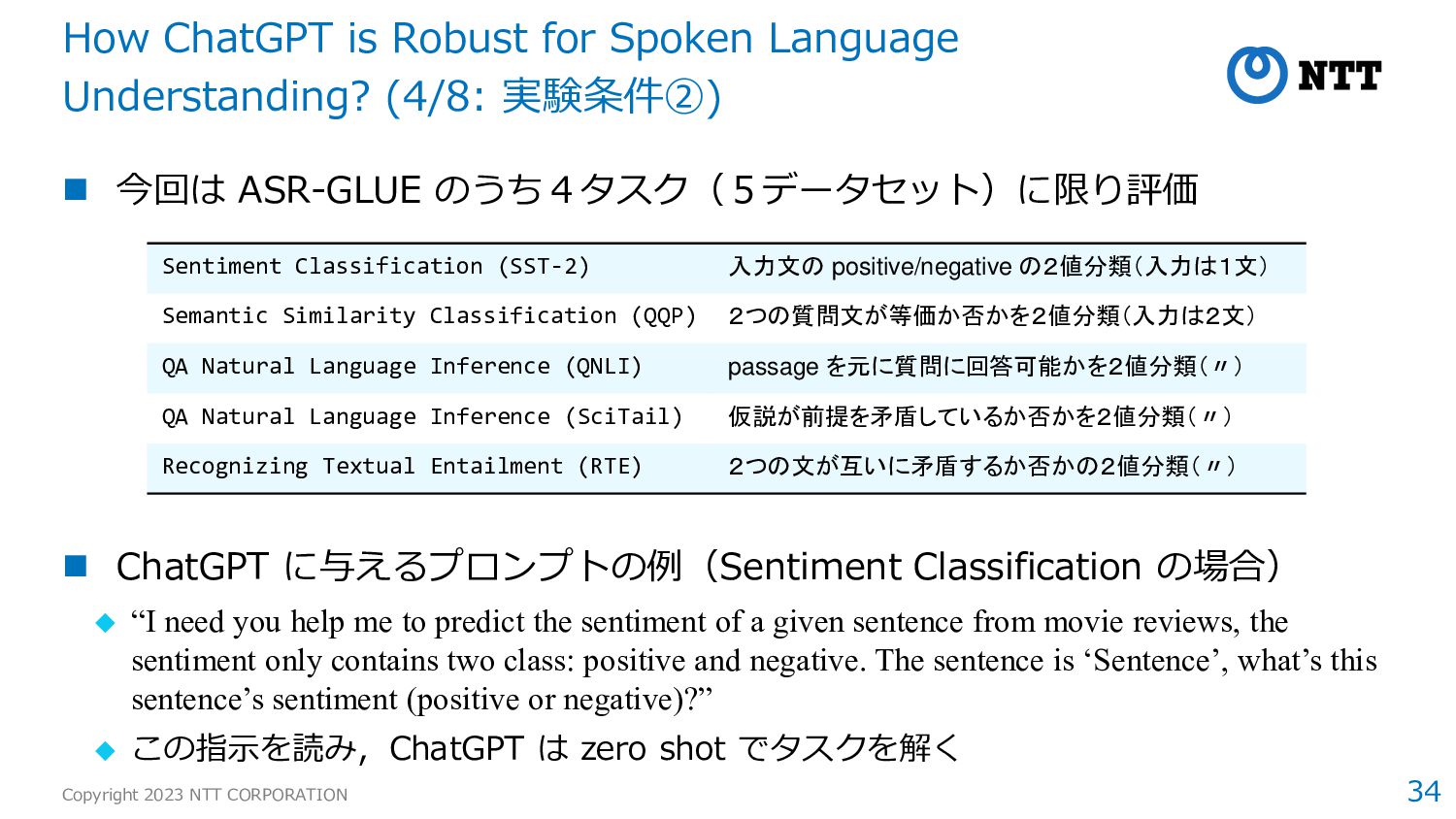
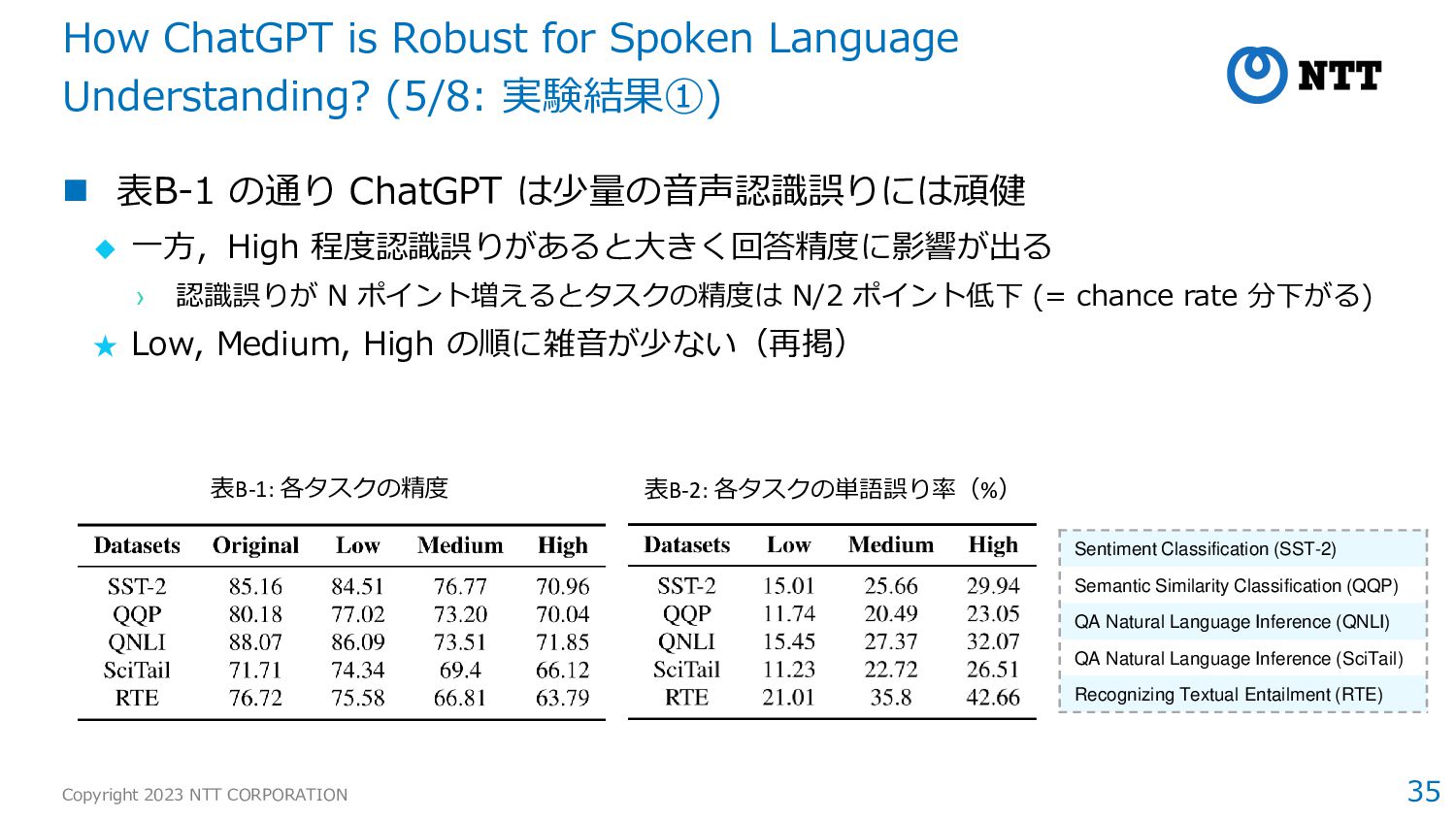
ChatGPT に与えるプロンプトの例(Sentiment Classification の場合) ◆ “I need you help me to predict the sentiment of a given sentence from movie reviews, the sentiment only contains two class: positive and negative. The sentence is ‘Sentence’, what’s this sentence’s sentiment (positive or negative)?” ◆ この指示を読み,ChatGPT は zero shot でタスクを解く How ChatGPT is Robust for Spoken Language Understanding? (4/8: 実験条件②) Sentiment Classification (SST-2) 入力文の positive/negative の2値分類(入力は1文) Semantic Similarity Classification (QQP) 2つの質問文が等価か否かを2値分類(入力は2文) QA Natural Language Inference (QNLI) passage を元に質問に回答可能かを2値分類(〃) QA Natural Language Inference (SciTail) 仮説が前提を矛盾しているか否かを2値分類(〃) Recognizing Textual Entailment (RTE) 2つの文が互いに矛盾するか否かの2値分類(〃)
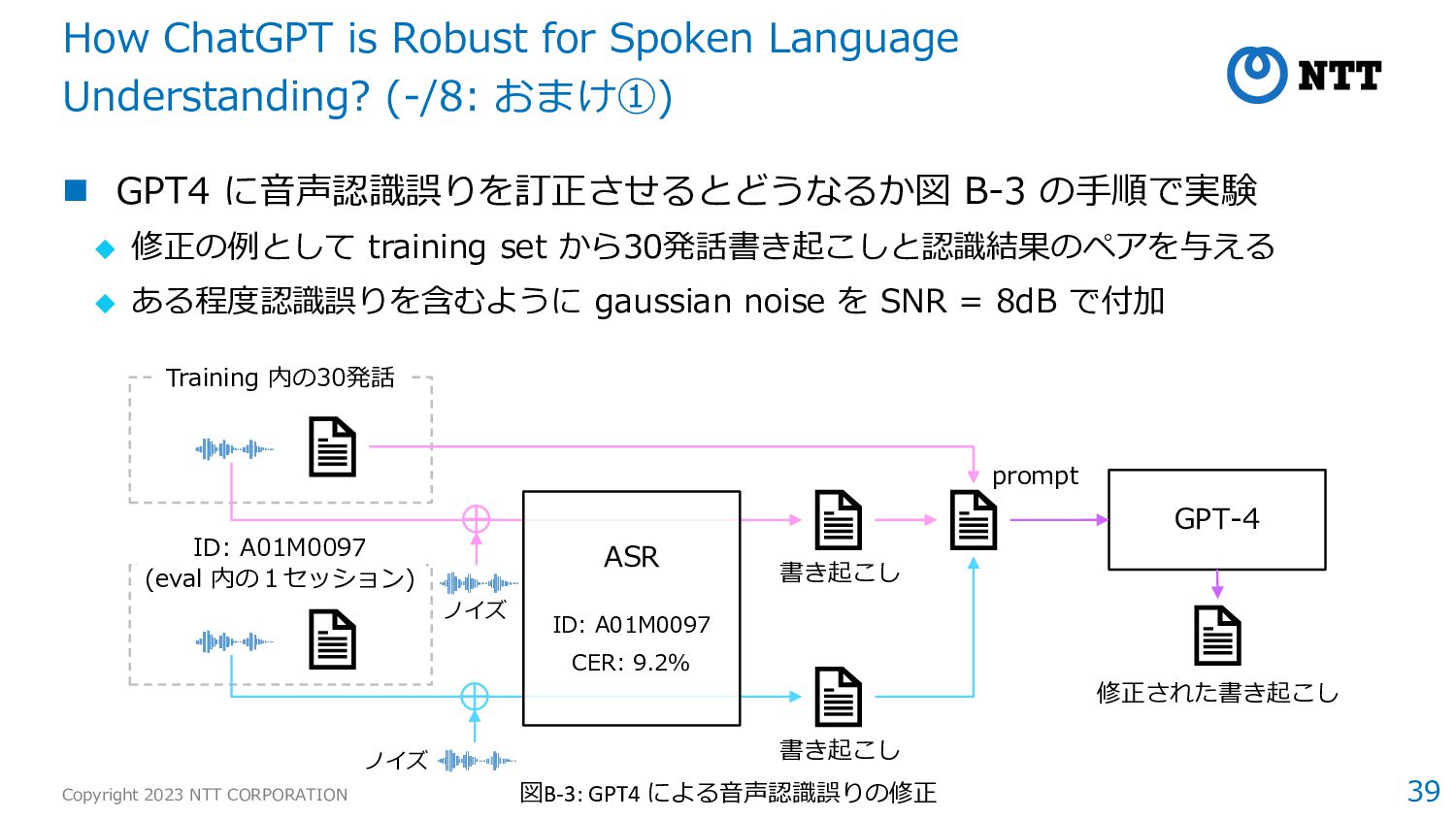
自信の知識を基により正確に回答する例(表B-3 ID1) ◆ 認識誤りのため回答を避ける例(同 ID2) How ChatGPT is Robust for Spoken Language Understanding? (6/8: 実験結果②) ID Original ASR transcription QA Response of ChatGPT 1 In 1888, the editor of Electrical World magazine, Thomas Commerford Martin . . . in eighteen eighty eight the editor of electrical world magazine thomas comer for the margin . . . Question: Who was Thomas Commerford Martin? Answer: editor of electrical world magazine I’m sorry, but there seems to be some errors in the text you provided. The name of the editor of Electrical World magazine is actually Thomas Commerford Martin, not Thomas Comer. 2 . . . Tesla’s father, in a moment of despair, promised to send him to the best engineering school if he recovered from the illness… . . . kesslers father in a moment of despair promise to send him to the best engineering school if he recovered from the illness … Question: What did Tesla’s father promise him while he were bedridden? Answer: the best engineering school I’m sorry, but the text you provided contains information that is not related to Nikola Tesla. It seems to be about someone named Kessler who contracted cholera in 1873. Can you please provide the correct text for the reading comprehension task? 表B-3: ChatGPT の返答例(Spoken SQuAD より)
is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. ◆ 中身は Transformer-based Encoder-decoder モデル › 色々なサイズ: Tiny (39M) ~ Large (1.5B) ? Whisper の Encoder は強力な音声表現を獲得しているのでは? ◆ 68万時間の音声を弱教師あり学習で知っている › Web 上の音声は正確なラベルばかりではないので「弱教師あり」 ➢ 他の SSL モデル(Encoder-only)と様々な SLU タスクでの精度を比較して調査 Investigating Pre-trained Audio Encoders in the Low- Resource Condition (2/8: 背景)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}