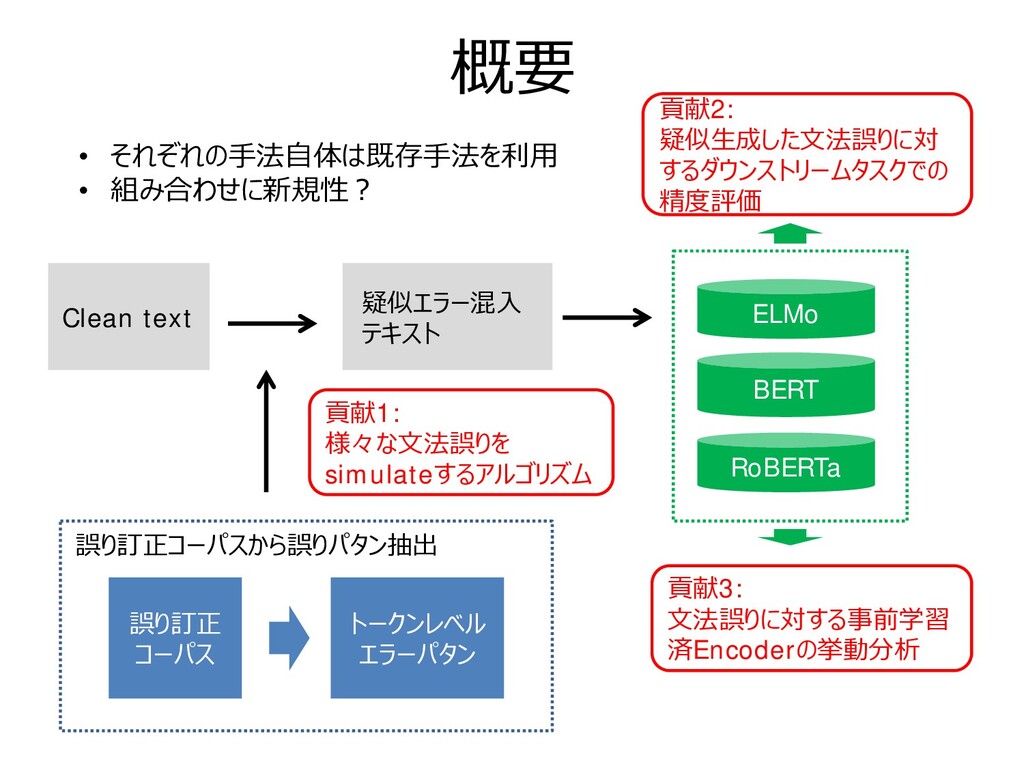
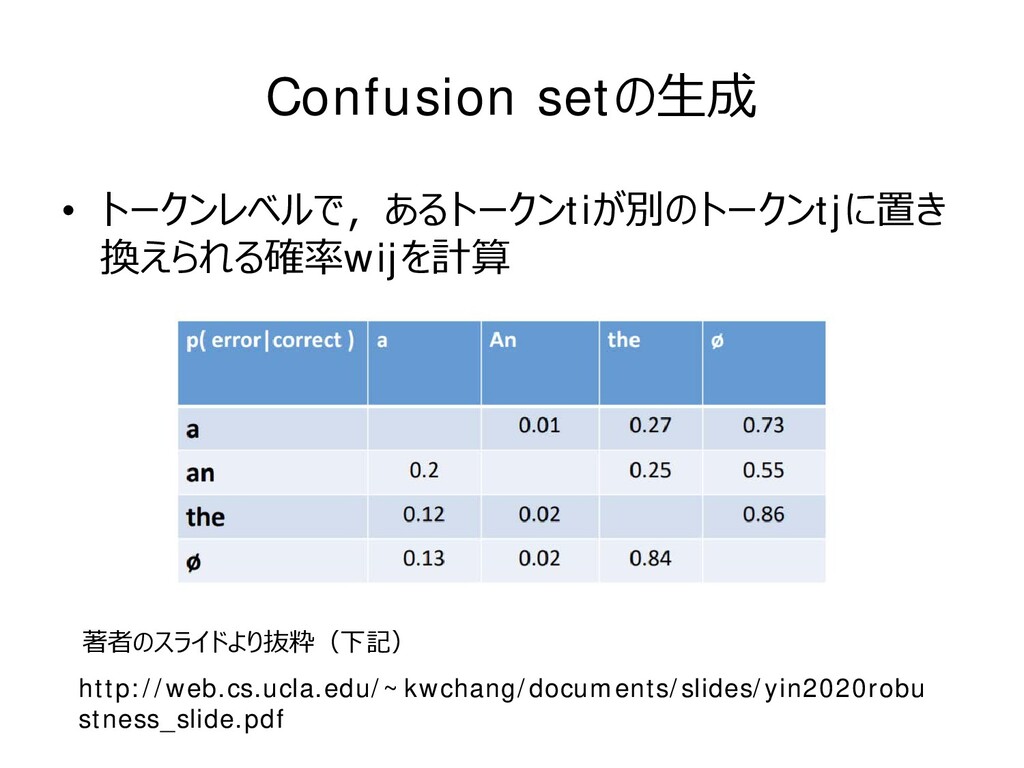
これを上位k個保持するのがbeam search Step2を次のいずれかの条件を満たすまで繰り返す – モデルの予測結果が変化する – 事前に指定した1文あたりの置き換え上限数に達する Step1の重要度について • 各単語を削除したときと削除しないときのラベルYの予測スコア の差が大 きい(正しいラベルの予測確率を下げる)ほど重要度が大きいと仮定し,す べての単語について下記を計算する Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment [Jin et al., AAAI2020]のアルゴリズムを利用
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
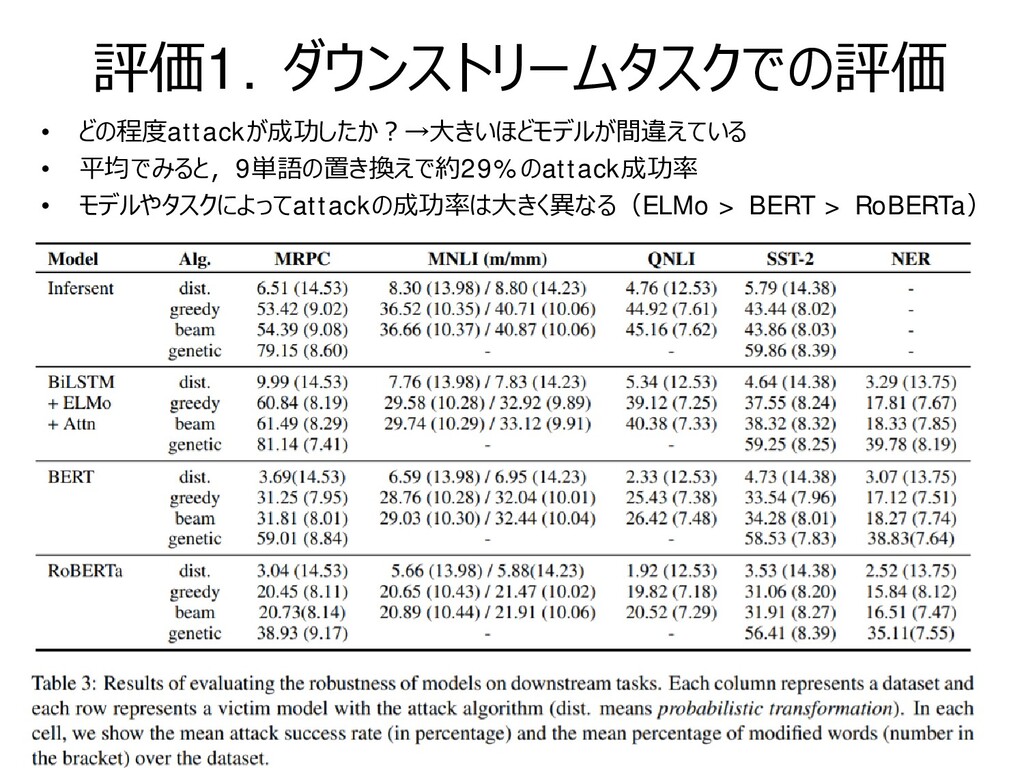
![Attackの成功確率と置き換え率 • 事前学習データ数が多いほど,ノイズにも頑健? – Electra [Clerk et al., ICLR2020]だとBERTから意味的に近い 負例をサンプリングしながら事前学習するので,さらに頑健そう](https://files.speakerdeck.com/presentations/6010d58c9480401dbc954b943fec7b2d/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}