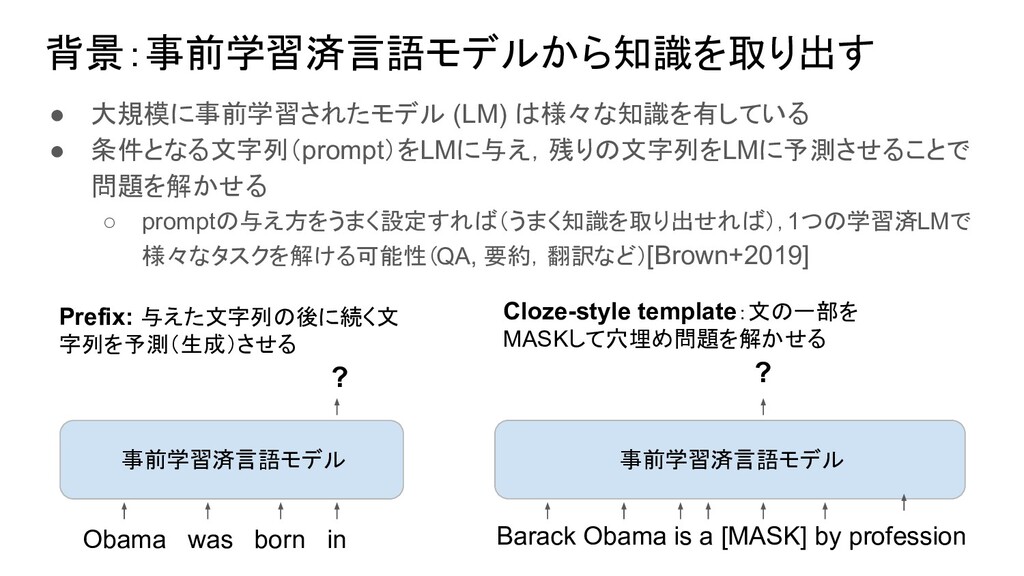
1つの学習済LMで 様々なタスクを解ける可能性(QA, 要約,翻訳など)[Brown+2019] 事前学習済言語モデル 事前学習済言語モデル Prefix: 与えた文字列の後に続く文 字列を予測(生成)させる Cloze-style template:文の一部を MASKして穴埋め問題を解かせる Obama was born in ? Barack Obama is a [MASK] by profession ?
x : subject, y: object, r: relation ◦ rに対応する自然言語表現 を人手で作成 (e.g., x is born in y) ◦ x, yには具体的なentityが入っている • LMから知識を取り出す際には,xに表層を入れ,yの表層を穴埋め問題として当てる問 題にする(固定の候補の中から最も確率が高いものを選択) ◦ Obama worked as a [MASK] 関係rを表す自然言語表現 をpromptと呼ぶ
= Intel Original prompt Generated prompts 事前学習済言語 モデル(LM) [MASK] = Microsoft [MASK] released the DirectX DirectX is created by [MASK] ポイント1: promptを自動生成 ポイント2: 良いpromptを選択 ・ ・ ・ ✔ ✖
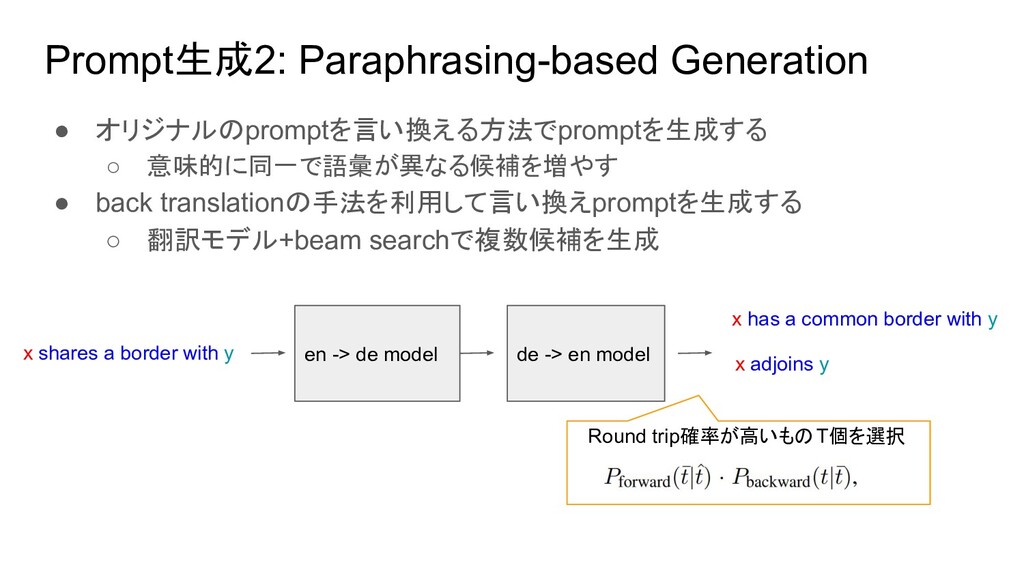
• subjectとobjectの間に含まれる文字列をpromptとして用いる Dependency-based Prompts • subjectとobjectのdependency pathで連結される文字列をpromptとして用いる 例:Barack Obama was born in Hawaii -> x was born in y 例:The capital of France is Paris -> capital of x is y
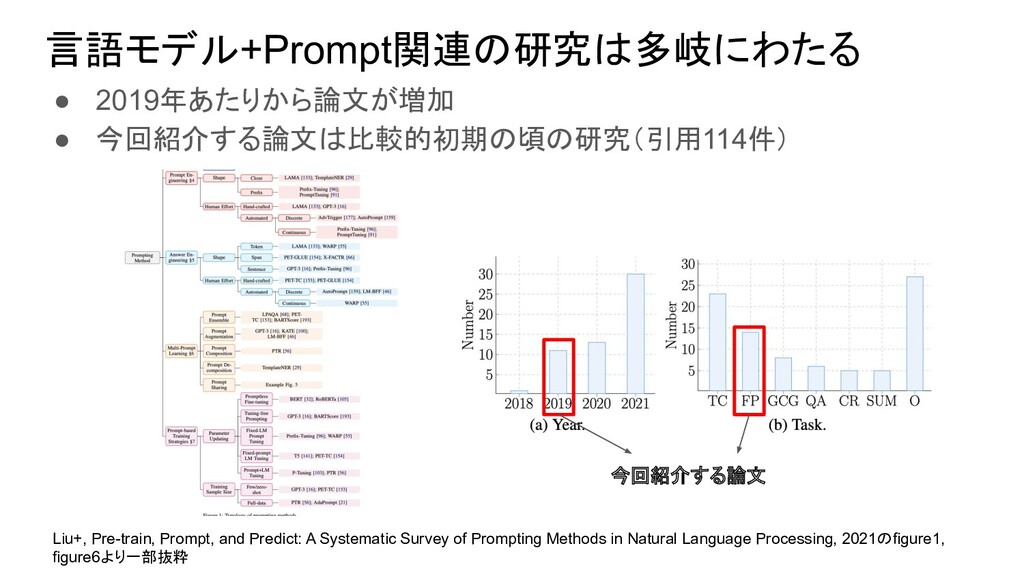
◦ promptの生成(search)を賢くする ▪ Shin+, AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts, 2020 ◦ promptを文字列ではなく潜在表現として表現する ▪ Qin+, Learning How to Ask: Querying LMs with Mixtures of Soft Prompts, 2021 感想 • シンプルな手法で分析をたくさん行っている研究 • Prompt+LMでZero-shotやfew-shotの性能を検証する研究は今後も増えそう ◦ Wei+, Finetuned language models are zero-shot learners, 2021
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![本研究で扱う知識の対象と問題設定 • <x, r, y>というtriple形式で表現された知識を対象とする [Petroni et al., 2019] ◦](https://files.speakerdeck.com/presentations/f5b131ef8560448ea214007dc9f843b3/slide_6.jpg){kind=link}
{kind=link}
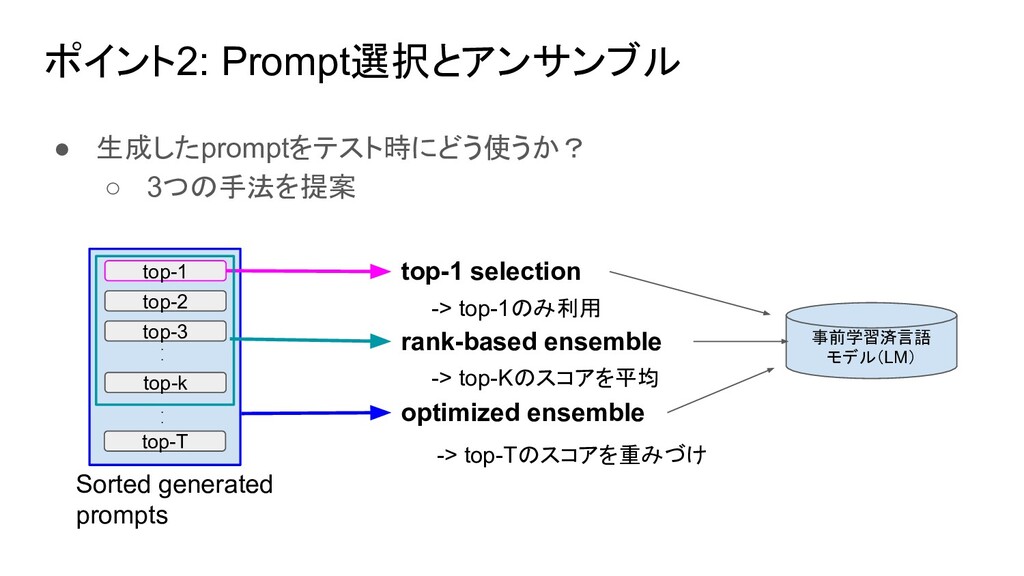
![本研究の目的とポイント 目的:LMを用いてground-truthのyを予測するための良いpromptを自動的に生成・選択 DirectX is developed by [MASK] 事前学習済言語 モデル(LM) [MASK]](https://files.speakerdeck.com/presentations/f5b131ef8560448ea214007dc9f843b3/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
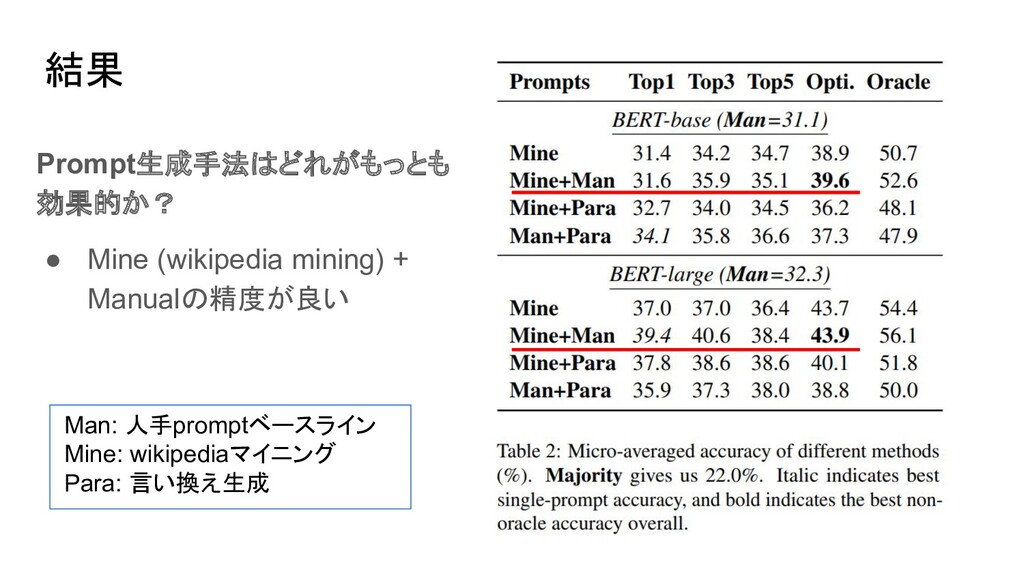{kind=link}
{kind=link}
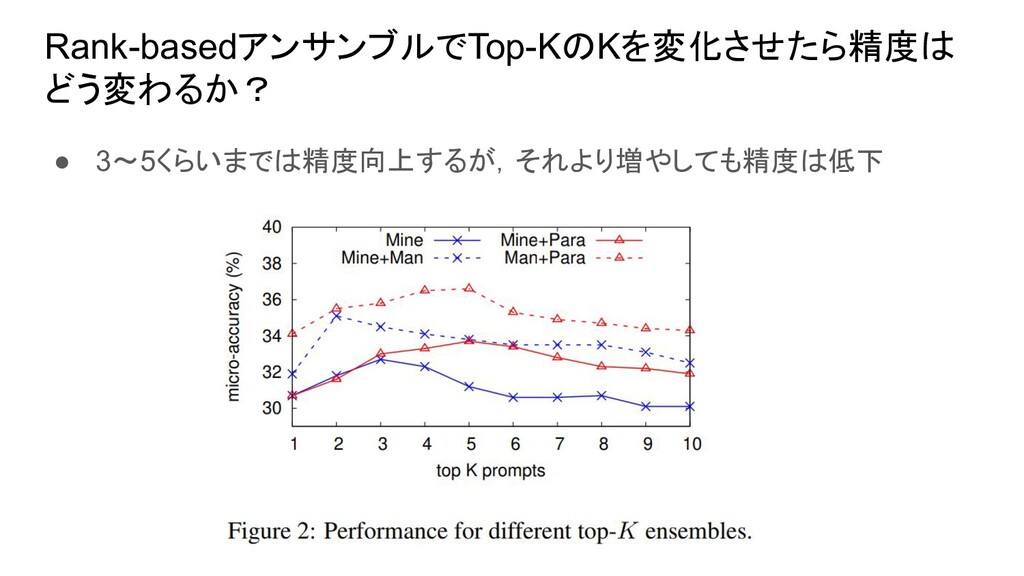{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}