Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
SNLP2019.pdf
Search
kichi
September 25, 2019
420
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
SNLP2019.pdf
kichi
September 25, 2019
More Decks by kichi
See All by kichi
snlp2024
kichi
0
410
snlp2021
kichi
0
510
snlp2020
kichi
0
220
snlp2018
kichi
0
240
Featured
See All Featured
A designer walks into a library…
pauljervisheath
211
24k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
410
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
910
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
310
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.3k
Fireside Chat
paigeccino
42
4k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
Statistics for Hackers
jakevdp
799
230k
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
470
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
180
A better future with KSS
kneath
240
18k
Transcript
Mask-Predict: Parallel Decoding of Conditional Masked Language Models (EMNLP2019) 2019/9/27
紹介者:斉藤いつみ 図表は論文より抜粋
概要 • Encoder-decoderモデルのdecoderは通常左から順に一 単語ずつ生成する自己回帰型 (Autoregressive : AR) • 本研究では,すべての時刻の出力を同時に予測する非 自己回帰型
(Non-autoregressive :NAR)の新しいモデルを 提案 • 翻訳タスクの評価において,従来のNARモデルの中で最 も良い精度 • ARモデルに比べて精度は少し劣るが,高速にデコーディ ング可能
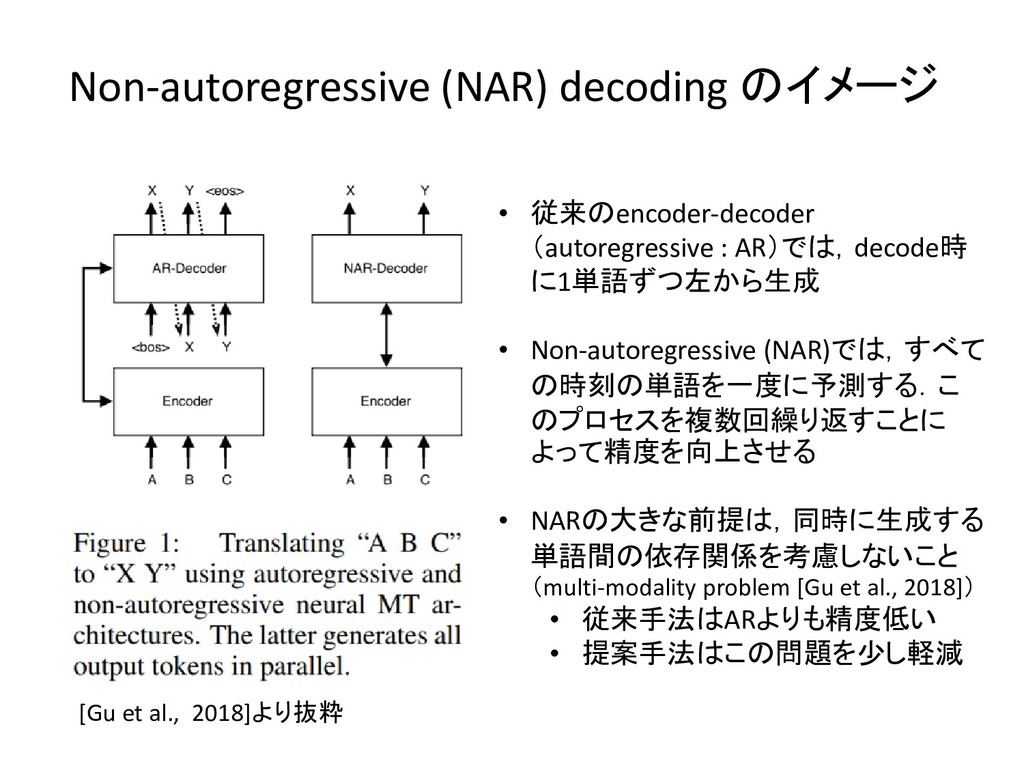
Non-autoregressive (NAR) decoding のイメージ • 従来のencoder-decoder (autoregressive : AR)では,decode時 に1単語ずつ左から生成
• Non-autoregressive (NAR)では,すべて の時刻の単語を一度に予測する.こ のプロセスを複数回繰り返すことに よって精度を向上させる • NARの大きな前提は,同時に生成する 単語間の依存関係を考慮しないこと (multi-modality problem [Gu et al., 2018]) • 従来手法はARよりも精度低い • 提案手法はこの問題を少し軽減 [Gu et al., 2018]より抜粋
Conditional Masked Language Models (CMLM) • ソーステキスト とターゲットテキストの一部 が与 えられたとき,残りのターゲットテキスト
の生成確 率 を求める.ここで ターゲットテキストの長さNは次のようになる Transformer encoder Transformer decoder <MASK> <MASK> <MASK>
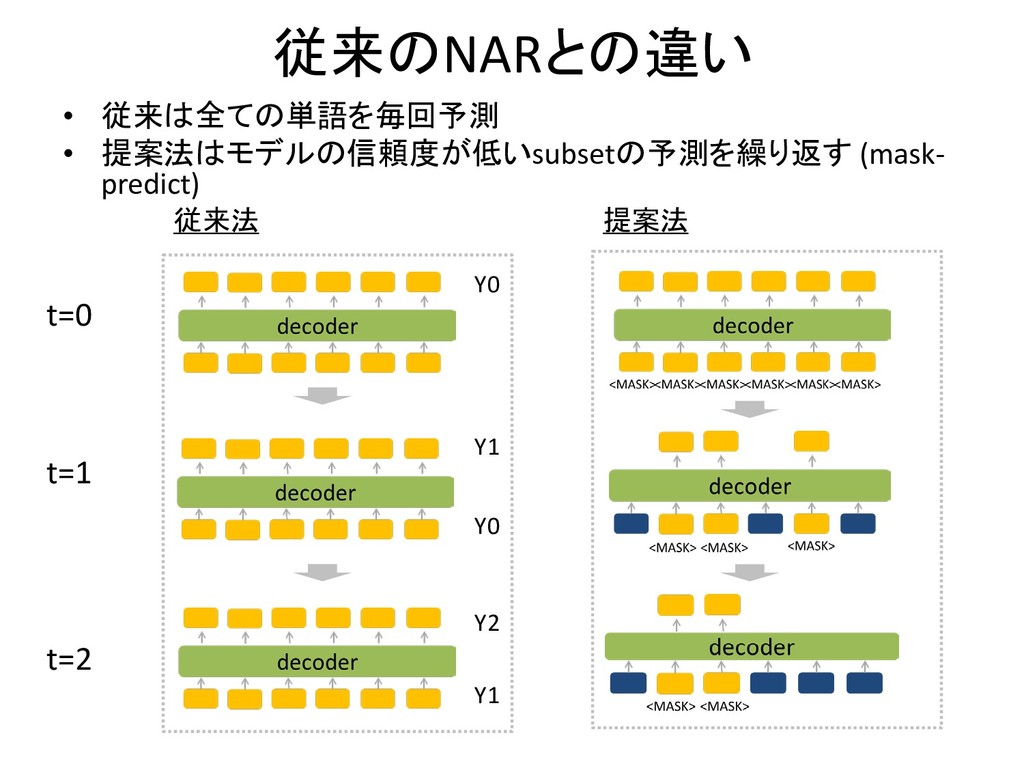
従来のNARとの違い • 従来は全ての単語を毎回予測 • 提案法はモデルの信頼度が低いsubsetの予測を繰り返す (mask- predict) t=0 t=1 t=2
従来法 提案法 Y0 Y1 Y0 Y2 Y1
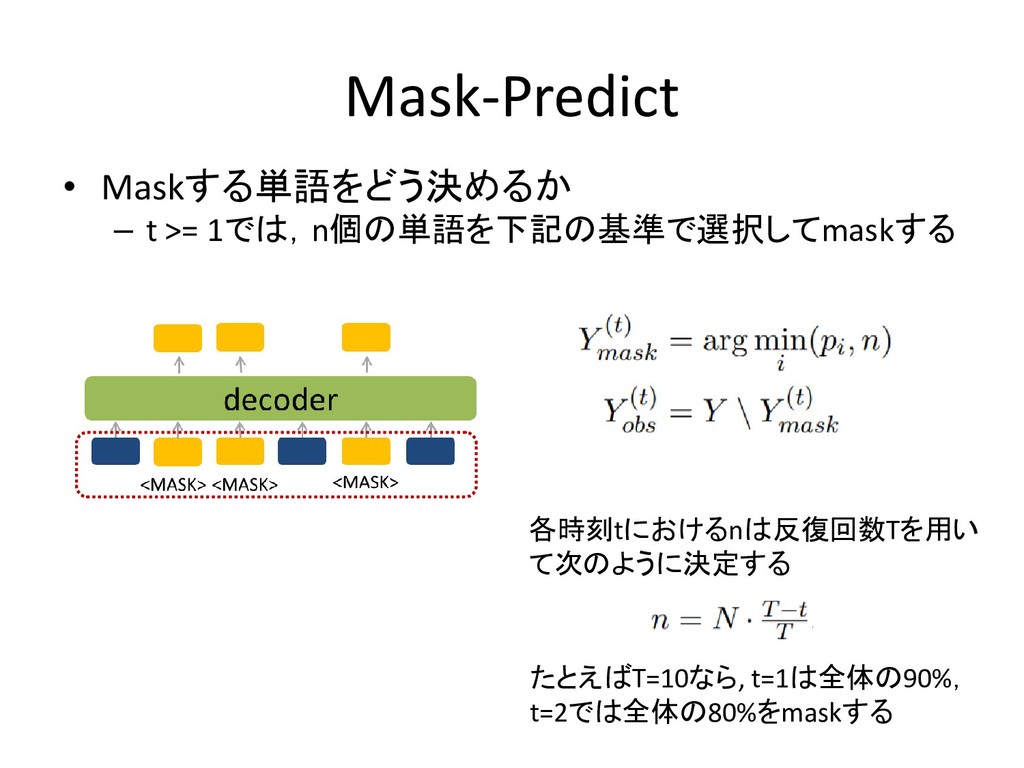
Mask-Predict • Maskする単語をどう決めるか – t >= 1では,n個の単語を下記の基準で選択してmaskする 各時刻tにおけるnは反復回数Tを用い て次のように決定する たとえばT=10なら,
t=1は全体の90%, t=2では全体の80%をmaskする
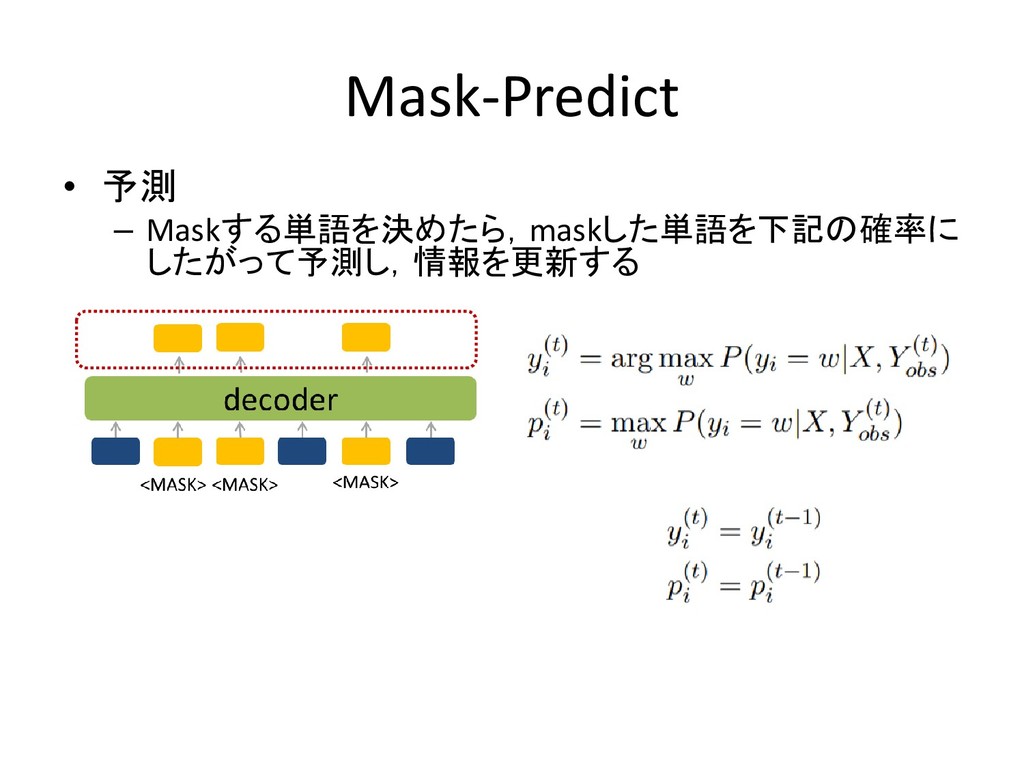
Mask-Predict • 予測 – Maskする単語を決めたら,maskした単語を下記の確率に したがって予測し,情報を更新する
Mask-predictの例 • t=0では繰り返しや文法的に不自然な箇所が多いが,反復 回数を重ねるごとに解消されている
ターゲットの長さ予測 • NARでは,ターゲットの長さをあらかじめ決めておく必要がある • 本手法では,Encoder側に長さを予測するための特殊トークン を追加 (BERTにおける[CLS]トークンに似た形) テスト時は,長さの候補上位l件を並列にデコーディングして,その結果を 下記のスコアで比較しもっともよい候補を選択する
Model Distillation • 過去の研究において,ARモデルの出力を教師として学習を行う方 法が精度向上に寄与することが知られている [Gu et al., 2018], [Stern
et al., 2019] • 今回の論文でも,ARモデルを事前に学習し,その結果を教師とし て学習を行う(この方法の効果は実験で確認している) • 具体的には,下記の式のα=1として,ARモデルの出力を教師とす る部分のみを用いている(下記の式はオリジナルのsentence-level knowledge distillation [kim and Rush., 2016]) Auto regressiveモデルの出力を教師とする
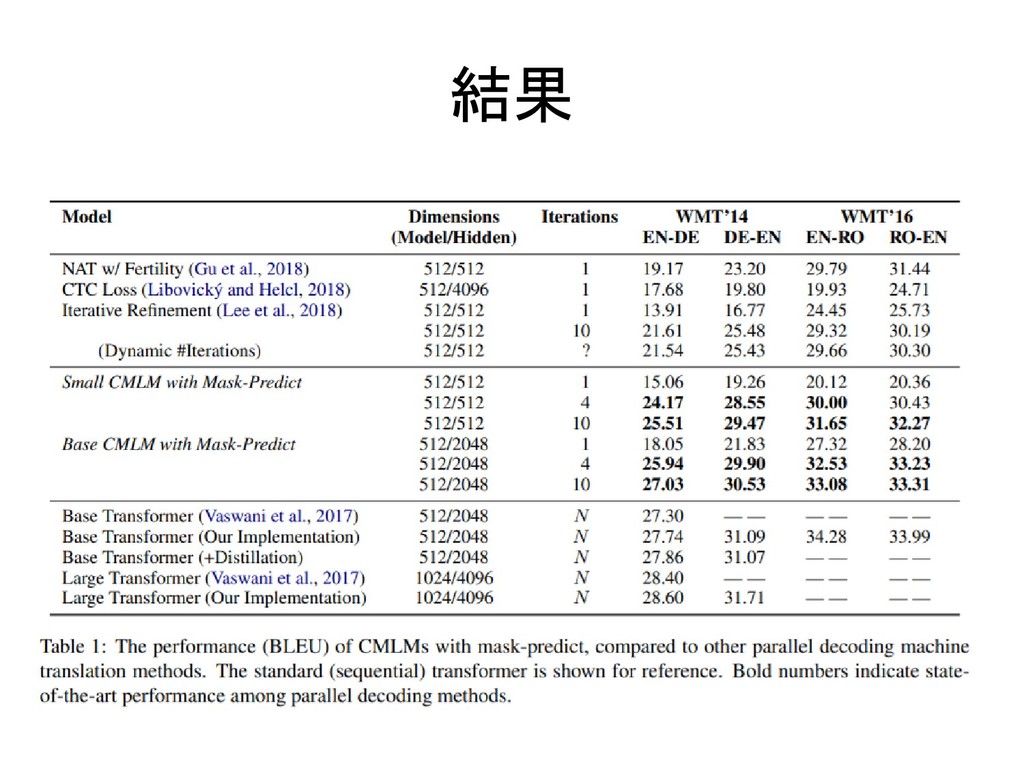
結果
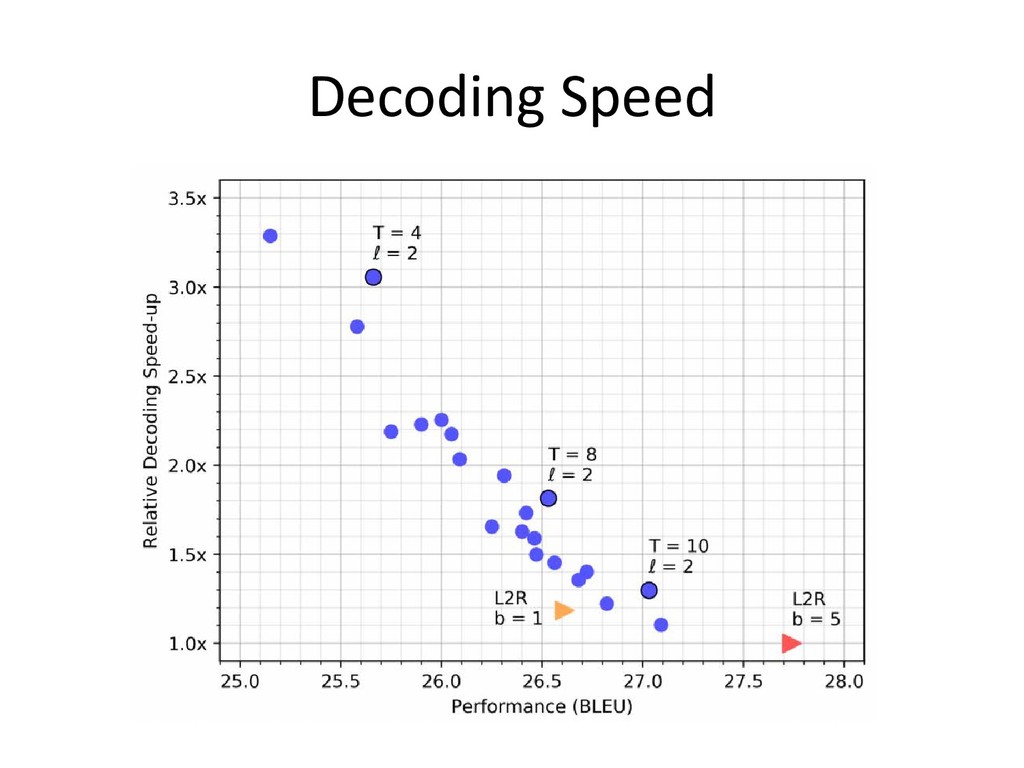
Decoding Speed
なぜ複数回の反復が必要なのか? • NATでは,複数の出力を同時に予測するため,各出力同士の依存 関係は考慮しない.その結果単語の繰り返しが出現しやすくなる • 一旦出力した候補を条件として繰り返し出力を予測することで,単 語の繰り返しが軽減できる(特に最初の2~3回が重要)
出力が長い系列の場合より多くの反復を 必要とするか? • ターゲットの長さが長いほど,反復回数を増やす効果は高い • しかし,ターゲットの長さによってそれほど大きな差分はなく, T=10程度でそれなりに高いスコアを達成している
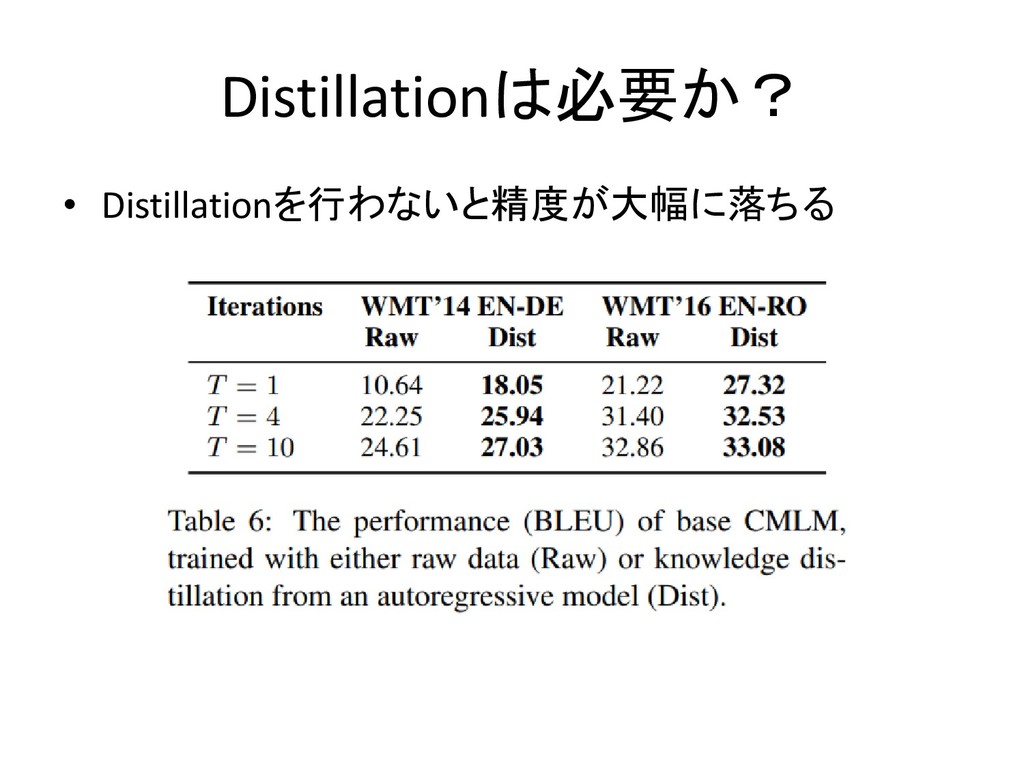
Distillationは必要か? • Distillationを行わないと精度が大幅に落ちる
まとめと所感 • NARの新しい手法(mask-predict)を提案し,既存のNARに比 べて高い精度(ARに迫る精度) – ARと同等精度になればより利用されやすくなる? • 初めに決めた長さの中で修正していくのはかなり制約が強 い?数単語の増減を許すような形式にできたほうが柔軟性 がありそう
• 長い文章を生成するためには結局反復回数を多くする必要 がある? – Maskする箇所をより効率的に決定するような手法?
参考文献 • Kim and Rush., Sequence-Level Knowledge Distillation, EMNLP, 2016
• Lee et al., Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement, EMNLP, 2018 • Gu et al., Non-Autoregressive Neural Machine Translation, ICLR, 2018
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ターゲットの長さ予測 • NARでは,ターゲットの長さをあらかじめ決めておく必要がある • 本手法では,Encoder側に長さを予測するための特殊トークン を追加 (BERTにおける[CLS]トークンに似た形) テスト時は,長さの候補上位l件を並列にデコーディングして,その結果を 下記のスコアで比較しもっともよい候補を選択する](https://files.speakerdeck.com/presentations/59b29787f12b4ef98b27029def1d46ca/slide_8.jpg){kind=link}
![Model Distillation • 過去の研究において,ARモデルの出力を教師として学習を行う方 法が精度向上に寄与することが知られている [Gu et al., 2018], [Stern](https://files.speakerdeck.com/presentations/59b29787f12b4ef98b27029def1d46ca/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}