Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
snlp2024
Search
kichi
August 20, 2024
410
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
snlp2024
kichi
August 20, 2024
More Decks by kichi
See All by kichi
snlp2021
kichi
0
510
snlp2020
kichi
0
220
SNLP2019.pdf
kichi
0
420
snlp2018
kichi
0
240
Featured
See All Featured
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Why Our Code Smells
bkeepers
PRO
340
58k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
My Coaching Mixtape
mlcsv
0
170
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
Agile that works and the tools we love
rasmusluckow
331
22k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
New Earth Scene 8
popppiees
3
2.4k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
620
Transcript
2024/8/26 最先端NLP勉強会 紹介者: 東北大学 斉藤いつみ 特に断りがない場合にはスライド中の画像は論文からの引用です.
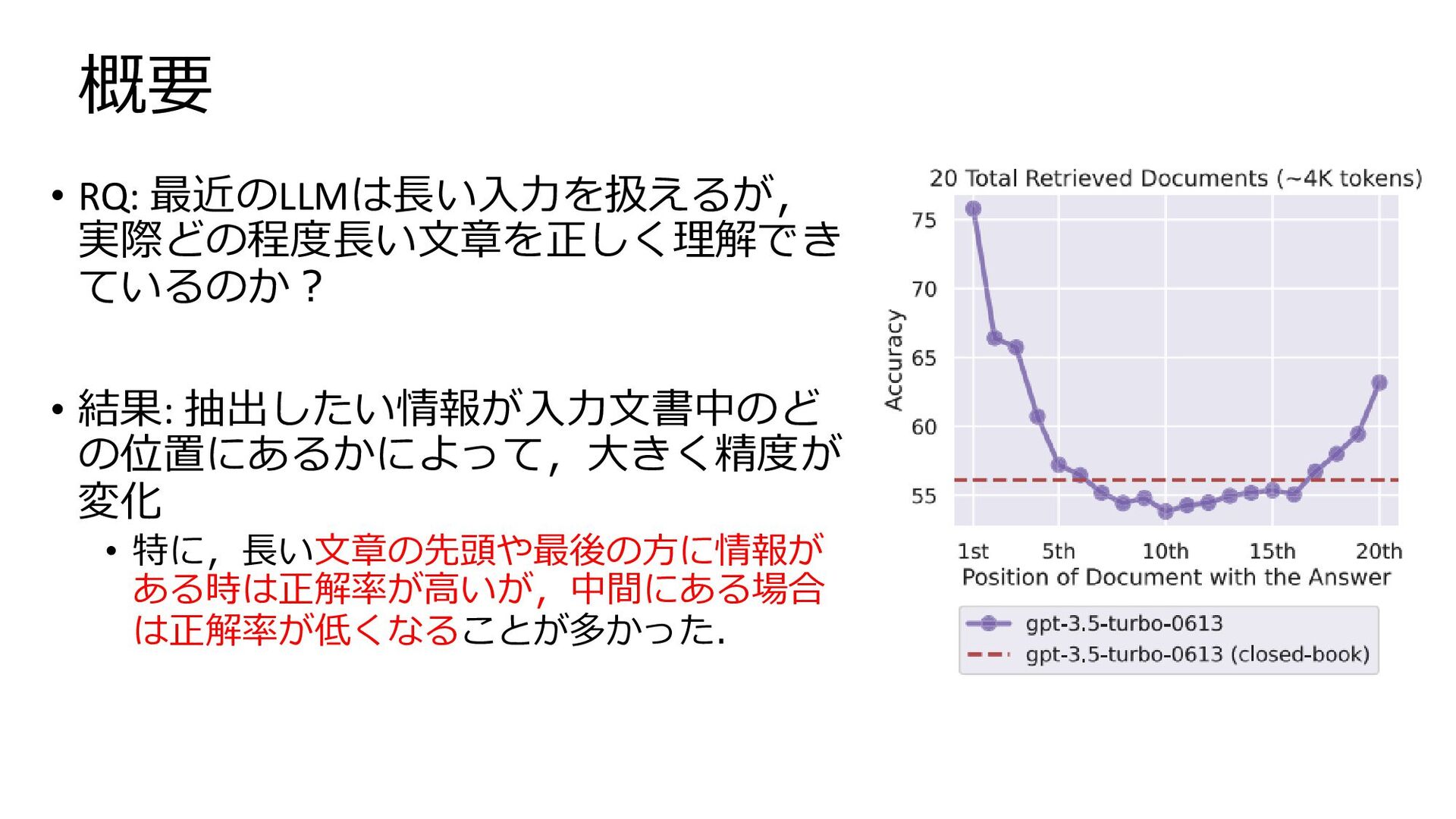
概要 • RQ: 最近のLLMは長い入力を扱えるが, 実際どの程度長い文章を正しく理解でき ているのか? • 結果: 抽出したい情報が入力文書中のど の位置にあるかによって,大きく精度が
変化 • 特に,長い文章の先頭や最後の方に情報が ある時は正解率が高いが,中間にある場合 は正解率が低くなることが多かった.
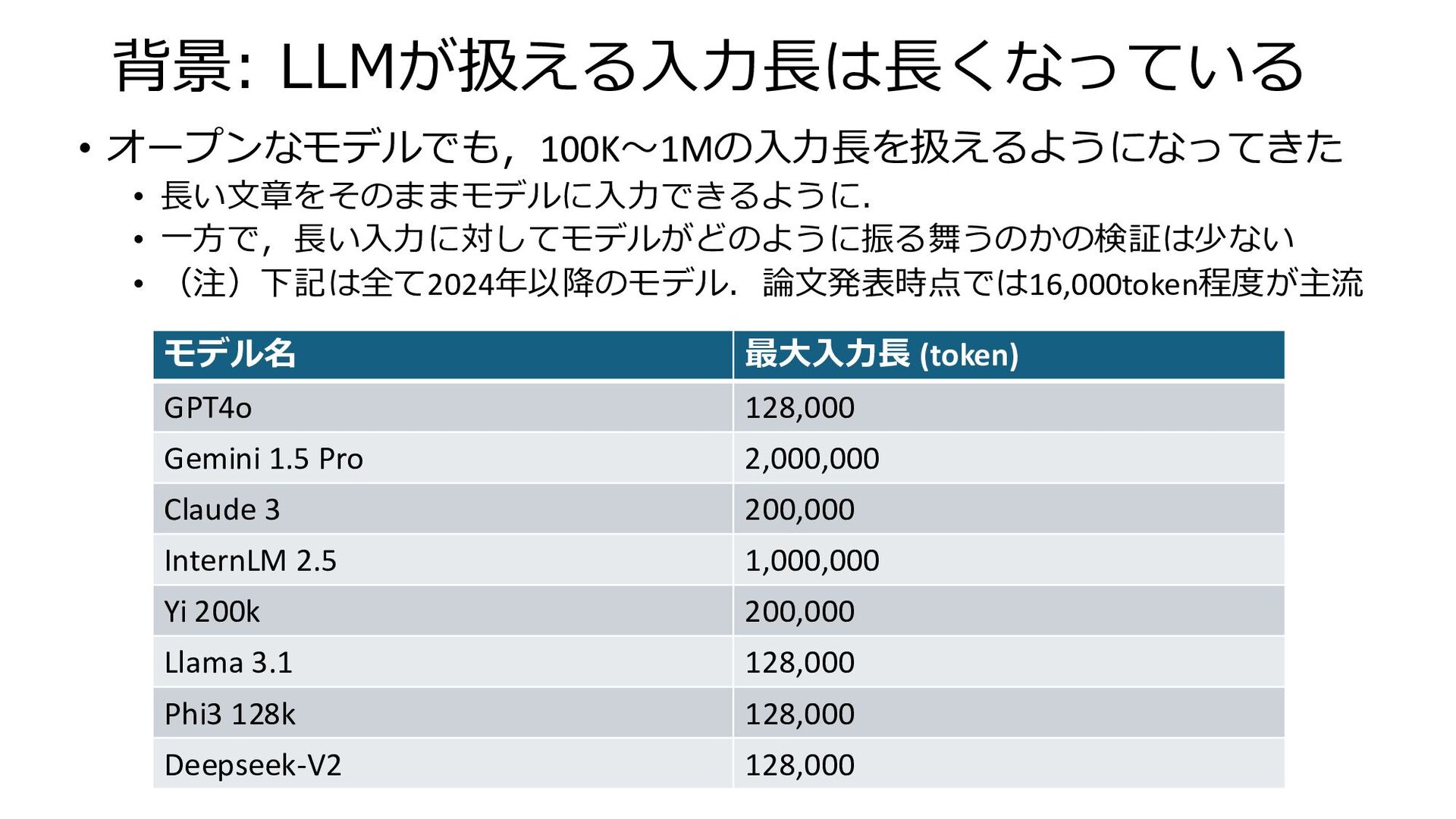
背景: LLMが扱える入力長は長くなっている モデル名 最大入力長 (token) GPT4o 128,000 Gemini 1.5 Pro
2,000,000 Claude 3 200,000 InternLM 2.5 1,000,000 Yi 200k 200,000 Llama 3.1 128,000 Phi3 128k 128,000 Deepseek-V2 128,000 • オープンなモデルでも,100K〜1Mの入力長を扱えるようになってきた • 長い文章をそのままモデルに入力できるように. • 一方で,長い入力に対してモデルがどのように振る舞うのかの検証は少ない • (注)下記は全て2024年以降のモデル.論文発表時点では16,000token程度が主流
長い入力の理解が必要とされる例 • 特に下記のようなケースでは,入力が数千〜数十万と長くなる マニュアルや本などを丸ごと理解 情報検索との組み合わせ(RAG) Q. XXのサービス解約の手順を教えて A. 解約を行うには,まずYY を確認し,次にZZの確認を行
う必要があります.…. LLM LLM A. Llama 3.1では長い入力 に対応するために〜 Q. Llama3.1が長い入力対応をどのように行 なっているか教えて
研究の目的と方法 • 目的:長い入力を扱えるモデルが,どの程度長い入力を正しく 理解できているのかを調べたい • 特に,正解の情報が含まれる位置に着目 • もしモデルが正しく長い入力を理解できているなら,正解となる情報が 入力文書のどこに位置していても,ほぼ同等の精度で答えられるはず. •
方法: 入力テキスト長と,正解を含むテキストの位置をコント ロールした実験を行い,これらが正解率に与える影響を調査.
検証タスク1: 複数文書質問応答 • 質問QとK個の文書を含む文書集合Xが与えられ,回答Aを生成する • K個の文書の中に,一つだけ正解が含まれる文書x_gがある • 正解以外のK-1個の文章は検索モデルを用いて構築(RAGと近い設定) • データセットはNaturalQuestions-Openを利用
検証方法 • 文書集合Kの数と,正解が含まれる文書x_gの位置を変化させて モデルの性能の変化を観察する. 例: K=5に増やす 例: x_gの位置を1番目にする
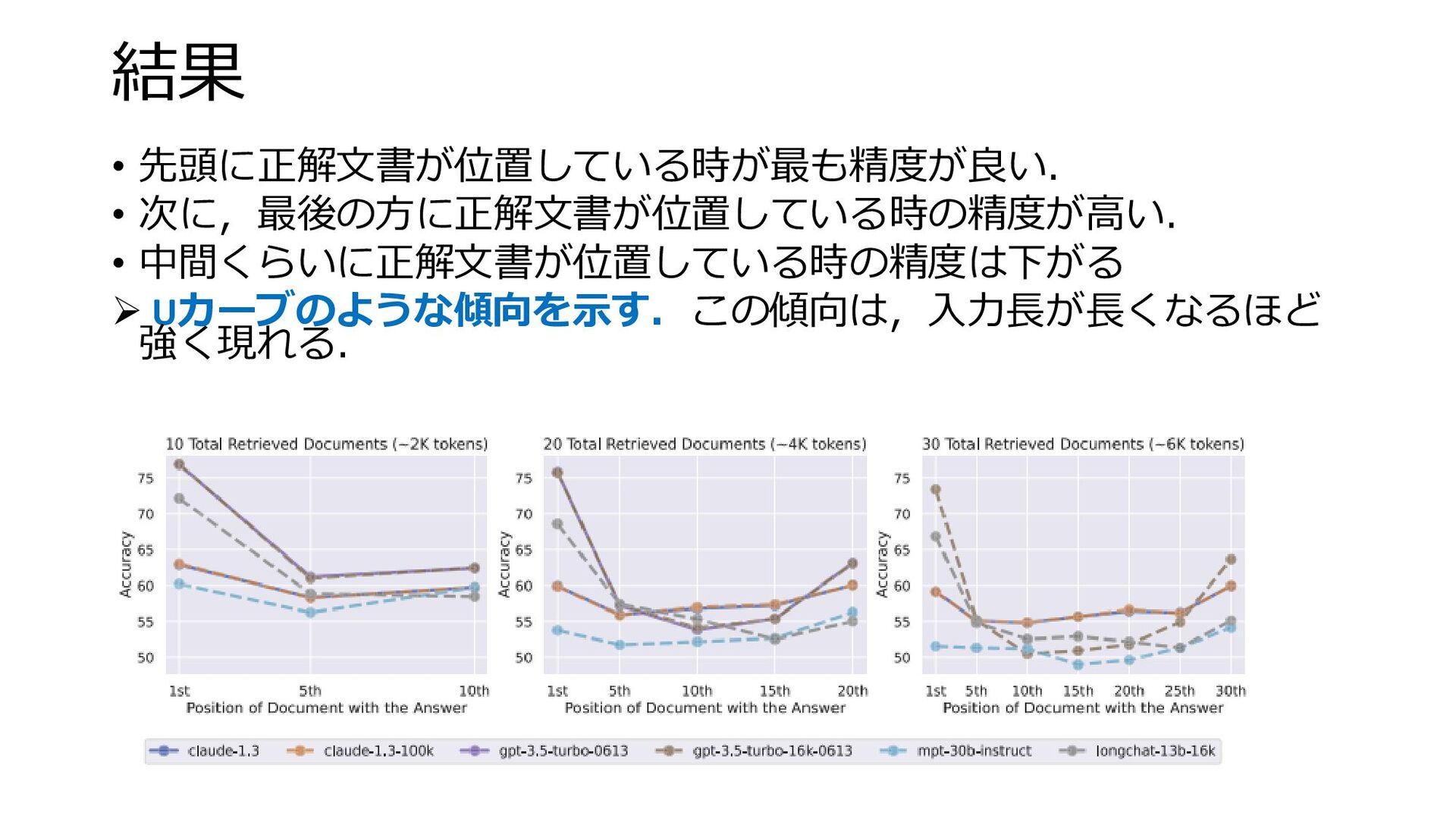
結果 • 先頭に正解文書が位置している時が最も精度が良い. • 次に,最後の方に正解文書が位置している時の精度が高い. • 中間くらいに正解文書が位置している時の精度は下がる ➢ Uカーブのような傾向を示す.この傾向は,入力長が長くなるほど 強く現れる.
検証タスク2: key-value抽出タスク • より簡単な抽出タスクで検証 • Keyとvalueのペアが入力文書として与えられ,クエリとしてkey が与えらえたときに対応するvalueを抽出するタスク
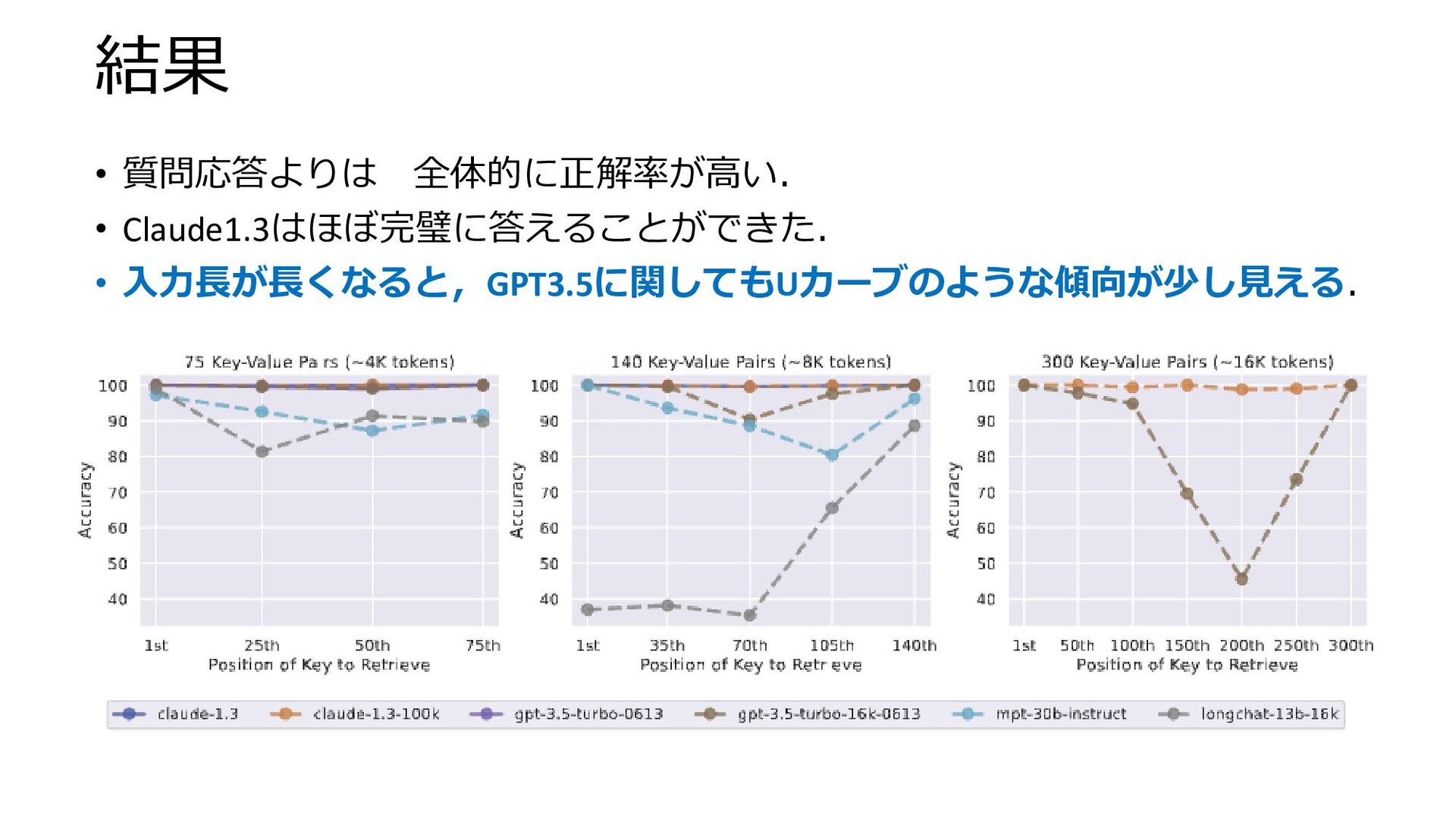
結果 • 質問応答よりは 全体的に正解率が高い. • Claude1.3はほぼ完璧に答えることができた. • 入力長が長くなると,GPT3.5に関してもUカーブのような傾向が少し見える.
なぜUカーブが生じるのか? • 要因を探るため,下記の3つの観点で実験を実施 • モデル構造の影響 • クエリ位置の影響 • 指示チューニングの影響
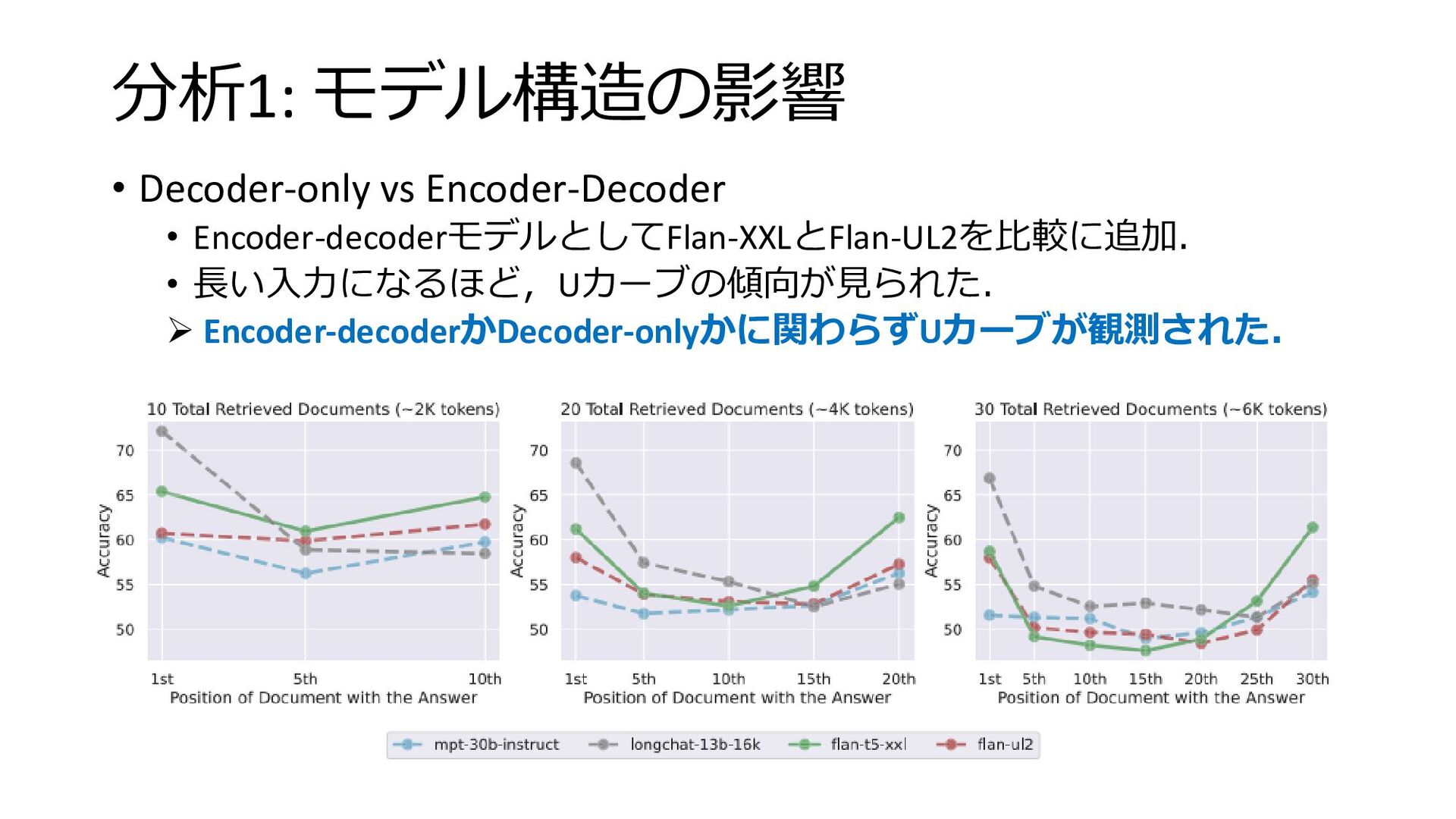
分析1: モデル構造の影響 • Decoder-only vs Encoder-Decoder • Encoder-decoderモデルとしてFlan-XXLとFlan-UL2を比較に追加. • 長い入力になるほど,Uカーブの傾向が見られた.
➢ Encoder-decoderかDecoder-onlyかに関わらずUカーブが観測された.
分析2: クエリ位置の影響 • クエリ(質問)を入力文書の前と後におくことで,クエリの影 響をより考慮できるか? • クエリを先頭に置くことで,入力文書の内部表現を計算する際にクエリ とのアテンションを考慮できるようになる Question: who
got the first nobel prize in prize in physics ←文頭にクエリを追加
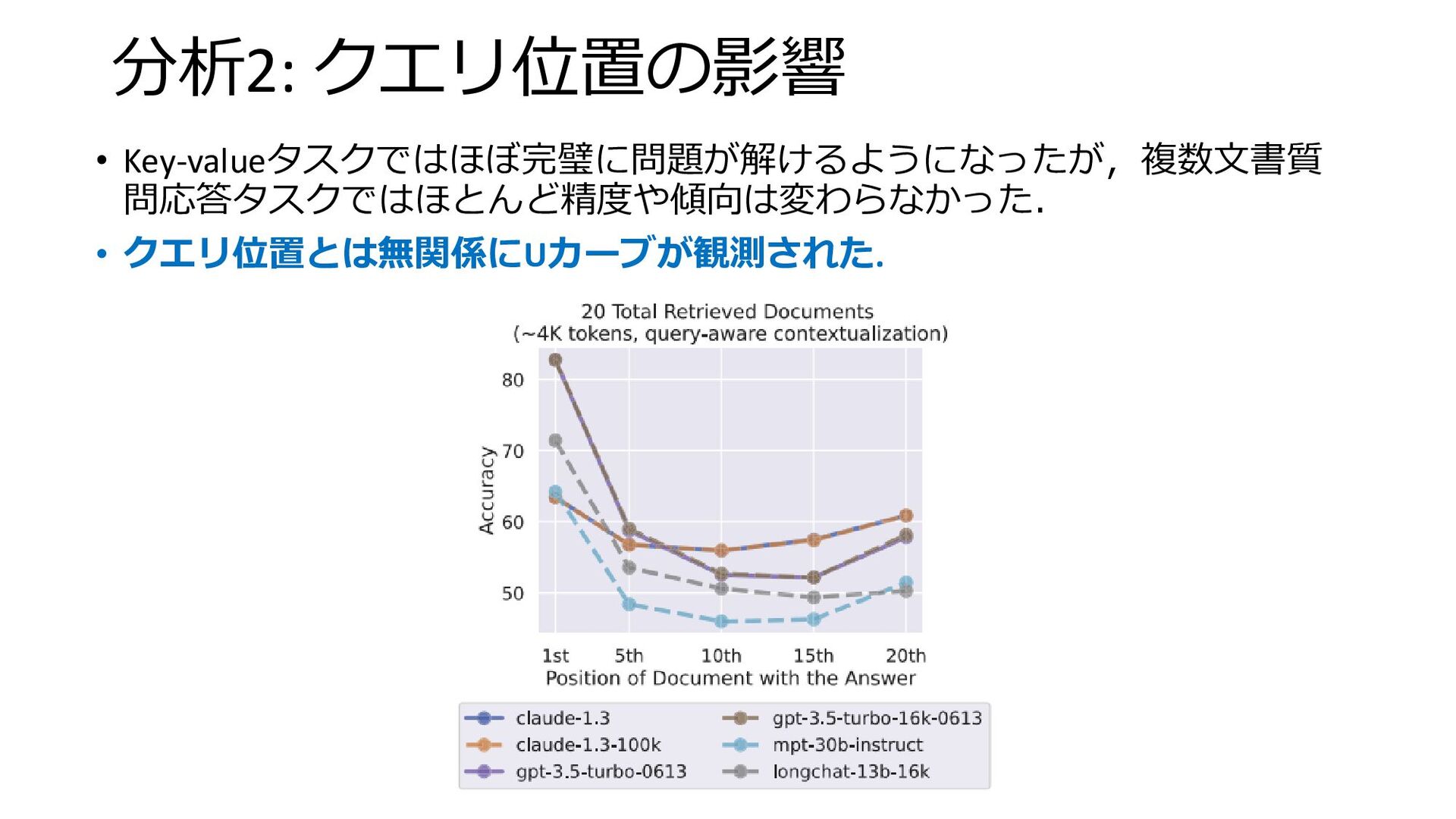
分析2: クエリ位置の影響 • Key-valueタスクではほぼ完璧に問題が解けるようになったが,複数文書質 問応答タスクではほとんど精度や傾向は変わらなかった. • クエリ位置とは無関係にUカーブが観測された.
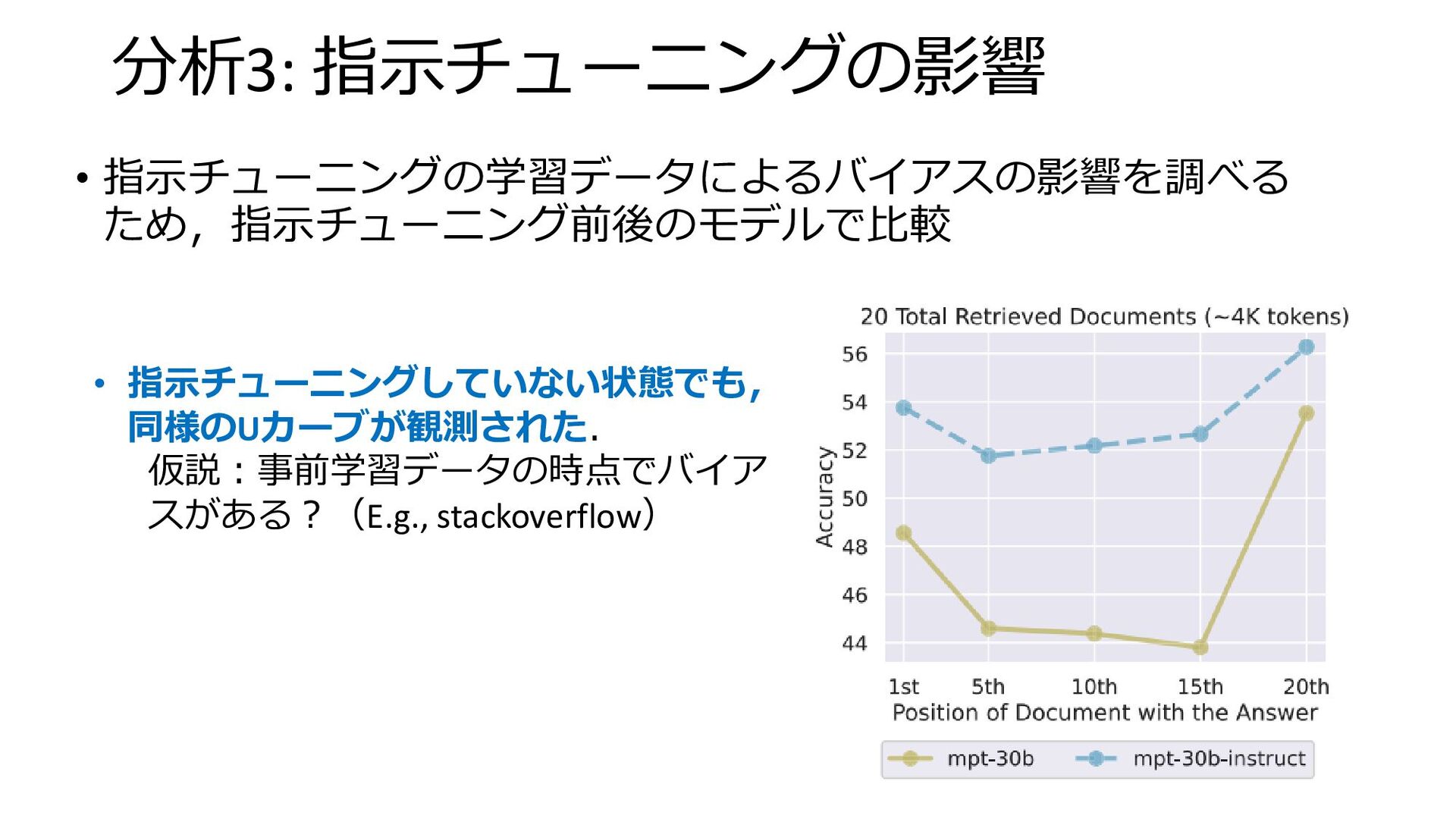
分析3: 指示チューニングの影響 • 指示チューニングの学習データによるバイアスの影響を調べる ため,指示チューニング前後のモデルで比較 • 指示チューニングしていない状態でも, 同様のUカーブが観測された. 仮説:事前学習データの時点でバイア スがある?(E.g.,
stackoverflow)
応用分析:Open DomainQAで長い入力を読めるか? • NaturalQuestions-Openのデータセットで,K個の関連文書を検索し,その文書 を入力として質問応答を行い精度を評価 • いわゆるRAGの設定.検索したK個の文書の中に正解があるとは限らない. • 検索のrecallは検索文書数Kを増やすほど上 がっていくが,回答精度は頭打ちになる
のが早い 長い入力から正しい回答を見つけられて いない
Lost in the middle論文のまとめ • LLMが長い入力を読むときに,入力の先頭や最後にある情報に比 べ,中間にある情報を正しく取り出すことができないという位置 バイアスがあることを実験的に明らかにした. • なぜこのような現象が起こるのかという原因を探るため,モデル
構造やクエリ位置,指示チューニングなどの影響を調べたが,い ずれもUカーブが観測され,明確な原因はわからなかった. • 長い入力の理解に関して改善が必要であることを示した.
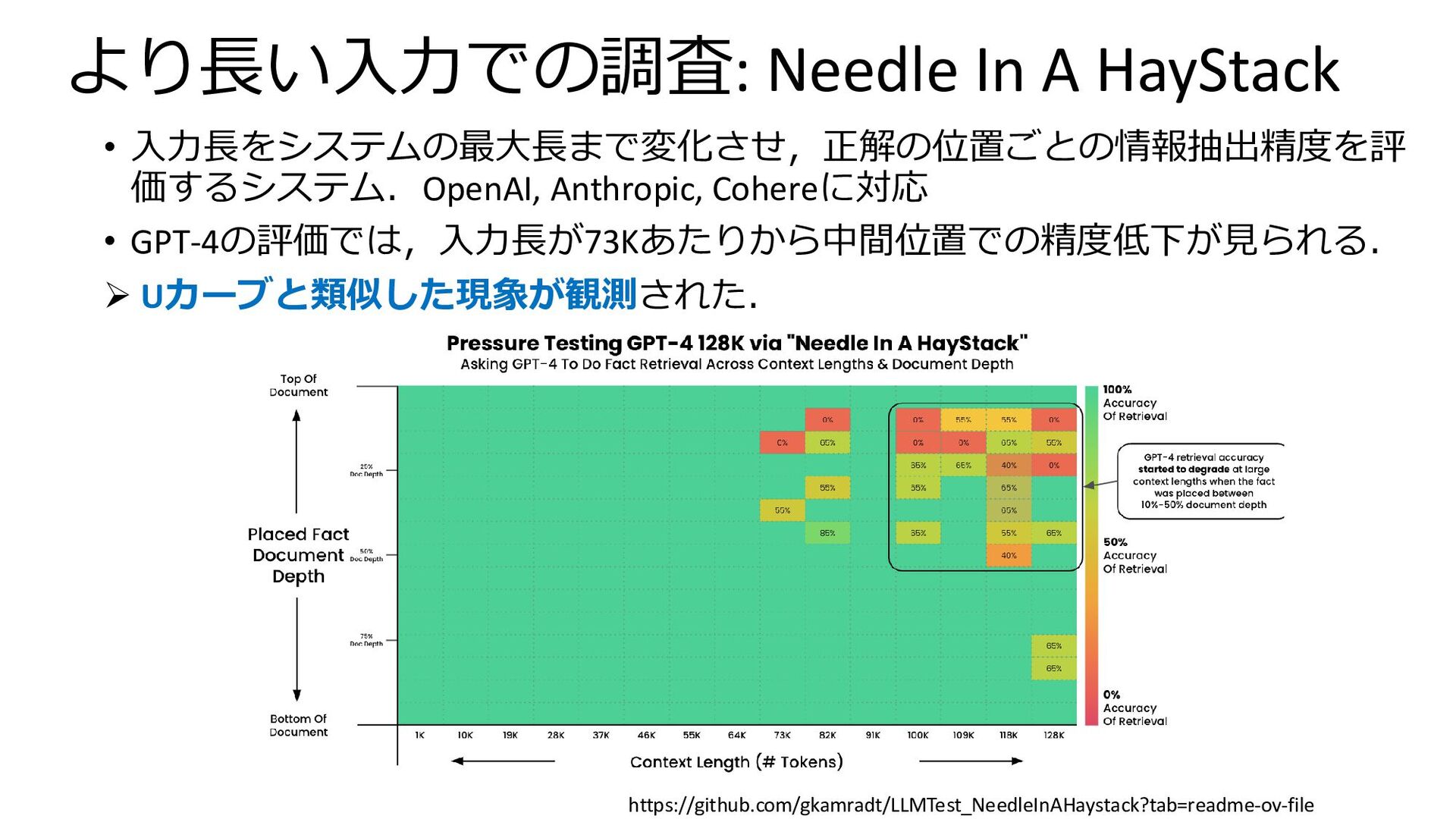
より長い入力での調査: Needle In A HayStack • 入力長をシステムの最大長まで変化させ,正解の位置ごとの情報抽出精度を評 価するシステム.OpenAI, Anthropic, Cohereに対応
• GPT-4の評価では,入力長が73Kあたりから中間位置での精度低下が見られる. ➢ Uカーブと類似した現象が観測された. https://github.com/gkamradt/LLMTest_NeedleInAHaystack?tab=readme-ov-file
• Claude2.1の場合,入力長は200Kまで増やせるが,入力長を増やすと中間位置 での精度が大きく低下. • 一定以上入力長を増やすと抽出の精度が悪化 • Uカーブと類似した現象が観測された より長い入力での調査: Needle In
A HayStack https://github.com/gkamradt/LLMTest_NeedleInAHaystack?tab=readme-ov-file
より長い入力での評価: ∞BENCH [ACL 2024] • 12種類のタスクを含む長い入力を評価するためのベンチーマークデー タセットを提案 • 入力長の平均は100Kを超える •
彼らの評価では,Lost-in-the-middleの明確な傾向はみられなかった. • 入力長やタスクによって,Uカーブの傾向が見られる場合とそうでない場合がある? • ただし,正解の位置によって精度が大きく異なるという現象は存在. • 事前に学習されたデータやタスクの影響も大きそう. https://arxiv.org/abs/2402.13718
アテンションバイアスの補正 Found in the middle [ACL findings 2024] • LLMのセルフアテンションを分析したところ,先頭と最後にattentionが強く
かかるバイアスがあることを確認. • 文書の位置をランダムに入れ替えても同じようなバイアスが観測された. • Attentionの位置バイアスを補正する方法を提案し,精度向上を確認. https://arxiv.org/abs/2406.16008
位置バイアスの補正・改善 • 位置encodingを工夫する [Zhang+ 2024] • 位置情報を含む内部表現を特定し補正する [Yu+ 2024] •
位置バイアスを補正するような学習データ・タスクを用いてモデルをfinetune する [Staniszewski+ 2023] [He+ 2023] [An+ 2024] • 入力を複数のchunkに区切って,複数のエージェントに処理させ,結果をマー ジする [Zhao+ 2024] • これらの手法によって正解が中間に位置する場合の精度は向上するが,先頭 に位置している時は精度が悪化してしまうこともある. https://arxiv.org/abs/2403.04797 https://arxiv.org/abs/2406.02536 https://arxiv.org/abs/2404.16811 https://arxiv.org/abs/2402.11550 https://arxiv.org/abs/2311.09198 https://arxiv.org/abs/2312.17296
LLMを用いたランキングタスクにおける 位置バイアス • 長い入力とは無関係に,LLMを出力評価などのランキングタスクに用 いる場合にposition biasが存在することは以前から指摘されてきた. [Wang+ 2023] [Shi+ 2024]
• E.g., 先頭の候補が選択されやすい. • 根本的には同じ問題? • ランキングタスクに対しては,入力の順序を複数パターン検証し結果 を統合することである程度位置バイアスが解消できることが報告され ている[Wang+ 2023] [Tang+ 2023] • 長い入力の場合コストが高すぎてこの方法は現実的ではなさそう https://arxiv.org/abs/2305.17926 https://arxiv.org/abs/2310.07712 https://arxiv.org/abs/2406.07791
まとめ • 長い入力を扱うことが可能なモデルが増加. • モデル構造や計算効率の向上. • 実際に,長い入力に対してモデルがどのような振る舞いをするかについては 調査が行き届いていない. • 長い入力の理解では,正解の情報の位置によって精度が大きく変化.
• LLMには位置のバイアスが存在する • これらを改善するための手法も多数提案されている.
所感 • なぜ位置のバイアスが生じるのか? • 学習データや次単語予測の影響?Positional encodingの影響? • 位置バイアスはどのような意味を持つのか? • テキストの構造や特徴を捉えた必要な(自然な)バイアスなのか,意図しない(排除すべ
き)バイアスなのか • 位置のバイアスを軽減させるためには? • 事後学習の工夫やposition encodingの事後的な工夫が多い • 事前学習の時点での工夫が必要か? • 例えば,Instruction Pre-training [1]のような,事前学習で指示チューニングも合わせて行う ような手法も出てきているが,このようなモデルでは傾向が異なるか? [1] https://arxiv.org/abs/2406.14491
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![より長い入力での評価: ∞BENCH [ACL 2024] • 12種類のタスクを含む長い入力を評価するためのベンチーマークデー タセットを提案 • 入力長の平均は100Kを超える •](https://files.speakerdeck.com/presentations/3981add398884ca686df3845d6a581c5/slide_19.jpg){kind=link}
![アテンションバイアスの補正 Found in the middle [ACL findings 2024] • LLMのセルフアテンションを分析したところ,先頭と最後にattentionが強く](https://files.speakerdeck.com/presentations/3981add398884ca686df3845d6a581c5/slide_20.jpg){kind=link}
![位置バイアスの補正・改善 • 位置encodingを工夫する [Zhang+ 2024] • 位置情報を含む内部表現を特定し補正する [Yu+ 2024] •](https://files.speakerdeck.com/presentations/3981add398884ca686df3845d6a581c5/slide_21.jpg){kind=link}
![LLMを用いたランキングタスクにおける 位置バイアス • 長い入力とは無関係に,LLMを出力評価などのランキングタスクに用 いる場合にposition biasが存在することは以前から指摘されてきた. [Wang+ 2023] [Shi+ 2024]](https://files.speakerdeck.com/presentations/3981add398884ca686df3845d6a581c5/slide_22.jpg){kind=link}
{kind=link}
{kind=link}