Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
snlp2018
Search
kichi
August 04, 2018
240
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
snlp2018
kichi
August 04, 2018
More Decks by kichi
See All by kichi
snlp2024
kichi
0
410
snlp2021
kichi
0
510
snlp2020
kichi
0
220
SNLP2019.pdf
kichi
0
420
Featured
See All Featured
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Test your architecture with Archunit
thirion
1
2.3k
A Tale of Four Properties
chriscoyier
163
24k
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
340
Utilizing Notion as your number one productivity tool
mfonobong
4
480
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.5k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
How to Think Like a Performance Engineer
csswizardry
28
2.7k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
Thoughts on Productivity
jonyablonski
76
5.3k
Transcript
ACL2018 2018/8/4 最先端NLP勉強会2018 読み手:斉藤いつみ Wan-Ting Hsu, Chieh-Kai Lin, Ming-Ying Lee,
Kerui Min, Jing Tang, Min Sun A Unified Model for Extractive and Abstractive Summarization using Inconsistency Loss
概要 • 貢献:抽出型(extractive)と生成型(abstractive) の要約の利点を融合 – 抽出型から計算される文レベルのアテンションと生 成型から計算される単語レベルのアテンションの双 方を利用 – 双方の整合性を取るようなinconsistency
lossを提案 – それぞれのベースモデルは既存の(当時の)state- of-the-artモデルを使用→組み合わせ方に新規性 • 結果: – CNN/Daily Mailデータセットで自動・主観評価ともに 良い結果
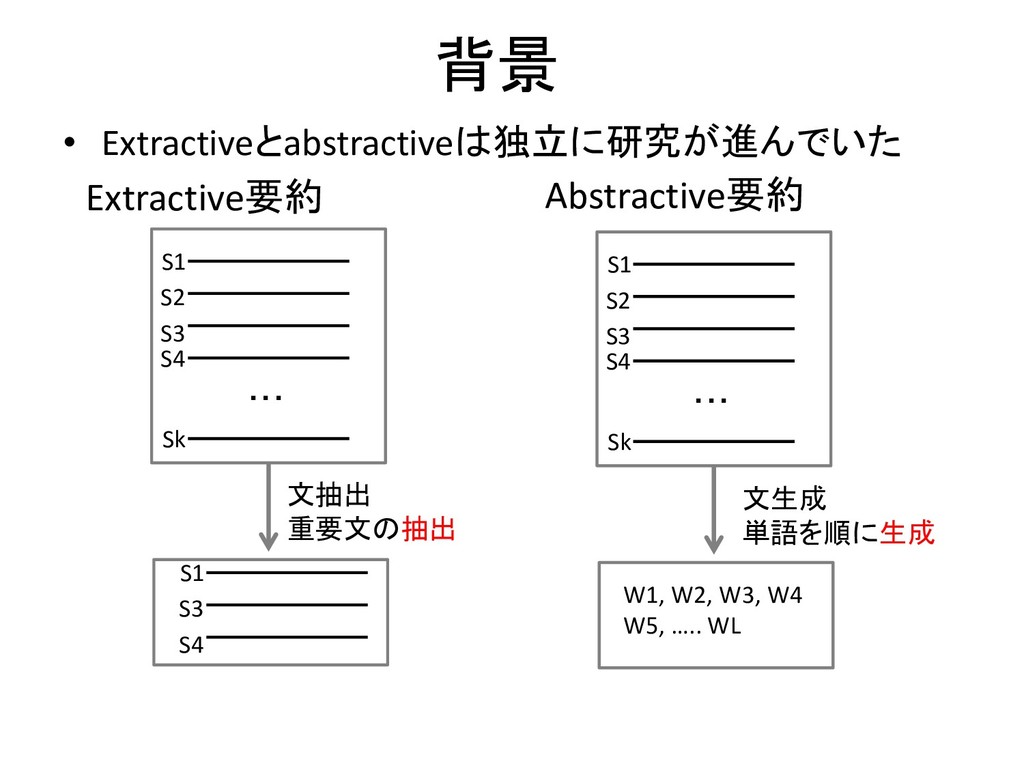
背景 S1 S2 S3 Sk ・・・ 文抽出 重要文の抽出 S1 S3
S4 S4 Extractive要約 Abstractive要約 S1 S2 S3 Sk ・・・ 文生成 単語を順に生成 S4 W1, W2, W3, W4 W5, ….. WL • Extractiveとabstractiveは独立に研究が進んでいた
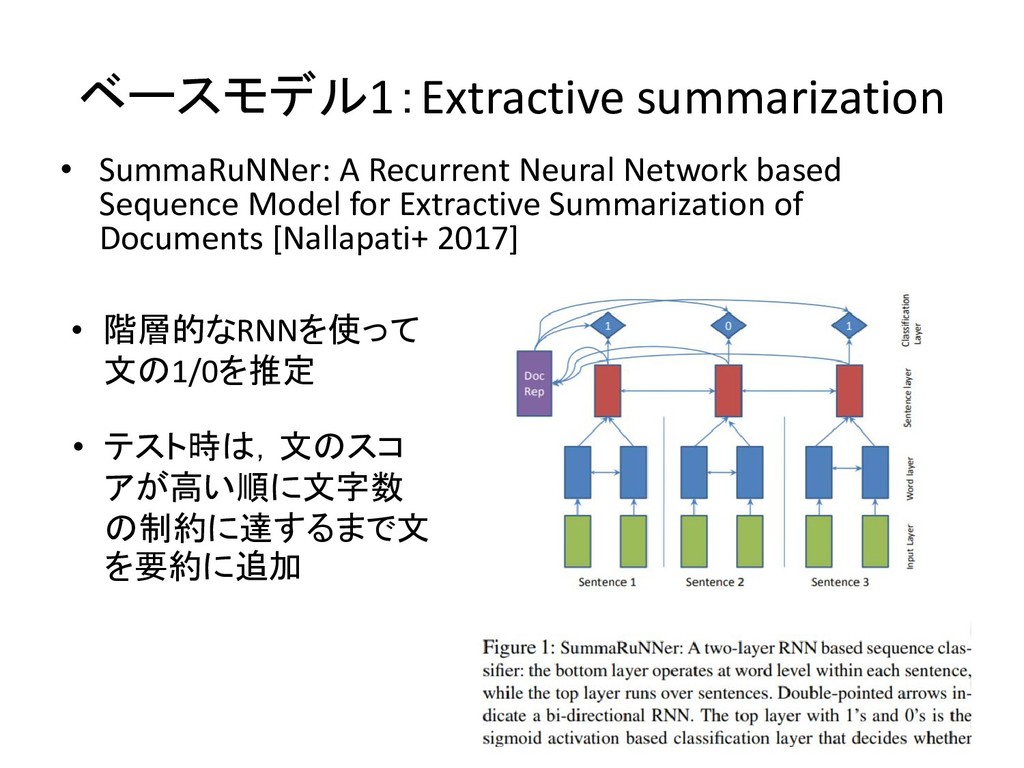
ベースモデル1:Extractive summarization • SummaRuNNer: A Recurrent Neural Network based Sequence
Model for Extractive Summarization of Documents [Nallapati+ 2017] • 階層的なRNNを使って 文の1/0を推定 • テスト時は,文のスコ アが高い順に文字数 の制約に達するまで文 を要約に追加
ベースモデル2:Abstractive summarization • Get To The Point: Summarization with Pointer-
Generator Networks [See+ 2017] – 単語生成確率に,ソース文書中の単語コピー確率を 考慮.単語レベルでの抽出的な操作を考慮
それぞれのメリット・デメリット Extractive Abstractive メリット ROUGEが高い値 Readabilityが高い デメリット Readabilityが低い (文のつながりが悪 い・簡潔でない)
事実が欠落したり, 誤った生成を行う ことがある
• 指しているものが不明 確(文のつながりが悪 い) • 文をそのまま抽出する ので冗長 Extractive 実際の例
事実と異なる固有 名詞を生成 Abstractive 実際の例
事実と矛盾しない 程度に短縮や書 き換え Unified 実際の例
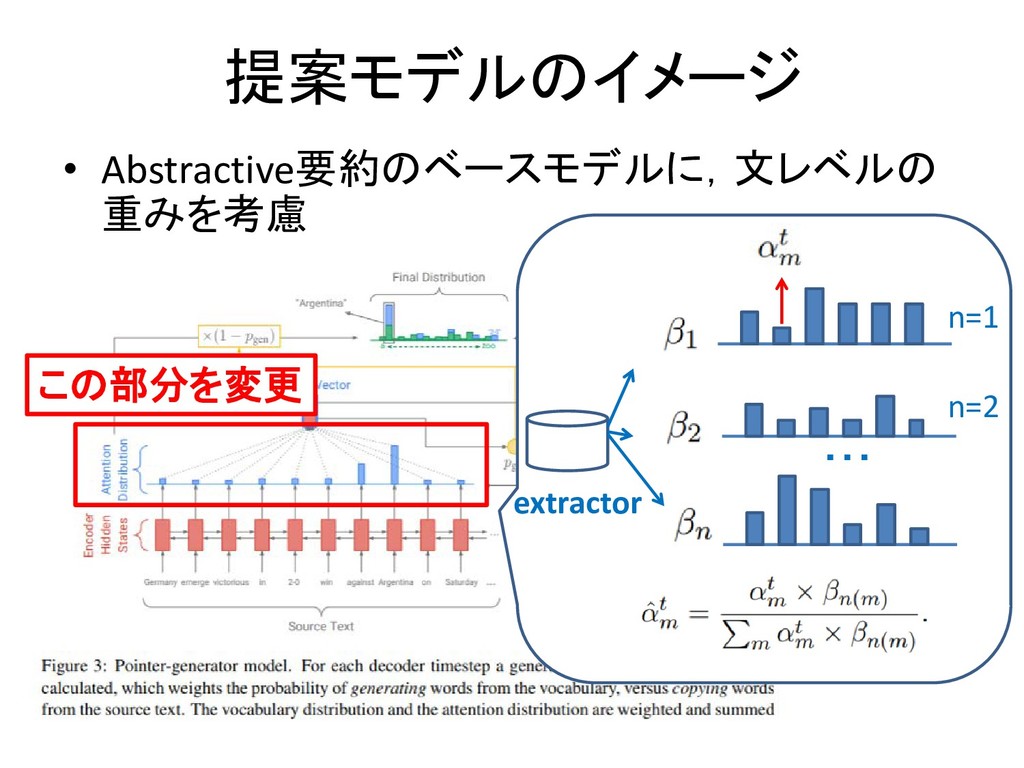
提案モデルのイメージ • Abstractive要約のベースモデルに,文レベルの 重みを考慮 この部分を変更 extractor n=1 n=2 ・・・
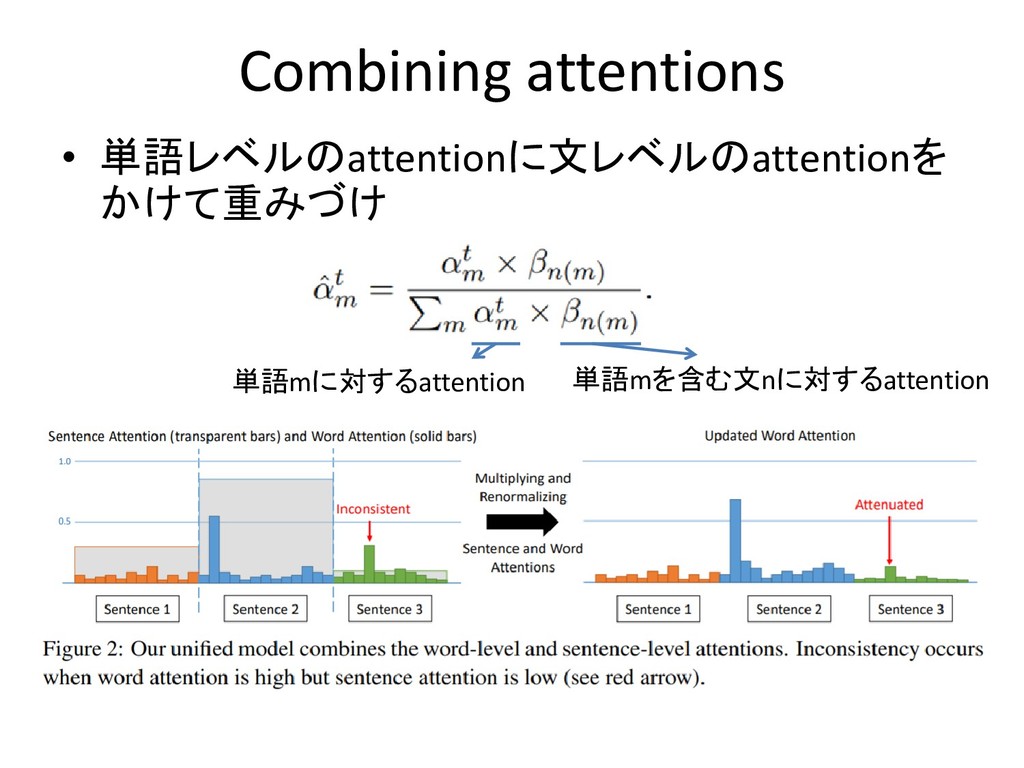
Combining attentions • 単語レベルのattentionに文レベルのattentionを かけて重みづけ 単語mに対するattention 単語mを含む文nに対するattention
Inconsistency loss • 単語レベルのattentionが高い単語を含む文 は文レベルのattentionも高くしたい • 単語レベルのattention確率が高いK個の単語につ いて,上記のロスを計算
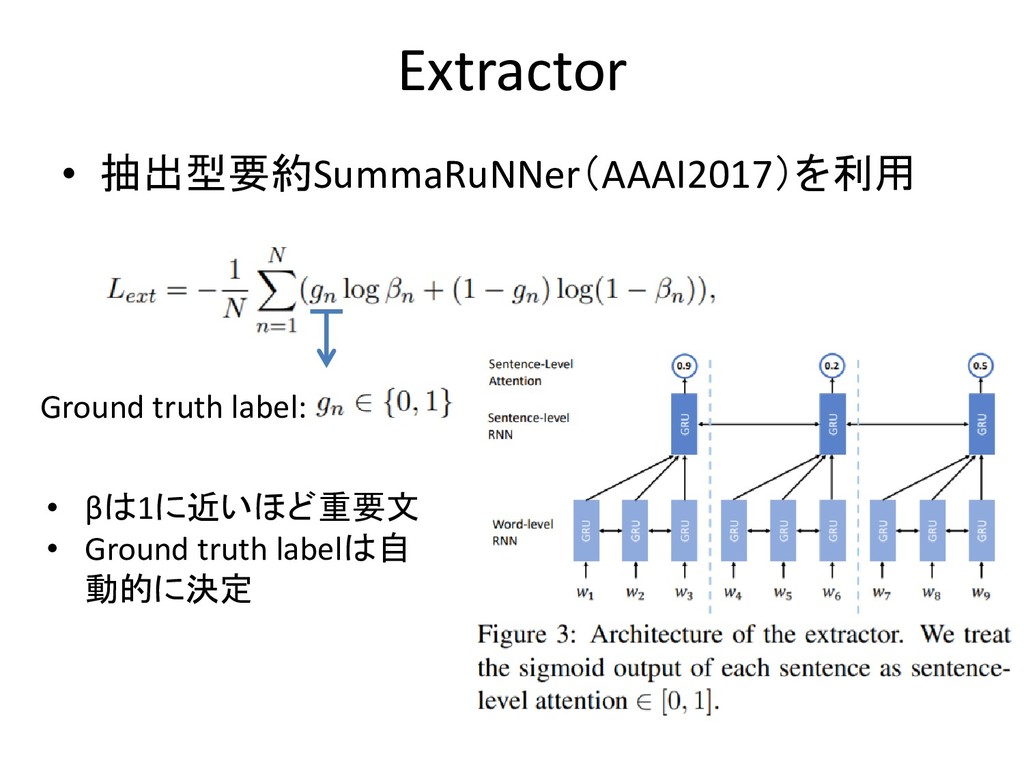
Extractor • 抽出型要約SummaRuNNer(AAAI2017)を利用 Ground truth label: • βは1に近いほど重要文 • Ground
truth labelは自 動的に決定
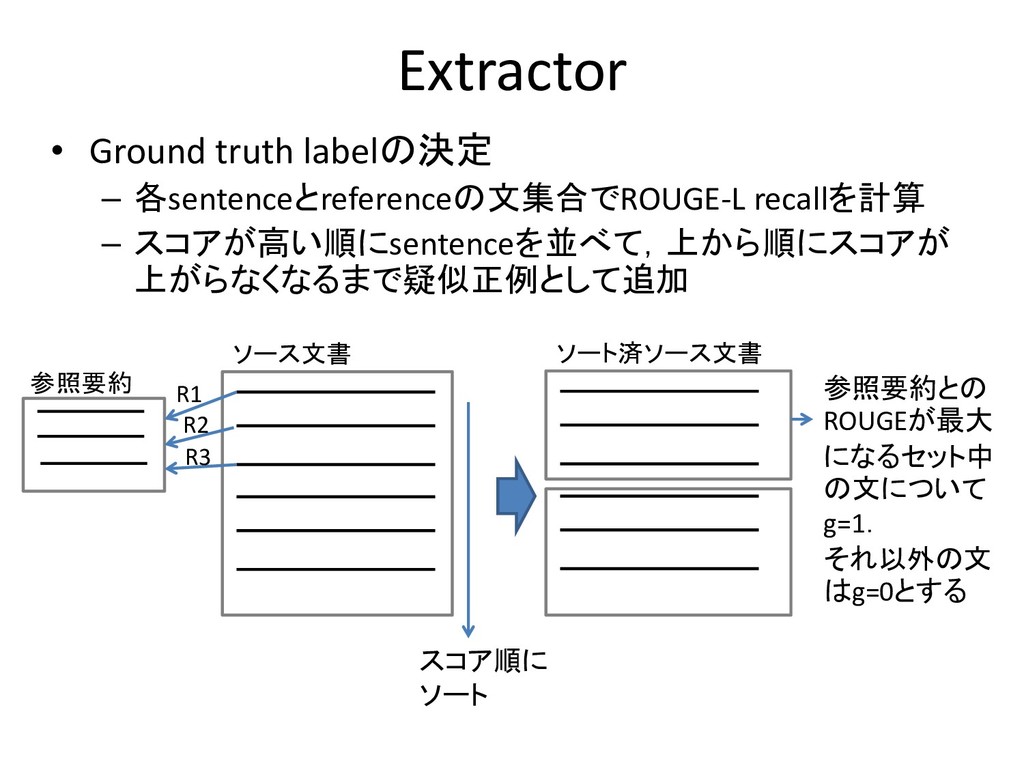
Extractor • Ground truth labelの決定 – 各sentenceとreferenceの文集合でROUGE-L recallを計算 – スコアが高い順にsentenceを並べて,上から順にスコアが
上がらなくなるまで疑似正例として追加 ソース文書 スコア順に ソート ソート済ソース文書 参照要約との ROUGEが最大 になるセット中 の文について g=1. それ以外の文 はg=0とする 参照要約 R1 R2 R3
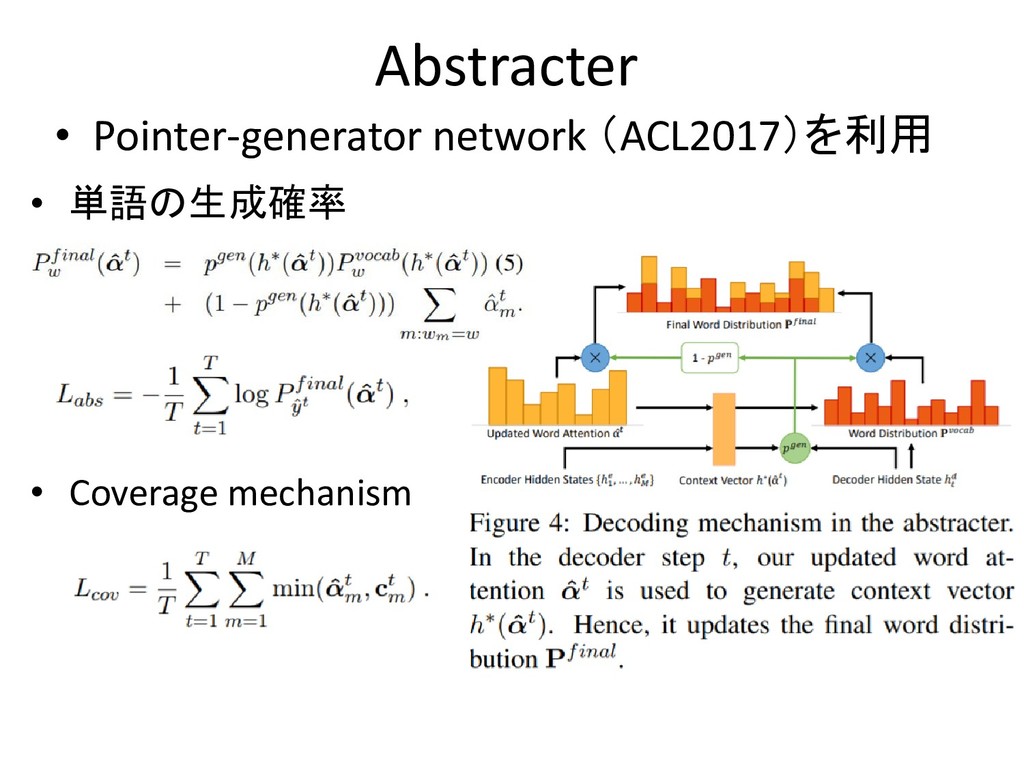
Abstracter • Pointer-generator network (ACL2017)を利用 • Coverage mechanism • 単語の生成確率
学習 • Pre-train – ExtractorとAbstracterをそれぞれ個別に学習 – Abstracterを学習する際には,文選択の正解 ( )を入力として学習を行う •
Extractor + Abstracter – Two-stages training • Extractorで高いアテンションが得られた文をhard samplingして入力とする – End-to-end training • すべてのlossをまとめて学習
データセット • CNN/Daily Mail Dataset – 要約でよく使われるデータセット – train:287,113, validation:13,368
, test: 11,490 Grusky et al., (2018) NEWSROOM: A Dataset of 1.3 Million Summaries with Diverse Extractive Strategiesより引用
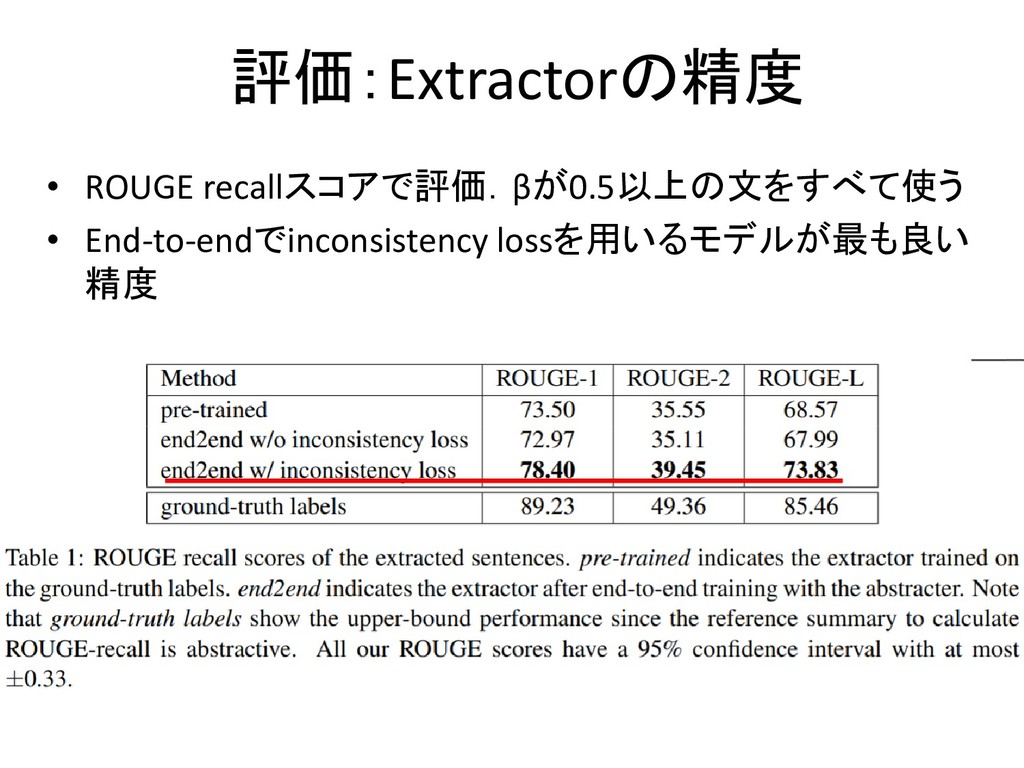
評価:Extractorの精度 • ROUGE recallスコアで評価.βが0.5以上の文をすべて使う • End-to-endでinconsistency lossを用いるモデルが最も良い 精度
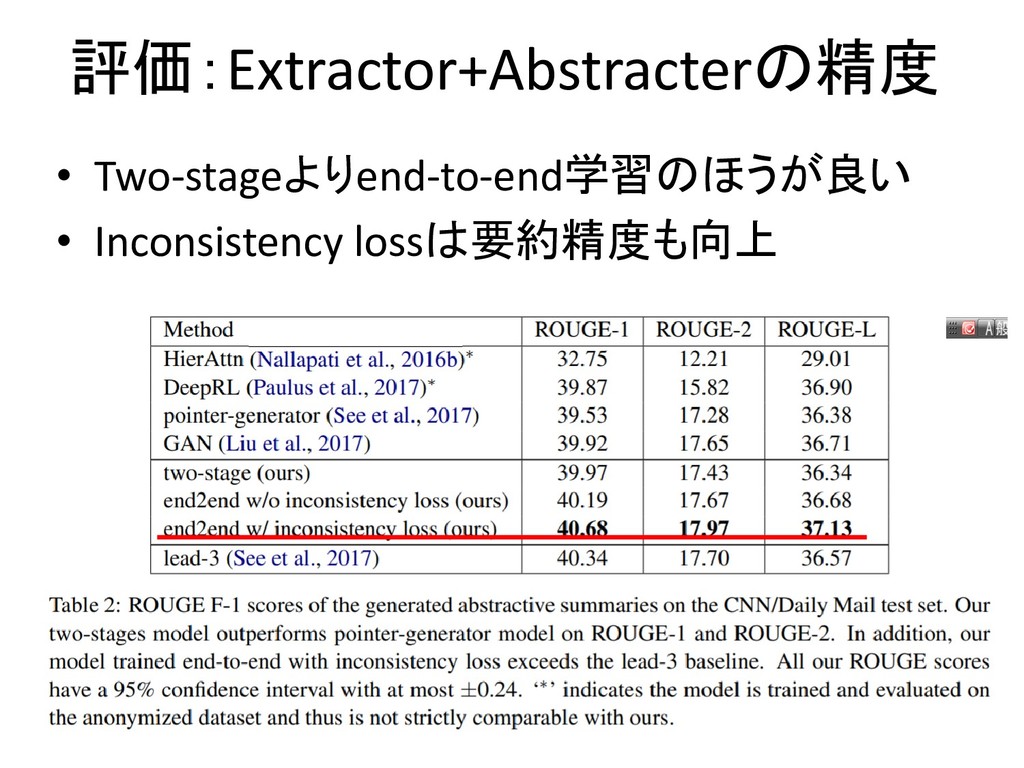
評価:Extractor+Abstracterの精度 • Two-stageよりend-to-end学習のほうが良い • Inconsistency lossは要約精度も向上
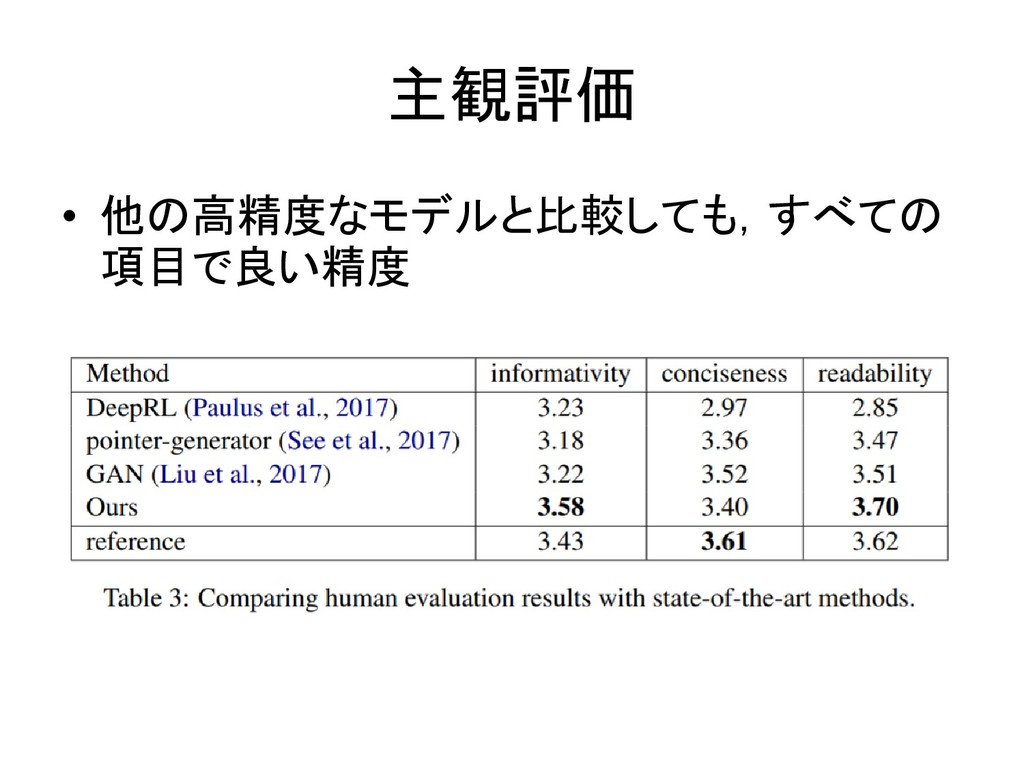
主観評価 • 他の高精度なモデルと比較しても,すべての 項目で良い精度
分析:Inconsistency lossの効果 • 単語attentionと文 attentionの不一致率 各デコードstepで,attentionの高い単 語が含まれる文のスコアが低い割合
まとめ • 抽出型要約と生成型要約の組み合わせ – それぞれのモデルの強みを生かす – 各モデルの構造は既存のものを流用 • 新聞要約タスクで自動・主観評価ともに良い 精度
• 根幹となるアイデア(inconsistency loss)の間 接的な評価・分析
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}