STRING(256), LastName STRING(256), SingerInfo BYTES(MAX), ) PRIMARY KEY (SingerId); CREATE TABLE Albums ( SingerId INT64 NOT NULL, AlbumId INT64 NOT NULL, AlbumTitle STRING(256), ) PRIMARY KEY (SingerId, AlbumId), INTERLEAVE IN PARENT Singers ON DELETE CASCADE; SELECT s.*, ARRAY( SELECT AS STRUCT a.* FROM Albums a WHERE a.SingerId = s.SingerId ) Albums, FROM Singers s WHERE s.SingerId = @SingerId 物理的に⼀緒に格納 ⼀緒に取得する場合、JOINコストがなく⾼速 https://cloud.google.com/spanner/docs/schema-and-data-model?hl=ja ARRAY(サブクエリで取得) 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ホットスポット UserAccessLog(LastAccess, UserId, …) ×単調増加するキーが主キーの先頭 保存されるスプリットはキーの範囲で決定 https://cloud.google.com/spanner/docs/schema-design?hl=ja [1230219000000000, 001930]までのデータ →](https://files.speakerdeck.com/presentations/74068da799824604b0772c0a540a2c6a/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
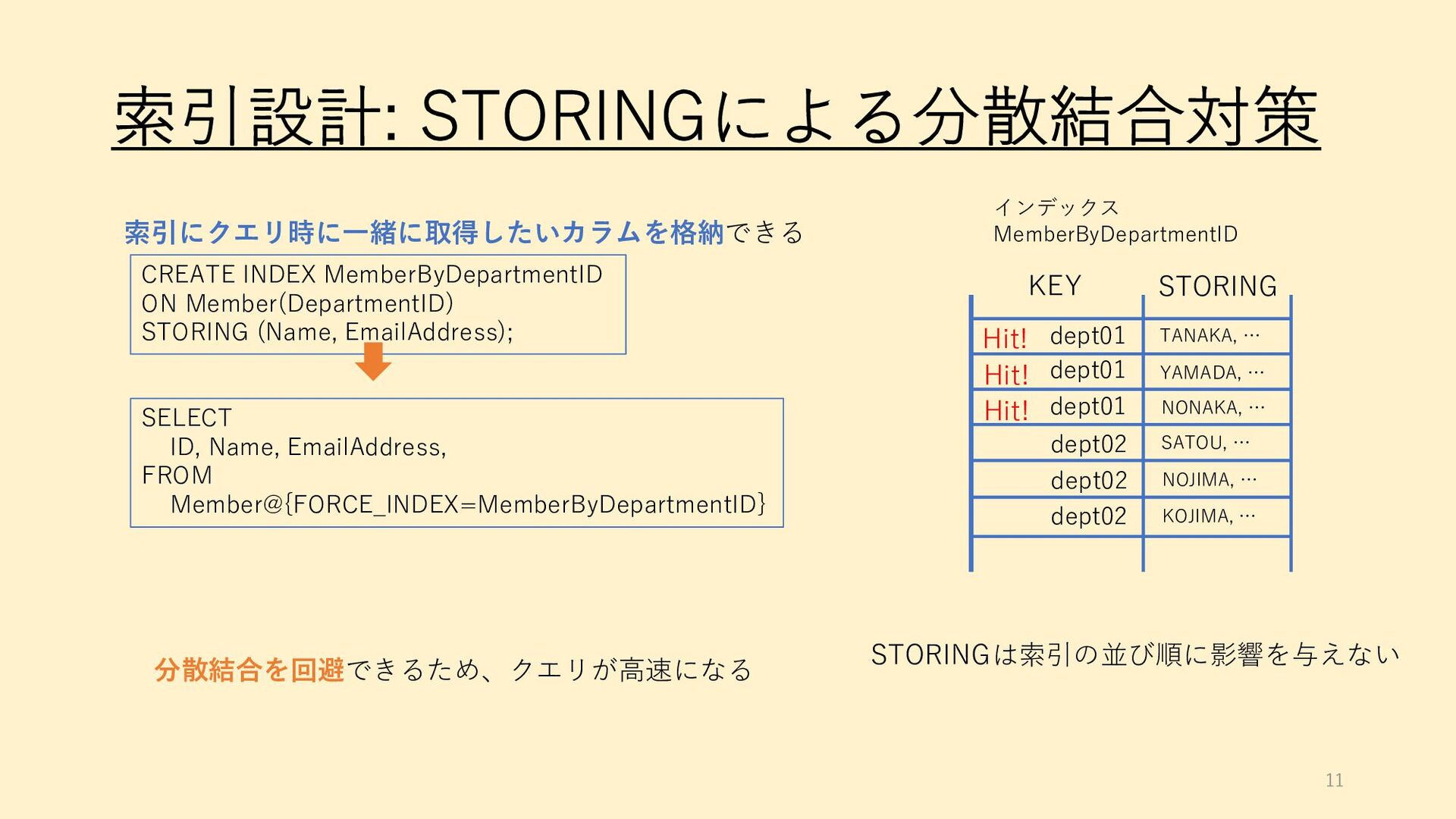{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}