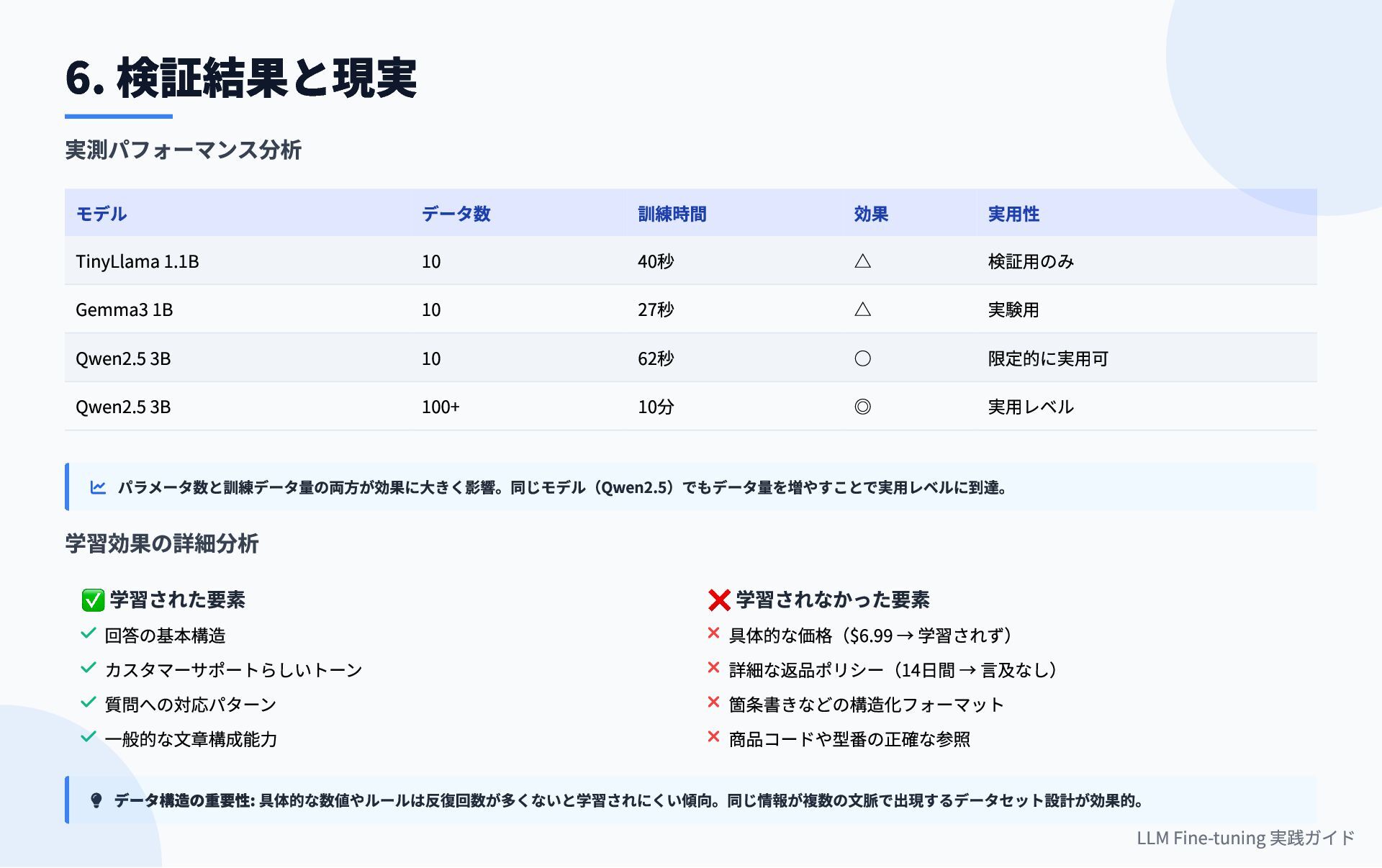
params: 2,359,296 || all params: 1,102,885,120 訓練時間: 0:00:40.123456 効果の検証 # 検証スクリプト実行 python verify_tinyllama_finetuning.py Before(ベースモデル): Q: What are the shipping costs? A: I do not have access to specific shipping rates... (一般的で曖昧な回答) After(Fine-tuned): Q: What are the shipping costs? A: Shipping costs vary depending on your location... (やや改善されたが、具体的な価格は学習されず) 🔍 重要な観察ポイント 部分的な改善 回答の構造は改善、しかし具体的な情報($6.99など)は学習されない データ量の影響 10サンプルでは限界あり、実用レベルには100+サンプル必要 4. Fine-tuning実演デモ LLM Fine-tuning 実践ガイド
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}