Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
食品パッケージ画像分析チャレンジ 学生部門 7th Place Solution
Search
kq5y
October 14, 2023
18
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
食品パッケージ画像分析チャレンジ 学生部門 7th Place Solution
kq5y
October 14, 2023
Featured
See All Featured
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Exploring anti-patterns in Rails
aemeredith
3
450
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Producing Creativity
orderedlist
PRO
348
40k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
190
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
410
Product Roadmaps are Hard
iamctodd
55
12k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.3k
Transcript
テクノプロ・デザイン社 食品パッケージ画像分析チャレンジ 学生部門 7th Place Solution 2023/10/14 tksnn
1 自己紹介 地方国公立大学B1 SIGNATE Student Cup 2023 モデリング部門 42nd🥈 今回が初めての画像系コンペティション
→ テーブルコンペの経験を活かして取り組んだ
目次 2 1. コンペについて 1. データの特徴 2. 解法紹介 1. データ前処理
2. モデリング 3. アンサンブル 4. スコア 3. その他 1. うまく行かなかったこと 2. 精度向上のために
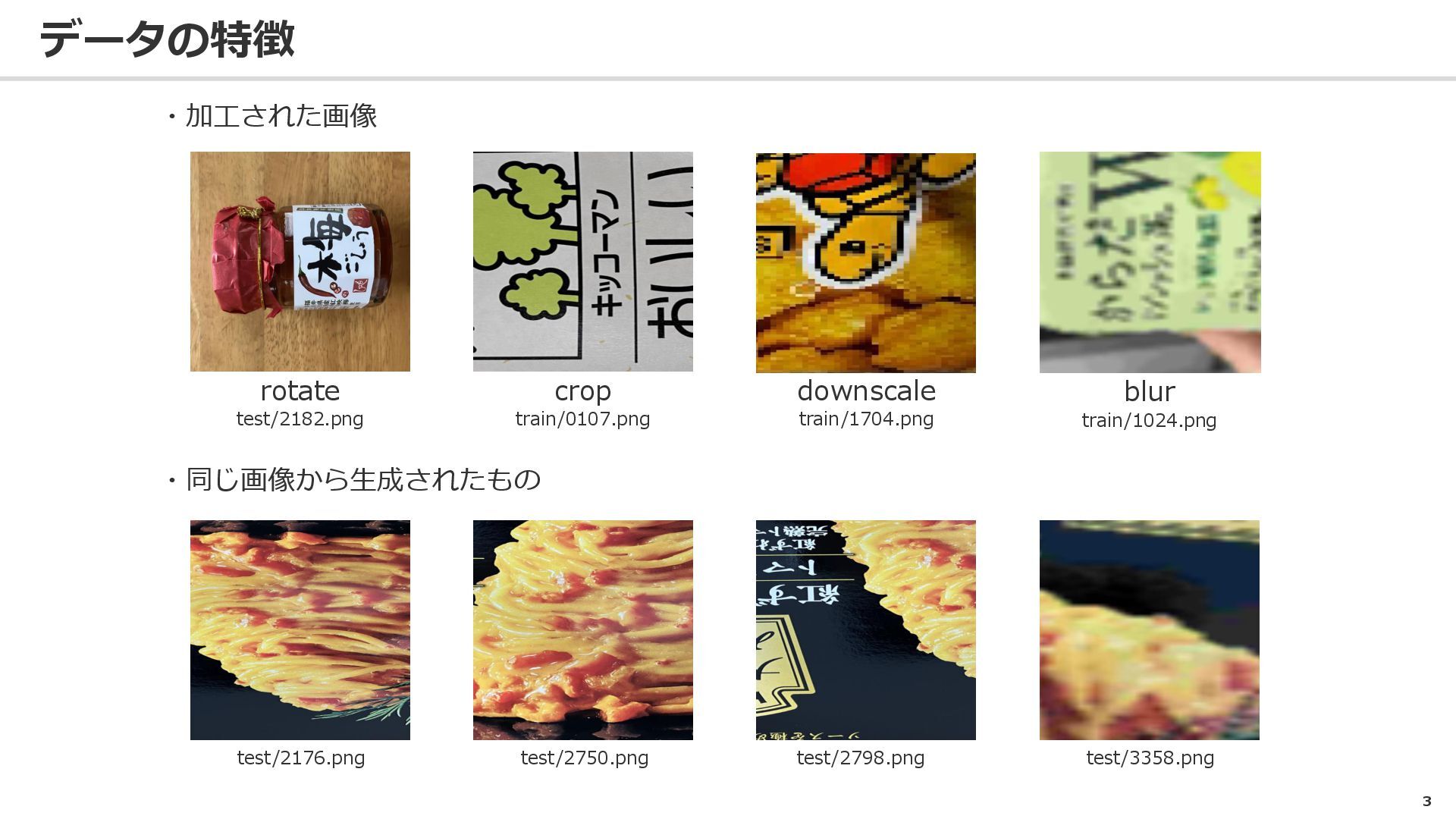
データの特徴 3 ・加工された画像 rotate test/2182.png crop train/0107.png downscale train/1704.png blur
train/1024.png ・同じ画像から生成されたもの test/2176.png test/2750.png test/2798.png test/3358.png
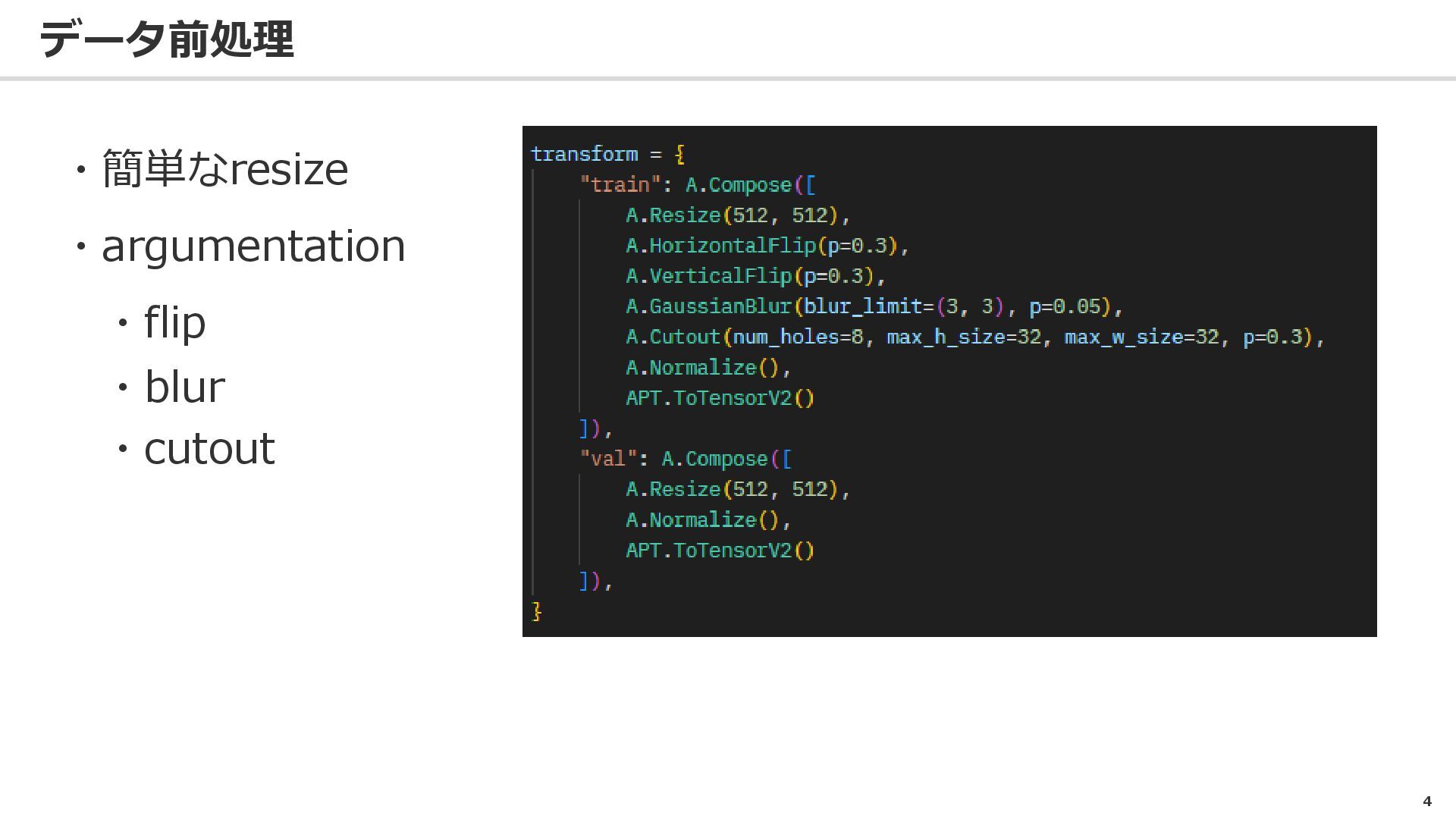
データ前処理 4 ・簡単なresize ・argumentation ・flip ・blur ・cutout
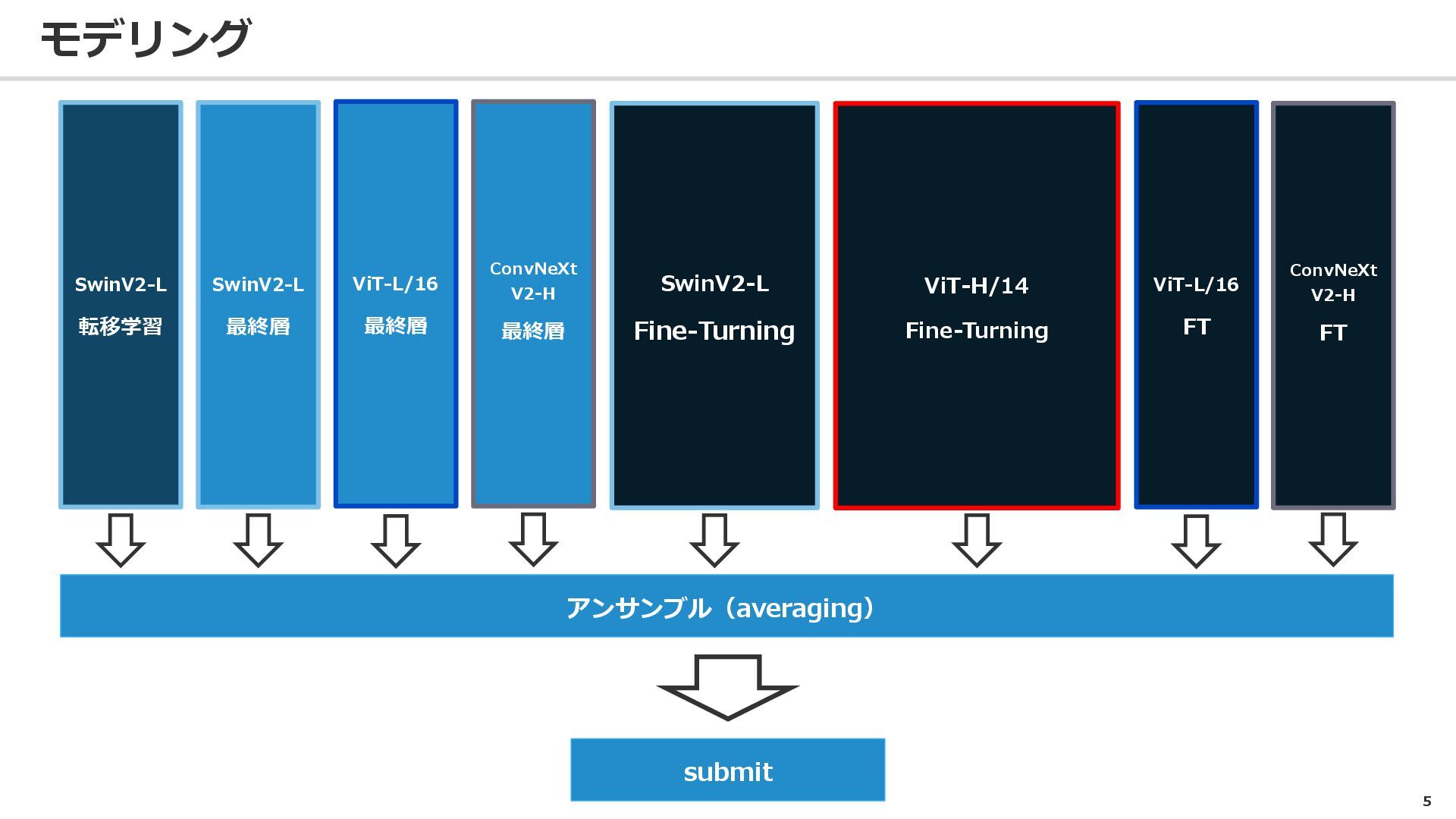
モデリング 5 アンサンブル(averaging) SwinV2-L 転移学習 SwinV2-L 最終層 ViT-L/16 最終層 ConvNeXt
V2-H 最終層 SwinV2-L Fine-Turning ViT-H/14 Fine-Turning ConvNeXt V2-H FT ViT-L/16 FT submit
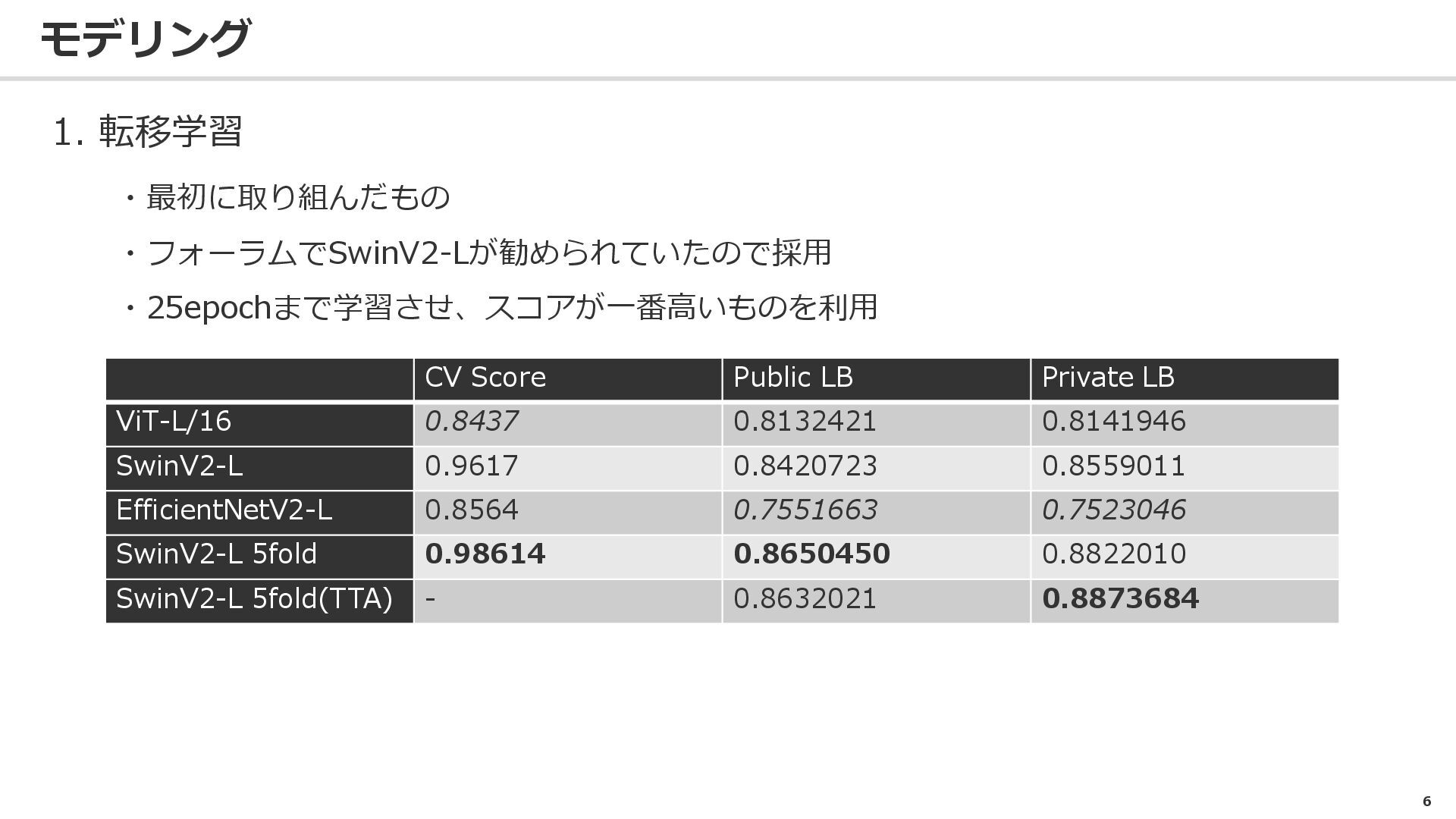
6 モデリング 1. 転移学習 ・最初に取り組んだもの ・フォーラムでSwinV2-Lが勧められていたので採用 ・25epochまで学習させ、スコアが一番高いものを利用 CV Score Public
LB Private LB ViT-L/16 0.8437 0.8132421 0.8141946 SwinV2-L 0.9617 0.8420723 0.8559011 EfficientNetV2-L 0.8564 0.7551663 0.7523046 SwinV2-L 5fold 0.98614 0.8650450 0.8822010 SwinV2-L 5fold(TTA) - 0.8632021 0.8873684
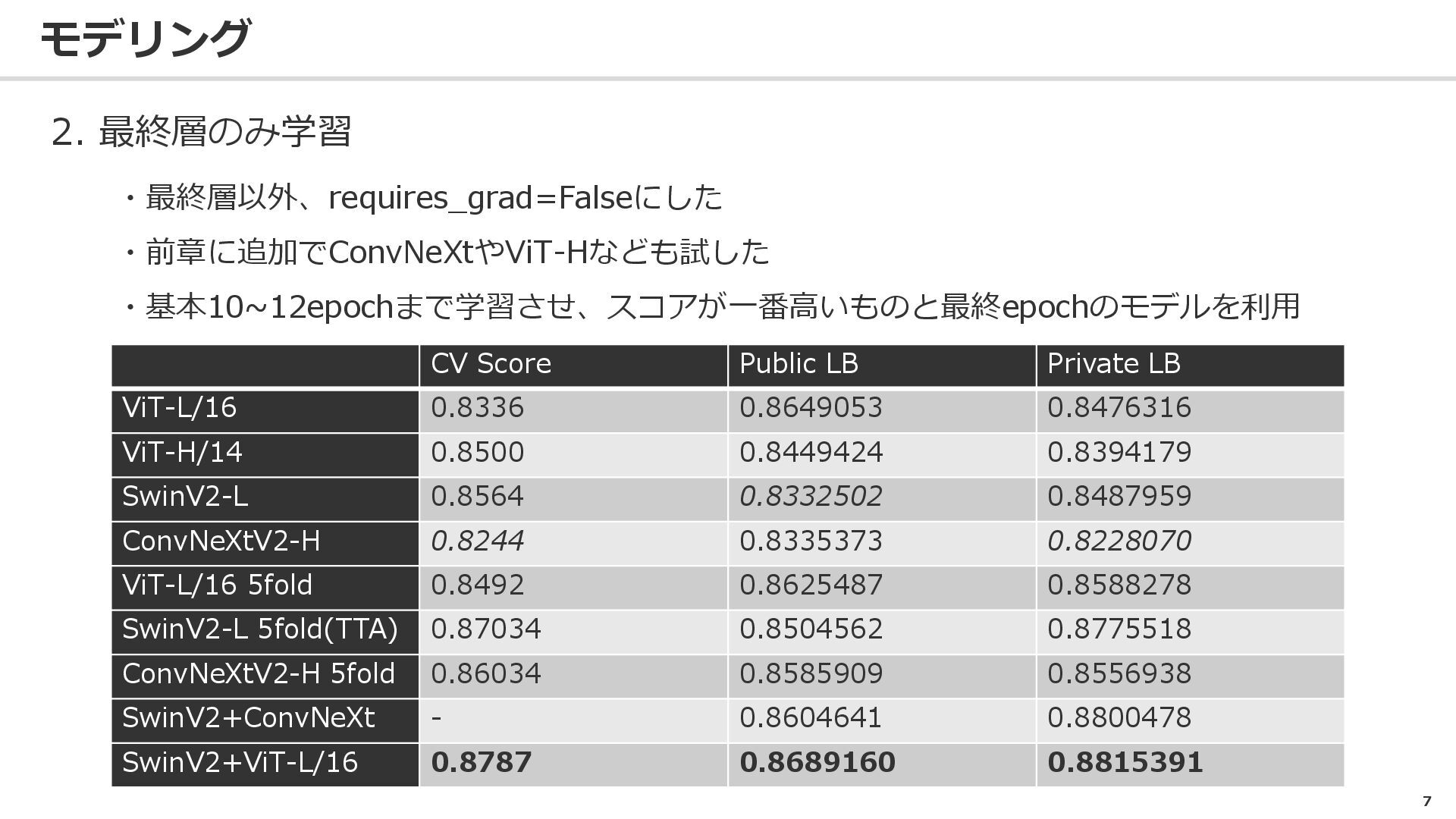
7 モデリング 2. 最終層のみ学習 ・最終層以外、requires_grad=Falseにした ・前章に追加でConvNeXtやViT-Hなども試した ・基本10~12epochまで学習させ、スコアが一番高いものと最終epochのモデルを利用 CV Score Public
LB Private LB ViT-L/16 0.8336 0.8649053 0.8476316 ViT-H/14 0.8500 0.8449424 0.8394179 SwinV2-L 0.8564 0.8332502 0.8487959 ConvNeXtV2-H 0.8244 0.8335373 0.8228070 ViT-L/16 5fold 0.8492 0.8625487 0.8588278 SwinV2-L 5fold(TTA) 0.87034 0.8504562 0.8775518 ConvNeXtV2-H 5fold 0.86034 0.8585909 0.8556938 SwinV2+ConvNeXt - 0.8604641 0.8800478 SwinV2+ViT-L/16 0.8787 0.8689160 0.8815391
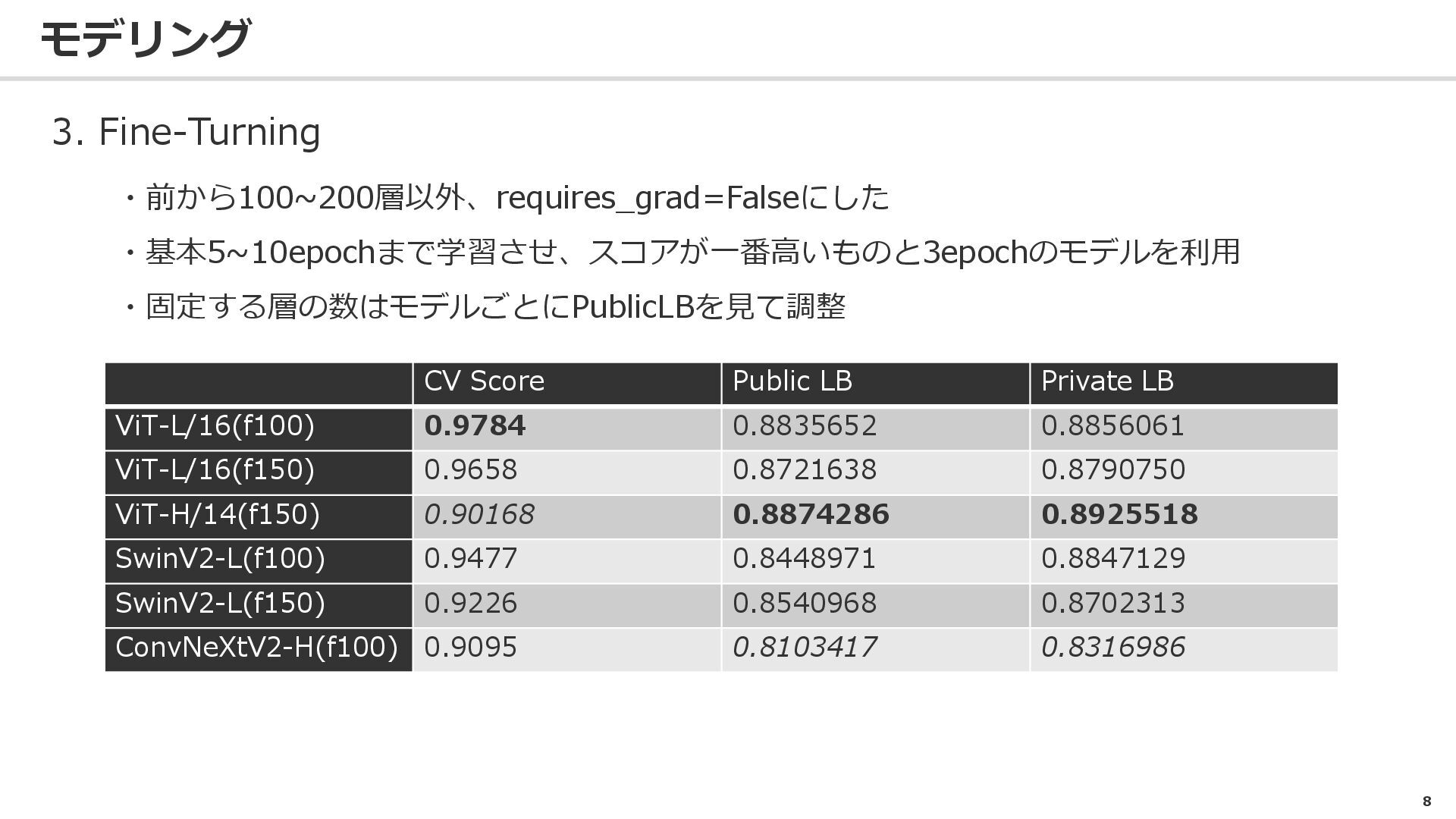
8 モデリング 3. Fine-Turning ・前から100~200層以外、requires_grad=Falseにした ・基本5~10epochまで学習させ、スコアが一番高いものと3epochのモデルを利用 ・固定する層の数はモデルごとにPublicLBを見て調整 CV Score Public
LB Private LB ViT-L/16(f100) 0.9784 0.8835652 0.8856061 ViT-L/16(f150) 0.9658 0.8721638 0.8790750 ViT-H/14(f150) 0.90168 0.8874286 0.8925518 SwinV2-L(f100) 0.9477 0.8448971 0.8847129 SwinV2-L(f150) 0.9226 0.8540968 0.8702313 ConvNeXtV2-H(f100) 0.9095 0.8103417 0.8316986
9 アンサンブル ・テーブルコンペの経験から多彩なモデルを採用 ・Cross Validation ・Seed Averaging ・KFoldのtrainとvalを逆転させたものも利用 ・FTだけではなく、過去の転移学習や最終層のみも混ぜたアンサンブルも実施 Public
LB Private LB ViT-L/16 5fold 0.8845811 0.8856699 ViT-L/16 rev 5fold 0.8821263 0.8852552 ViT-L/16+SwinV2-L (24models) 0.8895662 0.8936762 ViT-L/16+ViT-H/14+SwinV2-L (33models) 0.8954349 0.8967305 ViT-L/16+ViT-H/14+SwinV2-L+ConvNeXt-H (60models)* 0.8964319 0.8992185 ViT-L/16+ViT-H/14+SwinV2-L+ConvNeXt-H (77models)* 0.8961978 0.8997608 ViT-L/16+ViT-H/14+SwinV2-L+ConvNeXt-H FT (57models) 0.8962280 0.8987081
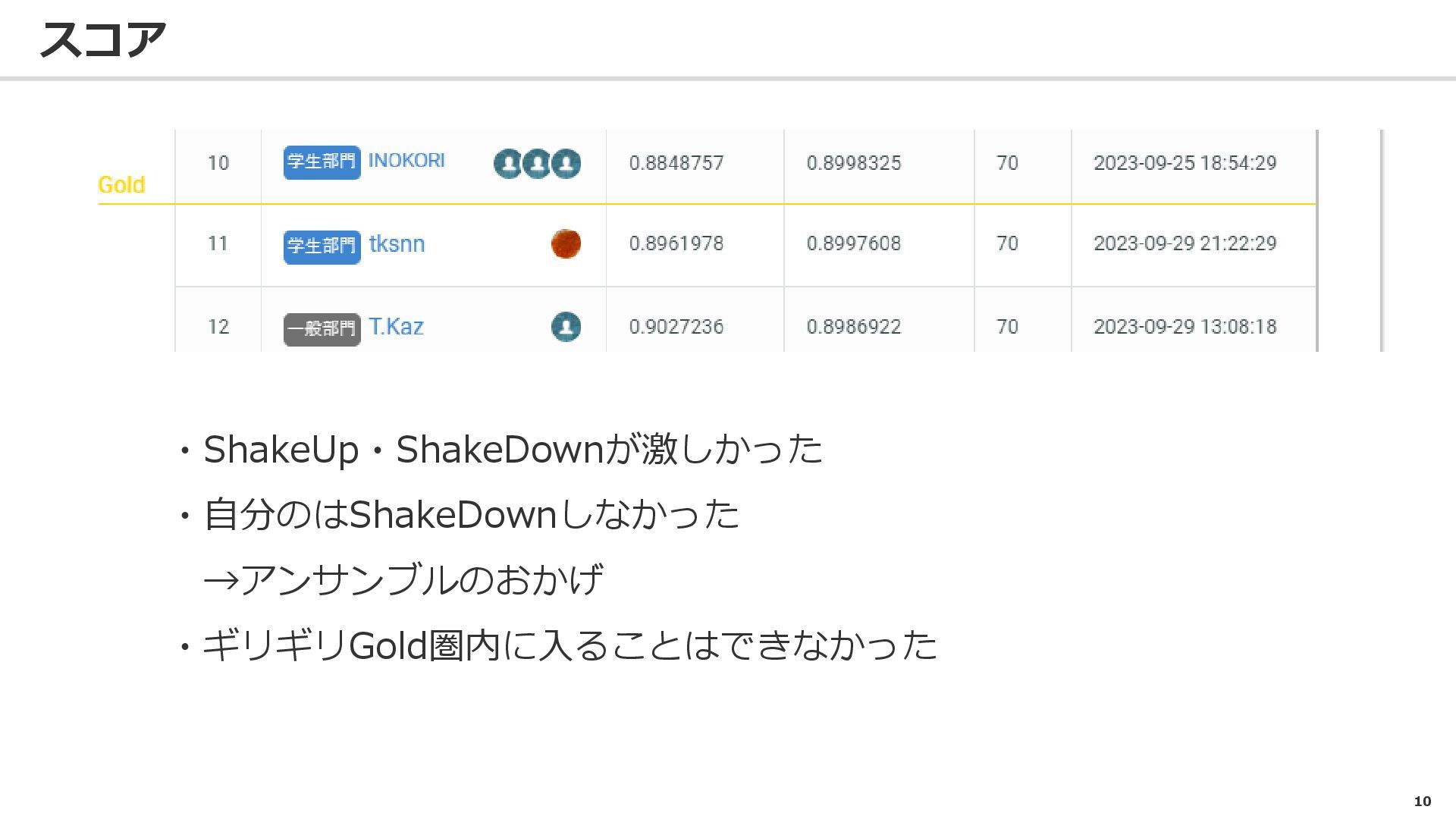
10 スコア ・ShakeUp・ShakeDownが激しかった ・自分のはShakeDownしなかった →アンサンブルのおかげ ・ギリギリGold圏内に入ることはできなかった
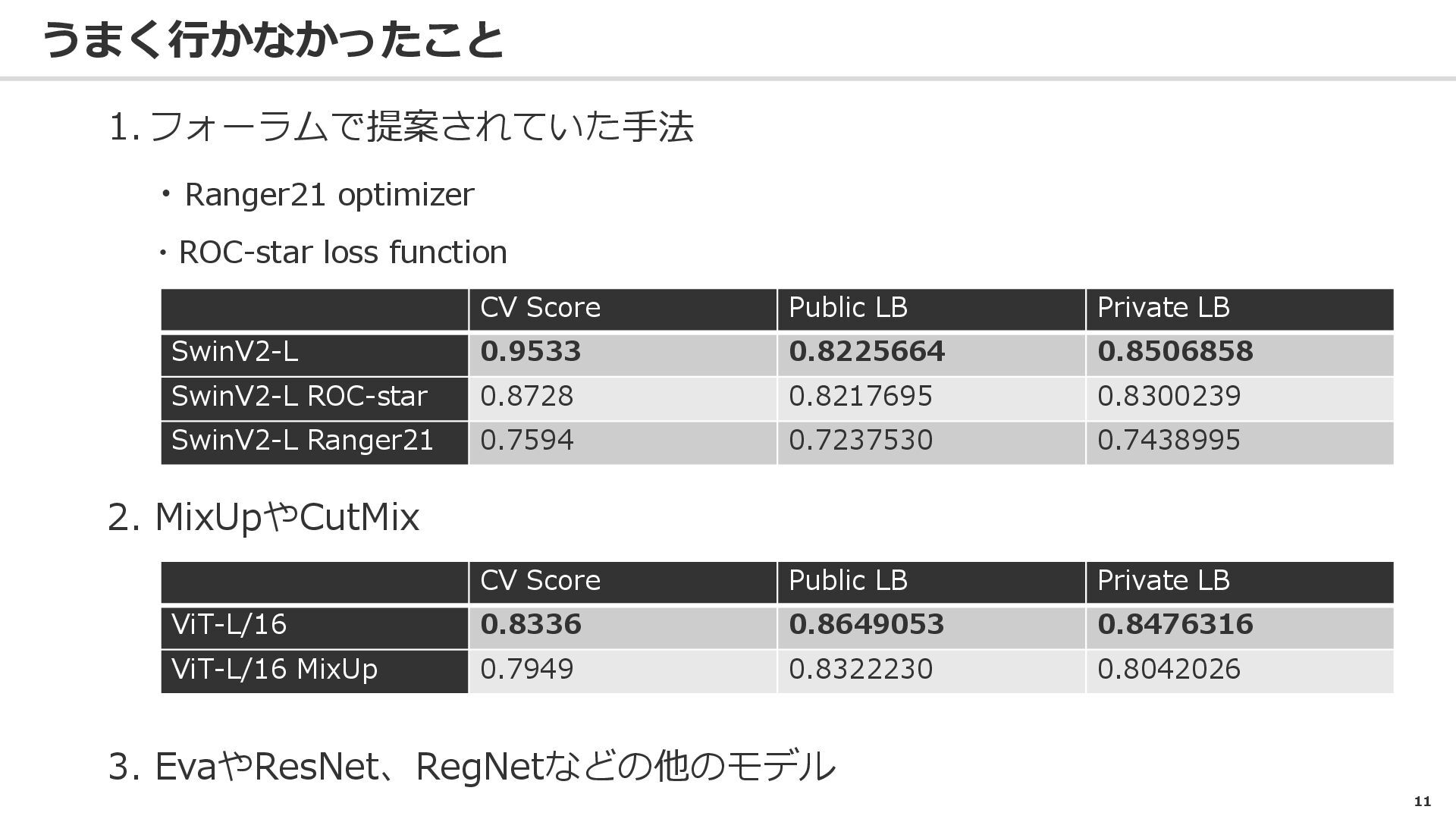
11 うまく行かなかったこと 1. フォーラムで提案されていた手法 ・Ranger21 optimizer ・ROC-star loss function CV
Score Public LB Private LB SwinV2-L 0.9533 0.8225664 0.8506858 SwinV2-L ROC-star 0.8728 0.8217695 0.8300239 SwinV2-L Ranger21 0.7594 0.7237530 0.7438995 2. MixUpやCutMix CV Score Public LB Private LB ViT-L/16 0.8336 0.8649053 0.8476316 ViT-L/16 MixUp 0.7949 0.8322230 0.8042026 3. EvaやResNet、RegNetなどの他のモデル
12 精度向上のために 1. TTAの採用 2. 誤判定を減らす ・人間でも判断できない画像を学習用から消す・外部のデータセットの利用 ・argumentationの種類を増やす ・ノイズ削減・超解像処理 true:1
pred:0.01 train/0983.png true:1 pred:0.04 train/0860.png true:0 pred:0.97 train/1685.png スープの素? 何かわからない レトルトパッケージ 透明ボトル true:1 pred:0.01 train/1644.png 3. 文字の認識・キャプションの追加 4. 他のアンサンブル方法の検討(stackingやbagging) 5. batch_sizeなどハイパラの調整
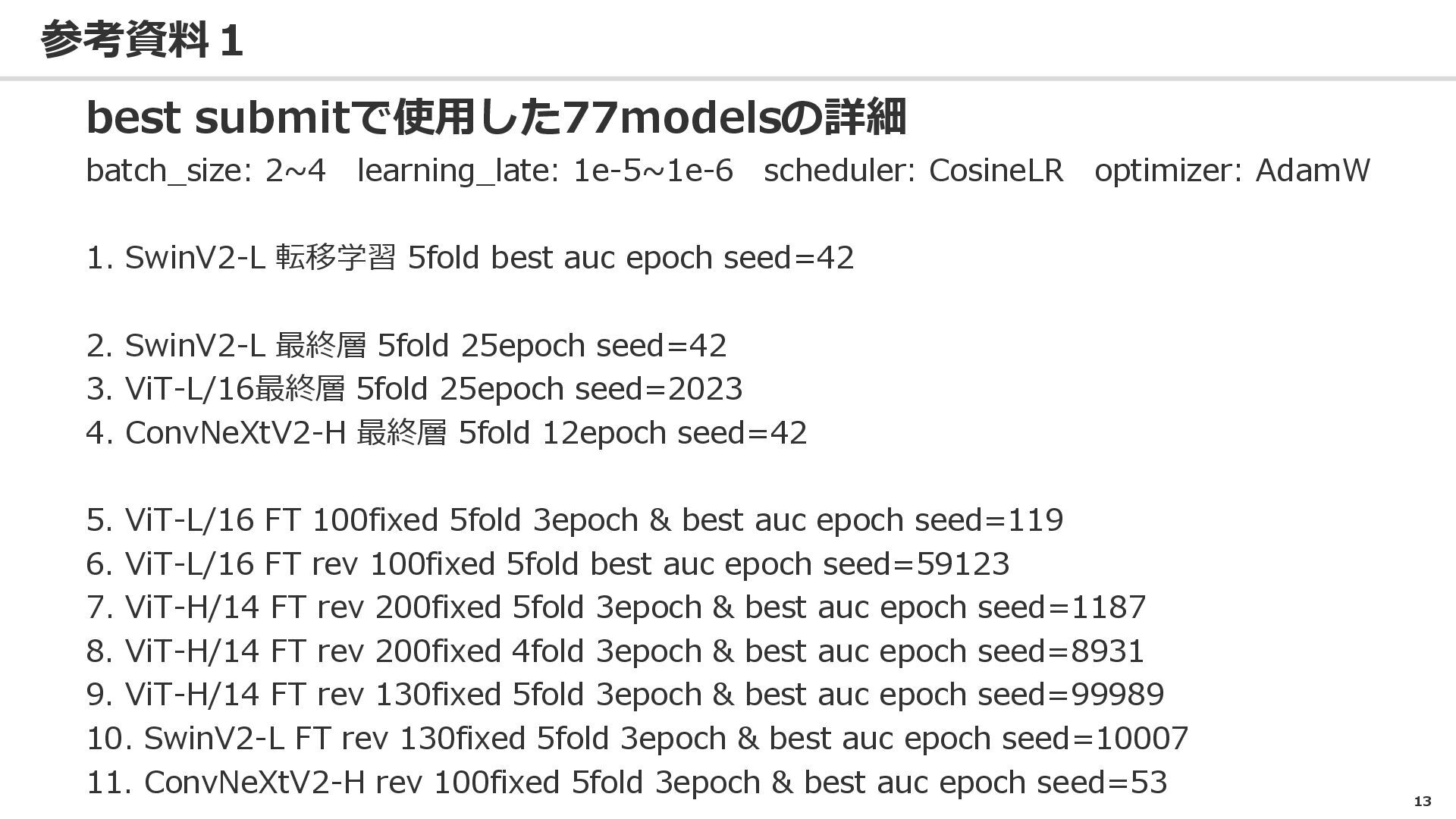
13 参考資料1 best submitで使用した77modelsの詳細 batch_size: 2~4 learning_late: 1e-5~1e-6 scheduler: CosineLR
optimizer: AdamW 1. SwinV2-L 転移学習 5fold best auc epoch seed=42 2. SwinV2-L 最終層 5fold 25epoch seed=42 3. ViT-L/16最終層 5fold 25epoch seed=2023 4. ConvNeXtV2-H 最終層 5fold 12epoch seed=42 5. ViT-L/16 FT 100fixed 5fold 3epoch & best auc epoch seed=119 6. ViT-L/16 FT rev 100fixed 5fold best auc epoch seed=59123 7. ViT-H/14 FT rev 200fixed 5fold 3epoch & best auc epoch seed=1187 8. ViT-H/14 FT rev 200fixed 4fold 3epoch & best auc epoch seed=8931 9. ViT-H/14 FT rev 130fixed 5fold 3epoch & best auc epoch seed=99989 10. SwinV2-L FT rev 130fixed 5fold 3epoch & best auc epoch seed=10007 11. ConvNeXtV2-H rev 100fixed 5fold 3epoch & best auc epoch seed=53
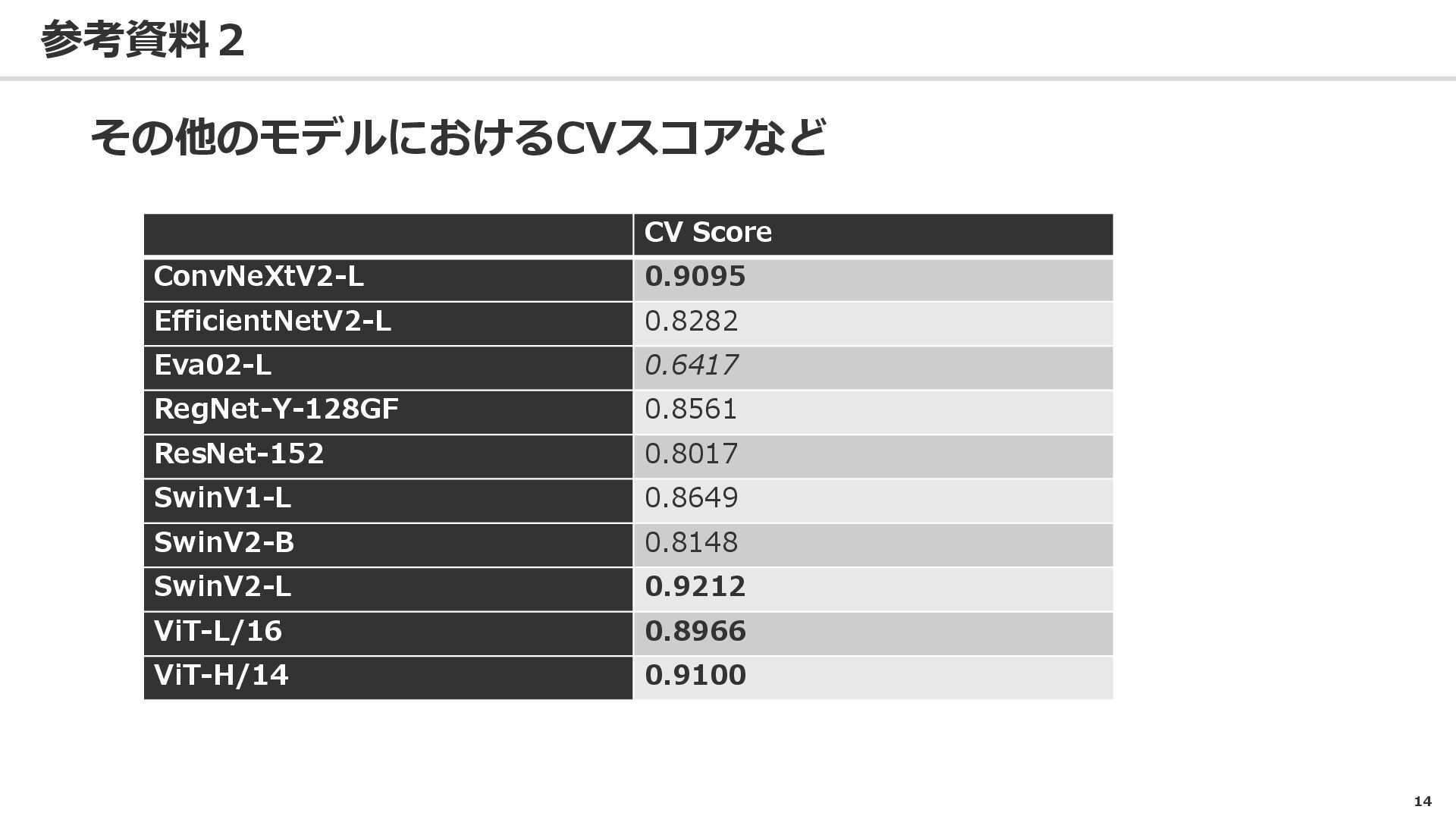
14 参考資料2 その他のモデルにおけるCVスコアなど CV Score ConvNeXtV2-L 0.9095 EfficientNetV2-L 0.8282 Eva02-L
0.6417 RegNet-Y-128GF 0.8561 ResNet-152 0.8017 SwinV1-L 0.8649 SwinV2-B 0.8148 SwinV2-L 0.9212 ViT-L/16 0.8966 ViT-H/14 0.9100
15 参考資料3 開発の環境について ツール PyTorch, GitHub 環境 オンプレのNVIDIA RTX 3080
GCPのNVIDIA Tesla T4 GCPのNVIDIA L4 実行時間(NVIDIA L4) 処理速度(sec/epoch) 推定速度(sec/image) ViT-L/16 262 0.065 ViT-H/14 462 0.138 SwinV2-L 151 0.056 ConvNeXtV2-H 53 0.026
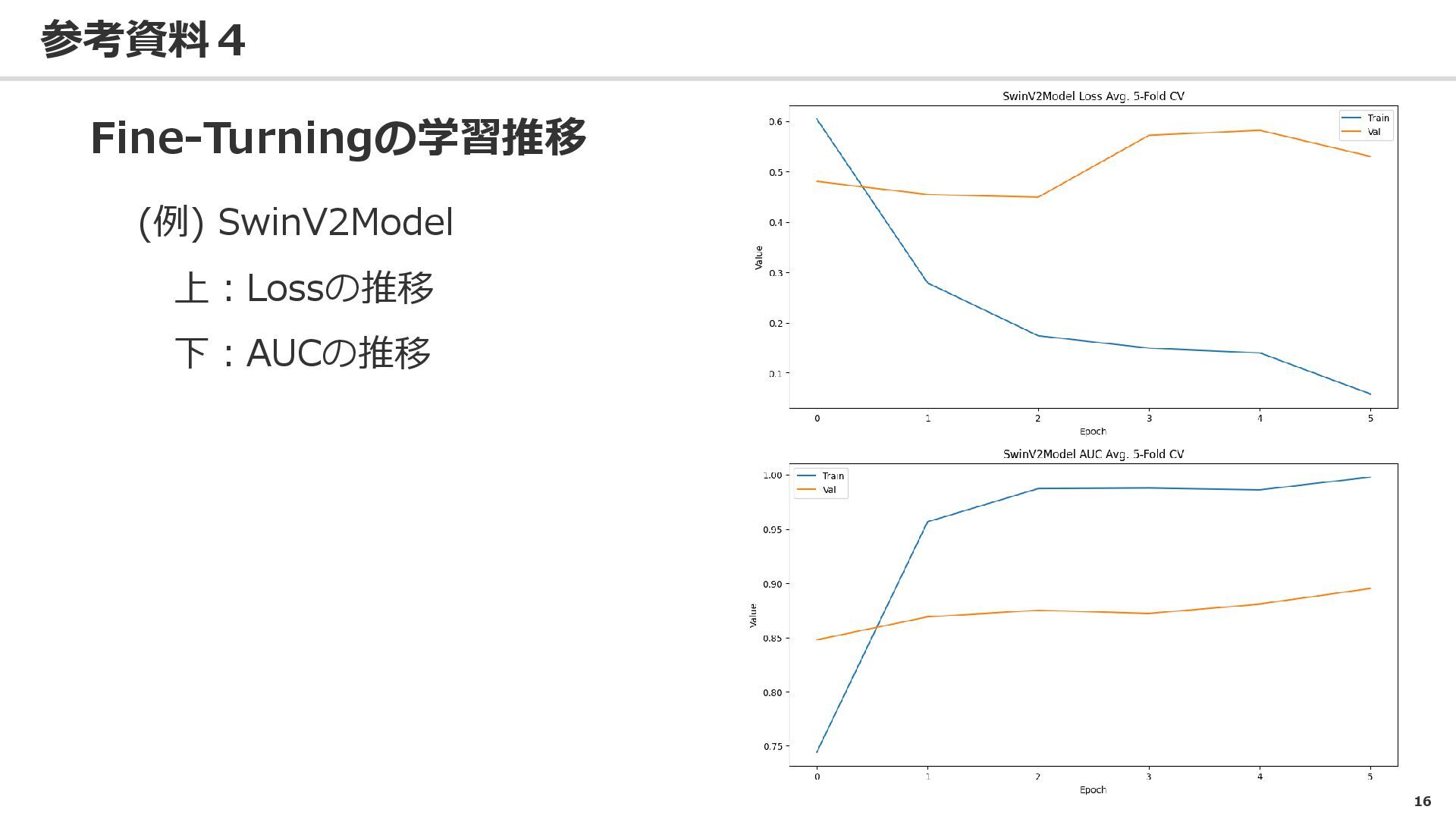
16 参考資料4 Fine-Turningの学習推移 (例) SwinV2Model 上:Lossの推移 下:AUCの推移
17 参考文献 VIT_L_16 Baseline [CV: 0.9441 LB:0.832611](フォーラム) (https://signate.jp/competitions/1106/discussions/vit-l-16-baseline-cv-09441-lb0832611) PyTorchでクロスバリデーション(交差検証) (https://qiita.com/ground0state/items/ad879a84bf946ef94da8)
PyTorchとEfficientNetV2で作る画像分類モデル (https://zenn.dev/aidemy/articles/f851fb091dbb23) Models and pre-trained weights (https://pytorch.org/vision/stable/models.html) kaggle1位の解析手法 「Cdiscountの画像分類チャレンジ」1コンペの概要 (https://data-analysis-stats.jp/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92/) Kaggleの画像コンペに初心者だけでチーム組んで挑んでみたら銅メダル取れた話 (https://qiita.com/RedBull_7584/items/97a1fefc8d00d6d4d520) Kaggleに挑戦 ~鯨とイルカの画像から個体を識別する~ (https://www.nri-digital.jp/tech/20230418-13269/) DeepLearningで画像分類を学習させる (https://www.tetsumag.com/2021/01/11/265/) 【Pytorch】SwinTransformerでLet's画像分類! (https://qiita.com/Kentea/items/b0e3ae03834d65f6ca41) TTA(Test-Time Augmentation)の効果をいかに引き上げるか (https://blog.bassbone.tokyo/archives/725) 複数の画像を組み合わせるオーグメンテーション (mixup, CutMix) (https://ohke.hateblo.jp/entry/2020/07/11/230000) Intro2DL : NNにおける損失関数 (https://zenn.dev/yoshida0312/articles/3b757e81ee42ec) Data Augmentation どれ使おう?ってときに役立つページなど (https://www.guruguru.science/competitions/17/discussions/9382fbc5-73b6-47b9-8571-77ed3fd8763b/) Vision Transformerモデルのファインチューニングを試す【ViT解説】 (https://farml1.com/vit/)
18 参考文献 An Image is Worth 16x16 Words: Transformers for
Image Recognition at Scale (https://arxiv.org/abs/2010.11929) Swin Transformer V2: Scaling Up Capacity and Resolution (https://arxiv.org/pdf/2111.09883v2.pdf) ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders (https://arxiv.org/abs/2301.00808) hongyi-zhang/mixup (https://github.com/hongyi-zhang/mixup) iridiumblue/roc-star (https://github.com/iridiumblue/roc-star)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 (https://signate.jp/competitions/1106/discussions/vit-l-16-baseline-cv-09441-lb0832611) PyTorchでクロスバリデーション(交差検証) (https://qiita.com/ground0state/items/ad879a84bf946ef94da8)](https://files.speakerdeck.com/presentations/69e82daa6f904578b8995aa88df8249b/slide_17.jpg){kind=link}
{kind=link}