funkcji jako rezultat wywołania funkcji 3. Przypisanie funkcji do zmiennej def f1(g: Int => Int): Int = g(2) f1(x => 3 * x) def f2(x: Int): Int => Int = { y: Int => y + x } f2(5)(4) val f3 = f2(10) f3(20)
match { case Nil => 0 case x :: xs if pred(x) => 1 + countBy(xs, pred) case _ :: xs => countBy(xs, pred) } def sumBy[A](list: List[A], f: A => Double): Double = list match { case Nil => 0.0 case x :: xs => f(x) + sumBy(xs, f) }
0.0): Double = list match { case Nil => acc case x :: xs => sumBy(xs, f, f(x) + acc) } def countBy[A](list: List[A], pred: A => Bool, acc: Int = 0): Int = list match { case Nil => acc case x :: xs if pred(x) => countBy(xs, pred, 1 + acc) case _ :: xs => countBy(xs, pred, acc) }
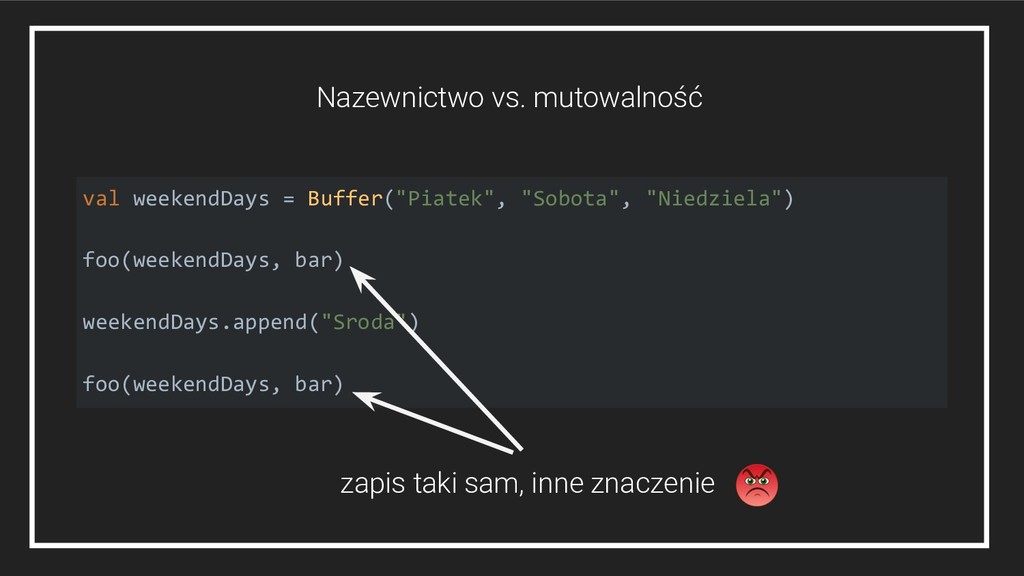
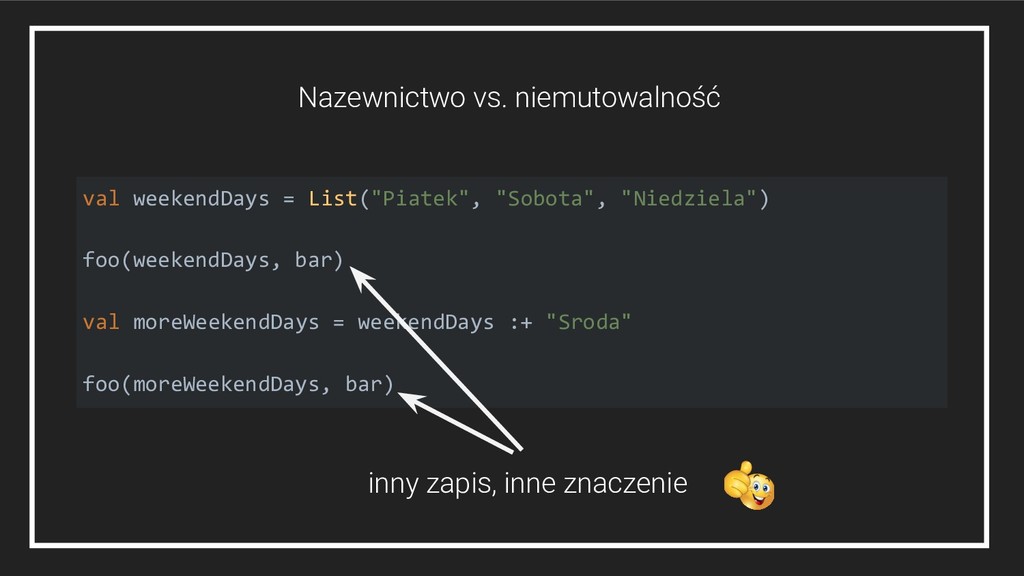
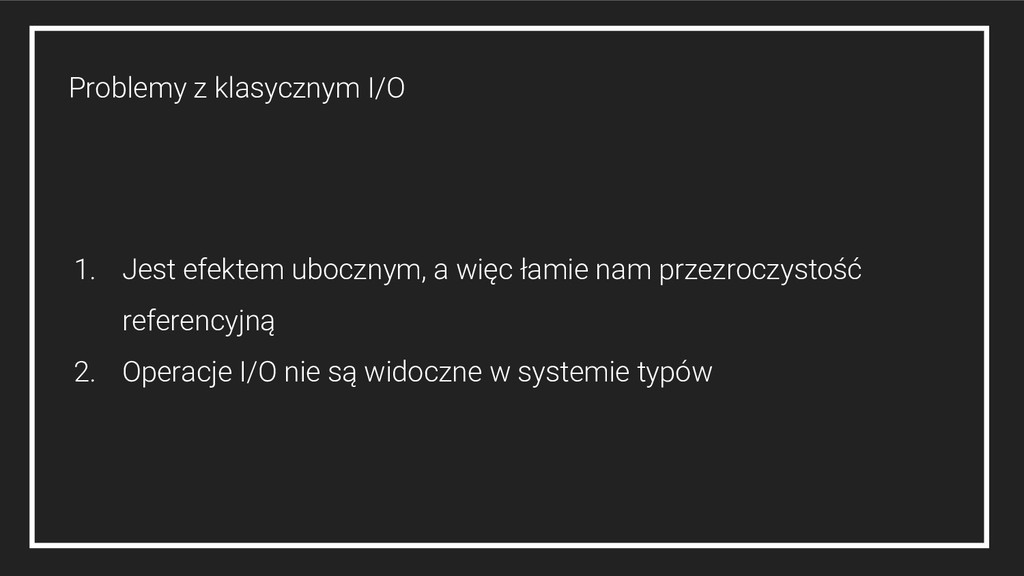
3. Większość struktur danych posiada efektywne niemutowalne odpowiedniki 4. Niemutowalne struktury mają swoje osobliwości, np: a. efektywny dostęp do początku listy b. złączanie list w czasie liniowym - wymaga przebudowania pierwszej z nich
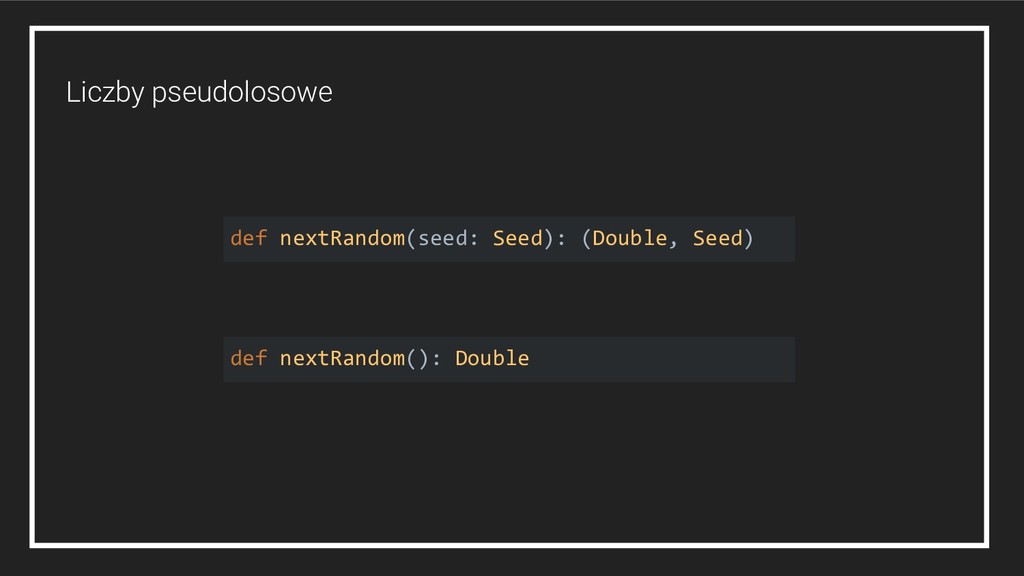
Abstrakcje numeryczne 3. Mapowanie schematu bazy danych 4. Generowanie losowych wartości 5. Abstrakcje w teorii kategorii (Functor, Monad, Applicative, etc.) 6. Walidacje strukturalne* 7. Transformacje danych*
i utrzymywanie ogromnych ilości kodu 2. Jednolita implementacja wszystkich instancji 3. Wiele bibliotek już teraz oferuje gotowe reguły do generycznej derywacji (wystarczy jeden import i voilà!) 4. Type safety
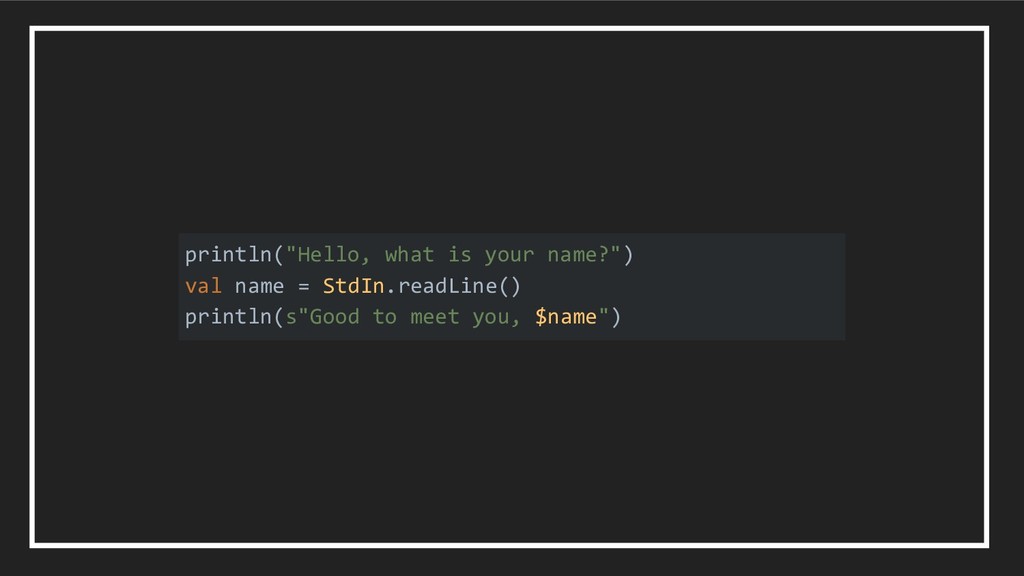
=> A) extends Console[A] case class PrintLine[A](line: String, rest: Console[A]) extends Console[A] case class ReadLine[A](rest: String => Console[A]) extends Console[A] PrintLine("Hello, what is your name?", ReadLine(name => PrintLine(s"Good to meet you, $name") ) )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Lokalna mutowalność def sort(list: List[Int]): List[Int] = { val arr](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_21.jpg){kind=link}
{kind=link}
: List[A] = xs match { case Nil](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_23.jpg){kind=link}
: List[A] = list](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_24.jpg){kind=link}
:](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
: Int = list](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
![trait List[A] { def foldLeft[B](z: B)(op: (B, A) => B):](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_31.jpg){kind=link}
: Double = list.foldLeft(0.0)](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_32.jpg){kind=link}
![trait List[A] { def foldLeft[B](z: B)(op: (B, A) => B):](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![1. Definicja klasy typów to sparametryzowany interfejs trait Show[A] {](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Derywacja instancji klas typów implicit def pairShow[A: Show, B: Show]:](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_47.jpg){kind=link}
![Derywacja instancji klas typów intShow boolShow fooShow pairShow implicitly[Show[(Int, Foo)]]](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_48.jpg){kind=link}
![Generyczna derywacja klas typów int bool genTC implicitly[TC[Foo]] string double](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_49.jpg){kind=link}
![Generyczna derywacja klas typów int bool genTC implicitly[TC[Foo]] string double](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
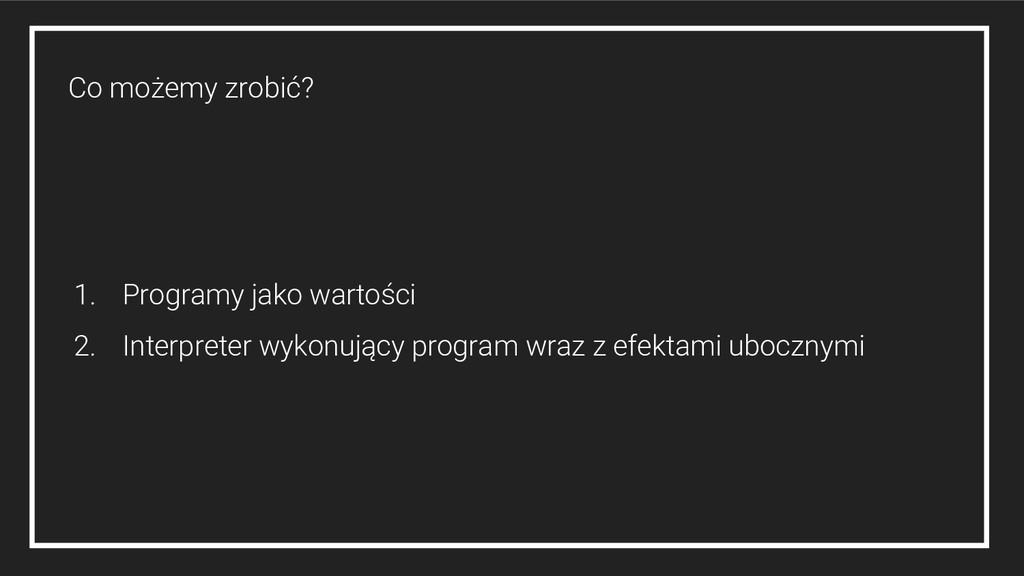
![Programy jako wartości sealed trait Console[+A] case class Return[A](value: ()](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_58.jpg){kind=link}
: A = program match](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_59.jpg){kind=link}
![Programy jako wartości val program: Console[String] = for { _](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_60.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![https://github.com/scalalandio/chimney trait Transformer[From, To] { def transform(src: From): To }](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_66.jpg){kind=link}
![https://github.com/scalalandio/chimney import io.scalaland.chimney.dsl._ val event = command.into[CoffeeMade] .withFieldRenamed(_.addict, _.forAddict) .withFieldComputed(_.at,](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_67.jpg){kind=link}
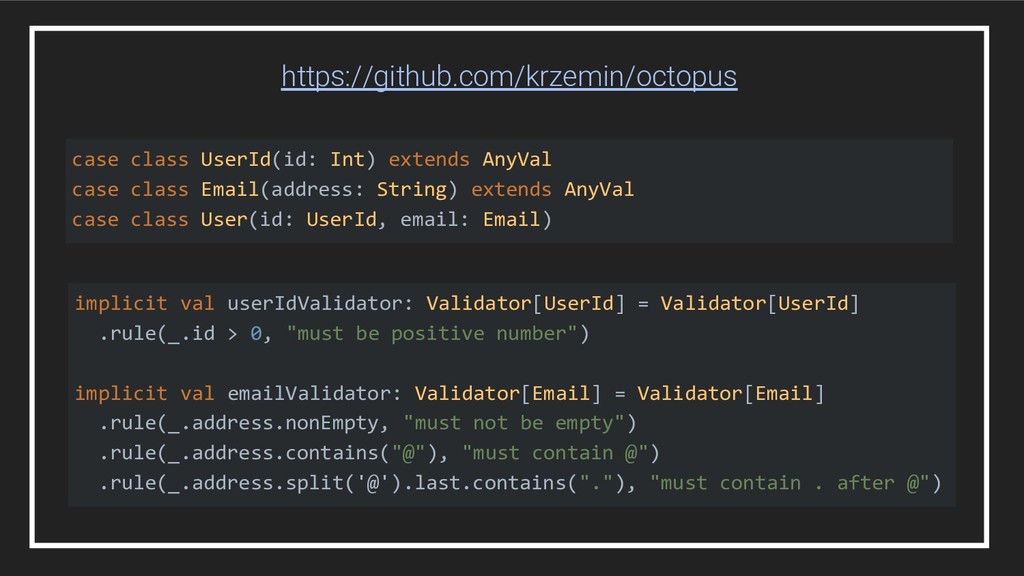
![trait Validator[T] { def validate(obj: T): List[ValidationError] } https://github.com/krzemin/octopus](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_68.jpg){kind=link}
:](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_69.jpg){kind=link}
{kind=link}
![val user1 = User(UserId(1), Email("[email protected]")) user1.isValid // true user1.validate.toEither //](https://files.speakerdeck.com/presentations/5a83bb366fda447a8fd6ee039e052e6e/slide_71.jpg){kind=link}