Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Ameba Falco Security
Search
Kumo Ishikawa
September 22, 2025
Programming
83
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Ameba Falco Security
Kumo Ishikawa
September 22, 2025
More Decks by Kumo Ishikawa
See All by Kumo Ishikawa
Platform Engineering as a Product: Criteria for Improvement and Multi-Tenant Design
kumorn5s
0
570
「OSSがあるなら自作するな」は AI時代も正しいか ── Build vs Adopt の新しい判断基準
kumorn5s
7
3.4k
Efficient EKS Pod Communication: A Practical Implementation Using Cloudflare Zero Trust and CoreDNS
kumorn5s
2
440
PEK2025: Multi-Tenancy Design in Ameba
kumorn5s
1
1.6k
Ameba CI/CD: Terraform and Argo CD Improvements
kumorn5s
9
3.2k
Amebaにおける Platform Engineeringの実践
kumorn5s
7
1.6k
同一クラスタ上でのFluxCDとArgoCDのリソース最適化の話
kumorn5s
0
690
HA構成のArgoCD パフォーマンス最適化への道
kumorn5s
3
720
Other Decks in Programming
See All in Programming
ECSアプリログをFireLensでコスト削減しようとしたけど諦めた話 in Fargate×Node.js
akihisaikeda
2
4.2k
アルゴリズムは何を圧縮しているのか ─ Haskell から育った「圧縮代数」というメンタルモデル
naoya
14
2.8k
気圧・高度・GPSを記録&可視化するアプリ「Koudo」を作った話
hjmkth
1
340
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
0
1.4k
IBM Bobを活用したレガシーアプリの最新化
oniak3ibm
PRO
1
240
dRuby over BLE
makicamel
2
410
例外の正しい扱い方 そのエラー try-catchして大丈夫?
jinwatanabe
0
340
ローカルLLMでどこまでコードが書けるか -拡張版 / How much code can be written on a local LLM Extended
kishida
12
4.6k
LaravelLive Japan の裏方のすべて — 第188回 PHP勉強会@東京 (2026-06-24)
suguruooki
2
150
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
AI 輔助遺留系統現代化的經驗分享
jame2408
1
1.2k
Creating Composable Callables in Contemporary C++
rollbear
0
190
Featured
See All Featured
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
340
How to Think Like a Performance Engineer
csswizardry
28
2.7k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
300
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
380
Code Review Best Practice
trishagee
74
20k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
250
1.3M
Side Projects
sachag
455
43k
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
180
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
ラッコキーワード サービス紹介資料
rakko
1
3.8M
Transcript
AmebaのFalco活用事例から見る 継続可能なセキュリティ運用 石川 雲 / Kumo Ishikawa
本セッション前半について 話す内容 1. Amebaの基盤(Ameba Platform)のセキュリティ 2. Kubernetesセキュリティ 3. Falcoの概要・運用に関するTips・ベストプラクティス 話さない内容
1. Ameba Platformの詳細な話 興味があれば、PEFM#12をご覧ください 2. Falcoの詳しい仕組み QiitaでFalcoシリーズ記事を執筆中
❏横断組織 Service Reliability Group (SRG)所属 ❏Ameba Platform 担当 ❏得意領域 Security
Multi-Tenant・Zero Trust・Runtime Monitoring CI/CD ArgoCD・FluxCD・Terraform 今年Kubestronautになった 石川 雲 Kumo Ishikawa
0. 背景
背景 Amebaのこれまでのセキュリティ施策 • 統一認証認可基盤によるアカウント管理 全Cloud/Dev Tools Accountフェデレーション連携、ロール管理 • 全社規模のCSPM導入 全てのCloud
Account対象、検出・対応体制 • コンテナセキュリティ ベースイメージの選定・イメージスキャン • Pod Security ガードレールの適用 全てのデプロイマニフェストへPod Securityの設定展開
背景 さらに強化しなければならない理由 • 直近国内外のセキュリティインシデント頻発 • 前回の脅威モデリングが2022年、新しい仕組みを入れる必要があった • 社内のセキュリティ強化を促す取り組みがあった CyberAgent Security
CREST(クレスト)制度
背景 CyberAgent社内新セキュリティ評価制度 ◦ Security CREST制度導入(AWS協力・NIST CSF 2.0ベース) ◦ 成熟度1〜4で段階評価し、現状から目標への成長を促す運用 ◦
エンジニアによる高度な取り組みを奨励し、光を当ててモチベーションを高める
背景 Amebaセキュリティ評価で見えた課題 1. 未報告のイメージ脆弱性を入口とする攻撃を防げられない ◦ 対策: 一般的な攻撃パターンにあるプロセスアクティビティを検知 2. 内部からの攻撃を防げれない ◦
対策: デバッグ・運用行為以外のアクティビティを検知 3. コンテナランタイムレベルの攻撃に関するモニタリング手段がない ◦ 対策: 攻撃されたら検知できる仕組みを導入する
背景 Amebaセキュリティ評価で見えた課題 1. 未報告のイメージ脆弱性を入口とする攻撃を防げられない ◦ CVSS未報告であるため、対策はほぼ不可能 ◦ 一般的な攻撃を防げる事前防御を取る ◦ 一般的な攻撃パターンにあるプロセスアクティビティを検知
背景 Amebaセキュリティ評価で見えた課題 2. 内部からの攻撃を防げれない ◦ 内部に悪意があれば、何をしても防げられない ◦ デバッグ・運用行為以外のアクティビティを事後検知
背景 Amebaセキュリティ評価で見えた課題 3. コンテナランタイムレベルの攻撃に関するモニタリング手段がない ◦ 既存のセキュリティ対策は攻撃手段をなくす事前防御 ▪ Pod Security Standards・RuntimeClassなど
◦ 事前防御を超えた攻撃を検知したい (事後検知) ▪ Kubernetes Native機能にない ▪ Falco
復習 - K8s Security 通常のK8s Security対策 • Cluster Security ◦
適切なRBAC・ServiceAccount ◦ 適切なNetwork Policy ◦ コンポーネントセキュリティ設定 (認証・認可・TLS) • Pod Security ◦ 適切なK8s Secrets扱い ◦ イメージ脆弱性対応(サプライチェーン攻撃) ◦ Security Contexts関連設定 ◦ RuntimeClass / Sandbox Podの使用 ◦ Linux Kernel (Seccomp, AppArmor, SELinux)
復習 - K8s Security 通常のK8s Security対策 • Cluster Security ◦
適切なRBAC・ServiceAccount *必要 ◦ 適切なNetwork Policy *必要 ◦ コンポーネントセキュリティ設定 (認証・認可・TLS) *Managedの場合、一部設定済み • Pod Security ◦ 適切なK8s Secrets扱い *必要 ◦ イメージ脆弱性対応(サプライチェーン攻撃) *必要 ◦ Security Contexts関連設定 *必要 ◦ RuntimeClass / Sandbox Podの使用 * 使用事例が少ない ◦ Linux Kernel (Seccomp, AppArmor, SELinux) * Managedの場合、制限がある
復習 - K8s Security 通常のK8s Security対策 • Cluster Security ◦
適切なRBAC・ServiceAccount *必要 ◦ 適切なNetwork Policy *必要 ◦ コンポーネントセキュリティ設定 (認証・認可・TLS) *Managedの場合、一部設定済み • Pod Security ◦ 適切なK8s Secrets扱い *必要 ◦ イメージ脆弱性対応(サプライチェーン攻撃) *必要 ◦ Security Contexts関連設定 *必要 ◦ RuntimeClass / Sandbox Podの使用 * 使用事例が少ない ◦ Linux Kernel (Seccomp, AppArmor, SELinux) * Managedの場合、制限がある コンテナランタイム セキュリティ
復習 - K8s Security ランタイムセキュリティの分類 • Preventive(事前防御) AppArmor, Seccomp, SELinux,
Security Contexts(Linux Capabilities…) Kubernetes v1.25以降: 上記をまとめたPod Security Standards(PSS)が利用可能 RuntimeClass / Sandbox Pod: 不正が発生してもHostへの影響を抑える • Detective(事後検知) Falco: 不正が発生したらイベント記録・エコシステム連携
復習 - K8s Security ランタイムセキュリティの分類 • Preventive(事前防御) AppArmor, Seccomp, SELinux,
Security Contexts(Linux Capabilities…) Kubernetes v1.25以降: 上記をまとめたPod Security Standards(PSS)が利用可能 RuntimeClass / Sandbox Pod: 不正が発生してもHostへの影響を抑える • Detective(事後検知) *K8s Native機能にない Falco: 不正が発生したらイベント記録・エコシステム連携
AmebaにおけるFalcoの導入と構成
Falcoとは ランタイムセキュリティチェックOSSツール • システムコールの監視 ◦ 事前に定義された「通常行われないような操作」を検知し、条件に応じてアラートを発す • 2018年: SysdigがCNCFへ寄贈 •
2024年: CNCF Graduated ◦ (CKSの出題範囲)
Falco Ecosystems 1. Falco Plugin: 多目的のツールへ • システムコール以外もルールベースで検出可能 • RuleSets:
K8s Audit Log、AWS CloudTrail、Docker、Github、Salesforce 2. Falco Sidekick: 全てを繋げる • Chat/Observability/Datastore/SIEM/Functions 計60+種類のツールと連携可能 3. Falco Talon: 検知したら対処する • Pod標記 / Pod削除 / Pod Log/File保存 • Podネットワーク隔離(NetworkPolicy作成) / Functions連携(Lambda/CloudRun)
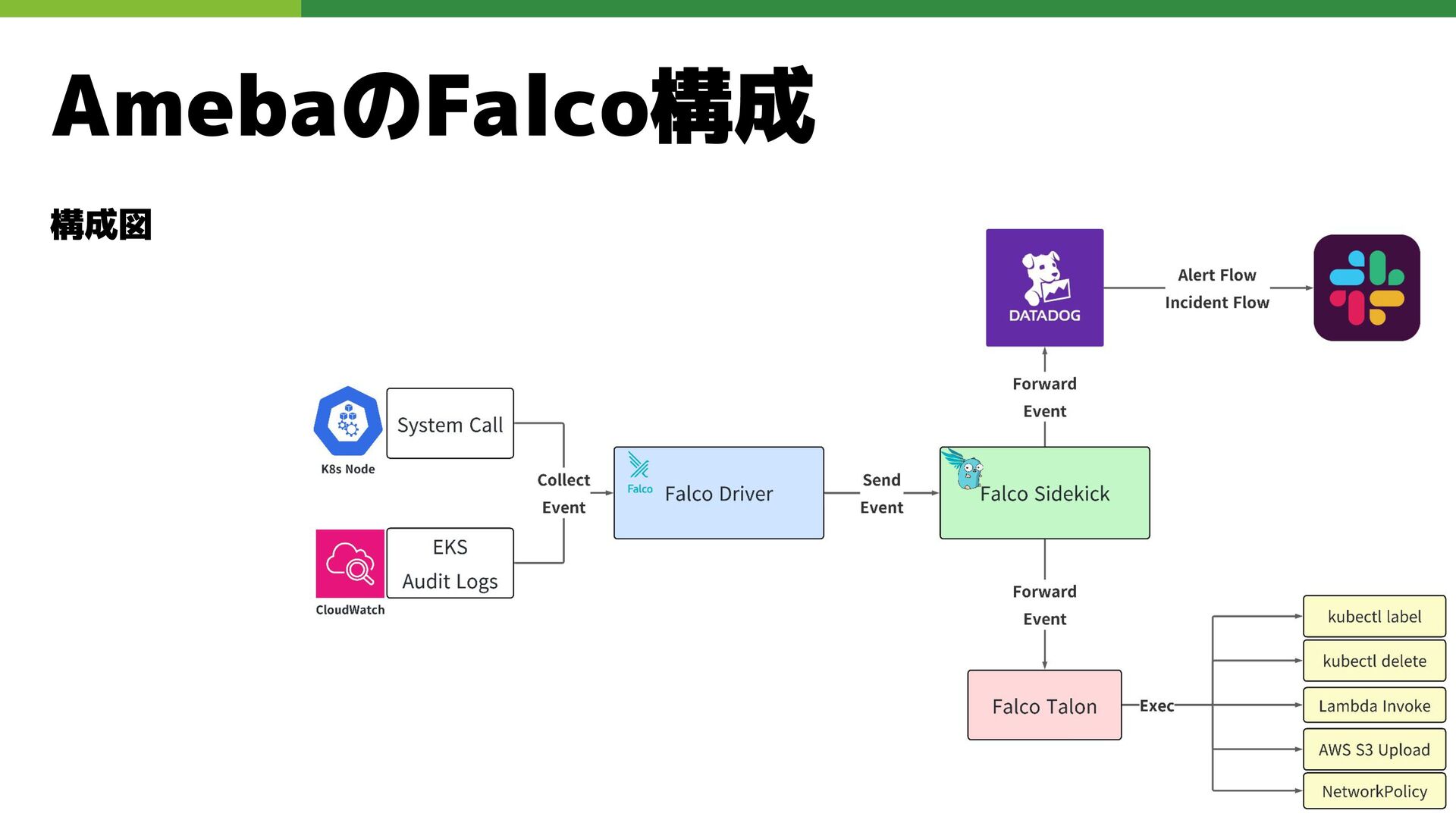
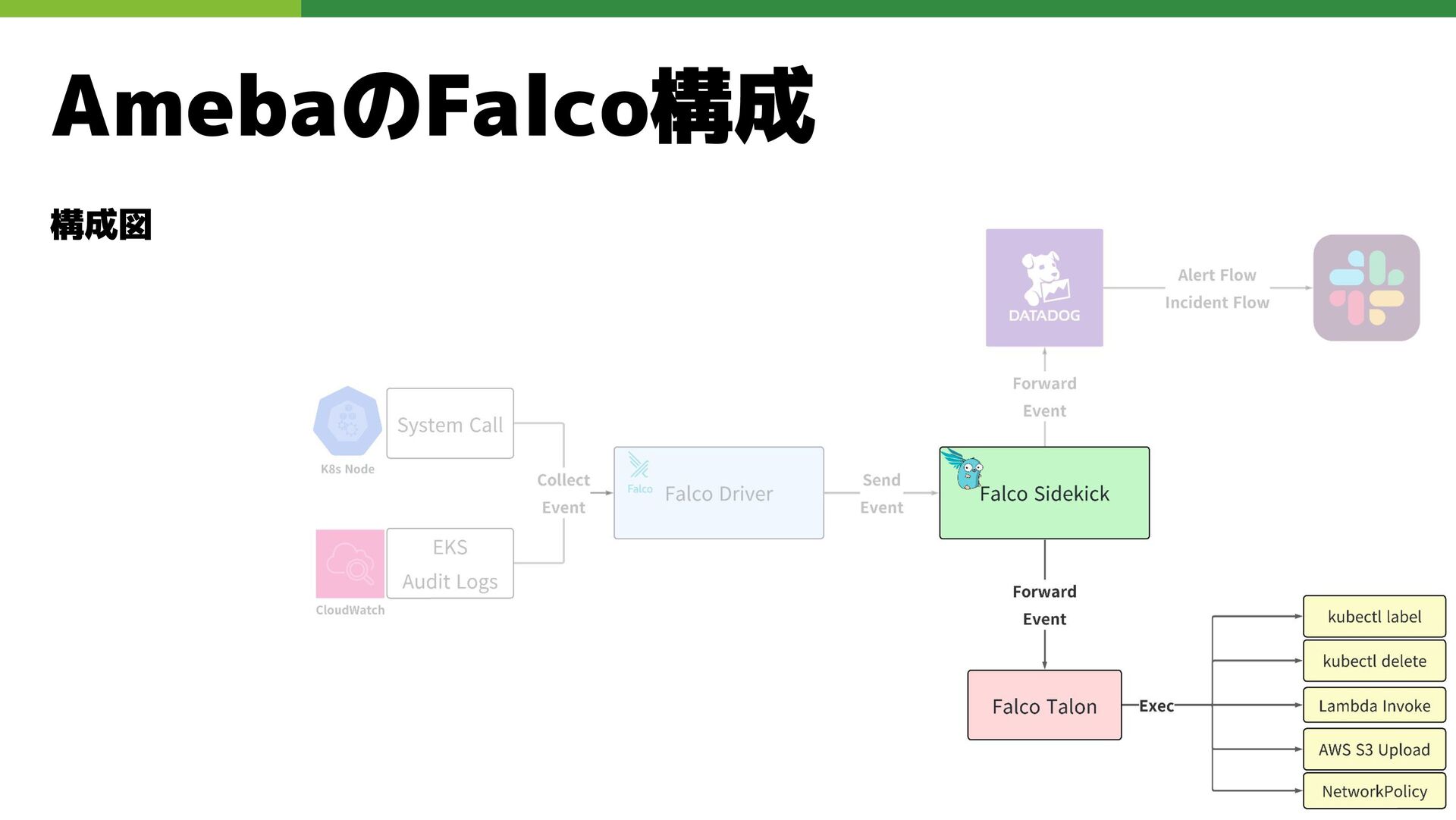
AmebaのFalco構成 構成図
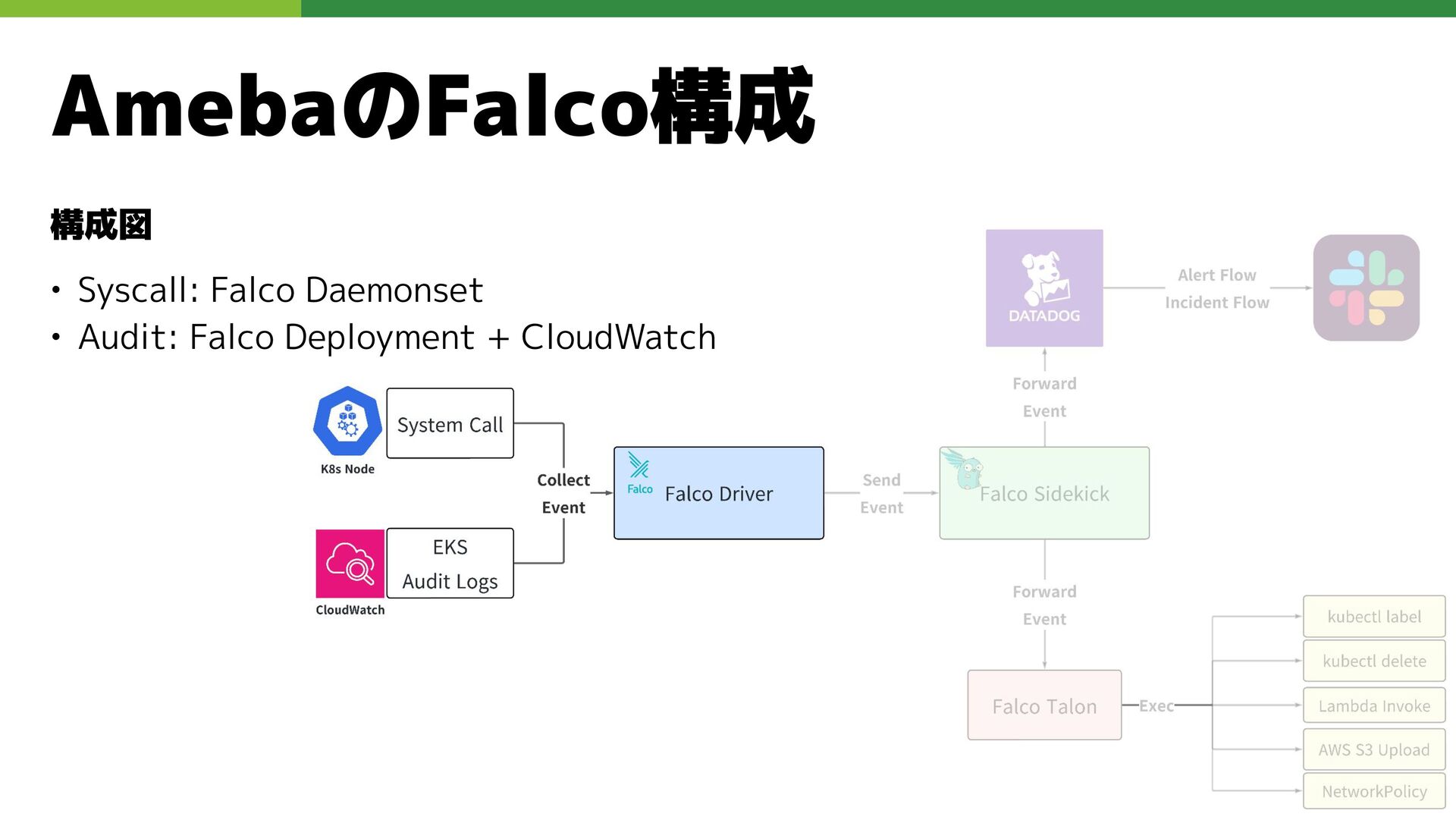
AmebaのFalco構成 構成図 • Syscall: Falco Daemonset • Audit: Falco Deployment
+ CloudWatch
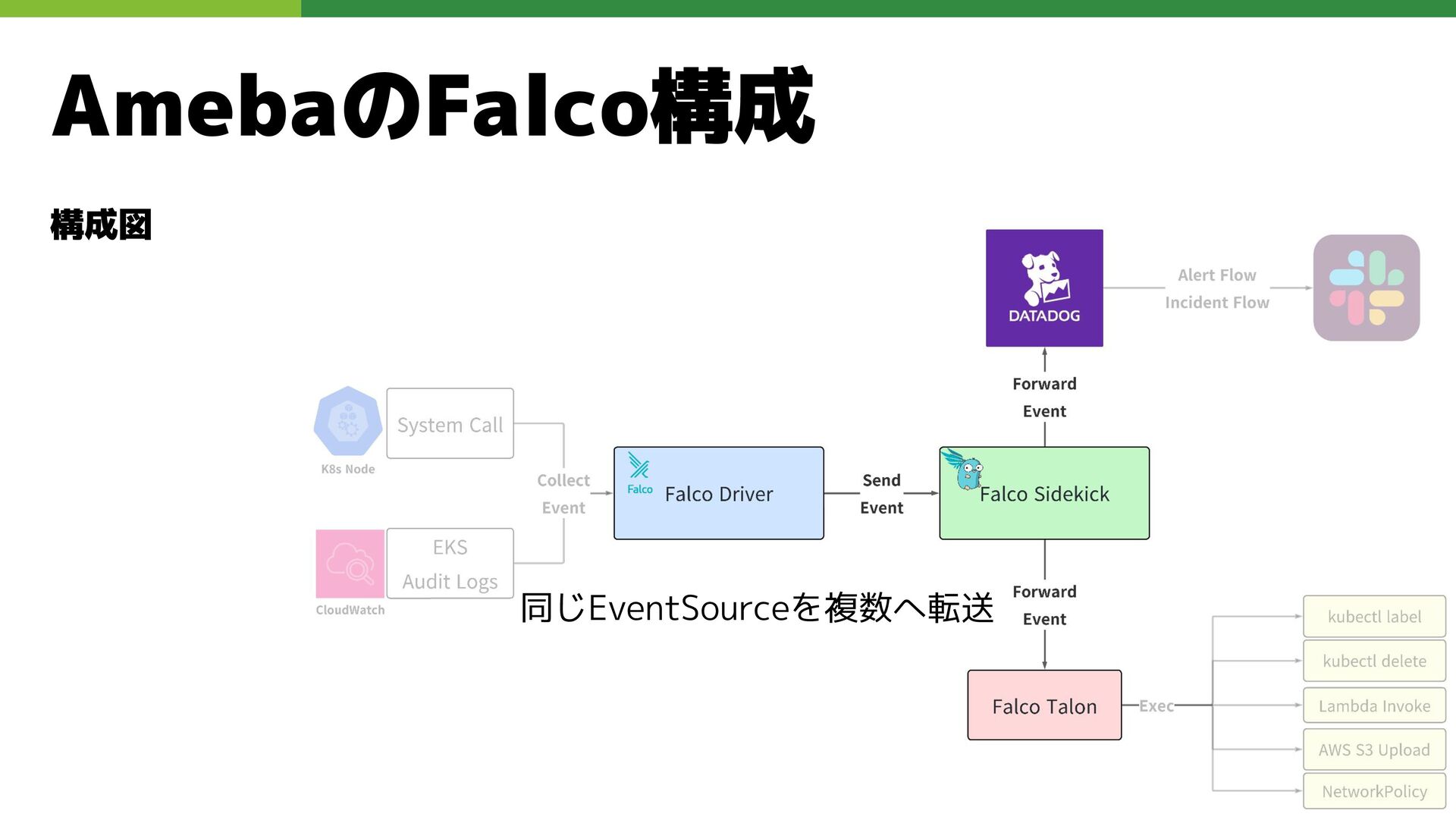
AmebaのFalco構成 構成図 同じEventSourceを複数へ転送
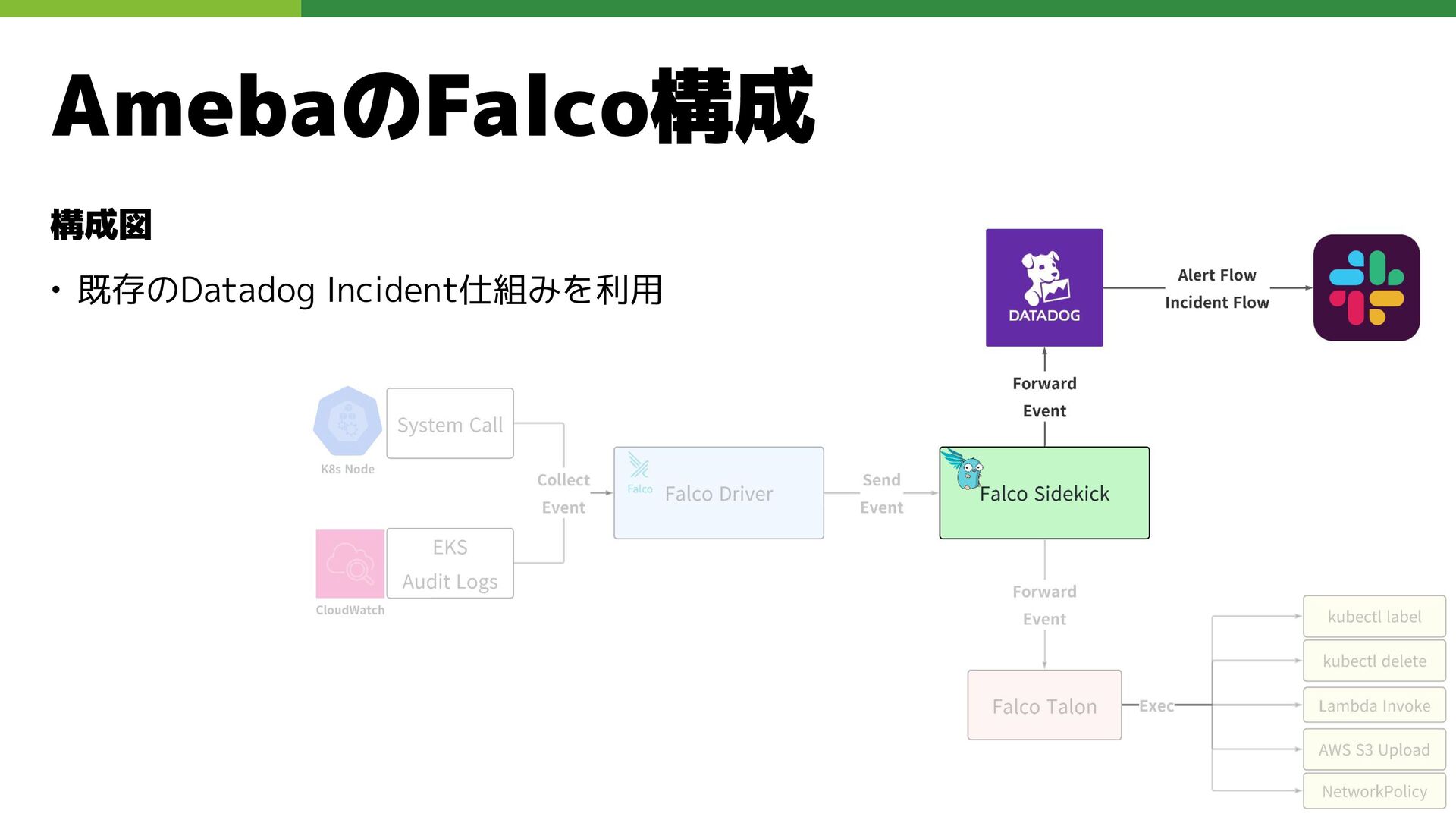
AmebaのFalco構成 構成図 • 既存のDatadog Incident仕組みを利用
AmebaのFalco構成 構成図
導入への道 ➢ 着地点: 目指すのはどのような状態なのか? ◦ 不正行為を逃さず、即時に検知し自動で対処する仕組みを持つ状態 ➢ Rule運用: どこまで検知するのか? ◦
運用者に過度な負担をかけず、広く深くリスクをカバーするルールセット ➢ インシデント対応: セキュリティインシデントどうやって対応するのか? ◦ 重大インシデントは自動処理、その他は即座に調査へつなげる
導入への道 時間軸 • 2024年8月: 導入検討開始・調査 • 2024年11月: 試験運用開始 • 2024年11月-2025年5月:
ノイズ除去 30k件/日 -> 5件/日 • 2025年7月: 本番アラート運用開始 • 2025年9月: ノイズ1件、インシデント0件 • 2025年中: SIEM(Amazon Security Lake)連携検討
運用を成功させる実践的アプローチ
プラクティス 1 小さく始めて段階的に拡張
小さく始めて段階的に拡張 Falco運用の課題 1. コンポーネント設定が多い • Falco,Falcoctl,Falcosidekick,FalonTalon… Falco(DaemonSet): SystemCall監視用、デバッグ・Rule更新が手間 Falco(Deployment): 単一ソースのプラグイン処理用、手軽にデバッグ・Rule更新可能
Falcoctl: プラグインダウンロード・ライフサイクル管理 Falcosidekick,FalonTalon: 通知・レスポンス処理用 2. Default Ruleをそのまま使うと、ノイズが非常に多い • ノイズの多い順(体感) k8s-audit > Sandbox Falco Rule > Incubating Falco Rule > Stable Falco Rule
小さく始めて段階的に拡張 Falco運用の課題 1. コンポーネント設定が多い 2. Default Ruleをそのまま使うと、ノイズが非常に多い 解決方法 • 三つのPhaseで段階的に導入・拡張
a. 最小構成のAudit Log監視 b. 必要な時にSystemCallの監視 c. 需要に応じて他のコンポーネントを導入
小さく始めて段階的に拡張 Phase 1: 最小構成のAudit Log監視 スタート地点 • Audit Log を分析し、Kubernetes
API の異常操作を検知 • まずはここから始めて問題なし 検知例 • K8s Secret Get Successfully • Create Privileged Pod • Disallowed K8s User
小さく始めて段階的に拡張 Phase 1: 最小構成のAudit Log監視 特徴 • インフラ影響:最小 • 学習コスト:低
• 必要リソース:Pod 1つ (複数を持つと通知が重複してしまう) 実装イメージ • ServiceAccount: CloudWatch IAM Role • Deployment構成: 単一Podで運用
小さく始めて段階的に拡張 Phase 2: 必要な時にSystemCallの監視 開始のタイミング • コンテナ内部の動きを詳しく検知したい時 • Falco 運用にある程度慣れた時
留意点 • Stable Rule から運用、多くのケースでは Stable Rule だけで十分 • Stable Rule でも一定のノイズが発生 • DaemonSet と Deployment は 別々の Helm Chart での管理が必要
小さく始めて段階的に拡張 Phase 3: 需要に応じて他のコンポーネントを導入 イベント・ログ集約 • ルール数が増えると Falco Logs の確認が負担に
• FalcoSidekickを使い、別ツールへログを集約 • いきなり Slack 連携するとノイズで運用者の負荷が増大 アラート・インシデント・レスポンス • 集約先でアラートとインシデントを一元管理 • 特定のアラートに対する対応手順が固まったら、レスポンスエンジンを導入
プラクティス 2 シナリオベースのRule選定
シナリオベースのRule選定 欲張らないRule運用のポイント • 脅威シナリオを想定 → そのシナリオに必要な Rule だけ導入 • Stable
を優先、必要に応じて他の Maturityを導入、どうしても無ければ自作 • 用途がないとdisable、「後ろめたさ」は不要
シナリオベースのRule選定 ノイズ発生の原因 • そもそもDefault Ruleには、最低限の除外設定しか設定していない • 利用者が自分で追加していく運用を想定している 例: Disallowed K8s
User Rule non_system_user: system: で始まるユーザ は除外 allowed_k8s_users: kubelet, kops, kube-apiserver-healthcheck など最低限のみ eks_allowed_k8s_users: eks:node-manager など古い値
シナリオベースのRule選定 ノイズ発生の原因 • そもそもDefault Ruleには、最低限の除外設定しか設定していない • 利用者が自分で追加していく運用を想定している 例: Disallowed K8s
User Rule non_system_user: system: で始まるユーザ は除外 allowed_k8s_users: kubelet, kops, kube-apiserver-healthcheck など最低限のみ eks_allowed_k8s_users: eks:node-manager など古い値 追加設定をしなければ ノイズ地獄が発生
シナリオベースのRule選定 ノイズ除去の原則: 完璧は求めず、段階的に改善していく 実践手段 • Override / Exception の活用 ◦
list/condition/output/tag/priority/enableの一部・全部をOverrideオプションで変更する ◦ フィルタリングの結果に対して、細かくExceptionを設定する
シナリオベースのRule選定 ノイズ除去の原則: 完璧は求めず、段階的に改善していく 実践手段 • Override / Exception の活用 ◦
Rule ConfigMapのベスト構成
シナリオベースのRule選定 ノイズ除去の原則: 完璧は求めず、段階的に改善していく 実践手段 • テスト条件の用意 ◦ Sandbox で意図的にイベントを発生させて確認 ▪
例: 特定のNamespaceで発生したイベントを除外しない • 長期的な観察 ◦ 定期的に起きるイベントを把握し、除外調整 ▪ 例: 認証・キャッシュなど
プラクティス 3 恐れないアラート運用
恐れないアラート運用 アラートの現実 • 90% はノイズ、9% は「要調査の謎挙動」、1% は「インシデントか不明」 チーム体制の重要性 • 一人で抱え込まず、チームで対応する仕組みを作る
• ノイズも「練習の機会」と捉え、ナレッジ共有を徹底 • アラート運用の段階(Amebaの例) ◦ ALPHA(1ヶ月): 特定のSlackユーザへ通知(私) ◦ BETA(3-6ヶ月): ノイズを告知した上、チームへ通知 ◦ GA: アラート鳴ったらすぐ対応
継続可能な運用に向けた課題と今後
セキュリティエンジニアの不在 課題 • 攻撃パターンの理解不足 ◦ 既存の Rule では最新の攻撃手法をカバーできない • インシデント判断の難しさ
◦ ノイズか脅威か分からず、1% の問題を「勘」で判断しがち 今後の方向性 • 入口のセキュリティを強化 ◦ Image セキュリティ強化(署名・スキャン) ◦ そのほかの手段(RuntimeClass・NetworkPolicy) • シナリオベースの避難訓練 ◦ 想定脅威ごとに実践的な対応手順を訓練
対応自動化の難しさ 課題 • Rule とRuleの目的を理解していないと、自動化に落とし込みにくい ◦ 対応自動化は「Pod Kill」ではない 今後の方向性 •
証拠保全の強化 ◦ 対象 Pod のログ収集 ◦ 関連ファイルや環境情報の抽出 • 調査プロセスまでを含む自動化 ◦ 隔離に加え、分析につながるアクションへ拡張
今後の期待 1. 現時点のペインを解消し、継続可能な運用を実現する 2. セキュリティエンジニアを巻き込み、より成熟なSOARプラットフォームを構築する ゴールイメージ • ノイズに追われず、重大インシデントに集中できる運用 • 人手に依存しない持続可能なセキュリティ基盤
• チーム全体で成熟度を高める仕組み
ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}