Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AutoML Tables で コードを書かずに機械学習入門 / Introduction t...
Search
kutakutat
November 25, 2021
Technology
600
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AutoML Tables で コードを書かずに機械学習入門 / Introduction to Machine Learning without Writing Code with AutoML Tables
AutoML Tables で コードを書かずに機械学習入門
kutakutat
November 25, 2021
More Decks by kutakutat
See All by kutakutat
Cloudflare MCP ServerでClaude Desktop からWeb APIを構築
kutakutat
1
1.3k
AI ファーストなコードエディター Cursor を導入してみた
kutakutat
0
1.4k
Bitcoinから学ぶブロックチェーン入門
kutakutat
0
280
Other Decks in Technology
See All in Technology
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
2
3.8k
はじめてのWDM
miyukichi_ospf
1
140
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
0
120
人を動かすのは時間ではなく、納得感 〜新任EMが入社3ヶ月、組織を2回変えた話〜
kakehashi
PRO
3
210
AI時代の EM への処方箋
staka121
PRO
0
130
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
110
インフラ寄りSREでも 開発に踏み出せる〜境界を越えてユーザー体験に向き合いたい〜
sansantech
PRO
2
3.6k
Keeping applications secure by evolving OAuth 2.0 and OpenID Connect
ahus1
PRO
1
160
Claude Code 珍プレー好プレー
shinyasaita
0
320
GuardrailからGovernanceへ~AIエージェント運用の次の課題~
sbspsy
2
270
[2026-07-15] AI Ready なはずだったアーキテクチャと、見えてきた課題・次に目指す状態
wxyzzz
4
2.5k
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
2.6k
Featured
See All Featured
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.4k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
1.9k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
280
Between Models and Reality
mayunak
4
370
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Navigating Weather and Climate Data
rabernat
0
300
WENDY [Excerpt]
tessaabrams
11
38k
Agile that works and the tools we love
rasmusluckow
331
22k
Crafting Experiences
bethany
1
210
The Pragmatic Product Professional
lauravandoore
37
7.4k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
800
Transcript
AutoML Tables で コードを書かずに機械学習入門
自己紹介 • 名前 ◦ 吉田 拓 (Taku Yoshida) • 所属
◦ FrontierTech代表 • 普段やってること ◦ Webアプリ開発、プロダクトマネジメント ◦ 機械学習は基礎の基礎だけ知ってるくらい • 趣味 ◦ コーヒー☕ 最近は扉の解施錠、NFCカードなどのハードウェアにも進出中
Agenda 1. AutoML の背景 2. AutoML Tables の紹介 3. AutoML
Tables のデモンストレーション 4. まとめ
AutoML の背景
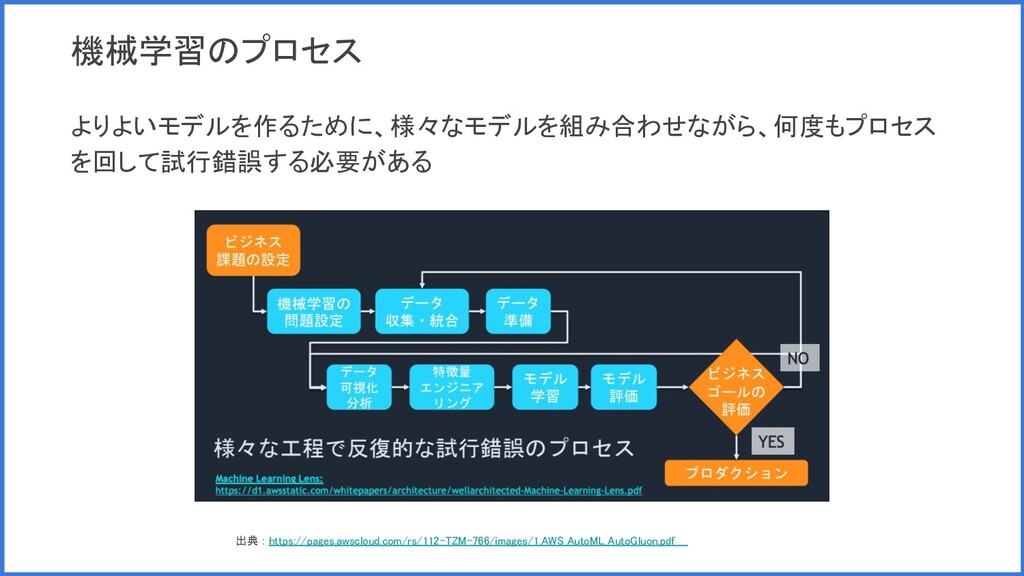
機械学習のプロセス よりよいモデルを作るために、様々なモデルを組み合わせながら、何度もプロセス を回して試行錯誤する必要がある 出典 : https://pages.awscloud.com/rs/112-TZM-766/images/1.AWS_AutoML_AutoGluon.pdf
機械学習のプロセスの課題 • 様々なモデルを組み合わせて試行錯誤するハードルが高い ◦ モデルのアンサンブルが主流になりつつあり、より高度な機械学習の知識が必要 ◦ 機械学習エンジニア、データサイエンティストはひっぱりだこ。。 •
何度もプロセスを回す手間が大きい ◦ 簡単にプロセスを回せないと検証するためのコストが高くなってしまう ◦ プロセスの自動化には時間がかかる。。 ✅ 最低限の機械学習の知識でモデルの試行錯誤したい ✅ 試行錯誤を高速で行いたい ✅ 簡単にプロセス自動化したい
AutoML とは AutoML(Automated Machine Learning:自動化された機械学習) ※ サービス名称ではなく一般的な言葉 → 機械学習を実世界の問題に適用するタスクを自動化するプロセス
出典 : https://en.wikipedia.org/wiki/Automated_machine_learning 自動化するプロセスの例 データの取り込み、特徴量エンジニアリング、モデルの選択 、ハイパーパラメータ− 調整、学習や推論のインフラ構築 など
AutoML に関するサービス例 • Google : Cloud AutoML など • Amazon
: AutoGluon など • DataRobot : DataRobot AI Cloud
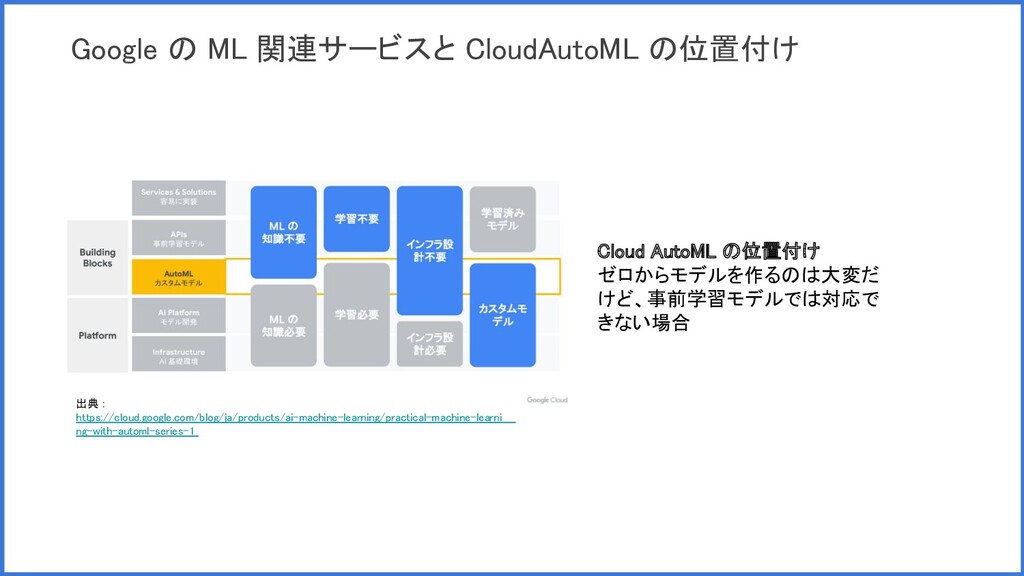
Google の ML 関連サービスと CloudAutoML の位置付け 出典 : https://cloud.google.com/blog/ja/products/ai-machine-learning/practical-machine-learni ng-with-automl-series-1
Cloud AutoML の位置付け ゼロからモデルを作るのは大変だ けど、事前学習モデルでは対応で きない場合
Cloud AutoML GCP の AutoML に関するプロダクト群の総称 プロダクト群 • 表形式データ :
AutoML Tables • 画像: AutoML Vision • 動画 : AutoML Video Intelligence • テキスト: AutoML Natural Language • テキスト(翻訳) : AutoML Translation • 統合プラットフォーム : Vertex AI
AutoML Tables の紹介
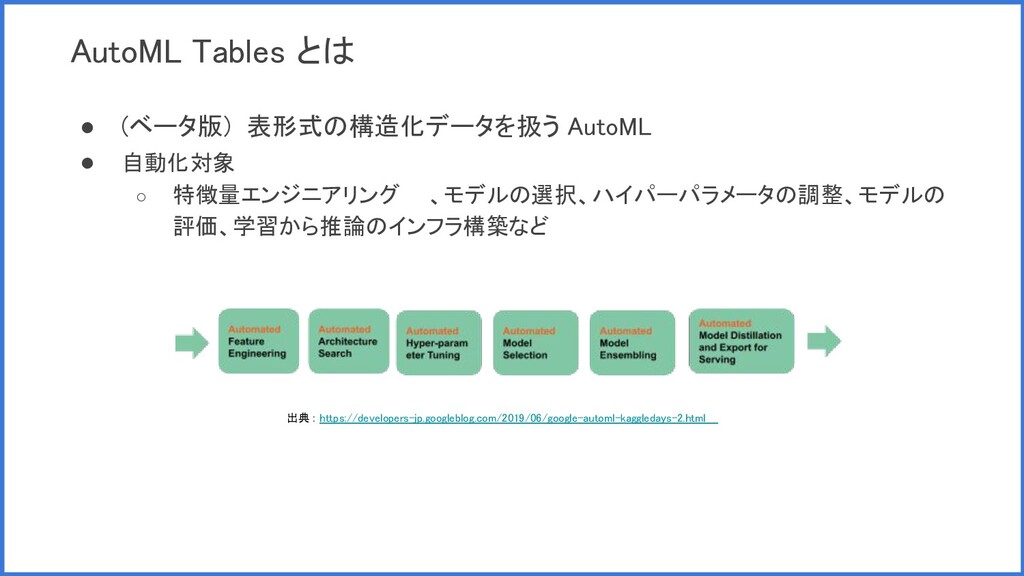
AutoML Tables とは • (ベータ版) 表形式の構造化データを扱う AutoML • 自動化対象 ◦
特徴量エンジニアリング 、モデルの選択、ハイパーパラメータの調整、モデルの 評価、学習から推論のインフラ構築など 出典 : https://developers-jp.googleblog.com/2019/06/google-automl-kaggledays-2.html
AutoML Tables の実例 • Kaggle Days SF Hackathon 2位 ◦
自動車部品の製造における欠陥を予測する課題 ◦ 最大 3 名のチーム 74 組が 8 時間半をかけて競うコンペ 出典 : https://developers-jp.googleblog.com/2019/06/google-automl-kaggledays-2.html
AutoML Tables のワーフフロー 1. データの収集、準備 : データを収集し正しい形式であることを、インポートの前後に確認 2. トレーニング:
パラメータを設定してモデルを構築 3. 評価: モデルの評価指標を確認 4. デプロイと使用: モデルを使用できるようにデプロイ、エクスポート
AutoML Tables のワーフフロー 1. データの収集、準備 : データを収集し正しい形式であることを、インポートの前後に確認 2. トレーニング:
パラメータを設定してモデルを構築 3. 評価: モデルの評価指標を確認 4. デプロイと使用: モデルを利用できるようにデプロイ、 エクスポート
トレーニングデータの要件 トレーニング データは次の要件に従う必要があります。 • 100 GB 以下 • 予測する値(ターゲット列)が含まれている
• 列数は 2~1,000 列 • 行数は 1,000~200,000,000 行 ◦ 1,000 行では高品質のモデルをトレーニングするために十分でない場合もある ◦ 推奨される最低行数の目安 ▪ 分類問題 : 特徴数 × 50 ▪ 回帰問題: 特徴数 × 200 ベストプラクティスは公式の こちら
データのインポート、特徴量エンジニアリング データのインポート時に 自動で行われる特徴量エンジニアリング
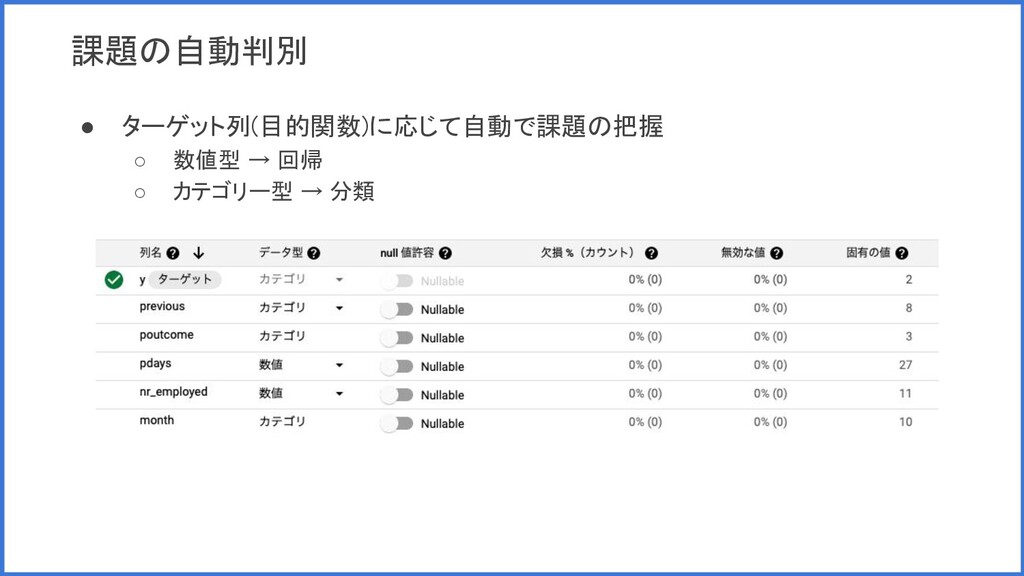
課題の自動判別 • ターゲット列(目的関数)に応じて自動で課題の把握 ◦ 数値型 → 回帰 ◦ カテゴリー型 →
分類
AutoML Tables のワーフフロー 1. データの収集、準備 : データを収集し正しい形式であることを、インポートの前後に確認 2. トレーニング:
パラメータを設定してモデルを構築 3. 評価: モデルの評価指標を確認 4. デプロイと使用: モデルを利用できるようにデプロイ、エクスポート
モデルのトレーニングの設定 主な設定項目 • トレーニング予算 ◦ 1~72 ノード時間 • 利用する特徴量の選択 ◦
デフォルトは無効な値が含まれる列以外すべて • 最適化の目標 ◦ デフォルトは問題に合わせて自動で選択 • 早期停止 ◦ 過学習になる前に学習を停止。デフォルト ON • データ分割の設定 ◦ デフォルト (Training)80% : (Dev)10% : (Test)10%
モデルの自動選択 • モデルの自動選択、組み合わせ ◦ 1つ以上のモデルを自動で組み合わせて最終的なモデルを作成 • モデルは以下のモデルを利用 ◦ AdaNet
モデル ◦ AdaNet AutoEnsemble モデル ◦ DNN 線形モデル ◦ 勾配ブースト ディシジョン ツリー モデル ◦ フィードフォワード ニューラル ネットワーク モデル 例) モデル構造のログ
データの自動分割 交差検証自動でを行います 通常は (Training)80% : (Dev)10% : (Test)10% にデータ分割
別のサンプリングがしたい場合は データ分割列を元データに追加した上で、個々の行(サンプル)を TRAIN / VALIDATE / TEST / UNASSIGNED のいずれかに手動でランダムにラベリングして割り振る 時系列の場合はランダムサンプリングではなく、時系列でカットする 出典 : https://cloud.google.com/blog/ja/products/ai-machine-learning/practical-machine-learning-with-automl-series-4
AutoML Tables のワーフフロー 1. データの収集、準備 : データを収集し正しい形式であることを、インポートの前後に確認 2. トレーニング:
パラメータを設定してモデルを構築 3. 評価: モデルの評価指標を確認 4. デプロイと使用: モデルを利用できるようにデプロイ、エクスポート
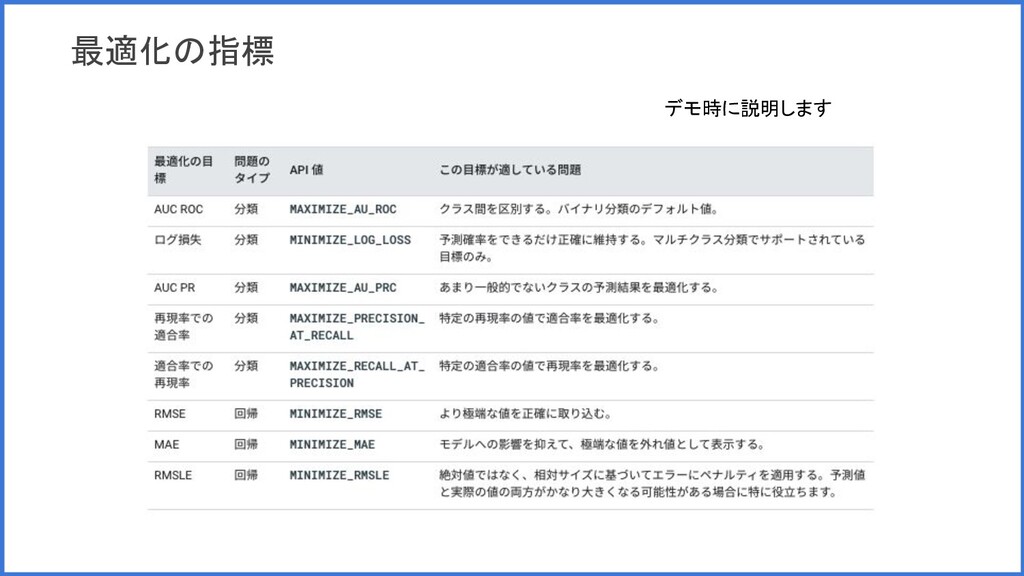
最適化の指標 デモ時に説明します
AutoML Tables のワーフフロー 1. データの収集、準備 : データを収集し正しい形式であることを、インポートの前後に確認 2. トレーニング:
パラメータを設定してモデルを構築 3. 評価: モデルの評価指標を確認 4. デプロイと使用: モデルを使用できるようにデプロイ、 エクスポート
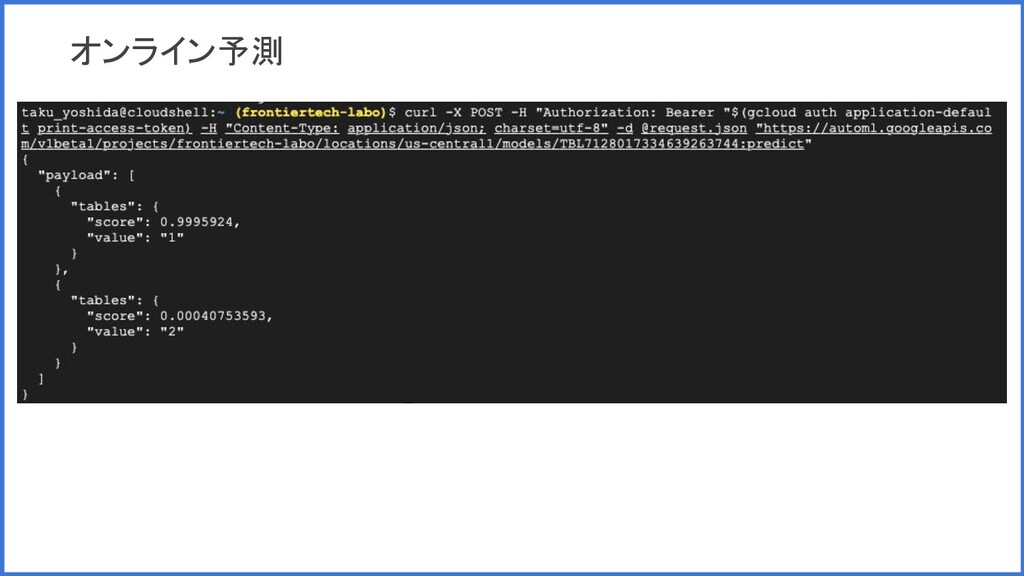
モデルの利用 • バッチ予測 ◦ 新しいデータをアップロードしてみて推論 ◦ リアルタイム性を求められずまとまったデータの推論を行いたいときに有用 •
オンライン予測 ◦ REST リクエストを送信できるようにモデルがデプロイして推論 ◦ リアルタイムに推論を返したい場合に有用 • モデルのエクスポート ◦ TensorFlow パッケージをダウンロード。Docker 上などで動かして推論 ◦ 手元のローカル環境や、アプリに組み込んで使用したい場合に有用
オンライン予測
デモがあります💁
デモで扱うデータ AutoML Tables 公式のクイックスタート • データ ◦ ポルトガルの銀行のダイレクトマーケティングキャンペーン に関するデータ ◦
顧客の口座等の情報と、商品(銀行の定期預金)が契約されたか否かのデータ 4万件 • 課題 ◦ 何度も DM して意思確認するのは骨が折れる • 解決策 ◦ 事前に申し込みそうかどうか、事前にあたりを付けたい 👉「銀行の定期預金をしそうか/しそうでないか」の教師あり分類問題
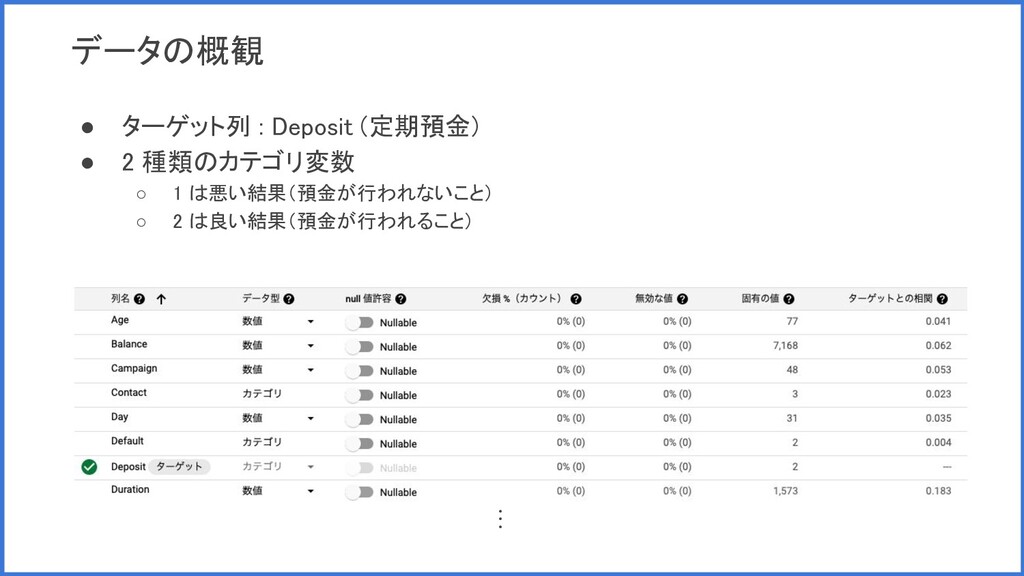
データの概観 • ターゲット列 : Deposit (定期預金) • 2 種類のカテゴリ変数 ◦
1 は悪い結果(預金が行われないこと) ◦ 2 は良い結果(預金が行われること) ︙
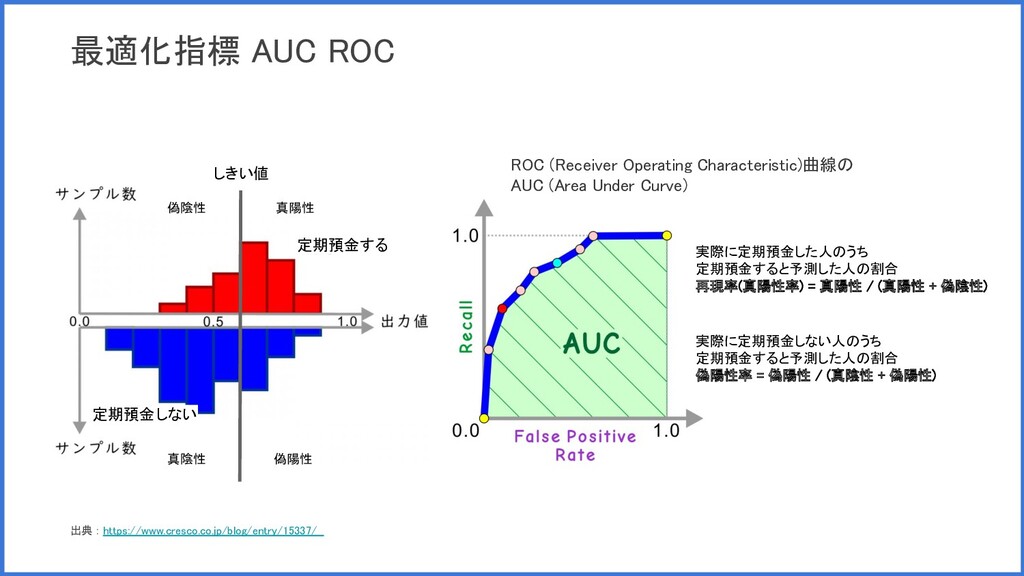
最適化指標 AUC ROC 定期預金する 定期預金しない しきい値 真陽性 偽陰性 偽陽性 真陰性
実際に定期預金した人のうち 定期預金すると予測した人の割合 再現率(真陽性率) = 真陽性 / (真陽性 + 偽陰性) 実際に定期預金しない人のうち 定期預金すると予測した人の割合 偽陽性率 = 偽陽性 / (真陰性 + 偽陽性) 出典 : https://www.cresco.co.jp/blog/entry/15337/ ROC (Receiver Operating Characteristic)曲線の AUC (Area Under Curve)
BigQuery ML との使い分け 出典 : https://cloud.google.com/automl-tables/docs/features 素早く、簡易なモデルでの学習から推論なら BigQueryML
利用料金等
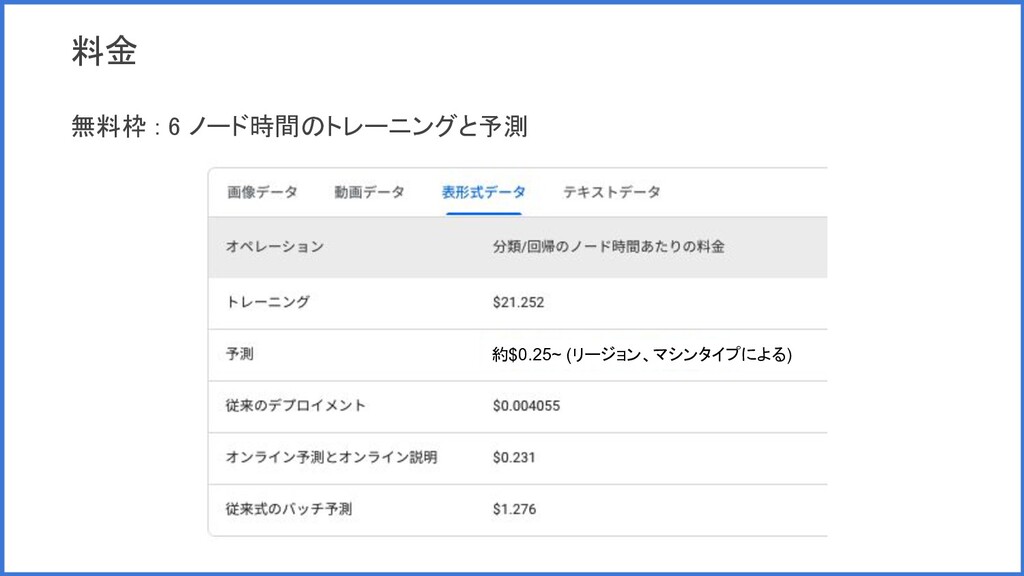
料金 約$0.25~ (リージョン、マシンタイプによる) 無料枠 : 6 ノード時間のトレーニングと予測
まとめ
まとめ • 専門知識が少なくても、インポートから推論まで簡単できるのでお手軽 • モデルの評価軸、特徴量の寄与なども可視化できて直感的 • データ量などが整っていることが前提になるのでデータが少ない場合には注意
• 現実の課題でもまずはお試しして、参考値を手に入れるのは1つの手では?
Appendix
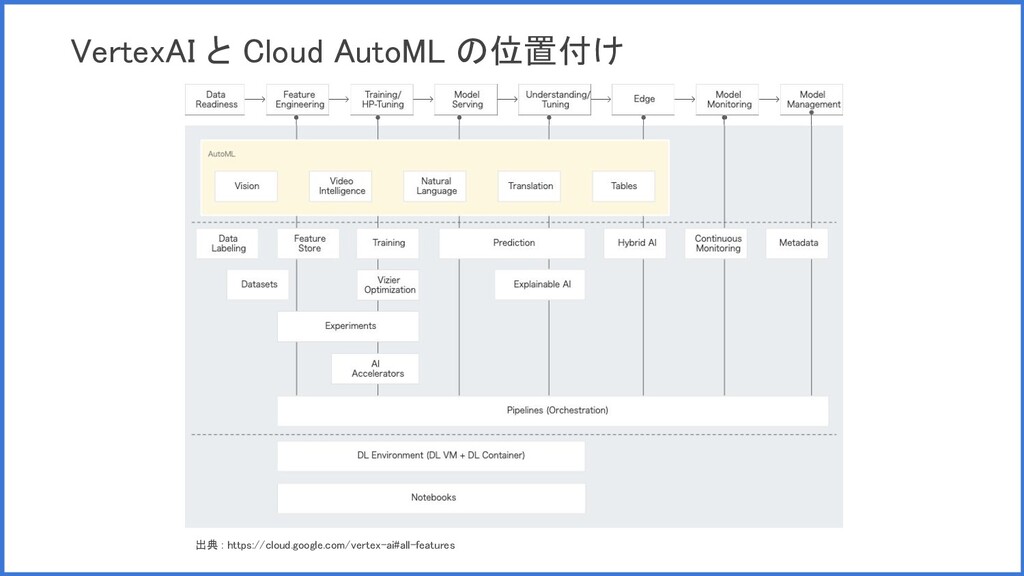
VertexAI と Cloud AutoML の位置付け 出典 : https://cloud.google.com/vertex-ai#all-features
トレーニングデータの作成 モデルの品質を高めるためにデータセットの準備時に気をつけること • データの漏出を避ける( 予測を求める際には利用できない予測情報が含まれないように) • トレーニング/サービングスキューを避ける •
未来の情報を過去に混入させない • 意図的に難読化・無作為化・匿名化されたデータを復元したものを含めない • モデルの運用環境に存在しないデータを含めない ︙ ベストプラクティスは公式の こちら
早期停止 過学習を避けるために、学習データに対する学習を進めながら同時に Dev データに対する交差検証誤差をモニタリングし、こ れが下がらなくなったら学習を打ち切る
パフォーマンスが低いときは。。 • スキーマを見直す a. すべての列の型が正しいこと b. ID 列といった予測されない列をトレーニングから除外
• データを見直す a. null 値を許容しない列に 1 つでも値がないと、その行は無視されるので注意 b. データ内のエラーが多すぎないように c. トレーニング データにできるだけ偏りがないように • テスト データセットをエクスポートして調べる • トレーニング データの量を増やす • トレーニング時間を増やす
逆にほぼ完璧なときは。。 • ターゲットの漏出 a. ターゲットの漏出は、トレーニング時には把握できない、結果に基づいた特徴がトレーニング データに含まれて いる場合に発生します。 b. たとえば、初めて購入を行うユーザーが実際に購入するかどうかを判断できるようトレーニングするモデルに常 連購入者番号を含めた場合、そのモデルの評価指標は非常に高くなります。しかし実際のデータでは常連購入
者番号を含められないため、パフォーマンスが低くなります。 • 時間列 a. データの時刻が重要な場合は、「時間」列または時間に基づく手動分割を使用していることを確認
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}