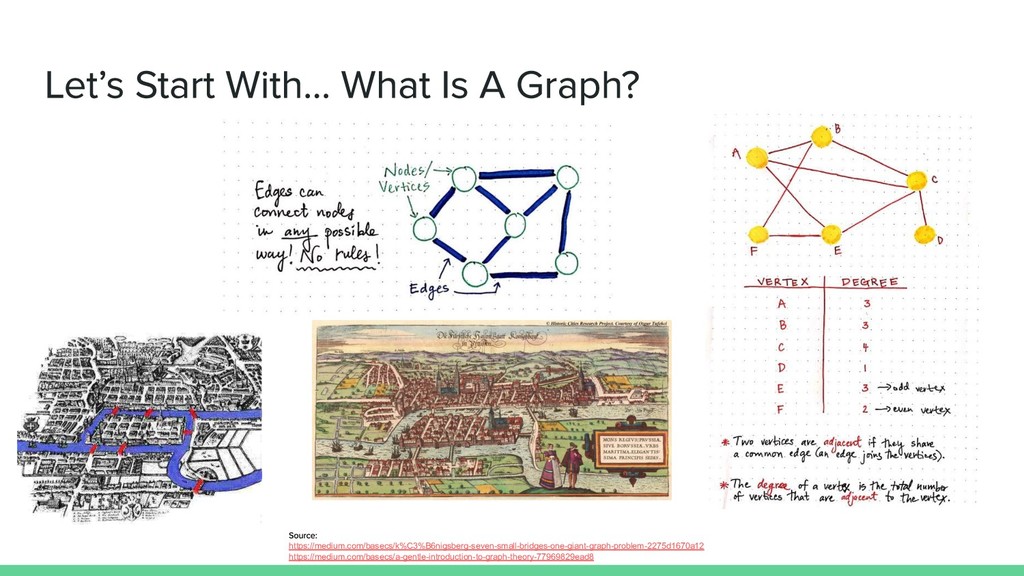
In this talk I introduce what a graph data structure is, how a graph database leverages the benefits of modeling data in a graph, and some of the unique problems graph databases allow you to solve.
databases. • Relational DBs have stood the test of time and have shown to be reliable • Document DBs are relatively new and are JSON-like storage systems, which is great for easily talking between and front-end and back-end. • Each of these have architectural pros and cons • Graph DBs are the newest and most untested, yet offer unique advantages when trying to provide certain functionality
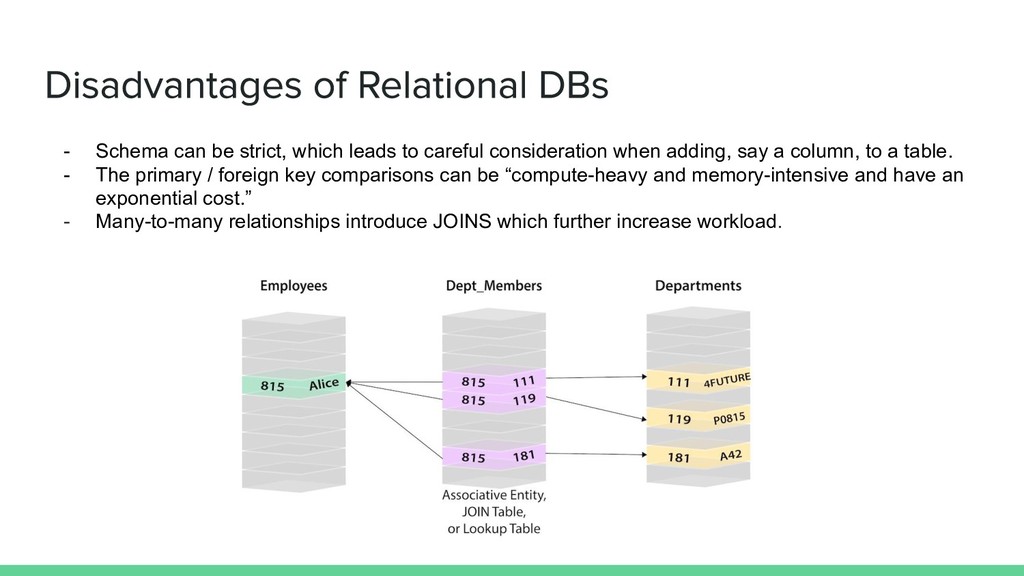
when adding, say a column, to a table. - The primary / foreign key comparisons can be “compute-heavy and memory-intensive and have an exponential cost.” - Many-to-many relationships introduce JOINS which further increase workload.
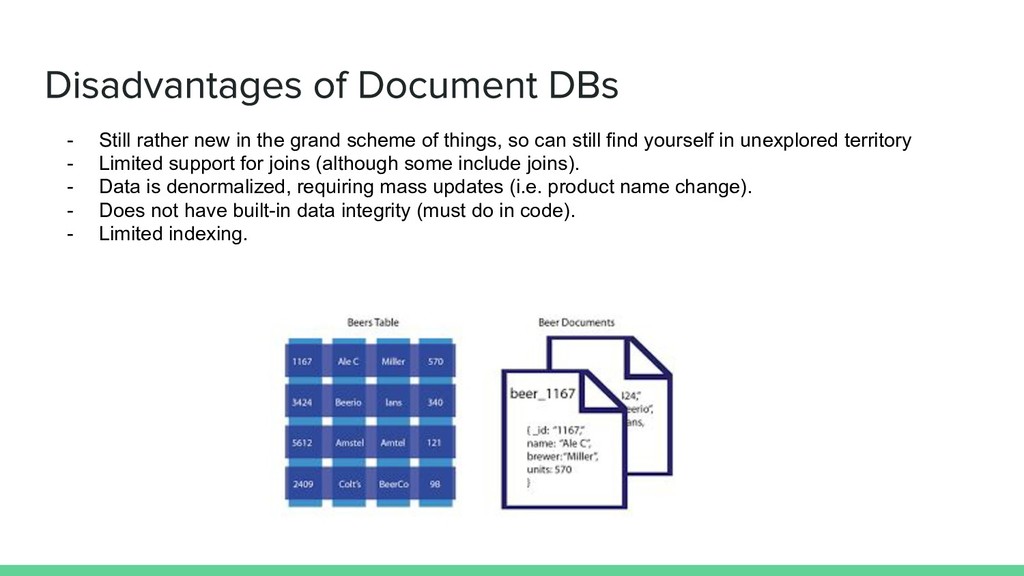
so can still find yourself in unexplored territory - Limited support for joins (although some include joins). - Data is denormalized, requiring mass updates (i.e. product name change). - Does not have built-in data integrity (must do in code). - Limited indexing.
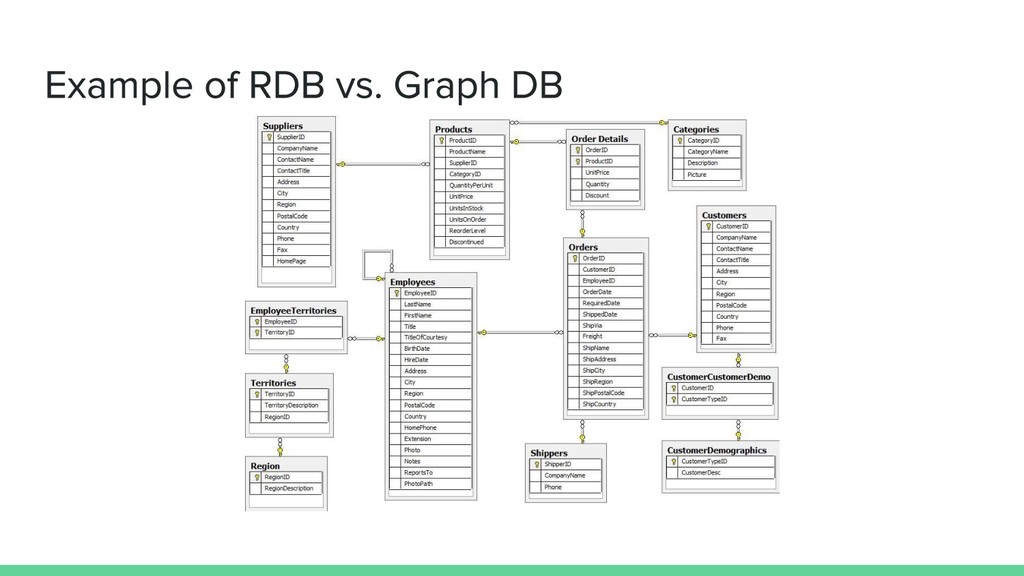
between your data are as important or more important than the data itself - Does your application need to perform tasks like making “recommendations”, IAM (identity and access management), or algorithmically analyze data? This is where a graph database can help tackle these challenges - This is a bit overkill for simple applications where a relational or document database would be easier to stand up and maintain
and select the Recommendations sandbox 3. Open the neo4j Browser This will lead you through a tutorial, importing data into the DB and using Cypher to run some introductory queries to get familiar with Cypher and end with us writing an algorithm for generating movie recommendations based on user review.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}