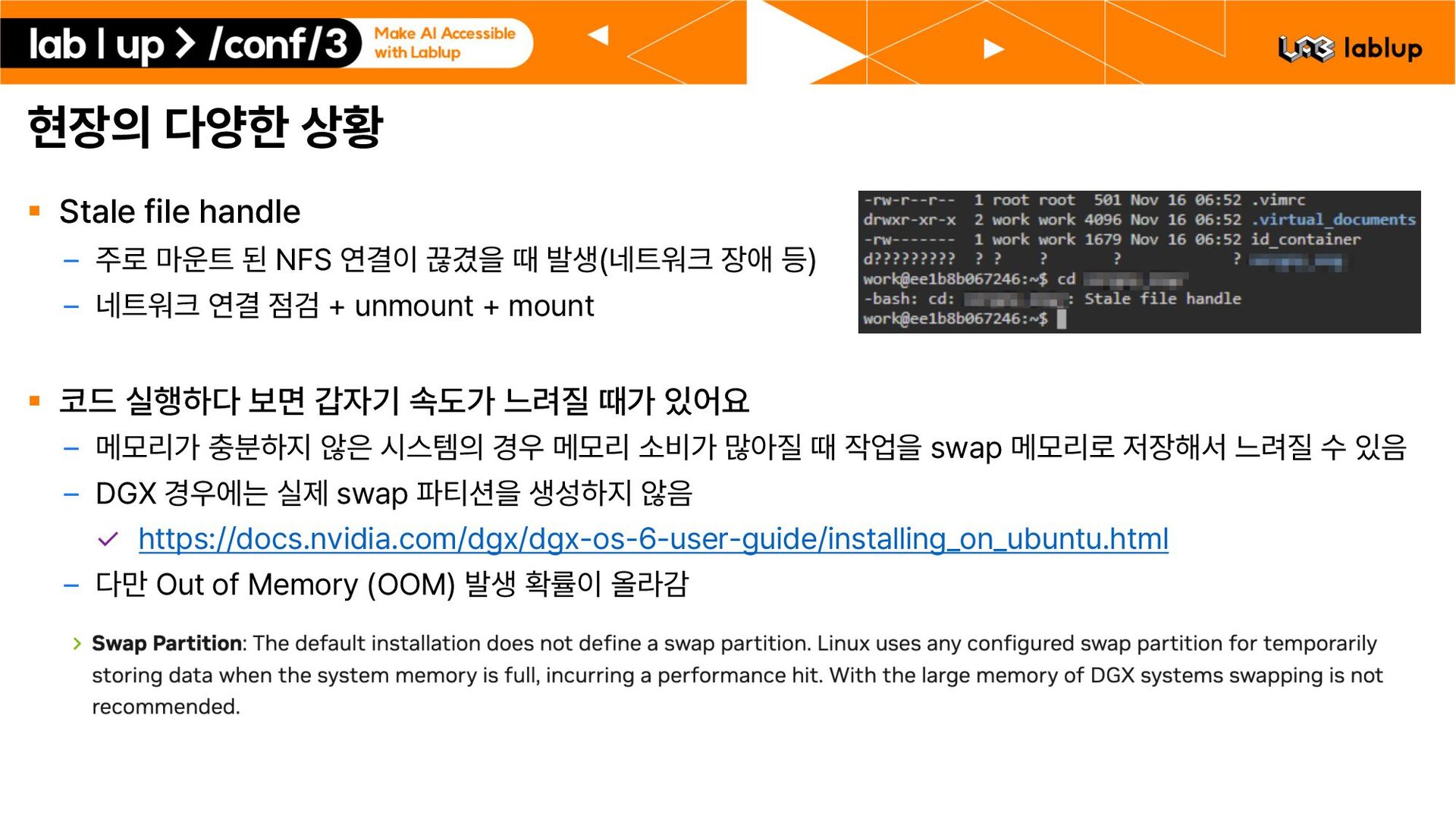
필요한 구체적인 사안 논의 및 컨설팅 참여 _ 설치 일정 및 제반 사항 확인/문의 § 설치 _ 기반 시스템 확인 OS 및 연산 가속 장치 GPU 등 호스트 구동 확인 설치 대상 서버의 연결 상태 및 방화벽 구성, NAT 유무 등 네트워크 망 구성 상태 확인 로컬 디스크 구조 / 공용 스토리지 마운트 및 작동 확인 HA 또는 도메인 적용시 VIP, 도메인, SSL 인증서 등 확인 HA 구성 여부에 따라 필요 일정에 다소 차이가 발생 _ Backend.AI Enterprise 설치, 구성, 테스트
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}