양자화를 위한 다양한 데이터 유형 (FP32, FP16, FP8, FP4, INT8, INT4…) 메모리 계층 구조: 온칩 메모리, HBM, GDDR6 등 – SRAM: Groq, Cerebras, Sambanova 및 TPU (온칩 메모리) – HBM: NVIDIA Datacenter GPU, AMD Instinct GPU, Intel Gaudi, Sambanova(차세대), Furiosa RNGD 등 – GDDR: 대부분의 컨슈머 GPU, Tenstorrent 및 다양한 NPU들 상호 연결: PCIe, NVLink, UALink, 기타 사용자 정의 상호 연결 등.. 프로그래밍 모델 – CUDA, OpenCL, ROCm/HIP, Metal, … – TensorFlow, PyTorch 등
{kind=link}
{kind=link}
{kind=link}
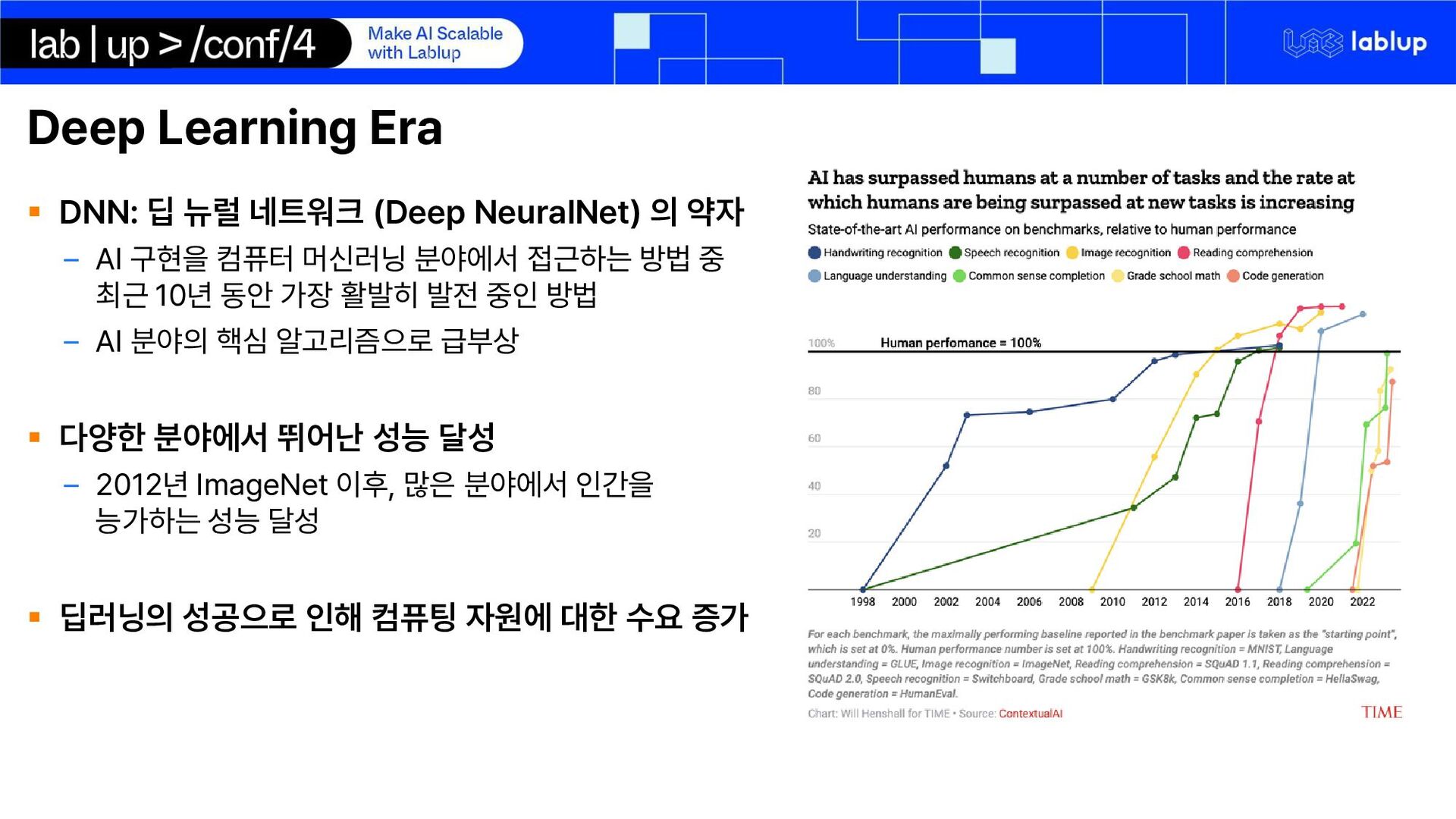{kind=link}
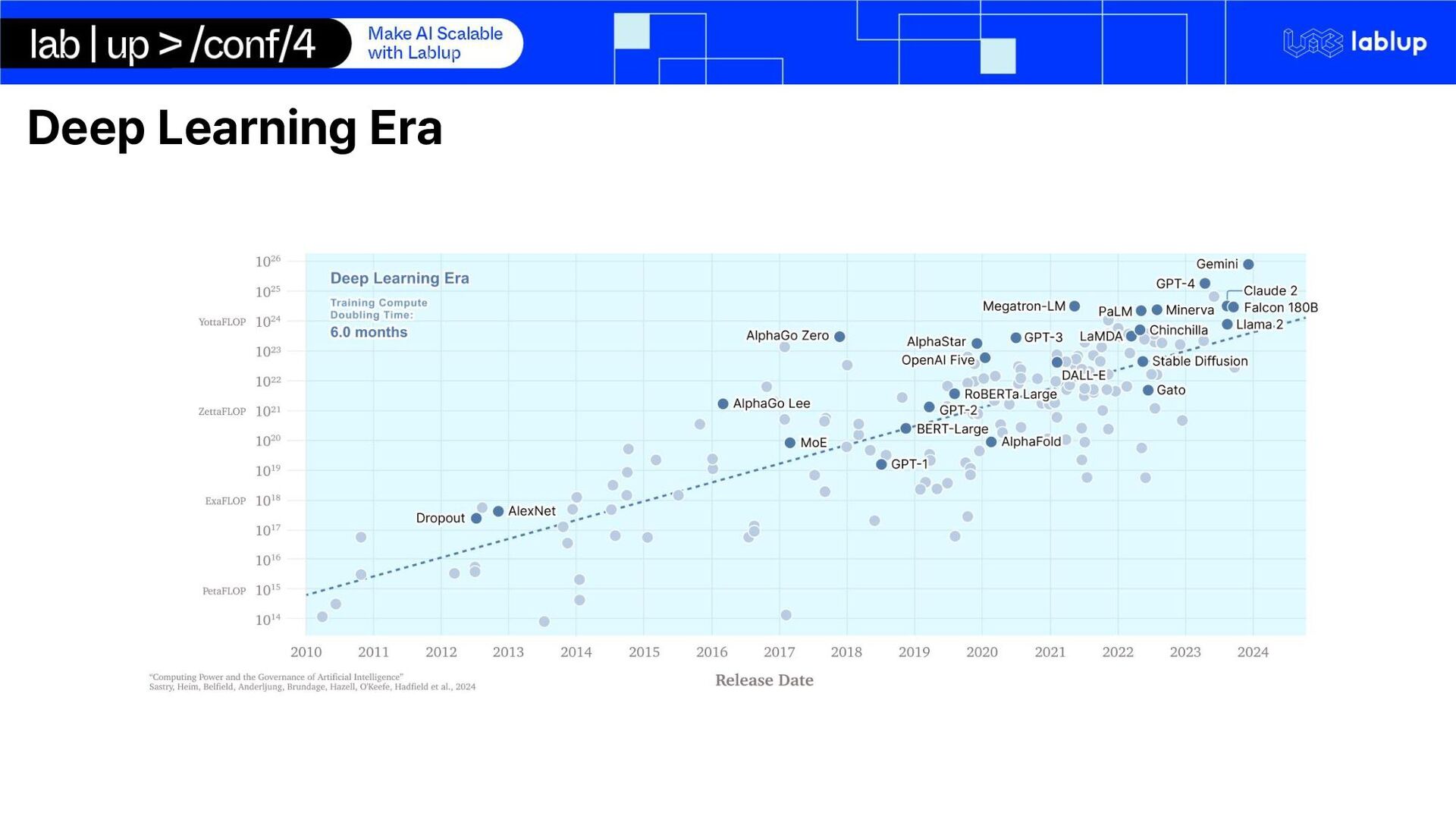{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}