tblvector(id bigserial PRIMARY KEY, embedding vector(3)); 임베딩된 3차원 평면 데이터 저장 – INSERT INTO tblvector (id, embedding) VALUES (1, '[1,2,3]'), (2, '[4,5,6]'), (3, '[5,4,6]'), (4, '[3,5,7]'), (5, '[7,8,9]’); INSERT INTO ~ ON CONFLICT 문으로, 조건과 일치하는 레코드 업데이트와 같은 대체 작업을 지정 – 잠재적 충돌을 보다 효율적이고 효과적인 방식으로 처리 – INSERT INTO tblvector (id, embedding) VALUES (1, '[1,2,3]'), (2, '[4,5,6]’) ON CONFLICT (id) DO UPDATE SET embedding = EXCLUDED.embedding;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
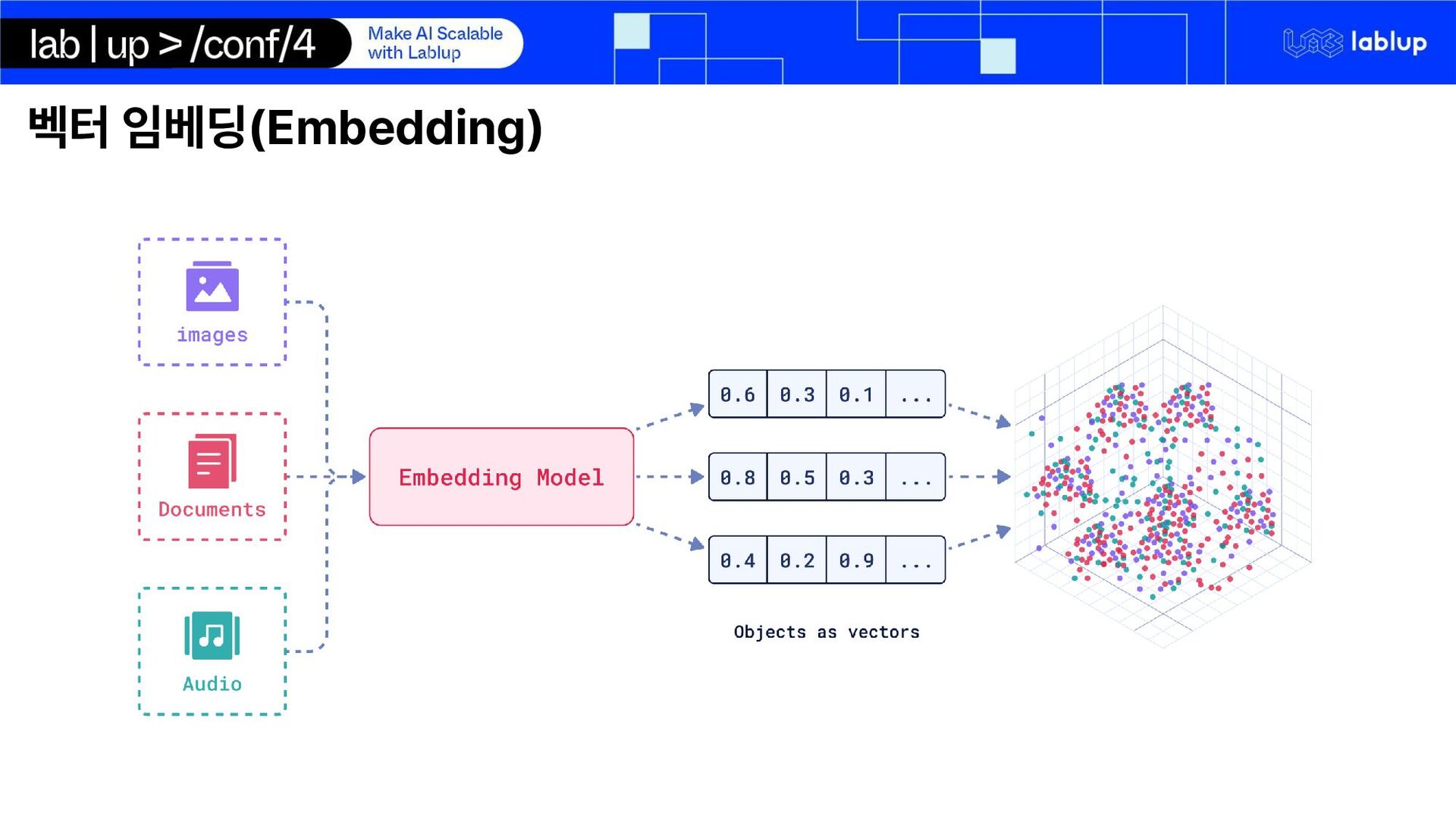{kind=link}
{kind=link}
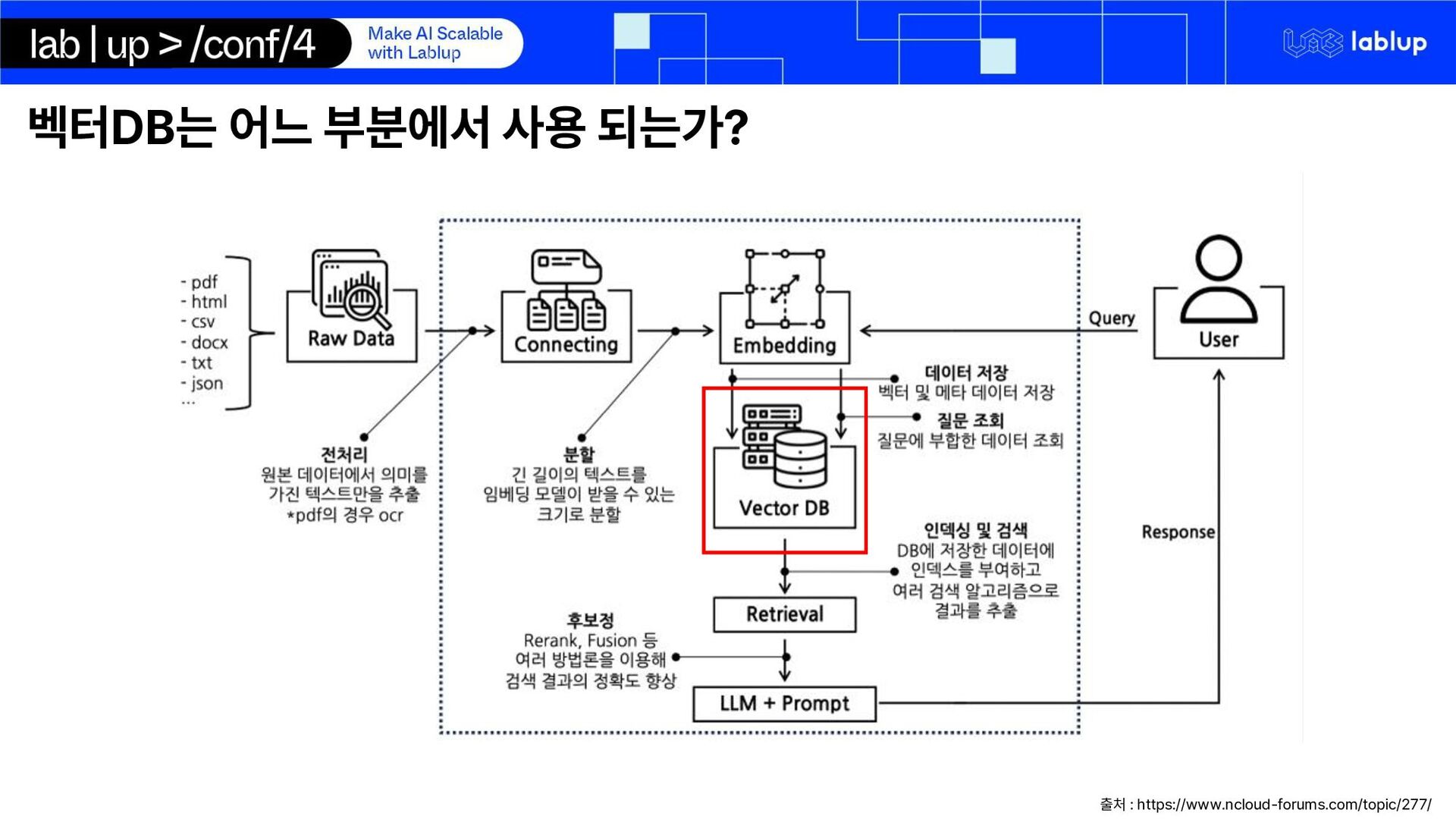{kind=link}
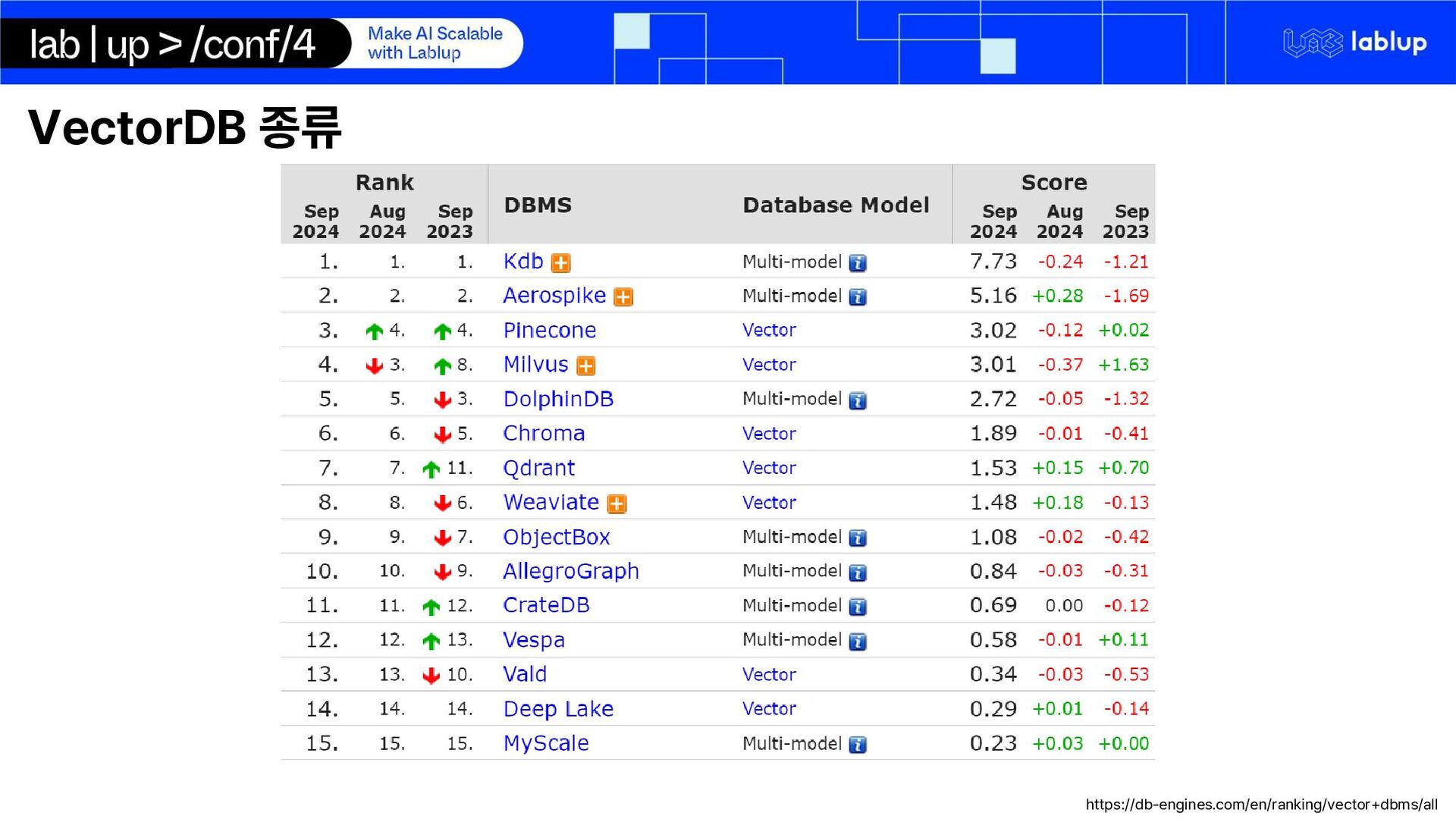{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
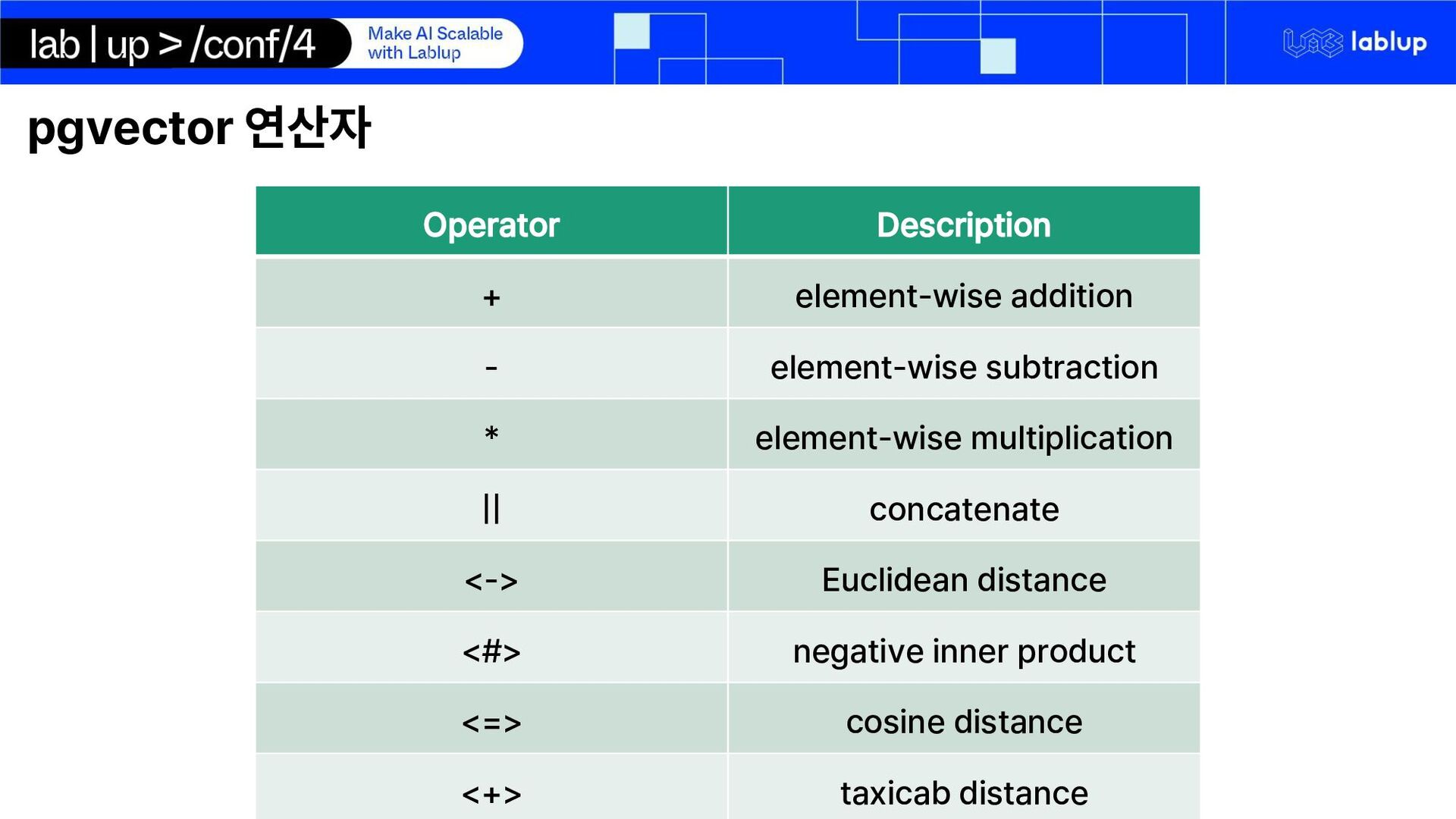{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
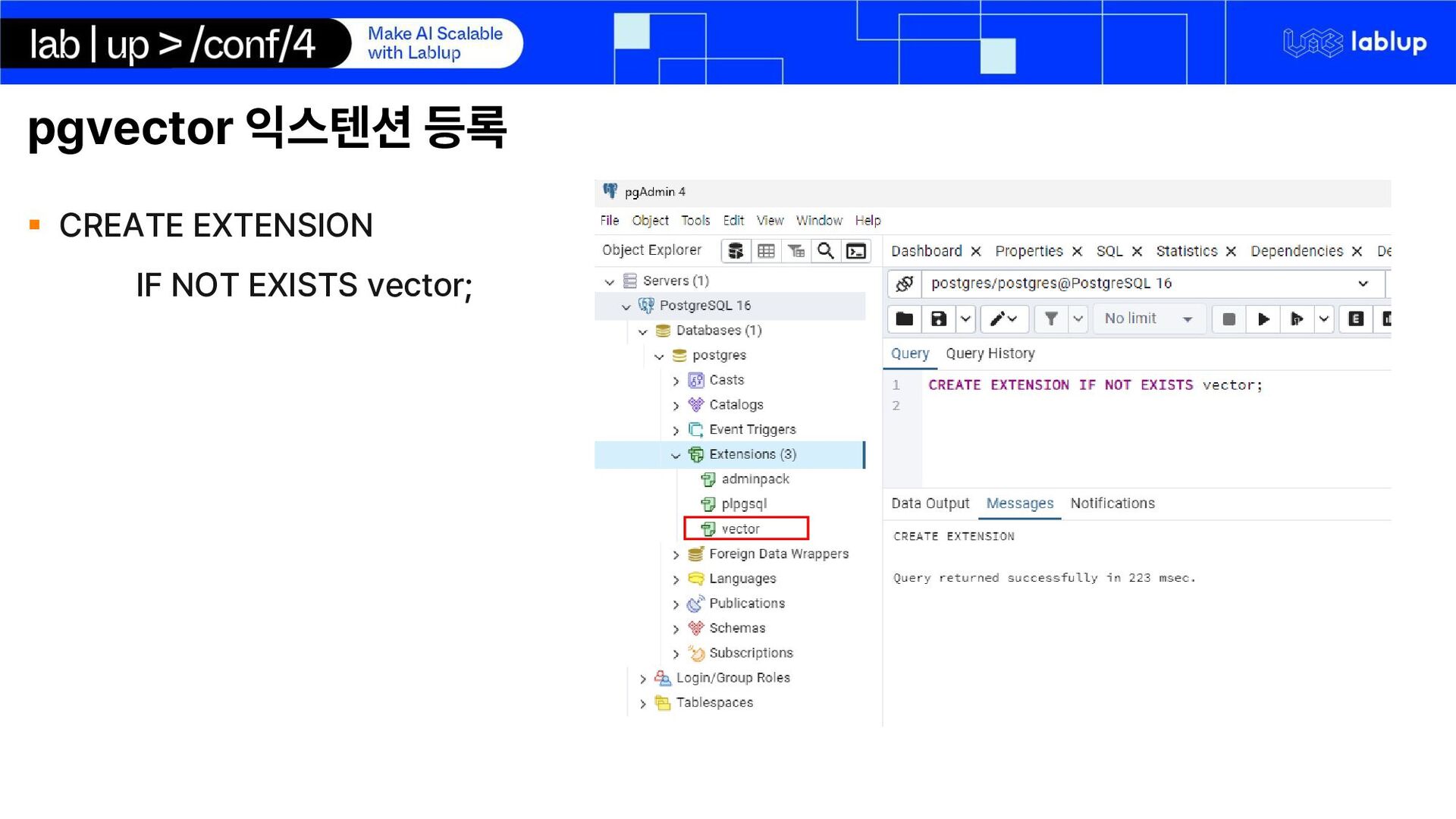{kind=link}
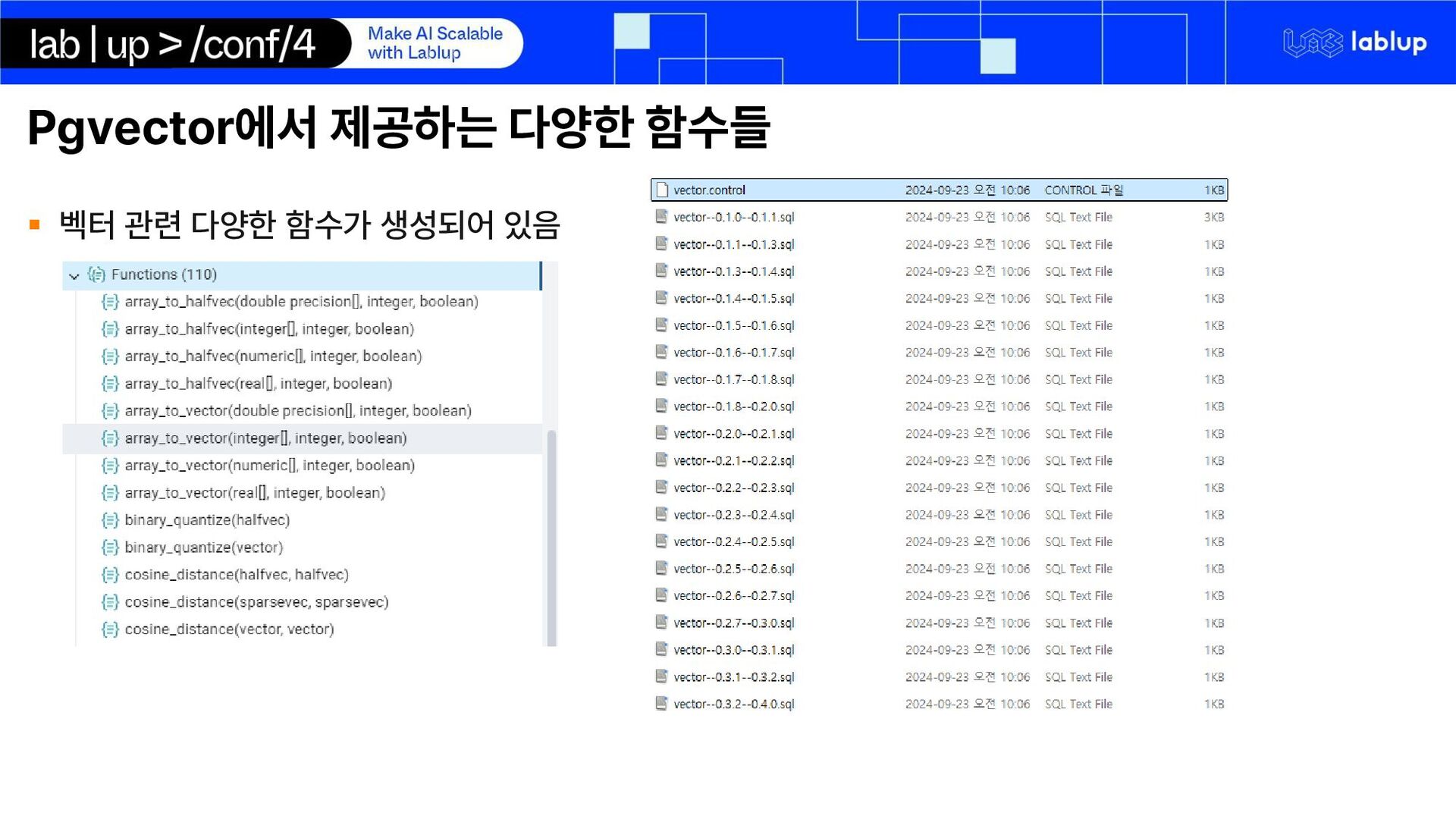{kind=link}
{kind=link}
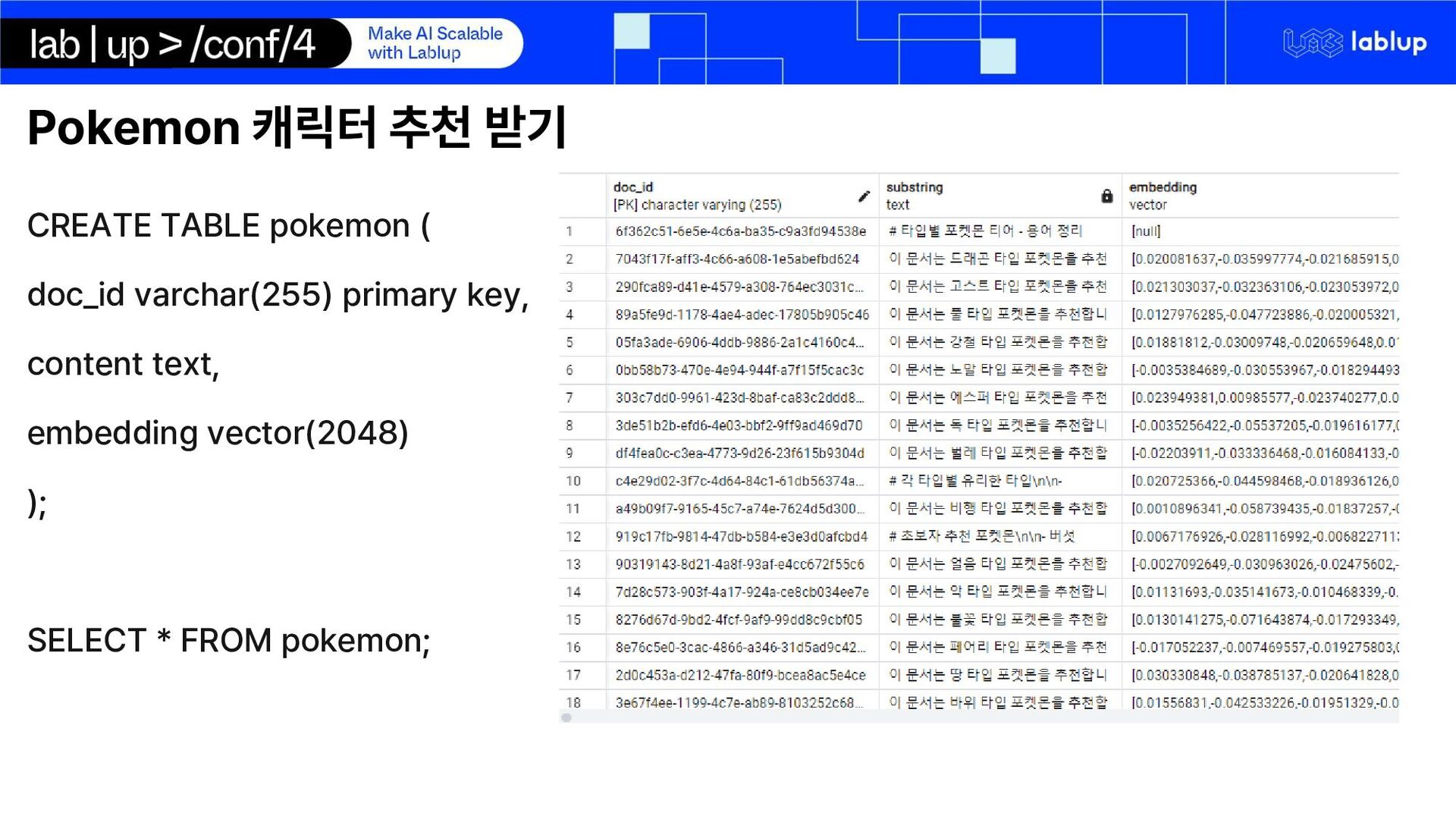{kind=link}
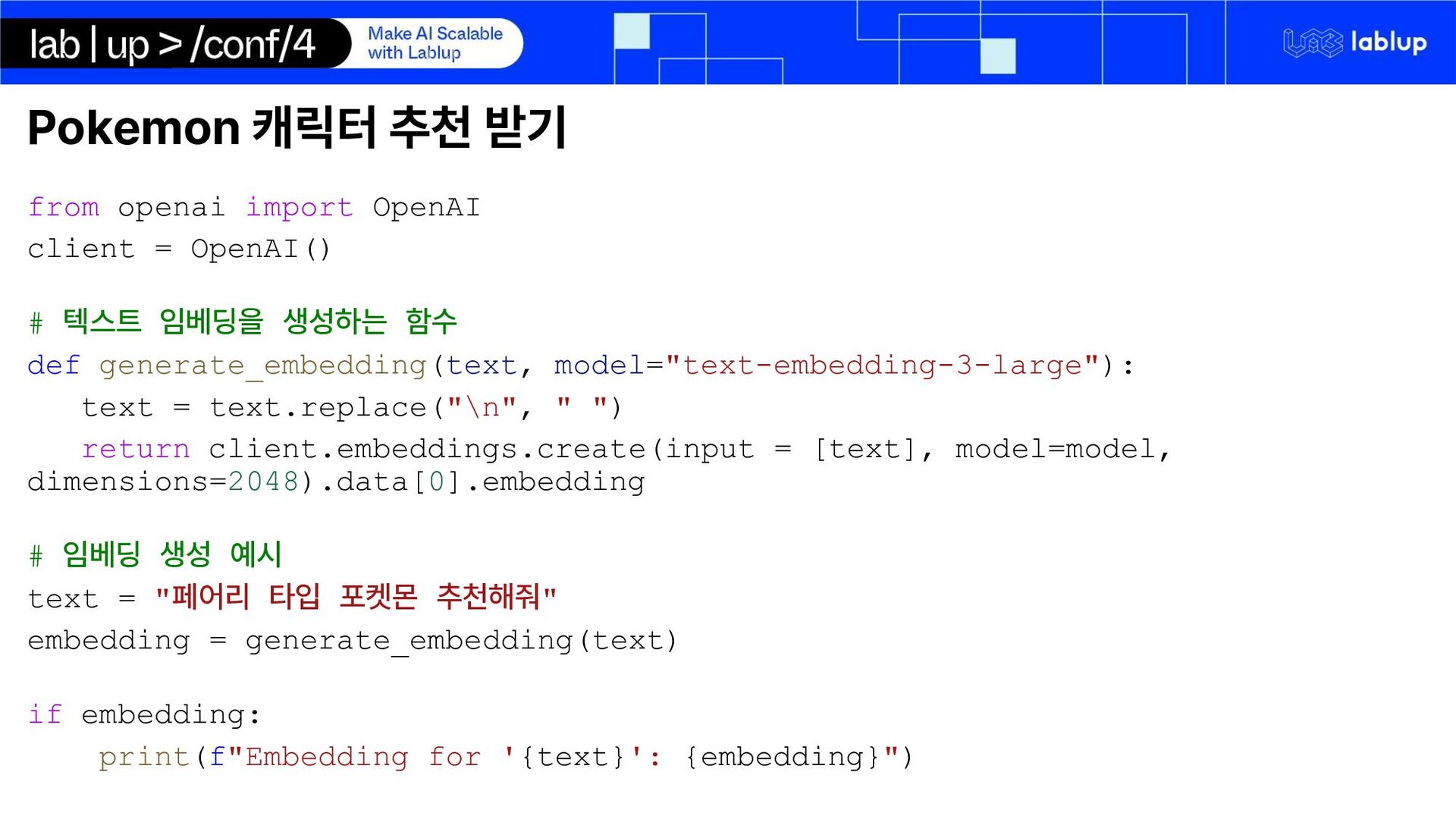{kind=link}
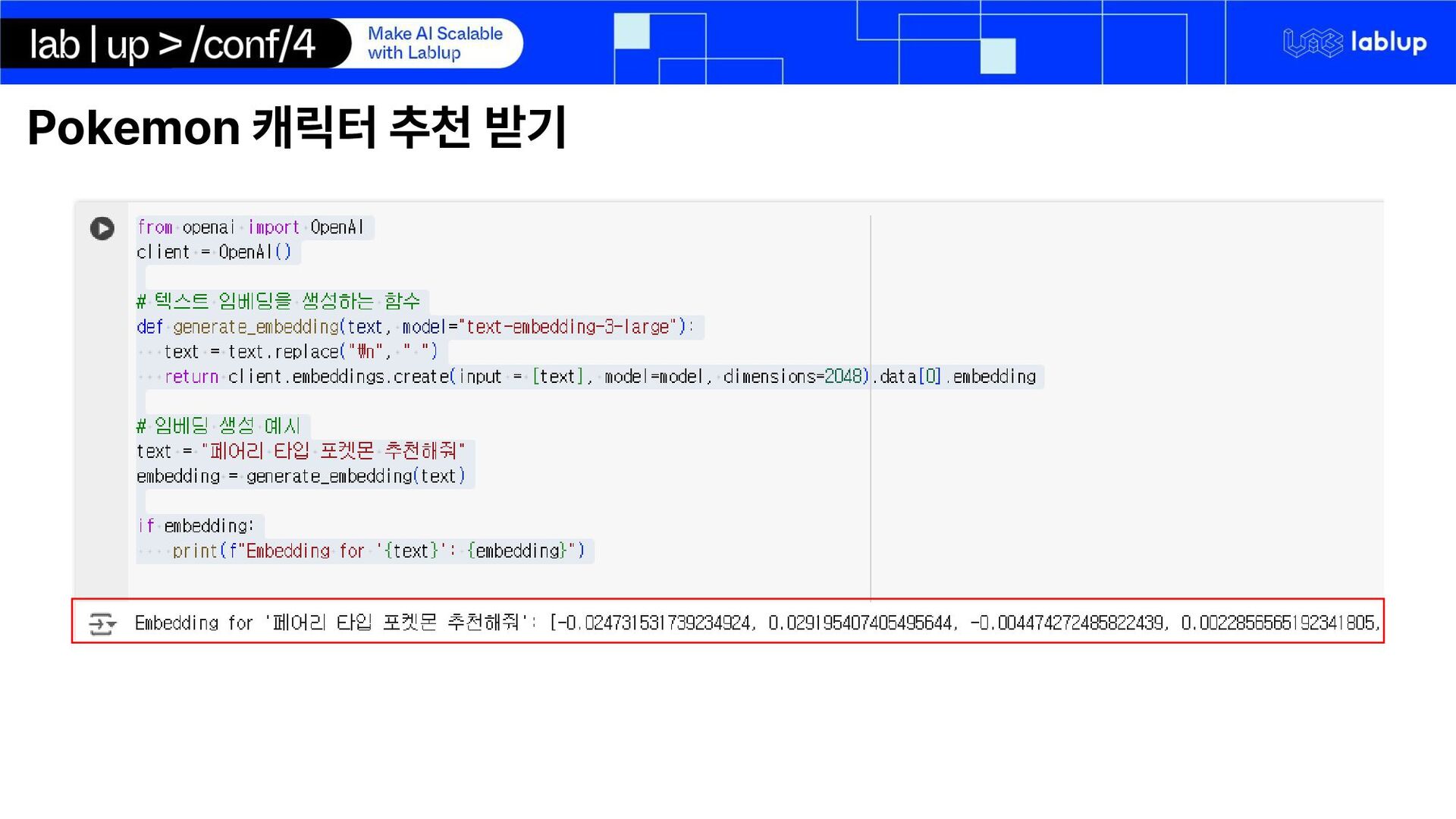{kind=link}
![ SELECT * FROM pokemon ORDER BY embedding <-> ‘[vector_value’]](https://files.speakerdeck.com/presentations/845eb4ffdc3f4ab686ca808bde3ccc28/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
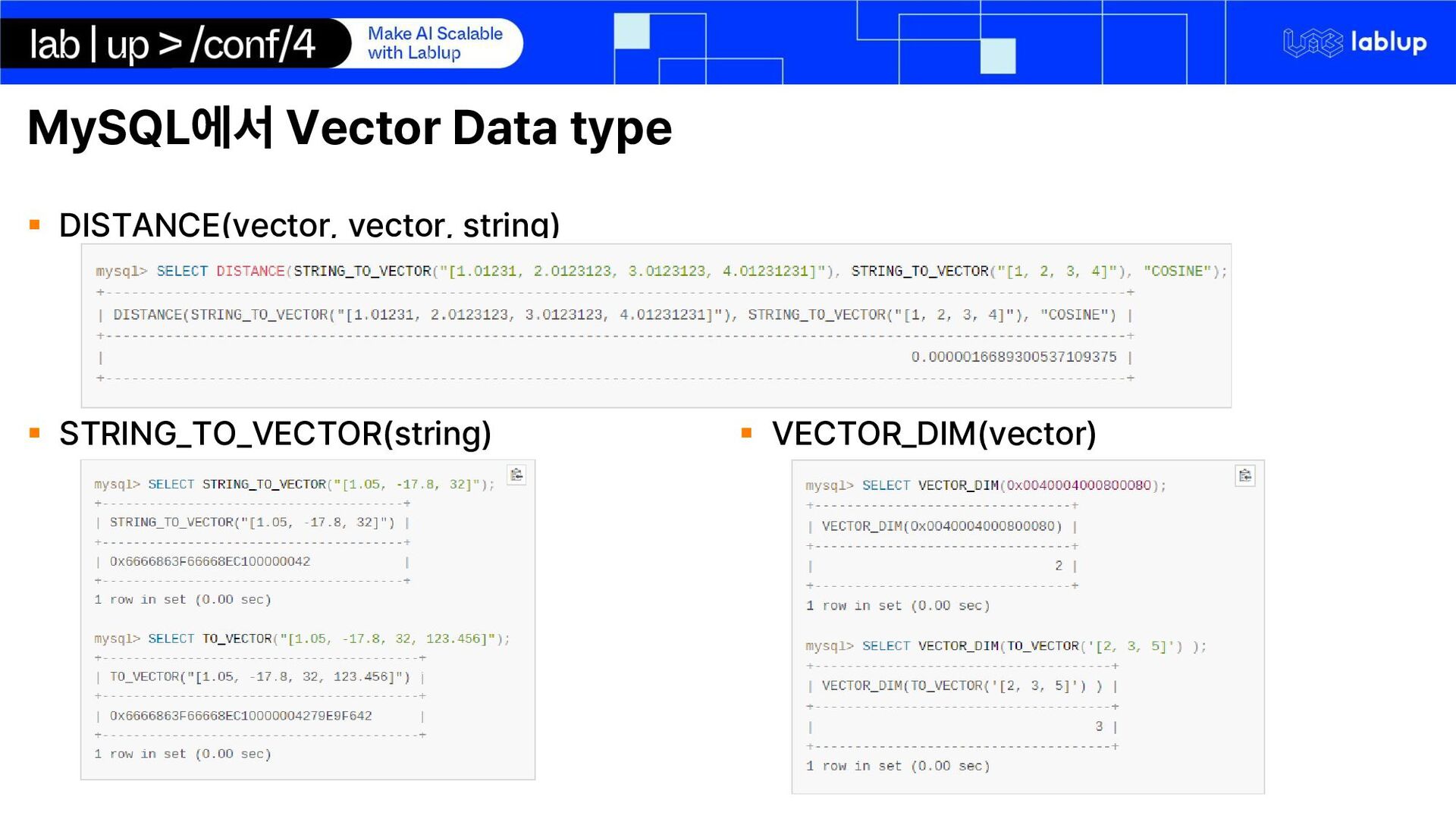{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}