Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
대형언어모델 추론과 강화학습
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Lablup Inc.
November 02, 2025
23
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
대형언어모델 추론과 강화학습
Track 3_1500_Lablup Conf 2025_윤도균
Lablup Inc.
November 02, 2025
More Decks by Lablup Inc.
See All by Lablup Inc.
효율적인 Agentic 아키텍처 구성을 위한 개발 Tip
lablup
0
64
Tokens/$ 극대화를 위한 소프트웨어 기술
lablup
0
42
Backend.AI Continuum을 이용한 AI Product 개발하기
lablup
1
38
Making Sense of HS Codes: HSense AI System for Automated Tariff Classfication
lablup
0
34
LLM을 통한 합성 데이터 생성
lablup
0
65
당신의 기업, AI 전환이 안되는 3가지 이유
lablup
1
47
Agentic AI를 위한 MCP Sidecar sLM 학습(시도)기
lablup
0
81
[Keynote] Composable AI, Composable Software
lablup
0
70
[Keynote] AAA: Agentic, Autonomous, Adaptive Intelligence
lablup
0
67
Featured
See All Featured
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
590
Abbi's Birthday
coloredviolet
3
8.9k
Un-Boring Meetings
codingconduct
0
360
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
41k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
330
Are puppies a ranking factor?
jonoalderson
1
3.7k
Mobile First: as difficult as doing things right
swwweet
225
10k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
New Earth Scene 8
popppiees
3
2.4k
Transcript
None
대형언어모델 추론과 강화학습 대형언어모델의 추론과 강화학습을 알아보고 실제로 고려해야 할
사례를 알아봅니다.
사람과 앵무새의 차이가 뭘까요? 안녕하세요 안녕하세요
None
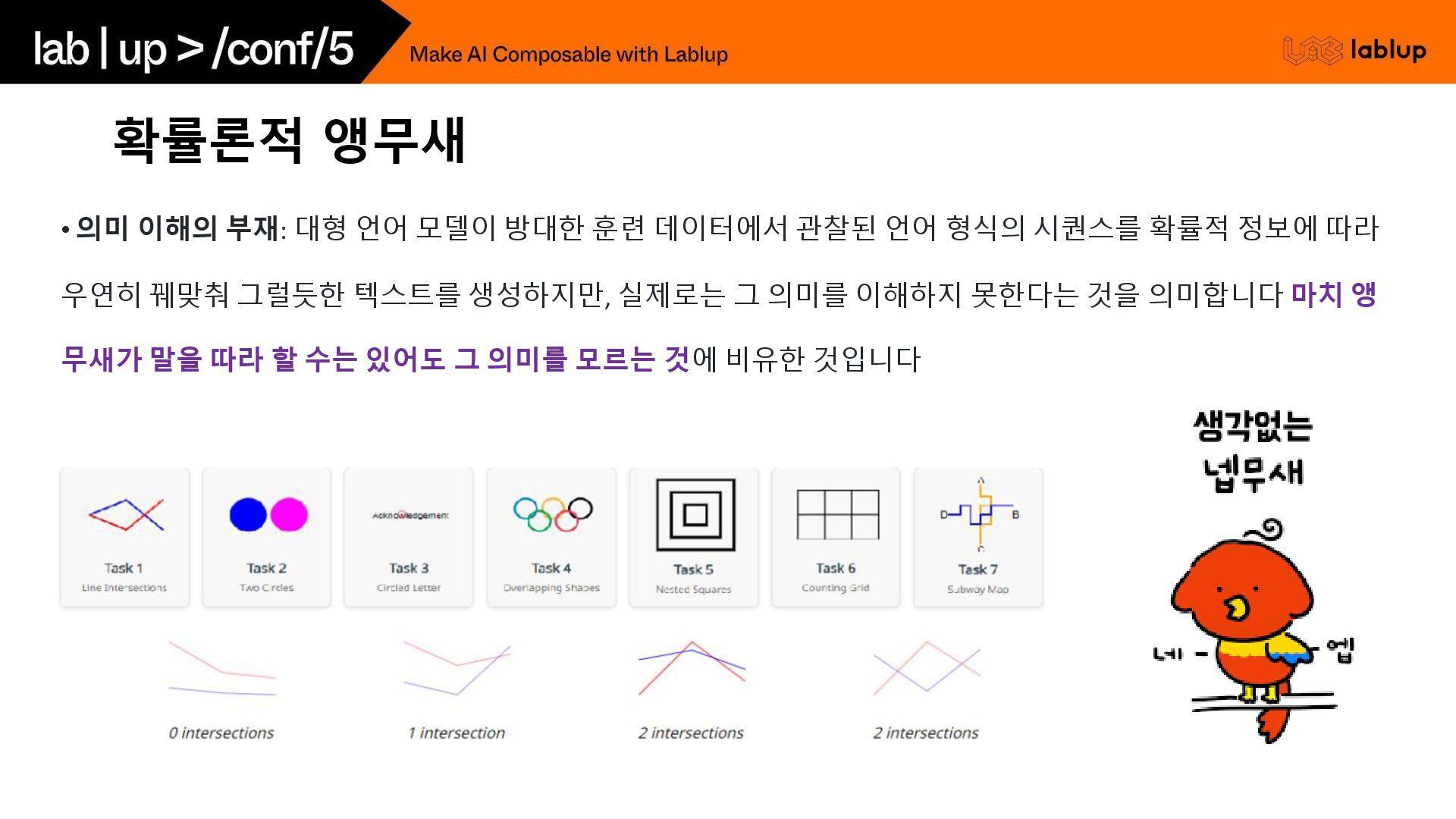
확률론적 앵무새 • 의미 이해의 부재: 대형 언어 모델이 방대한
훈련 데이터에서 관찰된 언어 형식의 시퀀스를 확률적 정보에 따라 우연히 꿰맞춰 그럴듯한 텍스트를 생성하지만, 실제로는 그 의미를 이해하지 못한다는 것을 의미합니다 마치 앵 무새가 말을 따라 할 수는 있어도 그 의미를 모르는 것에 비유한 것입니다
Chain of Thought (CoT) • Chain of Thought (CoT) 는
복잡한 작업을 최종 해결을 향한 일련의 논리적 단계로 세분화하여 인간과 유사한 추 론 과정을 시뮬레이션하는 인공 지능의 접근 방식입니다. 추론 데이터셋 (ORCA) CoT Prompt
'사고'의 출현과 패러다임 전환 기존 방식 입력 X → 출력
Y 단일의 복잡한 추론 과제 새로운 접근 X → 사고 1 → 사고 2 → Y 순차적 계산 스크래치패드 핵심 효과 복잡한 문제를 간단한 단계로 분해 인간 인지 과정 모방
Reasoning Model (o1, R1 등등)
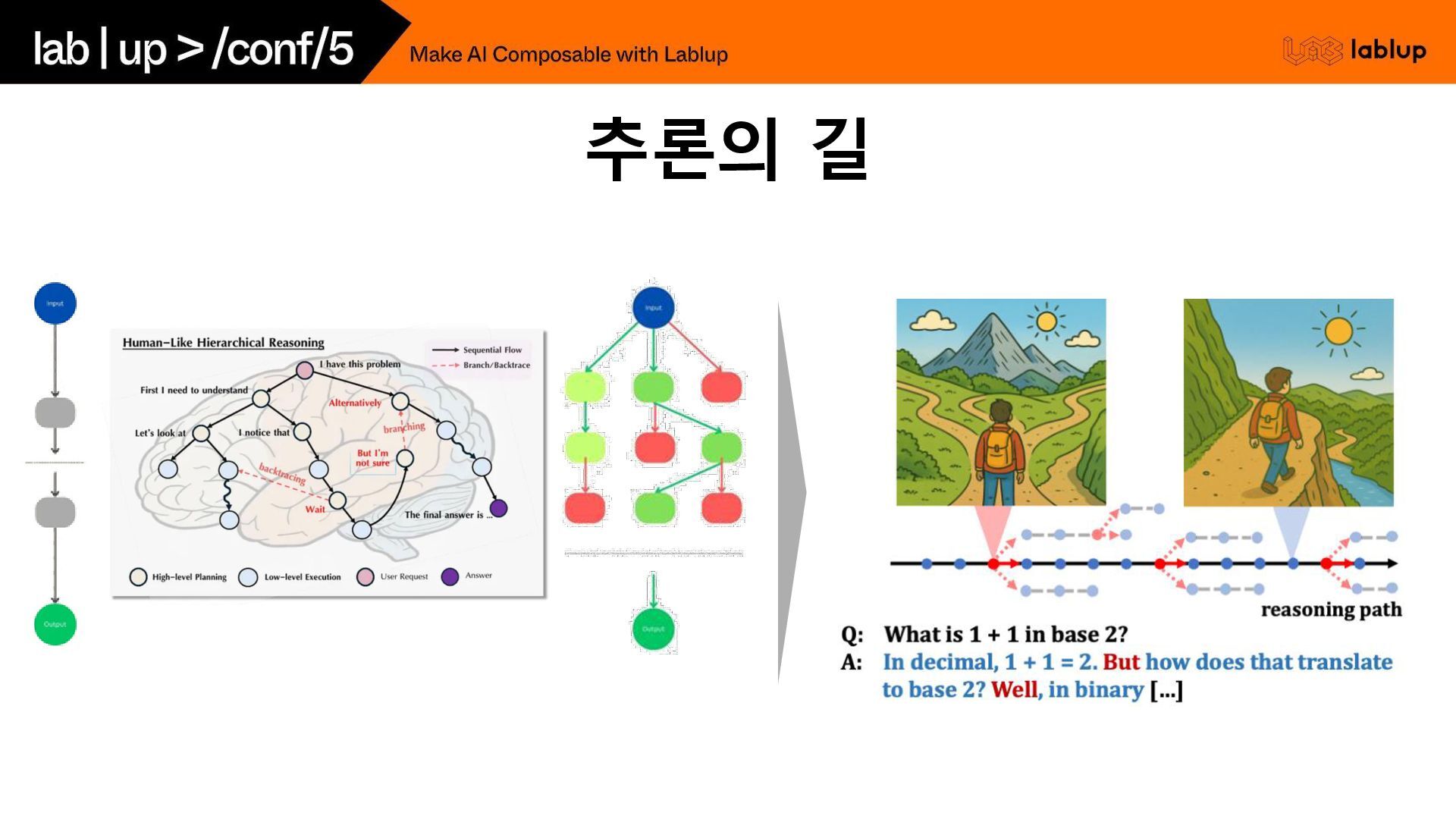
추론의 길
이미 만들어진 길에서 경로 탐색 길을 만들고 다듬기 (Test time
scaling) (추론 학습)
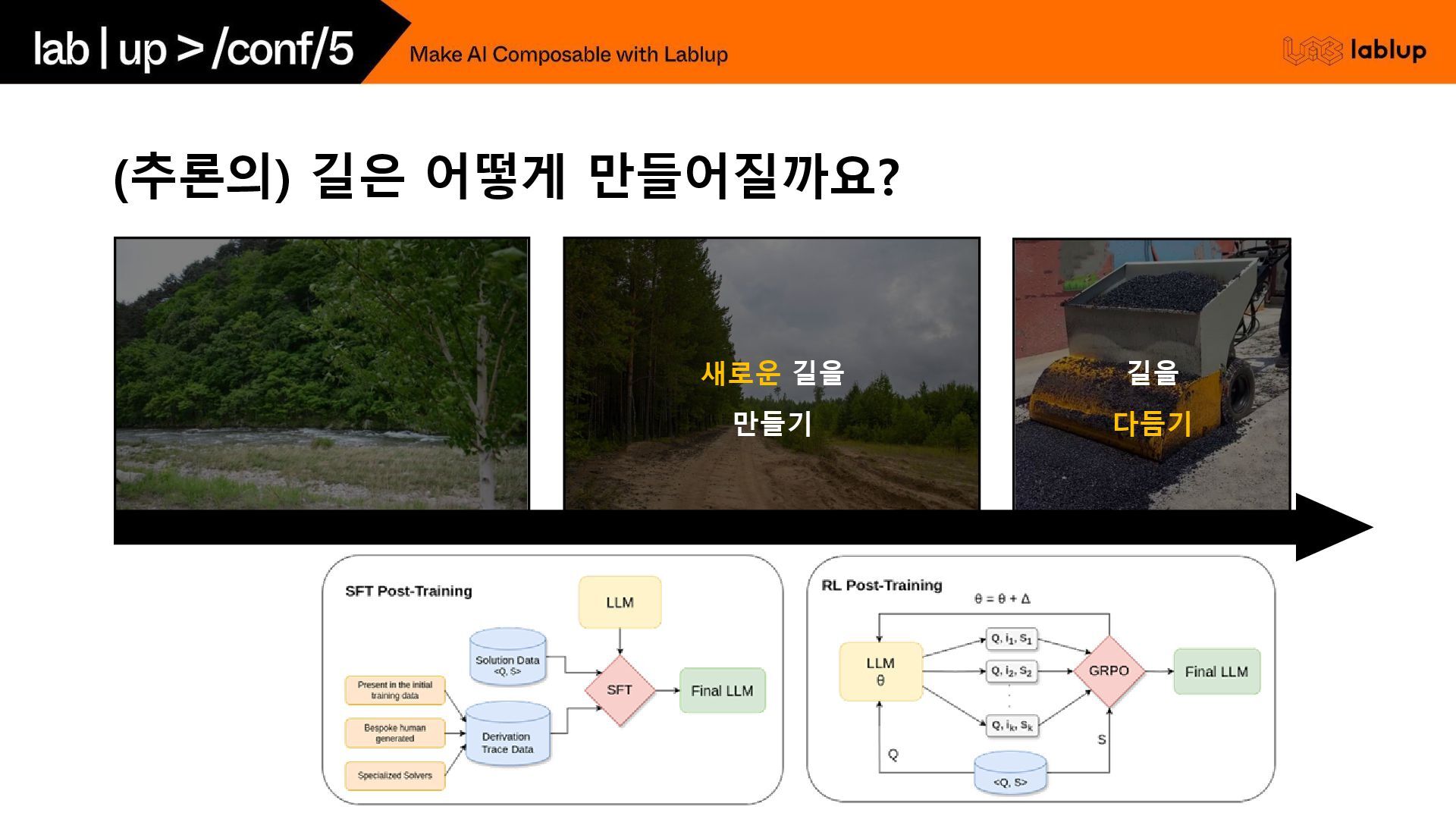
(추론의) 길은 어떻게 만들어질까요? 새로운 길을 만들기 길을 다듬기
RLHF 지도 미세조정 (SFT) 고품질 인간 시연 데이터로 초기 모델
적응 보상 모델 (RM) 훈련 인간 선호도 순위 데이터로 평가 모델 구축 RL 정책 최적화 PPO 알고리즘으로 보상 최대화하며 안전성 유지 보상 모델의 품질과 견고성이 전체 RLHF 파이프라인 성공의 핵심
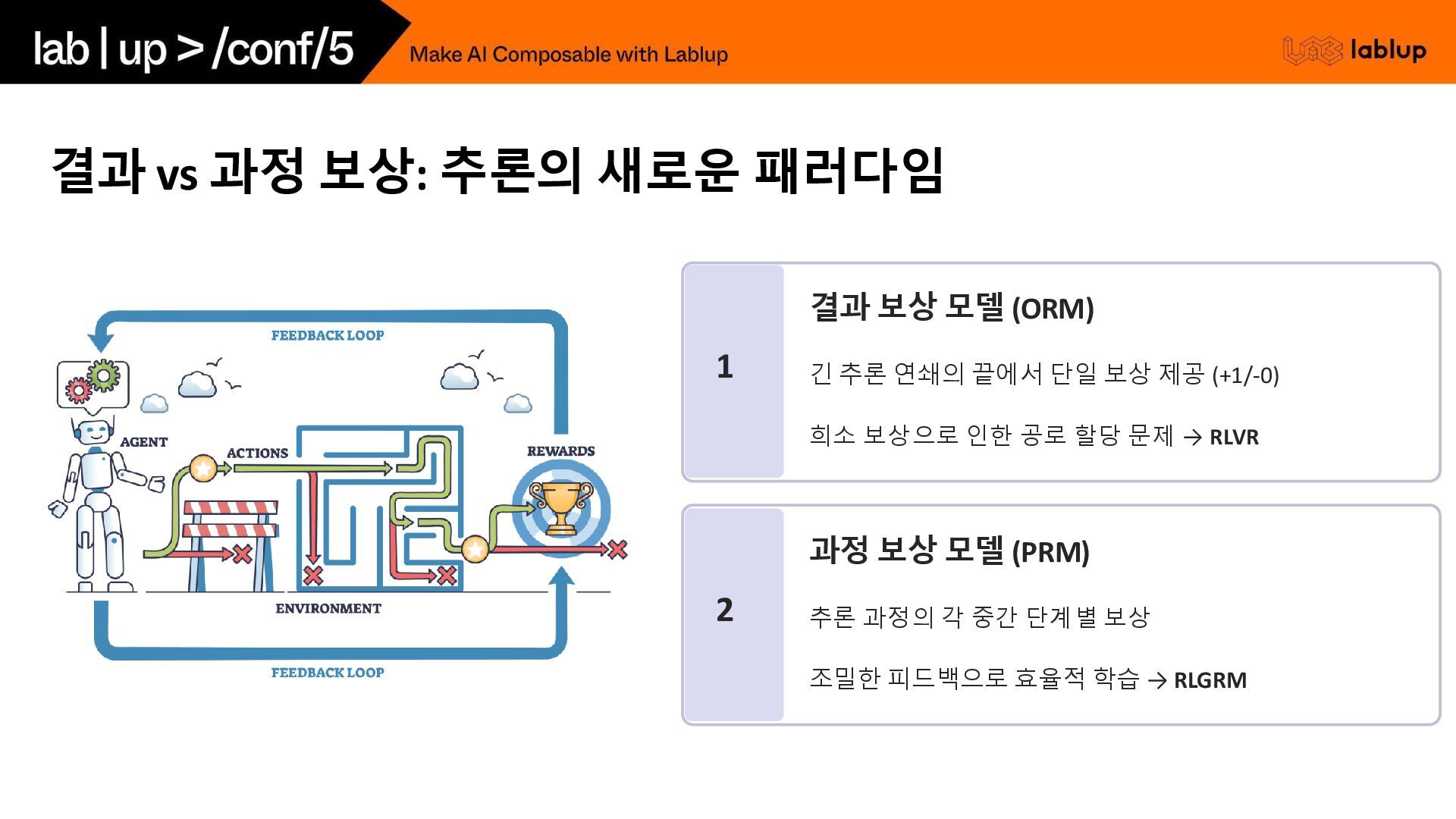
결과 vs 과정 보상: 추론의 새로운 패러다임 1 결과 보상
모델 (ORM) 긴 추론 연쇄의 끝에서 단일 보상 제공 (+1/-0) 희소 보상으로 인한 공로 할당 문제 → RLVR 2 과정 보상 모델 (PRM) 추론 과정의 각 중간 단계별 보상 조밀한 피드백으로 효율적 학습 → RLGRM
Reinforcement Learning with Verifiable Reward (RLVR) RLVR은 계산기, 코드 수행
결과 등 검증 가능한 결과를 이용하여 제대로 추론을 수행하였는지 확인하며 강화학 습하는 방식입니다.
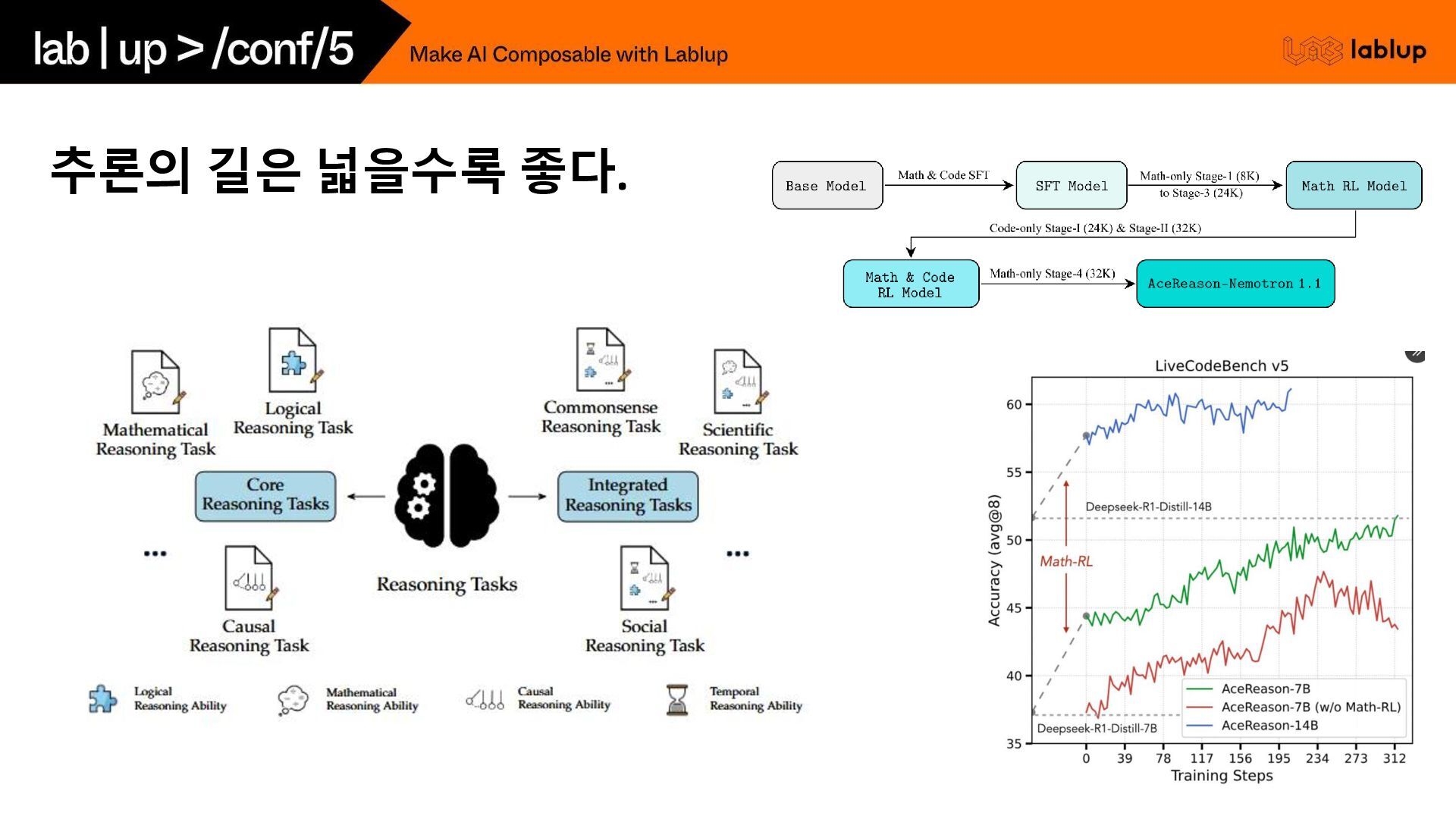
길은 어느정도 너비로 하는게 좋을까요?
추론의 길은 넓을수록 좋다.
어느 곳에 도로 공사를 하는 것이 좋을까요?
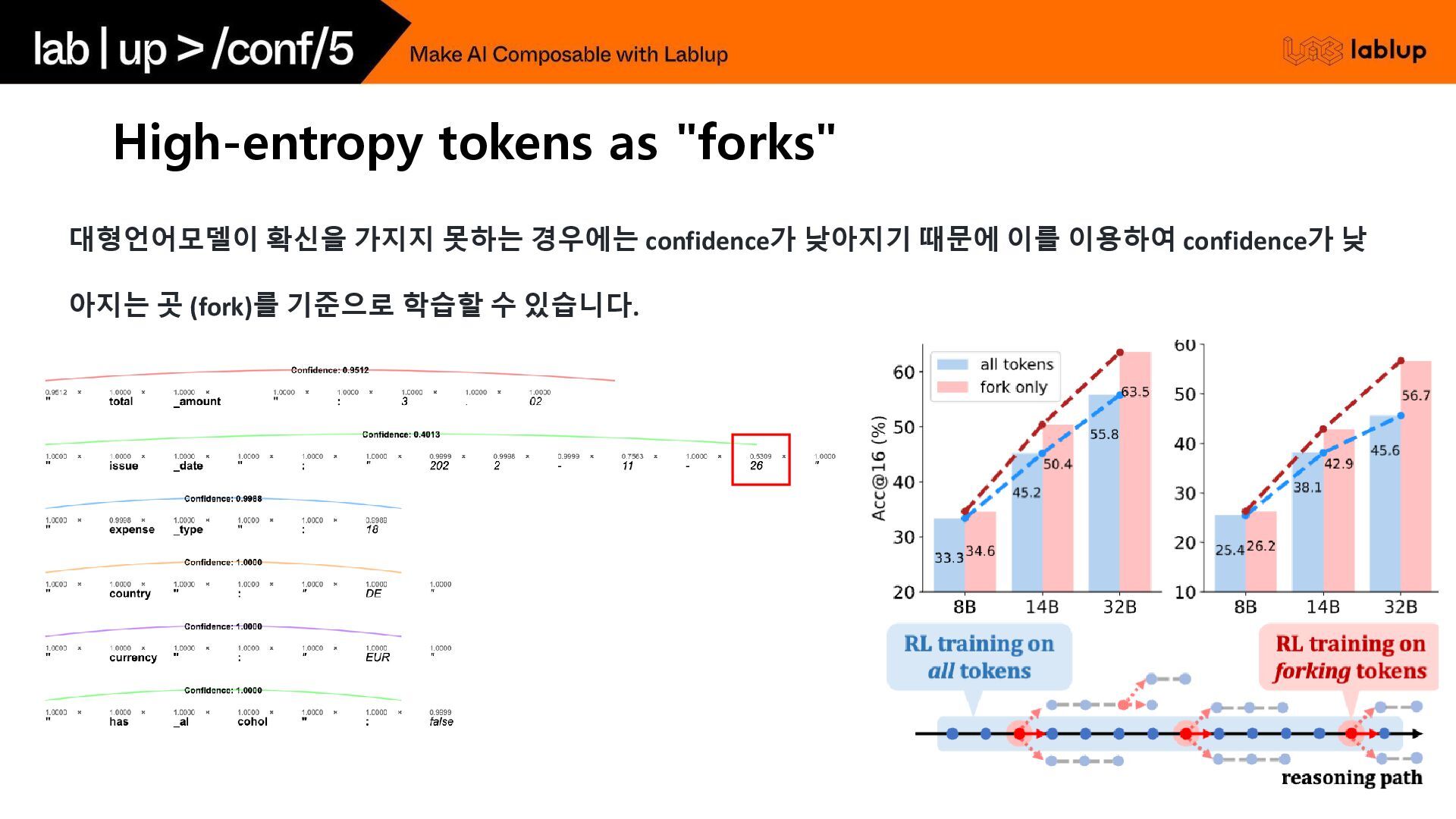
High-entropy tokens as "forks" 대형언어모델이 확신을 가지지 못하는 경우에는 confidence가
낮아지기 때문에 이를 이용하여 confidence가 낮 아지는 곳 (fork)를 기준으로 학습할 수 있습니다.
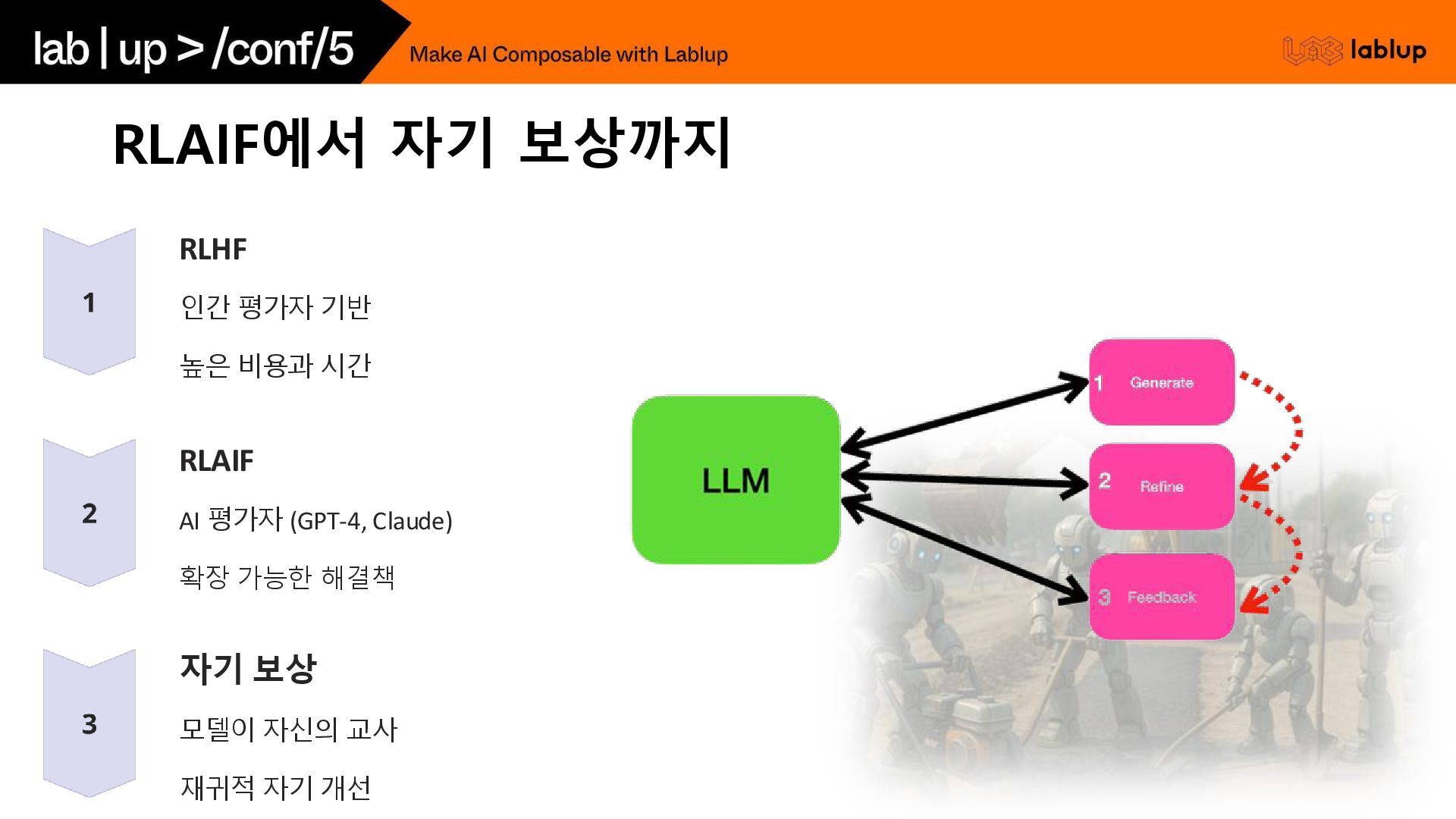
RLAIF에서 자기 보상까지 RLHF 인간 평가자 기반 높은 비용과 시간
RLAIF AI 평가자 (GPT-4, Claude) 확장 가능한 해결책 자기 보상 모델이 자신의 교사 재귀적 자기 개선
지금 우리가 진정한 기술적 돌파구와 마주하고 있을지도 모릅니다
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}