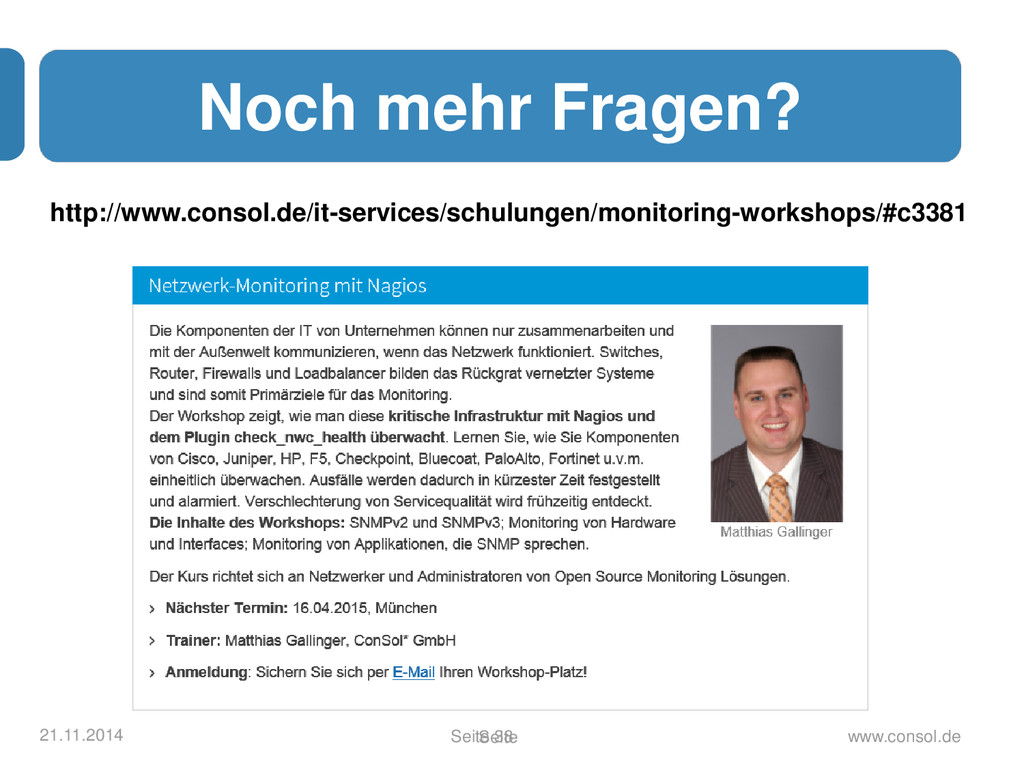
Die Komponenten einer Unternehmens-IT können nur zusammenarbeiten und mit der Außenwelt kommunizieren, wenn das Netzwerk funktioniert. Switches, Router, Firewalls und Loadbalancer bilden das Rückgrat vernetzter Systeme und sind somit Primärziele für das Monitoring. Bisher gab es für jedes Fabrikat und jeden Abfragetyp ein extra Plug-in. Dies führte dazu, dass in Nagios-Installationen mehr als zehn Plug-ins, natürlich jedes mit seiner eigenen Kommandozeilensyntax, zum Einsatz kamen. Um diesen Irrsinn zu beenden wurde check_nwc_health geschrieben. Es hat sich zum Ziel gesetzt, sämtliche Anforderungen beim Monitoring der gebräuchlichsten Netzwerkkomponenten in einem einzigen Plug-in zu bündeln.
Mittlerweile wird es in mehreren Umgebungen mit jeweils tausenden von Netzknoten (Cisco, Juniper, HP, CheckPoint, F5, Brocade, Bluecoat uvm.) erfolgreich eingesetzt und die Liste der Features wächst stetig.
Gerhard Laußer zeigt, wie mit wenig Aufwand ein Netzwerk-Monitoring auf Basis von check_nwc_health eingerichtet werden kann und wie man das Plug-in mit wenigen Zeilen Code für spezielle Anforderungen aufbohren kann.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}