Presented at SDSS 2019:
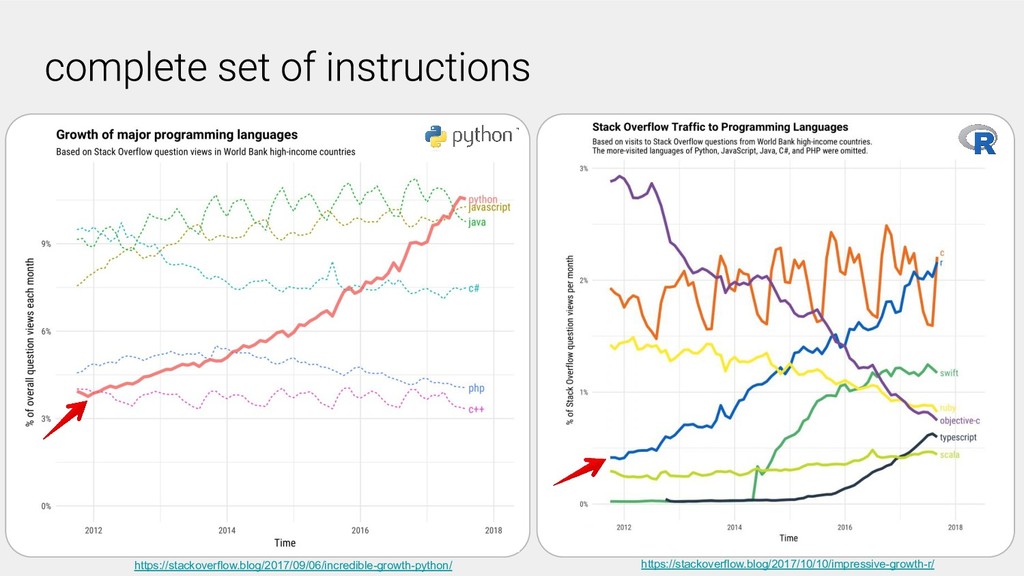
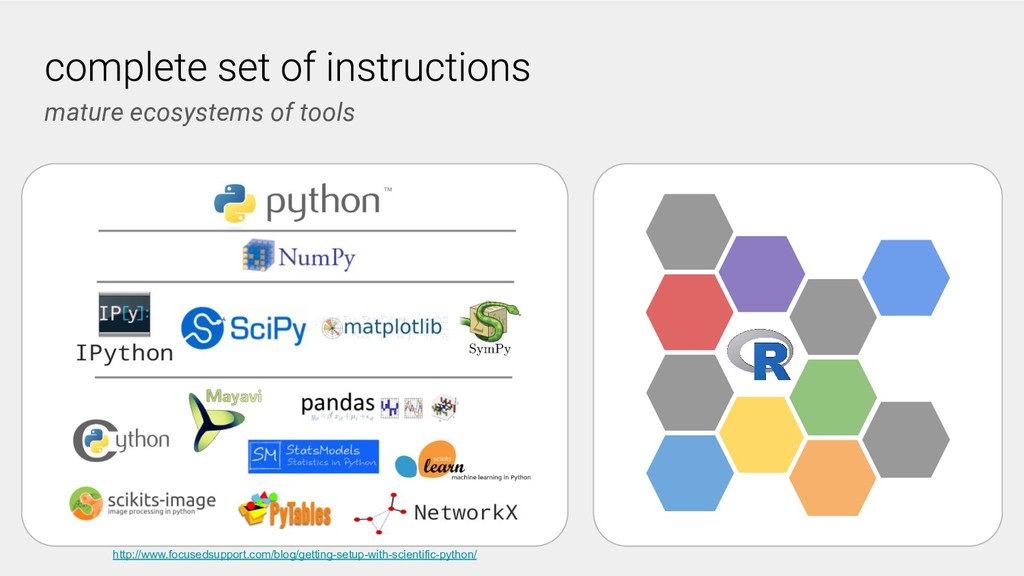
Despite the motivation that many researchers have to make their computationational work reproducible, there are a number of barriers that make it challenging. Some of these are cultural and behavioral, for example the use of proprietary codes or a lack of documentation. Others challenges are more technical in nature, these include the overhead of installing software and managing a software environment. Many research groups are promoting a cultural shift to the open sharing of research code and data, for example sharing their work on GitHub, GitLab, or the Open Science Framework. However, there is no easy way for other researchers or interested users to interact with these analyses.
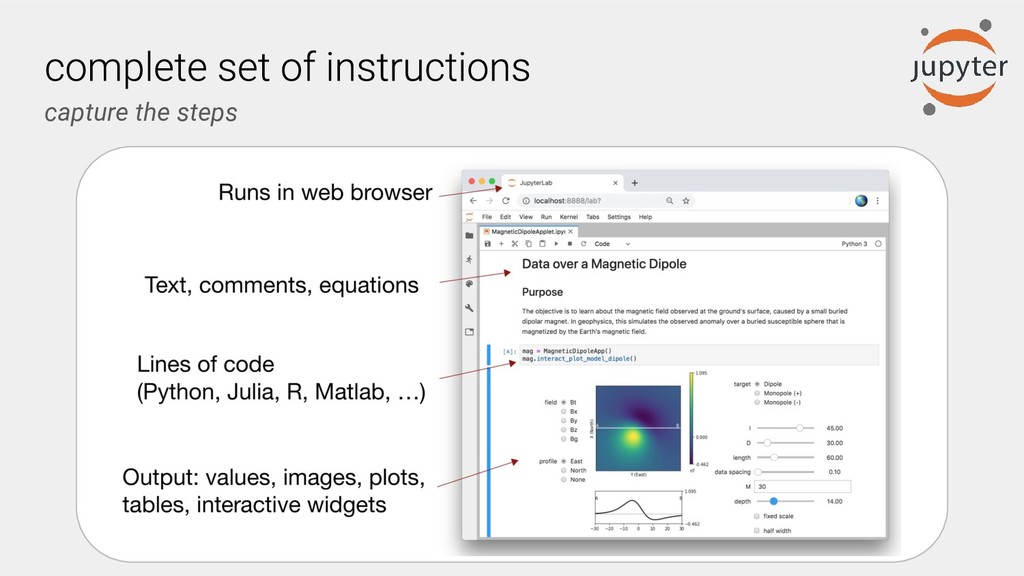
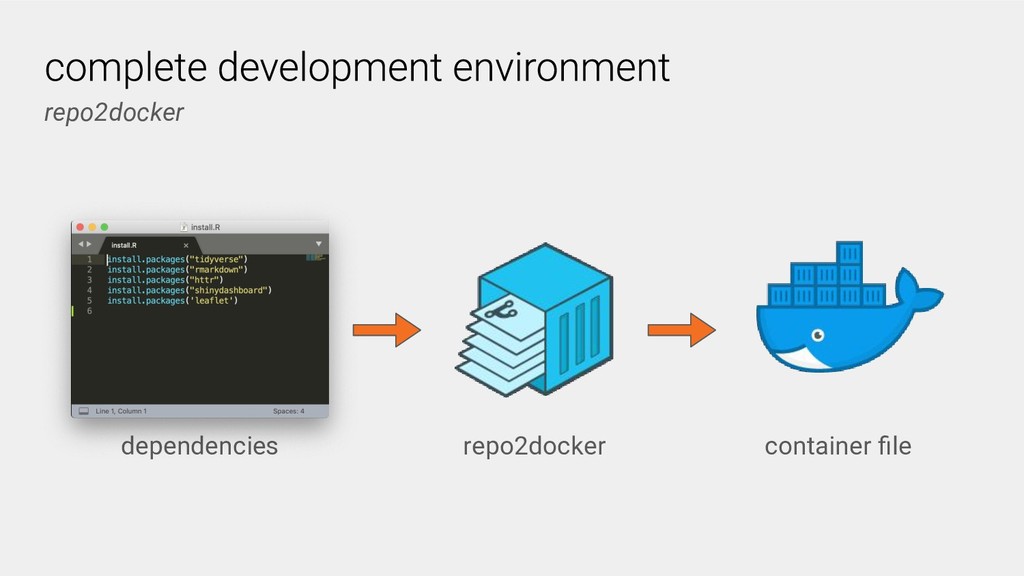
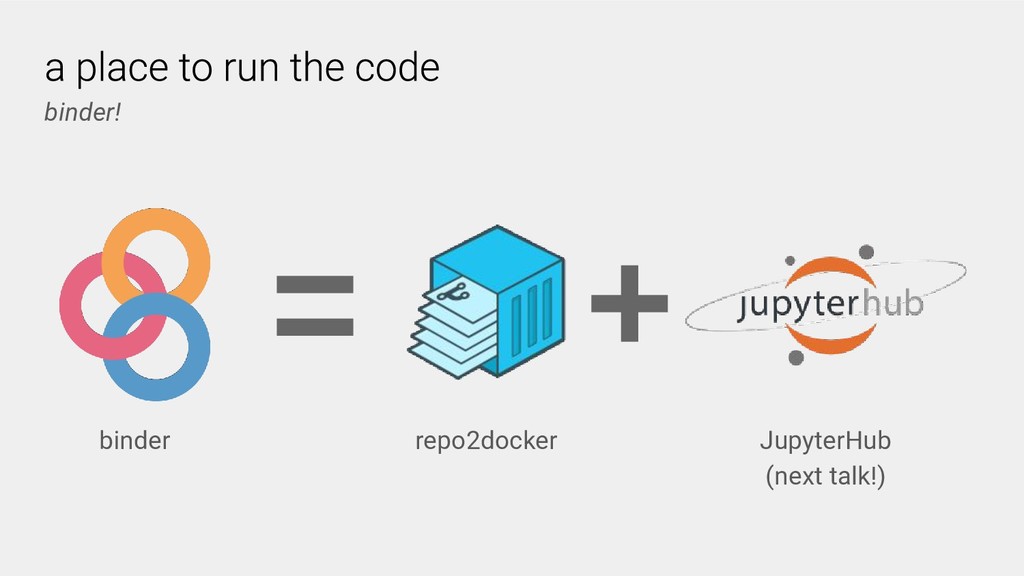
The Binder project aims to reduce these technical barriers by enabling researchers to share their computational workflows in an interactive computing environment that runs in the cloud. It is built on the Jupyter architecture; e.g. the BinderHub component builds upon JupyterHub for the specific use case of sharing standalone code repositories. BinderHub provides the core framework that deploys the Binder service in the cloud. It is scalable, can be deployed on your own cloud instances or hardware, and supports many of the common languages (e.g. Python, Julia and R) and interfaces (e.g. JupyterLab, RStudio) that are used in data science.
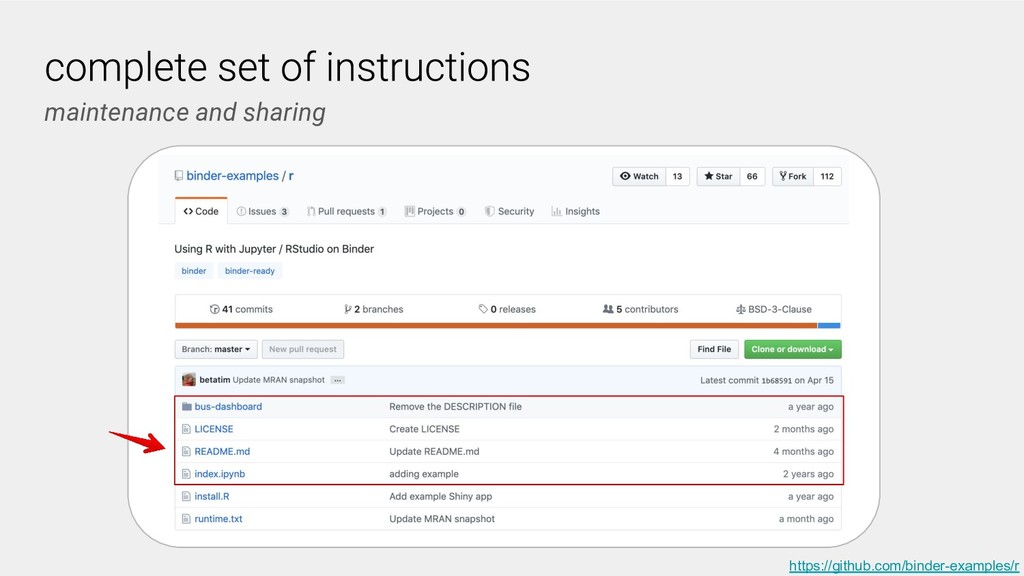
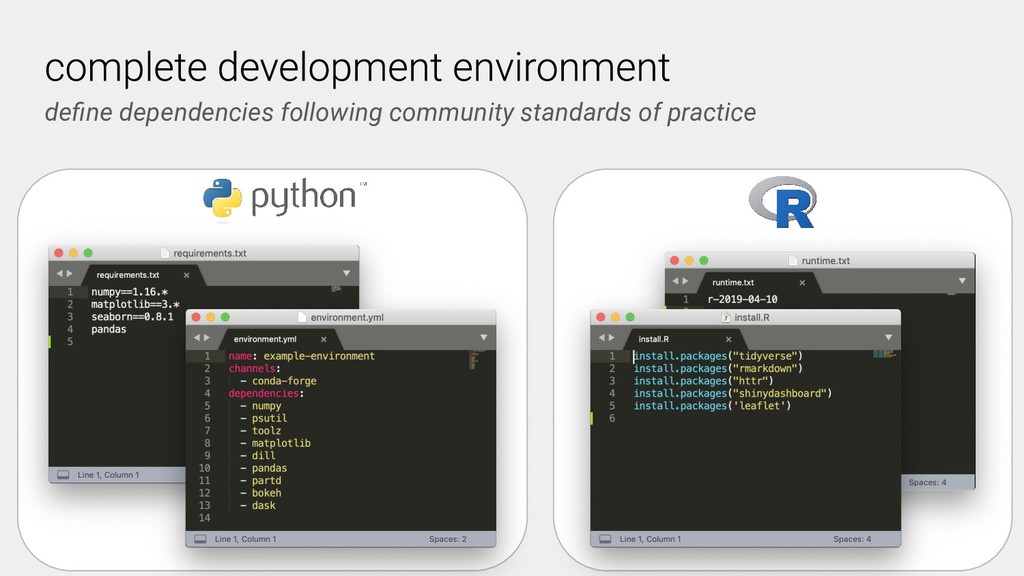
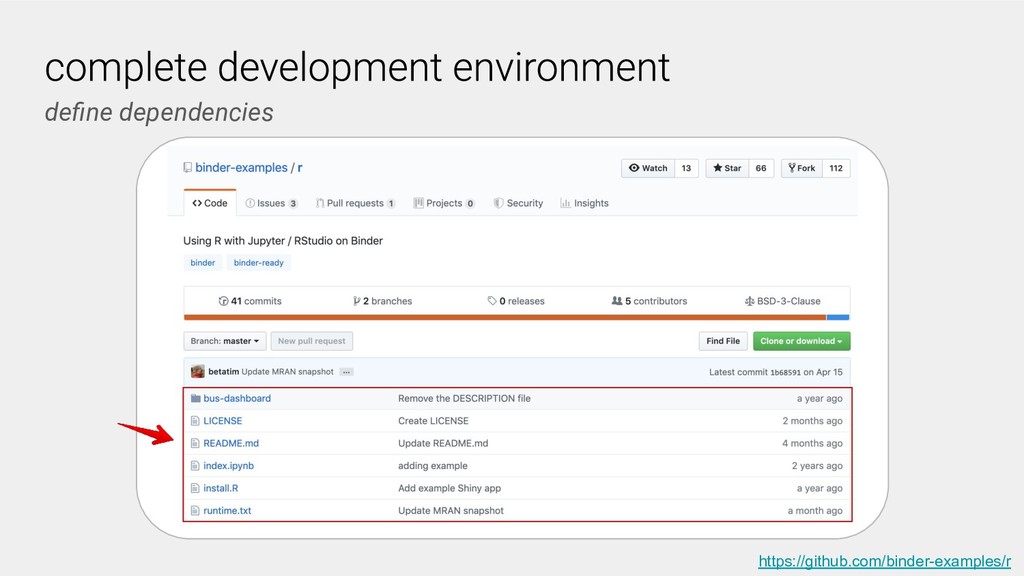
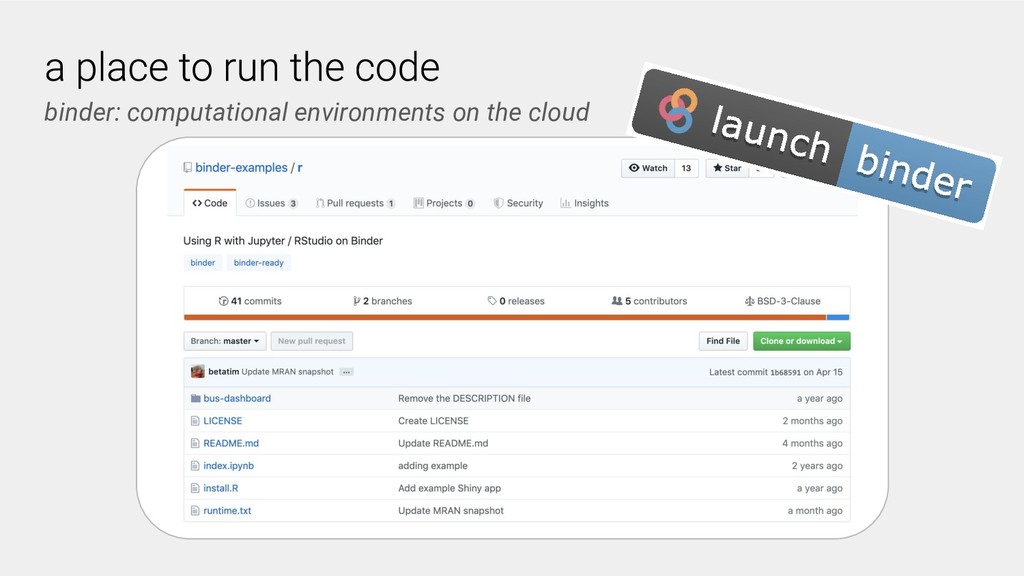
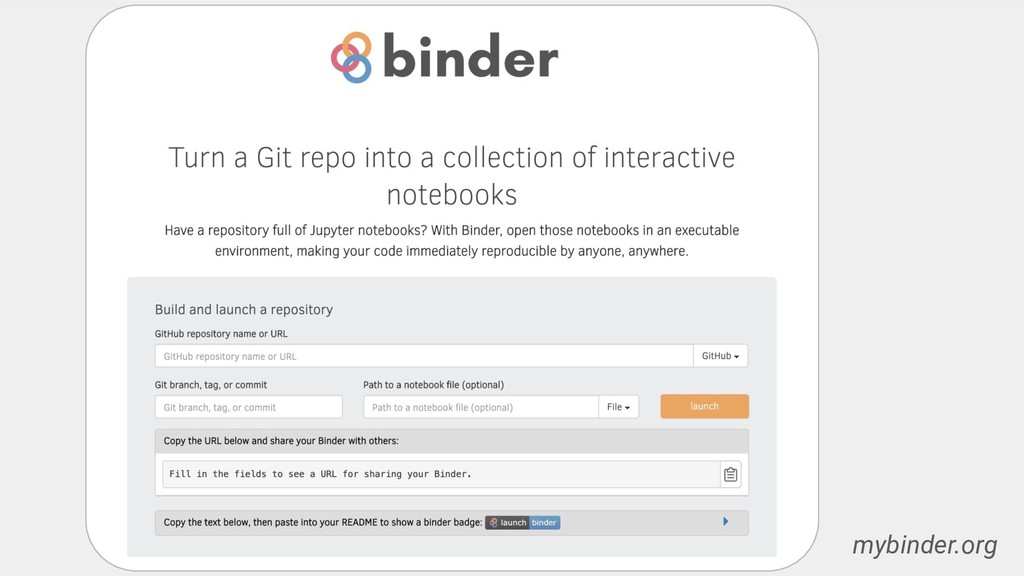
A researcher sharing their work specifies the computational environment, for example, in Python dependencies can be specified in a requirements.txt file, and provides their computational workflows, commonly in the form of Jupyter notebooks in a GitHub repository. Users and other researchers can then access and interactively run these computations on the cloud simply by following a URL. One free-to-use example of a BinderHub deployment is: https://mybinder.org.
In this presentation, we will provide an overview of the Binder project and demonstrate how researchers can share their computations through Binder.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}