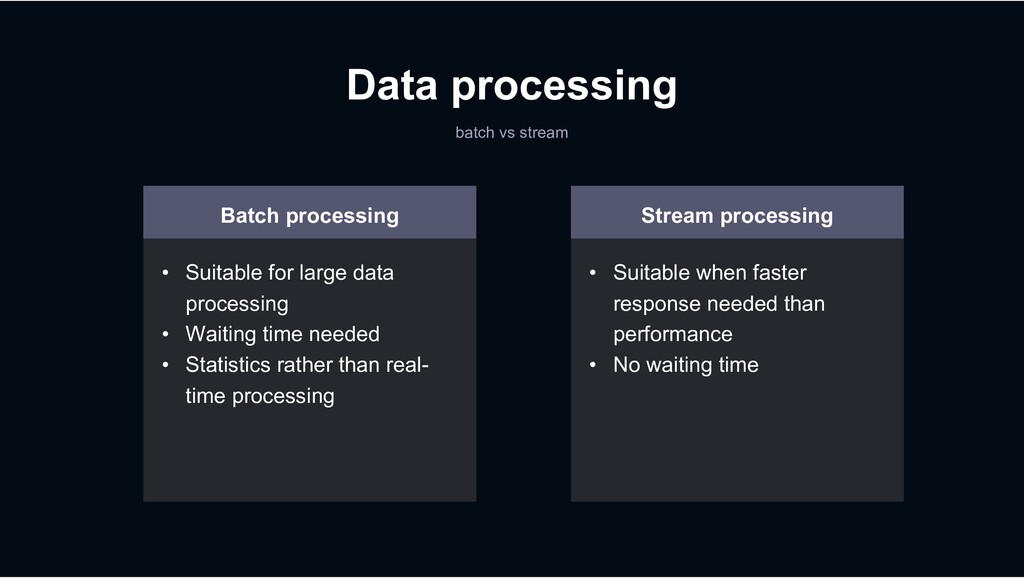
large data processing • Waiting time needed • Statistics rather than real- time processing Stream processing • Suitable when faster response needed than performance • No waiting time
products? Batch processing • Suitable for large data processing • Waiting time needed • Statistics rather than real- time processing Stream processing • Suitable when faster response needed than performance • No waiting time
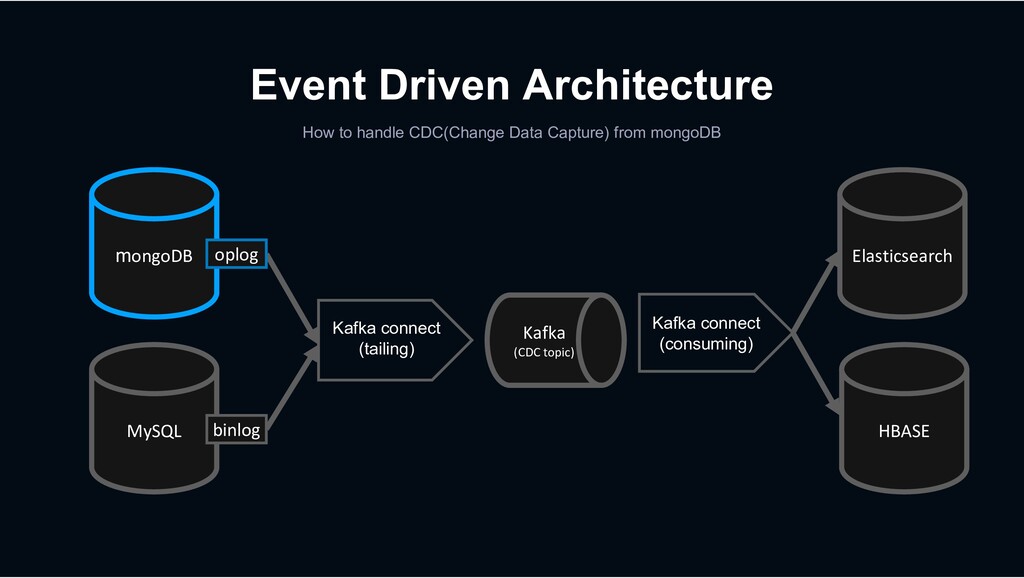
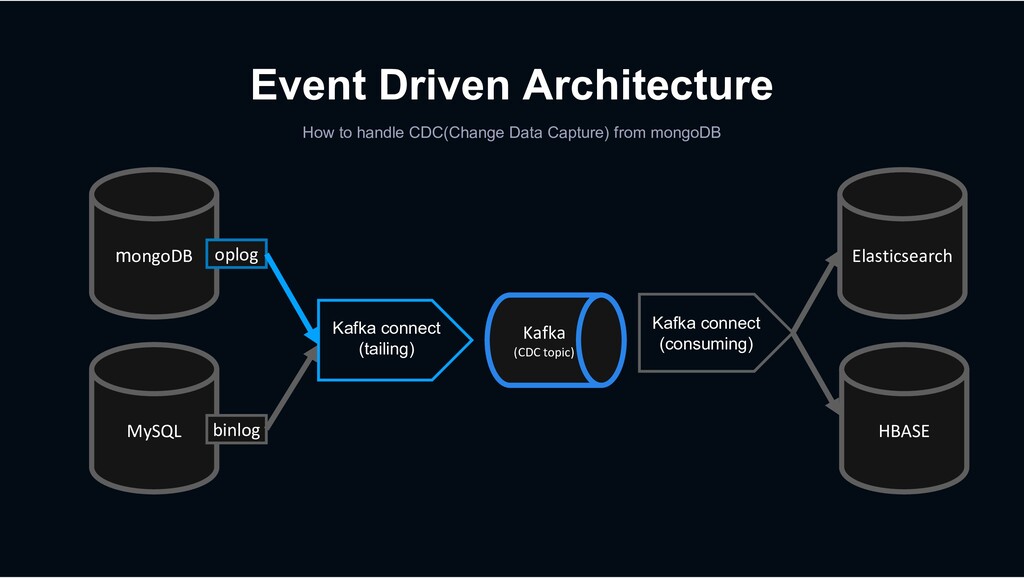
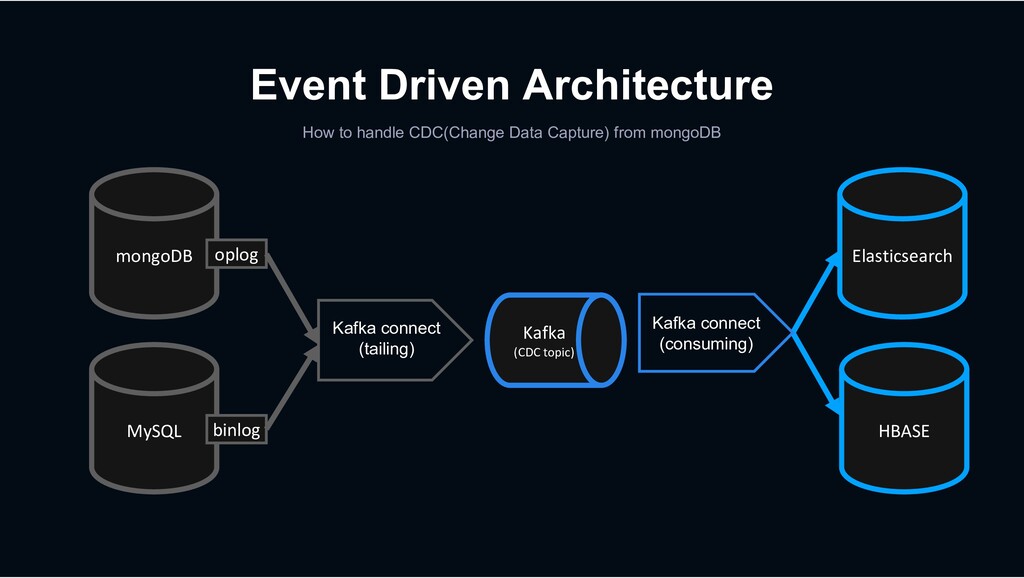
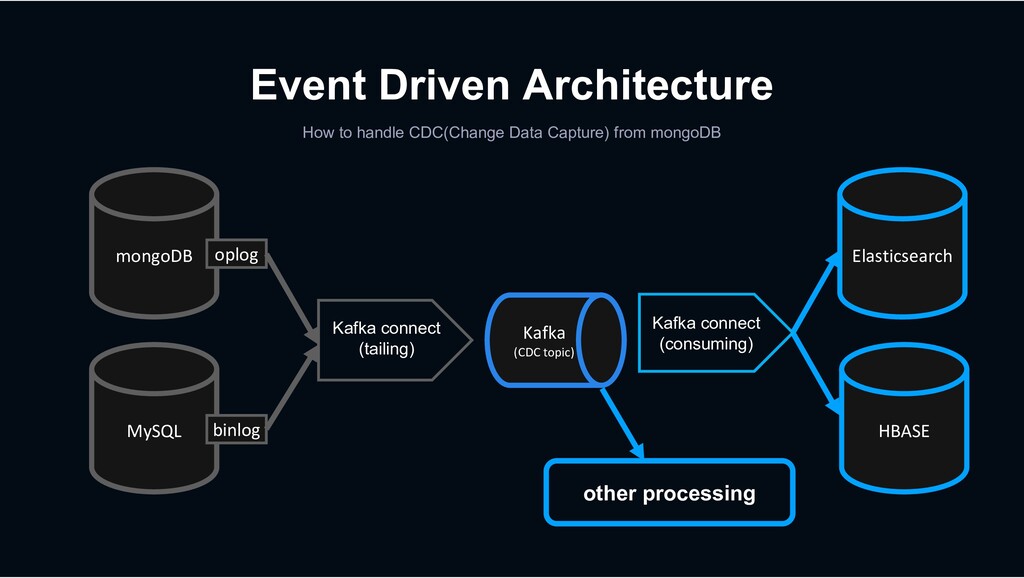
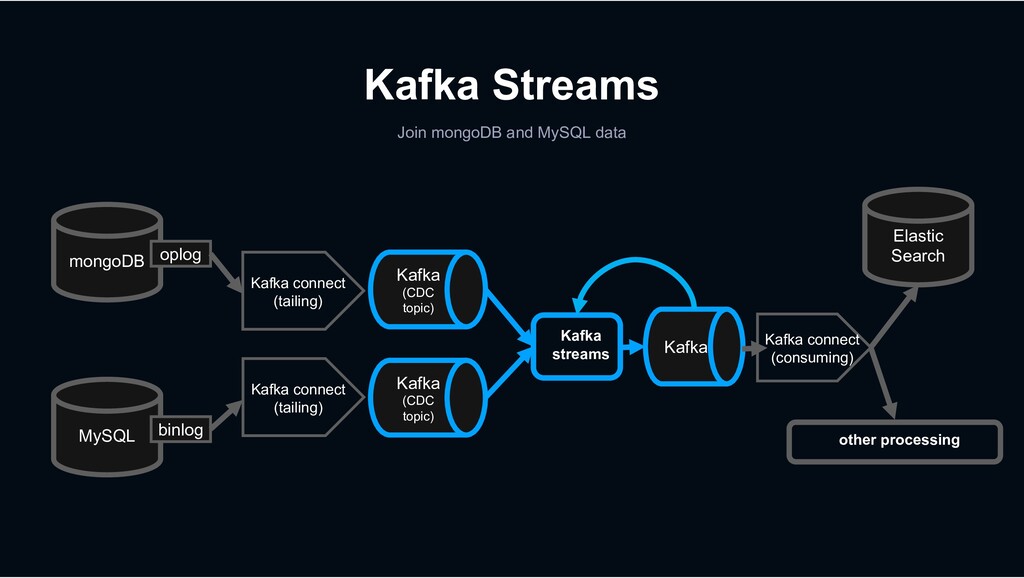
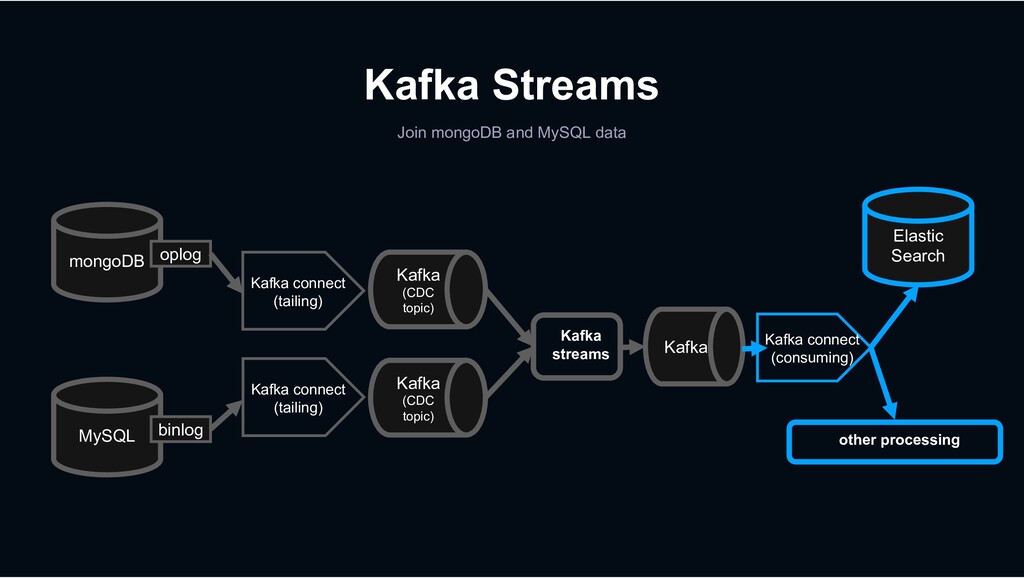
Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other data systems. It makes it simple to quickly define connectors that move large data sets into and out of Kafka.
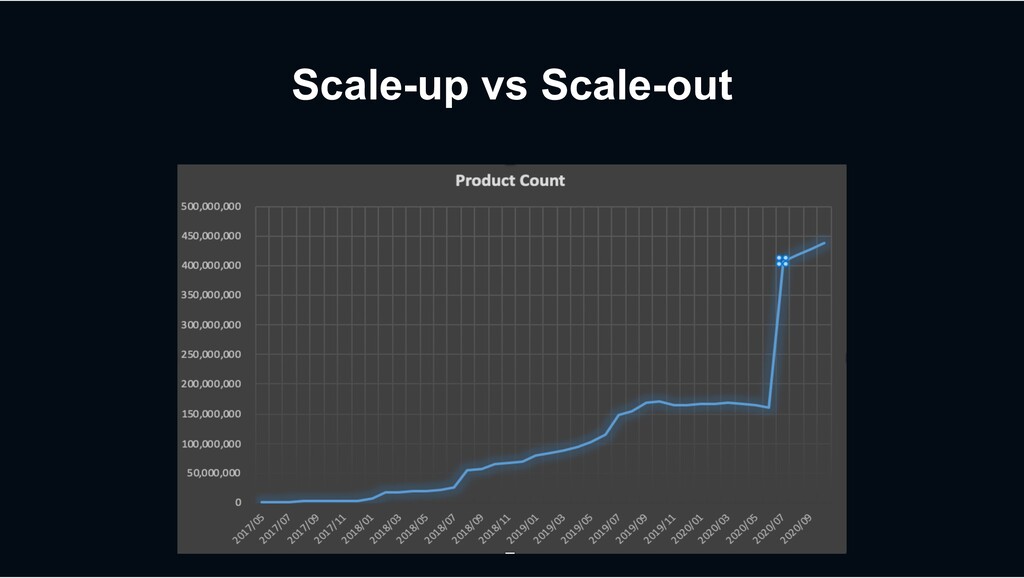
as OLTP • Less increase in performance with a cost increase • Fewer control points Scale-out • Suitable for parallel processing of large amounts of data • Linear performance improvement expected with a cost increase • Needs to manage a large number of servers
as OLTP • Less increase in performance with a cost increase • Fewer control points Scale-out • Suitable for parallel processing of large amounts of data • Linear performance improvement expected with a cost increase • Needs to manage a large number of servers
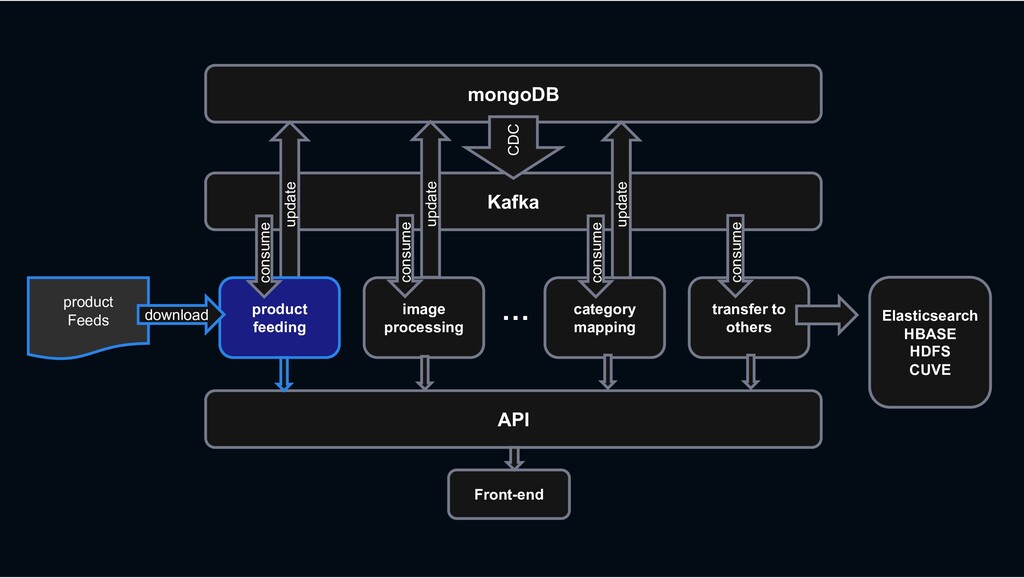
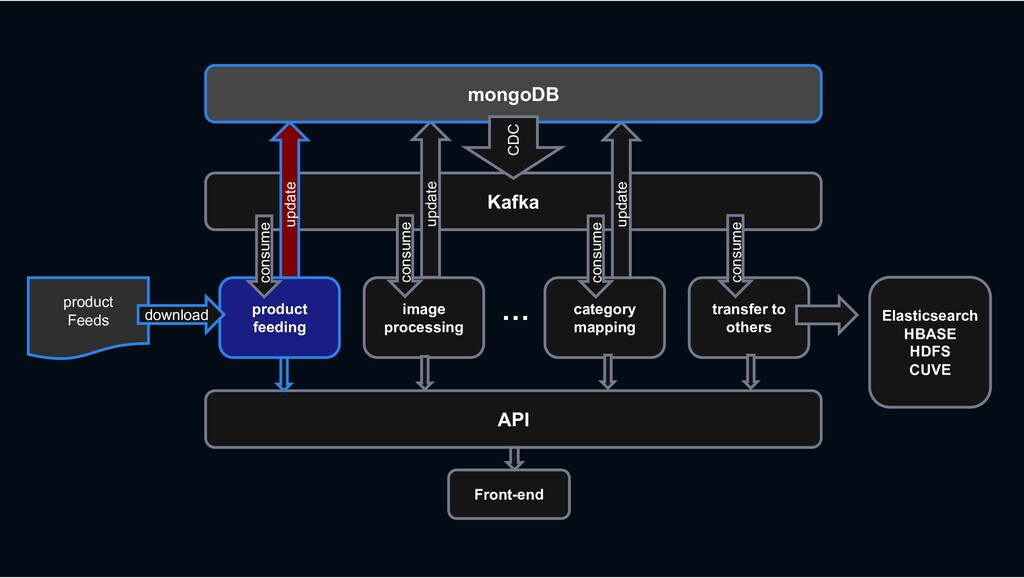
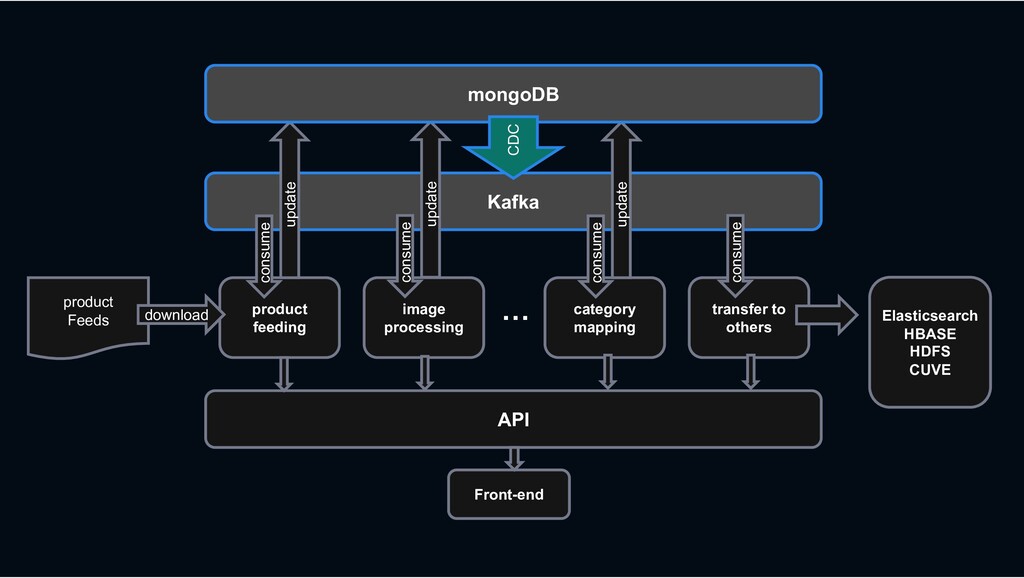
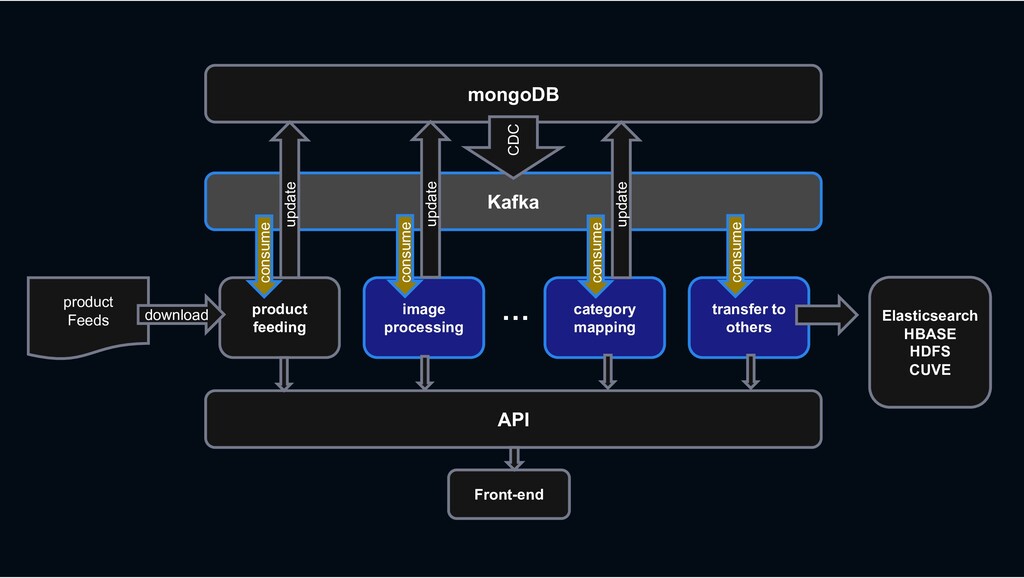
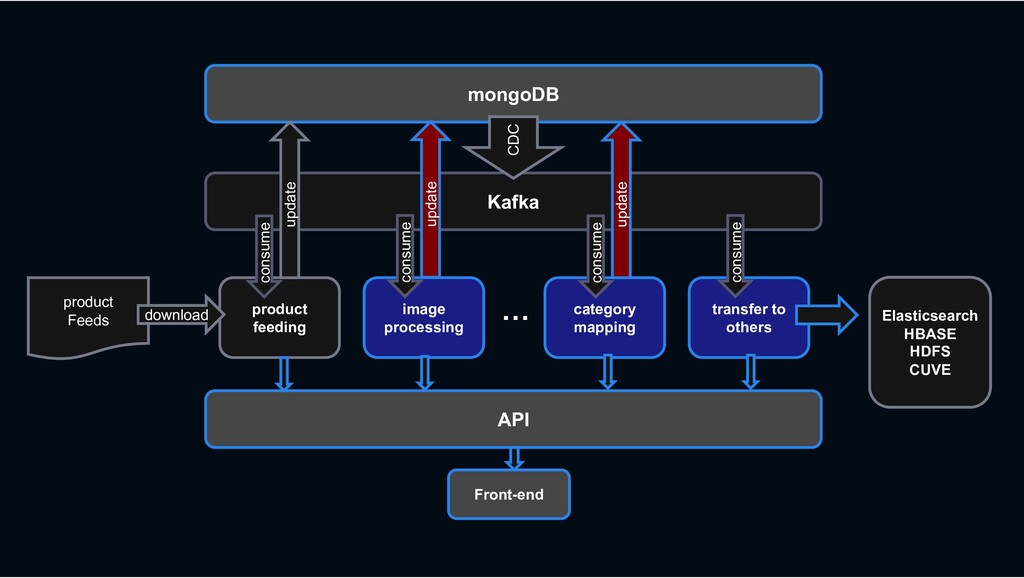
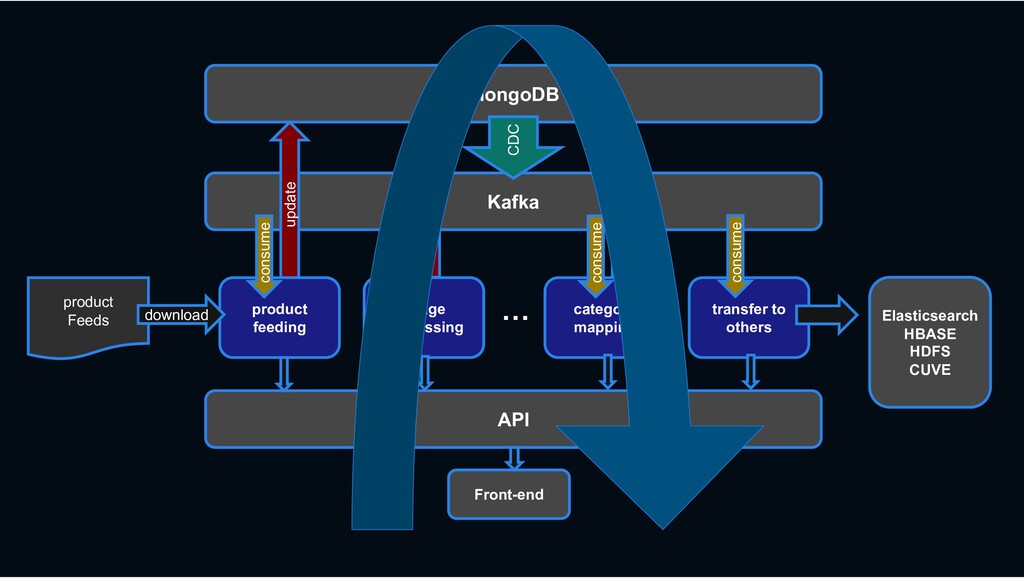
RESTful API RESTful API Front-end Stream process › feeding processing, image processing, category mapping, etc. › ES index, Hbase linkage, search system linkage
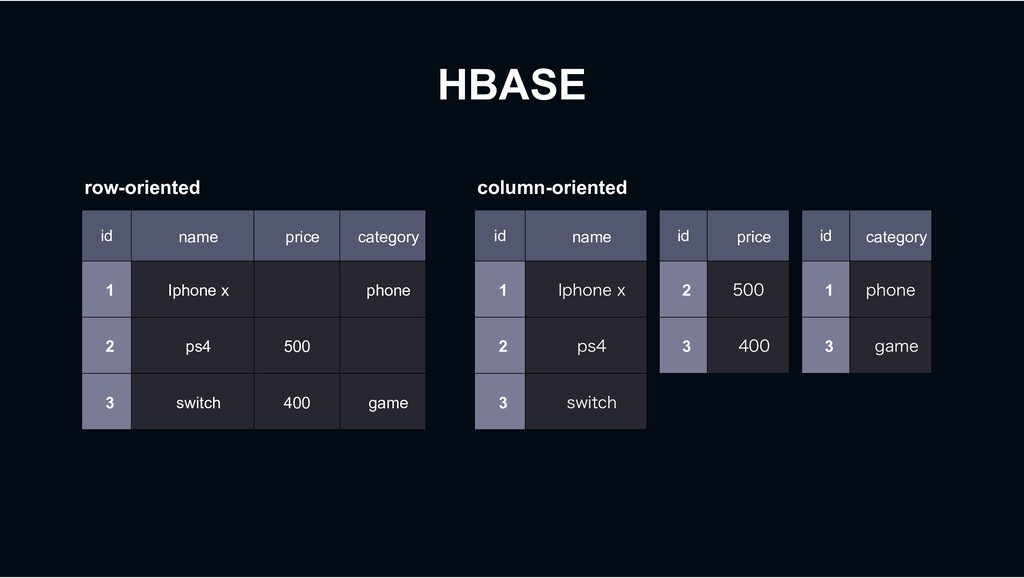
Shopping › less rows and requires transactions MySQL › column-oriented versioning › Backbone for stream processing HBASE Kafka › Bulk data requiring scalability mongoDB › High-performance big data processing › Provide search function Hadoop Elasticsearch
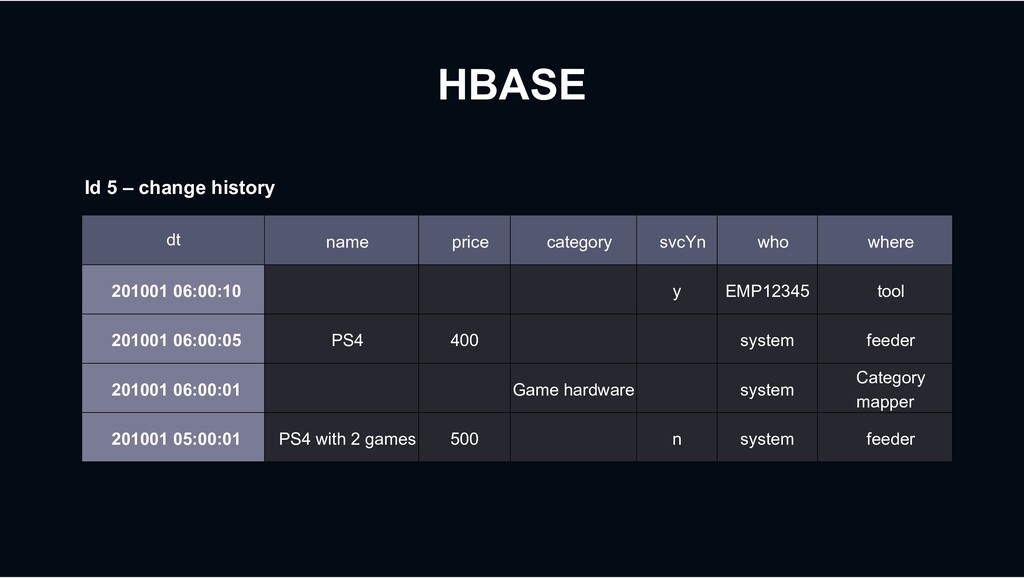
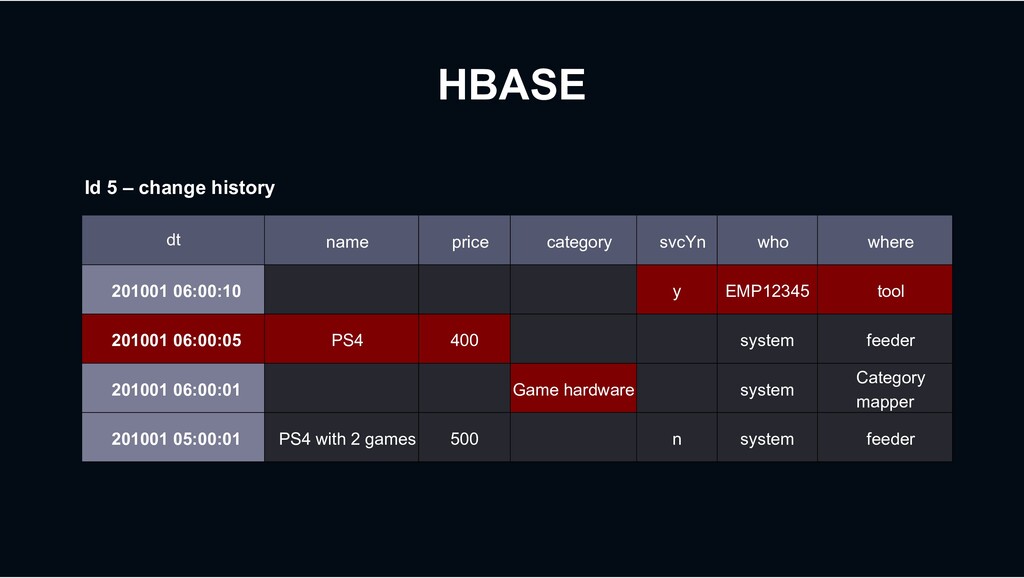
y EMP12345 tool 201001 06:00:05 PS4 400 system feeder 201001 06:00:01 Game hardware system Category mapper 201001 05:00:01 PS4 with 2 games 500 n system feeder Id 5 – change history
y EMP12345 tool 201001 06:00:05 PS4 400 system feeder 201001 06:00:01 Game hardware system Category mapper 201001 05:00:01 PS4 with 2 games 500 n system feeder Id 5 – change history
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
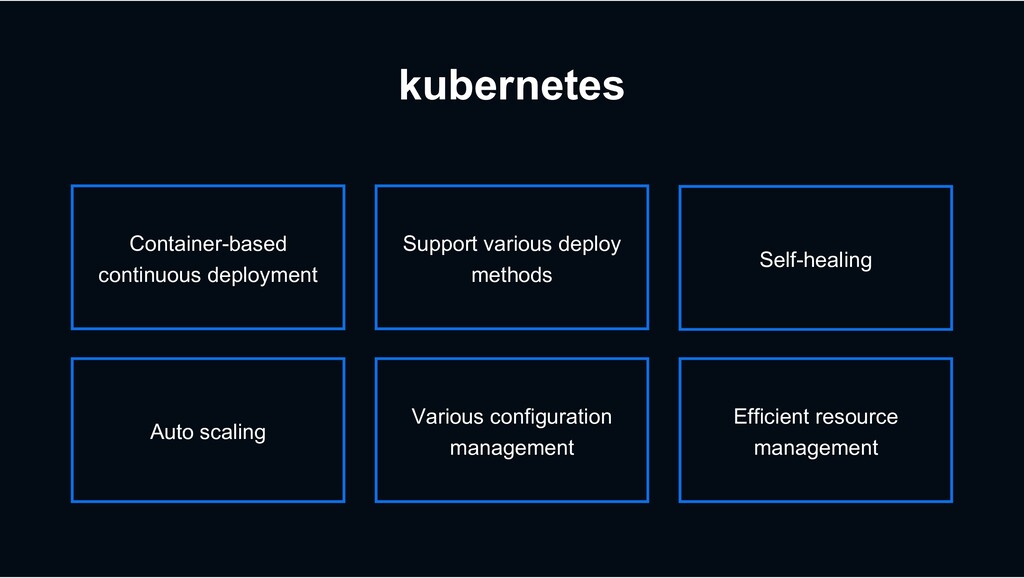{kind=link}
{kind=link}
{kind=link}
{kind=link}
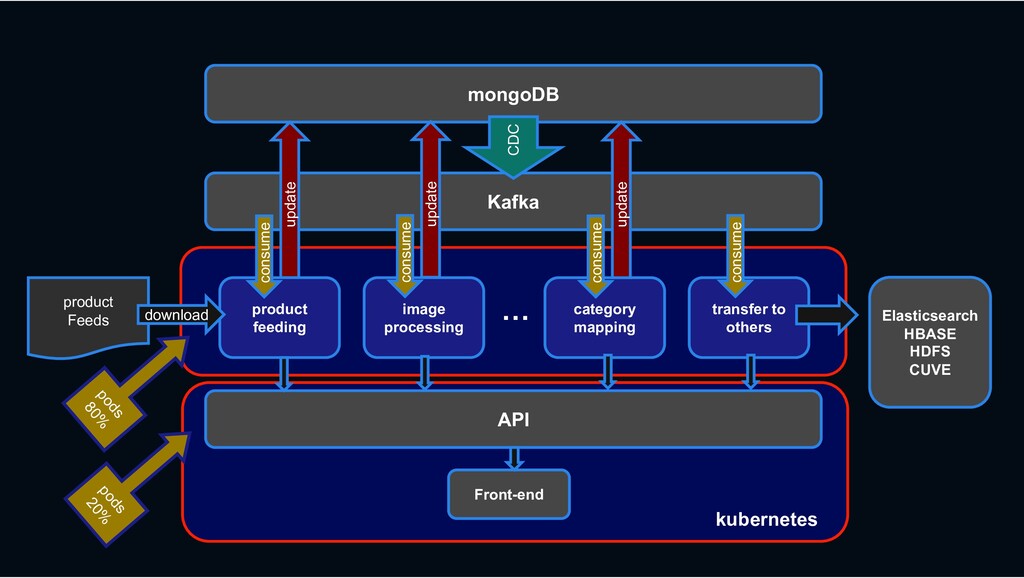{kind=link}
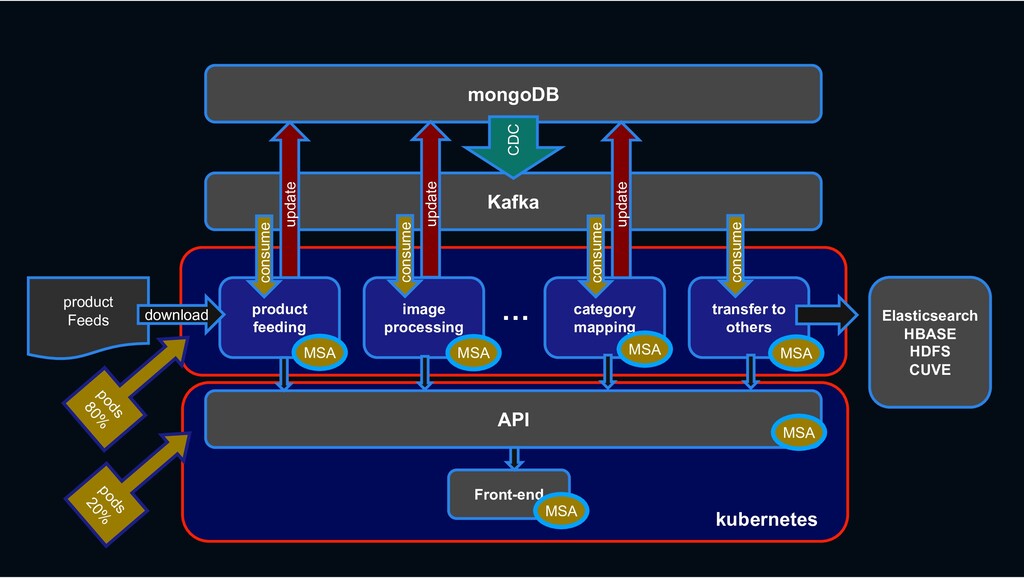{kind=link}
{kind=link}
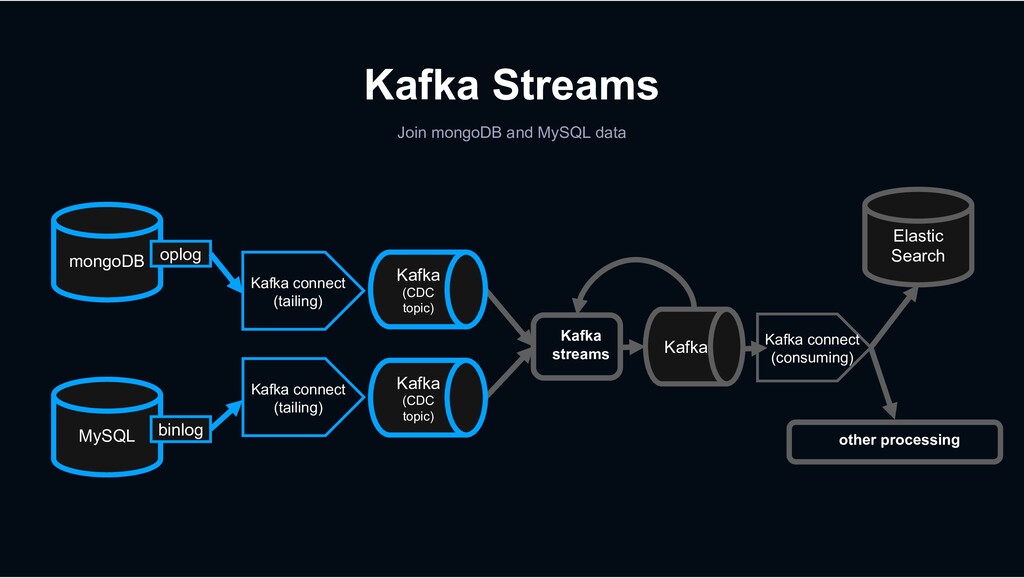{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}