2017] Liu, Weiyang, et al. "Deep hyperspherical learning." Advances in Neural Information Processing Systems. 2017. [Ranjan, Rajeev, et al. 2017] Ranjan, Rajeev, Carlos D. Castillo, and Rama Chellappa. "L2-constrained softmax loss for discriminative face verification." arXiv preprint arXiv:1703.09507 (2017). [Liu, Yu, et al. 2017] Liu, Yu, Hongyang Li, and Xiaogang Wang. "Rethinking feature discrimination and polymerization for large-scale recognition." arXiv preprint arXiv:1710.00870 (2017). [Liu, Weiyang, et al. 2016] Liu, Weiyang, et al. "Large-Margin Softmax Loss for Convolutional Neural Networks." ICML. 2016. [Liu, Weiyang, et al. 2017] Liu, Weiyang, et al. "Sphereface: Deep hypersphere embedding for face recognition." The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Vol. 1. 2017. [Li, Jian, et al. 2018] Li, Jian, et al. "AF-Softmax for Face Recognition." 2018 International Conference on Network Infrastructure and Digital Content (IC-NIDC). IEEE, 2018. [Liang, Xuezhi, et al. 2017] Liang, Xuezhi, et al. "Soft-margin softmax for deep classification." International Conference on Neural Information Processing. Springer, Cham, 2017. [Wang, Feng, et al. 2018] Wang, Feng, et al. "Additive margin softmax for face verification." IEEE Signal Processing Letters 25.7 (2018): 926-930. 33
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
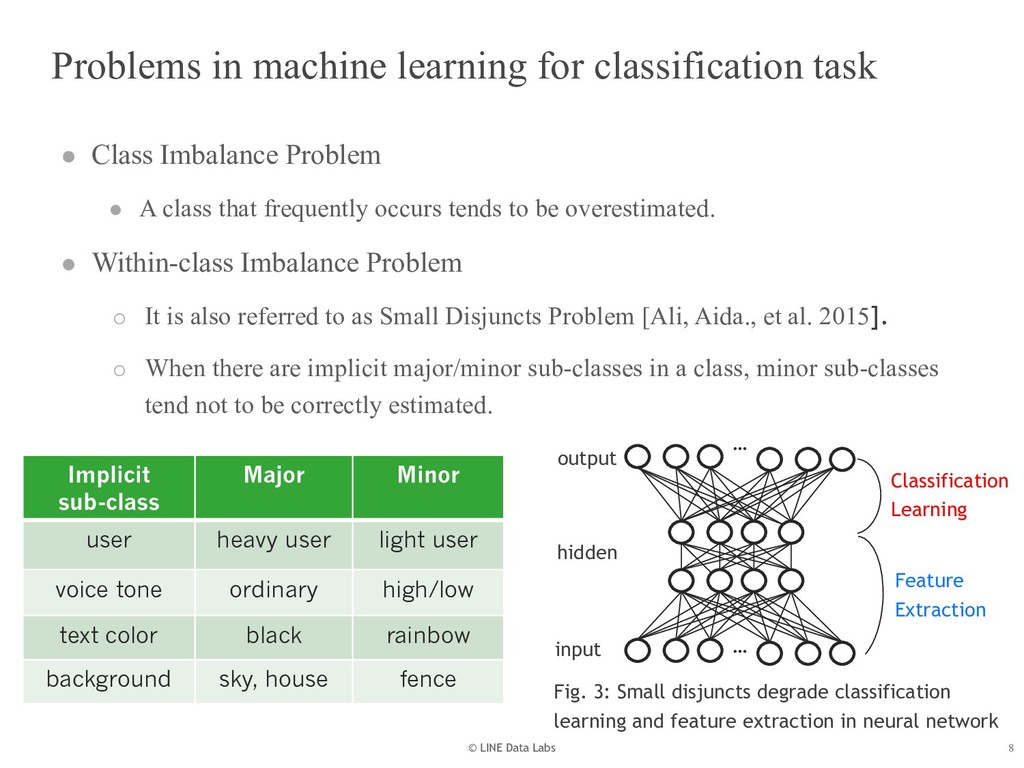{kind=link}
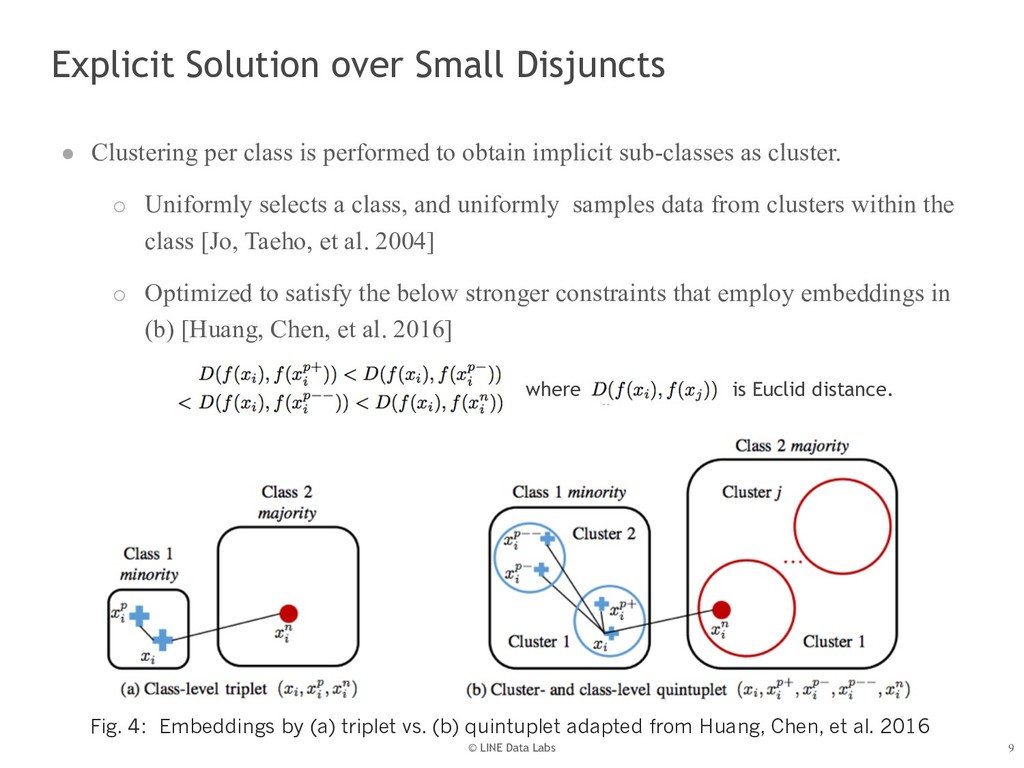{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
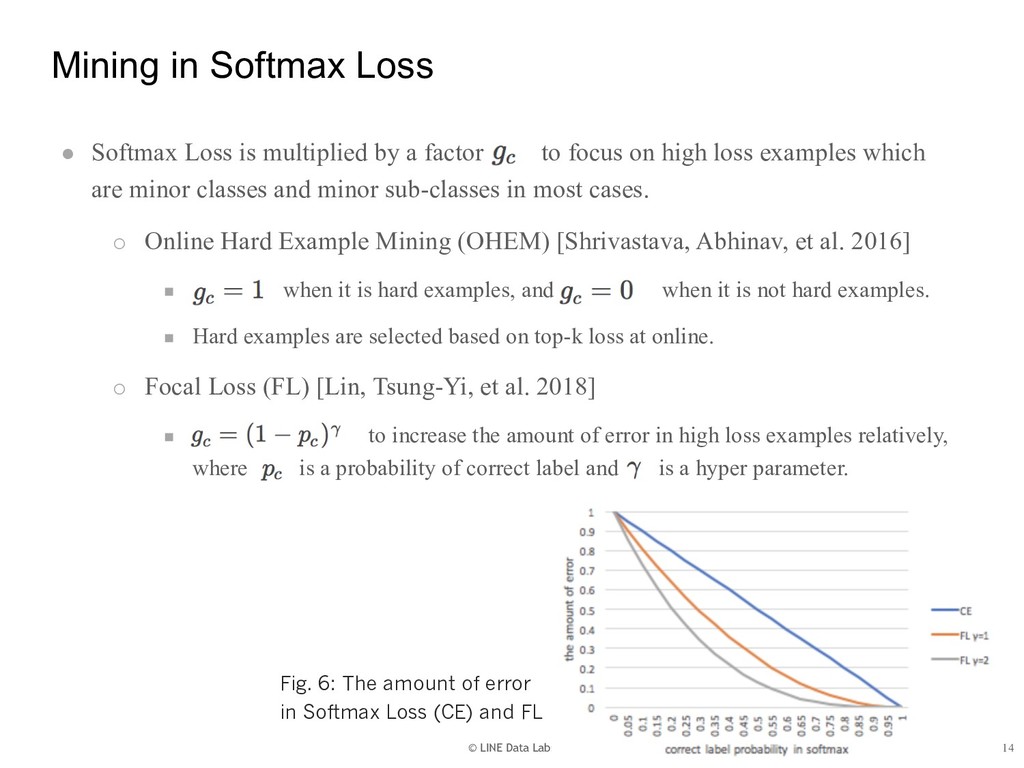{kind=link}
{kind=link}
{kind=link}
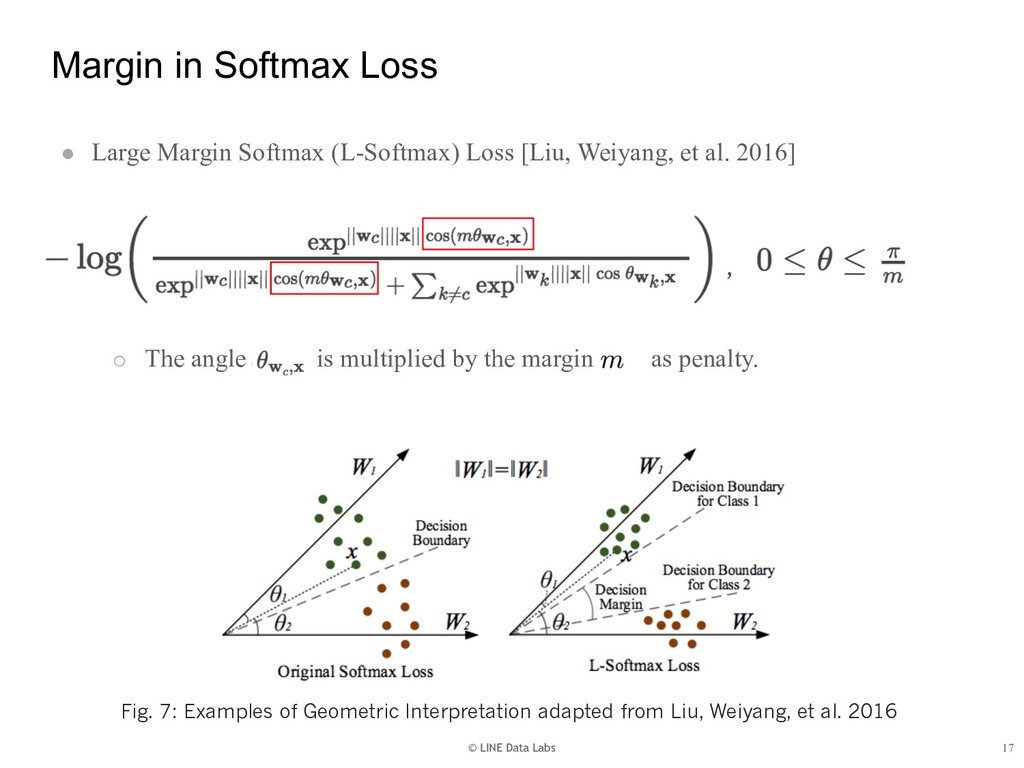{kind=link}
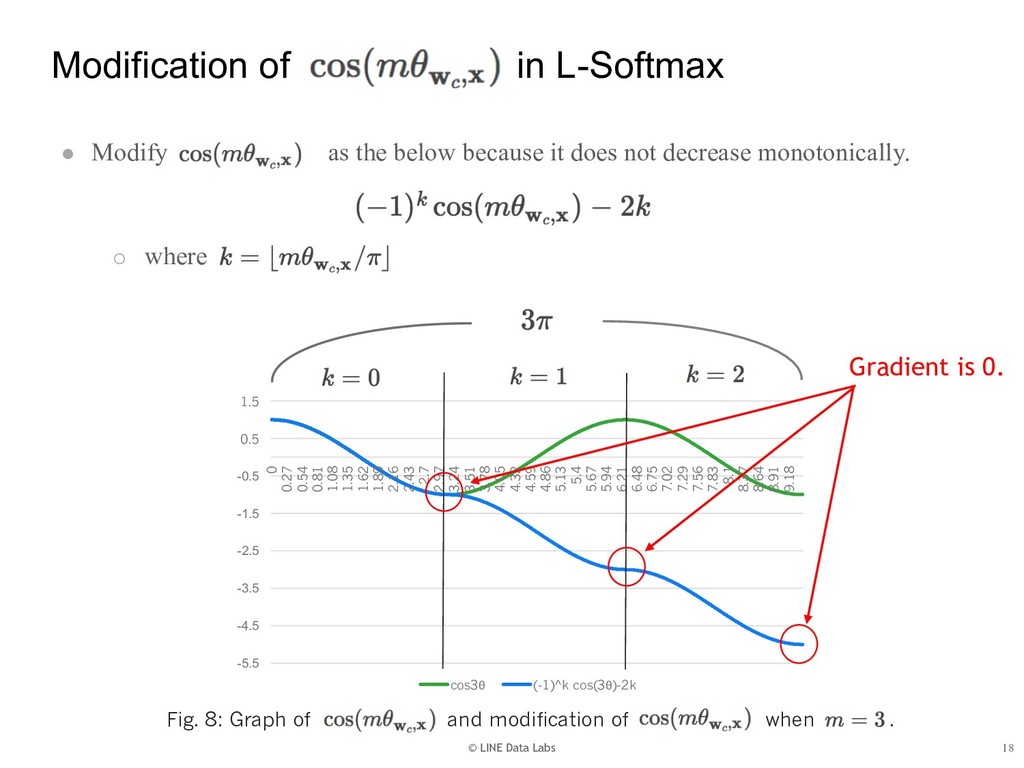{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
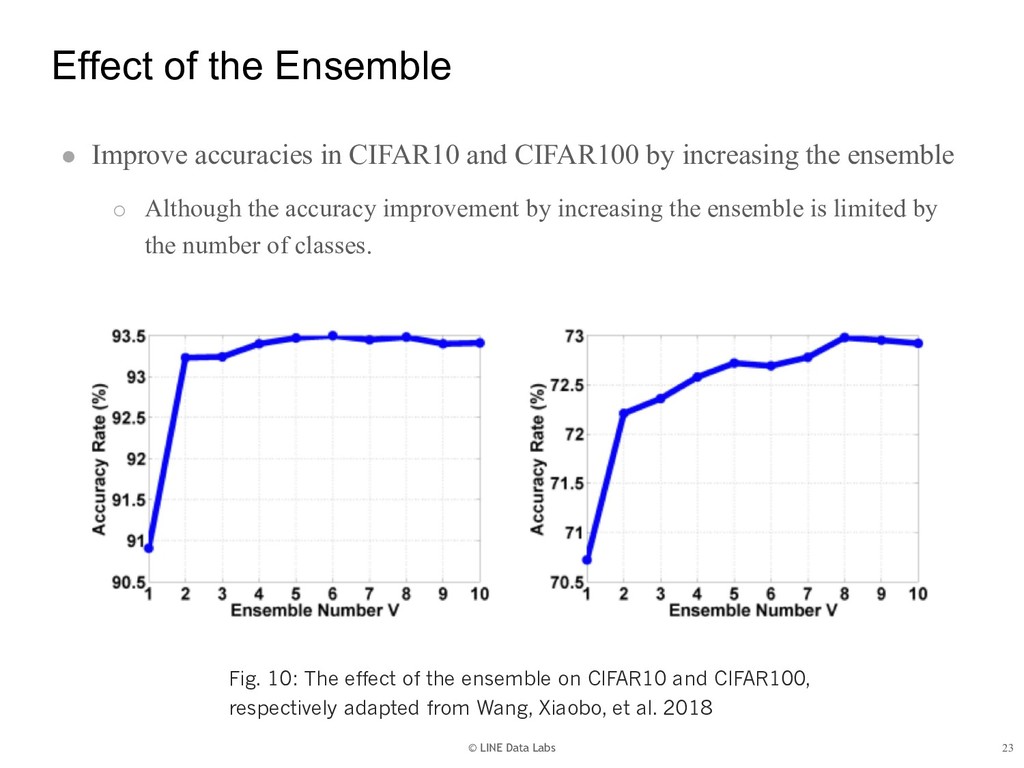{kind=link}
{kind=link}
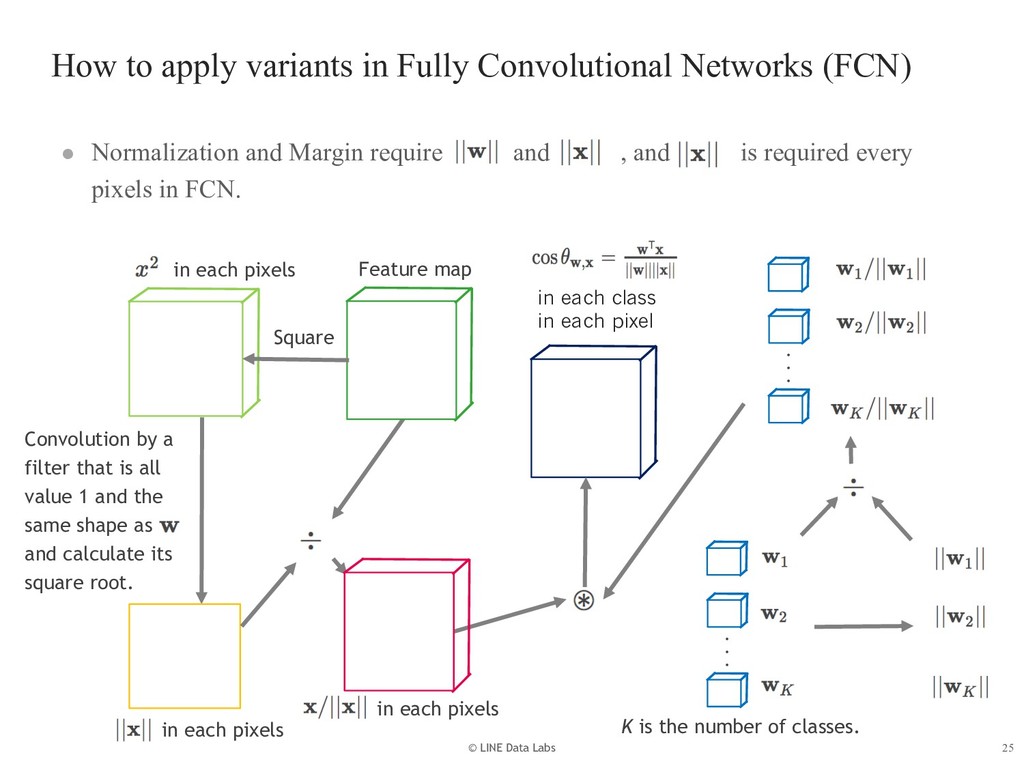{kind=link}
{kind=link}
{kind=link}
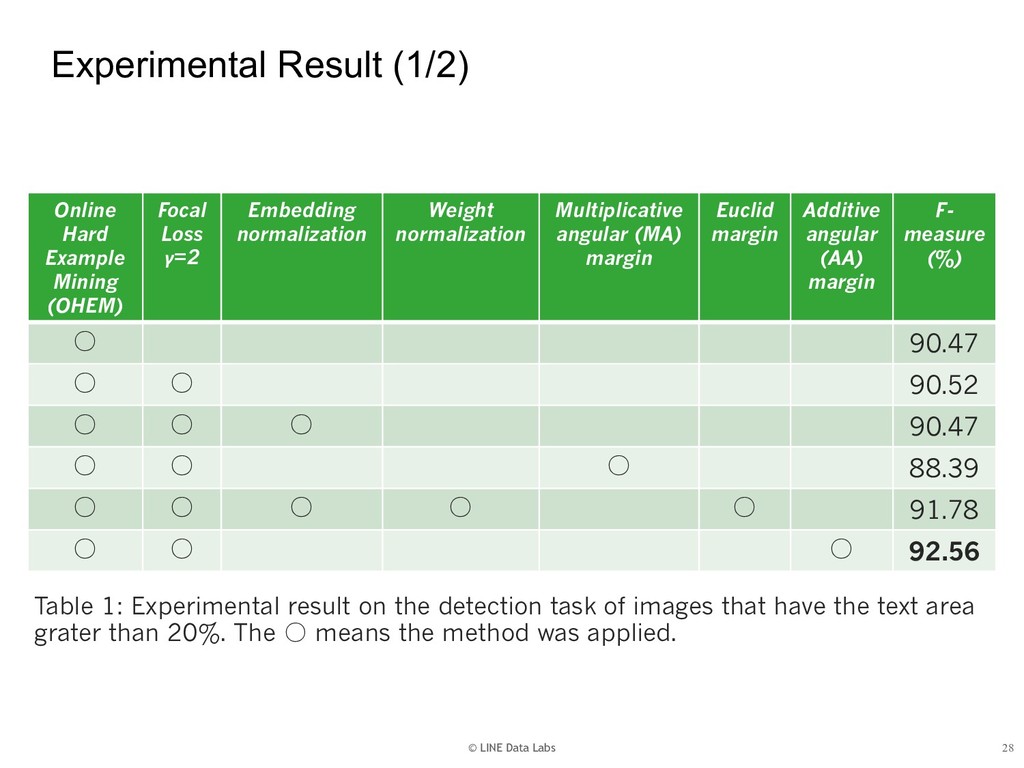{kind=link}
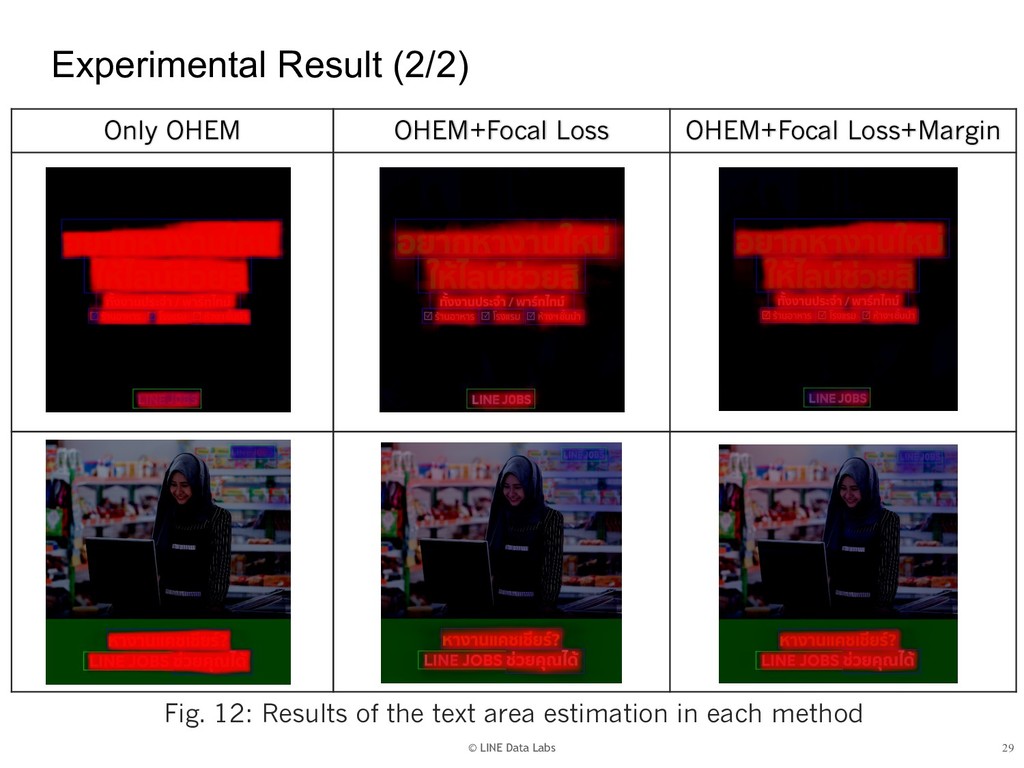{kind=link}
{kind=link}
{kind=link}
![© LINE Data Labs References (1/3) [Bridle, John S. 1990]](https://files.speakerdeck.com/presentations/29c9b55fa9454ed18f43bd03b1967b41/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}