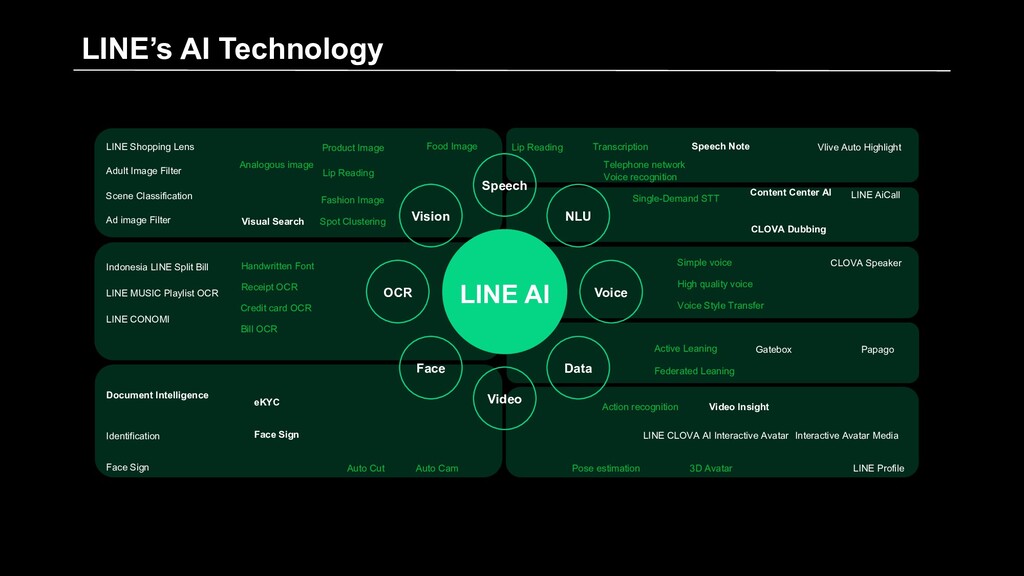
LINE Shopping Lens Adult Image Filter Scene Classification Ad image Filter Visual Search Analogous image Product Image Lip Reading Fashion Image Spot Clustering Food Image Indonesia LINE Split Bill LINE MUSIC Playlist OCR LINE CONOMI Handwritten Font Receipt OCR Credit card OCR Bill OCR Document Intelligence Identification Face Sign eKYC Face Sign Auto Cut Auto Cam Transcription Telephone network Voice recognition Single-Demand STT Simple voice High quality voice Voice Style Transfer Active Leaning Federated Leaning Action recognition Pose estimation Speech Note Vlive Auto Highlight Content Center AI CLOVA Dubbing LINE AiCall CLOVA Speaker Gatebox Papago Video Insight LINE CLOVA AI Interactive Avatar Interactive Avatar Media 3D Avatar LINE Profile Lip Reading LINE’s AI Technology
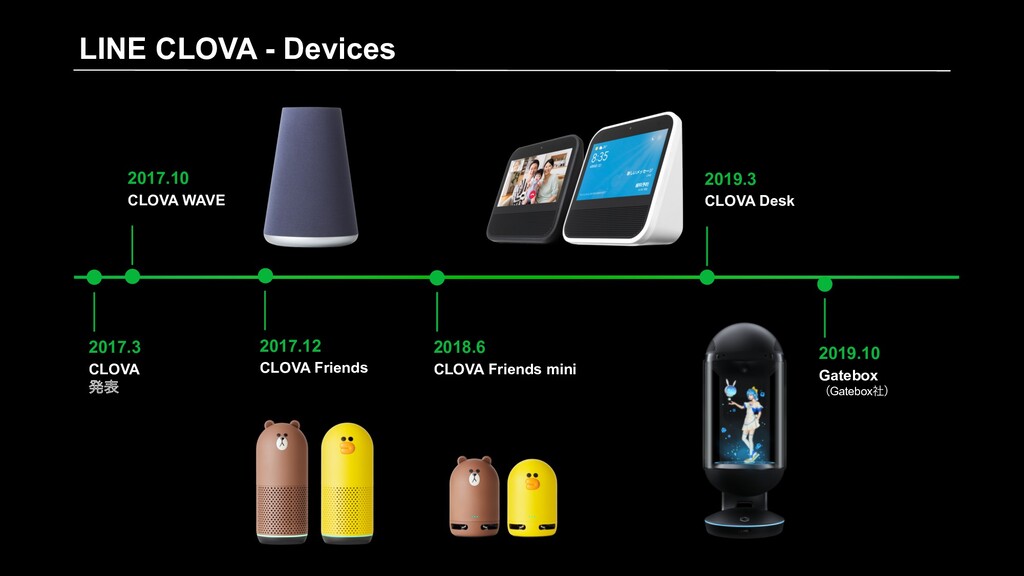
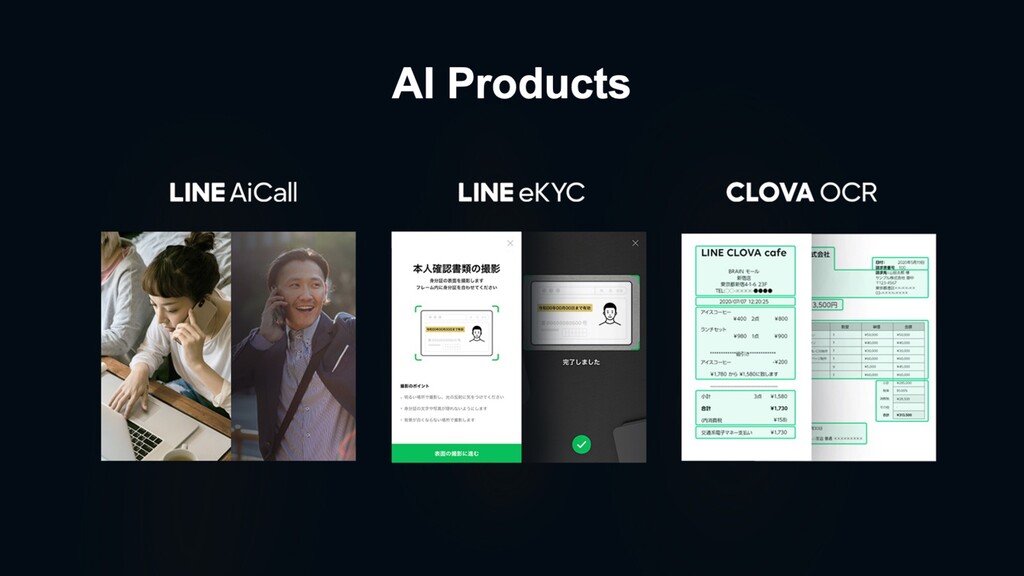
Speech CLOVA Text Analytics CLOVA Face CLOVA Assistant LINE AiCall LINE eKYC Solutions Devices CLOVA Friends CLOVA Friends mini CLOVA Desk CLOVA WAVE LINE’s AI Technology Brand
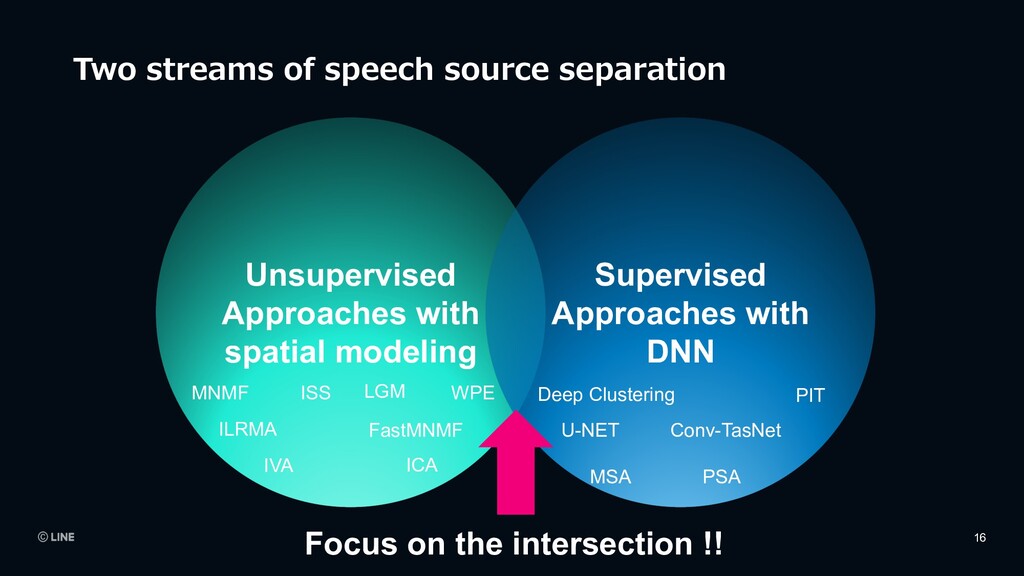
› Diverse categories of environmental sounds City Surveillance › Scream › Shouting › Glass breaking Home Monitoring › Speech › Dog barking › home appliances
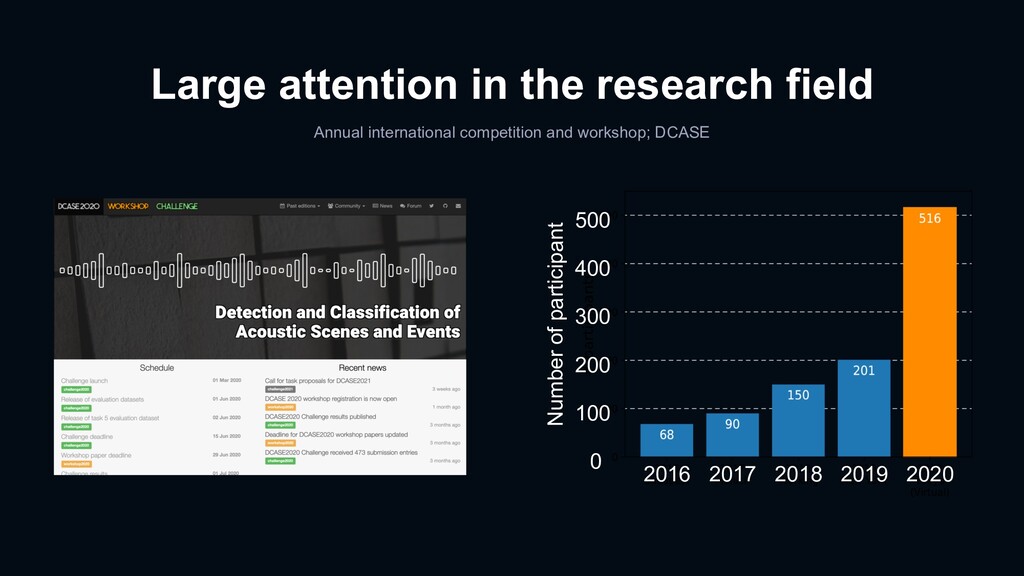
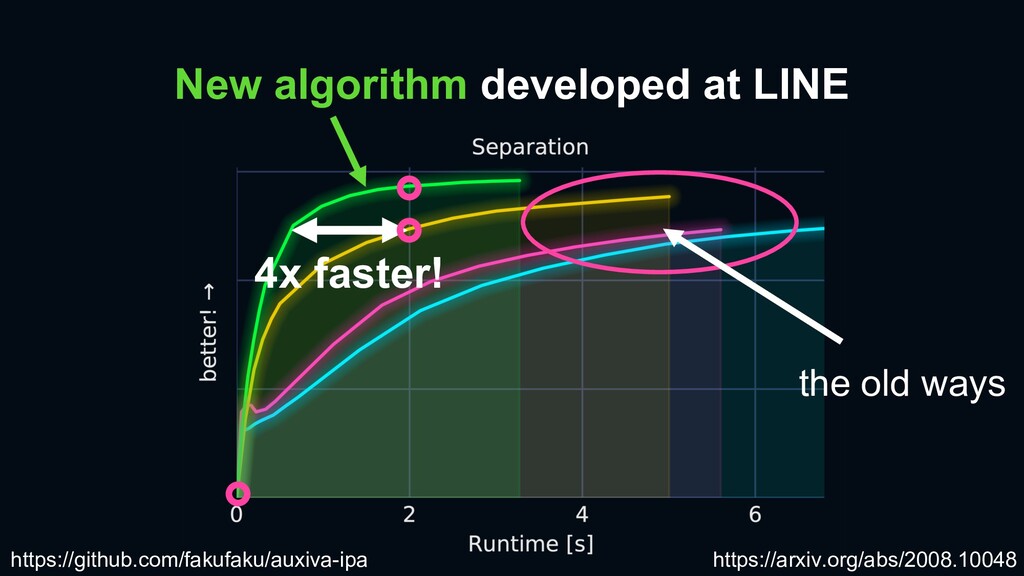
21 teams, 72 system submission › 14.6 % higher than Baseline system › 3.3 % higher than 2nd place team submission Our team http://dcase.community/challenge2020/task-sound-event-detection-and-separation-in-domestic-environments-results
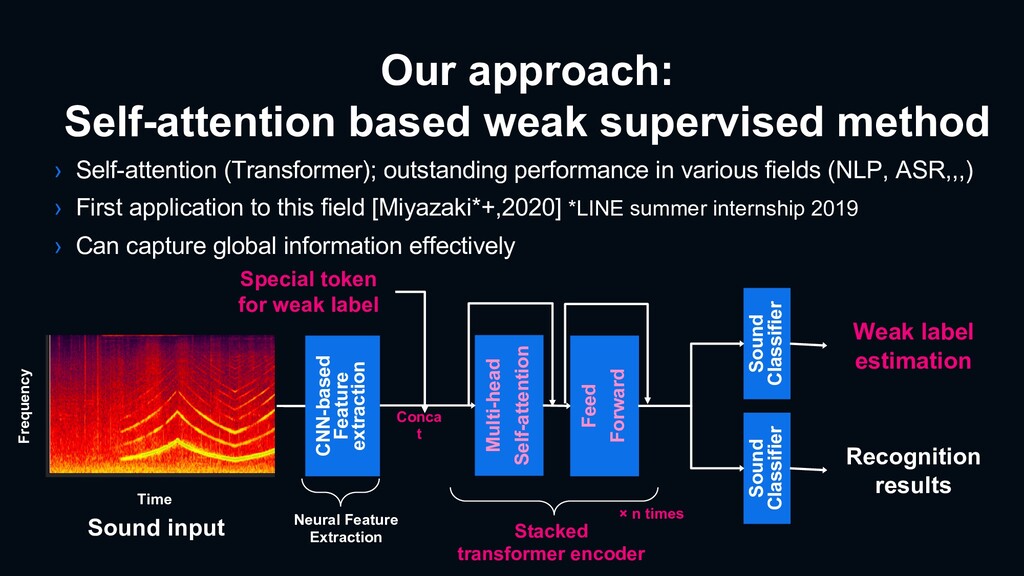
outstanding performance in various fields (NLP, ASR,,,) › First application to this field [Miyazaki*+,2020] *LINE summer internship 2019 › Can capture global information effectively Multi-head Self-attention Sound input Time Frequency Sound Classifier Weak label estimation Neural Feature Extraction Stacked transformer encoder Feed Forward Sound Classifier Recognition results Special token for weak label × n times Conca t CNN-based Feature extraction
human listening devices 2) Improvement of automatic speech recognition (ASR) performance Automatic minutes transcription ASR under car-noise environments
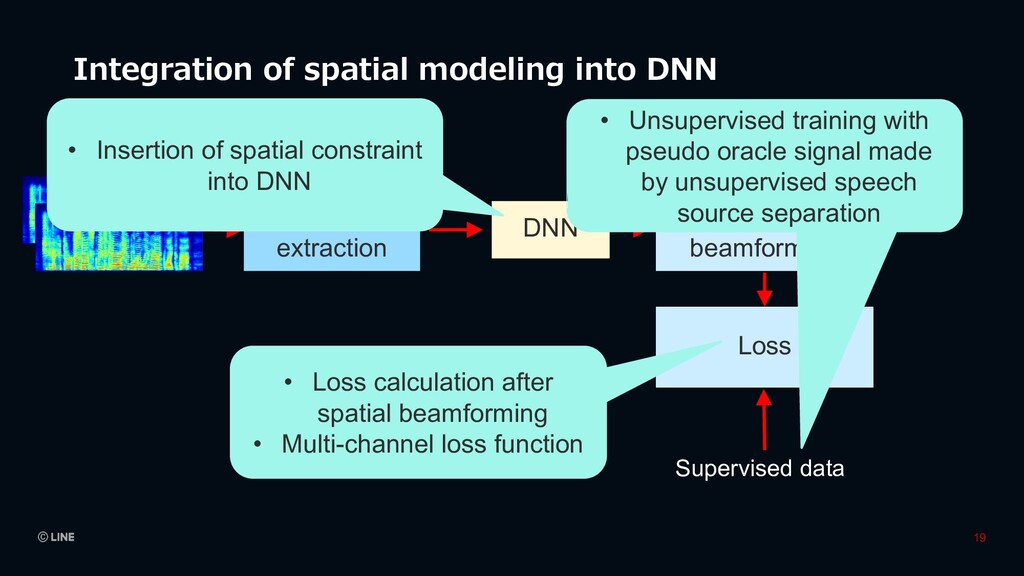
beamforming Loss Supervised data • Loss calculation after spatial beamforming • Multi-channel loss function • Insertion of spatial constraint into DNN • Unsupervised training with pseudo oracle signal made by unsupervised speech source separation
estimation Separated signal and estimated variance Back Propagation Non-DNN speech source separation Separated signal and estimated variance Loss Non-DNN speech source separation is utilized as a pseudo clean signal generator ! Deep Neural Network
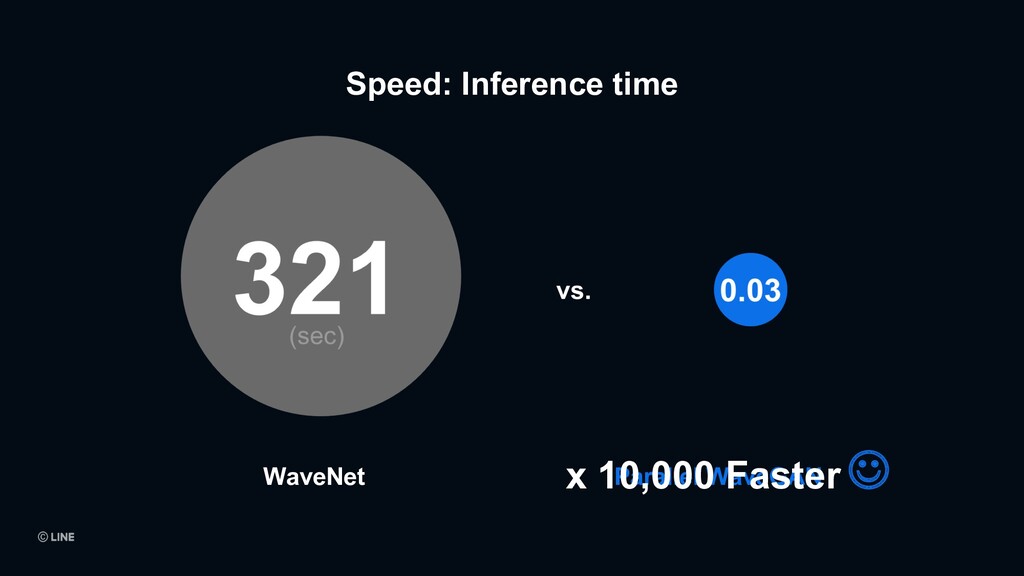
WaveGAN [4] R. Yamamoto et al., “Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram,” in Proc. ICASSP, 2020, pp. 703.
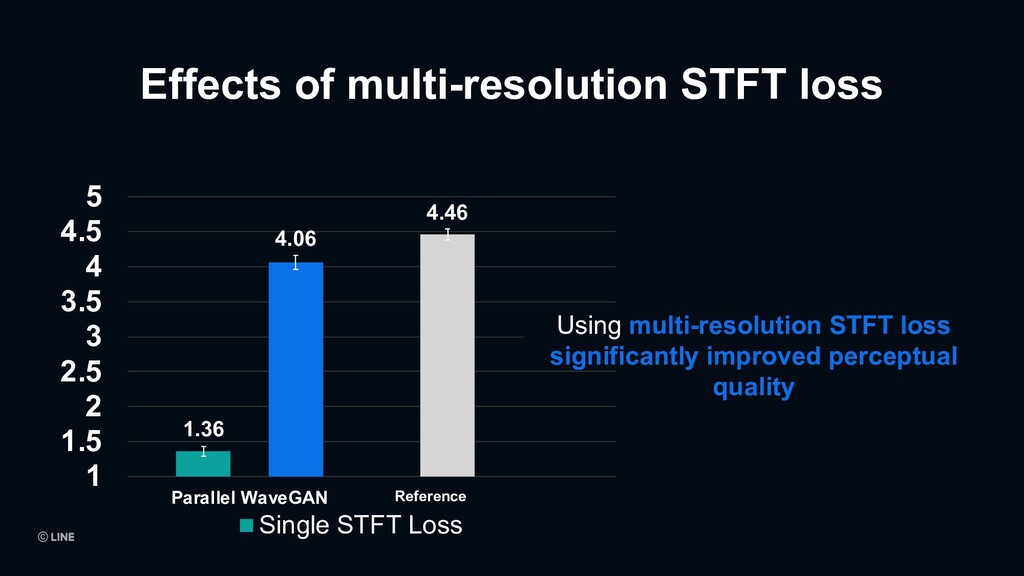
4.5 5 Parallel WaveGAN Single STFT Loss Using multi-resolution STFT loss significantly improved perceptual quality Effects of multi-resolution STFT loss Reference
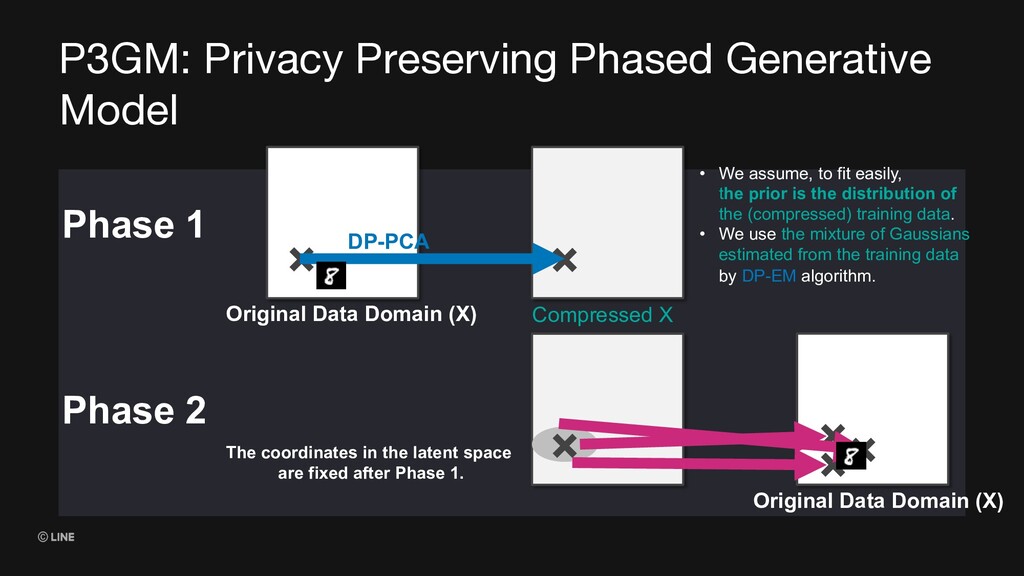
(X) • We assume, to fit easily, the prior is the distribution of the (compressed) training data. • We use the mixture of Gaussians estimated from the training data by DP-EM algorithm. × DP-PCA × × × × Original Data Domain (X) Compressed X Phase 1 Phase 2 The coordinates in the latent space are fixed after Phase 1.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Unsupervised DNN training [Togami ICASSP2020] Speech source model Spatial model](https://files.speakerdeck.com/presentations/eb40881bf9804ad89ca8229751119f0e/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}